植被净初级生产力(Net Primary Productivity,NPP)是生态学中的一个重要概念,表示单位面积植被在特定时间内吸收的净光合有机物,是衡量生态系统中植物通过光合作用所产生的有机物质减去植物呼吸作用消耗的有机物质的量,反映了植物通过光合作用固定的有机物质与其呼吸消耗之间的差异。之前我们分享过2001-2024年我国逐年植被净初级生产力(NPP)数据,该数据集来源于NASA-EARTHDATA的MOD17A3HGFv061数据集。数据单位为kgC/m²/year(千克碳/每平方米/每年),数据空间分辨率为500m,数据格式为Tiff。另外,我们基于此栅格数据按照行政区划取平均值,得到了Shp和Excel格式的我国省市 县三个等级的2001-2024年逐年植被净初级生产力(NPP)数据**!很多小伙伴拿到数据后反馈是否有空间尺度精细到乡镇级的逐年**NPP数据!
我们特地对上述逐年NPP栅格数据进行了进一步处理,依据乡镇(街道)边界,进行了边界内求平均数处理得到了本次分享的数据------Shp和Excel格式的我国乡镇(街道)的2001-2024年的逐年NPP数据!
对于数值需要说明的是:①原始逐年NPP栅格数据的比例因子为0.0001,本文对其统一乘以0.0001,使逐年NPP数值缩放至−1~1区间。②在计算乡镇尺度的逐年平均NPP时,先扣除栅格数据中的特殊值(包括行政区域范围内经比例因子0.0001转换后的特定设置值),再对剩余有效像元进行平均值计算。③缺失值说明:shp文件中数值为0表示缺失值,Excel文件中缺失值以空白单元格表示;原始栅格数据中特殊值的含义见下文说明:
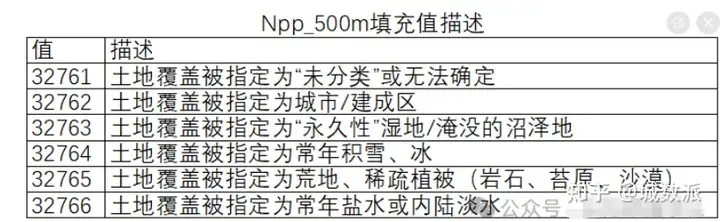
以下为数据的详细介绍:
数据预览
全国乡镇2001-2024年逐年NPP数据提供Excel和Shp两种格式的数据,所有年份的NPP数据汇总在一个Excel文件和一个Shp文件中。
我们以Excel格式的全国乡镇的2001-2024年逐年NPP为例来预览一下数据,数据字段包括省份名称、城市名称、区县名称、乡镇名称、完整名称和逐年NPP数值。
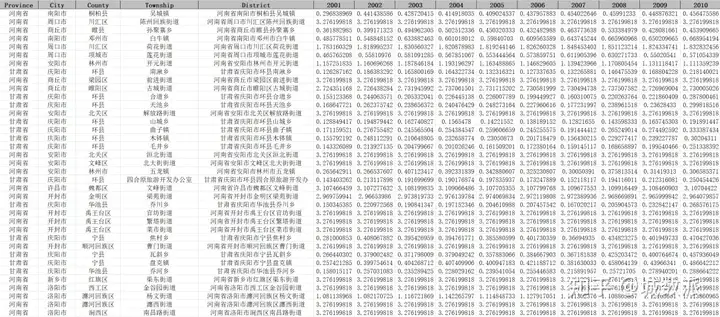
2001-2024年全国各乡镇逐年NPP数据(Excel格式)
接着,我们再以乡镇级别2024年NPP为例来预览一下Shp格式的数据:
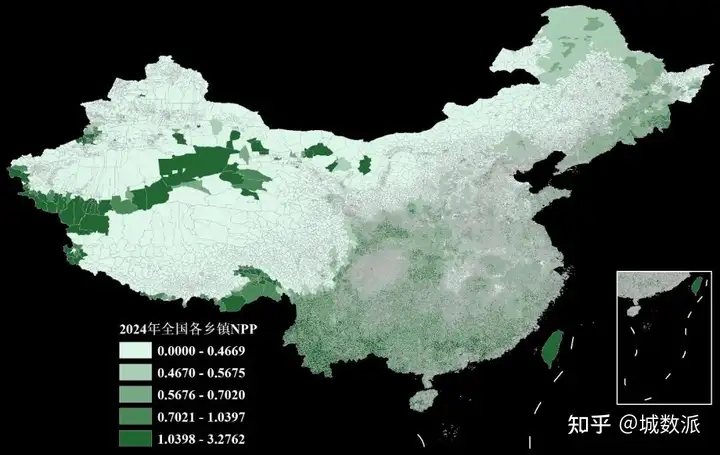
2024年全国各乡镇逐年NPP(Shp格式)
数据详情
数据来源:
原始逐年NPP栅格数据来源于NASA地球科学数据网站(NASA-EARTHDATA)
行政区划数据来源:
该数据的处理使用到了乡镇行政区划数据,该数据较难获取,我们综合对比后,采用的"学研录"公众号分享的乡镇边界数据!需要说明的是:乡镇行政边界数据没有官方来源,因此本数据的精度有待考量,可能会存在错误,大家在使用的时候自行判断和调整!
数据处理说明:
基于2001-2024年逐年NPP栅格数据,依据上述乡镇行政边界数据,对每个乡镇(街道)的年NPP值进行了求平均值处理,最终得到了全国乡镇(街道)的年NPP数据。
数据格式:
Shp和Excel格式
时间范围:
2001年-2024年(逐年)
数据单位:
kgC/m²/year(千克碳/每平方米/每年)
空间范围:
全国乡镇
数据坐标:
GCS_WGS_1984
数据引用:
Running, S., M. Zhao. <i>MODIS/Terra Net Primary Production Gap-Filled Yearly L4 Global 500m SIN Grid V061</i>. 2021, distributed by NASA EOSDIS Land Processes Distributed Active Archive Center
如有数据使用需求请按照官方平台的要求进行引用,更多数据详情可以查看官网获悉!
【下载→
方式一(推荐):主页 *个人* 简介
方式二:数据下载方式汇总-CSDN博客