Claude 4.6 深度对比:Sonnet vs Opus,如何选择最适合你的模型?
2026年2月,Anthropic 连续发布两款重磅模型:Opus 4.6 和 Sonnet 4.6。这次更新不仅是性能提升,更是一次性价比革命------Sonnet 4.6 以仅 Opus 五分之一的价格,提供接近旗舰级的性能。
本文基于 Anthropic 官方文档和基准测试数据,深入分析这两款模型的差异、适用场景和选型策略,帮助你做出明智的技术决策。
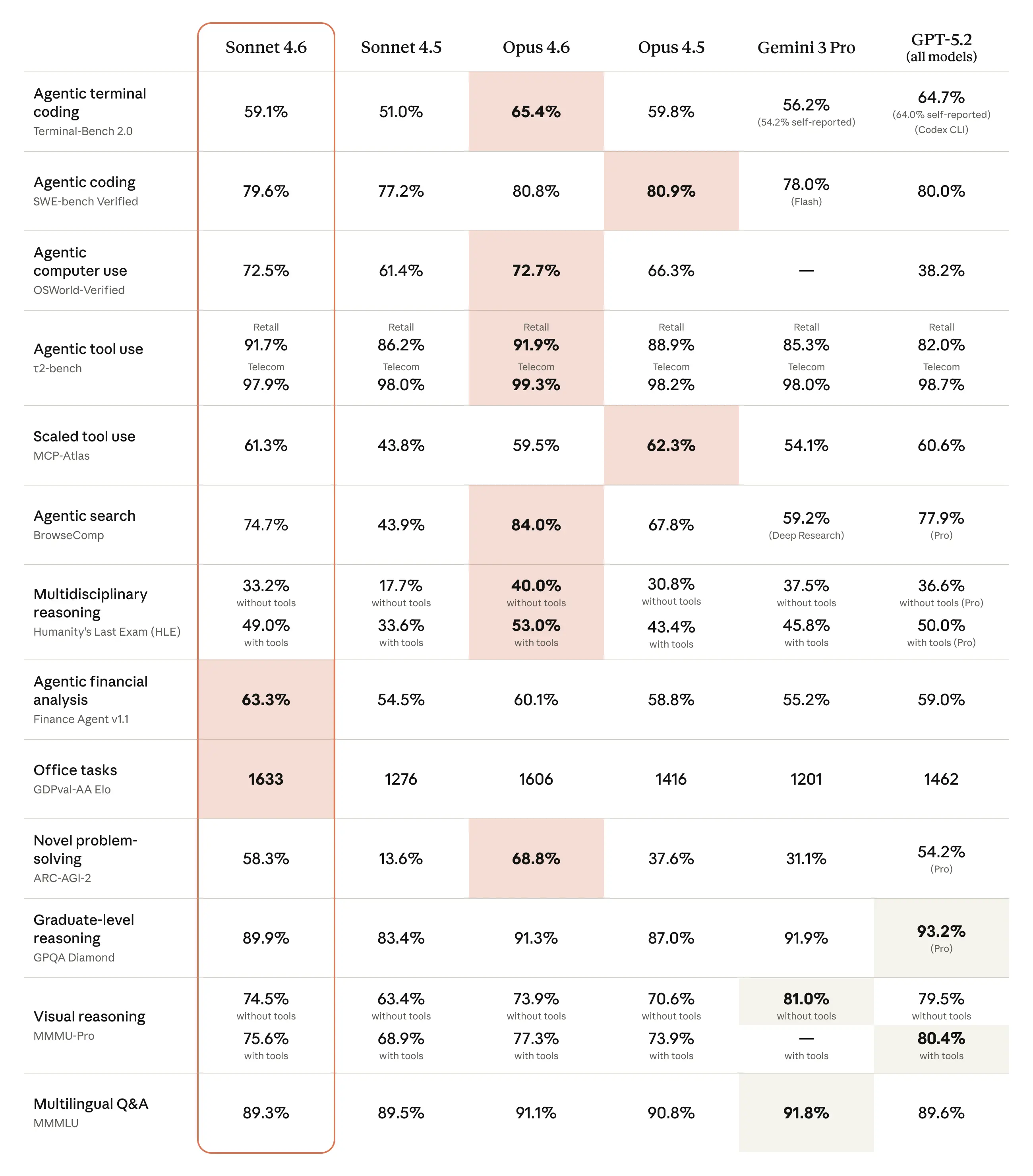
一、核心参数对比
价格与规格一览
| 参数 | Claude Opus 4.6 | Claude Sonnet 4.6 | 差异 |
|---|---|---|---|
| 发布日期 | 2026年2月5日 | 2026年2月17日 | - |
| 定位 | 旗舰级 | 平衡型 | - |
| 输入价格 | $5/MTok | $3/MTok | Sonnet 便宜40% |
| 输出价格 | $25/MTok | $15/MTok | Sonnet 便宜40% |
| 上下文窗口 | 1M tokens (beta) | 1M tokens (beta) | 持平 |
| 输出限制 | 128K tokens | 未明确说明 | Opus 更优 |
| 长上下文定价 | >200K: 10/37.5 | >200K: 6/22.5 | Sonnet 便宜40% |
注: MTok = 百万 tokens。长上下文定价为输入/输出每百万 tokens 价格。
基准测试表现
| 测试项目 | Opus 4.6 | Sonnet 4.6 | 说明 |
|---|---|---|---|
| Terminal-Bench 2.0 | 行业最高 | - | 智能体编码评估 |
| Humanity's Last Exam | 行业领先 | - | 跨学科推理测试 |
| GDPval-AA | 超越 GPT-5.2 约144分 | 接近 Opus 水平 | 经济价值知识工作 |
| OfficeQA | - | 与 Opus 4.6 持平 | 企业文档理解 |
| 用户偏好度 | - | 59% 偏好 Sonnet 4.6 胜过 Opus 4.5 | Anthropic 内部测试 |
数据来源: Anthropic 官方发布公告(2026年2月)
二、核心能力深度解析
2.1 推理能力:深度 vs 效率
Opus 4.6:深度推理的标杆
Opus 4.6 在以下场景表现出明显优势:
- 多步骤复杂任务:在 Terminal-Bench 2.0(智能体编码评估)中达到行业最高分,能够处理需要长时间规划和多轮工具调用的任务
- 边缘情况处理:Anthropic 官方报告称,Opus 4.6 会"更仔细地重新审视推理",在难问题上通过"想更久"来提升准确率
- 跨领域综合推理:在 Humanity's Last Exam(复杂跨学科推理测试)中领先所有前沿模型
典型用例:
- 大型代码库的系统性重构
- 需要多轮推理的安全审计
- 跨多个专业领域的复杂分析
Sonnet 4.6:接近旗舰的性价比之选
令人惊讶的是,Sonnet 4.6 在很多场景下并不逊色:
- 用户真实偏好:在 Anthropic 内部测试中,59% 的情况下用户更偏好 Sonnet 4.6 而非 Opus 4.5
- 一致性提升:用户反馈 Sonnet 4.6"更少过度工程化,更少懒惰",指令遵循能力显著增强
- 幻觉率降低:开发者报告 Sonnet 4.6 在多步骤任务中更少虚假声称成功,更少幻觉
典型用例:
- 日常开发任务(代码编写、调试)
- 前端开发与 UI 设计
- 数据分析与可视化
- 文档理解与摘要
2.2 代码能力:代理级别的突破
Opus 4.6:智能体编码的里程碑
Opus 4.6 在代码领域的突破主要体现在"代理能力"(Agentic Coding):
- 多文件自主操作:能够跨越多个文件进行修改,理解文件间的依赖关系
- 大型代码库可靠运行:官方称其在"大型代码库中运行更可靠"
- 自我纠错:更好的代码审查和调试技能,能捕获自己的错误
早期合作伙伴反馈:
"Claude Opus 4.6 在代理规划上有巨大飞跃。它将复杂任务拆分为独立子任务,并行运行工具和子代理,并精准识别阻塞点。"
------ Michele Catasta,Replit 总裁
Sonnet 4.6:开发者的日常利器
虽然不是为极致代理任务设计,但 Sonnet 4.6 在开发者日常工作中表现优异:
- 快速编码:Opus 的"想更久"在某些场景下是成本而非优势
- 阅读上下文再修改:用户报告 Sonnet 4.6 更有效地阅读上下文,而不是盲目修改
- 逻辑整合:倾向于整合共享逻辑而非重复代码
开发者反馈:
"Claude Sonnet 4.6 的性能成本比极其出色。它在我们的编排评估中表现优异,能处理最复杂的代理工作负载。"
------ Michele Catasta,Replit 总裁
2.3 上下文管理:1M tokens 的真正突破
2026年最显著的技术突破是1M 上下文窗口从实验性走向实用化。但真正重要的不是容量,而是"如何有效使用全部上下文进行推理"。
Opus 4.6:长上下文推理的标杆
在 8-needle 1M MRCR v2(长上下文信息检索基准测试)中:
- Opus 4.6 得分:76%
- Sonnet 4.5 得分:18.5%
这个差距表明:Opus 4.6 在处理大量上下文时,性能下降远小于 Sonnet 4.5。官方称其"在长时间对话中保持焦点",并在 Vending-Bench Arena(模拟企业经营的测试)中比 Opus 4.5 多赚取 $3,050.53。
Sonnet 4.6:1M 上下文的平民化
Sonnet 4.6 同样配备了 1M 上下文窗口,这意味着:
- 上下文容量不再是"旗舰独占",而是"标准配置"
- 企业应用可以在不升级到 Opus 的情况下处理长文档(合同、研究报告、长对话历史)
- 成本降低的同时,获得处理复杂上下文的能力
关键洞察:1M 上下文的价值不在于"一次塞进更多内容",而在于"跨全部上下文有效推理"。Opus 4.6 在这方面的优势更明显,但 Sonnet 4.6 的平民化让更多场景成为可能。
三、适用场景指南
3.1 场景分类矩阵
| 场景类型 | 推荐模型 | 理由 | 成本考量 |
|---|---|---|---|
| 企业级代理系统 | Opus 4.6 | 最强的代理规划和执行能力,适合协调多个子代理工作流 | 高成本,但ROI高 |
| 大规模代码重构 | Opus 4.6 | 深度推理、careful planning,在大型代码库中更可靠 | 一次性任务,值得投入 |
| 日常开发任务 | Sonnet 4.6 | 成本效益最优,性能接近 Opus,用户偏好度高 | 长期成本可控 |
| 前端开发与设计 | Sonnet 4.6 | 客户反馈设计质量明显提升,需要的手动迭代更少 | 频繁使用,成本敏感 |
| 金融分析 | Sonnet 4.6 | 在客户测试中表现出色,OfficeQA 与 Opus 持平 | 数据密集型任务,性价比重要 |
| 多步骤办公任务 | Sonnet 4.6 | 在 OfficeQA 上与 Opus 4.6 持平,成本更低 | 常规企业流程 |
| 高风险安全审计 | Opus 4.6 | "做到恰到好处"最关键时,深度推理值得成本 | 一次性但关键的任务 |
3.2 选型决策树
开始
│
├─ 任务是否需要多代理协调?
│ ├─ 是 → Opus 4.6
│ └─ 否 → 下一步
│
├─ 上下文是否超过 200K tokens?
│ ├─ 是 → 评估是否真的需要 Opus 的深度推理
│ │ ├─ 是 → Opus 4.6(注意长上下文溢价)
│ │ └─ 否 → Sonnet 4.6(1M 上下文已足够)
│ └─ 否 → 下一步
│
├─ 任务失败成本是否极高?
│ ├─ 是(如安全审计、核心系统重构)→ Opus 4.6
│ └─ 否 → 下一步
│
└─ 默认选择 → Sonnet 4.6(在 80%+ 场景下已足够)四、成本优化策略
4.1 官方成本优化机制
Prompt Caching(提示缓存)
对于重复性交互模式,Prompt Caching 可以节省高达 90% 的成本:
| 模型 | 写入成本 | 读取成本 | 节省比例 |
|---|---|---|---|
| Opus 4.6 (≤200K) | $6.25/MTok | $0.50/MTok | 92% |
| Sonnet 4.6 (≤200K) | $3.75/MTok | $0.30/MTok | 92% |
适用场景:
- 企业知识库问答:相同文档被反复查询
- 代码审查工具:相同代码规范被多次应用
- 对话式应用:多轮对话中重复的系统提示词
Batch Processing(批处理)
对于异步批量任务,使用 Batch API 可获得 50% 成本节省:
- 适用场景:夜间数据生成、报告生成、批量代码审查
- 限制:非实时任务,可延迟处理
- ROI:对于大批量任务,节省显著
US-only Inference(美国独占推理)
- 价格系数:1.1x(输入和输出)
- 用途:满足数据驻留合规要求(如 GDPR、HIPAA)
- 权衡:10% 溢价换取合规保障
4.2 实用成本优化建议
1. 动态 Effort 调整
Anthropic 在 Opus 4.6 中引入了四个 Effort 等级:low、medium、high(默认)、max。
- 简单任务:使用 low/medium effort,避免 Opus 的"想更久"变成成本负担
- 复杂任务:使用 high/max effort,确保深度推理
- 策略:监控任务复杂度与完成质量,动态调整
2. 上下文长度优化
- 200K vs 1M:Opus 4.6 和 Sonnet 4.6 对 >200K tokens 的请求收取 2 倍价格
- 策略:评估任务是否真的需要 1M 上下文,200K 足够时避免溢价
- 技巧:使用 Context Compaction(上下文压缩)功能,自动总结较早上下文
3. 混合模型部署
对于企业级应用,可以考虑智能路由:
简单任务(如文档摘要、基础问答)→ Sonnet 4.6
中等复杂度(如数据分析、前端开发)→ Sonnet 4.6(高 effort)
复杂任务(如代码重构、代理编排)→ Opus 4.6(中 effort)
极度复杂(如安全审计、跨系统协调)→ Opus 4.6(max effort)成本估算示例:
假设一个企业应用的使用分布:
- 70% Sonnet 4.6
- 20% Sonnet 4.6(高 effort)
- 10% Opus 4.6
有效平均成本:
- 输入:$3.70/MTok(相比全 Opus 节省 26%)
- 输出:$18.50/MTok(相比全 Opus 节省 26%)
五、未来演进趋势
5.1 模型层级战略稳定
Anthropic 的三层架构已成固定战略,短期内不太可能改变:
| 层级 | 定位 | 价格区间 | 目标市场 |
|---|---|---|---|
| Haiku | 极致速度、成本效率 | 1/5 | 高并发、简单任务 |
| Sonnet | 智能与成本的平衡 | 3/15 | 通用任务、企业规模部署 |
| Opus | 最强推理能力 | 5/25 | 复杂、高风险任务 |
战略意义: 明确的市场细分,避免单一模型"一刀切",让开发者根据任务复杂度选择合适层级。
5.2 技术演进方向
1. Hybrid Reasoning(混合推理)模式成熟化
Opus 4.6 和 Sonnet 4.6 均支持两种模式:
- 即时响应:快速回答,适合简单任务
- 扩展思考(Extended Thinking):深度推理,适合复杂任务
Adaptive Thinking:模型自主判断何时需要深度推理,而非强制选择。这标志着从"二选一"到"智能自适应"的演进。
2. Agent Teams(代理团队)标准化
Claude Code 现支持多代理并行工作:
- 多个代理可以同时处理不同组件
- 通过 Shift+Up/Down 或 tmux 直接接管任何子代理
- 代理间共享上下文,实现协作
趋势: 从单一代理到代理编排,模拟人类团队协作模式。
3. Context Compaction(上下文压缩)
自动总结较早上下文,扩展有效上下文长度。这解决了"上下文腐化"(context rot)问题------即随着对话变长,性能下降的现象。
4. 计算机使用能力提升
在 OSWorld(AI 计算机使用基准测试)中:
- Sonnet 4.6 在 16 个月内稳步提升
- 早期用户反馈:在导航复杂电子表格、填写多步骤网页表单等任务中达到"人类水平"能力
5.3 定价策略信号
1. 性能锚定下的价格稳定
- Sonnet 4.6 性能接近 Opus,但价格保持不变(3/15)
- Opus 4.6 相比 Opus 4.1 价格下降 67%,但 4.6 与 4.5 持平
信号: Anthropic 可能通过规模化降低边际成本,而非通过提价变现。这表明价格战接近尾声,竞争焦点转向性能、效率和安全。
2. 差异化定价精细化
从"一刀切"定价到基于使用场景的精细定价:
- 长上下文(>200K)价格翻倍:鼓励合理使用上下文
- Premium 特性收费:如 US-only 推理(1.1x)、Fast Mode(6x 价格)
- Prompt Caching:大幅降低重复交互成本
3. 开发者友好机制
Anthropic 持续推出降低开发者试错成本的机制:
- Prompt Caching:降低重复性任务成本
- Batch Processing:批量任务 50% 折扣
- Effort 控制:让开发者平衡速度与成本
趋势: 降低开发者试错成本,鼓励规模化应用,而非通过定价限制使用。
5.4 安全与能力平衡
关键观察:
Opus 4.6 在自动化安全审计中显示出"最低的过度拒绝率"(refusal rate),这意味着:
- 模型在拒绝有害请求的同时,尽量不拒绝良性请求
- 避免了"过度安全"导致的用户体验下降
安全投资:
Anthropic 同时投资于:
- 防御性应用:帮助发现和修补开源软件漏洞
- 检测机制:开发了 6 个新的网络安全探测器
- 可解释性研究:使用可解释性工具理解模型行为
信号: Anthropic 正积极推动防御性 AI 应用,而非仅仅限制有害用途。这表明其战略是"安全与能力并重",而非"安全优先于能力"。
六、总结与建议
6.1 核心洞察
1. Sonnet 4.6 是转折点
以 Sonnet 的价格提供接近 Opus 的性能,用户在 59% 的情况下更偏好它而非 Opus 4.5。这标志着"中端模型"开始侵蚀"旗舰模型"的使用场景。
对于大多数开发者,Sonnet 4.6 应该成为默认选择,仅在明确需要深度推理时切换到 Opus 4.6。
2. Opus 4.6 是技术标杆
在代理编码、深度推理、长上下文检索等维度达到行业领先,证明"更贵 ≠ 更好"的时代------只有需要极致能力时才值得为 Opus 付费。
3. 1M 上下文成为新战场
不再是简单的"容量"竞争,而是"如何有效使用全部上下文进行推理"的竞争。Opus 4.6 在 MRCR v2 的 76% vs Sonnet 4.5 的 18.5% 是关键证据。
4. 价格战基本结束
Opus 4.5/4.6 和 Sonnet 4.x 的价格已稳定,未来竞争焦点转向性能、效率、安全而非单纯降价。
6.2 行动建议
对于开发者:
- 默认使用 Sonnet 4.6:覆盖 80%+ 用例,性能已足够
- 仅在必要时升级 Opus 4.6:深度推理、大型代码库、高风险决策任务
- 利用 Prompt Caching:对于重复性任务模式,可节省最高 90% 成本
- 动态调整 Effort:简单任务用 low/medium,复杂任务用 high/max
对于企业决策者:
- Sonnet 4.6 作为默认:覆盖大多数企业场景,成本效益最优
- Opus 4.6 作为特例:仅用于关键路径任务(如代码重构、代理编排)
- 构建智能路由机制:按任务复杂度动态选择模型
- 预算规划:假设 70% Sonnet + 30% Opus 的混合模式,有效平均成本比全 Opus 节省约 26%
对于行业观察者:
- 关注代理能力成熟度:Opus 4.6 在 Terminal-Bench 2.0 的领先表明 AI 代理正在接近生产就绪
- 观察企业部署规模:Sonnet 4.6 的性价比革命可能加速企业 AI 的采用曲线
- 监控安全与能力平衡:Anthropic 的防御性 AI 投资可能成为行业趋势
6.3 最终思考
Claude 4.6 的发布不仅是一次性能升级,更是一次产品策略的成熟------从"模型竞赛"转向"场景化落地"。
对于大多数用户,Sonnet 4.6 已经足够强大。而对于那些真正需要极致能力的场景,Opus 4.6 的存在保证了上限。
最终的问题不是"哪个模型更好",而是"哪个模型更适合你的场景"。希望本文的对比和分析能帮助你做出明智的选择。
数据来源:
- Anthropic 官方公告:Introducing Claude Opus 4.6(2026年2月5日)
- Anthropic 官方公告:Introducing Claude Sonnet 4.6(2026年2月17日)
- Anthropic 官方定价页面:https://claude.com/pricing
- Anthropic 官方文档:Claude Model Overview
更新时间: 2026年2月18日