1. 大规模可靠运行的两个硬条件
想让大规模 Flink 作业稳定跑起来,必须同时满足:
- 能稳定、可靠地完成 checkpoint(否则 Exactly-once 形同虚设,故障恢复也没有可靠恢复点)
- 故障后有足够资源"追平"故障期间积压的数据(catch up),否则恢复只是开始,真正的灾难是恢复后吞吐打不过输入
注意:容量评估一定要在"开启 checkpoint 的真实状态"下做基线,因为 checkpoint 会持续占用网络、CPU、IO 等资源。
2. 先会看:UI 与关键指标怎么读
最简单的入口是 Flink Web UI 的 Checkpoints 页面(以及 task 级 metrics)。在大状态扩容时,有两个数尤其关键:
2.1 Barrier 到达时间:触发 checkpoint 后多久算子收到第一个 barrier
当这个值持续偏高,意味着 barrier 从 source 走到下游很慢,通常说明系统处于持续背压(backpressure)状态:处理不过来、网络拥堵、下游外部系统慢、数据倾斜等。
直觉解释:barrier 就像"打卡点",它都走不动了,说明整个流水线在堵。
2.2 Alignment Duration:从收到第一个 barrier 到收到最后一个 barrier 的时间
这是 aligned exactly-once checkpoint 的核心成本。
aligned exactly-once 的对齐逻辑是:某些通道先到 barrier 后,这些通道会被阻塞,直到其他通道也到 barrier 才能继续。这段等待就是 alignment duration。
alignment 高通常意味着:
- 上游某些通道更慢(数据倾斜、慢分区、网络抖动)
- 下游背压导致部分通道积压严重
补充:在 unaligned exactly-once 或 at-least-once checkpoint 中,subtask 不需要为了对齐阻塞通道,因此 alignment 的形态和影响会不同。
2.3 一个很重要的误区
Unaligned checkpoints 可以加快 barrier 传播、减轻对齐等待,但它并不会消除根因。背压仍在,端到端延迟也仍然高。把 unaligned 当"背压万能药"是典型误用。
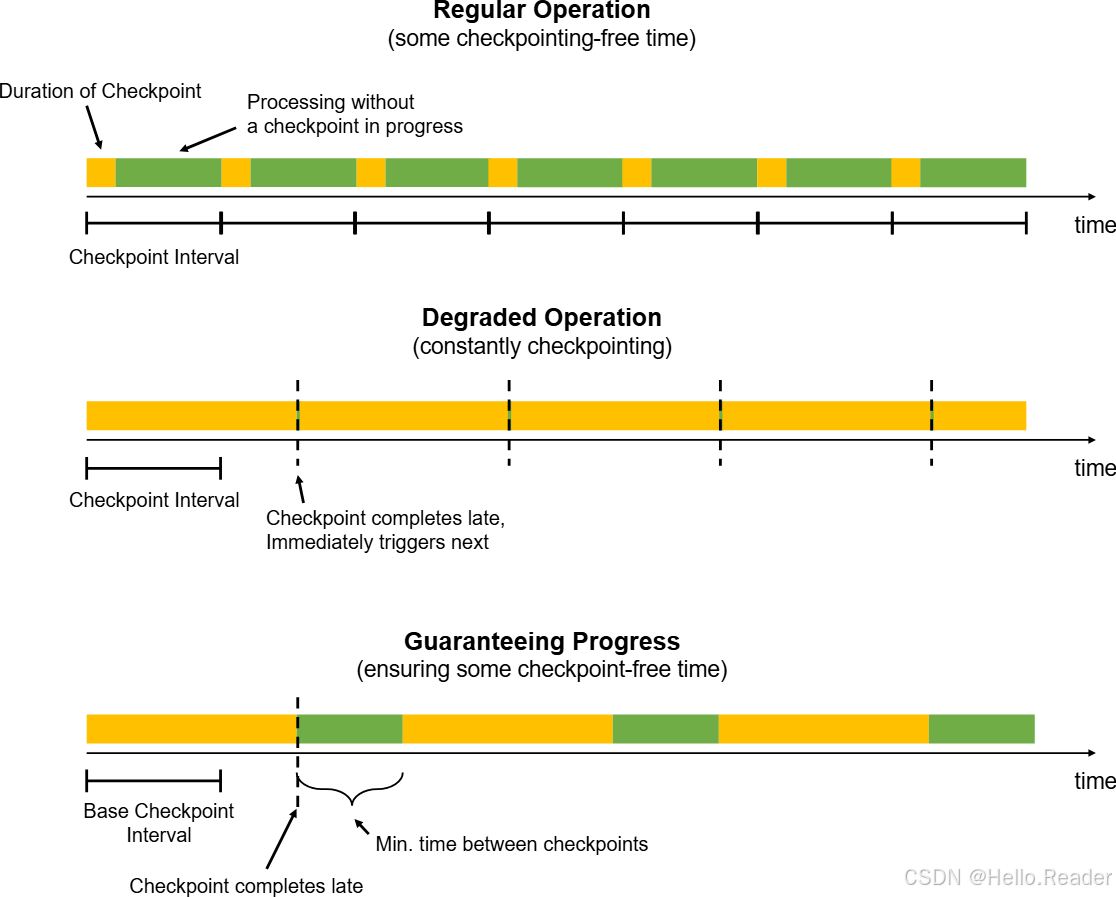
3. Checkpoint 频率调优:别让作业陷入"永远在做 checkpoint"
Checkpoint 有一个很常见的坏现象:
- 你设置了 interval 比如 30s
- 但实际 checkpoint 完成要 50s
- Flink 会等当前 checkpoint 完成后立刻触发下一个
- 结果:作业几乎一直在 checkpoint,资源被 checkpoint 吸干,算子处理进度越来越慢,进一步让 checkpoint 更慢,进入恶性循环
3.1 设置最小间隔:Min Pause Between Checkpoints
当你观察到 checkpoint 频繁"顶着跑",第一件要做的就是加上最小间隔,让作业喘口气:
java
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(30_000); // 例如 30s含义:上一次 checkpoint 结束后,至少等待这么久才能开始下一次。
适用场景:
- checkpoint 存储偶尔慢(HDFS/S3 抖动)
- 状态增大后 checkpoint 明显变慢
- 业务允许 checkpoint 稍微稀疏一些,但要求整体吞吐稳定
3.2 并发 checkpoint:大状态下通常是"坑"
Flink 可以配置允许多个 checkpoint 并发进行,但在大状态作业里,这往往会把网络与 IO 打爆:
- 多个 checkpoint 并发上传
- 多份状态快照同时占资源
- checkpoint 更慢,业务更慢
经验原则:大状态优先保持 max-concurrent-checkpoints 偏小(很多场景 1 就很好),并发要上也要先压测再上。
另外要注意:手动触发 savepoint 时,可能会与正在进行的 checkpoint 并发,这会进一步放大资源竞争。
4. RocksDB / ForSt:大状态的"状态引擎"怎么调
大规模 keyed state 的主力通常是 RocksDB State Backend。ForSt 的设计与 RocksDB 很像,参数体系也类似,所以以下从 RocksDB 角度讲,ForSt 也可以照同思路做对应配置。
4.1 增量 Checkpoint:第一优先级
如果你在意 checkpoint 时长,增量 checkpoint 应该是最先考虑的手段之一。
核心思想:checkpoint 只记录相对于上次完成 checkpoint 的变化,而不是每次都做全量备份。
典型收益:
- 大状态下 checkpoint 时间大幅下降
- 长尾改善明显(但仍取决于 compaction 和上传特性)
注意点:
- UI 里显示的 checkpointed size 在增量模式下通常是 delta,不是全量状态大小
- 恢复时间可能变快也可能变慢:网络瓶颈 vs CPU/IO 瓶颈下结论不一样
4.2 Timer 放哪里:RocksDB 还是 JVM Heap
默认 timer 存在 RocksDB(稳健、可扩展)。
如果作业几乎没 timer(没有 window,不用 ProcessFunction timer),把 timer 放堆上可能更快:
- 好处:少量 timer 场景可能提升性能
- 代价:timer 受内存限制,且可能增加 checkpoint 成本
配置开关(示意,具体以你版本文档为准):
yaml
state.backend.rocksdb.timer-service.factory: heap使用建议:非常谨慎。只有在你明确 timer 很少、且压测证明收益明显时再上。
4.3 RocksDB 内存:最影响性能的那根杠杆
RocksDB backend 性能高度依赖它可用的内存(cache、write buffer 等)。
默认 Flink 会用 managed memory 给 RocksDB 做"总量管控":
yaml
state.backend.rocksdb.memory.managed: true调优的推荐顺序是:
- 先加 managed memory(最粗但最有效)
- 再根据瓶颈调整读写路径内存比例(write-buffer-ratio 等)
- 最后才进入 expert mode(OptionsFactory / ColumnFamily 级别调参)
4.3.1 优先增加 managed memory
很多大容器(多 GB 进程内存)场景下,默认 managed memory fraction(比如 0.4)是偏保守的,通常可以适当提高,尤其当你的业务逻辑并不需要很大 JVM heap 时。
4.3.2 你有多少 state,就有多少 ColumnFamily
一个很容易忽略的事实:
- RocksDB 中每个 state 往往对应一个 ColumnFamily
- ColumnFamily 越多,需要的 write buffers 等资源越多
- 所以"状态数量很多"的作业,即使总状态大小不夸张,也可能因为 CF 太多导致写侧瓶颈(频繁 flush)
当你看到频繁 MemTable flush(写侧瓶颈),但又不能给更多内存时,可以尝试提高写侧内存比例:
yaml
state.backend.rocksdb.memory.write-buffer-ratio: 0.6 # 示例:从 0.5 提到 0.64.3.3 managed vs 非 managed 模式对比测试
你也可以临时把 managed memory 关掉做对比基线:
yaml
state.backend.rocksdb.memory.managed: false但要知道副作用:RocksDB 内存占用会随着状态数量变化而变化,应用一改拓扑/一加 state,内存占用就可能飙升。
你给的经验规则很实用:非 managed 模式下,内存上界大约会随 num-states-across-all-tasks * num-slots 成比例增长(timer 也算 state)。
4.3.4 Expert mode:OptionsFactory 减少 flush
当你状态很多、flush 很频繁且内存无法增加时,可以用 OptionsFactory 做更细粒度调参,例如增加后台 flush 线程、降低 arena block size 等:
java
public class MyOptionsFactory implements ConfigurableRocksDBOptionsFactory {
@Override
public DBOptions createDBOptions(DBOptions currentOptions, Collection<AutoCloseable> handlesToClose) {
return currentOptions.setMaxBackgroundFlushes(4);
}
@Override
public ColumnFamilyOptions createColumnOptions(
ColumnFamilyOptions currentOptions, Collection<AutoCloseable> handlesToClose) {
return currentOptions.setArenaBlockSize(1024 * 1024);
}
@Override
public OptionsFactory configure(ReadableConfig configuration) {
return this;
}
}这类调参一定要压测验证,因为它会改变 RocksDB 内部行为,对 CPU、IO、latency 都可能产生连锁反应。
5. 容量规划:让作业"平时不背压、故障后追得上"
容量规划的规则可以用三句话概括:
- 正常运行要能做到"不是长期背压"
- 在正常所需资源之上,再预留一部分资源用于故障恢复后的 catch-up
- 基线必须在 checkpoint 开启时测出来
5.1 背压不是绝对坏事,但"长期背压"是
短期背压用于抑制尖峰、外部系统短暂变慢、恢复后追数据是正常的。
危险的是长期背压:它意味着你的持续处理能力低于持续输入能力。
5.2 Window 的"脉冲负载"要算进去
Window 往下游发射结果常常是"脉冲式"的:
- 窗口构建阶段下游看似很闲
- 窗口触发时下游瞬间爆忙
下游并行度与资源要按"脉冲峰值处理速度"规划,而不是按平均值。
5.3 最大并行度(max parallelism)一定要提前设好
后期想靠 savepoint rescale 扩容,max parallelism 是硬上限。建议一开始就设到合理的较大值,给未来扩容留空间。
原因:Flink 的 key-group 机制以 max-parallelism 粒度做状态切分与账本管理。
6. Checkpoint/Savepoint 压缩:什么时候值得开
Flink 支持对 checkpoint/savepoint 开启快照压缩(默认关),压缩算法是 snappy。
开启方式(Java):
java
ExecutionConfig executionConfig = new ExecutionConfig();
executionConfig.setUseSnapshotCompression(true);注意:对 RocksDB 增量快照没有影响,因为 RocksDB 内部格式本身就默认使用 snappy。
建议:
- HashMapStateBackend、全量快照的场景可以评估压缩的收益(省存储与网络)
- 增量 RocksDB 的收益不大,不要指望它解决大状态 checkpoint 慢的问题
7. Task-Local Recovery:大状态恢复提速的"捷径"
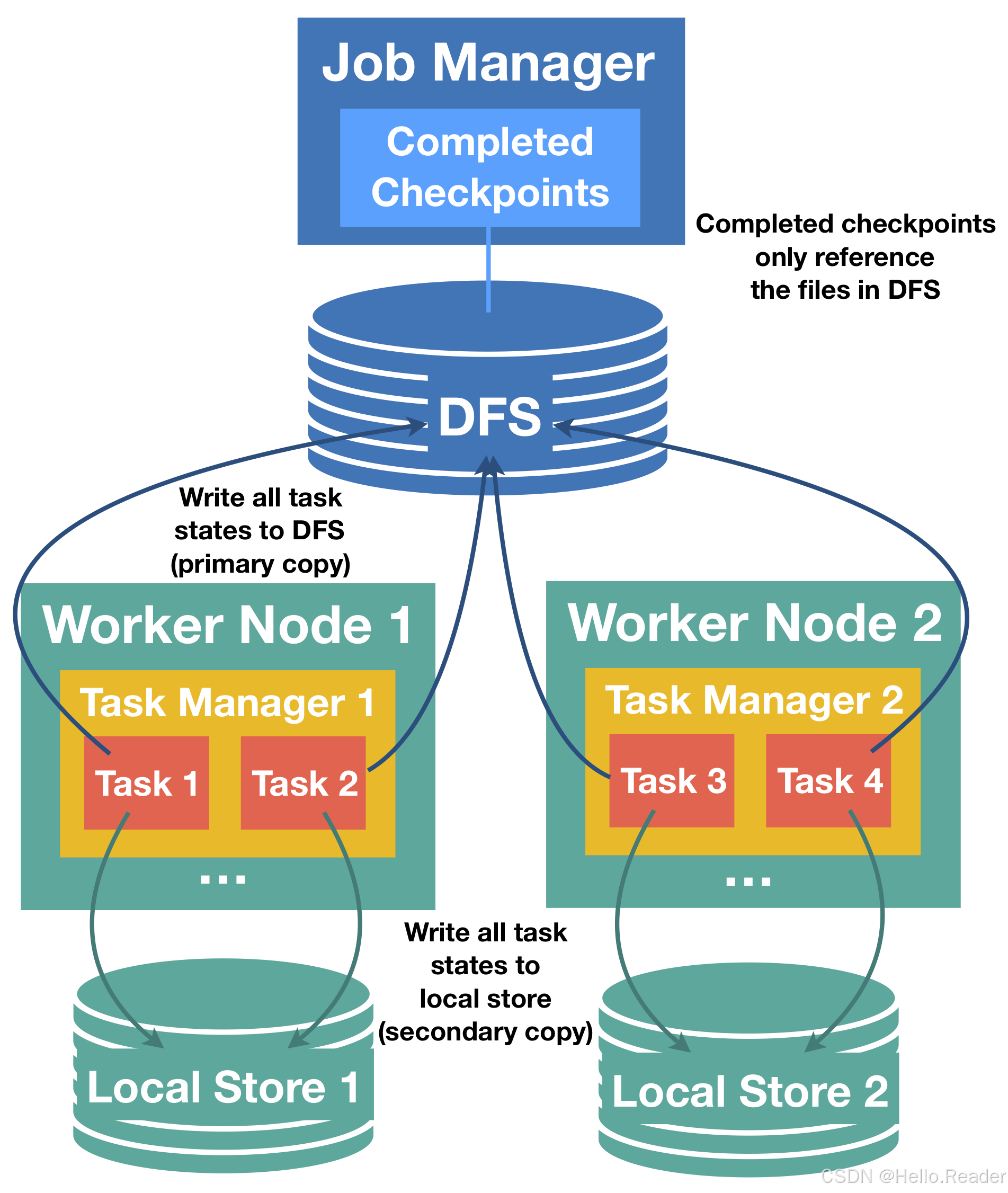
大状态作业恢复慢的主要原因之一是:恢复时每个 task 都要从远程存储(HDFS/S3)拉回状态,网络成本巨大。
Task-Local Recovery 的核心思想是:
- 每次 checkpoint 除了写一份到远端分布式存储(primary copy)
- 还在本地(TaskManager 本地盘/内存)保留一份 secondary copy
- 恢复时优先从本地恢复,若本地不可用再回退到远端恢复
7.1 关键语义:主副关系
- primary(远端)才是"真相",必须成功,否则 checkpoint 失败
- secondary(本地)写失败不会让 checkpoint 失败
- 恢复优先用本地,失败会透明回退到远端
- 本地副本可能只有部分状态,Flink 会"能本地就本地,其余回远端"
7.2 配置开关
默认关闭,需要显式开启(配置项示意):
yaml
state.backend.local-recovery: true重要限制:unaligned checkpoints 目前不支持 task-local recovery。
7.3 不同 backend 的成本差异
-
HashMapStateBackend:本地恢复通过复制 state 到本地文件实现,会增加额外写成本与占用本地盘
-
EmbeddedRocksDBStateBackend:
- 全量 checkpoint:同样需要额外复制
- 增量 checkpoint:本地副本基于 RocksDB 原生 checkpoint 机制,很多情况下不引入额外成本,只是保留本地目录不删
而且可能通过 hard link 共享活动文件,活动文件不额外占空间
7.4 hard link 的"物理设备"限制(很容易踩坑)
使用 hard link 共享文件要求:
- RocksDB 工作目录与 local recovery 目录在同一个物理设备上
否则 hard link 建立失败(你给的内容里也提到了相关 issue)
此外,如果 RocksDB 目录配置在多个物理设备上,也会影响 local recovery 的可用性。
7.5 为什么需要"保留分配"的调度策略
Task-local recovery 想生效,一个前提是:故障后尽可能把 task 调度回原来的 TaskManager/slot。
Flink 的 allocation-preserving scheduling 思路是:
- task 先请求"原来的 slot"
- 如果原 slot 不可用,再申请新 slot
- 避免恢复过程中 task 互相抢 slot,导致本来能回原位置的也回不去了,从而本地恢复收益下降
8. 一套可执行的调优流程(排障顺序建议)
当你遇到"大状态 checkpoint 慢/失败/长尾"的问题,可以按下面顺序走,基本不会乱:
- 看 UI:barrier 到达时间、alignment duration 是否持续偏高
偏高就先按背压思路排:下游慢、数据倾斜、网络抖动、外部系统慢、并行度不足 - 如果 checkpoint 频繁超过 interval,先加
minPauseBetweenCheckpoints,避免"永远 checkpoint" - 大状态 + RocksDB:优先启用增量 checkpoint
- RocksDB 性能不够:先加 managed memory,再考虑 write-buffer-ratio,再考虑 OptionsFactory
- 恢复慢:开启 task-local recovery(前提不是 unaligned checkpoint),并检查硬链接/目录设备条件
- 容量规划:确保正常不长期背压,并预留故障追数据的余量
- 若为了降低对齐成本上 unaligned,记住它不治根因,并且会限制某些能力(如 local recovery)