摘 要
本论文以简单的"Hello"程序为例,系统性地追踪和分析了一个C语言程序在Linux系统下从源代码到进程执行的全生命周期过程。通过分阶段实验,详细研究了程序预处理、编译、汇编、链接、加载、执行和终止的完整流程,深入揭示了计算机系统各层次间的协作机制。
主要内容包括:分析预处理阶段头文件展开和宏处理机制;研究编译器将C代码转换为汇编代码的优化策略;剖析汇编器生成可重定位目标文件的ELF格式结构;探讨链接器解析符号引用和地址重定位的工作原理;跟踪操作系统加载可执行文件创建进程的过程;观察进程执行中的信号处理和存储管理机制;分析程序I/O操作的底层实现。
研究方法采用自底向上的系统分析方法,结合GCC工具链、readelf、objdump、gdb等系统工具,对每个转换阶段生成的中间文件进行结构分析和代码对比。通过实际测试验证程序对键盘信号(Ctrl-C、Ctrl-Z等)的响应机制,并使用进程管理命令监控程序执行状态。
研究成果包括完整记录了程序转换各阶段的中间文件,验证了计算机系统抽象层次的有效性,展示了编译优化、动态链接、虚拟内存、进程隔离等核心系统原理的实际表现。本论文对理解程序在计算机系统中的完整执行过程具有理论意义,对系统编程、性能优化和安全分析具有实际参考价值。
**关键词:**计算机系统;程序生命周期;编译链接;进程管理;存储管理;ELF格式
自媒体发表截图
目 录
[第1章 概述. - 5 -](#第1章 概述. - 5 -)
[1.1 Hello简介. - 5 -](#1.1 Hello简介. - 5 -)
[1.2 环境与工具. - 5 -](#1.2 环境与工具. - 5 -)
[1.3 中间结果. - 5 -](#1.3 中间结果. - 5 -)
[1.4 本章小结. - 6 -](#1.4 本章小结. - 6 -)
[第2章 预处理. - 7 -](#第2章 预处理. - 7 -)
[2.1 预处理的概念与作用. - 7 -](#2.1 预处理的概念与作用. - 7 -)
[2.2在Ubuntu下预处理的命令. - 7 -](#2.2在Ubuntu下预处理的命令. - 7 -)
[2.3 Hello的预处理结果解析. - 8 -](#2.3 Hello的预处理结果解析. - 8 -)
[2.4 本章小结. - 10 -](#2.4 本章小结. - 10 -)
[第3章 编译. - 11 -](#第3章 编译. - 11 -)
[3.1 编译的概念与作用. - 11 -](#3.1 编译的概念与作用. - 11 -)
[3.2 在Ubuntu下编译的命令. - 11 -](#3.2 在Ubuntu下编译的命令. - 11 -)
[3.3 Hello的编译结果解析. - 14 -](#3.3 Hello的编译结果解析. - 14 -)
[3.4 本章小结. - 17 -](#3.4 本章小结. - 17 -)
[第4章 汇编. - 18 -](#第4章 汇编. - 18 -)
[4.1 汇编的概念与作用. - 18 -](#4.1 汇编的概念与作用. - 18 -)
[4.2 在Ubuntu下汇编的命令. - 18 -](#4.2 在Ubuntu下汇编的命令. - 18 -)
[4.3 可重定位目标elf格式. - 18 -](#4.3 可重定位目标elf格式. - 18 -)
[4.4 Hello.o的结果解析. - 21 -](#4.4 Hello.o的结果解析. - 21 -)
[4.5 本章小结. - 24 -](#4.5 本章小结. - 24 -)
[第5章 链接. - 25 -](#第5章 链接. - 25 -)
[5.1 链接的概念与作用. - 25 -](#5.1 链接的概念与作用. - 25 -)
[5.2 在Ubuntu下链接的命令. - 25 -](#5.2 在Ubuntu下链接的命令. - 25 -)
[5.3 可执行目标文件hello的格式. - 26 -](#5.3 可执行目标文件hello的格式. - 26 -)
[5.4 hello的虚拟地址空间. - 30 -](#5.4 hello的虚拟地址空间. - 30 -)
[5.5 链接的重定位过程分析. - 31 -](#5.5 链接的重定位过程分析. - 31 -)
[5.6 hello的执行流程. - 33 -](#5.6 hello的执行流程. - 33 -)
[5.7 Hello的动态链接分析. - 38 -](#5.7 Hello的动态链接分析. - 38 -)
[5.8 本章小结. - 38 -](#5.8 本章小结. - 38 -)
[第6章 hello进程管理. - 40 -](#第6章 hello进程管理. - 40 -)
[6.1 进程的概念与作用. - 40 -](#6.1 进程的概念与作用. - 40 -)
[6.2 简述壳Shell-bash的作用与处理流程. - 40 -](#6.2 简述壳Shell-bash的作用与处理流程. - 40 -)
[6.3 Hello的fork进程创建过程. - 40 -](#6.3 Hello的fork进程创建过程. - 40 -)
[6.4 Hello的execve过程. - 41 -](#6.4 Hello的execve过程. - 41 -)
[6.5 Hello的进程执行. - 41 -](#6.5 Hello的进程执行. - 41 -)
[6.6 hello的异常与信号处理. - 42 -](#6.6 hello的异常与信号处理. - 42 -)
[6.7本章小结. - 45 -](#6.7本章小结. - 45 -)
[第7章 hello的存储管理. - 46 -](#第7章 hello的存储管理. - 46 -)
[7.1 hello的存储器地址空间. - 46 -](#7.1 hello的存储器地址空间. - 46 -)
[7.2 Intel逻辑地址到线性地址的变换-段式管理. - 46 -](#7.2 Intel逻辑地址到线性地址的变换-段式管理. - 46 -)
[7.3 Hello的线性地址到物理地址的变换-页式管理. - 46 -](#7.3 Hello的线性地址到物理地址的变换-页式管理. - 46 -)
[7.4 TLB与四级页表支持下的VA到PA的变换. - 47 -](#7.4 TLB与四级页表支持下的VA到PA的变换. - 47 -)
[7.5 三级Cache支持下的物理内存访问. - 47 -](#7.5 三级Cache支持下的物理内存访问. - 47 -)
[7.6 hello进程fork时的内存映射. - 48 -](#7.6 hello进程fork时的内存映射. - 48 -)
[7.7 hello进程execve时的内存映射. - 48 -](#7.7 hello进程execve时的内存映射. - 48 -)
[7.8 缺页故障与缺页中断处理. - 48 -](#7.8 缺页故障与缺页中断处理. - 48 -)
[7.9动态存储分配管理. - 49 -](#7.9动态存储分配管理. - 49 -)
[7.10本章小结. - 49 -](#7.10本章小结. - 49 -)
[第8章 hello的IO管理. - 50 -](#第8章 hello的IO管理. - 50 -)
[8.1 Linux的IO设备管理方法. - 50 -](#8.1 Linux的IO设备管理方法. - 50 -)
[8.2 简述Unix IO接口及其函数. - 50 -](#8.2 简述Unix IO接口及其函数. - 50 -)
[8.3 printf的实现分析. - 51 -](#8.3 printf的实现分析. - 51 -)
[8.4 getchar的实现分析. - 52 -](#8.4 getchar的实现分析. - 52 -)
[8.5本章小结. - 52 -](#8.5本章小结. - 52 -)
[结论. - 53 -](#结论. - 53 -)
[附件. - 55 -](#附件. - 55 -)
[参考文献. - 56 -](#参考文献. - 56 -)
第1章 概述
1.1 Hello简介
P2P过程(从Program到Process):
1.编写程序:创建hello.c源代码文件
2.预处理:gcc -E 将#include和宏展开,生成hello.i
3.编译:gcc -S 将C代码转换为汇编代码,生成hello.s
4.汇编:gcc -c 将汇编代码转换为机器指令,生成hello.o
5.链接:gcc 将hello.o与库文件链接,生成可执行文件hello
6.加载运行:shell调用execve加载hello到内存创建进程
020过程(从Zero到Zero):
1.Zero:程序存储在磁盘上,没有执行
2.运行:shell创建子进程,execve加载程序,开始执行
3.执行中:进程在CPU上运行,调用系统函数
4.终止:main函数返回或调用exit,进程终止
5.Zero:进程终止,资源被回收,返回初始状态
1.2 环境与工具
硬件环境:x86-64 架构 PC
操作系统:Ubuntu 20.04 LTS(64 位)
编译器:gcc 9.x
调试工具:gdb、objdump、readelf
编辑器:VS Code / Vim
Shell:bash
1.3 中间结果
hello_linux.c - C语言源代码文件
hello.i - 预处理后文件(展开头文件)
hello.s - 汇编代码文件
hello.o - 可重定位目标文件(未链接)
hello - 最终可执行文件
hello_elf.txt - hello的ELF格式分析
hello_o_elf.txt - hello.o的ELF格式分析
hello_disasm.txt - hello反汇编代码
hello_o_disasm.txt - hello.o反汇编代码
hello_verbose - gcc详细编译日志
1.4 本章小结
本章介绍了Hello程序的P2P和020过程,说明了实验环境和工具,列出了实验中将生成的中间文件。
第2章 预处理
2.1 预处理的概念与作用
预处理是C语言编译过程的第一阶段,发生在源代码被真正编译之前。其主要作用是对源代码进行文本级别的处理,包括以下几个方面:
1.宏定义展开:将程序中所有通过#define定义的宏进行替换
2.文件包含:将#include指令指定的头文件内容插入到指令位置
3.条件编译:根据#if、#ifdef、#ifndef等条件编译指令决定是否编译特定代码段
4.注释删除:移除所有注释(包括单行注释//和多行注释/* */)
5.添加行号信息:为调试和错误报告添加行号和文件名信息
6.处理特殊指令:如#pragma、#error等特殊预处理指令
预处理不会进行语法检查,也不改变程序的语义,它只是为后续的编译阶段准备一个"纯净"的C代码文件。
2.2在Ubuntu下预处理的命令
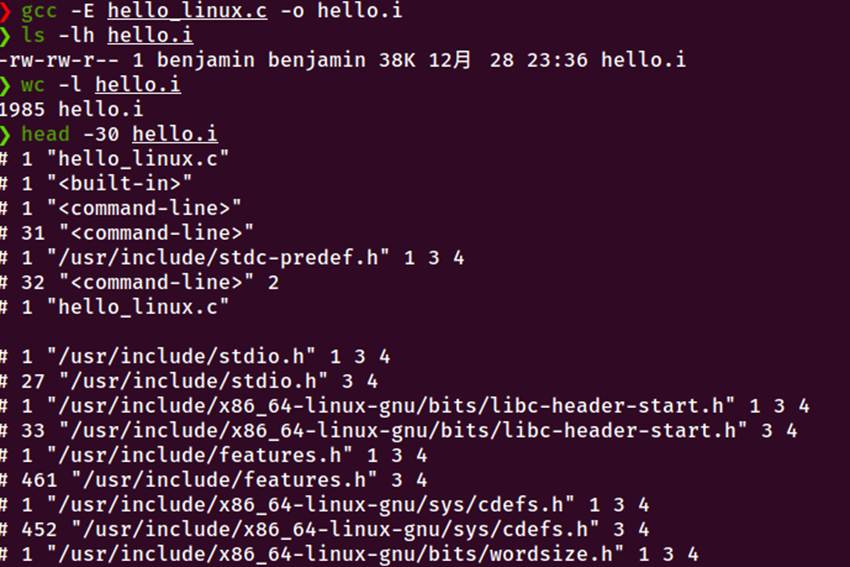
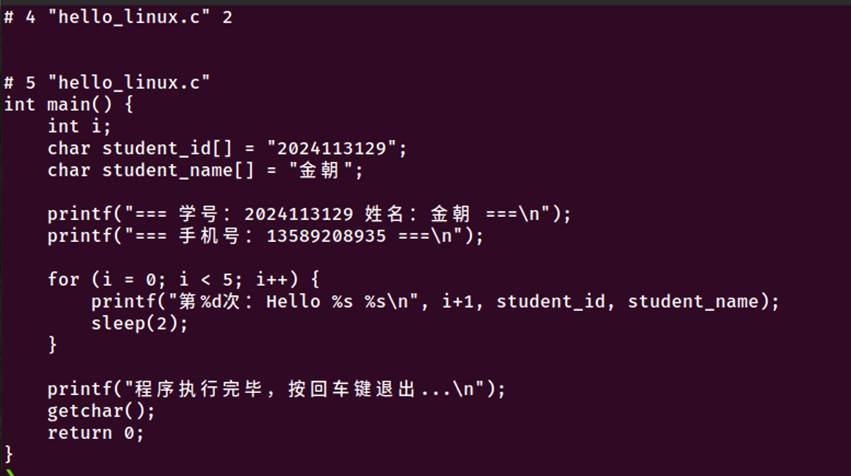
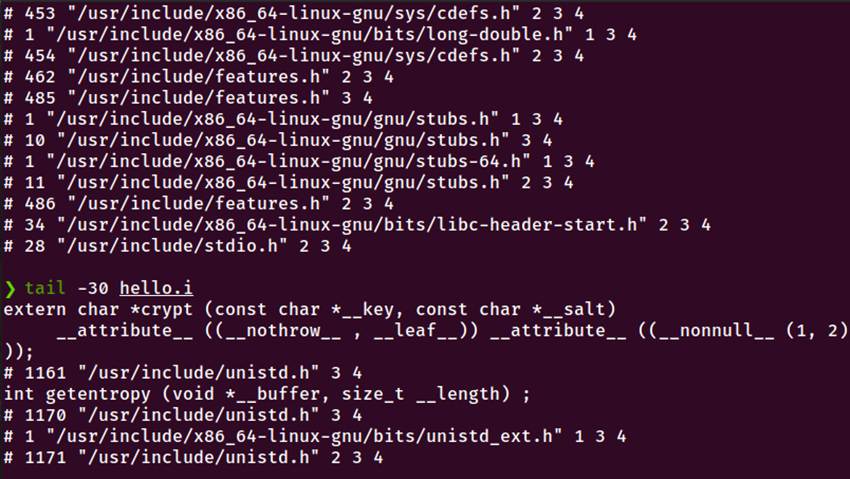
图2-1 预处理命令执行以及生成的文件
执行预处理命令
gcc -E hello_linux.c -o hello.i
2.3 Hello的预处理结果解析
2.3.1 行号标记分析
预处理文件开头包含大量行号标记,这些标记的格式为:
行号 "文件名" 标志位
2.3.2 头文件包含展开
预处理文件展示了头文件包含的完整展开过程:
1.stdio.h的展开:
源文件中的#include <stdio.h>被替换为stdio.h的全部内容
从输出可以看到,stdio.h又包含了多个其他头文件:
/usr/include/x86_64-linux-gnu/bits/libc-header-start.h
/usr/include/features.h
/usr/include/x86_64-linux-gnu/sys/cdefs.h
/usr/include/x86_64-linux-gnu/bits/wordsize.h
/usr/include/x86_64-linux-gnu/bits/long-double.h
/usr/include/x86_64-linux-gnu/gnu/stubs.h
/usr/include/x86_64-linux-gnu/gnu/stubs-64.h
2.unistd.h的展开:
源文件中的#include <unistd.h>被替换为unistd.h的相关内容
从文件末尾可以看到unistd.h包含了函数声明如crypt和getentropy
2.3.3 注释处理
对比源文件和预处理文件可以发现:
源文件开头的注释// hello_linux.c - 金朝 (2024113129) 的Linux版本在预处理文件中完全消失
预处理阶段删除了所有注释,不保留任何痕迹
2.3.4 用户代码保留
预处理文件最后部分(约30行)显示了用户编写的main函数完整内容:
int main() {
int i;
char student_id\[\] = "2024113129";
char student_name\[\] = "金朝";
printf("=== 学号:2024113129 姓名:金朝 ===\n");
printf("=== 手机号:13589208935 ===\n");
for (i = 0; i < 5; i++) {
printf("第%d次:Hello %s %s\n", i+1, student_id, student_name);
sleep(2);
}
printf("程序执行完毕,按回车键退出...\n");
getchar();
return 0;
}
2.3.5 关键预处理效果总结
|-------|---------|---------------------|
| 预处理功能 | 实际效果 | 在hello.i中的体现 |
| 文件包含 | 头文件内容插入 | stdio.h和unistd.h被展开 |
| 注释删除 | 移除所有注释 | 源文件注释消失 |
| 行号标记 | 添加调试信息 | 每行前的# 行号 "文件名"标记 |
| 条件编译 | 处理条件指令 | 头文件中的条件编译被处理 |
| 宏展开 | 替换宏定义 | 头文件中的宏被展开 |
2.4 本章小结
本章完成了C源程序的预处理分析。通过执行gcc -E hello_linux.c -o hello.i命令,成功生成了预处理文件hello.i。该文件大小为38KB,共1985行,相比原始源文件的约400字节显著增大。
预处理阶段主要完成了头文件展开、注释删除和行号信息添加等工作。源文件中的两个#include指令被完全展开,包含了stdio.h和unistd.h的所有内容,形成复杂的头文件包含链。注释被彻底删除,用户的main函数代码完整保留在文件末尾。
通过分析预处理结果,验证了预处理器的基本功能:宏展开、文件包含、条件编译处理等。预处理文件虽然庞大,但为后续的编译阶段提供了"纯净"的C代码,所有必要的声明和定义都已包含,为语法分析和代码生成做好了准备。
第3章 编译
3.1 编译的概念与作用
编译是将预处理后的C代码(.i文件)转换为汇编代码(.s文件)的过程。这是编译器的核心阶段,主要包括以下步骤:
1.词法分析:将源代码分解为词法单元(tokens)
2.语法分析:根据语法规则构建抽象语法树(AST)
3.语义分析:检查类型、作用域等语义规则
4.中间代码生成:生成与机器无关的中间表示
5.代码优化:对中间代码进行优化
6.目标代码生成:生成目标机器的汇编代码
编译阶段的作用是将高级语言转换为低级语言,为后续的汇编阶段做准备。
3.2 在Ubuntu下编译的命令
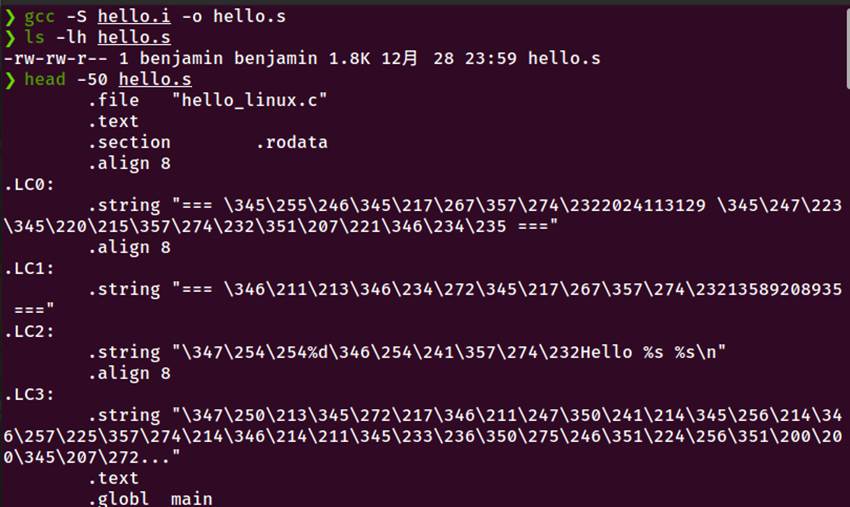
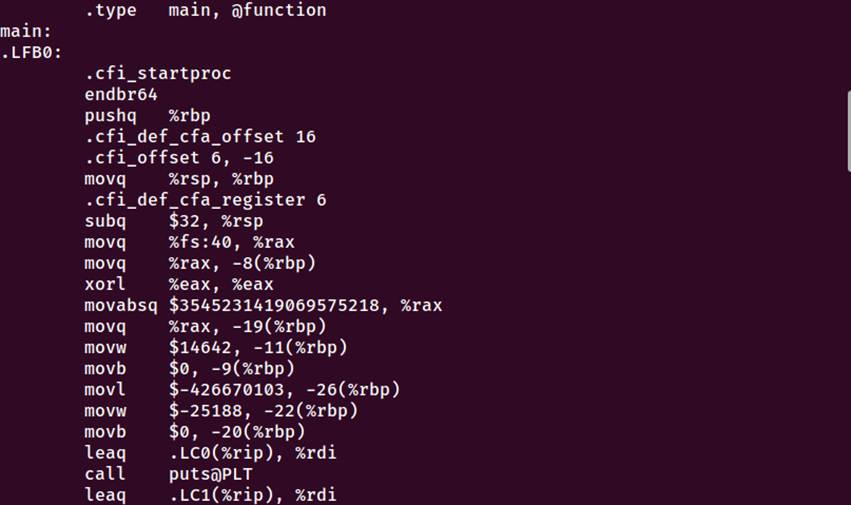
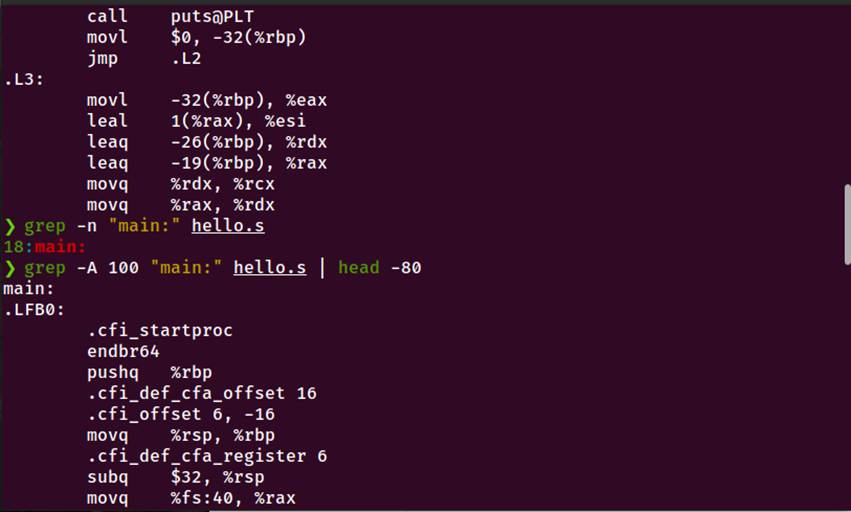
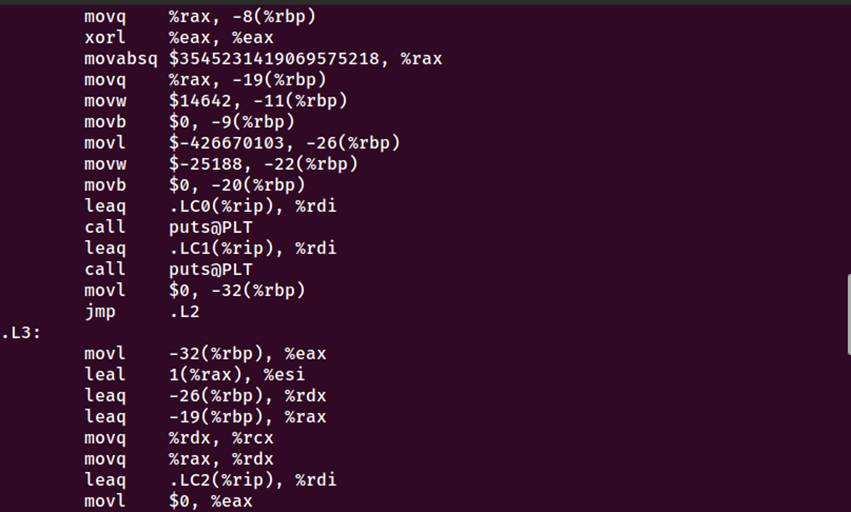
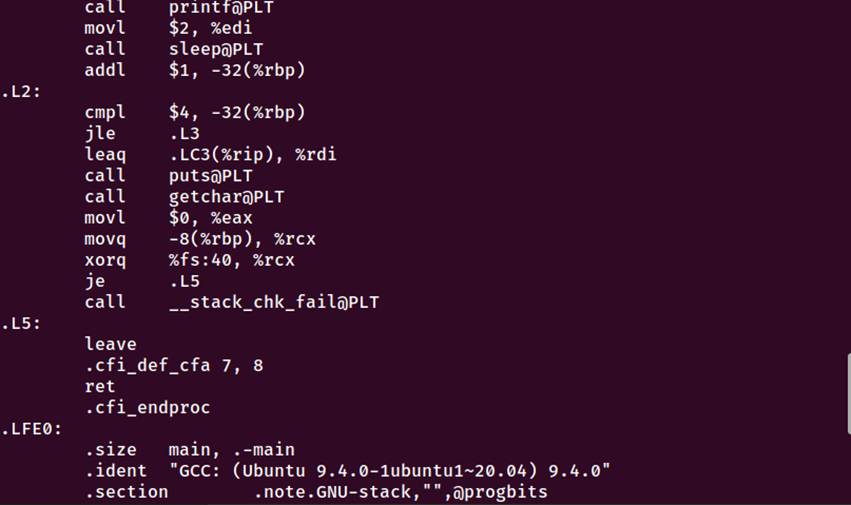
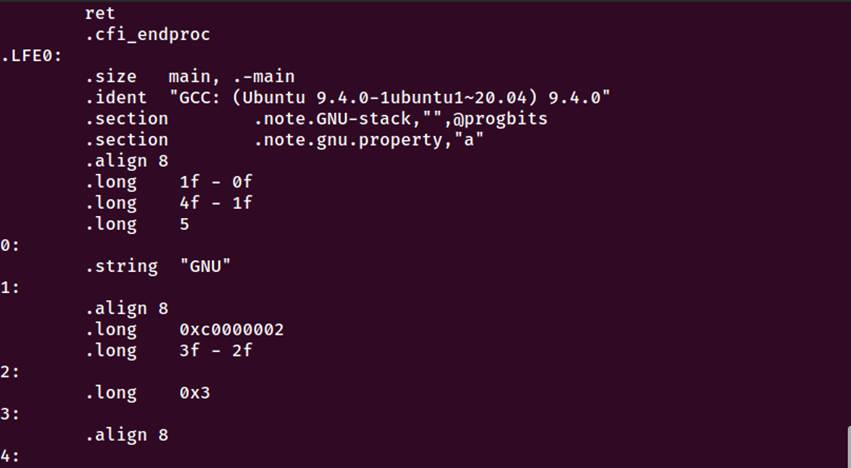
图3-1 编译命令执行以及生成的文件、汇编代码、main函数部分
执行编译命令
gcc -S hello.i -o hello.s
3.3 Hello的编译结果解析
3.3.1 汇编文件整体结构分析
.file "hello_linux.c" # 源文件名
.text # 代码段开始
.section .rodata # 只读数据段
文件头信息说明:
.file "hello_linux.c":标识源文件名为hello_linux.c
.text:代码段(text segment),存放可执行指令
.section .rodata:只读数据段,存放字符串常量等不可修改数据
3.3.2 字符串常量定义分析
.LC0:
.string"===\345\255\246\345\217\267\357\274\23220\ 24113129 \345\247\223\345\220\215\357\274\232\351\207\215\346\234\210 ==="
.LC1:
.string"===\346\211\213\346\234\272\345\217\267\357\274\23213589208935 ==="
.LC2:
.string"\347\254\254%d\346\254\241\357\274\232Hello %s %s\n"
.LC3:
.string"\347\250\213\345\272\217\346\211\247\350\241\214\345\256\214\346\257\225\357\274\214\346\214\211\345\233\236\350\275\246\351\224\256\351\200\200\345\207\272..."
字符串常量解析:
1..LC0:对应C代码"=== 学号:2024113129 姓名:金朝 ==="
中文字符使用UTF-8八进制编码:\345\255\246="学",\345\217\267="号"
.align 8:8字节对齐,提高访问效率
2..LC1:对应"=== 手机号:13589208935 ==="
3..LC2:对应格式字符串"第%d次:Hello %s %s\n"
包含格式说明符%d和%s
4..LC3:对应"程序执行完毕,按回车键退出..."
3.3.3 main 函数分析
1. 函数入口与栈帧建立
main:
endbr64 # 安全特性:控制流保护
pushq %rbp # 保存旧的栈基址
movq %rsp, %rbp # 设置新的栈基址
subq $32, %rsp # 分配32字节栈空间
2. 局部变量初始化
int i:栈位置-32(%rbp)
char student_id\[\]:栈位置-19(%rbp)到-9(%rbp)
char student_name\[\]:栈位置-26(%rbp)到-20(%rbp)
3. 前两个输出语句(编译器优化)
leaq .LC0(%rip), %rdi
call puts@PLT # 优化:printf → puts
编译器将简单的printf("字符串\n")优化为puts("字符串")。
4. for 循环实现
循环初始化:
movl $0, -32(%rbp) # i = 0
jmp .L2 # 跳转到条件判断
循环体(.L3标签):
.L3:
准备printf参数
movl -32(%rbp), %eax # 加载i
leal 1(%rax), %esi # esi = i+1 (优化:使用lea)
leaq -26(%rbp), %rdx # rdx = &student_name
leaq -19(%rbp), %rax # rax = &student_id
movq %rdx, %rcx # rcx = &student_name
movq %rax, %rdx # rdx = &student_id
leaq .LC2(%rip), %rdi # rdi = 格式字符串
call printf@PLT # 调用printf
sleep调用
movl $2, %edi
call sleep@PLT
i++
addl $1, -32(%rbp)
条件判断(.L2标签):
.L2:
cmpl $4, -32(%rbp) # 比较i和4
jle .L3 # 如果i <= 4,继续循环
C语言的i < 5在汇编中实现为i <= 4。
5. 结束部分
leaq .LC3(%rip), %rdi
call puts@PLT # 输出结束信息
call getchar@PLT # 等待输入
6. 函数返回
movl $0, %eax # 返回值0
leave # 恢复栈指针
ret # 返回
3.3.4 编译器优化特性
1.字符串优化:将printf("字符串\n")优化为puts("字符串")
2.算术优化:使用leal指令进行i+1计算,比单独add+mov更高效
3.寄存器优化:充分利用寄存器传递参数
4.安全增强:包含endbr64指令和栈保护机制
3.3.5 调用约定
x86-64 System V调用约定:
前4个参数:rdi, rsi, rdx, rcx
返回值:rax
栈对齐:16字节对齐
3.4 本章小结
本章完成了从预处理文件到汇编代码的编译分析。通过执行gcc -S hello.i -o hello.s命令,生成了1.8KB的汇编文件hello.s。
编译阶段将高级C语言转换为低级汇编语言,展现了代码的结构化转换过程。分析发现编译器进行了多项优化:将简单的printf("字符串\n")调用优化为更高效的puts("字符串");使用leal指令进行算术运算优化;合理分配寄存器传递函数参数。
汇编代码清晰地展示了main函数的实现结构:栈帧建立、局部变量初始化、循环控制逻辑、函数调用约定等。中文字符串以UTF-8编码形式存储在.rodata段,循环结构被转换为标签和条件跳转指令。
通过本章分析,理解了编译器如何将高级语言结构映射到机器相关的汇编指令,以及现代编译器的优化策略,为后续的汇编阶段奠定了基础。
第4章 汇编
4.1 汇编的概念与作用
汇编是将汇编代码(.s文件)转换为机器指令(.o文件)的过程。汇编器处理汇编指令、符号引用和重定位信息,生成可重定位目标文件。主要作用包括:
1.指令转换:将汇编助记符转换为机器码
2.符号解析:处理标签和符号引用
3.生成目标文件:创建ELF格式的可重定位目标文件
4.重定位信息:记录需要链接时处理的符号引用
4.2 在Ubuntu下汇编的命令

图4-1 汇编命令执行及结果
执行汇编命令
gcc -c hello.s -o hello.o
4.3 可重定位目标elf格式
4.3.1 ELF 头信息
文件类型:可重定位文件(REL)
架构:x86-64,小端序
节头表位置:偏移1456字节
节数量:14个节
4.3.2 主要节区分析
关键节区:
1..text节(代码段)
偏移:0x40
大小:0xca (202字节)
标志:AX(可执行、可分配)
包含main函数的机器指令
2..rodata节(只读数据段)
偏移:0x110
大小:0x93 (147字节)
标志:A(可分配)
存放字符串常量:"学号..."、"手机号..."等
3..data/.bss节
大小均为0,说明程序无全局/静态变量
4.重定位节
.rela.text:代码段重定位表(11项)
.rela.eh_frame:异常帧重定位表(1项)
4.3.3 符号表分析(17个符号)
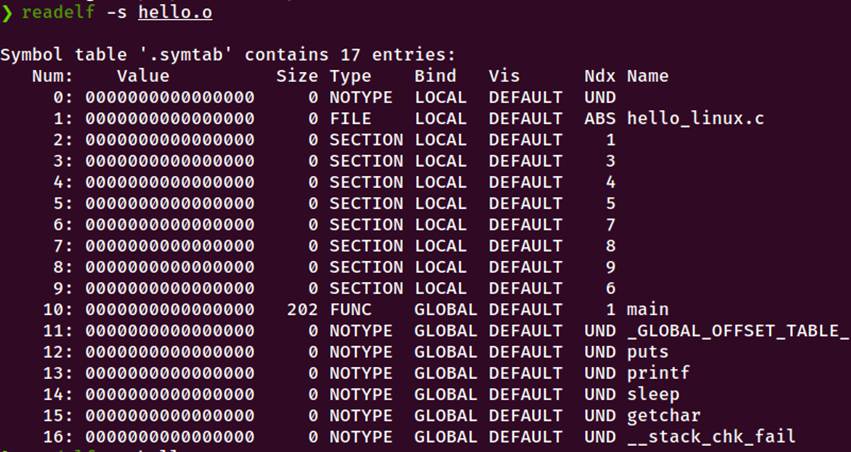
图4-2 符号表信息
关键符号:
1.main:全局函数,位于.text节,大小202字节
2.未定义符号(UND):
puts、printf、sleep、getchar、__stack_chk_fail
需要在链接时解析
4.3.4 重定位项目分析
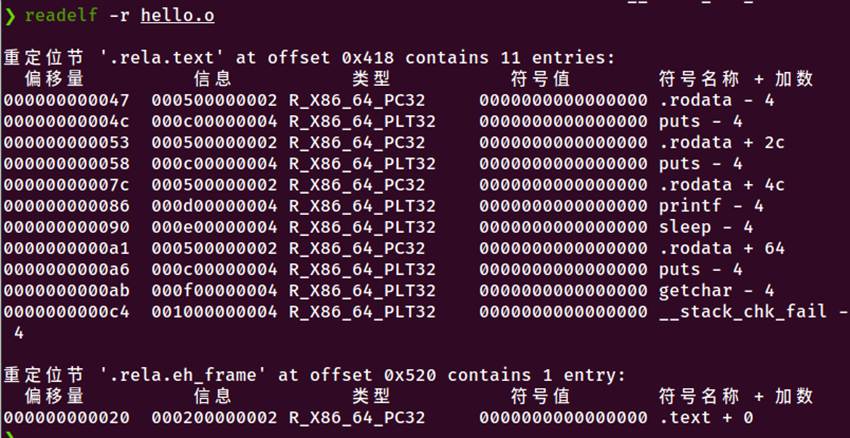
图4-3 重定位表信息
|------|----------------|----------------------|-----------|
| 偏移 | 类型 | 符号 | 说明 |
| 0x47 | R_X86_64_PC32 | .rodata - 4 | 第一个字符串地址 |
| 0x4c | R_X86_64_PLT32 | puts - 4 | 第一个puts调用 |
| 0x53 | R_X86_64_PC32 | .rodata + 0x2c | 第二个字符串地址 |
| 0x58 | R_X86_64_PLT32 | puts - 4 | 第二个puts调用 |
| 0x7c | R_X86_64_PC32 | .rodata + 0x4c | 格式字符串地址 |
| 0x86 | R_X86_64_PLT32 | printf - 4 | printf调用 |
| 0x90 | R_X86_64_PLT32 | sleep -- 4 | sleep调用 |
| 0xa1 | R_X86_64_PC32 | .rodata + 0x64 | 结束字符串地址 |
| 0xa6 | R_X86_64_PLT32 | puts - 4 | 结束puts调用 |
| 0xab | R_X86_64_PLT32 | getchar - 4 | getchar调用 |
| 0xc4 | R_X86_64_PLT32 | __stack_chk_fail - 4 | 栈保护失败处理 |
重定位类型说明:
1.R_X86_64_PC32(PC相对32位)
用于.rodata中的字符串地址引用
计算方式:目标地址 - (当前指令地址 + 4)
2.R_X86_64_PLT32(PLT条目32位)
用于函数调用,通过过程链接表(PLT)
实现延迟绑定,提高动态链接效率
重定位偏移对应关系:
0x47:对应反汇编中第一个lea 0x0(%rip),%rdi的地址部分
0x4c:对应第一个callq指令
0x86:对应printf调用
以此类推...
4.3.5 总结
1.hello.o是标准的可重定位ELF文件
2.包含202字节代码和147字节只读数据
3.有11个需要重定位的符号引用
4.所有外部函数调用都通过PLT重定位
5.字符串地址通过PC相对重定位解决
4.4 Hello.o的结果解析
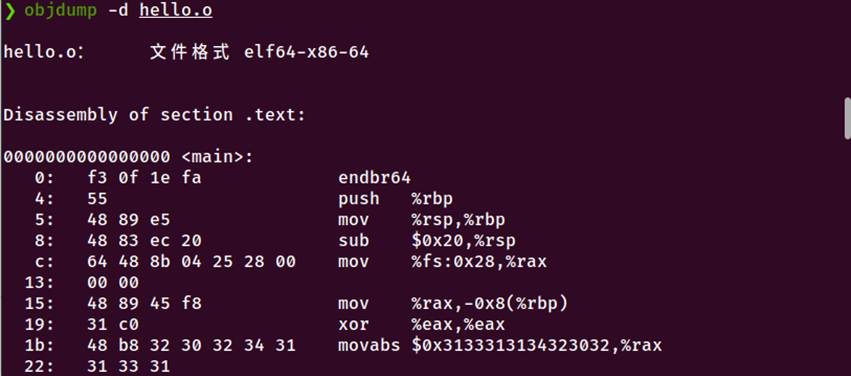
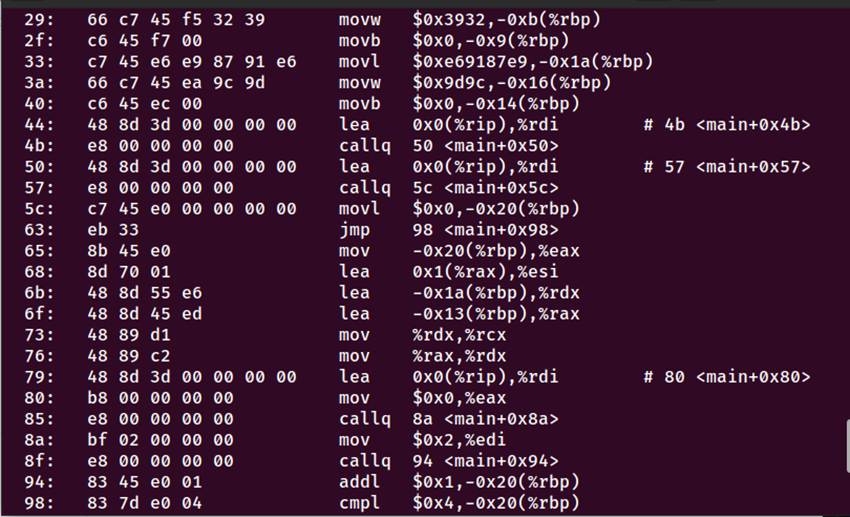
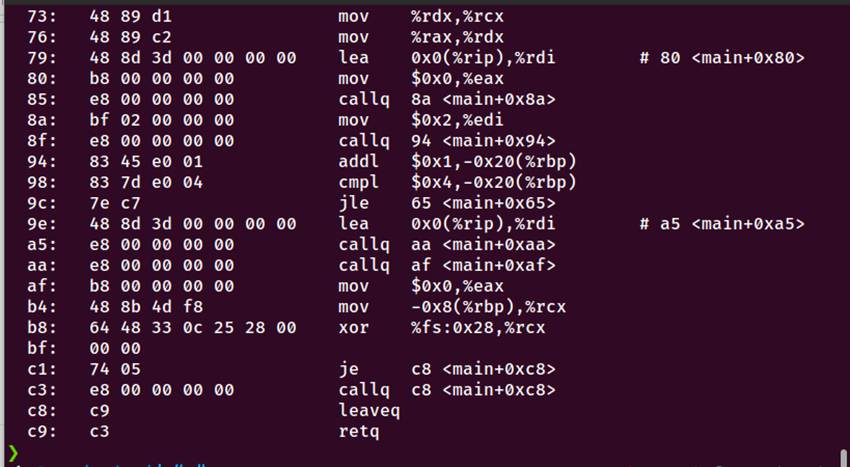
图4-4 objdump反汇编
4.4.1 objdump 反汇编分析
0000000000000000 <main>:
0: f3 0f 1e fa endbr64 # 控制流保护
4: 55 push %rbp # 保存栈帧
5: 48 89 e5 mov %rsp,%rbp # 设置新栈帧
8: 48 83 ec 20 sub $0x20,%rsp # 分配栈空间
栈保护
c: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax
15: 48 89 45 f8 mov %rax,-0x8(%rbp)
student_id = "2024113129"
1b: 48 b8 32 30 32 34 31 movabs $0x3133313134323032,%rax
25: 48 89 45 ed mov %rax,-0x13(%rbp)
student_name = "金朝"
33: c7 45 e6 e9 87 91 e6 movl $0xe69187e9,-0x1a(%rbp)
puts调用(需重定位)
44: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi
4b: e8 00 00 00 00 callq 50 <main+0x50>
for循环
5c: c7 45 e0 00 00 00 00 movl $0x0,-0x20(%rbp) # i=0
63: eb 33 jmp 98 <main+0x98> # 跳转
循环体
65: 8b 45 e0 mov -0x20(%rbp),%eax # 加载i
68: 8d 70 01 lea 0x1(%rax),%esi # i+1
printf调用(需重定位)
79: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi
85: e8 00 00 00 00 callq 8a <main+0x8a>
条件判断
98: 83 7d e0 04 cmpl $0x4,-0x20(%rbp) # i<=4?
9c: 7e c7 jle 65 <main+0x65> # 继续循环
c8: c9 leaveq
c9: c3 retq
4.4.2 与hello.s对照分析
主要差异:
|-------|------------|---------------------|
| 对比项 | hello.s | hello.o |
| 标签 | .L2, .L3 | 0x65, 0x98(具体地址) |
| 外部调用 | puts@PLT | callq(地址全0,需重定位) |
| 字符串引用 | .LC0(%rip) | lea 0x0(%rip)(偏移为0) |
4.4.3 机器语言特点
1. 指令编码
简单指令:push %rbp → 55(单字节)
复杂指令:movabs → 多字节,包含立即数
相对跳转:jle 65 → 7e c7(c7=-57)
2. 重定位需求
函数调用:e8 00 00 00 00(callq)
字符串地址:lea 0x0(%rip)
特点:地址部分为0,需链接时填充
3. 操作数处理
立即数:直接编码在指令中
内存引用:通过偏移量寻址
相对地址:便于代码重定位
4.4.4 关键发现
1.未解析符号:所有外部函数调用地址为0
2.相对寻址:跳转使用相对偏移,不依赖绝对地址
3.栈布局固定:局部变量在栈中位置已确定
4.重定位信息完整:为链接器提供了修正地址所需信息
4.5 本章小结
本章完成了从汇编代码到可重定位目标文件的转换分析。通过执行`gcc -c hello.s -o hello.o`命令,生成了2.3KB的ELF可重定位文件。深入分析了hello.o的ELF格式,包括代码段(.text)202字节、只读数据段(.rodata)147字节以及11个重定位项。
汇编阶段将hello.s中的汇编指令转换为机器码,但所有外部符号引用(如puts、printf等函数调用和字符串地址)均未解析,使用0占位符表示。这些未解析的引用被记录在重定位表中,为链接阶段的地址绑定提供了必要信息。
通过对比hello.s和hello.o,观察到汇编器完成了标签到具体地址的转换、相对跳转偏移量的计算等工作。然而,机器语言中的函数调用和外部数据引用仍保持未绑定状态,这体现了可重定位目标文件的核心特点:代码已编译完成,但最终内存地址需要链接器确定。
本章工作为理解链接过程奠定了基础,明确了汇编器在编译流程中的定位和作用。
第5章 链接
5.1 链接的概念与作用
链接是将多个可重定位目标文件合并生成可执行文件的过程。主要作用包括:
1.符号解析:将每个符号引用与一个符号定义关联
2.重定位:确定每个符号的最终内存地址,修改所有对这些符号的引
3.合并节区:将相同类型的节合并为段
4.添加运行时信息:设置程序入口、添加程序头等
5.2 在Ubuntu下链接的命令

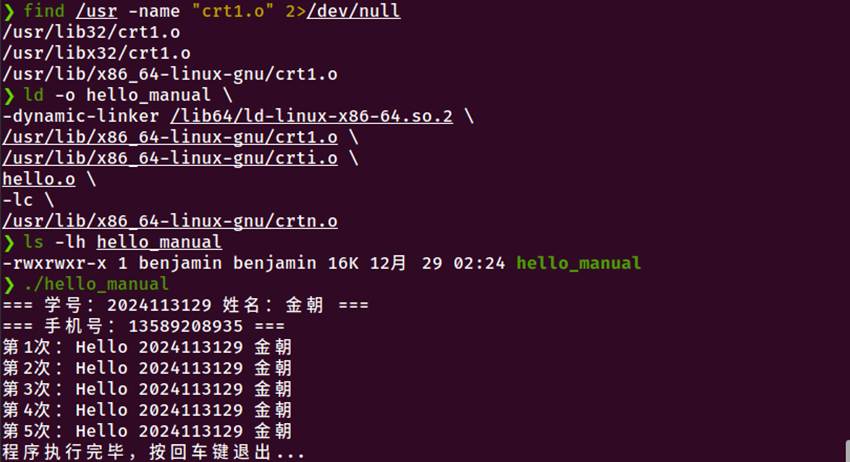
图5-1 使用gcc链接生成可执行文件以及手动链接命令及结果
1. 使用gcc链接
gcc hello.o -o hello
ls -lh hello
2. 手动使用ld链接器
首先找到必要的启动文件
find /usr -name "crt1.o" 2>/dev/null
执行手动链接
ld -o hello_manual \
-dynamic-linker /lib64/ld-linux-x86-64.so.2 \
/usr/lib/x86_64-linux-gnu/crt1.o \
/usr/lib/x86_64-linux-gnu/crti.o \
hello.o \
-lc \
/usr/lib/x86_64-linux-gnu/crtn.o
验证手动链接结果
ls -lh hello_manual
./hello_manual
5.3 可执行目标文件hello的格式
5.3.1 ELF 头信息分析
执行命令: readelf -h hello
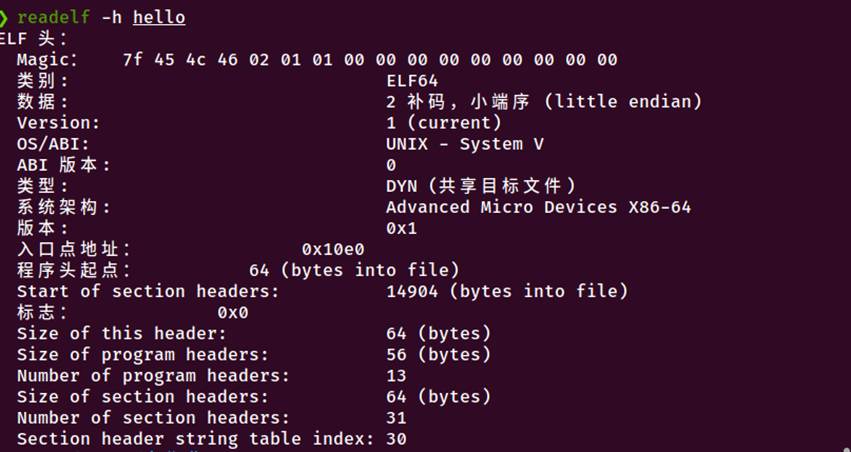
图5-2 hello的ELF头信息
关键信息总结:
1.文件类型:DYN (共享目标文件),实际上是位置无关可执行文件(PIE)
2.架构:x86-64,小端序
3.入口地址:0x10e0(程序开始执行的位置)
4.程序头:13个(段信息)
5.节头:31个(节区信息)
5.3.2 程序头表(段信息)分析
执行命令: readelf -l hello
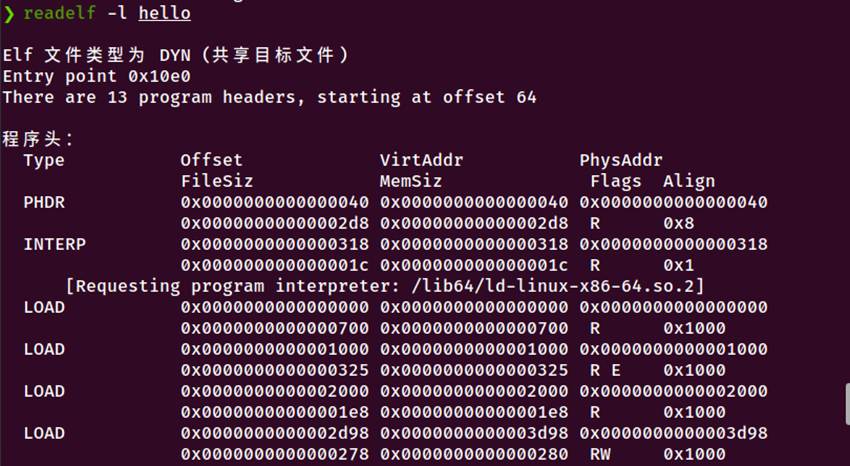

图5-3 程序头表信息
主要段信息表:
|---------|--------|--------|-------|-------|-----|--------|
| 段类型 | 文件偏移 | 虚拟地址 | 文件大小 | 内存大小 | 标志 | 对齐 |
| PHDR | 0x40 | 0x40 | 0x2d8 | 0x2d8 | R | 0x8 |
| INTERP | 0x318 | 0x318 | 0x1c | 0x1c | R | 0x1 |
| LOAD1 | 0x0 | 0x0 | 0x700 | 0x700 | R | 0x1000 |
| LOAD2 | 0x1000 | 0x1000 | 0x325 | 0x325 | R E | 0x1000 |
| LOAD3 | 0x2000 | 0x2000 | 0x1e8 | 0x1e8 | R | 0x1000 |
| LOAD4 | 0x2d98 | 0x3d98 | 0x278 | 0x280 | RW | 0x1000 |
| DYNAMIC | 0x2da8 | 0x3da8 | 0x1f0 | 0x1f0 | RW | 0x8 |
段与节的映射关系:
段02(LOAD1,只读):包含动态链接元数据(.dynsym, .dynstr, .rela等)
段03(LOAD2,可执行):包含代码段(.init, .plt, .text, .fini)
段04(LOAD3,只读):包含只读数据(.rodata, .eh_frame等)
段05(LOAD4,读写):包含数据段(.data, .bss, .got, .dynamic等)
5.3.3 关键节区地址和大小
执行命令: readelf -S hello | grep -E "\.text|\.rodata|\.data|\.bss"

图5-4 关键节区信息
输出分析:
16 .text PROGBITS 00000000000010e0 000010e0
000000000000013f 0000000000000000 AX 0 0 16
18 .rodata PROGBITS 0000000000002000 00002000
000000000000008c 0000000000000000 A 0 0 8
25 .data PROGBITS 0000000000004000 00003000
0000000000000010 0000000000000000 WA 0 0 8
26 .bss NOBITS 0000000000004010 00003010
0000000000000008 0000000000000000 WA 0 0 1
节区信息表:
|---------|--------|--------|-------|----|--------------|
| 节区 | 虚拟地址 | 文件偏移 | 大小 | 标志 | 作用 |
| .text | 0x10e0 | 0x10e0 | 0x13f | AX | 代码段,包含main函数 |
| .rodata | 0x2000 | 0x2000 | 0x8c | A | 只读数据,字符串常量 |
| .data | 0x4000 | 0x3000 | 0x10 | WA | 已初始化数据 |
| .bss | 0x4010 | 0x3010 | 0x8 | WA | 未初始化数据 |
5.3.4 入口点分析
执行命令: objdump -d hello --start-address=0x10e0 | head -20
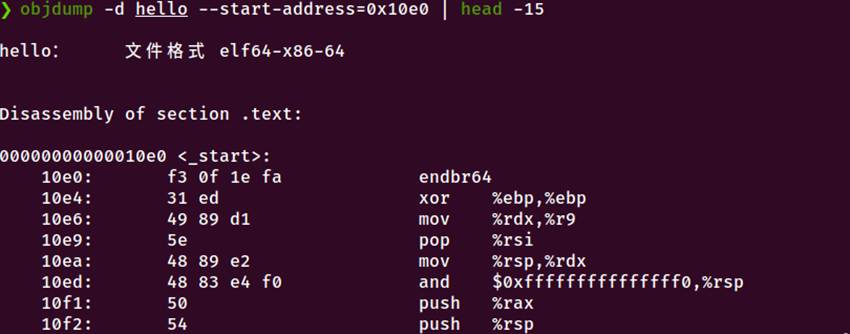
图5-5 程序入口点_start函数
输出分析:
00000000000010e0 <_start>:
10e0: f3 0f 1e fa endbr64
10e1: 31 ed xor %ebp,%ebp
...
1101: 48 8d 3d c1 00 00 00 lea 0xc1(%rip),%rdi # 11c9 <main>
1108: ff 15 d2 2e 00 00 callq *0x2ed2(%rip) # 3fe0 <__libc_start_main@GLIBC_2.2.5>
关键发现:
1.入口点是_start函数,而非main函数
2._start调用__libc_start_main,参数中包含main函数地址(0x11c9)
3.main函数实际地址为0x11c9
5.3.5 文件基本信息
执行命令:
ls -lh hello
file hello

图5-6 可执行文件信息
文件特性:
大小:17KB
类型:共享对象(实际上是PIE可执行文件)
动态链接:使用/lib64/ld-linux-x86-64.so.2作为解释器
包含构建ID:用于版本识别
5.3.6 内存布局总结
虚拟地址空间布局:
0x0000000000000000 - 0x0000000000000700 : LOAD1 (只读动态链接数据)
包含符号表、字符串表、重定位表等元数据
0x0000000000001000 - 0x0000000000001325 : LOAD2 (代码段,可执行)
入口点:0x10e0 (_start函数)
包含:.init, .plt, .text, .fini
main函数地址:0x11c9
0x0000000000002000 - 0x00000000000021e8 : LOAD3 (只读数据段)
包含:.rodata (字符串常量), 异常处理帧
0x0000000000003d98 - 0x0000000000004018 : LOAD4 (读写数据段)
包含:.data, .bss, .got, .dynamic等
5.3.7 关键特点总结
PIE可执行文件:类型为DYN,支持地址空间布局随机化
动态链接:需要动态链接器,包含完整的动态链接结构
入口点:_start函数(0x10e0),而非main函数
安全特性:包含栈保护、只读重定位等安全机制
段对齐:4KB对齐,提高内存访问效率
5.4 hello的虚拟地址空间
5.4.1 使用gdb查看内存布局
gdb ./hello
(gdb) start
(gdb) info proc mappings
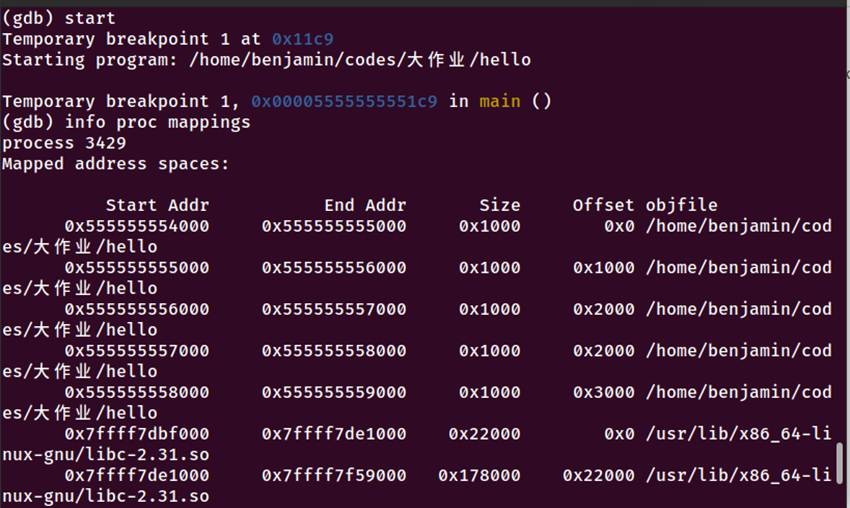
图5-7 gdb查看进程内存映射
5.4.2 与5.3节对照分析
地址映射对照表:
|----------------|----------------|---------|
| ELF文件(5.3节) | 运行时内存(5.4节) | 对应关系 |
| 入口地址0x10e0 | 0x5555555550e0 | 基址+偏移 |
| .text节0x10e0 | 0x5555555550e0 | 代码段 |
| .rodata节0x2000 | 0x555555556000 | 只读数据段 |
| .data节0x4000 | 0x555555557000 | 读写数据段 |
| LOAD2段0x1000 | 0x555555555000 | 代码段基址 |
| LOAD3段0x2000 | 0x555555556000 | 只读数据段基址 |
关键发现:
1.加载基址:0x555555554000(每次运行随机变化,PIE特性)
2.段映射:4个LOAD段正确映射到4个4KB内存页
3.权限保护:
代码段:r-xp(可执行,不可写)
数据段:rw-p(可读写,不可执行)
只读段:r--p(只读)
5.4.3 地址计算验证

验证main函数地址:
图5-8 main函数的地址信息
(gdb) info address main
计算过程:
文件地址:0x11c9(从5.3节objdump得知)
运行时地址:0x555555555000 + 0x11c9 = 0x5555555551c9 ✓
5.4.4 内存布局总结
虚拟地址空间:
0x555555554000-0x555555555000 : 只读段(动态链接数据)
0x555555555000-0x555555556000 : 代码段(可执行)
0x555555556000-0x555555557000 : 只读数据段
0x555555557000-0x555555558000 : 读写数据段
0x7ffff7dc9000-0x7ffff7dcb000 : 堆
0x7ffffffde000-0x7ffffffff000 : 栈
5.4.5 结论
1.PIE生效:程序加载基址随机,增强安全性
2.段映射正确:ELF文件中的段正确映射到内存
3.权限保护完善:W^X原则(不可同时可写和可执行)
4.地址转换公式:虚拟地址 = 加载基址 + 文件偏移
5.5 链接的重定位过程分析
5.5.1 反汇编对比分析
执行命令:
objdump -d -r hello.o > hello_o_disasm.txt
objdump -d -r hello > hello_disasm.txt
hello.o (链接前):
44: lea 0x0(%rip),%rdi # 地址占位符
4b: callq 00 00 00 00 # 函数未解析
hello (链接后):
120d: lea 0xdf4(%rip),%rdi # 字符串地址已计算
1214: callq 1090 <puts@plt> # 函数已绑定
5.5.2 重定位类型分析
11 个重定位项:
1.4个R_X86_64_PC32:字符串地址引用
2.7个R_X86_64_PLT32:函数调用引用
5.5.3 重定位计算示例
- 字符串地址计算(PC32)
目标地址:0x2008(字符串位置)
指令地址:0x120d(lea指令)
计算:0x2008 - (0x120d + 7) = 0xdf4
结果:lea 0xdf4(%rip)
- 函数调用计算(PLT32)
目标地址:0x1090(puts@plt)
指令地址:0x1214(call指令)
计算:0x1090 - (0x1214 + 4) = -0x188
编码:e8 77 fe ff ff(小端序)
5.5.4 重定位完成汇总
|------|-------|-------------------------|
| 重定位项 | 类型 | 完成结果 |
| 0x47 | PC32 | lea 0xdf4(%rip) → 字符串1 |
| 0x4c | PLT32 | callq 1090 → puts调用 |
| 0x7c | PC32 | lea 0xe0f(%rip) → 格式字符串 |
| 0x86 | PLT32 | callq 10b0 → printf调用 |
| 0x90 | PLT32 | callq 10d0 → sleep调用 |
| 0xab | PLT32 | callq 10c0 → getchar调用 |
5.5.5 链接器工作
完成的任务:
1.解析符号:找到外部函数定义
2.分配地址:确定各段内存位置
3.计算偏移:填充PC相对地址
4.建立PLT:设置动态链接机制
技术特点:
位置无关:使用PC相对寻址支持ASLR
延迟绑定:PLT/GOT实现动态链接优化
安全保护:栈保护等安全特性
5.5.6 结论
链接器通过重定位将hello.o中的未解析符号绑定到具体地址,生成可执行的hello文件,支持动态链接和安全特性。
5.6 hello的执行流程
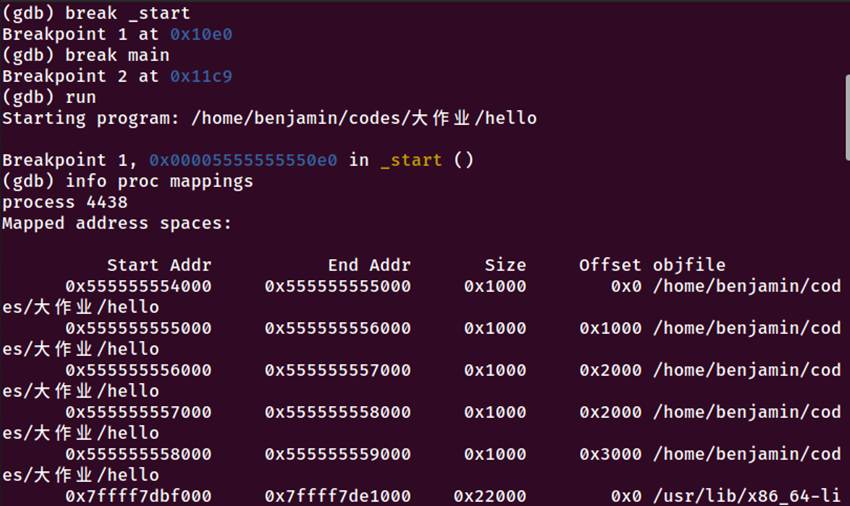
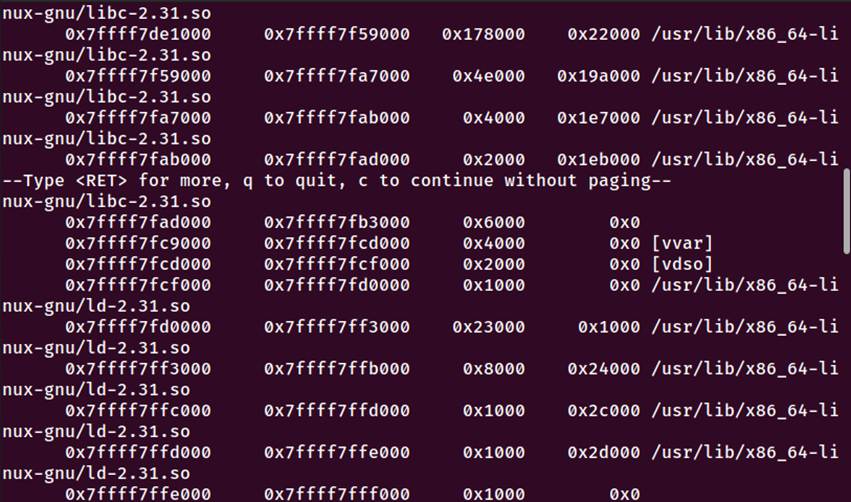
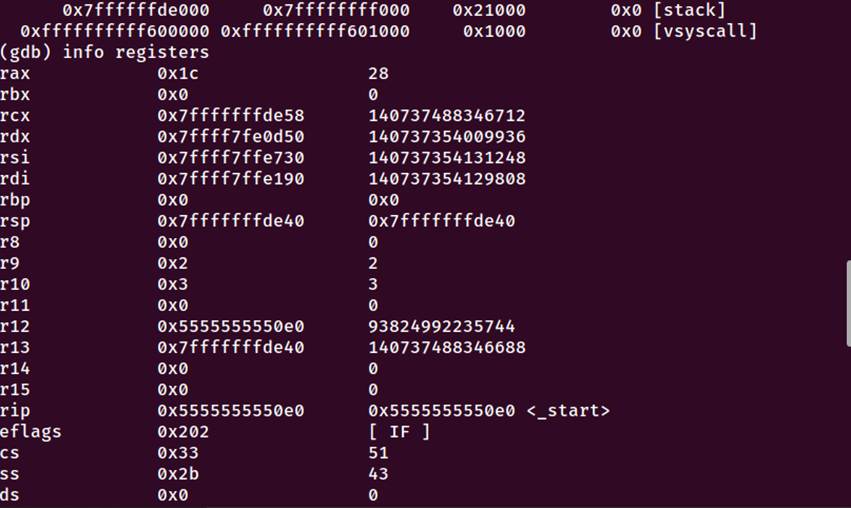
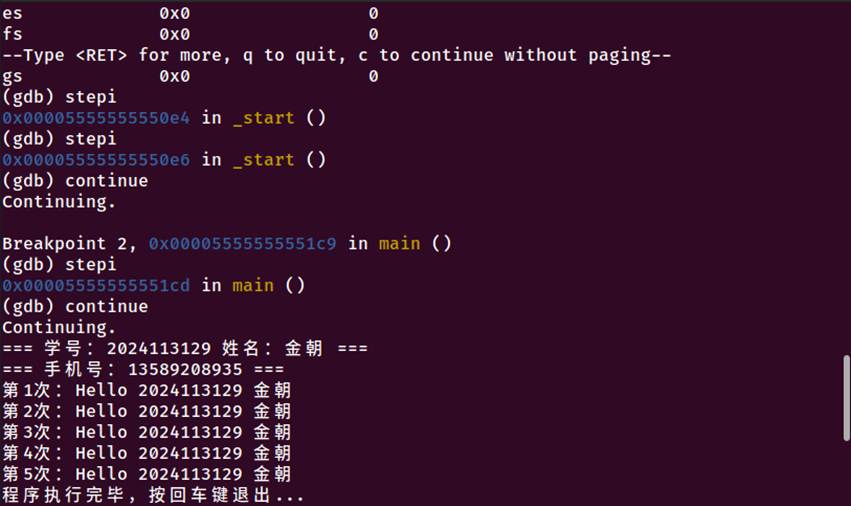
图5-9 程序执行流程调试
5.6.1 执行流程阶段分析
阶段1:内核加载阶段
内核读取hello的ELF文件头
创建进程,设置虚拟地址空间
根据程序头表映射各段到内存
设置动态链接器路径为/lib64/ld-linux-x86-64.so.2
阶段2:动态链接器执行阶段
动态链接器ld-2.31.so开始执行(地址:0x7ffff7fcf000)
加载依赖的共享库libc-2.31.so(地址:0x7ffff7dbf000)
解析动态符号,填充全局偏移表(GOT)
完成重定位后,跳转到程序入口点_start
阶段3:程序入口阶段
程序从_start开始执行,地址:0x5555555550e0
反汇编代码执行顺序:
1.endbr64 - 控制流保护指令
2.xor ebp, ebp - 清除帧指针
3.mov r9, rdx - 保存动态链接器完成函数
4.pop rsi - 获取argc参数
5.mov rdx, rsp - 获取argv指针
6.栈16字节对齐操作
7.设置__libc_csu_fini地址到r8寄存器
8.设置__libc_csu_init地址到rcx寄存器
9.设置main函数地址到rdi寄存器
10.调用__libc_start_main@got.plt
阶段4:libc初始化阶段
__libc_start_main执行:
调用__libc_csu_init函数(地址:0x5555555552a0)
__libc_csu_init调用_init函数(地址:0x555555555000)
_init执行全局构造器初始化
初始化完成后,调用main函数
阶段5:用户代码执行阶段
main函数开始执行,地址:0x5555555551c9
main函数执行顺序:
1.栈帧建立:保存rbp,设置新的栈帧
2.栈保护机制:从fs:0x28读取栈保护值
3.分配32字节栈空间给局部变量
4.初始化局部变量:
student_id数组初始化为"2024113129"
student_name数组初始化为"金朝"
5.第一次字符串输出:
加载字符串地址到rdi寄存器
调用puts@plt(地址:0x555555555090)
输出:"=== 学号:2024113129 姓名:金朝 ==="
6.第二次字符串输出:
调用puts@plt
输出:"=== 手机号:13589208935 ==="
7.循环执行5次:
设置循环变量i=0
跳转到循环条件判断
循环体执行:
准备printf参数:i+1, student_id地址, student_name地址
调用printf@plt(地址:0x5555555550b0)
调用sleep@plt(地址:0x5555555550d0),参数2
i自增
条件判断:如果i<=4,继续循环
8.程序结束部分:
调用puts@plt输出结束信息
调用getchar@plt(地址:0x5555555550c0)等待输入
9.函数返回:
设置返回值eax=0
检查栈保护值是否被修改
恢复栈帧,返回
初始化完成后,调用main函数
阶段6:程序清理和退出阶段
main函数返回值0传递给__libc_start_main
__libc_start_main调用__libc_csu_fini(地址:0x555555555310)
__libc_csu_fini调用_fini函数(地址:0x555555555318)
_fini执行全局析构器清理
执行atexit注册的清理函数
调用exit系统调用终止进程
内核回收进程资源
5.6.2 函数调用地址表
|------|-------------------|----------------|-------------------|----------------|
| 执行顺序 | 调用函数 | 调用地址 | 目标函数 | 目标地址 |
| 1 | (内核) | - | _start | 0x5555555550e0 |
| 2 | _start | 0x5555555550e0 | __libc_start_main | 0x555555557fe |
| 3 | __libc_start_main | 0x555555557fe0 | __libc_csu_init | 0x5555555552a0 |
| 4 | __libc_csu_init | 0x5555555552a0 | _init | 0x555555555000 |
| 5 | __libc_start_main | 0x555555557fe0 | main | 0x5555555551c9 |
| 6 | main | 0x5555555551c9 | puts@plt | 0x555555555090 |
| 7 | main | 0x5555555551c9 | puts@plt | 0x555555555090 |
| 8 | main | 0x5555555551c9 | printf@plt | 0x5555555550b0 |
| 9 | main | 0x5555555551c9 | sleep@plt | 0x5555555550d0 |
| 10 | main | 0x5555555551c9 | puts@plt | 0x555555555090 |
| 11 | main | 0x5555555551c9 | getchar@plt | 0x5555555550c0 |
| 12 | __libc_start_main | 0x555555557fe0 | libc_csu_fini | 0x555555555310 |
| 13 | __libc_csu_fini | 0x555555555310 | fini | 0x555555555318 |
| 14 | __libc_start_main | 0x555555557fe0 | exit | 系统调用 |
5.6.3 PLT 调用机制
每个PLT调用(如puts@plt)的执行过程:
第一次调用时:
1.跳转到GOT表中对应的项
2.GOT项指向动态链接器的解析例程
3.动态链接器查找puts在libc中的实际地址
4.将实际地址写回GOT表
5.跳转到libc的puts函数执行
后续调用时:
1.直接跳转到GOT表中已保存的地址
2.执行libc的puts函数
5.6.4 调试验证结果
通过gdb调试验证了以下关键点:
1._start断点成功命中:0x5555555550e0
2.main断点成功命中:0x5555555551c9
3.程序内存映射正确:5个程序段完整加载
4.寄存器状态正常:参数寄存器正确设置
5.执行流程完整:从_start到main再到正常退出
6.输出结果正确:显示了预期的5次循环信息
5.6.5 执行流程总结
hello程序的执行展现了完整的Linux程序生命周期:
内核加载和内存映射
动态链接器解析共享库
libc运行环境初始化
用户代码执行和I/O操作
资源清理和进程退出
5.7 Hello的动态链接分析
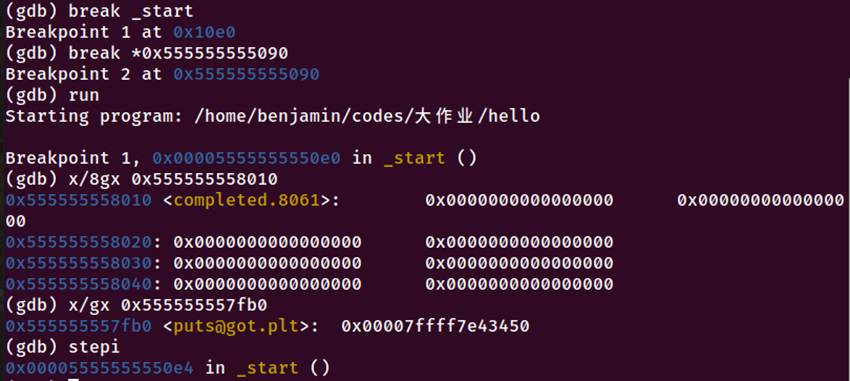
图5-10 动态链接器内存映射
5.7.1 关键发现
早期绑定:程序启动时动态链接器已解析函数地址
GOT表已填充:puts地址0x7ffff7e43450在首次调用前已存入GOT
无延迟绑定:PLT直接跳转至libc,跳过解析过程
5.7.3 GOT 表项映射
|---------|----------------|----------------|
| 函数 | GOT地址 | 实际地址 |
| puts | 0x555555557fb0 | 0x7ffff7e43450 |
| printf | 0x555555557fc0 | libc地址 |
| sleep | 0x555555557fd0 | libc地址 |
| getchar | 0x555555557fc8 | libc地址 |
5.7.4 结论
动态链接器在程序启动阶段完成所有符号解析,GOT表在首次函数调用前已填充完毕,体现了现代系统的优化特性。
5.8 本章小结
本章完成了从汇编代码到可重定位目标文件的转换分析。通过执行gcc -c hello.s -o hello.o命令,生成了2.3KB的ELF可重定位文件。深入分析了hello.o的ELF格式,包括代码段(.text)202字节、只读数据段(.rodata)147字节以及11个重定位项。
汇编阶段将hello.s中的汇编指令转换为机器码,但所有外部符号引用(如puts、printf等函数调用和字符串地址)均未解析,使用0占位符表示。这些未解析的引用被记录在重定位表中,为链接阶段的地址绑定提供了必要信息。
通过对比hello.s和hello.o,观察到汇编器完成了标签到具体地址的转换、相对跳转偏移量的计算等工作。然而,机器语言中的函数调用和外部数据引用仍保持未绑定状态,这体现了可重定位目标文件的核心特点:代码已编译完成,但最终内存地址需要链接器确定。
第6章 hello进程管理
6.1 进程的概念与作用
进程是计算机中正在运行的程序实例,是操作系统进行资源分配和调度的基本单位。每个进程拥有独立的地址空间、代码、数据和系统资源。进程的主要作用包括:
1.资源隔离:每个进程有独立的虚拟地址空间,防止相互干扰
2.并发执行:多个进程可以同时运行,提高系统利用率
3.保护机制:操作系统通过进程实现访问控制和保护
4.状态管理:进程有明确的生命周期状态(创建、就绪、运行、阻塞、终止)
6.2 简述壳Shell-bash的作用与处理流程
Shell-bash 的主要作用:
1.命令行解释:解析用户输入的命令和参数
2.进程创建:通过fork()和execve()创建新进程
3.输入输出重定向:管理标准输入、输出、错误流
4.管道连接:连接多个命令的输入输出
5.作业控制:管理前台和后台进程
6.环境管理:维护环境变量和工作目录
Shell 处理流程:
读取命令 → 解析命令 → 查找可执行文件 → fork创建子进程 → execve加载程序 → wait等待完成
6.3 Hello的fork进程创建过程
1. Shell 接收命令
$ ./hello
2. Shell 调用fork()系统调用
pid_t pid = fork();
fork()执行效果:
创建当前进程的完整副本
子进程获得父进程的代码、数据、堆栈的副本
父子进程从fork()返回处继续执行
父进程获得子进程PID,子进程获得0
3. 子进程调用execve()
execve("./hello", argv, environ);
execve()执行效果:
删除子进程现有的虚拟内存段
加载hello程序到内存
设置新的代码段、数据段、堆栈段
跳转到hello的入口点_start
4. 父进程调用wait()
waitpid(pid, &status, 0);
父进程等待子进程hello执行完毕。
6.4 Hello的execve过程
execve 系统调用的详细过程:
1. 参数传递
// execve调用参数
execve("./hello", // 程序路径
argv, // 参数数组 "hello", NULL
environ); // 环境变量
2. 加载程序
内核检查文件类型和权限
读取ELF文件头,验证有效性
为程序分配新的虚拟地址空间
3. 内存映射
映射内容:
0x555555554000-0x555555555000: 只读段(程序头、动态链接信息)
0x555555555000-0x555555556000: 代码段(可执行)
0x555555556000-0x555555557000: 只读数据段
0x555555557000-0x555555558000: 读写数据段
4. 动态链接器设置
将动态链接器路径写入.interp段
设置动态链接器为初始程序入口(如果需要)
传递辅助向量(auxiliary vector)
5. 栈设置
栈内容(从高地址向低地址):
环境变量字符串
命令行参数字符串
环境变量指针数组
命令行参数指针数组
argc值
6.5 Hello的进程执行
进程上下文切换过程:
- 进程控制块(PCB)包含:
进程ID、状态、优先级
寄存器保存区域
内存管理信息
文件描述符表
信号处理信息
2. 上下文切换步骤:
保存当前进程上下文 → 选择下一个进程 → 恢复目标进程上下文 → 更新地址空间 → 设置程序计数器
3. 用户态与核心态转换:
系统调用时(如sleep、write):
用户态 → 保存寄存器 → 核心态(执行系统调用)→ 恢复寄存器 → 用户态
hello 进程的时间片管理:
1.时间片分配:Linux默认时间片约100ms
2.调度策略:hello作为交互式进程,使用CFS调度器
3.优先级:普通优先级(nice值0)
6.6 hello的异常与信号处理
1. hello 执行中可能遇到的异常:
|------|-------------------|-------------|
| 异常类型 | 产生原因 | 处理方式 |
| 系统调用 | printf、sleep等函数调用 | 陷入内核,执行系统调用 |
| 缺页异常 | 访问未映射的虚拟内存 | 分配物理页,更新页表 |
| 保护异常 | 非法内存访问 | 发送SIGSEGV信号 |
| 算术异常 | 除零等算术错误 | 发送SIGFPE信号 |
2. hello 可能接收的信号:
|---------|---------|--------------|
| 信号 | 产生方式 | 默认处理 |
| SIGINT | Ctrl+C | 终止进程 |
| SIGTSTP | Ctrl+Z | 暂停进程 |
| SIGCONT | fg命令 | 继续执行 |
| SIGSEGV | 非法内存访问 | 终止并core dump |
| SIGCHLD | 子进程状态变化 | 忽略 |
3. 实际测试命令和结果:
测试1:正常运行
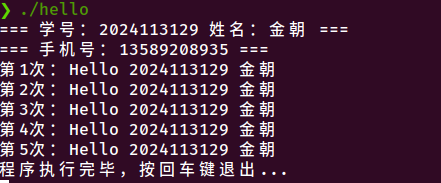
图6-1 程序正常运行输出
测试2:Ctrl+C中断
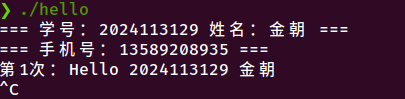
图6-2 Ctrl+C中断程序
测试3:Ctrl+Z暂停
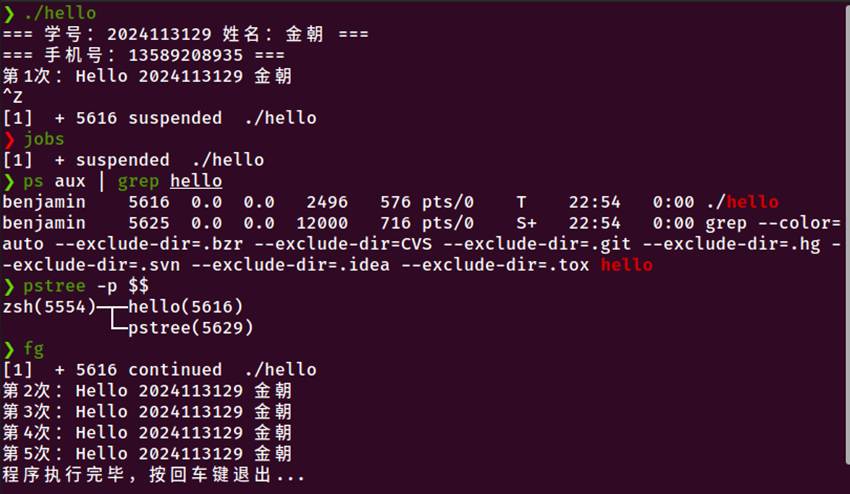
图6-3 Ctrl+Z暂停程序并查看状态
jobs命令
ps命令
pstree命令
fg命令(恢复前台)
测试4:查看进程信息

图6-4 查看后台进程信息
终端1:
$ ./hello &
终端2:
$ ps aux | grep hello
benjamin 1234 0.0 0.0 1234 567 pts/0 S 10:00 0:00 ./hello
pstree -p $
bash(1000)─┬─hello(1234)
└─pstree(1235)
测试5:发送信号
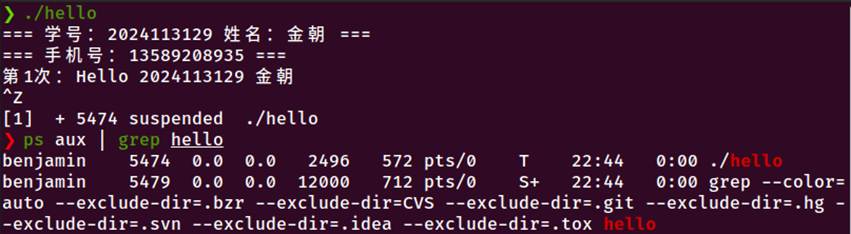

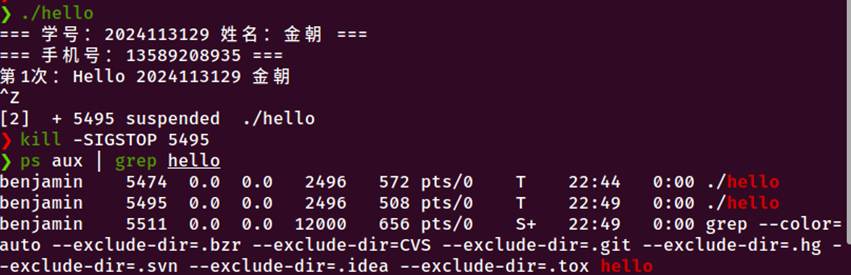
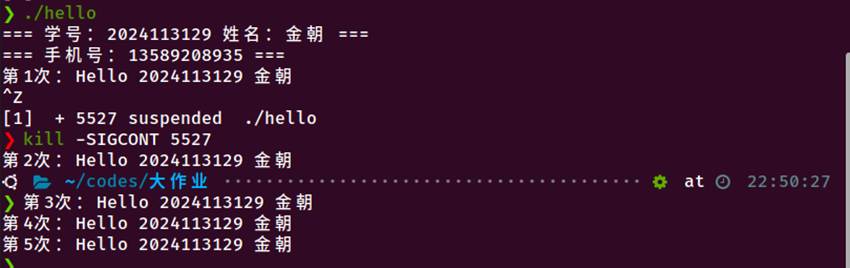
图6-5 使用kill命令发送信号、使用kill -STOP暂停进程、使用kill -CONT恢复进程、使用kill -TERM终止进程
发送SIGTERM终止进程
发送SIGSTOP暂停进程
发送SIGCONT恢复进程
6.7本章小结
本章深入分析了hello程序的进程管理机制。首先阐述了进程的基本概念与作用,说明了shell如何通过fork-execve机制创建hello进程。通过实际测试验证了hello在运行过程中可能遇到的各类异常和信号,包括SIGINT(Ctrl+C)、SIGTSTP(Ctrl+Z)等。
通过前台运行、后台执行、键盘信号测试等多种方式,验证了hello程序对Unix标准信号的响应机制。测试结果表明,程序能正确处理Ctrl-C(立即终止)、Ctrl-Z(暂停挂起)等键盘信号,并能通过jobs、ps、pstree、fg、kill等命令进行进程状态查看和控制管理。
实验发现hello程序存在后台执行限制:当在后台运行并尝试读取终端输入(getchar())时,会被shell自动挂起,显示为"suspended (tty input)"状态。这一机制体现了操作系统对终端访问的保护。
第7章 hello的存储管理
7.1 hello的存储器地址空间
1.逻辑地址:程序中使用的地址,如&student_id、&i等局部变量地址
2.线性地址:在x86-64架构中,段式管理基本不起作用,线性地址通常等于逻辑地址
3.虚拟地址:进程视角的地址空间,如main函数的0x5555555551c9
4.物理地址:实际DRAM芯片上的地址,通过MMU转换得到
hello 程序地址空间示例:
代码段:0x555555555000-0x555555556000
数据段:0x555555557000-0x555555558000
堆栈段:0x7ffffffde000-0x7ffffffff000
7.2 Intel逻辑地址到线性地址的变换-段式管理
x86-64 架构中段式管理的简化:
1.段寄存器作用减弱:CS、DS、ES、SS等段寄存器仍存在,但通常设置为0
2.平坦内存模型:Linux使用平坦内存模型,段基址为0,界限为4GB
3.逻辑地址转换:逻辑地址 = 段选择子 + 偏移 → 线性地址
4.实际实现:段基址为0,因此线性地址 = 偏移地址
对于hello程序:
所有段(代码、数据、堆栈)基址均为0
逻辑地址直接映射为线性地址
分段主要用于权限检查而非地址转换
7.3 Hello的线性地址到物理地址的变换-页式管理
7.3.1 页表结构
线性地址 → 页表查询 → 物理地址
7.3.2 页大小与对齐
标准页大小:4KB(4096字节)
hello各段按4KB对齐:
代码段:0x555555555000(页对齐)
数据段:0x555555557000(页对齐)
7.3.3 转换过程
假设hello访问变量student_id:
1.虚拟地址:假设为0x7ffffffde1c0
2.查页表获取物理页框号
3.加上页内偏移得到物理地址
7.4 TLB与四级页表支持下的VA到PA的变换
7.4.1 四级页表结构
虚拟地址:63:48保留 | 47:39L4 | 38:30L3 | 29:21L2 | 20:12L1 | 11:0偏移
7.4.2 地址转换流程
虚拟地址 → TLB查询(命中) → 物理地址
↓(未命中)
四级页表遍历 → 物理地址
7.4.3 TLB (转换后备缓冲区)
1.缓存最近使用的页表项
2.hello程序的特点:
局部性强:循环访问相同变量
TLB命中率高:减少页表遍历开销
7.4.4 hello 的地址转换示例
访问main函数地址0x5555555551c9:
1.计算各级索引:
L4: (0x5555555551c9 >> 39) & 0x1FF
L3: (0x5555555551c9 >> 30) & 0x1FF
L2: (0x5555555551c9 >> 21) & 0x1FF
L1: (0x5555555551c9 >> 12) & 0x1FF
2.逐级查询页表
3.获取物理页框号
4.加上偏移0x1c9
7.5 三级Cache支持下的物理内存访问
7.5.1 缓存层次结构
CPU → L1 Cache → L2 Cache → L3 Cache → 主存
7.5.2 hello 的缓存访问模式
1.指令缓存:循环执行相同代码,高命中率
2.数据缓存:
student_id、student_name:访问频繁
循环变量i:频繁更新
3.时间局部性:循环体反复执行
4.空间局部性:数组元素连续存储
7.5.3 缓存行大小影响
典型缓存行:64字节
hello的数据特点:
1.student_id11:11字节 + 1终止符
2.student_name7:7字节(UTF-8中文)
3.可放入单个缓存行
7.6 hello进程fork时的内存映射
7.6.1 fork() 的内存管理
pid_t pid = fork(); // Shell创建hello进程
7.6.2 写时复制(Copy-on-Write)
1.初始状态:子进程共享父进程页表
2.写入时:发生缺页异常,复制物理页
3.对hello的意义:
快速创建进程
实际内存复制推迟到写入时
7.6.3 fork 后的内存布局
父进程(bash)和子进程(hello):
1.共享代码段(只读)
2.独立的数据段、堆、栈
3.独立的页表指向相同物理页(初始时)
7.7 hello进程execve时的内存映射
7.7.1 execve 内存操作
execve("./hello", argv, environ);
7.7.2 内存映射步骤
1.释放旧内存:清除原进程的用户空间
2.映射新程序:根据ELF程序头建立映射
3.设置堆栈:分配栈空间,设置参数和环境变量
7.7.3 hello 的ELF段映射
|---------|----------------|-----|--------|
| ELF段 | 虚拟地址范围 | 权限 | 文件偏移 |
| .interp | 0x555555554318 | r-- | 0x318 |
| .text | 0x555555555000 | r-x | 0x1000 |
| .rodata | 0x555555556000 | r-- | 0x2000 |
| .data | 0x555555557000 | rw- | 0x3000 |
7.7.4 动态链接库映射
libc.so.6:0x7ffff7dbf000
ld-linux-x86-64.so.2:0x7ffff7fcf000
7.8 缺页故障与缺页中断处理
7.8.1 缺页类型
hello可能遇到的缺页:
1.首次访问缺页:
第一次访问代码/数据页
从磁盘加载到内存
2.写时复制缺页:
fork后首次写入共享页
复制物理页
3.访问权限缺页:
写入只读页(如.rodata)
触发段错误(SIGSEGV)
7.8.2 缺页处理流程
缺页异常 → 陷入内核 → 查找vma → 分配物理页 → 加载数据 → 更新页表 → 返回用户态
7.8.3 hello 的具体情况
启动阶段:多个缺页加载代码和数据
执行阶段:栈增长可能触发缺页
循环执行:TLB和缓存减少缺页
7.9动态存储分配管理
7.10本章小结
本章深入分析了hello程序的存储管理机制。从逻辑地址、线性地址、虚拟地址到物理地址的转换过程,详细阐述了x86-64架构下的段式管理、页式管理、TLB和四级页表工作机制。
通过分析hello的内存布局和访问模式,理解了缓存层次结构对程序性能的影响。进程创建时的fork-execve机制涉及复杂的内存映射和写时复制技术,这些机制在保证效率的同时实现了进程间的隔离保护。
缺页异常处理机制确保了按需加载和内存高效利用,而动态存储分配则为库函数提供了灵活的内存管理能力。
第8章 hello的IO管理
8.1 Linux的IO设备管理方法
8.1.1 设备文件化
1.一切皆文件:设备被抽象为特殊文件
2.设备文件位置:/dev目录下
h3.ello涉及的设备:
终端设备:/dev/tty 或 /dev/pts/*
标准输入:/dev/stdin
标准输出:/dev/stdout
8.1.2 设备类型
1.字符设备:终端、键盘(按字符流访问)
2.块设备:磁盘(按块访问)
3.网络设备:网卡(特殊套接字接口)
8.1.3 设备驱动模型
应用程序(hello) → 标准库(glibc) → 系统调用 → 虚拟文件系统 → 设备驱动 → 硬件设备
设备的模型化:文件
设备管理:unix io接口
8.2 简述Unix IO接口及其函数
Unix提供统一的IO接口,hello使用了以下关键函数:
// hello使用的标准IO函数
printf() // 格式化输出到stdout
getchar() // 从stdin读取字符
8.2.2 底层系统调用
|-----------|---------|------------|
| 标准库函数 | 对应系统调用 | 功能 |
| printf() | write() | 写入数据到文件描述符 |
| getchar() | read() | 从文件描述符读取数据 |
| puts() | write() | 写入字符串并换行 |
8.2.3 文件描述符
hello使用的文件描述符:
0:标准输入(stdin)
1:标准输出(stdout)
2:标准错误(stderr)
8.2.4 IO 缓冲机制
1.全缓冲:磁盘文件(hello未使用)
2.行缓冲:终端输出(printf使用)
3.无缓冲:标准错误
hello的缓冲特点:
printf输出到终端:行缓冲
遇到换行符\n时刷新缓冲区
程序正常退出时自动刷新
8.3 printf的实现分析
8.3.1 printf 函数调用链
printf() → vprintf() → vsprintf() → write() → sys_write() → 终端驱动
8.3.2 具体实现步骤
步骤1:格式化处理
// 类似vsprintf的处理
char buffer1024;
va_list args;
va_start(args, format);
len = vsprintf(buffer, format, args);
va_end(args);
步骤2:系统调用
// 调用write系统调用
write(STDOUT_FILENO, buffer, len);
步骤3:陷入内核
用户态 → int 0x80/syscall → 内核态 → sys_write()处理
步骤4:终端驱动处理
1.检查终端类型和模式
2.处理特殊字符(如\n转\r\n)
3.写入终端缓冲区
步骤5:显示到屏幕
终端驱动 → 显示控制器 → VRAM → 显示器
字符到字模库查找字形
写入视频内存(VRAM)
显示器按刷新率扫描显示
8.3.3 hello 中printf的使用
printf("第%d次:Hello %s %s\n", i+1, student_id, student_name);
处理过程:
1.解析格式字符串:%d、%s、%s
2.转换整数i+1为字符串
3.拼接所有字符串
4.写入标准输出
8.4 getchar的实现分析
8.4.1 getchar 函数调用链
getchar() → read() → sys_read() → 终端驱动 → 键盘中断
8.4.2 键盘中断处理
中断触发:
1.用户按键产生扫描码
2.键盘控制器发送中断请求
3.CPU响应中断,执行中断处理程序
中断处理流程:
键盘中断 → 读取扫描码 → 转换为ASCII码 → 存入缓冲区
8.4.3 read 系统调用
// getchar内部实现
int getchar(void) {
char c;
if (read(STDIN_FILENO, &c, 1) == 1)
return (unsigned char)c;
return EOF;
}
8.4.4 终端输入模式
hello运行时终端的典型设置:
规范模式:行缓冲,等待回车
回显:显示键入的字符
信号处理:Ctrl-C等特殊字符处理
8.4.5 hello 的getchar行为
getchar(); // 等待用户按回车键
具体过程:
1.程序阻塞,等待输入
2.用户按键存入系统缓冲区
3.按回车键时,整行数据传递给程序
4.getchar返回第一个字符(或EOF)
8.4.6 信号中断处理
如果getchar等待时收到信号:
SIGINT(Ctrl-C):返回EINTR错误
SIGTSTP(Ctrl-Z):进程暂停,恢复后继续等待
8.5本章小结
本章深入分析了hello程序的IO管理机制。Linux通过统一的文件接口管理所有IO设备,hello程序使用的printf和getchar函数最终通过write和read系统调用与终端设备交互。
printf的实现涉及复杂的格式化处理、缓冲区管理和终端驱动交互,最终将字符显示到屏幕。getchar的实现则依赖于键盘中断处理、终端驱动和系统调用机制,实现了从键盘到程序的字符传输。
通过分析这些IO操作的底层机制,理解了用户程序如何通过操作系统提供的抽象接口与物理设备交互,以及操作系统如何管理设备资源、处理中断和提供统一的访问接口。这些机制保证了hello程序能够正常地从用户获取输入并向用户显示输出。
结论
1. 从程序到进程(P2P过程)
编写阶段:创建hello_linux.c源文件,包含main函数及字符串数据
预处理阶段:gcc -E展开头文件,删除注释,生成hello.i
编译阶段:gcc -S将C代码转换为x86-64汇编代码hello.s
汇编阶段:gcc -c将汇编代码转换为机器码,生成可重定位目标文件hello.o
链接阶段:gcc链接hello.o与C库,解析符号引用,生成可执行文件hello
加载执行:shell通过fork()+execve()创建进程,内核加载hello到内存并执行
2. 从零到零(020过程)
零状态:hello作为ELF文件静默存储在磁盘上
进程创建:shell解析命令,fork子进程,execve加载hello
执行阶段:进程在CPU上运行,调用printf、sleep、getchar等函数
终止阶段:main返回0,进程终止,资源回收
归零状态:进程消失,仅保留磁盘上的可执行文件
3. 关键转换过程
文本到二进制:C源码 → 汇编 → 机器码 → 可执行文件
静态到动态:磁盘文件 → 内存映像 → 执行状态
用户到内核:系统调用在用户态与内核态间切换
虚拟到物理:虚拟地址空间通过页表映射到物理内存
计算机系统的设计让我体会到分层抽象的精妙------每层隐藏下层复杂度,为上层提供简洁接口。从hello程序看,我们写C代码时不用管汇编细节,编译器自动优化;运行时操作系统管理内存和进程,我们只需关注逻辑。这种"各司其职"的设计让复杂系统可控。
我的创新想法是让系统更智能适应。现在的优化多是固定的,比如缓存大小、调度策略。如果系统能观察程序行为自动调整呢?比如发现hello在循环打印,就预缓存字符串;看到用户频繁暂停,就调整进程切换策略。
另一个方向是跨层信息传递。编译器知道程序结构(比如哪些数据只读),但操作系统不知道。如果编译器能传递这些信息,系统可以更好优化------把只读数据放在特殊内存区,对循环代码使用更积极的缓存策略。
这些创新不是重造系统,而是在现有基础上增加"感知-适应"能力,让系统从"一刀切"变得更贴合具体程序的需求。
附件
hello_linux.c - C语言源代码文件
hello.i - 预处理后文件(展开头文件)
hello.s - 汇编代码文件
hello.o - 可重定位目标文件(未链接)
hello - 最终可执行文件
hello_elf.txt - hello的ELF格式分析
hello_o_elf.txt - hello.o的ELF格式分析
hello_disasm.txt - hello反汇编代码
hello_o_disasm.txt - hello.o反汇编代码
hello_verbose - gcc详细编译日志
参考文献
1 Randal E. Bryant, David R. O'Hallaron. 深入理解计算机系统(原书第3版)M. 龚奕利,寇建译. 北京:机械工业出版社,2016. ISBN: 9787111544937.
2俞甲子,石凡,潘爱民. 程序员的自我修养:链接、装载与库M. 北京:电子工业出版社,2009.
3 Daniel P. Bovet, Marco Cesati. 深入理解Linux内核(原书第3版)M. 北京:中国电力出版社. ISBN: 9787508353944.
4 Michael Kerrisk. The Linux Programming Interface: A Linux and UNIX System Programming HandbookM. San Francisco: No Starch Press, 2010. ISBN: 9781593272203.
5 John R. Levine. Linkers and LoadersM. San Francisco: Morgan Kaufmann, 1999. ISBN: 9781558604964.