Agent-as-a-Judge
关于"智能体即裁判"的研究综述

摘要
LLM即评委通过利用大语言模型进行规模化评估,彻底改变了人工智能评价范式。然而,随着评估对象日益复杂化、专业化与多步骤化,LLM即评委的可靠性正受到内在偏见、浅层单次推理以及无法对照现实观测验证评估结果的制约。这推动了向智能体即评委的范式转变------智能体评委通过任务规划、工具增强验证、多智能体协作与持久记忆等技术,实现了更鲁棒、可验证且细致入微的评估。尽管智能体评价系统正快速涌现,该领域仍缺乏统一框架来厘清这一变革格局。为填补这一空白,我们首次对该演进路径进行了全面综述,具体而言:我们界定了此次范式转变的关键维度,建立了发展分类体系;系统梳理了核心方法,并综述了其在通用领域与专业领域的应用;进一步,我们剖析了前沿挑战并指出了有前景的研究方向,最终为下一代智能体评价系统提供了清晰的路线图。
1.引言
大型语言模型(LLM)的快速发展彻底改变了人工智能评估领域,催生了"LLM即评判者"的研究范式1。传统指标无法捕捉语义的细微差别,而人工评判又难以规模化,这种新方法则利用LLM的高级理解与决策能力,在多个领域实现接近人类水平的评估质量2。此外,作为人类偏好的可规模化代理,LLM评判者能为强化学习提供奖励信号3,并支持海量合成数据集的自动构建4。因此,LLM评判已成为人工智能评估与优化流程的基石,其判断精度直接决定着下游应用的成功与否5。
然而,随着生成式人工智能应用从简单的文本响应演变为跨专业领域的复杂多步骤任务,大语言模型即法官的可靠性已不可避免地受到限制2, 6。首先,单次评估者容易产生固有的参数偏见------例如倾向于冗长或自身的输出模式------这损害了其在评估偏离其训练分布的高复杂度回答时的中立性7。其次,单纯的大语言模型法官是被动的观察者,无法对现实世界的观察作出反应;它们仅依据语言模式评估答案而不进行验证,导致在专业领域产生幻觉性评估8。此外,在需要多维度评估量规的任务中,传统的大语言模型法官在试图通过单一推理步骤全面评估所有维度时,会经历认知过载,从而导致结果仅为未能反映具体细微差异的粗粒度评分9。
这些局限性推动了从"大语言模型即裁判"向"智能体即裁判"的转变。如在图1中,具身智能评估者通过多种能力主动参与评估:他们将复杂目标分解为子任务,通过多智能体协作减轻偏差10,借助工具增强的证据收集与正确性验证实现评估的实证基础8,并通过持久化中间状态、跨推理步骤自主规划评估过程,实现细粒度评估11, 12。这种范式转变使得评估更加稳健、可验证且细致入微,从而有效应对复杂AI生成评估对象的多维特性。
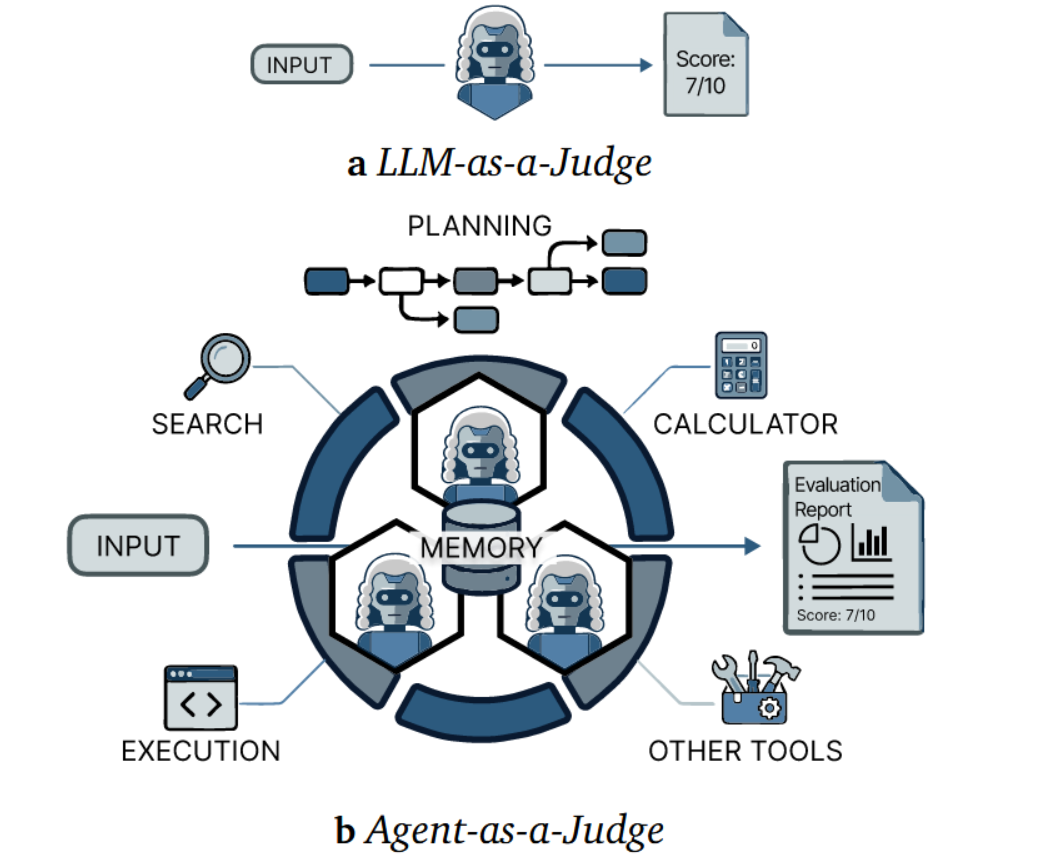
图1:LLM即法官(1a)与智能体即法官(1b)的对比。前者执行直接的单次评估,而后者利用规划、记忆和工具增强能力以实现更优的评估。
尽管代理评估系统具有上述潜力并正在快速普及,该领域仍缺乏一项系统性综述来总结和梳理这一动态发展的格局。为弥补这一空白,我们通过以下贡献首次提出了"智能体即评判员"的综合评述:
• 我们识别并界定了从"大语言模型即评判员"到"智能体即评判员"的范式转变,并将代理评判系统的发展趋势归纳为三个递进阶段(第2节)。
• 我们依据智能体的能力将核心方法论归纳为五个关键部分(第3节),并系统考察了其在通用领域与专业领域的应用实践(第4节)。
• 我们分析了前沿挑战并指出了具有潜力的研究方向,为构建下一代鲁棒且可验证的人工智能评判体系提供了战略路线图。
2.演进路径:从大语言模型即裁判到智能体即裁判
本节追溯从"LLM即评委"到"智能体即评委"的自动化评估范式演进。我们首先回顾基础性的"LLM即评委"框架及其局限性,继而审视向"智能体即评委"的范式转变,分析该智能体化方法的核心特征维度。最后,我们将"智能体即评委"的发展趋势总结为三个渐进阶段,每个阶段具备不同层级的自主性与适应性。
2.1 大语言模型即评判者
LLM-as-a-Judge范式的出现,旨在克服人工评估的可扩展性限制以及传统指标的语义不敏感性。Zheng等人1通过引入MT-Bench等基准来评估模型对齐度,从而正式确立了该方法。在此基础上,G-Eval59利用思维链提示来提升自然语言生成领域的对齐效果,而Prometheus60则通过专项调优在开源模型中实现了细粒度评估。为了缓解位置偏差和冗长偏好等系统性问题7,JudgeLM61采用微调技术开发了更为鲁棒的评估器。
2.2 从大语言模型即裁判到智能体即评判
随着评估对象从简单的文本响应演变为跨专业领域的复杂多步骤任务,传统的"大语言模型即评判者"范式已日益显得不足------其仅关注最终输出,既无法验证中间步骤,也难以满足专业领域的严谨标准2, 6。为弥补这一缺陷,当前范式正转向"智能体即评判者",该模式通过分布式审议、可执行验证与细粒度评估来缓解这些局限性。
演进中的稳健性:从单体到去中心化。为缓解单体大语言模型评审固有的参数偏见------例如倾向于冗长或自身输出模式的范式------代理即评审范式采用专门的去中心化智能体,这些智能体通过自主决策进行协作10, 13。关键在于,这种去中心化架构有助于注入专家先验知识:通过将复杂评估目标分解为子任务,或构建特定的交互工作流程,我们可以强制执行领域特定的约束,而通用模型通常会忽略这些约束16, 24。此外,多智能体审议确保了集体稳健性;不同的角色可以隔离特定的信息点以消除偏见,而辩论与自我反思使智能体能够审查自身的认知捷径,从而确保最终判断超越任何单一模型的启发式局限62, 7。
演进中的验证机制:从直觉判断到执行验证
静态大型语言模型评判器本质上是被动观察者,无法对现实世界反馈作出反应。它们基于语言合理性(回答表面的正确性)进行评估,既不进行验证也不收集证据,导致复杂任务中出现"幻觉正确性"8。智能体即评判器通过用执行替代直觉,弥合了这一现实鸿沟。通过与外部环境交互,智能体评判器能够:查询系统状态以验证副作用(如文件操作)48,51;运用代码解释器或定理证明器检验逻辑一致性37;调用搜索工具将事实主张锚定于实时文档38,8。这一转变将评估基准从内部模型知识转移至客观验证层面。
粒度演进:从全局评估到细粒度分析。许多评估任务本质需要多维度的评价体系,而传统的大语言模型评判者在单一推理步骤中面临认知过载,难以全面评估这些维度,导致产生的粗粒度评分无法反映具体细微差异9。智能体即评判者通过将评估从单次推理转变为自主分层推理来解决这一问题9。与单一整体评估不同,智能评判者能动态选择或创建任务专属的评价体系,自主规划评估过程以独立审查被评对象的每个组成部分44,并利用记忆机制追踪历史推理状态,将碎片化证据综合为连贯判断。因此,这些智能体能够精确定位在全局评分中可能被掩盖的特定缺陷,为每个评估维度提供细粒度反馈45。
2.3 智能体即裁判
Agent-as-a-Judge(法官式智能体)代表了一个快速发展的领域,其中"智能体"一词常被宽泛使用,涵盖从程序化智能体工作流到自主自我进化者等一系列异质性概念10, 45, 12。为厘清这一复杂领域的脉络,我们将智能体技术的持续发展概括如下。
程序性智能体即法官将单体推理解耦为智能体预定义工作流57, 24,或通过固定子智能体间的结构化讨论实现判断10, 56。这类系统通过协调多智能体交互可实现复杂判断,但仍受限于预设决策规则,无法适应新颖的评估场景。
反应式代理即裁判通过基于中间反馈的路由执行路径28, 45和调用外部工具8或子代理13,实现了自适应决策。然而,此类反应性仍局限于固定决策空间内的条件路由,缺乏优化底层评估准则的自主性。
自演进式智能体即评委代表了该领域的前沿,其特点是高度自主性,能够在运行过程中优化内部组件------即时合成评估准则53并依据经验教训更新记忆。这一范式为自适应评估系统开辟了新前沿,但如何确保自我修正过程中的稳定性仍是待解决的挑战63。
3.方法
本节将智能体判官方法体系归纳为五个维度:多智能体协作、规划、工具集成、记忆与个性化以及优化范式。如图2所示,实现复杂度揭示了其演进阶段:基础方法(协作、工具集成、优化)贯穿所有阶段持续发展,而其他维度(规划、记忆)则在高级范式中更为凸显。以下小节将逐一探讨各方法在这些阶段中的具体表现形式。
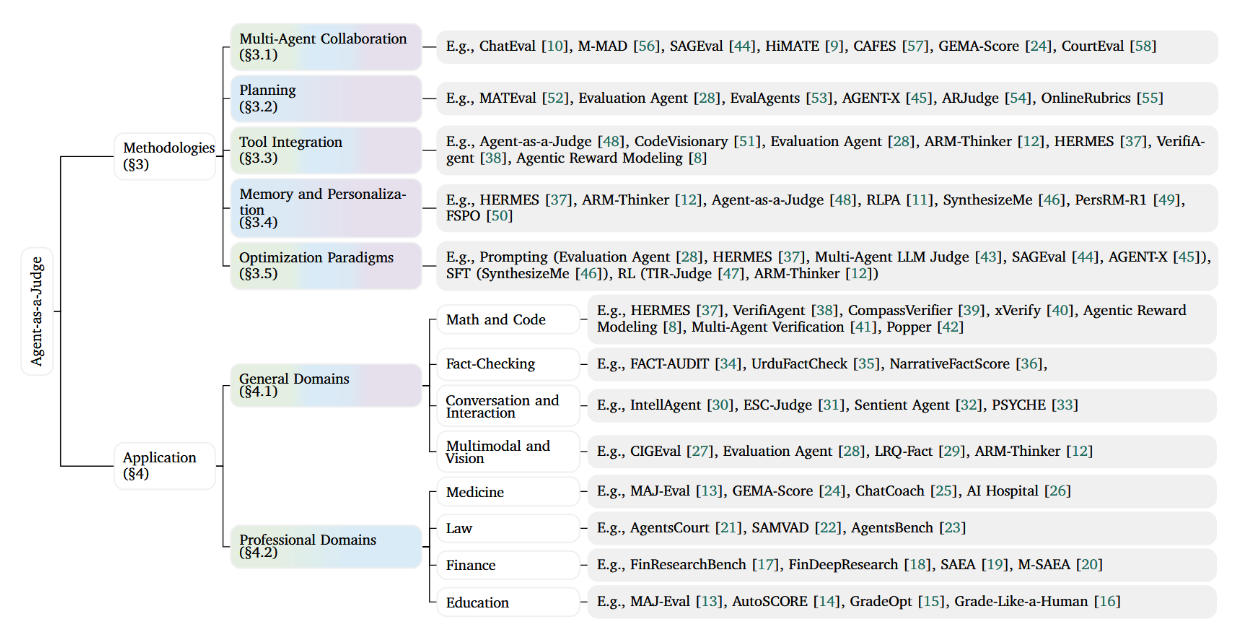
图2:作为评判者的智能体分类体系,涵盖方法论(§3)与应用领域(§4)。背景渐变色调展示了从"流程化"到"反应式",再到"自主演化"的发展阶段覆盖范围。
3.1 多智能体协作
多智能体协作利用集体推理来缓解Agent-as-a-Judge系统中单一大语言模型的偏差。早期系统遵循具有固定协议的程序化范式,而近期研究则演变为能根据反馈自适应选择智能体的反应式方法。我们将其归类为两种拓扑结构:
集体共识。横向辩论机制通过代理代表多元视角,以抵消单一大语言模型评估者固有的偏见,如图3所示。早期方法代表了程序化阶段:ChatEval 10 开创性地引入了法庭式讨论机制,代理遵循预定协议以平等地位进行辩论。这一范式后来被 M-MAD 56 扩展至机器翻译领域,而后续研究 64 则引入了明确的立场和"裁判"角色,以防止代理盲目附和多数意见。近期方法已变得更加自我进化:例如 Multi-agent-as-judge 13 等方法超越了静态集合,通过基于中间反馈创建领域特定专家来实现这一目标。
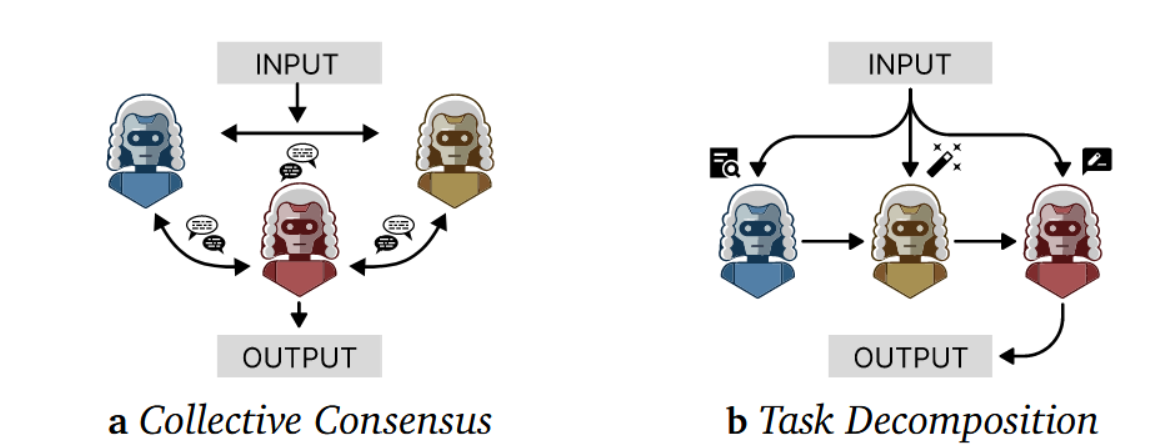
图3:多智能体协作范式。
任务分解。任务分解采用「分而治之」策略,将不同子任务分配给专业智能体进行系统性评估,如图3所示。早期框架遵循程序化设计:如CAFES 57和GEMA-Score 24, 58等序列方法将评估构建为预定义阶段(例如证据收集、推理、评分),而SAGEval 44则通过「评判裁判」元评估器引入监督机制,该机制会对先前智能体的决策进行复核,采用层级化方法的如HiMATE 9将智能体组织为树状结构,以实现不同错误粒度层级。近期研究则更多转向反应式范式:AGENT-X 45采用自适应路由智能体,能够基于中间分析结果动态选择最相关的基础智能体。
多智能体评估框架主要采纳两种拓扑结构:集体共识与任务分解。最新进展已朝着更自主的方向发展,系统能够自主选择或生成子智能体。
3.2 规划
规划作为智能体即评判员范式中的核心能力,能够将高层级评估目标分解为可执行的子任务,并根据中间分析动态调整评估轨迹。本节将从两个视角考察规划能力:
工作流编排。智能体即评委系统中的工作流编排涵盖从静态框架到动态代理的范畴,主要表征智能体评估的程序化与反应式阶段。以MATEval52为代表的方法依赖于静态分解,将任务拆解为固定的子维度序列。虽然这种通过预定义控制流确保系统化评估的方式具有优势,但其在复杂场景中的适应性受到限制。相比之下,评估智能体28引入了动态多轮规划机制,智能体能够根据中间反馈调整策略。该系统还通过自主终止机制进一步优化效率,使智能体能够自我监控信息增益,并在收集到充分证据时主动终止执行。
评估准则发现。与专注于任务完成的通用智能体不同,判据型智能体具备自主制定和完善评估准则的独特能力,这标志着其进入了自我演进阶段------在该阶段中,智能体能够优化其内部评估组件。EvalAgents 53 通过运用查询生成器规划网络搜索以发现隐性评估准则,体现了这一特性;而 AGENT-X 45 则采用自适应路由器来推断领域上下文并规划定制化的检测指南。ARJudge 54 通过迭代生成上下文敏感问题来自适应地构建评估准则,OnlineRubrics 55 则将规划整合进强化学习,使评估准则能够伴随策略优化同步演进,以检测奖励破解行为。核心启示:规划作为战略引擎,将评估从僵化的流程转变为自适应探索,使智能体能够优化其评估方式(工作流编排)与评估内容(评估准则发现)。
3.3 工具集成
工具集成是智能体即评委框架的一项关键能力,使评委能够基于外部证据和显性核查进行评估。如表1所示,现有方法可根据工具使用的目的,归类为证据收集与正确性验证两类。
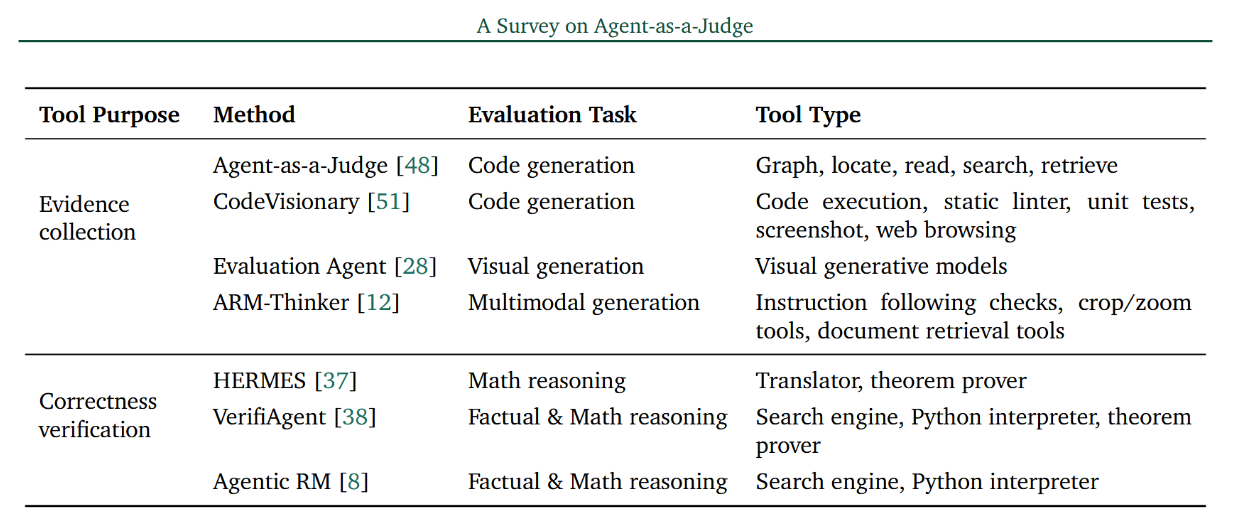
表1:按主要工具使用目的分组的代表性"智能体即评审"方法中的工具集成情况。
正确性验证。另一研究方向运用工具来验证评估对象的输出或中间推理步骤是否满足显式正确性约束,例如逻辑有效性、数学严谨性或事实一致性。在这些框架中,评判智能体负责识别哪些主张某些步骤需要验证,并调用相应工具进行检查。智能体随后在上下文中解读所产生的验证信号,以形成最终评估。HERMES 37 通过形式化定理证明来验证数学推理,而 VerifiAgent 38 则调用程序化与符号化检查器来验证事实性与计算性声明。智能体奖励建模 8 进一步整合了正确性验证,它结合事实核查工具与程序化验证器,以产生结构化的正确性信号,从而为最终评估提供依据。
3.4 记忆与个性化
记忆机制使"智能体即法官"框架能够在评估步骤间保留信息,从而支持多步推理、保持判断一致性并实现先前结果的重用。我们依据记忆功能对现有研究进行分类,包括中间状态追踪和个性化语境留存两个方面。
中间状态。在多步评估场景中,智能体即评委框架利用记忆模块来保留评估过程中产生的中间评估状态,为基于中间反馈的条件路由与自适应决策提供必要上下文------这是反应式智能体即评委的基本机制。HERMES 37 在结合推理与形式化定理证明时保留了中间证明状态,从而能在长推理链中实现一致性验证。ARMThinker 12 保留了视觉推理输出和工具交互结果等中间证据,后续将其复用以支撑评估。智能体即评委 48 则记录了执行轨迹与步骤级反馈,使得评估能够超越最终输出,同时考量中间行为。这些方法共同通过记忆机制保留中间状态,以支持具有累积性与步骤感知能力的评估。
个性化语境。作为评判者的智能体框架通常内置记忆模块,用以存储与用户相关的信息,从而在不同交互中建立评估条件。此类记忆模块能够捕捉用户偏好、评估标准或历史反馈,确保评判结果随时间推移保持一致性。PersRMR1 49 与 FSPO 50 存储从历史交互中提取的偏好数据(包括偏好标签或少样本示例),并将其复用于同一用户的后续评估条件设定。更先进的方法则将历史偏好信号抽象为持久化的用户画像或长期档案。RLPA 11 与 SynthesizeMe 46 通过构建并维护可存储复用的用户画像来体现这一思路,此类长期用户画像常服务于支持自我演进的作为评判者的智能体,使其能基于动态变化的偏好实现持续优化。这些方法共同通过记忆机制保留个性化语境,从而塑造评估行为并确保跨交互的一致性。
"记忆模块"使智能体作为裁判能够保留中间状态与个性化上下文,支持多步骤评估、保持判断一致性,并高效复用历史信息。
3.5 优化范式
优化范式界定了智能体即评委通过更新模型参数或调整评估行为以提升评估质量的具体方式。我们将现有研究归纳为两类:训练时优化与推理时优化。
训练时优化。训练时优化通过更新模型参数,使评判行为与评估目标对齐,从而优化"智能体即评委"系统。监督微调常用于规范评委行为,训练模型遵循明确标准,并在多任务中生成结构化判断。例如,SynthesizeMe 46 利用基于历史数据生成的角色引导监督信号,塑造评估行为。强化学习则优化评委更有效地执行评估动作,尤其在需要工具使用和多步验证的场景中。TIR-Judge 47 与 ARM-Thinker 12 训练评委决定何时及如何调用工具、整合外部信号并验证中间结果。训练时优化通过共同塑造内部决策过程,实现了更可靠、结构化的评估。
推理时优化。
推理时优化通过提示、工作流程或智能体交互来控制判断生成方式,从而在不更新模型参数的情况下调整评估行为。现有方法可大致分为两类:
- 第一类遵循预定义的评估流程,其推理步骤、验证例程或提示均预先固定,以确保一致性与效率。评估智能体28与HERMES37采用结构化的分步评估流程,是此类方法的典型代表。
- 第二类允许评估行为在推理过程中动态调整,其评估流程、参与智能体或所应用的评估标准根据中间结果动态调整。MultiAgent LLM Judge 43 通过多评审员协同机制迭代优化提示与上下文,而 SAGEval 44 则引入元评审员以监督并修正评审行为。ChatEval 10 与 AGENTX 45 进一步通过智能体交互和动态准则选择实现自适应评估。总体而言,推理时优化技术实现了对评估行为的灵活调控,其范围涵盖固定流程至基于交互的自适应判断。
摘取优化通过训练时参数更新学习评估行为或推理时调整评估策略来改进"智能体即评委"机制。
4.应用
基于上述方法,本节阐述了智能体即评判员方法在不同评估任务中的应用。如图4所示,我们将代表性应用组织为两组:通用领域与专业领域。
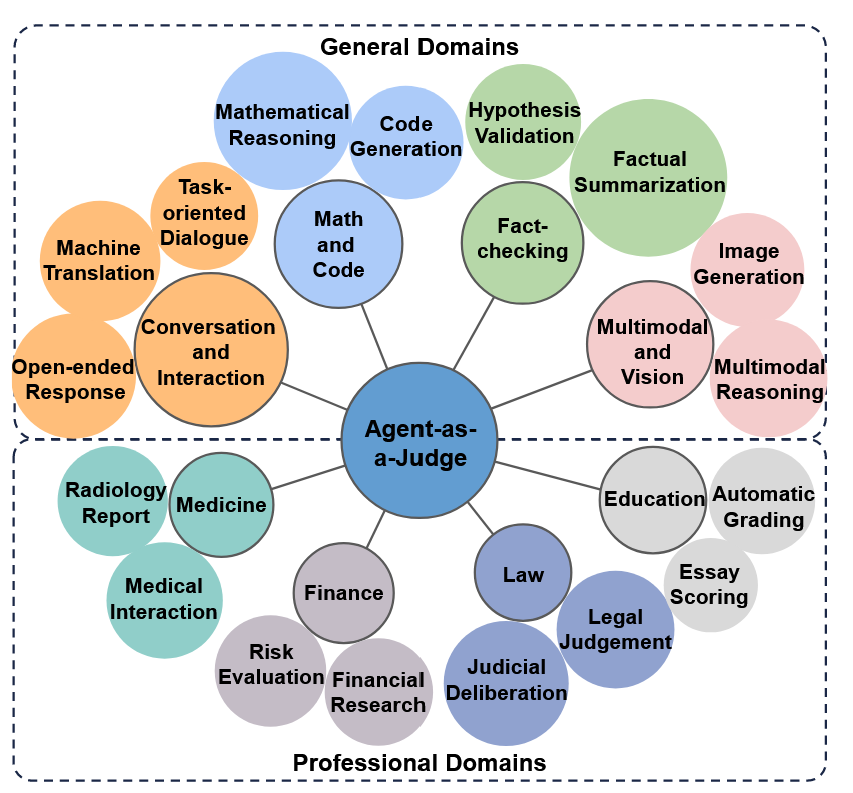
图4:智能体即裁判应用领域及其细粒度任务分类概览。
4.1 通用领域
数学与代码。在数学和代码评估中,Agent-as-a-Judge 系统通过将判断建立在可验证的推理信号基础上,超越了单次评分的局限。一项研究工作通过显式正确性检查来增强自由形式推理:HERMES 37 将大语言模型的推理锚定在中间形式化证明步骤上,减少了长推导过程中的偏差;VerifiAgent 38 将高层推理评估与基于工具的正确性验证解耦,实现了跨推理类型的自适应检查;CompassVerifier 39 和 xVerify 40 专注于数学与逻辑输出,解决了不同表面形式下的等价性检查问题。另一些方法通过聚合多重评估信号来强化判断:多智能体验证 41 将评估任务分配给面向特定方面的评审者;智能体奖励建模 8 将基于偏好的监督与可验证的正确性信号相结合,以提高奖励的可靠性;Popper 42 将判断构建为受控证伪过程,利用统计检验来验证自由形式的主张。
事实核查。在事实核查中,智能体即裁判(Agent-as-a-Judge)将评估范式从静态的标签预测,重构为结合证据收集与论证的交互式验证。FACT-AUDIT 34 将事实核查建模为一个多智能体协作的循环流程,联合评估论断准确性与论证质量。该范式在证据稀缺或矛盾细微时尤为有效。UrduFactCheck 35 通过多语言检索与证据增强,提升了低资源环境下的鲁棒性。NarrativeFastScore 36 通过构建角色级知识表示来处理长文本的事实一致性,从而能够检测状态与关系错误并提供可操作的反馈。
对话与交互。在对话与交互场景中,"Agent-as-a-Judge"从评估孤立回复转向构建多轮次交流,从而能够在动态变化的目标、约束条件和用户反应下进行评估。针对任务导向对话,IntellAgent 30 通过交互式用户模拟合成对话基准测试,而Kazi等人65则提出了可控用户目标与自动化评估框架的架构。在情感与社交交互方面,ESC-Judge 31 通过标准化咨询技巧构建情感支持智能体,Sentient Agent 32 追踪情绪随时间变化的轨迹以反映高阶社会认知,PSYCHE 33 则建立精神病患者画像用于伦理评估验证。Wu等人66将评估框架设计为多视角角色扮演,通过多样化评审角色覆盖主客观评估维度。
多模态与视觉领域。在多模态与视觉领域中,智能体即裁判从静态评分转向交互式审查。针对视觉生成任务,CIGEval 27 协同专用工具以探测控制依从性与主体一致性,而评估智能体 28 则通过多轮检查提供用户定制、可解释的分析。在真实性评估方面,LRQ-Fact 29 跨图像与文本生成有针对性的事实核查问题以引导证据检索,ARM-Thinker 12 则选择性调用图像检测等工具以完成最终判定。
4.2 专业领域
医学领域。在高风险临床自然语言处理中,智能体即法官(Agent-as-a-Judge)主要表现为两种形式:1)将临床质量评估分解为专项角色的多智能体评估器;2)通过交互激发临床行为的智能体模拟器。针对形式1,MAJ-Eval13构建了多个评估者角色进行辩论与交叉验证,而GEMA-Score24则利用智能体协作,通过工具辅助计算涵盖疾病严重程度和不确定性的细粒度评分。针对形式2,Chat-Coach25部署了自主患者与指导教练智能体对学员-医生对话进行评价,而AI Hospital26在多智能体模拟环境中对大型语言模型"医生"进行评估,尽管其最终评分通常仍需依赖传统指标。
金融领域。在金融分析中,"智能体即裁判"模式旨在解决静态基准的两大局限:1)捕捉长篇分析师报告的内部研究逻辑;2)识别幻觉风险与时效滞后等部署风险。针对第一点,FinResearchBench 17 从报告中提取逻辑树作为综合评估的中间结构,而FinDeepResearch 18 虽能生成分层评估框架,但仍依赖预设工作流。针对第二点,SAEA 19 提出通过审计智能体轨迹来缓解幻觉与时效错位问题;《从任务到团队》20 进一步扩展该方法,提出M-SAEA以追踪多智能体系统中的故障类型,例如跨智能体分歧与错误传播。
教育领域。在教育领域中,Agent-as-aJudge 系统通过协作化、角色专用化的工作流模拟教学中的细微差别。GradeLike-Human 16 与 AutoSCORE 14 将评分分解为阶段性流程(评分标准构建、证据识别、交叉评审),以提升依据性和一致性。除了静态评分外,MAJ-Eval 13 采用多角色辩论来与多维度的主观评价相校准,而 GradeOpt 15 则引入了能够诊断差异并迭代优化评分指南的智能体。
5.讨论
本节讨论在实践部署"智能体即评委"系统时衍生的更广泛议题。我们首先总结了制约其可扩展性、可靠性及实际应用的关键挑战,随后勾勒了若干未来研究方向,这些方向或许有助于突破现有局限,进一步推进智能体评估体系的发展。
5.1 挑战
代理即法官通过规划、工具调用、记忆与多智能体协作提升了评估可靠性,但这些能力也带来了超越静态大语言模型即法官的新挑战。关键挑战包括计算成本、延迟、安全性与隐私问题。
计算成本。智能体即裁判机制在训练和推断阶段都引入了更重的计算负担。1) 训练裁判智能体成本高昂。仅靠监督微调通常不足以支持工具调用、长期规划和自适应决策等智能体行为。强化学习为获取这些能力提供了一种自然途径,但这显著增加了训练成本,尤其是当裁判需要处理长轨迹或复杂工具调用序列时。2) 智能体即裁判的推断过程同样昂贵。与单次判断不同,智能体式评估通常涉及多步推理、中间决策以及多智能体间的协调,所有这些都增加了每次评估的计算开销。
延迟。除更高的计算成本外,智能体即评判方案还常面临推理延迟增加的问题。智能体评估需要顺序推理步骤、外部工具调用或多智能体通信,每个环节都会引入额外延迟。这种延迟在实时或交互场景中尤为突出,例如在线模型评估、面向用户的内容审核、或需要快速反馈的强化学习循环。因此,在评估可靠性与实际部署限制之间存在张力:在严格的延迟预算下,更彻底的智能体评判可能难以实现。
安全性。虽然"智能体即评委"旨在提升评估的稳健性,但同时也引发了新的安全隐患。工具增强型评委可能访问搜索引擎、代码执行器或数据库等外部系统,这扩大了提示注入、工具滥用或意外副作用等攻击面。若不安全行为在智能体间传播或出现对抗性交互,多智能体协作可能进一步放大风险。此外,当评委智能体被用于为模型优化提供奖励信号时,其判断中的系统性偏见或错误可能在训练过程中被固化并放大,最终导致模型出现预期外的行为。
隐私性。智能体作为评估者同样引入了隐私挑战,尤其是在涉及持久化记忆或个性化评估的场景中。为保持一致性或使判断适应用户特定情境,评估智能体可能存储中间状态、用户信息或历史交互数据。若未经审慎设计,此类记忆机制可能加剧敏感数据泄露或对用户属性进行未授权推断的风险。这一问题在医疗、法律、教育等专业领域尤为突出,因为这些领域的评估往往依赖机密信息或个人可识别信息。
5.2 未来方向
个性化。当前的"智能体即评委"系统受限于静态的、一刀切的评估标准,难以适应多样化的个人偏好。为弥补这一差距,未来研究应聚焦于提升评委智能体的自主性与适应性。其中关键的赋能机制是主动式记忆管理:智能体不应被动检索历史记录,而须主动管理用户特定知识的生命周期------自主决定何时记录新偏好、更新动态标准或剔除过时反馈。这种智能体主导的控制将记忆转化为动态信念系统,使评委能够持续优化其评判标准,并与用户的具体价值观及使用场景保持同步。
泛化能力。现有系统依赖于预先构建的离线评估标准,限制了其在多样化或开放性任务中的泛化能力。未来的评委智能体应利用规划能力,动态发现并适应评估标准。1)上下文感知的评估标准生成 :智能体应通过分析回答的具体意图与复杂程度,动态合成评估标准,识别设计阶段未预见的相关评估维度。2)自适应多粒度评分:评估标准应根据任务难度动态调整------对简单任务应用高层次整体性标准,对复杂工作流则分解为细粒度的子标准进行评估。
交互性。现有系统作为被动的单向观察者运行。未来智能体应演进为交互式评估者,能够主动与环境及人类参与者进行动态交互。1) 交互式环境反馈:评估智能体应摒弃静态测试集,动态定制评估轨迹------通过自主提升任务复杂度或隔离边缘案例,系统性地探查被评估对象的失效边界。2) 人机协同校准:针对主观性强或存在模糊性的场景,智能体需采用人在回路的机制。通过主动咨询专家以确认意图或解决分歧,评估者通过多轮对齐优化其评判标准,从而确保更高的可信度与可解释性。
优化。 当前方法主要依赖于推理阶段的工程优化,这在根本上受限于固定主干模型的能力瓶颈。为突破这些限制,该领域必须转向基于训练的优化。这一范式转变包含两个关键层面:
- 个体能力:利用强化学习内化复杂的智能体行为------例如序列化规划和自适应工具使用------这些行为仅通过提示难以有效激发。
- 习得式协同:将优化扩展到多智能体场景。与临时的推理时协作不同,应通过联合目标训练智能体,使其从本质上学习有效的沟通与共识策略。
结语:迈向真正的自主性。如第二节所述,现有实现方案展现出不同程度的能动性。前文讨论的未来方向------个性化、泛化性、交互性与优化------共同指向通往自主性的演进轨迹。新一代裁判智能体必须超越固定协议,成为真正具备能动性的实体,能够实现自主适应、主动情境构建与持续自我完善,最终充分发挥智能体的潜能,使其能够主动感知、推理,并与其评估的模型协同进化。
6 结论
本文首次对"智能体即裁判"范式进行了全面综述。我们建立了新颖的分类体系,并论证了智能体能力------包括多智能体协作、自主规划、工具集成与记忆机制------如何突破传统简单大语言模型裁判的局限性,从而在通用与专业领域实现更稳健、可验证且精细化的评估。尽管前景广阔,这一演进仍面临计算成本、延迟、安全性与隐私方面的挑战。未来的进展应优先关注个性化、泛化能力与系统优化,最终实现能够持续适应人工智能生态演进的真正自主评估体系。
范式共识的早期阶段。作为一项探索智能体即评委演化路径的先驱性研究,我们面临着该领域尚未在学术界获得完全广泛认可的挑战。尽管从"大语言模型即评委"到"智能体即评委"的转型已初具雏形,但关于评估智能体的定义仍缺乏长期共识。然而,建立这一基础框架对于引导未来研究方向至关重要。我们承诺将随着该范式的成熟和更广泛的认可,持续迭代完善此分类体系。
早期提示方法的纳入。我们认识到早期方法论与日益严格智能体定义之间可能存在差距。许多自动评估领域的开创性研究虽冠以"智能体"之名,实则高度依赖提示工程(例如固定角色扮演),这可能不符合当前学术界对自主性、动态规划或工具使用的严格标准。尽管如此,我们仍有意纳入这些基于提示的框架,因为它们代表了从单体推理向动态分解与自我演进系统的初始转向。若将其排除,将模糊这一转型轨迹,从而影响对该领域发展历程的完整理解。
7.引用文献
- 1 Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llmas-a-judge with mt-bench and chatbot arena. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS '23, Red Hook, NY, USA, 2023. Curran Associates Inc.
- 2 Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, et al. From generation to judgment: Opportunities and challenges of llm-as-a-judge. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2757--2791, 2025.
- 3 Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, and Sushant Prakash. Rlaif vs. rlhf: scaling reinforcement learning from human feedback with ai feedback. In Proceedings of the 41st International Conference on Machine Learning, ICML'24. JMLR.org, 2024.
- 4 Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, and Haobo Wang. On LLMs-driven synthetic data generation, curation, and evaluation: A survey. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Findings of the Association for Computational Linguistics: ACL 2024, pages 11065--11082, Bangkok, Thailand, August 2024. Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-acl. 658. URL https://aclanthology.org/2024. findings-acl.658/.
- 5 Hanyu Lai, Xiao Liu, Junjie Gao, Jiale Cheng, Zehan Qi, Yifan Xu, Shuntian Yao, Dan Zhang, Jinhua Du, Zhenyu Hou, Xin Lv, Minlie Huang, Yuxiao Dong, and Jie Tang. A survey of post-training scaling in large language models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2771--2791, Vienna, Austria, July 2025. Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long.140. URL https:// aclanthology.org/2025.acl-long.140/.
- 6 Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. The rise and potential of large language model based agents: A survey. Science China Information Sciences, 68(2):121101, 2025.
- 7 Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Lingpeng Kong, Qi Liu, Tianyu Liu, and Zhifang Sui. Large language models are not fair evaluators. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9440--9450, Bangkok, Thailand, August 2024. Association for Computational Linguistics. doi:10.18653/v1/2024.acl-long.511. URL https:// aclanthology.org/2024.acl-long.511/.
- 8 Hao Peng, Yunjia Qi, Xiaozhi Wang, Zijun Yao, Bin Xu, Lei Hou, and Juanzi Li. Agentic reward modeling: Integrating human preferences with verifiable correctness signals for reliable reward systems. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15934--15949, Vienna, Austria, July 2025. Association for Computational Linguistics. ISBN 9798-89176-251-0. doi: 10.18653/v1/2025.acl-long. 775. URL https://aclanthology.org/2025. acl-long.775/.
- 9 Shijie Zhang, Renhao Li, Songsheng Wang, Philipp Koehn, Min Yang, and Derek F. Wong. HiMATE: A hierarchical multi-agent framework for machine translation evaluation. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Findings of the Association for Computational Linguistics: EMNLP 2025, pages 1112111145, Suzhou, China, November 2025. Association for Computational Linguistics. ISBN 979-8-89176335-7. doi: 10.18653/v1/2025.findings-emnlp. 593. URL https://aclanthology.org/2025. findings-emnlp.593/.
- 10 Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better LLM-based evaluators through multi-agent debate. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum? id=FQepisCUWu.
- 11 Weixiang Zhao, Xingyu Sui, Yulin Hu, Jiahe Guo, Haixiao Liu, Biye Li, Yanyan Zhao, Bing Qin, and Ting Liu. Teaching language models to evolve with users: Dynamic profile modeling for personalized alignment. In Proceedings of the Thirty-Ninth Conference on Neural Information Processing Systems (NeurIPS 2025), 2025.
- 12 Shengyuan Ding, Xinyu Fang, Ziyu Liu, Yuhang Zang, Yuhang Cao, Xiangyu Zhao, Haodong Duan, Xiaoyi Dong, Jianze Liang, Bin Wang, Conghui He, Dahua Lin, and Jiaqi Wang. Arm-thinker: Reinforcing multimodal generative reward models with agentic tool use and visual reasoning, 2025.
- 13 Jiaju Chen, Yuxuan Lu, Xiaojie Wang, Huimin Zeng, Jing Huang, Jiri Gesi, Ying Xu, and Dakuo Wang. Multi-agent-as-judge: Aligning LLM-agent-based automated evaluation with multi-dimensional human evaluation. In First Workshop on Multi-Turn Interactions in Large Language Models, 2025. URL https: //openreview.net/forum?id=7AetgL7eVL.
- 14 Yun Wang, Zhaojun Ding, Xuansheng Wu, Siyue Sun, Ninghao Liu, and Xiaoming Zhai. Autoscore: Enhancing automated scoring with multi-agent large language models via structured component recognition. arXiv preprint arXiv:2509.21910, 2025.
- 15 Yucheng Chu, Hang Li, Kaiqi Yang, Harry Shomer, Hui Liu, Yasemin Copur-Gencturk, and Jiliang Tang. A llm-powered automatic grading framework with human-level guidelines optimization. arXiv preprint arXiv:2410.02165, 2024.
- 16 Wenjing Xie, Juxin Niu, Chun Jason Xue, and Nan Guan. Grade like a human: Rethinking automated assessment with large language models. arXiv preprint arXiv:2405.19694, 2024.
- 17 Rui Sun, Zuo Bai, Wentao Zhang, Yuxiang Zhang, Li Zhao, Shan Sun, and Zhengwen Qiu. Finresearchbench: A logic tree based agent-as-a-judge evaluation framework for financial research agents. In Proceedings of the 6th ACM International Conference on AI in Finance, pages 656--664, 2025.
- 18 Fengbin Zhu, Xiang Yao Ng, Ziyang Liu, Chang Liu, Xianwei Zeng, Chao Wang, Tianhui Tan, Xuan Yao, Pengyang Shao, Min Xu, et al. Findeepresearch: Evaluating deep research agents in rigorous financial analysis. arXiv preprint arXiv:2510.13936, 2025.
- 19 Zichen Chen, Jiaao Chen, Jianda Chen, and Misha Sra. Standard benchmarks fail -- auditing llm agents in finance must prioritize risk, 2025. URL https://arxiv.org/abs/2502.15865 (https://arxiv.org/abs/2502.15865).
- 20 Zichen Chen, Jianda Chen, Jiaao Chen, and Misha Sra. From tasks to teams: A risk-first evaluation framework for multi-agent llm systems in finance. In ICML 2025 Workshop on Reliable and Responsible Foundation Models, 2025.
- 21 Zhitao He, Pengfei Cao, Chenhao Wang, Zhuoran Jin, Yubo Chen, Jiexin Xu, Huaijun Li, Kang Liu, and Jun Zhao. Agentscourt: Building judicial decisionmaking agents with court debate simulation and legal knowledge augmentation. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 9399--9416, 2024.
- 22 Prathamesh Devadiga, Omkaar Jayadev Shetty, and Pooja Agarwal. Samvad: A multi-agent system for simulating judicial deliberation dynamics in india. arXiv preprint arXiv:2509.03793, 2025.
- 23 Cong Jiang and Xiaolei Yang. Agentsbench: A multiagent llm simulation framework for legal judgment prediction. Systems, 13(8):641, 2025.
- 24 Zhenxuan Zhang, Kinhei Lee, Weihang Deng, Huichi Zhou, Zihao Jin, Jiahao Huang, Zhifan Gao, Dominic C. Marshall, Yingying Fang, and Guang Yang. Gema-score: Granular explainable multiagent score for radiology report evaluation. CoRR, abs/2503.05347, March 2025. URL https://doi. org/10.48550/arXiv.2503.05347.
- 25 Hengguan Huang, Songtao Wang, Hongfu Liu, Hao Wang, and Ye Wang. Benchmarking large language models on communicative medical coaching: a dataset and a novel system. In Findings of the Association for Computational Linguistics ACL 2024, pages 1624--1637, 2024.
- 26 Zhihao Fan, Lai Wei, Jialong Tang, Wei Chen, Wang Siyuan, Zhongyu Wei, and Fei Huang. Ai hospital: Benchmarking large language models in a multiagent medical interaction simulator. In Proceedings of the 31st International Conference on Computational Linguistics, pages 10183--10213, 2025.
- 27 Jifang Wang, Xue Yang, Longyue Wang, Zhenran Xu, Yiyu Wang, Yaowei Wang, Weihua Luo, Kaifu Zhang, Baotian Hu, and Min Zhang. A unified agentic framework for evaluating conditional image generation. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12626--12646, Vienna, Austria, July 2025. Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long.620. URL https:// aclanthology.org/2025.acl-long.620/.
- 28 Fan Zhang, Shulin Tian, Ziqi Huang, Yu Qiao, and Ziwei Liu. Evaluation agent: Efficient and promptable evaluation framework for visual generative models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7561--7582, Vienna, Austria, July 2025. Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long.374. URL https:// aclanthology.org/2025.acl-long.374/.
- 29 Alimohammad Beigi, Bohan Jiang, Dawei Li, Tharindu Kumarage, Zhen Tan, Pouya Shaeri, and Huan Liu. Lrq-fact: Llm-generated relevant questions for multimodal fact-checking. arXiv preprint arXiv:2410.04616, 2024. URL https://arxiv. org/abs/2410.04616.
- 30 Elad Levi and Ilan Kadar. Intellagent: A multi-agent framework for evaluating conversational ai systems. arXiv preprint arXiv:2501.11067, 2025.
- 31 Navid Madani and Rohini Srihari. ESC-judge: A framework for comparing emotional support conversational agents. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 16059--16076, Suzhou, China, November 2025. Association for Computational Linguistics. ISBN 979-889176-332-6. doi: 10.18653/v1/2025.emnlp-main. 811. URL https://aclanthology.org/2025. emnlp-main.811/.
- 32 Bang Zhang, Ruotian Ma, Qingxuan Jiang, Peisong Wang, Jiaqi Chen, Zheng Xie, Xingyu Chen, Yue Wang, Fanghua Ye, Jian Li, et al. Sentient agent as a judge: Evaluating higher-order social cognition in large language models. arXiv preprint arXiv:2505.02847, 2025.
- 33 Jingoo Lee, Kyungho Lim, Young-Chul Jung, and Byung-Hoon Kim. Psyche: A multi-faceted patient simulation framework for evaluation of psychiatric assessment conversational agents. arXiv preprint arXiv:2501.01594, 2025.
- 34 Hongzhan Lin, Yang Deng, Yuxuan Gu, Wenxuan Zhang, Jing Ma, See-Kiong Ng, and Tat-Seng Chua. FACT-AUDIT: An adaptive multi-agent framework for dynamic fact-checking evaluation of large language models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 360--381, Vienna, Austria, July 2025. Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long.17. URL https:// aclanthology.org/2025.acl-long.17/.
- 35 Sarfraz Ahmad, Hasan Iqbal, Momina Ahsan, Numaan Naeem, Muhammad Ahsan Riaz Khan, Arham Riaz, Muhammad Arslan Manzoor, Yuxia Wang, and Preslav Nakov. UrduFactCheck: An agentic factchecking framework for Urdu with evidence boosting and benchmarking. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Findings of the Association for Computational Linguistics: EMNLP 2025, pages 2278822802, Suzhou, China, November 2025. Association for Computational Linguistics. ISBN 979-8-89176335-7. doi: 10.18653/v1/2025.findings-emnlp. 1240. URL https://aclanthology.org/ 2025.findings-emnlp.1240/.
- 36 Yeonseok Jeong, Minsoo Kim, Seung-won Hwang, and Byung-Hak Kim. Agent-as-judge for factual summarization of long narratives. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 23602 23619, Suzhou, China, November 2025. Association for Computational Linguistics. ISBN 979-889176-332-6. doi: 10.18653/v1/2025.emnlp-main. 1204. URL https://aclanthology.org/ 2025.emnlp-main.1204/.
- 37 Azim Ospanov, Zijin Feng, Jiacheng Sun, Haoli Bai, Xin Shen, and Farzan Farnia. Hermes: Towards efficient and verifiable mathematical reasoning in llms, 2025. URL https://arxiv.org/ abs/2511.18760.
- 38 Jiuzhou Han, Wray Buntine, and Ehsan Shareghi. VerifiAgent: a unified verification agent in language model reasoning. In Findings of the Association for Computational Linguistics: EMNLP 2025, 2025.
- 39 Shudong Liu, Hongwei Liu, Junnan Liu, Linchen Xiao, Songyang Gao, Chengqi Lyu, Yuzhe Gu, Wenwei Zhang, Derek F. Wong, Songyang Zhang, and Kai Chen. CompassVerifier: A unified and robust verifier for LLMs evaluation and outcome reward. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 33454--33482, Suzhou, China, November 2025. Association for Computational Linguistics. ISBN 979-889176-332-6. doi: 10.18653/v1/2025.emnlp-main. 1698. URL https://aclanthology.org/ 2025.emnlp-main.1698/.
- 40 Ding Chen, Qingchen Yu, Pengyuan Wang, Wentao Zhang, Bo Tang, Feiyu Xiong, Xinchi Li, Minchuan Yang, and Zhiyu Li. xverify: Efficient answer verifier for reasoning model evaluations. arXiv preprint arXiv:2504.10481, 2025.
- 41 Shalev Lifshitz, Sheila A McIlraith, and Yilun Du. Multi-agent verification: Scaling test-time compute with multiple verifiers. arXiv preprint arXiv:2502.20379, 2025.
- 42 Kexin Huang, Ying Jin, Ryan Li, Michael Y Li, Emmanuel Candes, and Jure Leskovec. Automated hypothesis validation with agentic sequential falsifications. In Proceedings of the 42nd International Conference on Machine Learning, 2025.
- 43 Hongliu Cao, Ilias Driouich, Robin Singh, and Eoin Thomas. Multi-agent llm judge: automatic personalized llm judge design for evaluating natural language generation applications, 2025.
- 44 Reshmi Ghosh, Tianyi Yao, Lizzy Chen, Sadid Hasan, Tianwei Chen, Dario Bernal, Huitian Jiao, and HM Hossain. Sageval: The frontiers of satisfactory agent based nlg evaluation for reference-free openended text. arXiv preprint arXiv:2411.16077, 2024.
- 45 Jiatao Li, Mao Ye, Cheng Peng, Xunjian Yin, and Xiaojun Wan. Agent-x: Adaptive guideline-based expert network for threshold-free ai-generated text detection. arXiv preprint arXiv:2505.15261, 2025.
- 46 Michael J. Ryan, Omar Shaikh, Aditri Bhagirath, Daniel Frees, William Held, and Diyi Yang. SynthesizeMe! inducing persona-guided prompts for personalized reward models in LLMs. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025.
- 47 Ran Xu, Jingjing Chen, Jiayu Ye, Yu Wu, Jun Yan, Carl Yang, and Hongkun Yu. Incentivizing agentic reasoning in llm judges via tool-integrated reinforcement learning, 2025.
- 48 Mingchen Zhuge, Changsheng Zhao, Dylan R. Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, Yangyang Shi, Vikas Chandra, and Jürgen Schmidhuber. Agent-as-ajudge: Evaluate agents with agents. In Forty-second International Conference on Machine Learning, 2025.
- 49 Mengdi Li, Guanqiao Chen, Xufeng Zhao, Haochen Wen, Shu Yang, and Di Wang. Persrm-r1: Enhance personalized reward modeling with reinforcement learning, 2025.
- 50 Anikait Singh, Sheryl Hsu, Kyle Hsu, Eric Mitchell, Stefano Ermon, Tatsunori Hashimoto, Archit Sharma, and Chelsea Finn. FSPO: Few-shot preference optimization of synthetic preference data elicits LLM personalization to real users. In 2nd Workshop on Models of Human Feedback for AI Alignment, 2025.
- 51 Xinchen Wang, Pengfei Gao, Chao Peng, Ruida Hu, and Cuiyun Gao. Codevisionary: An agent-based framework for evaluating large language models in code generation, 2025.
- 52 Yu Li, Shenyu Zhang, Rui Wu, Xiutian Huang, Yongrui Chen, Wenhao Xu, Guilin Qi, and Dehai Min. Mateval: A multi-agent discussion framework for advancing open-ended text evaluation. In Database Systems for Advanced Applications: 29th International Conference, DASFAA 2024, Gifu, Japan, July 2-5, 2024, Proceedings, Part VII, page 415--426, Berlin, Heidelberg, 2024. Springer-Verlag. ISBN 978-981-97-5574-5. doi: 10. 1007/978-981-97-5575-2_31. URL https://doi. org/10.1007/978-981-97-5575-2_31.
- 53 Manya Wadhwa, Zayne Rea Sprague, Chaitanya Malaviya, Philippe Laban, Junyi Jessy Li, and Greg Durrett. Evalagents: Discovering implicit evaluation criteria from the web. In Second Conference on Language Modeling, 2025. URL https: //openreview.net/forum?id=erGpkHCybv.
- 54 Kaishuai Xu, Tiezheng Yu, Yi Cheng, Wenjun Hou, Liangyou Li, Xin Jiang, Lifeng Shang, Qun Liu, and Wenjie Li. Learning to align multi-faceted evaluation: A unified and robust framework. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Findings of the Association for Computational Linguistics: ACL 2025, pages 9488--9502, Vienna, Austria, July 2025. Association for Computational Linguistics. ISBN 979-889176-256-5. doi: 10.18653/v1/2025.findings-acl. 494. URL https://aclanthology.org/2025. findings-acl.494/.
- 55 MohammadHossein Rezaei, Robert Vacareanu, Zihao Wang, Clinton Wang, Bing Liu, Yunzhong He, and Afra Feyza Akyürek. Online rubrics elicitation from pairwise comparisons. arXiv preprint arXiv:2510.07284, 2025.
- 56 Zhaopeng Feng, Jiayuan Su, Jiamei Zheng, Jiahan Ren, Yan Zhang, Jian Wu, Hongwei Wang, and Zuozhu Liu. M-MAD: Multidimensional multiagent debate for advanced machine translation evaluation. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7084--7107, Vienna, Austria, July 2025. Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long.351. URL https:// aclanthology.org/2025.acl-long.351/.
- 57 Jiamin Su, Yibo Yan, Zhuoran Gao, Han Zhang, Xiang Liu, and Xuming Hu. Cafes: A collaborative multi-agent framework for multigranular multimodal essay scoring. arXiv preprint arXiv:2505.13965, 2025.
- 58 Sandeep Kumar, Abhijit A Nargund, and Vivek Sridhar. Courteval: A courtroom-based multi-agent evaluation framework. In Findings of the Association for Computational Linguistics: ACL 2025, pages 2587525887, 2025.
- 59 Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: NLG evaluation using gpt-4 with better human alignment. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 25112522, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023. emnlp-main.153. URL https://aclanthology. org/2023.emnlp-main.153/.
- 60 Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, et al. Prometheus: Inducing fine-grained evaluation capability in language models. In The Twelfth International Conference on Learning Representations, 2023.
- 61 Lianghui Zhu, Xinggang Wang, and Xinlong Wang. JudgeLM: Fine-tuned large language models are scalable judges. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=xsELpEPn4A.
- 62 Yougang Lyu, Shijie Ren, Yue Feng, Zihan Wang, Zhumin Chen, Zhaochun Ren, and Maarten de Rijke. Self-adaptive cognitive debiasing for large language models in decision-making, 2025. URL https:// arxiv.org/abs/2504.04141.
- 63 Huan-ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Yiran Wu, et al. A survey of self-evolving agents: On path to artificial super intelligence. arXiv preprint arXiv:2507.21046, 2025.
- 64 Mahnaz Koupaee, Jake W. Vincent, Saab Mansour, Igor Shalyminov, Han He, Hwanjun Song, Raphael Shu, Jianfeng He, Yi Nian, Amy Wing-mei Wong, Kyu J. Han, and Hang Su. Faithful, unfaithful or ambiguous? multi-agent debate with initial stance for summary evaluation. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors, Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 12209--12246, Albuquerque, New Mexico, April 2025. Association for Computational Linguistics. ISBN 979-8-89176-189-6. doi: 10.18653/v1/2025. naacl-long.609. URL https://aclanthology. org/2025.naacl-long.609/.
- 65 Taaha Kazi, Ruiliang Lyu, Sizhe Zhou, Dilek Hakkani-Tür, and Gokhan Tur. Large language models as user-agents for evaluating task-orienteddialogue systems. In 2024 IEEE Spoken Language Technology Workshop (SLT), pages 913--920. IEEE, 2024.
- 66 Ning Wu, Ming Gong, Linjun Shou, Shining Liang, and Daxin Jiang. Large language models are diverse role-players for summarization evaluation. In CCF international conference on natural language processing and Chinese computing, pages 695--707. Springer, 2023.