集群这个词.
广义的集群,只要你是多个机器,构成了分布式系统,都可以称为是一个"集群"前面主从结构,哨兵模式,也可以称为是"广义的集群"狭义的集群,redis提供的集群模式.这个集群模式之下,主要是要要解决,存储空间不足的问题(拓展存储空间)
一、为什么需要分片?单节点 Redis 的天花板
在单节点或主从架构下,Redis 面临两个无法回避的瓶颈:
1. 容量瓶颈:单节点的内存容量受限于物理机配置,通常无法超过 256GB,难以支撑大规模业务数据的存储。
2. 性能瓶颈:单节点的读写 QPS 存在上限(约 10 万级),在高并发场景下会出现明显的响应延迟。
分片(Sharding)是解决这些问题的核心方案,它将数据分散存储在多个节点上,实现了水平扩容,让 Redis 集群的容量和性能能够随节点数量线性增长。
二、分片的核心算法:从简单哈希到一致性哈希
1. 简单哈希:最基础的分片方案
简单哈希是最直观的分片实现,核心逻辑是对键的哈希值取模,将键分配到对应节点:
cpp
# 示例:3 个节点的简单哈希
nodes = ["node1", "node2", "node3"]
def get_node(key):
return nodes[hash(key) % 3]-
优点:实现简单,计算速度快。
-
缺点:扩容时会导致大量键的映射关系失效(例如节点数从 3 增加到 4,约 75% 的键需要重新分配),引发"缓存雪崩"风险。
关于MD5
md5本身就是一个计算hash值的算法.针对一个字符串,里面的内容进行一系列的数学变换=>整数.
是一个十六进制的数字。
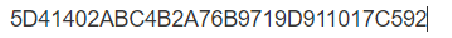
MD5是一个非常广泛使用的hash算法.特点:
- md5计算结果是定长的.
无论输入的原字符串多长,最终算出的结果就是固定长度.
-
md5计算结果是分散的.哈希函数两个原字符串,哪怕大部分都相同,只有一个小的地方不同,算出来的md5值也会差别很大.
-
md5计算结果是不可逆的.加密给你原字符串,可以很容易算出 md5的值.给你md5值,很难还原出原始的字符串的.(理论上是不可行的)
网上的一些md5破解,其实是把一些常见的字符串的md5值,提前算好,保存下来.就按照打表的方式,根据 md5值映射到原字符串.能不能查到,就随缘了.
2. 一致性哈希:解决扩容痛点
一致性哈希通过构建一个虚拟的哈希环(0~2^32-1)来解决简单哈希的扩容问题:
-
节点映射:将每个节点的 IP 或名称哈希到环上的一个位置。
-
键映射:将键哈希到环上的一个位置,然后顺时针找到第一个节点,该节点即为键的存储节点。
-
扩容影响 :新增节点时,仅需重新分配该节点在环上"接管"的部分键,影响范围约为
1/N(N 为原节点数),大幅降低了扩容成本。
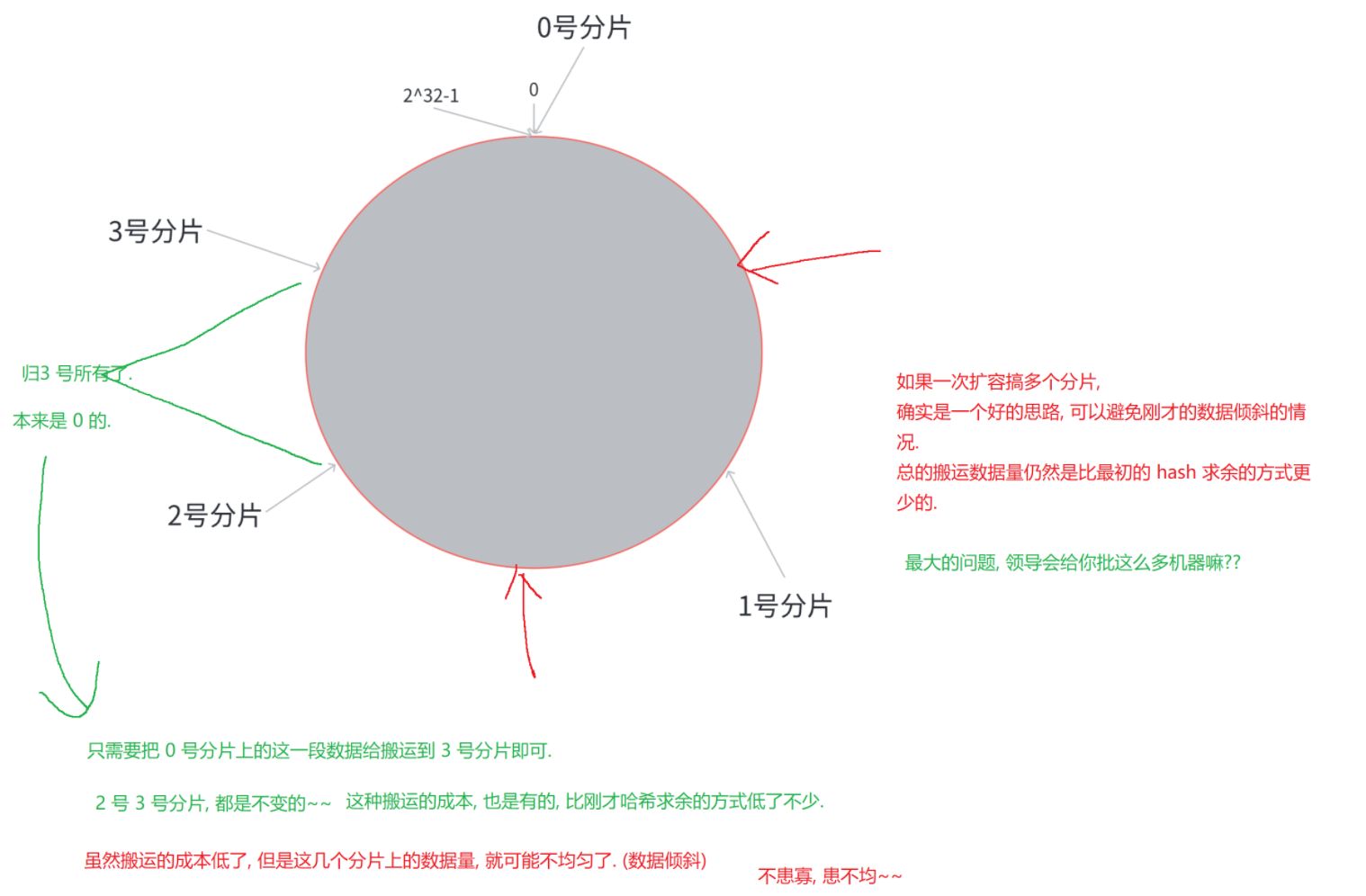
但一致性哈希仍存在数据倾斜问题:当节点数量较少时,哈希环上的节点分布不均,可能导致部分节点存储大量数据。为解决这个问题,引入了虚拟节点机制,为每个物理节点创建多个虚拟节点,让节点在环上分布更均匀。
3. Redis Cluster 的哈希槽:工业级分片方案
Redis Cluster 没有采用一致性哈希,而是设计了**哈希槽(Hash Slot)**机制,这是 Redis 分片的终极方案:
-
哈希槽总数:固定为 16384 个(0~16383)。
-
分片规则 :对每个键执行
CRC16(key) % 16384计算,得到键所属的哈希槽,再将哈希槽分配到对应的主节点。 -
优势:
-
扩容高效:新增节点时,仅需迁移部分哈希槽(而非大量键),迁移过程可平滑进行,不影响业务。
-
数据均匀:哈希槽数量固定,节点间的槽分配可人工干预,避免数据倾斜。
-
运维简单:Redis 提供了成熟的槽迁移工具,支持自动化扩容和缩容。
-
三、基于 Docker 与 Shell 脚本实现 Redis Cluster 自动化部署
手动部署 Redis Cluster 涉及大量重复操作,效率低且易出错。结合 Docker 和 Shell 脚本可以实现集群的自动化部署,大幅提升运维效率。
1. 环境准备
-
安装 Docker 和 Docker Compose。
-
确保宿主机有足够的资源(建议 4C8G 以上)运行 6 个 Redis 节点(3 主 3 从)。
2. 编写自动化部署脚本
创建 deploy-redis-cluster.sh 脚本,实现节点创建、配置生成和集群初始化:
cpp
#!/bin/bash
# 1. 创建数据目录
for i in {1..6}; do
mkdir -p ./data/redis-$i
done
# 2. 生成 Redis 配置文件
for i in {1..6}; do
cat > ./data/redis-$i/redis.conf << EOF
port 6379
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
done
# 3. 启动 Docker 容器
docker-compose up -d
# 4. 等待节点启动
sleep 10
# 5. 初始化集群
docker exec -it redis-1 redis-cli --cluster create \
172.17.0.2:6379 172.17.0.3:6379 172.17.0.4:6379 \
172.17.0.5:6379 172.17.0.6:6379 172.17.0.7:6379 \
--cluster-replicas 1 --cluster-yes
echo "Redis Cluster 部署完成!"3. 编写 Docker Compose 配置
创建 docker-compose.yml 文件,定义 6 个 Redis 节点:
cpp
version: '3'
services:
redis-1:
image: redis:6.2
container_name: redis-1
ports:
- "6379:6379"
- "16379:16379"
volumes:
- ./data/redis-1:/data
command: redis-server /data/redis.conf
redis-2:
image: redis:6.2
container_name: redis-2
ports:
- "6380:6379"
- "16380:16379"
volumes:
- ./data/redis-2:/data
command: redis-server /data/redis.conf
redis-3:
image: redis:6.2
container_name: redis-3
ports:
- "6381:6379"
- "16381:16379"
volumes:
- ./data/redis-3:/data
command: redis-server /data/redis.conf
redis-4:
image: redis:6.2
container_name: redis-4
ports:
- "6382:6379"
- "16382:16379"
volumes:
- ./data/redis-4:/data
command: redis-server /data/redis.conf
redis-5:
image: redis:6.2
container_name: redis-5
ports:
- "6383:6379"
- "16383:16379"
volumes:
- ./data/redis-5:/data
command: redis-server /data/redis.conf
redis-6:
image: redis:6.2
container_name: redis-6
ports:
- "6384:6379"
- "16384:16379"
volumes:
- ./data/redis-6:/data
command: redis-server /data/redis.conf4. 执行部署
bash
# 赋予脚本执行权限
chmod +x deploy-redis-cluster.sh
# 执行部署
./deploy-redis-cluster.sh四、生产环境的运维与优化
1. 监控与告警
通过 Prometheus + Grafana 监控集群的关键指标:
-
节点状态 :
cluster_nodes(节点数量)、cluster_state(集群状态,ok表示正常)。 -
哈希槽分布 :
cluster_slots_assigned(已分配槽数)、cluster_slots_ok(正常槽数)。 -
性能指标 :
redis_commands_processed_total(每秒处理命令数)、redis_memory_used_bytes(内存使用量)。
2. 扩容与缩容
-
扩容 :新增节点后,使用
redis-cli --cluster add-node加入集群,再通过redis-cli --cluster reshard迁移哈希槽。 -
缩容 :先通过
redis-cli --cluster reshard将待删除节点的槽迁移到其他节点,再使用redis-cli --cluster del-node删除节点。
3. 故障排查
-
节点离线 :通过
redis-cli cluster nodes查看节点状态,检查网络连接或资源占用情况。 -
槽迁移失败 :查看节点日志(
docker logs <container-id>),检查迁移过程中的错误信息。 -
数据倾斜 :通过
redis-cli dbsize查看各节点的键数量,若存在倾斜,手动调整哈希槽分配。
五、集群扩容
一旦服务器集群需要扩容,就需要更高的成本了.
分片主要目的就是为了能提高存储能力.
分片越多,能存的数据越多,成本也更高.
1. 哈希求余
一般都是先少搞几个分片. (3个)
但是随着业务逐渐增长,数据变多了。3个分片就已经不足以保存了.
就需要"扩容"
引入新的分片,N就改变了.
hash(key) % N => 0
当hash函数和key都不变的情况下,如果N改变了,整体的分片结果仍然会变!!!
如果发现某个数据,在扩容之后,不应该待在当前的分片中了,就需要重新进行分配(搬运数据)
比处列出的这些值,就可以脑补成hash(key)假设当前计算完hash值之后,得到的数值正好是100-120
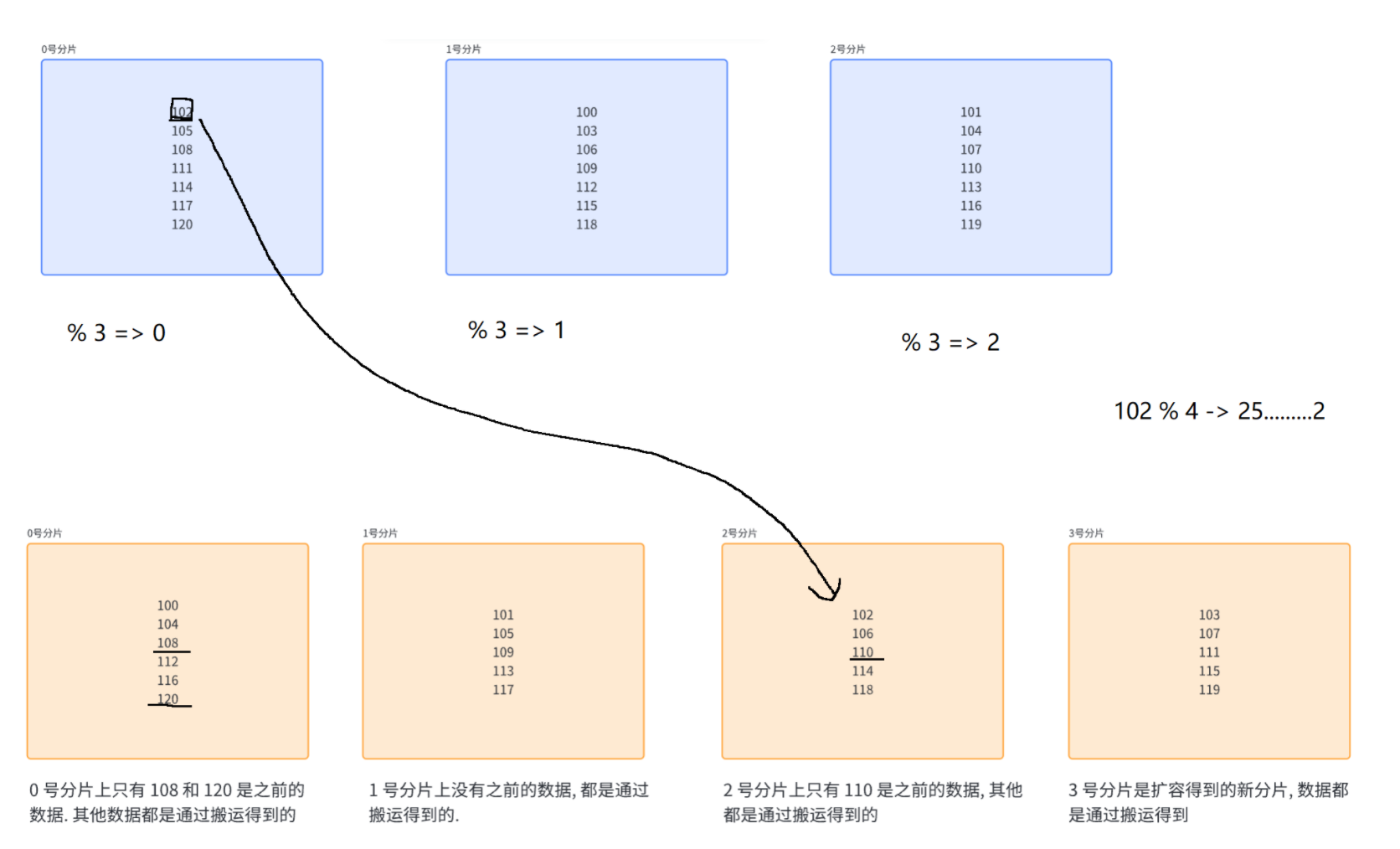
一共20个数据,只有3个数据不需要搬运,搬运了17个数据.
如果是20亿个数据呢??17亿数据就要搬运......这就是一个大活了!!
上述级别的扩容,开销极大的.往往是不能直接在生产环境上操作的.只能通过"替换"的方式来实现扩容。
依赖的机器更多了.成本更高,操作步骤非常复杂!!!
2. 一致性哈希
在hash求余这种操作中,当前key属于哪个分片,是交替的
在一致性哈希这样的设定下,把交替出现,改进成了连续出现

3. 哈希槽分区算法
Redis真正采用的分片算法

这种算法,本质就是把一致性哈希和哈希求余这两种方式结合一下.
会进一步的把上述的这些哈希槽,分配到不同的分片上.
假设当前有三个分片,一种可能的分配方式一
-
0号分片:0,5461,共5462个槽位
-
1号分片:5462,10923,共5462个槽位
-
2号分片:10924,16383,共5460个槽位
虽然不是严格意义的"均匀"差异非常小.
此时这三个分片上的数据就是比较均匀的了.
这里只是一种可能的分片方式.实际上分片是非常灵活的.
每个分片持有的槽位号,可以是连续,也可以是不连续的


在上述过程中,只有被移动的槽位,对应的数据才需要搬运.
针对某个分片,上面的槽位号,不一定非得是连续的区间.
redis中,当前某个分片包含哪些槽位都是可以手动配置的.
问题一:Redis 集群是最多有16384 个分片吗?
每个分片上就只有一个槽位. 此时很难保证数据在各个分片上的均衡性
有的槽位可能是 有多个key
有的槽位可能是 没有key
key是要先映射到槽位,再映射到分片的.
如果每个分片包含的槽位比较多,如果槽位个数相当,就可以认为是包含的key数量相当的.
如果每个分片包含的槽位非常少,槽位个数不一定能直观的反应到key的数目.
实际上Redis 的作者建议集群分片数不应该超过 1000.
如果真是1.6w 个分片,整个数据服务器的集群规模就太可怕了.
几万台主机构成的集群了.整个集群的可用性是非常堪忧的!!
问题二:为什么是16384个槽位?
心跳包中包含了该节点持有哪些slots.
这个值个数上基本够用了.同时占用的硬件资源(网络带宽)又不是很大.
需要表示出该节点持有哪些槽位.
虽然8kb比2kb也大不了多少.但是心跳包,周期性通信的.(非常频繁&吃网络带宽)
六、总结
Redis 分片是支撑大规模业务的核心技术,从简单哈希到一致性哈希,再到 Redis Cluster 的哈希槽,技术演进的目标始终是提升扩容效率和数据分布的均匀性。结合 Docker 和 Shell 脚本可以实现集群的自动化部署,大幅降低运维成本。在生产环境中,需要持续监控集群状态,优化配置和部署方式,才能保证 Redis 集群的稳定运行。