前言
以前做过的休闲回合制游戏的用的分层式分布式架构(只介绍分服/区域服架构)
这章主要来聊下这个分层式分布式架构(支持20W CCU,DAU 过100W)
本章 讲述的相关技术实现
1:基本架构
基本的业务服务 都支持水平伸缩
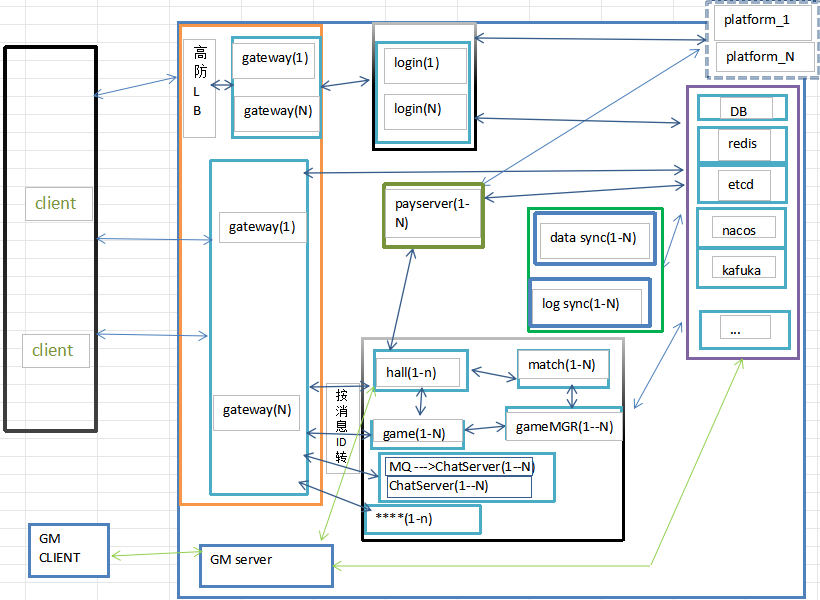
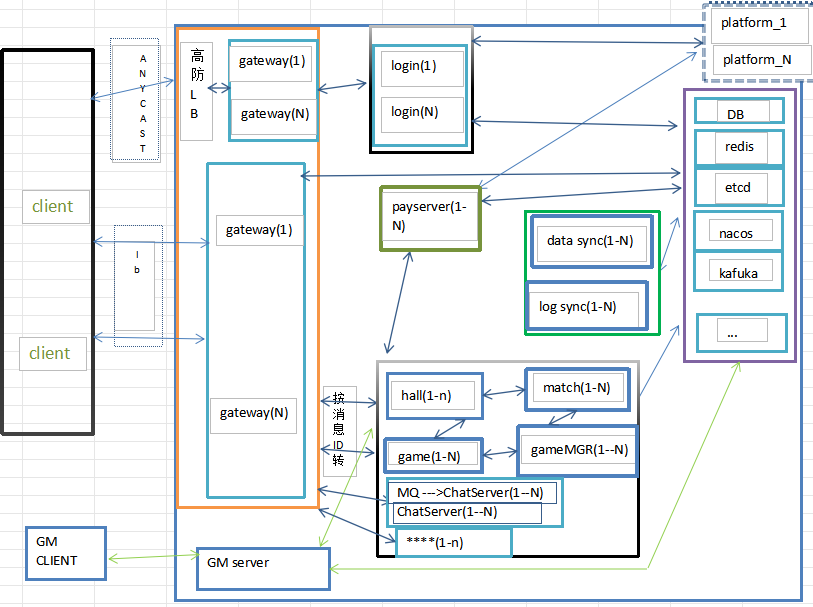
需要就近接入 参数前面2章相关内容, 增加anycast eip, 防攻击 长链接的gateway 前也加高仿LB
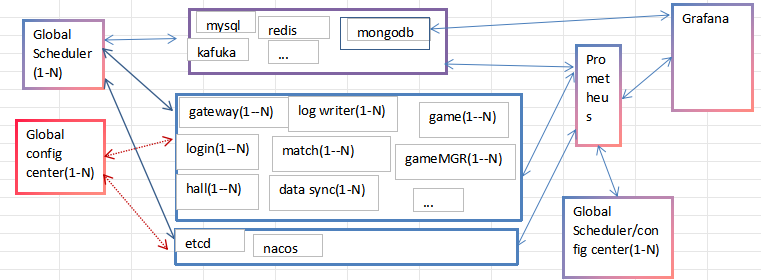
全局调度/配置中心 、资源使用情况及有限查询(少量可以Grafana 直接查db,其他参考后面的) 单独列出
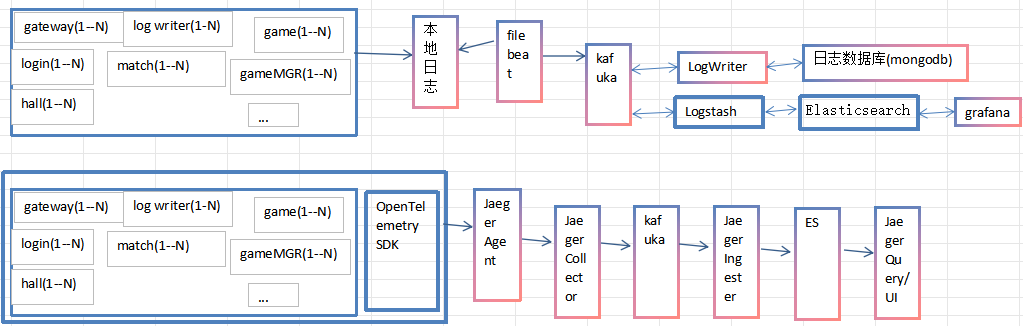
日志查询 搜索 检索及落库(需要增加kafka,ES等)
链路日志,一般不需要落库(根据实际业务 决定用不用Jaeger)
角色上线加载及落库过程
2:层次
1>接入层(access layer)
高仿LB
gateway(短链接,长连接)
2> 逻辑层(logic layer)
(1)账号与登录
login
(2)玩家核心业务
hall game match gamemanager
(3)运营与资金
gm server payserver
3> 公共服务层(common service layer)
(1)通用业务支撑
datasync 数据同步服务
msgwriter 消息/日志落库服务
(2)底层中间件
etcd/nacos 服务注册与发现
nacos 配置中心
kafka 消息队列
(3)平台管控服务
Global Scheduler 全局调度中心
Global config center 全局配置中心
服务发现 链路、监控、告警 限流、熔断、降级
4> 数据层(data layer)
redis mysql mongodb
clickhouse
文件(parquet/csv/json) (parquet 大数据文件,其他小数据文件)
2: 两条消息链路
1> 短链接
client<--->LB<--->gateway<--->login
2> 长链接
client<--->gateway<--->hall
client<--->gateway<--->hall<--->match<--->gamemgr<--->game
client<--->gateway<--->game
client<--->gateway<--->game--->hall--->gateway
client<--->gateway<--->hall<--->payserver
3:登录过程
重点:
IP 限流(防暴刷、防攻击)
黑名单 + TTL(超限直接拉黑一段时间)
Redis 全局防重复校验(同一个 token 只让一台网关去第三方)
Redis 缓存结果(有效 / 无效)+ 短 TTL(避免重复验)
1>高仿LB 自带监控
带宽、连接数、QPS、丢包、健康检查状态等都有。
2>gateway (无状态)主要是 做所有流量控制、熔断、限流、黑白名单、鉴权、路由
需要共享的数据可以通过redis 定时拉取/订阅更新
3>login(无状态) 处理登录校验 等待型
失败:给客户端相应消息
成功:选择 一个合适的 gateway 及TOKEN 给客户端(其他account,ACCOUNTID)
4>防攻击
无效token 加入缓存(类试防缓存穿透),单位 时间内 N个TOKEN 请求登录,加入black单,限制登录(N时间)
4: 进入游戏
slot id<---> hallid eg:1<--->hall1 2<--->hall1 3<--->hall1 10000<--->hallN
accountId % 16384 = 槽号 → hallId → ip+port
重复登录,挤号 ,换角色 只需要在同一个hall上处理就可以了,比用userid 方便
槽号 对应 hall, 这个可以用redis 主从+哨兵 (用redis话,最好单独,不用跟任何过期策略的混搭),也可以自己写 更简洁更稳,就是一点,高可用,不需要存档,
故障转移或恢复后 可以由全局调度中心 处理
踢人 挤号 redis 及hall 大厅缓存里各存一份 db也留一份, gateway 产生uuid(「服务类型 + 机器 ID + 时间戳 + 自增」) 关联 socket
key: online:{account_id}
value:
user_id: yyy # 你的游戏角色ID
hall_id: zzz # 大厅服ID
gateway_id: ggg # 网关ID
session_uuid: sss # 踢人用
踢人 通过hall 发消息 到指定gatway 踢掉UUID的socket链接
同时 可以保存玩家数据
挤人 ,如果是同一个角色,只需要 更新gatewayid session_uuid,把当前玩家数据给新链接发一份就行, 不是同一角色,就是踢人,保存数据,拉新角色数据.
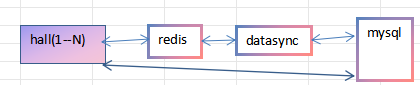
5:角色上线加载及落库过程
上线加载 先查redis 没有 查mysql ,查到回写redis
落库过程 都用lua执行保持原子性,先更新redis 及脏标志位,版本号,把uid 扔 set(去重) 及 list(先后顺序),datasync 从list 取uid, 根据脏标志位去redis 查询 user_base,user_task,user_bag 等 拉取并清除脏标志位及set 去掉uid
最后写入库
6:日志查询 搜索 检索及落库
按流程来就可以了,写得很明白了,kafka 一般5个topic(充值,玩家行为,全链路,服务日志,warn/error)
充值 玩家行为 写本地文件 进入es 同时落库
全链路,服务日志,warn/error 写本地文件 并进ES
7:全局调度/配置中心 单独列出
注册与发现 可以基于etcd sdk(eg:go zero),配置中心 可以基于nacos sdk(eg:go zero) 进行开发 最少是主从
调度中心几乎连所有:业务服务 + DB、Redis、Kafka、ETCD 全都管;
配置中心只连业务,不连基础中间件(除了ETCD,NACOS)
ETCD 服务注册与发现
NACOS 配置中心
只作有限日志查询 及prometheus拉取的数据
看服务的资源及业务指标(提供接口供prometheus拉取)
8:全链路tracer
写本地文件->filebeat->kafka->Logstash->es->AlertManager(告警系统)
es->Grafana
1>正常采样
一般1%--5% 采样
2>核心链路
全量采样
3>异常、错误、超时
某节以后 全量采样 主要给AlertManager(告警系统)
单独topic
traceID 64 bit
机器 ID:8 位(0~255)
业务类型:4 位(0~15)
时间戳:34 位(秒级 / 毫秒级都能用几十年)
自增序号:18 位(最多 26 万 / 毫秒)
spanId 用「服务类型 + 机器 ID + 时间戳 + 自增」
一条链路日志,必须有的最小字段
生产可用、排查问题必带的 5 个:
traceId整条链路唯一 ID,网关生成,全程不变。
spanId当前这段调用的 ID,每段新生成。
parentSpanId父调用的 spanId,用来串成调用树。
serviceName / module哪个服务 / 模块打的日志。
timestamp + level + message时间、日志级别、内容。
简单的 可以自行 搞定
复杂的用Jaeger 更稳妥
业务 OpenTelemetry SDK → Jaeger Agent → Jaeger Collector → Kafka → Jaeger Ingester → ES → Jaeger Query/UI
1)采集层(游戏服侧)
游戏后端:接入 Jaeger /OpenTelemetry SDK
每台游戏服起一个 Jaeger Agent(Sidecar / 本机进程)
Agent 做:批量上报、UDP/grpc 接收、限流
2)收集层
集群:Jaeger Collector 3~5 实例
作用:校验、格式化、写入 Kafka
不直接写 ES
3)缓冲层(关键)
Kafka Topic:jaeger-spans
建议分区:12~24 个(看 ES 写入能力)
保留 1~3 天即可
4)入库层
Jaeger 自带 ingester 组件(从 Kafka 读 → 写入 ES)
可多实例水平扩展
5)存储 & 查询
存储:Elasticsearch(6.8/7.x 最稳)
查询:Jaeger Query
UI:Jaeger UI
9:角色数据 redis 手动LRU
角色数据实时同步到redis, 通过datasync 异步 进程 ,多改合一/增量更新 同步到DB
把角色信息 N张表 因为每次更新,只会更新关联的表,所以不能全量存一起
但是角色信息 又是一个整体,要么全在,有么全不在,不能出现部分在的情况
user:base:{uid}
user:bag:{uid}
user:task:{uid}
。。。。。。。
1> 用ttl过期的问题
如果用ttl 过期,要么更新任何一张表,其他表的TTL 也同步更新,不然会出现 部分表过期的问题
2>解决方案
玩家所有模块 key(不过期)
一个 ZSet:
key = user:lru:zset
score = 最后更新时间戳
member = uid
ZADD user:lru:zset 1736947200 10001 自动覆盖
清理为用LUA 删除角色所有的表,必须是原子
(1)时间策略(兜底) 假定ttl 为24小时
只要玩家最后更新时间戳 超过 24 小时(86400 秒)
不管内存够不够,直接清理
目的:防止冷数据永远占内存
(2)内存策略(紧急)
Redis 内存占用 > 70%(70%可以自行调整,这里只是推荐)
不管有没有到 24 小时
直接从 ZSet 拿最老的一批清理
目的:防止 Redis 爆掉
3> 基础数据里增加version 防止倒灌
版本号只有一个,全局唯一
存在基础数据里
任何子模块(背包、任务、成就)改动
→ 都让 version++
全局单版本号,任何改动必自增;
同步只许高版本覆盖低版本,永不回写。
10: match 匹配规则
按星级 比如 1-10 match1* 处理 11-20 match2* 处理 21-30 match3* 处理 以正负2星 匹配4人队伍
星级 范围 按实际情况处理
hall->match set uid list uid
eg:1-10星 直接扔match11 12 *** match1* 最小2个
match11 list len<300 处理 1-299 数据
match12 list >=300 处理 300-599 数据 当数据长度 小于300,空闲,watch match11的健康状态,故障时,接手match11 从1-599 全处理
规则 接手自身前一个点的故障点,match11 match12 match13 match11 环形 逆时针
类试 一致性哈希(环 + 顺时针) + 虚拟节点(每台机器配多个)
match12 故障时 match11 从1-599 全处理
规则 watch 自身 前个的实例及前实例接管的实例
组队
从list 拿出N个 uid ,以第一个作为基点,以lua 方式执行 组对,判定 是否在线,星级等
找到,删除队成员UID,同时删除set 成员ID,通知gamemgr 创建房间 ,返回给hall 房间相关信息,再通知客户端
11:如果觉得有用,麻烦点个赞,加个收藏