一位Transformer架构的发明者正在远离自己曾经开创的领域,警告行业避免重蹈RNN被彻底淘汰的覆辙,与此同时,全球科技巨头们每年投入千亿美元维持这个庞大却性能增长日渐式微的系统。
"深度语言模型是超级数据学习者",这是2025年《Diffusion Language Models are Super Data Learners》研究论文的核心观点,揭示在高质量数据日益稀缺的背景下,新架构可能在重复利用有限数据方面具有独特优势。这一发现直接挑战了当前大模型持续扩大规模和数据需求的演进路径。
当RNN曾是序列建模的主流架构时,研究人员也在不断尝试改进它的门控单元和训练方式,但这些努力最终被Transformer架构的革命性突破彻底颠覆。今天,同样的历史周期可能正在重演。
重力井效应:被成功束缚的AI发展
Llion Jones,Transformer架构八位共同发明者之一,近期做出了一个让行业震惊的决定:大幅减少对Transformer相关研究的投入。他直言自己已成为"成功的受害者",当前研究已经陷入了"重力井"效应。
"就像有一个巨大的'重力井',所有尝试离开的新方法都会被拉回来。"Jones描述的是当前AI研究的困境。即使研究人员创造出了效果优于Transformer的新架构,只要行业巨头们继续将Transformer模型规模扩大十倍,新架构的优势就会被迅速抵消。
这种现象与历史上的RNN替代过程惊人相似。在Transformer出现之前,研究人员也致力于优化RNN架构,将语言建模性能从1.26比特/字符微调到1.25比特/字符。而当深度解码器Transformer应用于相同任务时,性能立刻跃升至1.1比特/字符,使所有先前研究瞬间过时。
现实问题显而易见:Transformer生态系统已过于成熟,从训练方法、微调技术到软件工具一应俱全。除非新架构能够展现出"碾压式"优势,否则整个行业不会放弃已有投入。但正是这种成熟性,将AI研究牢牢锁在局部最优解中。
技术演进:从循环神经网络到注意力革命
回顾AI技术发展历程,我们可以清晰地看到一条为解决序列依赖问题而不断演进的路径。RNN首次将时序概念引入神经网络,使模型能够处理序列数据,但它无法有效捕捉长距离依赖。
为了解决这一问题,LSTM和GRU应运而生,它们通过门控机制控制信息流动,但仍未摆脱串行计算的根本限制。
真正的革命始于2017年谷歌发布的《Attention Is All You Need》论文。Transformer抛弃了循环结构,引入自注意力机制,将"排队识字"变成"量子阅读",让模型能够同时处理整个序列。
我绘制了从RNN到Transformer这一关键的AI架构演进路径图:
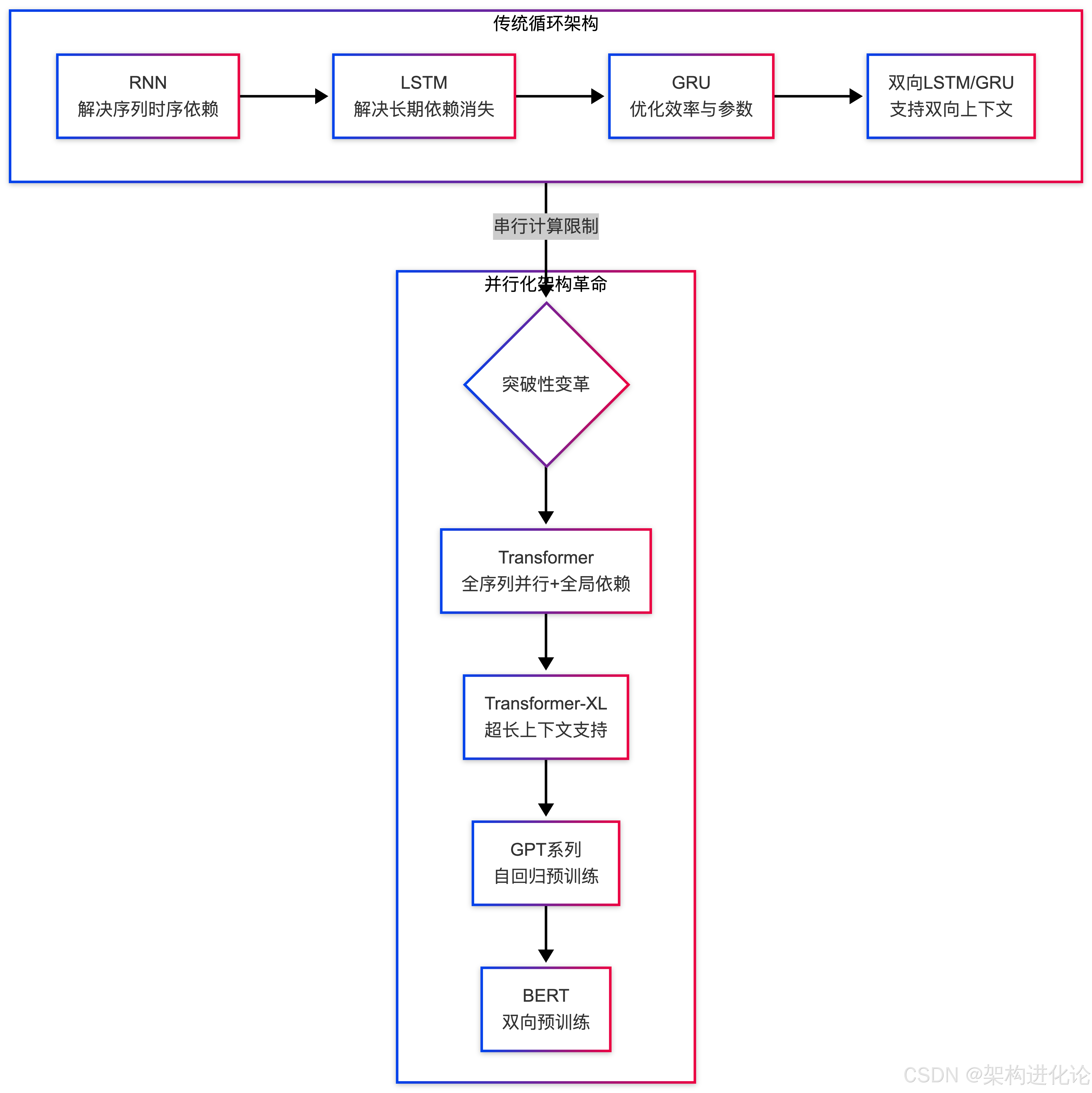
这样的技术跃迁解决了循环架构的串行计算问题,却也开启了新的瓶颈。
Transformer的核心------自注意力机制,其计算复杂度随着序列长度呈二次方增长,这意味着更长的上下文需要指数级增加的计算资源。
更令人担忧的是,如Jones所指出的,大语言模型呈现"锯齿状智能"特性:它们可能在某个任务上表现出博士级水平,却在另一项简单任务上犯下小学生级别的错误。这种不稳定性揭示了当前架构中存在根本性问题。
代码解剖:注意力机制的内在局限
要理解Transformer架构的根本限制,我们需要深入其核心代码实现。下面是一个简化的自注意力机制实现,它揭示了该架构的计算复杂性问题:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class ScaledDotProductAttention(nn.Module):
"""缩放点积注意力机制实现"""
def __init__(self, d_k, dropout=0.1):
super().__init__()
self.d_k = d_k # 键向量的维度
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value, mask=None):
"""
注意力计算核心过程
参数:
query: 查询张量,形状(batch_size, num_heads, seq_len_q, d_k)
key: 键张量,形状(batch_size, num_heads, seq_len_k, d_k)
value: 值张量,形状(batch_size, num_heads, seq_len_v, d_v)
mask: 可选的遮罩张量
返回:
注意力输出和注意力权重
"""
# 计算查询和键的点积
# 复杂度:O(seq_len_q * seq_len_k * d_k)
# 这是二次方复杂度的来源!
scores = torch.matmul(query, key.transpose(-2, -1))
# 缩放点积,防止梯度消失
scores = scores / math.sqrt(self.d_k)
# 应用遮罩(如因果遮罩)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 计算注意力权重
attention_weights = F.softmax(scores, dim=-1)
# 应用dropout正则化
attention_weights = self.dropout(attention_weights)
# 应用注意力权重到值张量
# 复杂度:O(seq_len_q * seq_len_v * d_v)
output = torch.matmul(attention_weights, value)
return output, attention_weights
class MultiHeadAttention(nn.Module):
"""多头注意力机制实现"""
def __init__(self, d_model, num_heads, dropout=0.1):
super().__init__()
assert d_model % num_heads == 0, "d_model必须能被num_heads整除"
self.d_model = d_model # 模型维度
self.num_heads = num_heads # 注意力头数
self.d_k = d_model // num_heads # 每个头的维度
# 线性变换层
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
self.attention = ScaledDotProductAttention(self.d_k, dropout)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
# 线性变换并分割为多个头
Q = self.W_q(query).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_k(key).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_v(value).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 计算注意力
attention_output, attention_weights = self.attention(Q, K, V, mask)
# 合并多头输出
attention_output = attention_output.transpose(1, 2).contiguous().view(
batch_size, -1, self.d_model
)
# 最终线性变换
output = self.W_o(attention_output)
return output, attention_weights
# 计算复杂度分析示例函数
def analyze_complexity(seq_length):
"""
分析不同序列长度下的计算复杂度
参数:
seq_length: 输入序列的长度
返回:
无,直接打印复杂度分析结果
"""
# Transformer注意力机制的计算复杂度
attention_complexity = seq_length ** 2
# 内存复杂度
memory_complexity = seq_length ** 2
# 实际的现代优化版本(如稀疏注意力)的复杂度
optimized_complexity = seq_length * math.log(seq_length)
print(f"序列长度: {seq_length}")
print(f"标准注意力计算复杂度: O(n²) = {attention_complexity}")
print(f"内存需求(注意力矩阵): {memory_complexity} 元素")
print(f"优化注意力(稀疏)复杂度: O(n log n) ≈ {optimized_complexity:.2f}")
print(f"优化带来的加速比: {attention_complexity / optimized_complexity:.2f}倍")
print("-" * 50)
# 示例:不同序列长度的复杂度对比
if __name__ == "__main__":
seq_lengths = [128, 512, 2048, 8192, 32768] # 常见序列长度
print("注意力机制计算复杂度对比分析:")
print("=" * 50)
for length in seq_lengths:
analyze_complexity(length)这段代码揭示了几个关键问题:首先,注意力机制的核心torch.matmul(query, key.transpose(-2, -1))行具有O(seq_len²)的复杂度,当处理长文档时计算成本急剧增加。
其次,注意力矩阵需要存储所有词对之间的关联强度,这导致内存需求也呈二次方增长。这些限制在AI应用日益需要处理更长上下文(如分析整个代码库或处理长篇文档)时变得尤为突出。
效率困境:算力需求与性能收益的严重失衡
随着模型规模的增长,AI训练和推理的算力需求呈指数级上升,但性能提升幅度却逐渐放缓。加州大学伯克利分校研究人员在2026年的报告中警告,当前Transformer架构正遭遇"行为崩溃":随着任务复杂性增加,最先进的模型也难以展现真正的推理能力,而是退回到基于训练数据的模式跟随或概率猜测。
这一问题在金融层面尤为突出。全球AI基础设施投资已接近惊人的1.5万亿美元,但2023-2024年出现的推理和可靠性突破性进展已基本消失。
科技巨头们的资本支出已经达到前所未有的水平:微软2026年单季度资本支出达349亿美元(同比增长74%),而Alphabet的年度支出已接近1000亿美元大关。
问题的核心在于Transformer架构的二次复杂度特性,这意味着随着模型处理更大信息集,能量和计算成本呈指数增长,而输出的边际效用却趋于平缓。结果是:万亿参数模型比其前代产品昂贵得多,但准确性和可靠性仅有个位数百分点的提升。
以下是当前主流大模型架构的演进与效率对比:

扩散语言模型在这一背景下展现出独特潜力,它们能够以相对快速且低廉的成本生成标记,因为与自回归模型"逐字"串行生成不同,扩散模型采用并行生成方式。
这种并行性在处理长序列时提供了显著的效率优势,但也带来了工具调用集成的挑战:扩散模型同时生成整个响应,难以在中间插入外部工具的交互步骤。
新范式探索:超越规模法则的AI发展路径
面对Transformer架构的局限性,研究社区正在积极探索多种替代方案。其中,连续思维机是受生物学启发的创新架构之一。
它模仿大脑神经元通过同步振荡传递信息的方式,使用神经动力学作为核心表示,让模型在"内部思维维度"上逐步展开计算。虽然不完全追求生物学可行性,但这种思路为研究提供了全新的可能性。
扩散语言模型在处理有限数据时展现出独特优势。研究表明,当进行多轮训练时,文本扩散模型的表现可能优于标准的自回归大语言模型。
这是因为扩散模型可以学习文本中任意位置之间的依赖关系,而自回归模型被迫只能从左到右学习。随着高质量文本数据日益稀缺,这一特性变得尤其重要。
《Diffusion Language Models are Super Data Learners》论文发现,当数据量充足时,自回归模型学习得更快;但当数据受限时,扩散语言模型最终胜出。对于扩散模型而言,验证集损失的上升并不一定意味着下游能力的下降------即便模型在验证集上看起来"过拟合"了,它在实际任务(如代码生成、推理)上的表现仍可能继续提升。
学术界对当前发展模式提出警示。Stuart Russell等伯克利专家警告,AI行业可能进入严重调整期,一个巨大的"AI泡沫"已经形成,其特点是资本支出飙升与大语言模型性能明显停滞之间存在危险脱节。
为了避免全面崩溃,研究人员呼吁行业从单体扩展转向"复合AI系统",这些系统专注于系统级工程------使用多个专业模型、检索系统(RAG)和多智能体编排,以实现比单个巨型模型更好的结果。
未来之路:后Transformer时代的AI架构革命
后Transformer架构正逐步进入主流视野,旨在突破当前技术的效率壁垒。像Mamba(选择性状态空间模型)和液态神经网络等架构因其能够以线性扩展处理海量数据集而获得关注,使其对企业使用更具成本效益。(扩展阅读:Transformer 是未来的技术吗?)
这些发展表明,AI近期未来将由"智慧"而非"规模"来定义。未来两年的挑战将是从"暴力扩展"过渡到"架构创新"。
从企业应用角度看,特定领域语言模型和多智能体系统正成为2026年的关键趋势。95%的企业AI投资未能兑现价值,问题主要不在于模型本身,而在于落地方法。
特定领域语言模型通过企业专属数据微调,能够精准适配行业需求,相比通用大模型有明显优势。Gartner预测,到2028年,企业使用的生成式AI模型中超过半数将是特定领域语言模型。
多智能体系统则解决了"AI干大事"的难题,通过"分而治之"的逻辑,将复杂目标拆解为子任务,由不同角色的智能体协同完成。这种模式不仅提升效率,更降低了单一智能体故障带来的风险,成为大型企业复杂业务自动化的最优解。
算力架构也在发生根本性变化,混合计算成为主流趋势。这种混合体现在两个维度:算力类型混合(CPU、GPU、AI ASIC各司其职)和算力调度混合(量子计算负责核心运算,传统算力协助纠错)。
2026年,算力竞争的核心将从"训练速度"转向"推理效率",推动ASIC芯片在推理场景的普及,加速算力向边缘端下沉。
未来AI架构的竞争正从单纯追求规模转向平衡性能、效率和专业性的多维竞争。当DeepSeek可以用低于硅谷厂商20%的训练成本实现同等推理性能时,全球大模型API价格被压到近乎免费。
这种趋势预示着AI发展正在进入一个更注重实用性和可持续性的新阶段。