一、核心原理:海量数据导致数据库变慢的原因与解决思路
1. 底层原因
数据库增删改查的本质是查找数据,一次查询的耗时由两个固定因素 + 一个可变因素决定:
- 固定因素:查找算法、存储数据结构(由数据库引擎实现,业务层无法修改)
- 可变因素:数据总量(唯一可由业务层优化的点)
2. 关键结论
MySQL InnoDB 存储引擎采用B + 树 作为存储结构,查找算法为树查找,时间复杂度固定为O(log n) ,因此解决海量数据性能问题的核心是减少单表数据总量。
3. 核心解决方案
拆分数据,分为两种策略(面试需区分二者优先级):
- 归档历史数据 (首选方案):将冷数据迁移至独立存储,保留热数据在原库,代码改动量极小
- 分库分表(次选方案):将单表数据拆分至多个库 / 表,适合热数据本身已达到海量的场景
4. 订单数据的特性:热尾效应
订单数据是带时间属性的时序数据 ,符合热尾效应:最近产生的数据(热数据)访问频率极高,超过一定时间的数据(冷数据)几乎很少被访问(如京东仅近 3 个月订单为热数据)。
二、订单数据归档实现:架构与核心流程
1. 归档整体设计思路
- 保留规则:MySQL 原库仅保留3 个月热数据,超过 3 个月的冷数据迁移至独立存储(本文选用 MongoDB)
- 业务影响:仅需修改查询统计类代码(按时间范围选择原库 / 历史存储查询),订单创建、支付、退款等核心业务逻辑无需改动
- 分表匹配:按每月 2000W 订单、平均 10 个商品 / 订单计算,3 个月冷数据迁移后,原库 32 个分表的单表数据量约 2000W,达到最优性能阈值。
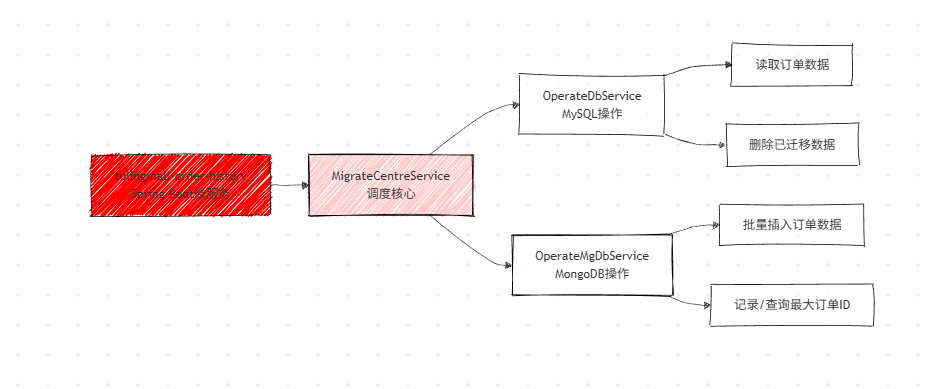
2. 归档服务核心架构(tulingmall-order-history)
该服务为 Java 微服务,核心包含3 个 Service 接口 + 实现类,职责单一且解耦,符合 Spring Boot 微服务设计规范。
核心 Service 职责划分
| 服务接口 | 实现类 | 核心职责 |
|---|---|---|
| MigrateCentreService | MigrateCentreServiceImpl | 归档调度核心,协调 MySQL 读取、MongoDB 写入、原库删除的整体流程 |
| OperateDbService | OperateDbServiceImpl | 操作 MySQL:读取指定范围的订单数据、删除已迁移的冷数据 |
| OperateMgDbService | OperateMgDbServiceImpl | 操作 MongoDB:批量插入迁移的订单数据、记录每次迁移的最大订单 ID、查询历史最大 ID |
服务架构图
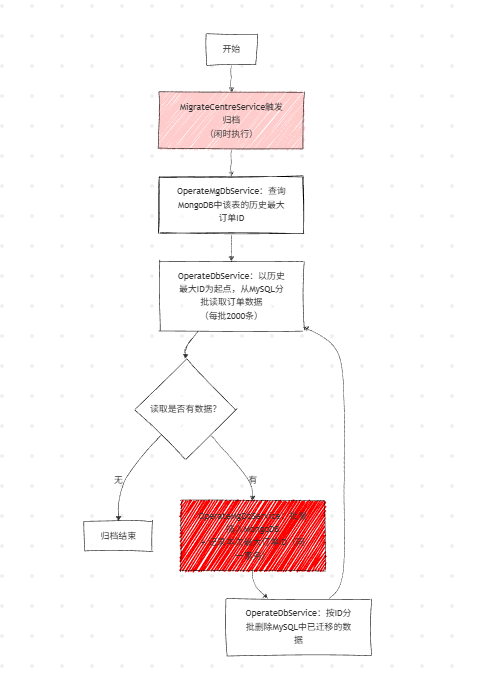
3. 归档核心执行流程
核心原则 :按订单 ID分批迁移,基于 MongoDB 记录的历史最大 ID 作为每次迁移的起始点,保证数据不重不漏。
归档流程图
4. 归档实施的关键注意事项
- 执行时间 :选择业务低峰期(如凌晨)执行,避免影响线上 MySQL 性能
- 分批操作 :MySQL 每次读取 / 删除的记录数控制在10000 条以内(本文默认 2000 条),防止大事务锁表
- 数据备份 :迁移前必须对 MySQL 订单数据做全量备份,防止误操作导致数据丢失
- 存储选择:历史数据存储可选用 MySQL/MongoDB/ES 等,根据业务查询需求选择(MongoDB 适合非结构化 / 海量时序数据,ES 适合全文检索)
三、批量操作:海量数据的批量删除实现
1. 批量删除的核心原则(面试高频)
订单数据按时间 筛选迁移,但按主键 ID执行删除,而非按时间删除,原因是 InnoDB 的 B + 树按主键组织,主键查询的效率远高于时间字段(即使时间字段建索引)。
2. 高效批量删除的实现方案
(1)核心 SQL 语句(按主键 ID 范围删除)
DELETE FROM ${orderTableName} o
WHERE o.id >= #{minOrderId} AND o.id <= #{maxOrderId}
ORDER BY id;(2)SQL 优化的底层原因
- 主键筛选:InnoDB 的 B + 树按主键有序组织,主键范围查询的时间复杂度为 O (log n),无需额外索引
- 按 ID 排序 :ID 连续的记录在磁盘物理文件上相邻存储,删除时 MySQL 的页回收效率更高,减少 B + 树碎片
- 分批删除:每次删除一个小的 ID 范围(如 2000 条),避免大事务导致的锁表和数据库负载飙升
3. 批量删除的额外优化点
- 删除后停顿 :执行完一批删除后,暂停一段时间(如 100ms),让 MySQL 完成B + 树页面的分裂与合并,均衡数据库负载
- 避免级联删除 :订单表与订单详情表尽量采用逻辑外键(而非数据库物理外键),删除订单时手动删除详情表数据,防止级联删除导致的大事务
- 禁用触发器:删除前禁用订单表的触发器,避免触发器执行额外逻辑,降低删除效率
4. 批量删除 vs 直接删除
| 操作方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 按 ID 分批删除 | 效率高、无锁表、负载低 | 需分批遍历 ID 范围,代码稍复杂 | 海量数据删除(千万级 +) |
| 按时间直接删除 | 代码简单、一步执行 | 时间索引查询效率低、易锁表、负载高 | 少量数据删除(万级以内) |
| truncate 表 | 效率最高(直接清空表) | 无法按条件删除、不可回滚、会重置自增 ID | 清空整表且无历史数据 |