Chain of Mindset:让AI学会像人一样"切换脑回路"
一句话总结:把推理拆成四种思维模式(空间/收敛/发散/算法),用元代理动态调度,实现了免训练的步级自适应推理。
📖 从"一根筋"到"多线程"
你有没有遇到过这种情况:
做数学题时,先在脑子里画图想象(空间思维),然后列公式推导(收敛思维),发现卡住了就换个思路试试(发散思维),最后用计算器验证(算法思维)。
人类解决问题从来不是"一根筋"------我们会根据问题的进展,动态切换不同的"脑回路"。
但现有的LLM推理方法却陷入了"单一思维陷阱":
| 方法 | 思维模式 | 问题 |
|---|---|---|
| Chain of Thought | 线性推理 | 所有步骤都是同一套路 |
| Tree of Thoughts | 分支探索 | 每个节点都用同样的思考方式 |
| ReAct | 行动-观察循环 | 反思模式固定 |
这就像让一个学生只用"刷题"这一种方法学所有科目------数学可能还行,但遇到几何题需要画图、遇到作文需要发散思维时,就抓瞎了。
这就是**Chain of Mindset (CoM)**要解决的核心问题。
🔍 CoM框架:三层解耦架构
整体设计
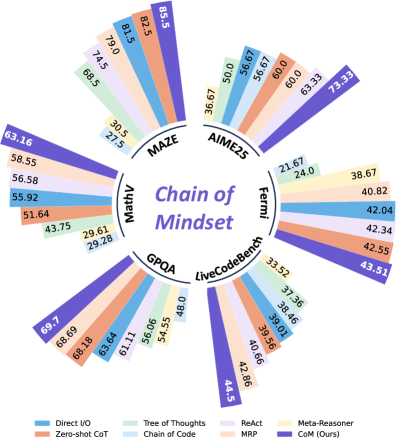
图1:CoM的三层解耦架构。Meta-Agent作为中央控制器,管理四种思维专家模块,双向Context Gate控制信息流。
CoM采用"决策与执行分离"的设计:
┌─────────────────────────────────────────────────────┐
│ Meta-Agent │
│ (元认知决策:决定"怎么思考",而不是"思考什么") │
└─────────────────┬───────────────────────────────────┘
│ <cognitive_decision>
▼
┌─────────────────────────────────────────────────────┐
│ Context Gate (双向门控) │
│ Input Gate: 过滤输入 Output Gate: 蒸馏输出 │
└─────────────────┬───────────────────────────────────┘
│
┌─────────────┼─────────────┬─────────────┐
▼ ▼ ▼ ▼
┌───────┐ ┌───────┐ ┌───────┐ ┌───────┐
│Spatial│ │Conver-│ │Diver- │ │Algori-│
│ │ │gent │ │gent │ │thmic │
└───────┘ └───────┘ └───────┘ └───────┘
空间思维 收敛思维 发散思维 算法思维四种思维模式详解
1. 空间思维(Spatial Mindset)
用途:将抽象问题可视化
能力:
- 生成文本描述的图像(DALL-E等)
- 图像编辑
- 用Matplotlib代码绘图
适用场景:
- 几何问题:画图理解空间关系
- 物理问题:可视化力学分析
- 费米估算:通过比例图理解隐喻
示例:
问题:如果太阳是人的头,它的手臂有多长?
Spatial Mindset 输出:
[生成人体比例图]
发现:手臂长度约为头部的3.5倍2. 收敛思维(Convergent Mindset)
用途:聚焦的逻辑分析,单步深度推理
能力:
- 基于既定事实进行推导
- 消除歧义和矛盾
- 执行精确的逻辑判断
适用场景:
- 数学证明:从已知条件推导结论
- 消除语义歧义
- 整合多个信息源
示例:
问题:确认"头部大小"的定义
Convergent Mindset 输出:
根据上下文,"头部大小"应理解为:
- 太阳的半径(而非直径)
- 价值:696,340 km3. 发散思维(Divergent Mindset)
用途:生成多个并行候选方案,打破推理僵局
能力:
- 生成多种解题思路
- 探索不同假设分支
- 发现非显而易见的解决方案
适用场景:
- 遇到推理瓶颈时
- 需要创新解法的问题
- 开放性问题
示例:
问题:卡在某个计算步骤
Divergent Mindset 输出:
方案A:换元法
方案B:几何法
方案C:反证法
选择方案B继续...4. 算法思维(Algorithmic Mindset)
用途:精确数值计算和验证
能力:
- 生成Python代码
- 执行代码获取结果
- 错误检测和修复
适用场景:
- 大数运算
- 复杂公式计算
- 需要精确验证的场景
示例:
python
# Algorithmic Mindset 执行
result = 3.5 * 696340 # 手臂长度 = 3.5 * 太阳半径
print(f"太阳手臂长度:{result} km")
# 输出:2,437,190 kmMeta-Agent:元认知决策中心
Meta-Agent不直接解决问题,而是回答一个更高层级的问题:"现在应该怎么思考?"
工作循环:
- Plan(规划):分析当前问题状态,制定思维序列
- Call(调用) :通过
<call_mindset>激活特定模块 - Internalize(内化):吸收输出门蒸馏的关键信息
这就像一个项目经理:不亲自写代码、画图、测试,而是决定"下一步该找谁来做"。
Context Gate:双向信息过滤
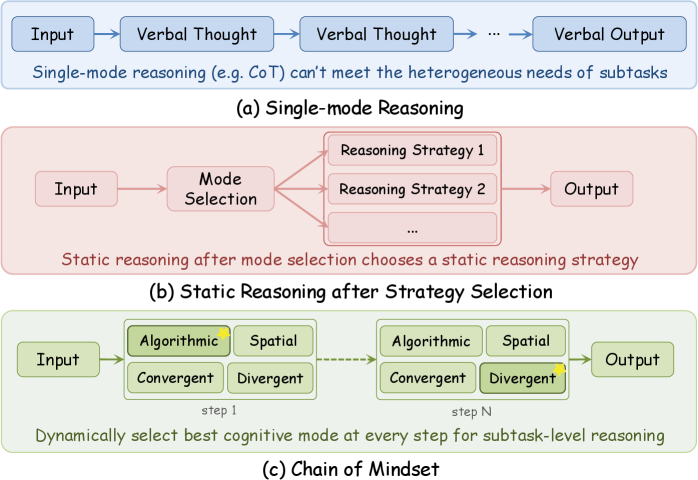
图2:Context Gate的双向过滤机制。输入门提取最小充分上下文,输出门将冗长输出蒸馏为简洁摘要。
为什么需要Context Gate?
考虑这个场景:
- 空间思维生成了详细的图像描述(1000 tokens)
- 这些信息传给算法思维时,大部分是噪音
- 算法思维只需要知道"手臂=3.5×头部"
输入门(Input Gate):
- 从历史记录中提取最小且充分的相关上下文
- 减少无关信息干扰
输出门(Output Gate):
- 将思维模块的冗长输出蒸馏为简洁的
<insight>摘要 - 只保留关键结论传回Meta-Agent
这个设计解决了**"相关性-冗余权衡"**问题:既要传递足够信息,又要避免上下文污染。
📊 实验结果:全面碾压
主要结果对比
论文在6个极具挑战性的基准上测试:
| 基准 | 类型 | 难度 |
|---|---|---|
| AIME 2025 | 数学竞赛 | 极高 |
| Real-Fermi | 费米估算 | 高 |
| LiveCodeBench | 代码生成 | 高 |
| GPQA-Diamond | 科学问答 | 高 |
| MathVision | 多模态几何 | 中-高 |
| MAZE | 迷宫导航 | 中 |
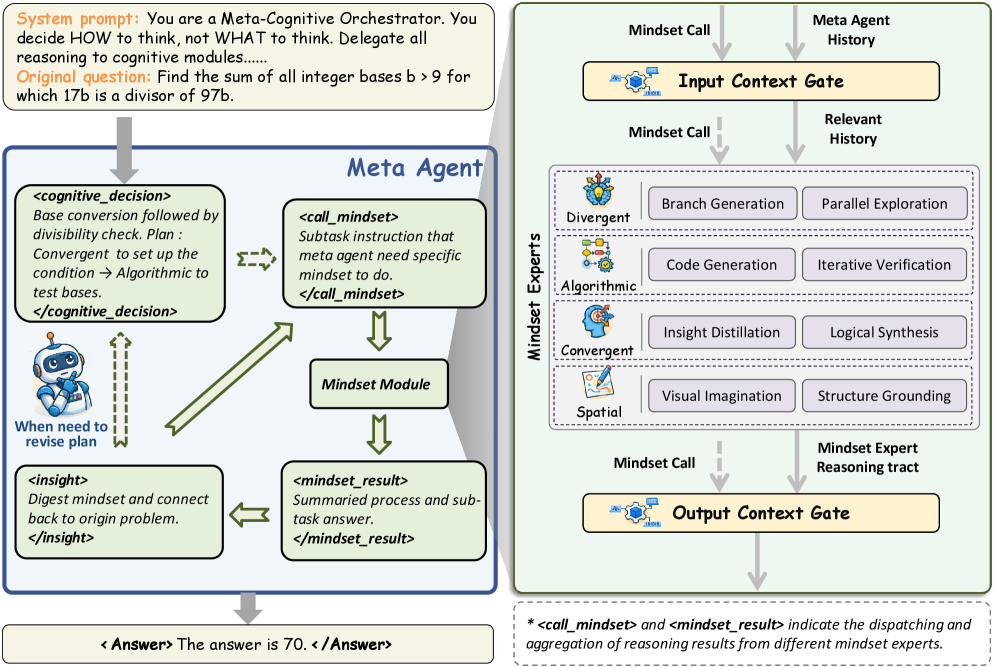
图3:CoM与其他方法在六个基准上的性能对比。CoM(蓝色)在几乎所有任务上都取得领先。
Qwen3-VL-32B-Instruct上的结果:
| 方法 | AIME25 | Fermi | Code | GPQA | MathVision | MAZE | 总体 |
|---|---|---|---|---|---|---|---|
| Direct I/O | 56.67 | 42.04 | 39.01 | 63.64 | 55.92 | 81.50 | 56.46 |
| Zero-shot CoT | 60.00 | 42.55 | 39.56 | 68.18 | 51.64 | 82.50 | 57.41 |
| Tree of Thoughts | 50.00 | 24.00 | 37.36 | 56.06 | 43.75 | 68.50 | 46.61 |
| ReAct | 63.33 | 42.34 | 40.66 | 61.11 | 56.58 | 74.50 | 56.42 |
| MRP | 60.00 | 40.82 | 42.86 | 68.69 | 58.55 | 79.00 | 58.32 |
| CoM (Ours) | 73.33 | 43.51 | 44.50 | 69.70 | 63.16 | 85.50 | 63.28 |
关键发现:
-
AIME 2025:73.33%,比次优方法高出10个百分点!这是美国数学邀请赛,难度极高。
-
MAZE:85.50%,迷宫导航需要空间想象和路径规划,CoM的空间思维优势明显。
-
整体:63.28%,比最强基线MRP高4.96个百分点。
消融实验:每个组件都很重要
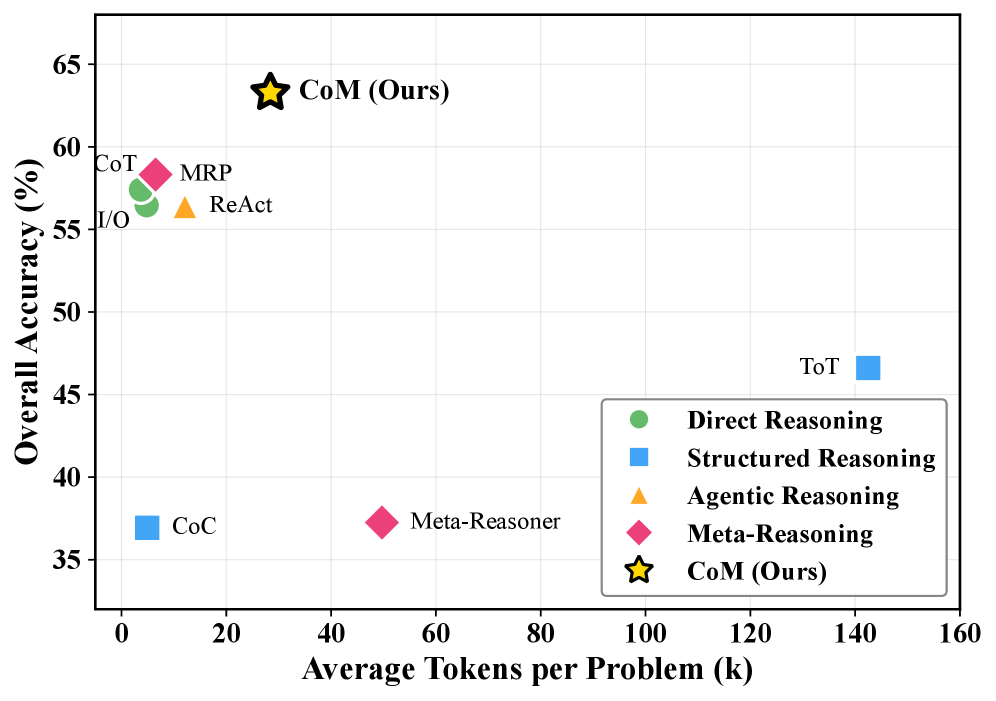
图4:移除不同组件后的性能变化。Context Gate影响最大(-8.24%),发散思维对数学问题至关重要。
Context Gate的影响:
- 移除后整体准确率下降 8.24%
- Token消耗增加 87%
- 说明信息过滤对防止干扰至关重要
发散思维的影响:
- 移除后AIME25准确率暴跌 16.66%
- 证明多路径探索对复杂数学问题至关重要
- 这就像考试遇到难题时,只会一种方法的学生容易被卡住
空间思维的影响:
- 移除后MathVision下降 9.87%
- MAZE下降 4.50%
- 视觉模态对空间任务是不可替代的
效率与准确率的平衡
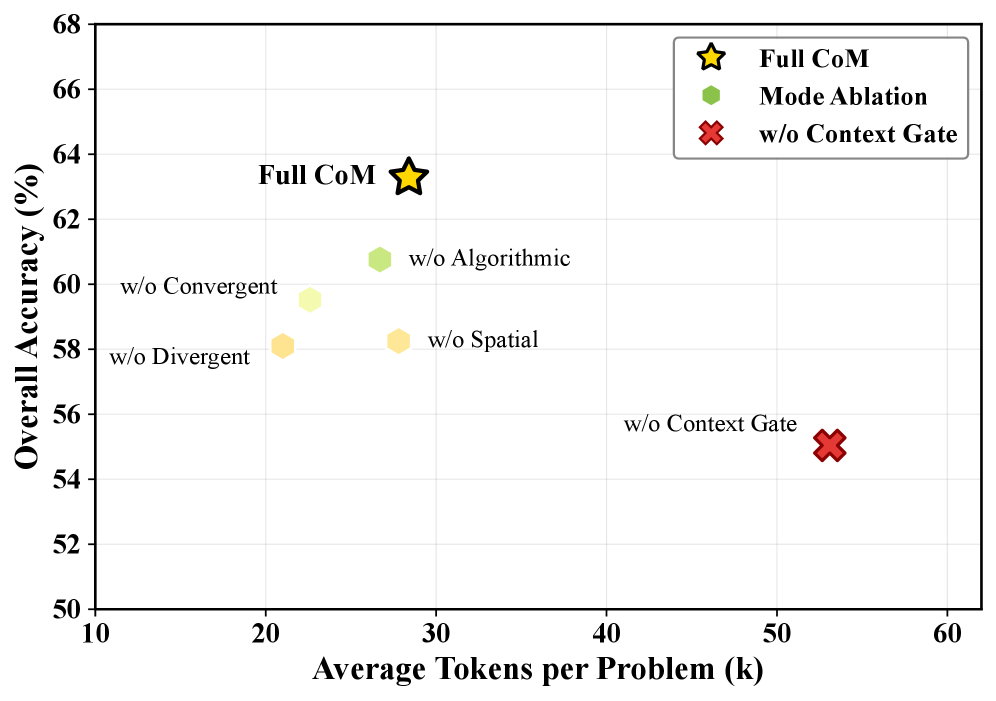
图5:准确率与Token消耗的帕累托前沿。CoM以适中的代价(28.4k tokens)实现了最高的准确率(63.28%)。
| 方法 | 准确率 | Token消耗 | 性价比 |
|---|---|---|---|
| Direct I/O | 56.46% | 2.1k | 高效率,低效果 |
| Zero-shot CoT | 57.41% | 8.7k | 中等 |
| Tree of Thoughts | 46.61% | 142.5k | 效率极低 |
| CoM | 63.28% | 28.4k | 最优平衡 |
CoM位于帕累托前沿:用适中的代价换取最高的准确率。
Tree of Thoughts虽然也是多路径方法,但消耗了142.5k tokens,是CoM的5倍,效果却更差。这说明盲目的分支探索不如智能的模式切换。
🧠 案例分析:费米问题的完整推理过程
图6:费米估算问题的完整推理过程。CoM展示了空间→收敛→算法的思维切换过程。
问题:"如果太阳是人的头,它的手臂有多长?"
Step 1: Spatial Mindset(空间思维)
[生成人体比例图]
分析:通过可视化人体比例
发现:手臂长度约为头部的3.5倍Step 2: Convergent Mindset(收敛思维)
问题:什么是"头部大小"?
可能性A:太阳直径 = 1,392,700 km
可能性B:太阳半径 = 696,340 km
分析上下文...
结论:头部大小通常指"头的高度",对应半径
确定:头部大小 = 696,340 kmStep 3: Algorithmic Mindset(算法思维)
python
# 精确计算
arm_length = 3.5 * 696340
print(f"太阳手臂长度 = {arm_length} km")
# 输出:2,437,190 km最终答案:如果太阳是人的头,它的手臂大约有2,437,190公里长。
这个案例完美展示了CoM的核心思想:不同阶段需要不同的思维方式。空间思维建立直觉,收敛思维消除歧义,算法思维精确计算。
💡 我的观点和启发
为什么CoM比ToT强?
Tree of Thoughts和Chain of Mindset都是"多路径"方法,但效果差异巨大。原因在哪?
ToT的问题:
- 每个节点用同样的思考方式
- 盲目分支,缺少针对性
- 信息冗余,上下文爆炸
CoM的优势:
- 不同问题阶段用不同思维模式
- 针对性地选择"武器"
- Context Gate过滤冗余信息
用一个类比:
- ToT像是一个只会"穷举法"的学生,每道题都试所有方法
- CoM像是一个经验丰富的老师,知道几何题要画图、代数题要列公式、估算题要验证
"思维模式"的本质是什么?
读完论文,我对"思维模式"有了新的理解:
思维模式 = 任务分解策略 + 工具集 + 输出格式
| 思维模式 | 分解策略 | 工具集 | 输出格式 |
|---|---|---|---|
| 空间 | 视觉化 | 图像生成、Matplotlib | 图像+描述 |
| 收敛 | 线性推导 | 逻辑推理 | 结论+证据 |
| 发散 | 并行分支 | 多假设生成 | 候选方案集 |
| 算法 | 可执行步骤 | Python解释器 | 代码+结果 |
这个视角很有启发性:思维模式不是玄学,而是工程化的推理模块。
Context Gate的设计哲学
Context Gate解决了多模块协作中的核心问题:如何在不让上下文爆炸的前提下,保持模块间的有效通信?
论文的设计思路值得借鉴:
- 输入端:只传递"最小充分"的信息
- 输出端:将冗长输出"蒸馏"为关键结论
- 决策端:Meta-Agent只看到高层摘要,不陷入细节
这让我想到项目管理中的"汇报原则":
- 给CEO的汇报应该是1页摘要,不是50页详情
- 细节由中层消化,只传关键结论
局限性和未来方向
论文也指出了几个局限:
- 依赖基础模型能力:如果基础模型在某方面很弱,相应的思维模块也发挥不出来
- 调度策略可优化:Meta-Agent的决策目前基于规则,可能不是最优的
- 成本仍然较高:虽然比ToT高效,但Token消耗仍是Direct I/O的13倍
我认为几个值得探索的方向:
方向1:学习最优调度策略
目前的调度基于规则(如"遇到几何问题调用空间思维")。是否可以用强化学习训练Meta-Agent,学习最优的调度策略?
方向2:动态思维模式组合
四种模式是否足够?是否可以定义更细粒度的思维模式?或者根据任务动态组合新的思维模式?
方向3:跨模态思维迁移
空间思维用图像,算法思维用代码。是否可以设计"表格思维"、"网络思维"等其他模态的思维模式?
🔧 实践指南:如何实现自适应思维推理
核心代码架构
python
from dataclasses import dataclass
from typing import Literal, List, Dict
from enum import Enum
class MindsetType(Enum):
SPATIAL = "spatial" # 空间思维
CONVERGENT = "convergent" # 收敛思维
DIVERGENT = "divergent" # 发散思维
ALGORITHMIC = "algorithmic" # 算法思维
@dataclass
class CognitiveDecision:
"""元认知决策"""
mindset: MindsetType
reason: str # 为什么选择这个思维模式
context_needed: List[str] # 需要哪些上下文
@dataclass
class MindsetOutput:
"""思维模块输出"""
insight: str # 关键结论(蒸馏后)
detail: str # 详细输出
confidence: float
class MetaAgent:
"""元智能体:决定"怎么思考" """
def decide(self, problem_state: Dict) -> CognitiveDecision:
"""根据问题状态决定下一步思维模式"""
prompt = f"""
当前问题状态:{problem_state}
请决定下一步应该使用哪种思维模式:
- SPATIAL:需要可视化、画图
- CONVERGENT:需要聚焦逻辑推理
- DIVERGENT:需要探索多种可能
- ALGORITHMIC:需要精确计算或代码执行
输出格式:
<cognitive_decision>
mindset: [选择模式]
reason: [选择理由]
context_needed: [需要的上下文]
</cognitive_decision>
"""
# 调用LLM解析决策
return self._parse_decision(llm.generate(prompt))
class MindsetExpert:
"""思维专家模块"""
SYSTEM_PROMPTS = {
MindsetType.SPATIAL: """
你擅长空间思维。请通过生成图像或代码绘图来可视化问题。
输出格式:
1. 图像描述或绘图代码
2. 从图像中得出的关键发现
<insight>关键结论</insight>
""",
MindsetType.CONVERGENT: """
你擅长收敛思维。请基于既定事实进行聚焦的逻辑分析。
消除歧义,推导确定性的结论。
<insight>关键结论</insight>
""",
MindsetType.DIVERGENT: """
你擅长发散思维。请生成多个并行的候选解决方案。
探索不同的可能性,打破思维僵局。
<insight>最有前景的方案</insight>
""",
MindsetType.ALGORITHMIC: """
你擅长算法思维。请生成Python代码来精确计算或验证。
代码将实际执行,结果用于决策。
<insight>计算结果</insight>
"""
}
def execute(self, mindset: MindsetType, context: str) -> MindsetOutput:
"""执行指定思维模式"""
prompt = self.SYSTEM_PROMPTS[mindset] + f"\n\n任务:{context}"
output = llm.generate(prompt)
# 提取<insight>标签中的关键结论
insight = self._extract_insight(output)
return MindsetOutput(
insight=insight,
detail=output,
confidence=self._estimate_confidence(output)
)
class ContextGate:
"""上下文门控:过滤信息流"""
def filter_input(self, history: List[str], instruction: str) -> str:
"""输入门:提取最小充分上下文"""
prompt = f"""
历史记录:{history}
当前任务:{instruction}
请提取与当前任务相关的最小上下文。
忽略无关信息,保持简洁。
"""
return llm.generate(prompt)
def filter_output(self, detail: str) -> str:
"""输出门:蒸馏关键结论"""
# 提取<insight>标签内容
if "<insight>" in detail:
return detail.split("<insight>")[1].split("</insight>")[0]
# 否则让LLM总结
prompt = f"请将以下内容提炼为一句话关键结论:{detail}"
return llm.generate(prompt)
class ChainOfMindset:
"""完整的CoM框架"""
def __init__(self):
self.meta_agent = MetaAgent()
self.expert = MindsetExpert()
self.gate = ContextGate()
def solve(self, problem: str, max_steps: int = 10) -> str:
problem_state = {"problem": problem, "history": []}
for step in range(max_steps):
# 1. Meta-Agent决策
decision = self.meta_agent.decide(problem_state)
# 2. 输入门过滤上下文
filtered_context = self.gate.filter_input(
problem_state["history"],
decision.context_needed
)
# 3. 执行思维模块
output = self.expert.execute(decision.mindset, filtered_context)
# 4. 输出门蒸馏结果
insight = self.gate.filter_output(output.detail)
# 5. 更新状态
problem_state["history"].append(insight)
problem_state["last_mindset"] = decision.mindset
# 6. 检查是否完成
if self._is_complete(output):
return self._extract_answer(output)
return "未能在限定步数内解决"实践建议
1. 定义清晰的思维模式边界
每种思维模式应该有明确的触发条件和输出格式,避免模块间职责模糊。
2. 设计有效的上下文过滤策略
Context Gate是关键。输入门要识别"最小充分信息",输出门要提取"核心结论"。
3. 平衡探索和利用
发散思维用于打破僵局,收敛思维用于推进推理。不要过度发散(浪费时间),也不要过早收敛(错过最优解)。
4. 监控思维模式切换频率
频繁切换可能说明:
- 问题分解不够合理
- 某个模块能力不足
- 调度策略需要优化
📊 详细数据:各思维模式贡献分析
不同任务类型的最优思维序列
| 任务类型 | 典型思维序列 | 关键模块 |
|---|---|---|
| 几何证明 | 空间→收敛→算法 | 空间思维(可视化) |
| 数学竞赛 | 发散→收敛→算法 | 发散思维(多解法) |
| 代码生成 | 收敛→算法→发散 | 算法思维(验证) |
| 科学问答 | 收敛→空间→收敛 | 收敛思维(知识整合) |
| 迷宫导航 | 空间→收敛→算法 | 空间思维(路径规划) |
| 费米估算 | 空间→收敛→算法 | 三者协同 |
思维模式使用频率
| 思维模式 | 使用频率 | 平均耗时 |
|---|---|---|
| 收敛思维 | 42% | 1.2s |
| 算法思维 | 28% | 2.8s |
| 发散思维 | 18% | 1.8s |
| 空间思维 | 12% | 3.5s |
收敛思维使用最频繁,说明大多数步骤需要聚焦推理。空间思维最耗时,但效果显著。
📝 总结
Chain of Mindset这篇论文提出了一个简单但深刻的洞见:推理不是单一思维的重复,而是多种认知模式的动态编排。
核心贡献:
- 四种异质思维模式:空间、收敛、发散、算法------覆盖了推理的主要类型
- Meta-Agent调度:决策与执行分离,实现步级自适应
- Context Gate:解决多模块协作中的信息污染问题
- 免训练框架:不修改模型参数,只通过Prompt工程实现
实验结果证明了方法的有效性:在6个基准上全面领先,AIME数学竞赛提升10个百分点。
对于Agent开发者,这篇论文的启示是:
- 不要用一把锤子修所有东西:不同问题需要不同的推理策略
- 设计有效的调度机制:Meta-Agent的思维值得借鉴
- 重视信息过滤:Context Gate的设计解决了多模块协作的痛点
- 平衡效率与效果:CoM在帕累托前沿找到了最优平衡点
人类智能的核心特征之一是认知灵活性------能够根据任务需求动态调整思维方式。CoM向这个目标迈出了重要一步。虽然距离真正的"通用智能"还很远,但至少我们学会了让AI"切换脑回路"。
🔗 参考资料
- 论文原文 :Chain of Mindset: Reasoning with Adaptive Cognitive Modes
- Chain of Thought :Prompting LLMs to Reason
- Tree of Thoughts :Deliberate Problem Solving
- ReAct :Synergizing Reasoning and Acting
- DeepSeek R1 :Incentivizing Reasoning Capability