一、数据的导入与预处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']#以便图片文字正确显示
%matplotlib inline
# Jupyter魔法命令,使图表在notebook中显示
#1.加载数据
data1=pd.read_excel('D:\ygw\python\experiments_v2\meal_order_detail.xlsx',sheet_name='meal_order_detail1')
data2=pd.read_excel('D:\ygw\python\experiments_v2\meal_order_detail.xlsx',sheet_name='meal_order_detail2')
data3=pd.read_excel('D:\ygw\python\experiments_v2\meal_order_detail.xlsx',sheet_name='meal_order_detail3')
#2.数据预处理(合并数据,NA等处理),分析数据
data=pd.concat([data1,data2,data3],axis=0)#axis=0按照行进行拼接数据
#data.head()
data.dropna(axis=1,inplace=True)#按照行删除na列,并且修改源数据
data.info()
<class 'pandas.core.frame.DataFrame'>
Index: 10037 entries, 0 to 3610
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 detail_id 10037 non-null int64
1 order_id 10037 non-null int64
2 dishes_id 10037 non-null int64
3 dishes_name 10037 non-null object
4 itemis_add 10037 non-null int64
5 counts 10037 non-null int64
6 amounts 10037 non-null int64
7 place_order_time 10037 non-null datetime64[ns]
8 add_inprice 10037 non-null int64
9 picture_file 10037 non-null object
10 emp_id 10037 non-null int64
dtypes: datetime64[ns](1), int64(8), object(2)
memory usage: 941.0+ KB
二、数据的统计与可视化
#统计卖出菜品的平均价格
round(data['amounts'].mean(),2)#法一:pandas自带函数
round(np.mean(data['amounts']),2)#法二:numpy函数处理
44.82
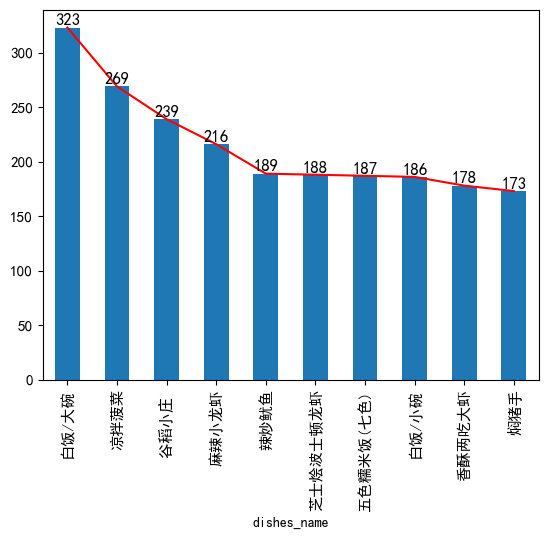
#频数统计,什么菜最受欢迎(对菜名进行频数统计,取最大前10名)
dishes_count=data['dishes_name'].value_counts()[:10]
dishes_count
dishes_name
白饭/大碗 323
凉拌菠菜 269
谷稻小庄 239
麻辣小龙虾 216
辣炒鱿鱼 189
芝士烩波士顿龙虾 188
五色糯米饭(七色) 187
白饭/小碗 186
香酥两吃大虾 178
焖猪手 173
Name: count, dtype: int64
#3.数据可视化matplotlib
dishes_count.plot(kind='line',color=['r'])
dishes_count.plot(kind='bar',fontsize=11)
for x,y in enumerate(dishes_count):
print(x,y)
plt.text(x,y+2,y,ha='center',fontsize=12)
0 323
1 269
2 239
3 216
4 189
5 188
6 187
7 186
8 178
9 173
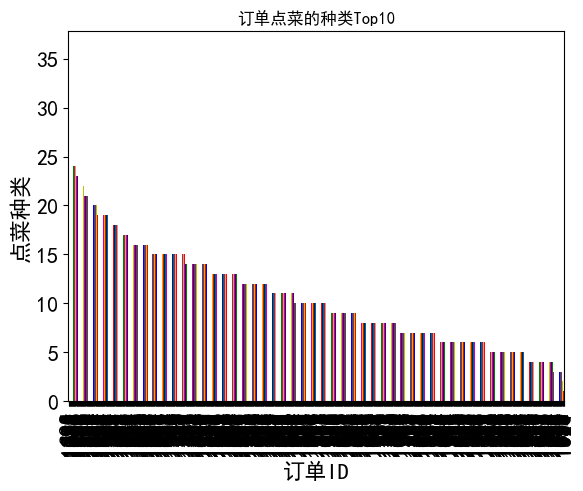
#订单点菜的种类最多(1,1,1 1,2,3)
data_group=data['order_id'].value_counts()[:]%[:]限定区域范围[10:100]10到100
data_group.plot(kind='bar',fontsize=16,color=['r','m','b','y','g'])
plt.title('订单点菜的种类Top10')
plt.xlabel('订单ID',fontsize=16)
plt.ylabel('点菜种类',fontsize=16)
#8月份餐厅订单点菜种类前10名,平均点菜25个菜品
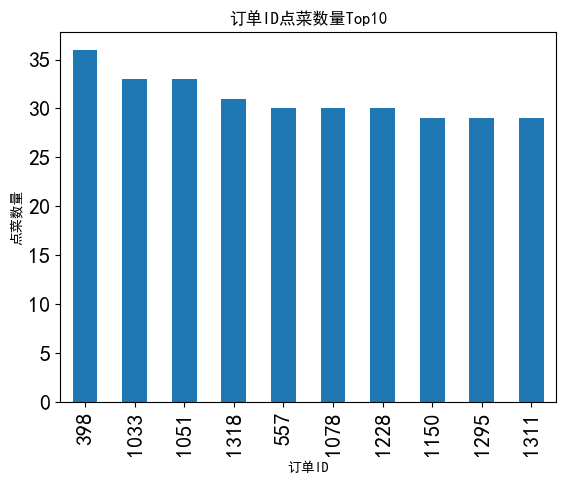
#订单ID点菜数量Top10(分组order_id,counts求和,排序,前十)
data['total_amounts']=data['counts']*data['amounts']#统计单道菜消费总额
dataGroup=data[['order_id','counts','amounts','total_amounts']].groupby(by='order_id')
#根据'order_id'为变量将三组数据分组求和
Group_sum=dataGroup.sum()#分组求和
sort_counts=Group_sum.sort_values(by='counts',ascending=False)#sort_values排序
sort_counts['counts'][:10].plot(kind='bar',fontsize=16)
plt.xlabel('订单ID')
plt.ylabel('点菜数量')
plt.title('订单ID点菜数量Top10')
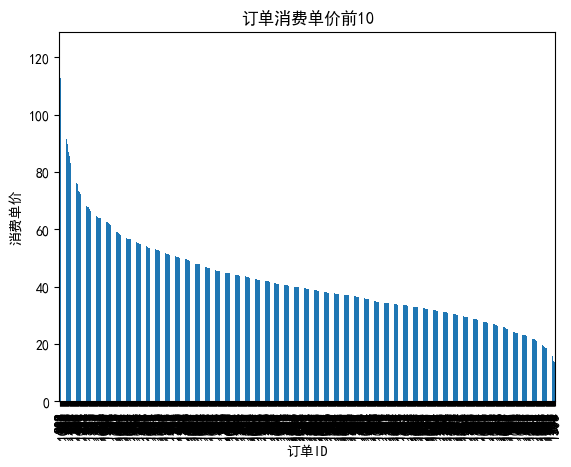
#哪个订单ID平均消费最贵
Group_sum['average']=Group_sum['total_amounts']/Group_sum['counts']
sort_average=Group_sum.sort_values(by='average',ascending=False)
#ascending 是 pandas 中用于排序的一个参数,ascending=False 表示降序排列(从大到小)
sort_average['average'][:].plot(kind='bar')#'average'求平均值
plt.xlabel('订单ID')
plt.ylabel('消费单价')
plt.title('订单消费单价前10')
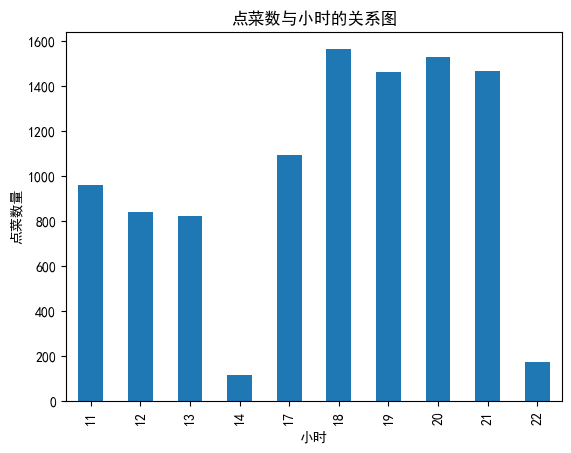
#一天当中什么时间段,点菜量比较集中(hour)
data['hourcount']=1#新列,用计数器
data['time']=pd.to_datetime(data['place_order_time'])#将时间转换成日期类型存储
data['hour']=data['time'].map(lambda x:x.hour)#以小时为单位
gp_by_hour=data.groupby(by='hour').count()['hourcount']
gp_by_hour.plot(kind='bar')
plt.xlabel('小时')
plt.ylabel('点菜数量')
plt.title('点菜数与小时的关系图')
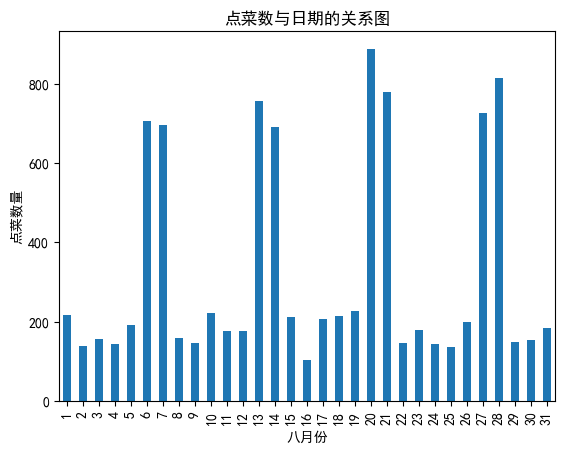
#哪一天订餐数量最多
data['daycount']=1
data['day']=data['time'].map(lambda x:x.day)#解析出天
gp_by_day=data.groupby(by='day').count()['daycount']
gp_by_day.plot(kind='bar')
plt.xlabel('八月份')
plt.ylabel('点菜数量')
plt.title('点菜数与日期的关系图')
#拓展:排序,取点菜量最大的前5天
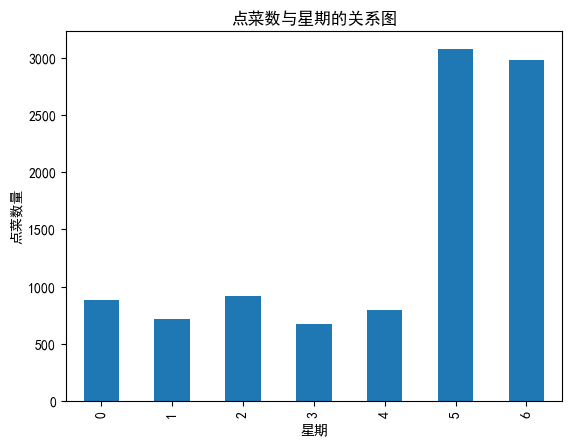
#查看星期几人数最多,订餐数最多,映射数据到星期
data['weekcount']=1
data['weekday']=data['time'].map(lambda x:x.weekday())
gp_by_weekday=data.groupby(by='weekday').count()['weekcount']
gp_by_weekday.plot(kind='bar')
plt.xlabel('星期')
plt.ylabel('点菜数量')
plt.title('点菜数与星期的关系图')