1,安装nvitop
nvitop 可以实时看显卡占用占用情况
pip install nvitop
nvitop -m auto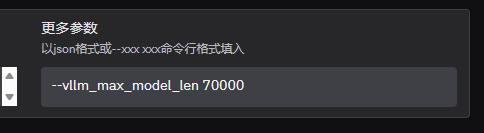
2,NewGELUActivation, PytorchGELUTanh, GELUActivation ImportError: cannot import name 'PytorchGELUTanh' from 'transformers.activations' (/mnt/workspace/ft_new/ft_qwen/lib/python3.11/site-packages/transformers/activations.py)
直接修改源码
bash
vim /mnt/workspace/ft_new/ft_qwen/lib/python3.11/site-packages/awq/quantize/scale.py找到第 12 行的导入代码:
python
# 原错误代码
from transformers.activations import NewGELUActivation, PytorchGELUTanh, GELUActivation修改为
python
# 新代码(移除PytorchGELUTanh,用原生GELU替代)
import torch
import torch.nn as nn
# 定义兼容类
class PytorchGELUTanh(nn.Module):
def forward(self, x):
return torch.nn.functional.gelu(x, approximate='tanh')
# 给awq用的别名(兼容原代码逻辑)
NewGELUActivation = PytorchGELUTanh
GELUActivation = PytorchGELUTanh3.ValueError: To serve at least one request with the models's max seq len (262144), (36.0 GiB KV cache is needed, which is larger than the available KV cache memory (12.16 GiB). Based on the available memory, the estimated maximum model length is 88544. Try increasing `gpu_memory_utilization` or decreasing `max_model_len` when initializing the engine.
注意需要加上下面参数进行部署
bash
--vllm_max_model_len 700004,模型导出并上传魔搭社区
bash
swift export \
--model output/v3-20260218-164346/checkpoint-75-merged \
--push_to_hub true \
--hub_model_id 'a80C51/llm-wayne-qwen3-4b-think-2507' \
--hub_token 'ms-43994f9b-8b99-4fc6-852f-1f7d44513e16' \
--use_hf false