介绍
多任务的优势
多个任务同时执行能够充分利用CPU资源,大大提高程序执行效率
- 思考一下: 利用现学知识能够让多个任务同时执行吗?
不能,因为之前所写的程序都是单任务的,也就是说一个函数或者方法执行完成,另外一个函数或者方法才能执行,要想实现多个任务同时执行就需要使用多任务。
概念
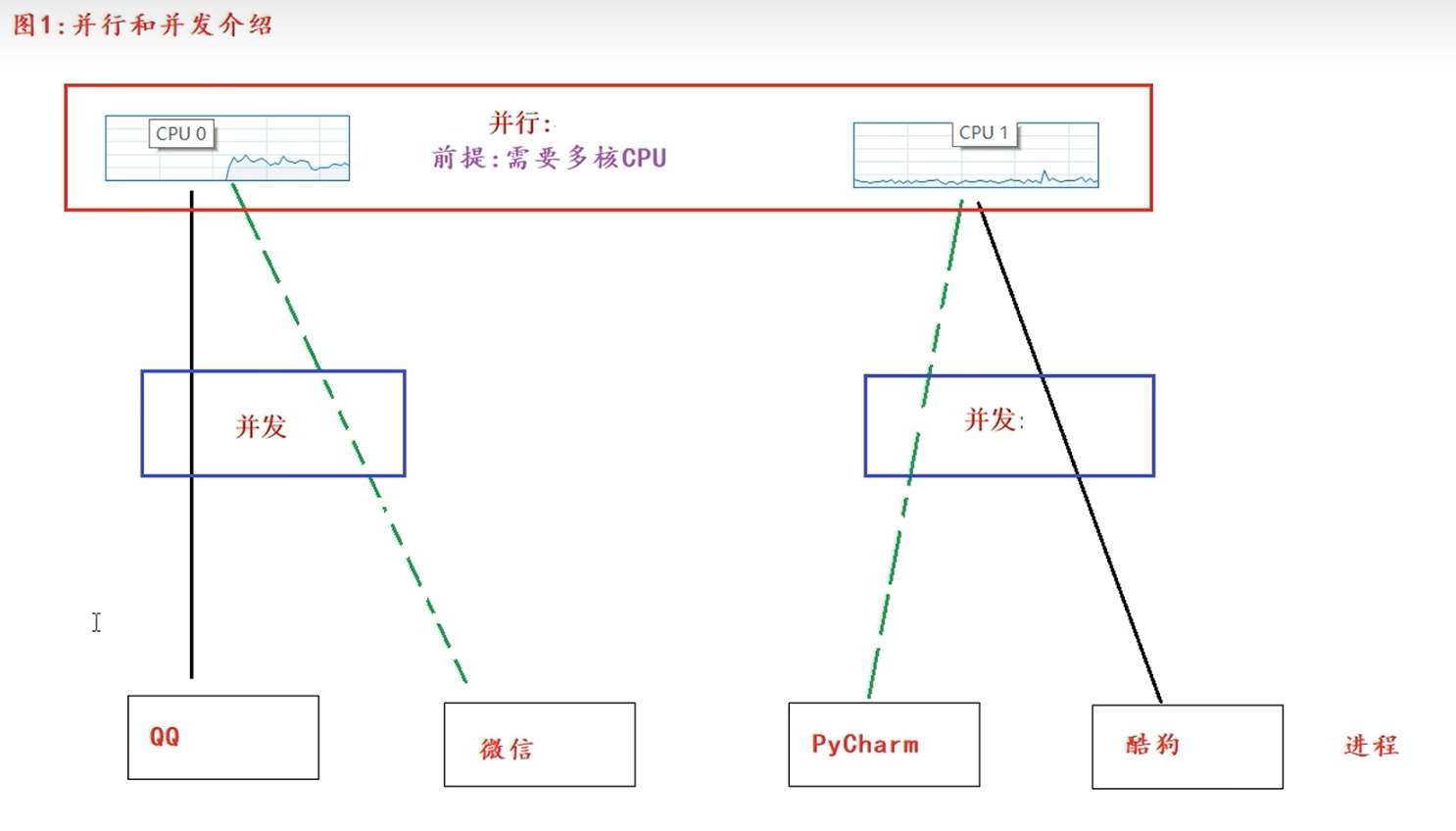
多任务是指在同一时间内执行多个任务(给我们的感觉)。
- 例如: 现在电脑安装的操作系统都是多任务操作系统,可以同时运行着多个软件。

- 多任务的两种表现形式
- 并发: 在一段时间内,交替执行任务
- 并行: 在一段时间内,真正的同时一起执行多个任务
进程
进程的概念
进程(Process)是CPU资源分配的最小单位,它是操作系统进行资源分配和调度运行的基本单位
通俗理解: 一个正在运行的程序就是一个进程.
例如: 正在运行的qq,微信等他们都是一个进程
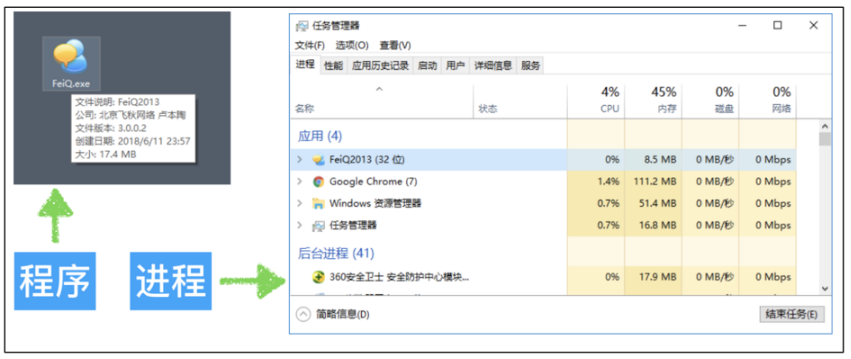
注意: 一个程序运行后至少有一个进程
多进程的作用
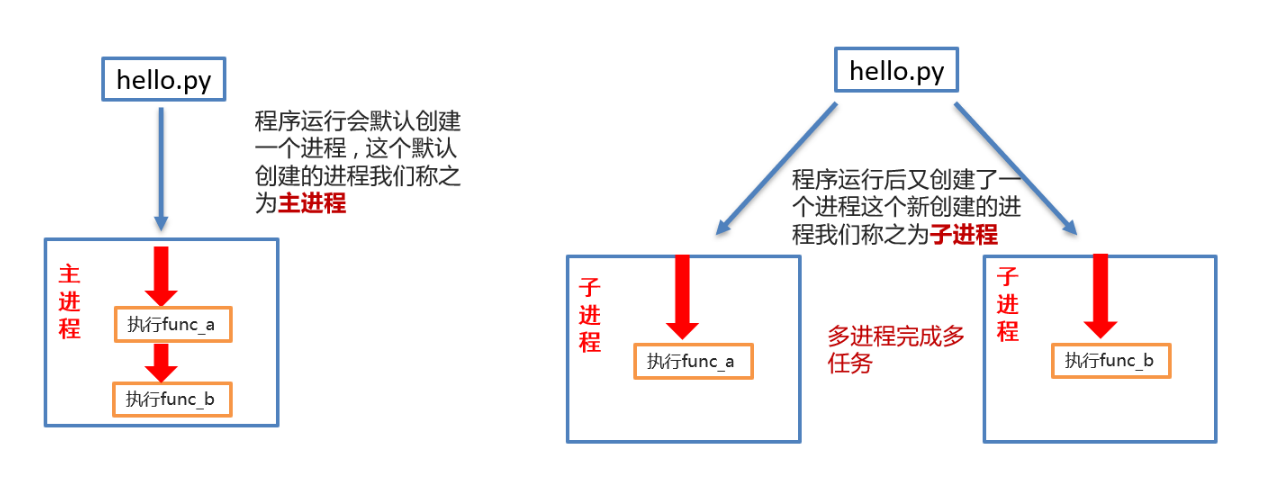
图中是一个非常简单的程序,
- 一旦运行hello.py这个程序,按照代码的执行顺序,
- func_a函数执行完毕后才能执行func_b函数.
- 如果可以让func_a和func_b同时运行,显然执行hello.py这个程序的效率会大大提升.

多进程基本工作方式
进程的创建步骤
- 导入进程工具包
- import multiprocessing
- 通过进程类实例化进程对象
- 子进程对象= multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={))
-
- group--参数未使用,值始终为None
- target--表示调用对象,即子进程要执行的任务(回调函数入口地址)
- args--表示以元组的形式向子任务函数传参,元组方式传参一定要和参数的顺序保持一致
- kwargs--表示以字典的方式给子任务函数传参,字典方式传参字典中的key要和参数名保持一致
- name--为子进程的名称
- 启动进程执行任务
- 进程对象.start()
进程创建与启动的代码
"""
使用多进程
模拟一边敲代码. 一边听音乐
"""
import multiprocessing
import time
def coding():
for i in range(3):
print("I'm coding")
time.sleep(0.2)
def music():
for i in range(3):
print("I'm music...")
time.sleep(0.2)
if __name__ == '__main__':
# 通过进程类创建进程对象
p1 = multiprocessing.Process(target=coding)
p2 = multiprocessing.Process(target=music)
# 启动进程
p1.start()
p2.start()任务函数有参数
使用多进程来模拟小明一边编写num行代码,一边听count首音乐功能实现。
"""
进程带参数的任务
"""
import multiprocessing
import time
def coding(num, name):
for i in range(num):
print(f"{name}在写第{i}行代码")
time.sleep(0.2)
def music(num, name):
for i in range(num):
print(f"{name}在听第{i}首音乐")
time.sleep(0.2)
if __name__ == '__main__':
# 通过进程类创建进程对象
p1 = multiprocessing.Process(target=coding, args=(3, "小王"))
p2 = multiprocessing.Process(target=music, kwargs={"num": 7, "name": "大名"})
# 启动进程
p1.start()
p2.start()a. 元组方式传参: 元组方式传参一定要和任务函数的参数顺序保持一致。
b. 字典方式传参: 字典方式传参字典中的key一定要和任务函数的参数保持一致
进程编号的作用
进程编号唯一标识一个进程,方便管理进程。
- 在一个操作系统中,一个进程拥有的进程号是唯一的,进程号可以反复使用。
- 获取进程编号的目的是验证主进程和子进程的关系,可以得知子进程是由那个主进程创建出来的
- 获取进程编号的两种操作
- 获取当前进程编号

- 获取当前父进程编号

进程的注意点介绍
进程之间不共享全局变量
-
例如,在不同进程中修改列表my_list[并新增元素,试着在各个进程中观察列表的最终结果。
"""
进程之间数据是相互隔离的.
因为子进程相当于是父进程的"副本",会将父进程的"main外资源"拷贝一份,即:各是各的.
"""
import multiprocessing
import timemy_list = []
def write_data():
for i in range(3):
my_list.append(i)
print("add:", i)
print("write_data:", my_list)def read_data():
print("read_data:", my_list)if name == 'main':
p1 = multiprocessing.Process(target=write_data)
p2 = multiprocessing.Process(target=read_data)
p1.start()
time.sleep(1)
p2.start()
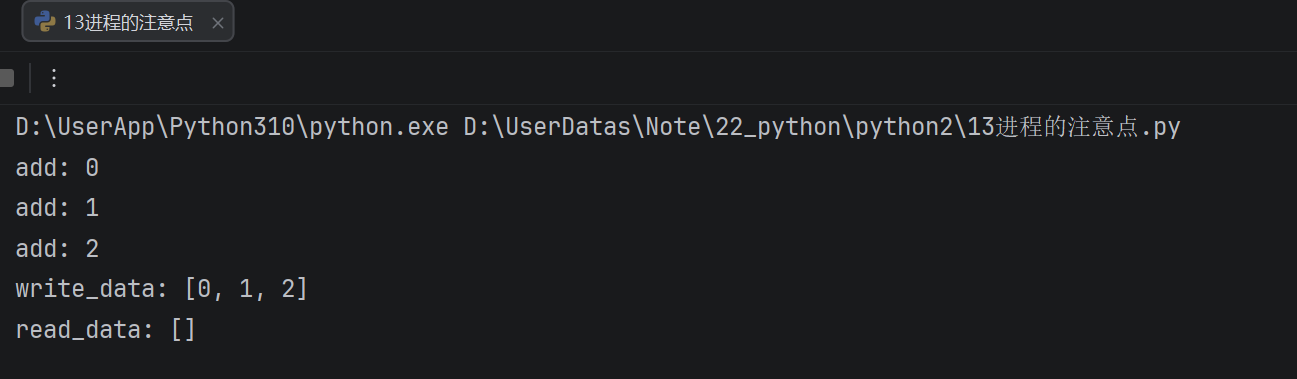
- 图解原理
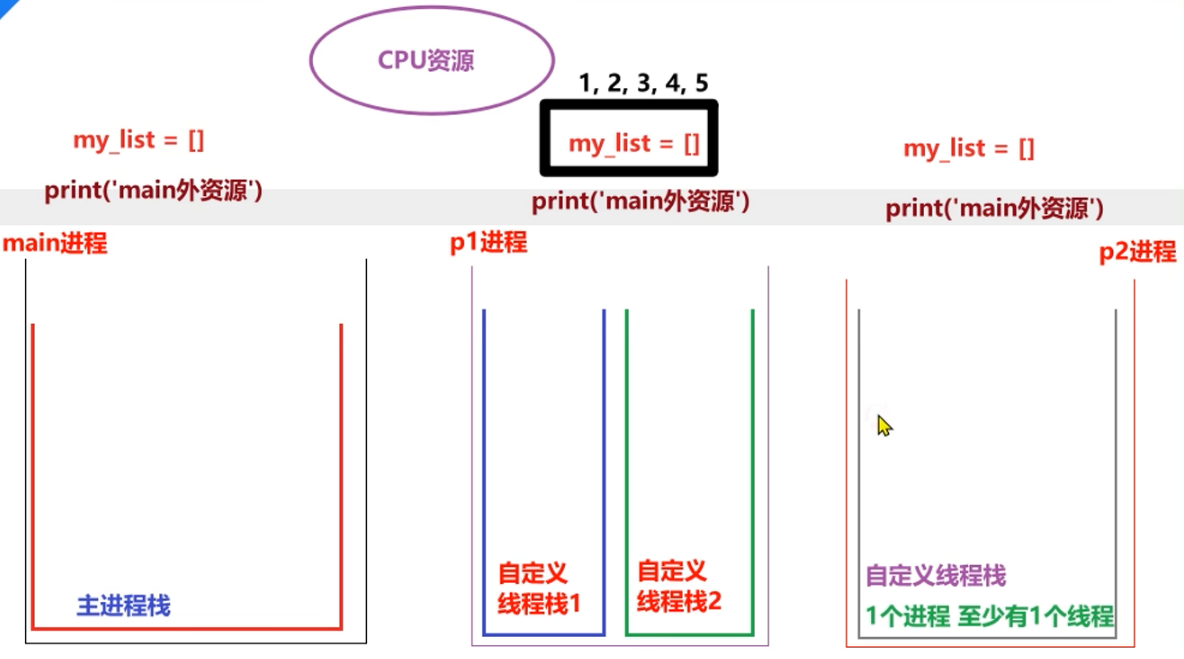
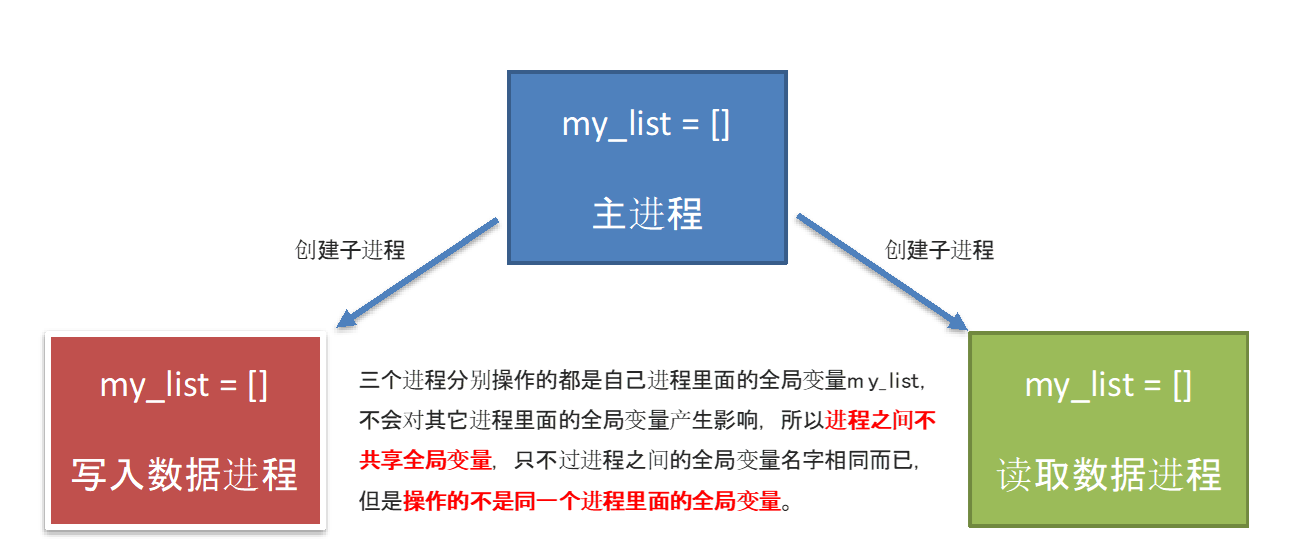
创建子进程会对主进程资源进行拷贝,也就是说子进程是主进程的一个副本,好比是一对双胞胎,之所以进程之间不共享全局变量,是因为操作的不是同一个进程里面的全局变量,只不过不同进程里面的全局变量名字相同而已。
主进程会等待所有的子进程执行结束再结束
-
假如我们现在创建一个子进程,子进程执行完大概需要2秒钟,现在让主进程执行1秒钟就退出程序:
"""
默认情况下,主进程会等待子进程执行结束再结束.
"""
def work():
for i in range(10):
print("work:", i)
time.sleep(0.2)if name == 'main':
work_process = multiprocessing.Process(target=work)
work_process.start()
time.sleep(1)
print("主进程结束")
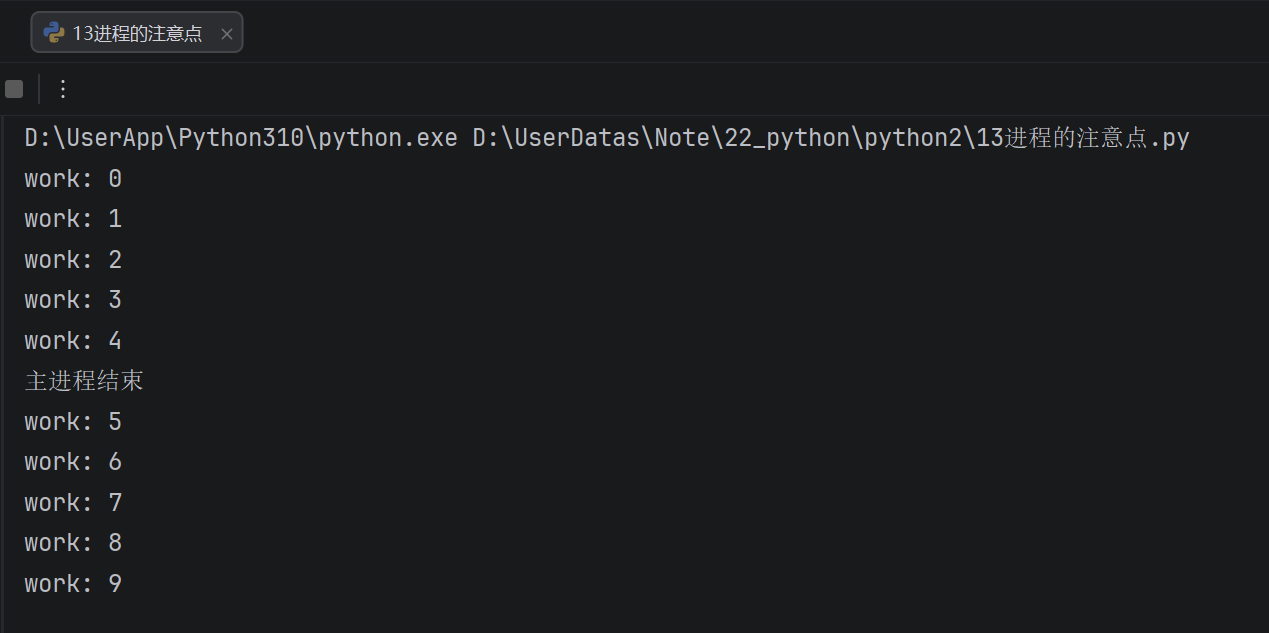
- 通过上面代码的执行结果,我们可以得知:主进程会等待所有的子进程执行结束再结束。
不让主进程等待子进程,
方法1: 子进程设置守候进程
- 让主进程退出时自动销毁子进程,主进程就不再等待子进程执行了。
方法2: 子进程自己主动的终止子进程
-
让守护进程或子进程提前结束
"""
不让主进程等待子进程
方式1: 设置子进程为守护进程 (推荐方式)
会释放资源
方式2: 强制关闭子进程
可能会导致子进程变成垃圾进程, 交由python解释器自动回收
"""
def work():
for i in range(10):
print("work:", i)
time.sleep(0.2)if name == 'main':
work_process = multiprocessing.Process(target=work)
# 方式1: 设置子进程为守护进程 (推荐方式)
work_process.daemon = True
work_process.start()
time.sleep(1)# 方式2: 强制关闭子进程 # work_process.terminate() print("主进程结束")
线程
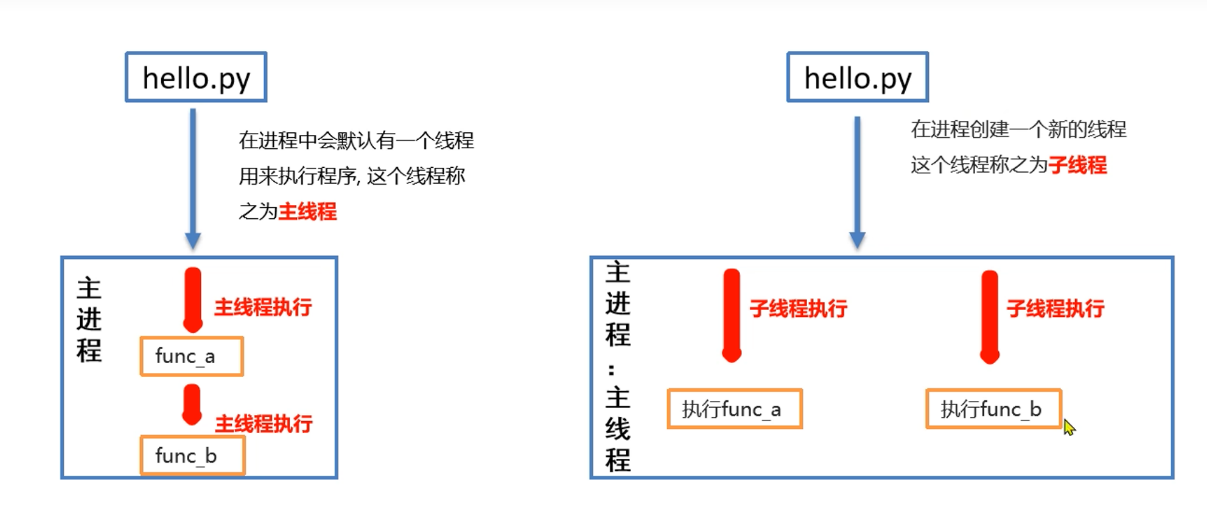
线程的介绍
图中是一个非常简单的程序,
- 一旦运行hello.py这个程序,按照代码的执行顺序,
- func_a函数执行完毕后才能执行func_b函数.
- 如果可以让func_a和func_b同时运行,显然执行hello.py这个程序的效率会大大提升

线程的作用
线程创建的步骤
- 导入线程模块
- import threading
- 通过线程类创建线程对象
- 线程对象 = threading.Thread(group, target, name, kwargs)
-
- group: 线程组,目前只能使用None
- target: 执行的目标任务名
- args: 以元组的方式给执行任务传参,元组方式传参一定要和目标任务函数参数的顺序保持一致。kwargs: 以字典方式给执行任务传参,字典方式传参字典中的key一定要和参数的顺序保持一致
- name: 线程名,一般不用设置
- 启动线程执行任务
- 线程对象.start()
多线程完成多任务的代码
例如,使用多线程来模拟一边写代码,一边听音乐的功能。
"""
多线程的使用
"""
import threading
import time
def coding():
for i in range(3):
print("I'm coding")
time.sleep(0.2)
def music():
for i in range(3):
print("I'm music...")
time.sleep(0.2)
if __name__ == '__main__':
coding_thread = threading.Thread(target=coding)
music_thread = threading.Thread(target=music)
coding_thread.start()
music_thread.start()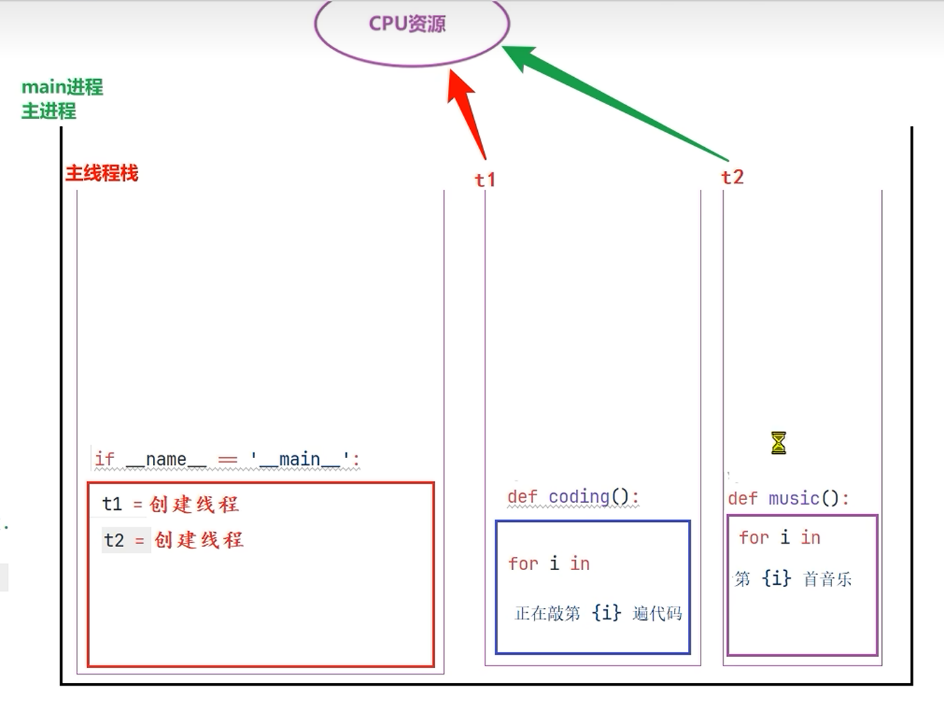
线程带参数的任务
使用多线程来模拟小明一边编写num行代码,一边听count首音乐功能实现。
"""
线程带参数的任务
"""
import threading
import time
def coding(name, num):
for i in range(num):
print(f"{name}正在编写第{i}行代码")
time.sleep(0.2)
def music(name, num):
for i in range(num):
print(f"{name}正在听第{i}首音乐")
time.sleep(0.2)
if __name__ == '__main__':
coding_thread = threading.Thread(target=coding, args=("小王", 3))
music_thread = threading.Thread(target=music, kwargs={"name": "大大大", "num": 6})
coding_thread.start()
music_thread.start()线程的注意点介绍
线程之间执行是无序的
-
线程之间执行是无序的,它是由操作系统调度决定的,操作系统调度哪个线程,哪个线程就执行,没有调度的线程是不能执行的。
-
创建多个线程,多次运行,观察各次线程的执行顺序
"""
线程调度的随机性
CPU调度资源的策略:
1.均分时间片: 给每个线程分配运算时间, 在有效时间内执行任务, 到期任务暂停
2.抢占式调度: 线程主动抢占cpu算力, 抢到之后执行任务 (大多数语言使用该策略)
"""
import threading
import timedef get_info():
time.sleep(0.5)
thread = threading.current_thread()
print(f"{thread.name}正在执行任务")if name == 'main':
for i in range(10):
t = threading.Thread(target=get_info)
t.start()
主线程会等待所有的子线程执行结束再结束
-
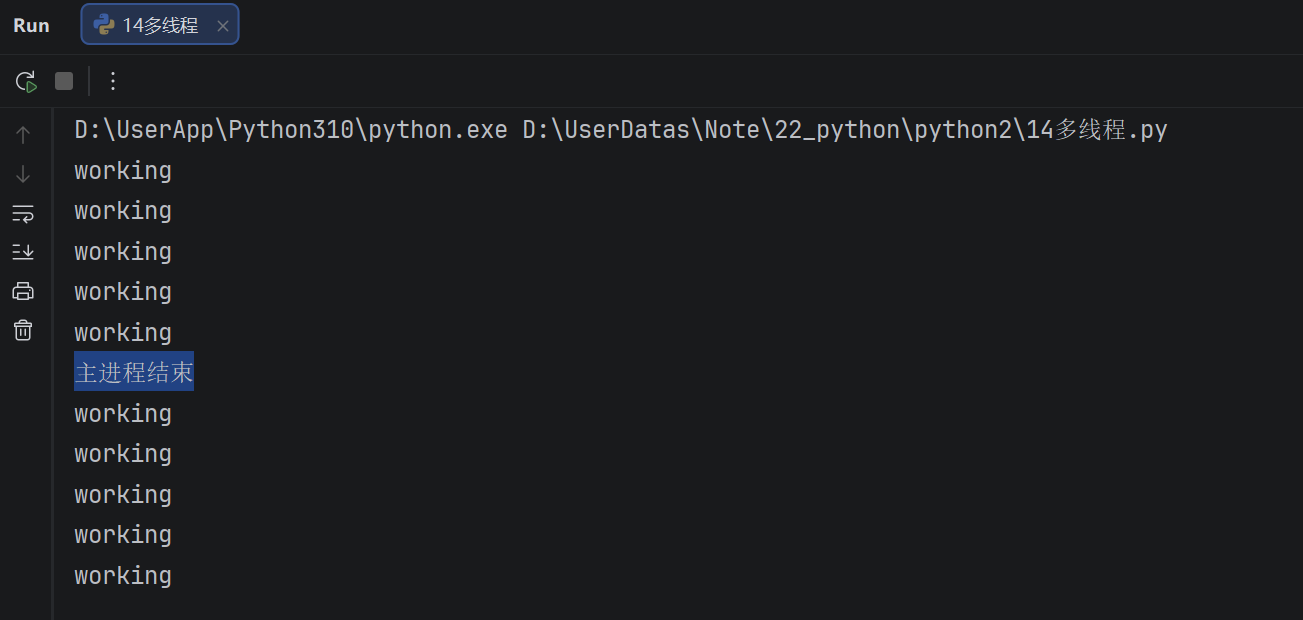
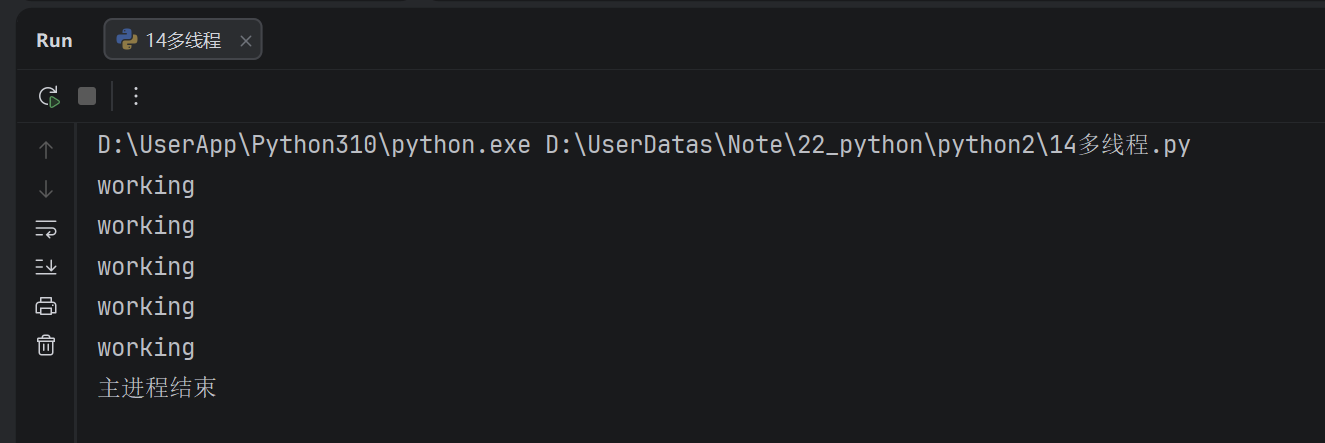
假如创建一个子线程,这个子线程执行完大概需要2.5秒钟,现在让主线程执行1秒钟就退出程序,查看一下执行结果
"""
主进程会等待所有子进程结束后再结束
"""
import threading
import timedef work():
for i in range(10):
print("working")
time.sleep(0.2)if name == 'main':
t = threading.Thread(target=work)
t.start()
time.sleep(1)
print("主进程结束")
- 假如我们就让主线程执行1秒钟,子线程就销毁不再执行,那怎么办呢?
- 我们可以设置守护主线程
-
守护主线程就是主线程退出子线程销毁不再执行
-
设置守护主线程有两种方式
# 方式1: 创建子进程时设置该线程为守护线程 t = threading.Thread(target=work, daemon=True) # 方式2: 通过线程对象设置为守护线程 t.setDaemon(True)
-
设置守护线程
"""
主进程会等待所有子进程结束后再结束
"""
import threading
import timedef work():
for i in range(10):
print("working")
time.sleep(0.2)if name == 'main':
# 方式1: 创建子进程时设置该线程为守护线程
t = threading.Thread(target=work, daemon=True)# 方式2: 通过线程对象设置为守护线程 # t.setDaemon(True) t.start() time.sleep(1) print("主进程结束")
线程之间共享全局变量
-
定义一个列表类型的全局变量,创建两个子线程分别执行, 向全局变量添加数据的任务和向全局变量读取数据的任务,查看线程之间是否共享全局变量数据
"""
线程之间共享全局变量
"""
my_list = []
def write_data():
for i in range(3):
my_list.append(i)
print("add:", i)
print("write_data:", my_list)def read_data():
print("read_data:", my_list)if name == 'main':
t1 = threading.Thread(target=write_data)
t2 = threading.Thread(target=read_data)
t1.start()
time.sleep(1)
t2.start()
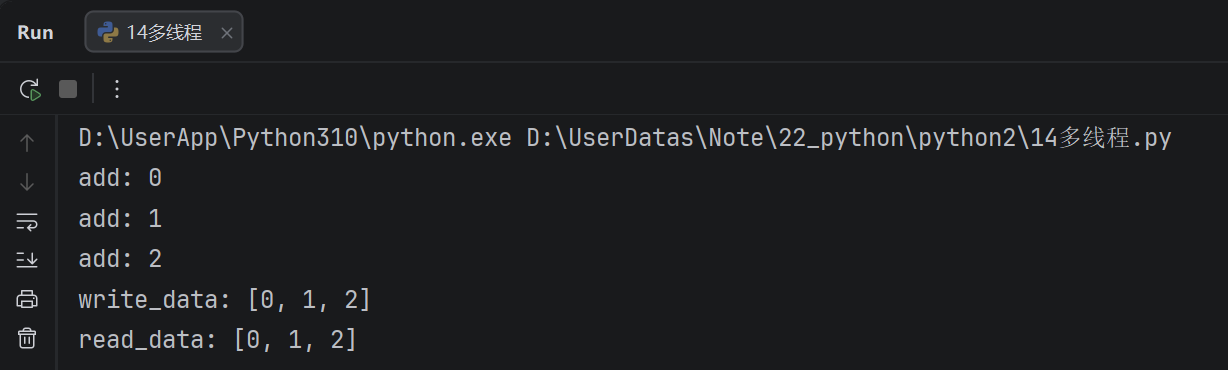
线程之间共享全局变量数据出现错误问题
-
定义两个函数,实现循环100万次,每循环一次给全局变量加1,创建两个子线程执行对应的两个函数,查看计算后的结果
my_count = 0
def write_data1():
global my_count
for i in range(1000000):
my_count += 1
print(f"write_data1:{my_count}",end="\n")def write_data2():
global my_count
for i in range(1000000):
my_count += 1
print(f"write_data2:{my_count}")if name == 'main':
t1 = threading.Thread(target=write_data1)
t2 = threading.Thread(target=write_data2)
t1.start()
t2.start()
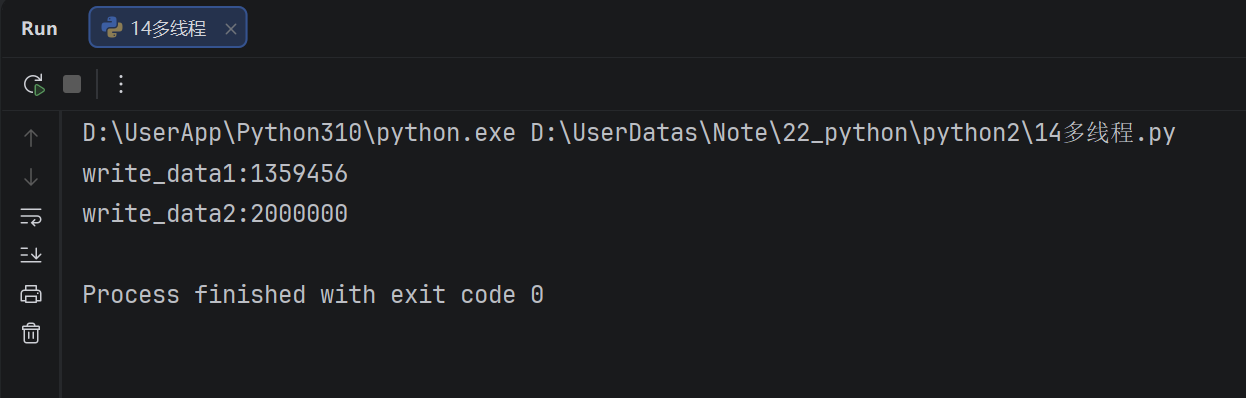
- 错误分析
- 两个线程对同一个全局变量my_count进行加1运算,由于是多线程同时操作,两个方法交替执行,
- 有可能出现下面情况:
- t1取得my_count=0。此时系统把t1调度为等待状态,把t2转换为"running'状态
- 由于t1还没有执行完成, t2拿到的my_count=0
- t1执行完毕后my_count=1,, t2执行完毕后my_count还是1
- 相当于t1和t2都对my_count加1, 应该得到2, 实际得到还是1
全局变量数据错误的解决办法:
- 线程同步: 保证同一时刻只能有一个线程去操作全局变量
- 同步: 就是协同步调,按预定的先后次序进行运行,好比现实生活中的对讲机, 你说完,我再说
- 线程同步的方式 加锁思想
- 互斥锁: 对共享数据进行锁定,保证同一时刻只有一个线程去操作。
- 互斥锁是多个线程一起去抢,抢到锁的线程先执行,没有抢到锁的线程进行等待,等锁使用完释放后,其它等待的线程再去抢这个锁。
- 互斥锁的使用流程
- 创建互斥锁: mutex = threading.Lock()
- 上锁: mutex.acquire()
- 释放锁: mutex.release()
-
死锁: 一直等待对方释放锁的情景就是死锁。
-
死锁的原因: 没有在合适的地方注意释放锁
-
死锁的结果: 会造成应用程序的停止响应,应用程序无法再继续往下执行了
"""
线程之间共享全局变量可能会出现安全问题
"""
my_count = 0创建锁
lock = threading.Lock()
def write_data1():
global my_count
lock.acquire() # 获取锁
for i in range(1000000):
my_count += 1
print(f"write_data1:{my_count}",end="\n")
lock.release() # 释放锁def write_data2():
global my_count
lock.acquire() # 获取锁
for i in range(1000000):
my_count += 1
print(f"write_data2:{my_count}")
lock.release() # 释放锁if name == 'main':
t1 = threading.Thread(target=write_data1)
t2 = threading.Thread(target=write_data2)
t1.start()
t2.start()
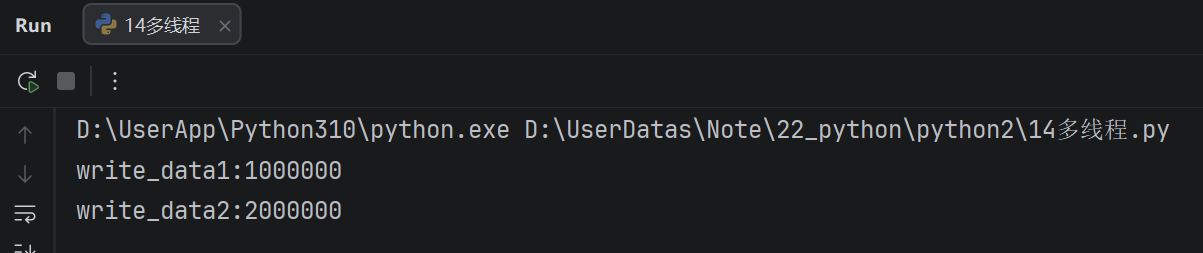
对比
关系对比
- 线程是依附在进程里面的,没有进程就没有线程
- 一个进程默认提供一条线程,进程可以创建多个线程
区别对比
- 进程之间不共享全局变量
- 线程之间共享全局变量,但是要注意资源竞争的问题,解决办法:互斥锁
- 创建进程的资源开销要比创建线程的资源开销要大
- 进程是操作系统资源分配的基本单位,线程是CPU调度的基本单位
- 线程不能够独立执行,必须依存在进程中
- Python中多进程开发比单进程多线程开发稳定性要强
优缺点对比
- 进程优缺点:
- 优点: 可以用多核
- 缺点: 资源开销大
- 线程优缺点:
- 优点: 资源开销小
- 缺点:不能使用多核