在人工智能快速普及的当下,个人AI助手已经逐渐渗透到我们的工作和生活中,它们能够跨平台接收消息、智能处理需求、执行指定任务,成为提升效率的重要工具。OpenClaw作为一款功能强大的个人AI助手,凭借其灵活的渠道适配、完善的路由机制、强大的Agent能力以及可靠的定时任务系统,在众多AI助手中脱颖而出。很多开发者在使用OpenClaw时,都会好奇其背后的运行逻辑:当我们在WhatsApp、Discord等平台发送消息时,OpenClaw是如何捕捉到这些消息的,又是如何一步步处理并给出回复的;Web UI端的消息传递和外部渠道有何不同;Pi Agent如何调用大语言模型(LLM)和执行本地命令;定时任务从创建到结束的完整生命周期又包含哪些环节。今天,我们就结合OpenClaw的源代码,对这些核心功能模块进行全面且深入的解析,带你走进这款个人AI助手的底层架构,读懂每一个流程背后的技术实现。
OpenClaw的整体架构遵循"模块化设计、统一化管理"的理念,无论是消息处理、Agent执行还是定时任务,都有清晰的模块划分和明确的流程逻辑,这不仅保证了系统的稳定性和可扩展性,也让开发者能够快速定位问题、扩展新功能。接下来,我们将从消息处理流程入手,逐步深入到路由机制、Web UI消息链路、Pi Agent的LLM调用与本地命令执行,最后详解定时任务的全生命周期,全方位拆解OpenClaw的核心技术细节。
一、OpenClaw消息处理完整流程:从消息接入到回复发送的全链路解析
OpenClaw最核心的功能之一就是跨平台消息处理,它能够支持WhatsApp、Discord、Telegram等多种外部渠道,同时也支持Web UI端的消息交互,无论用户从哪个渠道发送消息,OpenClaw都能高效捕捉、精准处理并及时回复。整个消息处理流程可以概括为四个核心环节:消息接入、路由决策、AI处理、回复发送,每个环节都有对应的核心文件和具体实现逻辑,环环相扣、无缝衔接。
1.1 核心模块与文件定位
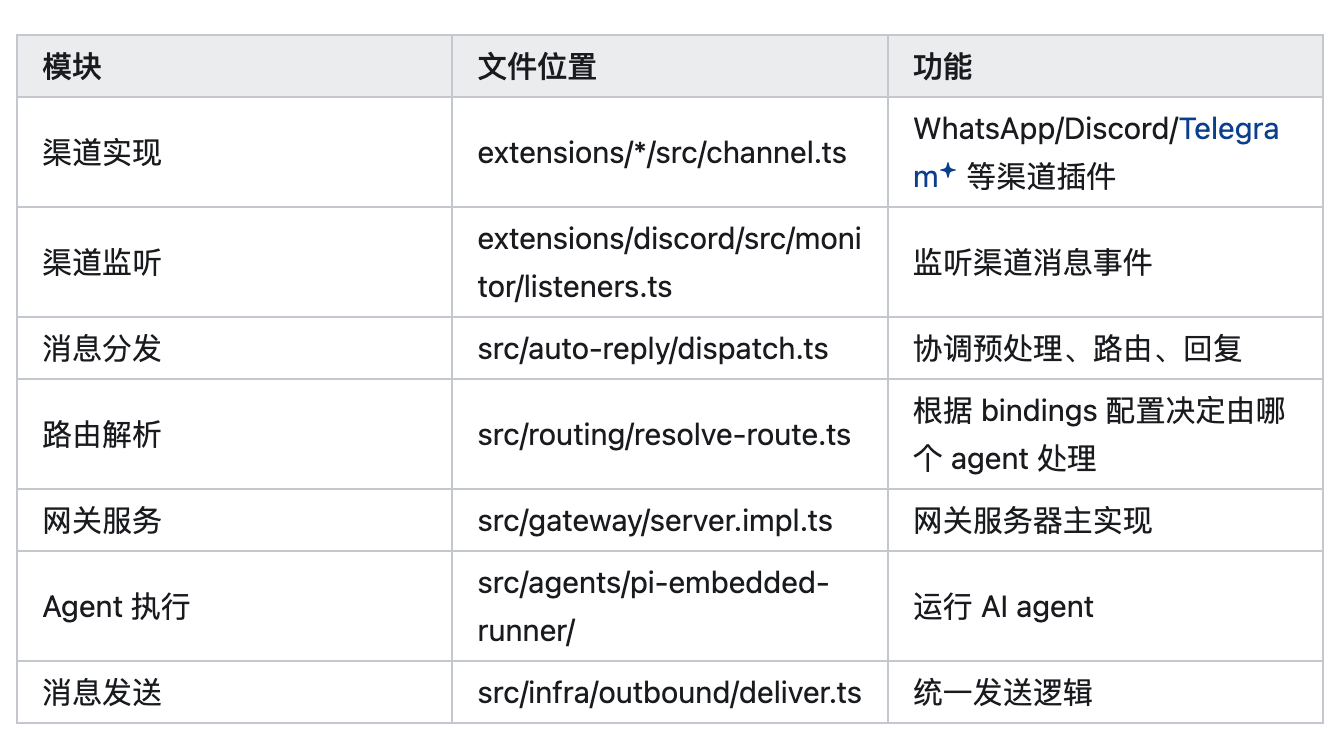
要理解消息处理流程,首先需要明确各个核心模块的职责和对应的文件位置,这是读懂源代码的基础。OpenClaw的消息处理模块采用插件化设计,不同渠道的实现相互独立,核心逻辑则集中在公共模块中,具体如下:
渠道实现模块主要负责适配不同的外部平台,所有渠道相关的插件都放在extensions/*/src目录下,其中channel.ts文件是每个渠道的核心实现文件,用于定义该渠道的消息接收、发送相关的基础逻辑,比如WhatsApp、Discord、Telegram等渠道,都有各自独立的channel.ts文件,这样的设计使得新增或修改某个渠道的功能时,不会影响其他渠道的正常运行。
渠道监听模块主要负责实时捕捉外部渠道的消息事件,以Discord渠道为例,其监听逻辑位于extensions/discord/src/monitor/listeners.ts文件中,通过DiscordMessageListener监听Discord平台的消息事件,一旦有用户发送消息,就会立即触发监听函数,进入后续的预处理环节。
消息分发模块是整个消息处理流程的"中枢神经",位于src/auto-reply/dispatch.ts文件中,主要职责是协调消息的预处理、路由决策和回复发送,核心函数是dispatchInboundMessage(),该函数会接收经过预处理的消息,调用路由解析模块确定处理该消息的Agent,再将消息传递给Agent进行处理,最后将处理结果交给回复发送模块。
路由解析模块负责根据系统配置的bindings规则,决定由哪个Agent来处理当前消息,核心文件是src/routing/resolve-route.ts,其中resolveAgentRoute函数是路由解析的核心,会按照预设的优先级匹配规则,从配置中找到对应的Agent,同时生成会话密钥(sessionKey),用于追踪整个会话的状态。
网关服务是OpenClaw的核心服务之一,位于src/gateway/server.impl.ts文件中,负责统一接收所有渠道的消息请求,包括外部渠道和Web UI端,同时处理回复的分发,相当于整个系统的"入口"和"出口"。
Agent执行模块负责运行AI Agent,处理消息内容并生成回复,核心文件位于src/agents/pi-embedded-runner/目录下,该模块会根据路由解析的结果,调用对应的AI Agent,执行消息处理、工具调用等操作,是AI能力的核心载体。
回复发送模块负责将Agent生成的回复,按照不同渠道的特性进行格式化处理,然后发送回对应的渠道,核心文件是src/infra/outbound/deliver.ts,该文件定义了统一的发送逻辑,无论哪个渠道,最终都会通过该模块的逻辑完成回复发送,保证了回复格式的统一性和发送流程的规范性。
1.2 详细流程示例:以Discord渠道为例
为了让大家更直观地理解消息处理的全流程,我们以Discord渠道为例,结合源代码中的具体函数和逻辑,一步步拆解从用户发送消息到接收回复的完整链路,让抽象的流程变得具体可感。
第一步,用户在Discord平台发送消息。当用户在Discord的服务器或私聊中发送一条消息时,Discord平台会触发对应的消息事件,而OpenClaw的Discord渠道监听模块会实时捕捉到这个事件。
第二步,监听模块触发并进行预处理。位于extensions/discord/src/monitor/listeners.ts文件中的DiscordMessageListener会立即响应这个消息事件,首先对消息进行预处理,包括权限检查、白名单验证,确保发送消息的用户有权限使用OpenClaw的服务,同时过滤掉无效或恶意消息。预处理完成后,会解析消息的核心内容,包括文本信息、附件(如图片、文件)、用户信息(如用户ID、所在服务器)等,将这些信息整理成标准化的消息格式,方便后续模块处理。
第三步,消息分发模块接收并转发消息。预处理完成后的标准化消息,会被传递到src/auto-reply/dispatch.ts文件中的dispatchInboundMessage()函数,该函数是消息分发的核心,会对接收到的消息进行进一步的处理,比如判断消息类型、加载对应的会话信息,然后调用路由解析模块,请求确定处理该消息的Agent。
第四步,路由解析模块匹配对应的Agent。路由解析模块的resolveAgentRoute函数会被调用,该函数会首先加载系统的bindings配置,然后按照预设的优先级规则,从配置中匹配对应的Agent。这里的匹配优先级非常关键,从高到低依次为:peer(直接匹配用户)、peer.parent(继承父线程的绑定)、guild+roles(Discord服务器+角色)、guild(Discord服务器)、team(Slack团队)、account(账户)、channel(渠道)、default(默认Agent)。按照这个优先级,只要匹配到对应的规则,就会停止后续匹配,确定目标Agent的ID,同时生成sessionKey和mainSessionKey(用于私聊合并),并记录匹配方式(用于调试)。
第五步,Agent执行模块处理消息并生成回复。路由解析完成后,消息分发模块会将消息和路由结果(包括Agent ID、sessionKey等)传递给src/agents/pi-embedded-runner/目录下的Agent执行模块,该模块会启动对应的AI Agent,将消息内容作为输入,让Agent进行处理。在处理过程中,Agent可能会调用各种工具(如本地命令、浏览器操作等),完成复杂的任务,最终生成回复内容。
第六步,回复发送模块格式化并发送回复。Agent生成的回复内容会被传递到src/infra/outbound/deliver.ts文件中,该模块会首先对回复内容进行规范化处理,然后根据Discord渠道的特性格式化消息(比如适配Discord的消息格式、支持附件发送等),最后调用extensions/discord/src/send.ts文件中的发送函数,将回复发送回Discord平台,用户就能在Discord中看到OpenClaw的回复了。
1.3 消息处理的关键设计点
OpenClaw的消息处理流程之所以能够高效、稳定地运行,得益于其几个关键的设计点,这些设计点不仅保证了系统的灵活性和可扩展性,也提升了用户体验。
第一个关键设计点是渠道插件化。每个外部渠道都在extensions/*/目录下独立实现,拥有自己的监听、发送、预处理逻辑,与核心模块解耦。这种设计的优势在于,新增一个渠道(比如微信、钉钉)时,只需要在extensions目录下新增对应的插件文件夹,实现该渠道的channel.ts、listeners.ts等核心文件,无需修改系统核心代码,极大地降低了扩展成本;同时,当某个渠道出现问题时,只需修改该渠道的插件代码,不会影响其他渠道和整个系统的正常运行。
第二个关键设计点是路由绑定机制。通过bindings配置文件,开发者可以灵活定义不同场景下的Agent匹配规则,并且按照预设的优先级进行匹配,确保消息能够被最适合的Agent处理。比如,开发者可以为某个重要用户设置专属Agent,让该用户的所有消息都由专属Agent处理;也可以为某个Discord服务器设置特定的Agent,处理该服务器内的所有消息,这种灵活的路由机制,让OpenClaw能够适配各种复杂的使用场景。
第三个关键设计点是会话管理。通过sessionKey追踪整个会话的状态,无论是用户的连续提问,还是Agent的工具调用,都能通过sessionKey关联到同一个会话,确保会话的连贯性。比如,用户发送一条消息后,又发送了补充消息,OpenClaw通过sessionKey能够识别出这两条消息属于同一个会话,Agent会结合两条消息的内容进行处理,而不是孤立地处理每条消息,提升了AI回复的准确性和连贯性。
第四个关键设计点是统一发送逻辑。所有渠道的回复发送,都通过src/infra/outbound/deliver.ts文件中的统一逻辑处理,该模块会根据不同渠道的特性,对回复内容进行格式化,确保回复能够在对应的渠道正常显示。这种统一化的设计,减少了代码冗余,同时也方便后续对回复发送逻辑进行修改和优化,比如新增附件发送功能时,只需修改统一的发送逻辑,所有渠道都能支持该功能。
二、Web UI消息流程:与外部渠道的异同解析
除了支持WhatsApp、Discord等外部渠道,OpenClaw还提供了Web UI端,用户可以通过浏览器访问Web界面,直接与AI助手进行交互。Web UI端的消息处理流程,与外部渠道既有相同之处,也有明显的区别,核心差异在于消息的传输通道和入口方法,而内部的路由机制和回复处理逻辑则保持一致,这也是OpenClaw"统一化管理"理念的体现。
2.1 Web UI消息完整链路图
Web UI端的消息处理流程,从用户在前端发送消息,到后端处理完成并返回回复,整个链路分为前端发送、WebSocket传输、网关处理、消息分发、路由解析、Agent执行、回复返回、前端展示八个环节,每个环节都有对应的核心文件和具体逻辑,具体链路如下:
首先是前端发送环节,位于ui/src/ui/controllers/chat.ts文件中,当用户在Web UI的聊天框中输入消息并点击发送时,会调用该文件中的sendChatMessage()函数,该函数会通过client.request("chat.send", ...)方法,将消息封装成JSON-RPC格式,发送给WebSocket客户端。
第二步是WebSocket传输环节,前端的WebSocket客户端位于ui/src/ui/gateway.ts文件中,通过GatewayBrowserClient.request()方法,将封装好的JSON-RPC消息,通过WebSocket协议发送到后端的网关服务端。WebSocket协议的优势在于能够实现双向通信,实时传输数据,确保消息能够快速发送和接收,提升Web UI端的交互体验。
第三步是网关处理环节,后端的网关服务端位于src/gateway/server-methods/chat.ts文件中,该文件中的chatHandlers"chat.send"函数会接收WebSocket客户端发送的消息,首先对消息参数进行验证,确保消息格式正确、参数完整;然后解析消息中的附件(如图片、文件),将附件转换为系统可处理的格式;接着加载对应的会话信息,通过sessionKey关联到对应的会话;最后检查消息中是否包含停止命令,如果没有停止命令,就调用消息分发模块的dispatchInboundMessage()函数,将消息传递给后续模块处理。
第四步是消息分发环节,与外部渠道的消息处理逻辑一致,位于src/auto-reply/dispatch.ts文件中的dispatchInboundMessage()函数,会对接收到的消息进行进一步处理,然后调用dispatchReplyFromConfig()函数,将消息传递给路由解析模块。
第五步是路由解析环节,同样与外部渠道使用相同的路由解析函数,位于src/routing/resolve-route.ts文件中的resolveAgentRoute()函数,会根据系统的bindings配置,按照预设的优先级规则,匹配对应的Agent,确定Agent ID和会话信息,确保消息能够被正确的Agent处理。
第六步是Agent执行环节,与外部渠道的逻辑一致,位于src/agents/pi-embedded-runner/目录下的Agent执行模块,会启动对应的AI Agent,处理消息内容,调用必要的工具,生成回复内容。
第七步是回复返回环节,Agent生成的回复内容,会被传递回src/gateway/server-methods/chat.ts文件中,通过broadcastChatFinal()函数或broadcastChatEvent()函数,将回复内容封装成WebSocket事件,然后通过WebSocket协议发送回前端的WebSocket客户端。这里需要注意的是,回复会分为"delta"状态和"final"状态,"delta"状态用于更新流式文本(比如AI回复实时生成、逐字显示),"final"状态用于加载完整的聊天历史,显示最终的回复内容,提升用户的交互体验。
第八步是前端展示环节,前端的ui/src/ui/controllers/chat.ts文件中的handleChatEvent()函数,会接收后端发送的WebSocket事件,根据事件的状态(delta或final),更新聊天界面,将AI回复显示在聊天框中,用户就能看到回复内容并继续进行交互。
2.2 Web UI消息处理的关键文件位置
为了方便开发者快速定位Web UI消息处理的相关代码,我们整理了各个环节对应的核心文件和说明,具体如下:
前端发送环节的核心文件是ui/src/ui/controllers/chat.ts,其中第75行的sendChatMessage()函数,负责将用户输入的消息封装并发送给WebSocket客户端;WebSocket客户端的核心文件是ui/src/ui/gateway.ts,其中第289行的GatewayBrowserClient.request()函数,负责通过WebSocket协议将消息发送到后端网关;网关处理环节的核心文件是src/gateway/server-methods/chat.ts,其中第704行的chatHandlers"chat.send"函数,负责接收和处理前端发送的消息;消息分发环节的核心文件是src/auto-reply/dispatch.ts,其中的dispatchInboundMessage()函数,负责协调后续的路由解析和Agent执行;路由解析环节的核心文件是src/routing/resolve-route.ts,其中第295行的resolveAgentRoute()函数,负责匹配对应的Agent;前端接收和展示环节的核心文件是ui/src/ui/controllers/chat.ts,其中第185行的handleChatEvent()函数,负责接收后端的回复并更新前端界面。
2.3 Web UI与外部渠道的异同对比
Web UI端和外部渠道的消息处理流程,核心差异在于消息的传输通道和入口方法,而内部的路由机制、Agent执行、回复处理逻辑则保持一致,这种设计既保证了系统行为的一致性,也兼顾了不同渠道的特性。具体的异同对比如下:
(一)不同点
首先是传输通道不同,Web UI端采用WebSocket协议(JSON-RPC格式)进行消息传输,能够实现双向实时通信,适合前端与后端的实时交互;而外部渠道(如WhatsApp、Discord)则通过各自平台的API或SDK进行消息传输,不同渠道的传输协议和格式各不相同,需要通过对应的插件进行适配。
其次是入口方法不同,Web UI端的消息入口是chat.send方法,通过前端的sendChatMessage()函数触发,消息封装成JSON-RPC格式后发送到后端网关;而外部渠道的消息入口是各自的渠道监听器,比如Discord渠道的入口是DiscordMessageListener,通过监听平台的消息事件触发,消息经过预处理后直接传递给消息分发模块。
第三是回复方式不同,Web UI端的回复通过WebSocket事件流返回,分为"delta"和"final"两种状态,能够实现流式显示,提升用户体验;而外部渠道的回复则通过各自平台的发送API返回,按照平台的格式要求进行展示,无需区分流式状态。
第四是Session Key的获取方式不同,Web UI端的Session Key是直接使用前端传递的会话信息生成,无需通过bindings配置解析;而外部渠道的Session Key则需要通过resolveAgentRoute函数,根据bindings配置解析生成,与渠道、用户、服务器等信息相关联。
第五是内部channel标识不同,Web UI端的内部channel标识为"internal"或"webchat",用于区分Web UI端和其他外部渠道;而外部渠道的内部channel标识则是实际的渠道名(如"whatsapp""discord"),方便系统识别不同的渠道。
(二)相同点
首先是使用相同的路由解析函数,无论是Web UI端还是外部渠道,最终都会调用src/routing/resolve-route.ts文件中的resolveAgentRoute函数(Web UI端通过resolveSessionAgentId函数间接调用,核心逻辑一致),按照相同的优先级规则匹配Agent,确保路由机制的一致性。比如,外部渠道在src/web/auto-reply/monitor/on-message.ts文件中直接调用resolveAgentRoute函数,传入渠道、账户ID、用户信息等参数,获取路由结果;而Web UI端在src/gateway/server-methods/chat.ts文件中调用resolveSessionAgentId函数,该函数内部会使用与resolveAgentRoute相同的逻辑,匹配对应的Agent ID。
其次是共享相同的路由规则,路由规则都在系统的配置文件中定义,对所有渠道(包括Web UI端)都统一生效,开发者只需修改一份配置文件,就能调整所有渠道的Agent匹配规则,无需分别配置,极大地提升了配置效率。路由解析的核心逻辑的是通过tiers数组定义匹配优先级,数组中的每一项对应一种匹配方式,包括匹配条件和判断逻辑,所有渠道都会按照这个数组的顺序进行匹配。
第三是使用统一的回复处理逻辑,无论是Web UI端还是外部渠道,Agent生成的回复内容,都会通过相同的回复处理逻辑进行处理,确保回复内容的规范性。比如,Web UI端在src/gateway/server-methods/chat.ts文件中,通过params.replyResolver或getReplyFromConfig函数处理回复;而外部渠道在src/web/auto-reply/monitor/process-message.ts文件中,通过params.replyResolver函数处理回复,两者的核心逻辑完全一致。
2.4 总结
Web UI端和外部渠道的消息处理流程,虽然在传输通道、入口方法等方面存在差异,但核心的路由机制、Agent执行和回复处理逻辑保持一致,这种设计既保证了系统行为的统一性,让开发者能够统一管理所有渠道的消息处理,也兼顾了不同渠道的特性,提升了用户体验。同时,这种模块化、统一化的设计,也为后续扩展新的渠道或优化消息处理逻辑提供了便利,体现了OpenClaw架构设计的合理性和可扩展性。
三、Pi Agent核心能力:LLM调用与本地命令执行机制
Pi Agent是OpenClaw的AI核心,负责处理用户的消息请求,生成智能回复,同时具备调用LLM和执行本地命令的能力,能够完成各种复杂的任务,比如代码编写、文件编辑、系统管理等。Pi Agent的LLM调用机制和本地命令执行机制,是其核心竞争力所在,也是OpenClaw能够灵活适配各种使用场景的关键。接下来,我们将详细解析Pi Agent如何调用LLM和执行本地命令,包括核心流程、关键文件、安全机制等细节。
3.1 LLM调用机制:连接大语言模型,实现智能回复
LLM(大语言模型)是AI助手实现智能交互的基础,OpenClaw的Pi Agent支持多种LLM模型,包括OpenAI/GPT-4o、Anthropic Claude 3、Google Gemini、Ollama(本地模型)、GitHub Copilot等,开发者可以通过配置文件灵活选择使用的模型,满足不同的需求。Pi Agent调用LLM的核心流程分为初始化Agent会话、配置模型和工具、发送提示给LLM三个步骤,每个步骤都有明确的实现逻辑。
(一)核心流程
第一步,初始化Agent会话。当Pi Agent接收到消息分发模块传递的消息后,首先会初始化一个Agent会话,通过createAgentSession函数创建会话实例,该函数会传入会话管理器(sessionManager)、设置管理器(settingsManager)等配置参数,会话实例用于管理整个LLM调用过程中的会话状态,包括消息历史、工具调用记录等。
第二步,配置模型和工具。会话初始化完成后,会根据系统配置的模型参数,配置LLM的调用方式。如果配置的模型API是"ollama"(本地模型),则会调用createOllamaStreamFn函数,创建Ollama模型的流式调用函数;如果是其他模型(如OpenAI、Anthropic),则会使用@mariozechner/pi-ai库中的streamSimple函数,实现通用的LLM流式调用。这种配置方式,使得开发者能够灵活切换不同的LLM模型,无需修改核心代码。
第三步,发送提示给LLM并获取回复。配置完成后,通过activeSession.prompt函数,将经过处理的消息提示(effectivePrompt)发送给LLM,同时可以传入图片等附件(如果有),LLM会根据提示内容生成回复,并通过流式方式返回给Pi Agent,Pi Agent会将回复内容整理后,传递给回复发送模块,最终发送给用户。
(二)关键实现位置
LLM调用机制的核心文件和位置如下:LLM配置的核心代码位于src/agents/pi-embedded-runner/run/attempt.ts文件的第612-634行,负责根据系统配置,初始化LLM的调用参数和方式;模型解析的核心文件是src/agents/pi-embedded-runner/model.ts,负责解析配置文件中的模型参数,确定模型的提供者和调用方式;会话管理依赖@mariozechner/pi-coding-agent库的SessionManager,负责管理Agent会话的状态;Ollama本地模型的调用逻辑位于src/agents/ollama-stream.ts文件中,实现Ollama模型的流式调用;通用LLM调用则依赖@mariozechner/pi-ai库的streamSimple函数,实现对OpenAI、Anthropic等模型的调用。
(三)支持的模型提供者
OpenClaw的Pi Agent支持多种主流的LLM模型提供者,包括OpenAI(GPT-4o等模型)、Anthropic(Claude 3等模型)、Google(Gemini等模型)、Ollama(本地部署的模型,如Llama 3、Qwen等)、GitHub Copilot(代码相关的模型),同时也支持通过配置文件定义其他自定义的模型提供者,满足开发者的个性化需求。这种多模型支持的设计,使得OpenClaw能够适配不同的使用场景,比如需要本地部署、注重隐私的场景,可以选择Ollama本地模型;需要高精度回复的场景,可以选择GPT-4o或Claude 3等模型。
3.2 本地命令执行机制:调用系统工具,完成复杂任务
除了调用LLM生成智能回复,Pi Agent还具备执行本地命令的能力,能够调用系统工具,完成文件编辑、代码编写、系统管理等复杂任务,这也是OpenClaw区别于其他普通AI助手的重要特性。Pi Agent的本地命令执行机制,通过创建专门的工具实例,实现对本地命令的安全调用,同时具备完善的安全机制,确保系统安全。
(一)核心工具创建
Pi Agent的本地命令执行,依赖于专门的工具实例,这些工具实例在src/agents/pi-tools.ts文件中创建,通过createOpenClawCodingTools函数,传入执行配置(execOverrides)、沙箱配置(sandbox)等参数,生成工具实例。工具实例包含多种类型的工具,能够满足不同的本地命令执行需求。
(二)工具类型
Pi Agent支持的工具类型主要分为四类:第一类是编码工具,用于读取、写入、编辑文件,比如读取本地的代码文件、修改配置文件、创建新的代码文件等,方便开发者进行代码开发相关的操作;第二类是执行工具,位于src/agents/bash-tools.exec.ts文件中,用于执行shell命令,比如ls(查看目录)、cat(查看文件内容)、git(版本控制)等,能够直接操作系统终端;第三类是进程工具,位于src/agents/bash-tools.process.ts文件中,用于管理长期运行的进程,比如启动、停止、重启某个服务进程,监控进程的运行状态等;第四类是OpenClaw特定工具,位于openclaw-tools.ts文件中,用于浏览器操作、发送消息等与OpenClaw系统相关的操作。
(三)命令执行流程
本地命令的执行流程,核心逻辑位于src/agents/bash-tools.exec-runtime.ts文件中的runExecProcess函数,该函数会接收命令参数、工作目录、环境变量、沙箱配置等参数,按照以下步骤执行命令:
第一步,安全检查和环境准备。首先调用validateHostEnv函数,对执行命令的环境变量进行安全检查,过滤掉危险的环境变量,确保命令执行的安全性;同时准备命令执行所需的环境,包括工作目录、环境变量等。
第二步,执行命令。根据是否启用沙箱配置,选择不同的执行方式:如果启用了沙箱(Docker),则会构建Docker执行参数,通过Docker容器执行命令,确保命令执行在隔离的环境中,不会影响宿主系统;如果没有启用沙箱,则直接通过childProcess.spawn函数,在宿主系统中执行命令。
第三步,输出处理和更新。命令执行过程中,会通过child.stdout.on('data')和child.stderr.on('data')事件,实时捕获命令的标准输出和错误输出,然后通过回调函数将输出内容返回给Pi Agent,Pi Agent会将输出内容整理后,传递给用户,让用户实时了解命令执行的情况。
第四步,结果返回。命令执行完成后,返回一个进程句柄(ExecProcessHandle),包含命令执行的状态、输出内容、错误信息等,Pi Agent会根据进程句柄中的信息,判断命令执行是否成功,并将结果反馈给用户。
(四)安全机制
本地命令执行涉及系统安全,因此OpenClaw设计了完善的安全机制,确保命令执行的安全性,防止恶意命令或误操作对系统造成损坏,主要包括以下四个方面:
第一,白名单检查。通过evaluateShellAllowlist函数,检查执行的命令是否在安全白名单中,只有白名单中的命令才能被执行,黑名单中的命令会被拒绝执行,有效防止恶意命令的执行。开发者可以通过配置文件,灵活修改白名单中的命令,适配自己的使用需求。
第二,沙箱执行。支持Docker沙箱,将命令执行在Docker容器中,容器与宿主系统隔离,即使命令执行出现问题,也不会影响宿主系统的安全,适合执行一些不确定安全性的命令。
第三,权限分级。根据系统配置,将命令执行的安全级别分为三级:deny(禁止执行所有本地命令)、allowlist(只允许执行白名单中的命令)、full(允许执行所有命令),开发者可以根据自己的需求,选择合适的安全级别,平衡安全性和灵活性。
第四,审计日志。会记录所有执行的本地命令,包括命令内容、执行时间、执行结果、执行用户等信息,方便开发者后续查看命令执行记录,排查问题,同时也能起到追溯作用,防止恶意操作。
(五)关键实现位置
本地命令执行机制的核心文件和位置如下:工具创建的核心文件是src/agents/pi-tools.ts,负责生成各种类型的工具实例;执行工具的核心文件是src/agents/bash-tools.exec.ts,定义执行shell命令的基础逻辑;执行运行时的核心文件是src/agents/bash-tools.exec-runtime.ts,负责命令的实际执行和输出处理;进程管理的核心文件是src/agents/bash-tools.process.ts,负责长期运行进程的管理;执行审批的核心文件是src/infra/exec-approvals.ts,负责对命令执行进行审批(如果配置了审批模式)。
3.3 工具调用流程:Agent与工具的交互逻辑
Pi Agent与工具的交互,核心逻辑位于src/agents/pi-embedded-subscribe.subscribe-embedded-pi-session.ts文件中的subscribeEmbeddedPiSession函数,该函数会创建一个订阅实例,监听Agent的工具调用事件,并处理工具执行的结果,具体流程如下:
首先,创建订阅实例,传入Agent会话(activeSession)、运行ID(runId)以及各种回调函数,其中onToolResult回调函数用于处理工具执行的结果。
然后,当Pi Agent需要调用工具时,会触发工具执行事件,订阅实例会监听到该事件,并调用对应的工具实例,执行工具操作(如执行本地命令、编辑文件等)。
工具执行过程中,会通过回调函数实时将执行状态和输出内容反馈给Pi Agent,Pi Agent会将这些信息整理后,传递给用户,让用户实时了解工具执行的情况。
工具执行完成后,会触发工具执行结束事件,订阅实例会调用onToolResult回调函数,将工具执行的结果(成功、失败、输出内容等)传递给Pi Agent,Pi Agent会根据工具执行的结果,继续处理用户的消息,生成最终的回复。
此外,订阅实例还会处理工具调用过程中的错误,比如工具执行失败、命令不存在等,会捕获这些错误,并将错误信息反馈给Pi Agent,Pi Agent会将错误信息整理后,告知用户,同时尝试进行错误恢复(如重试命令、提示用户修改命令等)。
3.4 配置和策略
Pi Agent的LLM调用和本地命令执行,都可以通过配置文件灵活配置,开发者可以根据自己的需求,修改配置参数,调整Agent的行为,主要包括工具策略配置和沙箱配置。
(一)工具策略配置
工具策略配置位于config.yaml文件中的tools节点,主要包括安全模式(security)、审批模式(ask)、安全命令白名单(safeBins)等参数,具体配置示例如下:
tools:
exec:
security: allowlist # 安全模式,可选deny、allowlist、full
ask: on-miss # 审批模式,当命令不在白名单中时,询问用户是否允许执行
safeBins: # 安全命令白名单,只有这些命令才能被执行
-
ls
-
cat
-
git
通过修改这些配置参数,开发者可以灵活调整本地命令执行的安全策略,平衡安全性和灵活性。
(二)沙箱配置
沙箱配置位于config.yaml文件中的sandbox节点,主要包括是否启用沙箱(enabled)、容器名称(containerName)、容器工作目录(containerWorkdir)等参数,具体配置示例如下:
sandbox:
enabled: true
containerName: openclaw-sandbox
containerWorkdir: /workspace
启用沙箱后,所有本地命令都会在Docker容器中执行,容器与宿主系统隔离,确保系统安全;容器工作目录用于指定命令执行的默认工作目录,方便开发者管理文件。
3.5 总结
Pi Agent作为OpenClaw的AI核心,通过完善的LLM调用机制和本地命令执行机制,实现了智能回复和复杂任务处理的双重能力。LLM调用机制支持多种模型,能够灵活适配不同的智能交互需求;本地命令执行机制具备完善的工具类型和安全机制,能够安全、高效地执行本地命令,完成文件编辑、系统管理等复杂任务。两者通过统一的工具接口实现交互,同时支持通过配置文件灵活调整策略,使得OpenClaw能够适配各种复杂的使用场景,成为开发者提升效率的重要工具。
四、定时任务系统:从创建到清理的全生命周期解析
除了实时消息处理和AI交互,OpenClaw还提供了强大的定时任务系统,支持一次性任务、周期性任务和Cron表达式任务,能够自动执行预设的任务,比如定时发送消息、定时执行本地命令、定时触发AI交互等,极大地提升了系统的自动化水平。OpenClaw的定时任务系统设计完善,实现了从任务创建、存储、调度、执行,到结果处理、更新删除、清理的完整生命周期管理,同时具备高可靠性和良好的扩展性。接下来,我们将详细解析定时任务的全生命周期,包括各个阶段的核心逻辑、关键文件和实现细节。
4.1 任务定义与配置:三种调度类型,灵活适配需求
OpenClaw的定时任务支持三种调度类型,分别是一次性任务、周期性任务和Cron表达式任务,开发者可以根据自己的需求,选择合适的调度类型,定义定时任务。三种调度类型的定义,位于src/cron/types.ts文件中的CronSchedule类型,具体如下:
第一种是一次性任务(kind: "at"),通过at参数指定任务的执行时间,支持ISO时间格式(如"2025-12-31T23:59:00")或duration格式(如"+1h"表示1小时后执行),任务执行一次后,会根据配置决定是否删除。
第二种是周期性任务(kind: "every"),通过everyMs参数指定任务的执行间隔(单位:毫秒),可选参数anchorMs用于指定任务的起始时间锚点,任务会按照指定的间隔,周期性地执行。
第三种是Cron表达式任务(kind: "cron"),通过expr参数指定Cron表达式(如"0 0 * * *"表示每天凌晨执行),可选参数tz用于指定时区,适合需要按照固定时间规律执行的任务(如每天固定时间备份文件、每周固定时间发送报告等)。
定时任务的配置信息,会存储在~/.openclaw/cron/目录下的JSON文件中,通过CronService服务进行统一管理,包括任务的创建、更新、删除、执行等操作,确保任务信息的持久化和可靠性。
4.2 调度器原理:定时器管理与调度策略
定时任务的调度器是整个定时任务系统的核心,负责管理定时任务的唤醒和执行,核心组件包括CronService、定时器管理和作业管理,同时具备完善的调度策略,确保任务能够按时、准确地执行。
(一)核心调度器组件
CronService是定时任务服务的主类,位于src/cron/service.ts文件中,负责统一管理定时任务的整个生命周期,包括任务的加载、调度、执行、结果处理等;定时器管理位于src/cron/service/timer.ts文件中,负责管理定时任务的唤醒,计算下一个任务的执行时间,启动定时器,确保任务能够按时触发;作业管理位于src/cron/service/jobs.ts文件中,负责任务的创建、更新、删除等操作,处理任务的配置和状态管理。
(二)调度策略
调度器的核心调度策略,位于src/cron/service/timer.ts文件中,主要包括最大定时器延迟、最小触发间隔和定时器武装逻辑,具体如下:
最大定时器延迟(MAX_TIMER_DELAY_MS)设置为60000毫秒(1分钟),也就是说,定时器的最大延迟时间不会超过1分钟,即使下一个任务的执行时间距离现在超过1分钟,定时器也会每1分钟唤醒一次,检查是否有任务需要执行,这样可以避免定时器延迟过长,导致任务无法按时执行,同时也能及时处理任务配置的变更。
最小触发间隔(MIN_REFIRE_GAP_MS)设置为2000毫秒(2秒),用于防止任务连续触发,确保任务执行有足够的间隔时间,避免多个任务同时执行,占用过多的系统资源。
定时器武装逻辑由armTimer函数实现,该函数会首先计算下一个任务的执行时间(nextAt),然后计算当前时间到下一个任务执行时间的延迟(delay),将延迟时间限制在最大定时器延迟范围内(clampedDelay),最后启动定时器,定时器到期后,会调用onTimer函数,触发任务执行,任务执行完成后,再重新武装定时器,循环往复,确保所有任务都能按时触发。
4.3 任务执行流程:从定时器触发到结果处理
定时任务的执行流程,核心逻辑位于src/cron/service/timer.ts文件中,分为定时器触发(onTimer函数)和任务执行(executeJobCore函数)两个核心步骤,同时包括任务查找、结果处理、会话清理等环节,具体流程如下:
(一)定时器触发(onTimer函数)
当定时器到期后,会调用onTimer函数,该函数是任务执行的入口,主要负责查找到期任务、执行任务、处理执行结果、重新武装定时器等操作,具体步骤如下:
第一步,防止重入。首先检查当前是否有任务正在执行(state.running),如果有,则重新启动定时器,延迟1分钟后再次触发,避免多个任务执行过程相互干扰。
第二步,查找到期任务。通过locked函数(确保操作原子性),加载最新的任务列表,查找到期的任务(findDueJobs函数),然后更新到期任务的状态,将runningAtMs设置为当前时间(表示任务正在执行),并将任务状态持久化到存储文件中。
第三步,执行任务。遍历所有到期的任务,调用executeJobCore函数,执行每个任务,记录任务的开始时间(startedAt)和结束时间(endedAt),收集任务执行结果(results数组)。
第四步,处理执行结果。再次通过locked函数,遍历任务执行结果,更新每个任务的状态(包括最后执行时间、执行状态、执行时长、连续错误次数、下次执行时间等),如果是一次性任务且执行成功,根据配置决定是否删除该任务,最后将任务状态持久化到存储文件中。
第五步,会话清理。调用sweepCronRunSessions函数,清理过期的定时任务会话,释放系统资源,确保系统的稳定性。
第六步,重新武装定时器。任务执行和结果处理完成后,将state.running设置为false,调用armTimer函数,重新启动定时器,准备下一次任务触发。
(二)任务执行(executeJobCore函数)
executeJobCore函数是任务执行的核心,负责根据任务的配置,执行具体的任务逻辑,支持主会话任务和隔离会话任务两种执行方式,具体如下:
第一种是主会话任务(sessionTarget: "main"),这种任务会发送系统事件,将任务执行的相关信息(如任务内容、执行状态)发送到主会话中,方便用户查看。同时,根据任务的wakeMode配置("now"或其他),决定是否立即执行心跳(runHeartbeatOnce函数)或请求立即执行心跳(requestHeartbeatNow函数),触发AI处理。
第二种是隔离会话任务(sessionTarget: "isolated"),这种任务会在隔离的会话中执行AI代理对话,不会影响主会话的上下文,通过调用state.deps.runIsolatedAgentJob函数,传入任务信息和消息内容,执行AI任务,生成任务执行结果。
4.4 执行入口:CLI命令与网关API
OpenClaw的定时任务提供了两种执行入口,分别是CLI命令和网关API,开发者可以根据自己的需求,选择合适的方式管理定时任务,具体如下:
(一)CLI命令
通过CLI命令,开发者可以在终端中直接管理定时任务,包括查看任务状态、列出所有任务、添加任务、立即运行任务等,常用的CLI命令如下:
-
查看任务状态:pnpm openclaw cron status,用于查看当前定时任务服务的运行状态,包括是否正在运行、当前有多少个任务等。
-
列出所有任务:pnpm openclaw cron list,用于列出所有已创建的定时任务,包括任务ID、调度类型、下次执行时间、执行状态等信息。
-
添加任务:pnpm openclaw cron add --at "2025-12-31T23:59:00" --message "Happy New Year!",用于添加一个一次性任务,指定执行时间和任务内容。
-
立即运行任务:pnpm openclaw cron run ,用于手动触发某个定时任务的执行,无论该任务是否到期,适合调试和紧急任务执行。
(二)网关API
通过网关API,开发者可以通过编程方式管理定时任务,将定时任务的管理集成到自己的应用程序中,网关API位于src/gateway/server-methods/cron.ts文件中,定义了多种网关请求处理函数,具体如下:
-
"cron.list":用于列出所有定时任务,返回任务的详细信息。
-
"cron.add":用于添加新的定时任务,接收任务配置参数,返回任务ID和创建结果。
-
"cron.run":用于手动触发某个定时任务的执行,接收任务ID,返回任务执行状态。
-
"cron.status":用于查看定时任务服务的运行状态,返回服务状态和任务统计信息。
4.5 任务全生命周期:从创建到清理的八个阶段
OpenClaw的定时任务实现了完整的生命周期管理,从任务创建到清理,共分为八个阶段,每个阶段都有明确的核心逻辑和关键文件,确保任务能够有序、可靠地执行,具体如下:
(一)任务创建阶段
任务创建是定时任务生命周期的开始,支持三种创建入口:CLI命令(pnpm openclaw cron add)、API调用(cron.add网关方法)和UI操作(通过Web UI或应用程序界面)。创建流程的核心逻辑位于src/cron/service/jobs.ts文件中的createJob函数,该函数会接收任务创建参数(input),生成任务实例(CronJob),设置任务的ID、调度类型、 payload、Agent ID、会话信息等参数,初始化任务状态(包括下次执行时间、连续错误次数等),然后将任务实例添加到任务列表中,完成任务创建。
任务创建完成后,会进行任务验证,确保任务配置的合法性,核心函数包括src/cron/normalize.ts文件中的normalizeCronJobCreate函数(用于规范化任务创建参数)和src/cron/validate-timestamp.ts文件中的validateScheduleTimestamp函数(用于验证任务执行时间的合法性),如果任务配置不合法,会返回错误信息,提示开发者修改配置。
(二)任务存储阶段
任务创建并验证通过后,会被持久化存储到本地文件中,确保任务信息不会丢失。存储位置默认是~/.openclaw/cron/目录,文件格式为JSON,存储接口位于src/cron/store.ts文件中,核心函数是saveCronStore函数,该函数会首先创建存储目录(如果不存在),然后将任务列表(CronStore)转换为JSON字符串,写入到存储文件中,完成任务的持久化。
(三)任务调度阶段
任务存储完成后,调度器会对任务进行调度,准备任务的执行。调度器初始化的核心逻辑位于src/cron/service/ops.ts文件中的start函数,该函数会首先加载存储的任务列表,清除过期的运行标记(确保任务状态正确),运行错过的任务(runMissedJobs函数),重新计算所有任务的下次运行时间(recomputeNextRuns函数),将任务状态持久化,然后调用armTimer函数,启动定时器,完成调度器的初始化,开始对任务进行调度。
定时器管理由armTimer函数实现,该函数会不断计算下一个任务的执行时间,启动定时器,确保任务能够按时触发,具体逻辑在前面的调度器原理中已经详细介绍。
(四)任务执行阶段
当定时器到期后,会触发任务执行阶段,核心逻辑由onTimer函数和executeJobCore函数实现,具体流程在前面的任务执行流程中已经详细介绍。该阶段主要完成到期任务的查找、任务的实际执行、执行过程的监控等操作,确保任务能够按照配置的逻辑执行。
(五)结果处理阶段
任务执行完成后,会进入结果处理阶段,核心逻辑由applyJobResult函数和appendCronRunLog函数实现。applyJobResult函数会根据任务的执行结果,更新任务的状态,包括最后执行时间、执行状态、执行时长、连续错误次数、下次执行时间等;如果任务执行失败,会采用指数退避策略,计算下次执行时间(避免重试风暴);如果是一次性任务且执行成功,根据配置决定是否删除该任务。
appendCronRunLog函数会将任务执行的结果(包括任务ID、执行时间、执行状态、错误信息等)记录到日志文件中,方便开发者后续查看和排查问题,日志文件存储在指定的目录下,支持后续的日志分析和追溯。
(六)任务更新与删除阶段
任务执行完成后,根据任务的配置和执行结果,会进入任务更新或删除阶段。任务更新的核心逻辑位于src/cron/service/jobs.ts文件中的patchJob函数,该函数会根据任务ID,查找对应的任务,合并任务更新参数(patch),重新计算任务的下次运行时间,完成任务的状态更新和配置更新,最后将更新后的任务列表持久化到存储文件中。常见的更新场景包括:周期性任务执行后更新下次执行时间、任务执行失败后更新连续错误次数、修改任务的消息内容或执行逻辑等。
任务删除分为主动删除和自动删除两种场景。主动删除可通过CLI命令(pnpm openclaw cron delete )、网关API(cron.delete方法)或UI操作触发,核心逻辑位于src/cron/service/jobs.ts文件中的deleteJob函数,该函数会根据任务ID,从任务列表中移除对应的任务,然后调用saveCronStore函数,将更新后的任务列表持久化,完成任务删除。自动删除主要针对一次性任务,当一次性任务执行成功后,若配置中未指定保留任务,则系统会自动将其删除;若任务执行失败且达到最大重试次数,也会根据配置自动删除,避免无效任务占用系统资源。
(七)任务监控阶段
定时任务在整个生命周期中,会被持续监控,确保任务执行的可靠性和稳定性,监控逻辑主要体现在两个方面:一是任务执行状态监控,二是任务异常监控。
任务执行状态监控通过记录任务的runningAtMs、startedAt、endedAt等时间戳,实时跟踪任务的执行进度,若任务执行时间过长(超过预设阈值),系统会标记任务为异常状态,并通过日志记录异常信息,方便开发者排查问题。任务异常监控主要针对任务执行失败、定时器异常、存储文件损坏等场景,当任务执行失败时,系统会记录连续错误次数,采用指数退避策略重试任务(如第一次重试间隔10秒,第二次间隔20秒,依次递增),若达到最大重试次数仍失败,则停止重试并标记任务为失败状态;若定时器异常或存储文件损坏,系统会触发容错机制,重新加载任务列表、重启定时器,确保任务调度能够恢复正常。
监控相关的核心文件包括src/cron/service/timer.ts(定时器异常处理)、src/cron/store.ts(存储文件校验与修复)和日志记录模块,日志会详细记录每个任务的执行状态、异常信息、重试次数等,为问题排查提供有力支撑。
(八)任务清理阶段
任务清理是定时任务生命周期的最后一个阶段,主要负责清理过期任务、无效任务和过期会话,释放系统资源,确保系统的高效运行。清理逻辑主要由两个核心函数实现:一是sweepCronRunSessions函数,二是sweepExpiredJobs函数。
sweepCronRunSessions函数位于src/cron/service/ops.ts文件中,主要负责清理过期的定时任务会话,会话过期时间可通过配置文件设置,默认情况下,会话会在任务执行完成后保留一段时间(如24小时),超过该时间后,函数会自动删除过期会话,释放内存资源。sweepExpiredJobs函数同样位于src/cron/service/ops.ts文件中,负责清理无效任务和过期任务,包括执行失败且达到最大重试次数的任务、已被标记为删除但未完成持久化的任务、过期的一次性任务等,该函数会定期执行(可通过配置设置清理频率),也可在任务执行完成后触发,确保系统中不存在无效的任务数据。
此外,任务清理阶段还会对存储文件进行优化,删除冗余数据、压缩日志文件,避免存储文件过大占用过多磁盘空间,确保存储系统的稳定运行。
4.6 关键设计亮点
OpenClaw的定时任务系统之所以能够实现高可靠性和良好的扩展性,得益于其几个关键的设计亮点,这些设计亮点贴合开发者的实际使用需求,解决了定时任务调度中的常见问题。
第一个设计亮点是多样化的调度类型,支持一次性、周期性和Cron表达式三种调度方式,同时支持ISO时间格式和duration格式的时间配置,能够适配各种复杂的定时场景,无论是简单的"1小时后执行",还是复杂的"每周一、三、五凌晨3点执行",都能通过简单配置实现。
第二个设计亮点是完善的容错机制,包括任务重试、定时器容错、存储容错等。任务执行失败时采用指数退避策略重试,避免重试风暴;定时器最大延迟限制为1分钟,确保任务能够及时触发,同时应对任务配置变更;存储文件损坏时,系统会自动校验并尝试修复,若修复失败则加载备份任务列表,确保任务数据不丢失。
第三个设计亮点是多入口管理,支持CLI命令、网关API和UI操作三种管理方式,开发者可以根据自己的使用场景灵活选择,无论是在终端快速调试,还是通过编程方式集成到应用程序中,都能高效管理定时任务。
第四个设计亮点是资源优化机制,通过任务自动删除、过期会话清理、存储文件优化等功能,减少无效任务和冗余数据对系统资源的占用,确保定时任务系统能够长期稳定运行,即使在任务数量较多的情况下,也能保持高效的调度和执行效率。
4.7 总结
OpenClaw的定时任务系统,通过完整的生命周期管理(创建、存储、调度、执行、结果处理、更新删除、监控、清理),实现了定时任务的高效、可靠调度,支持多样化的调度场景和多入口管理方式,同时具备完善的容错机制和资源优化机制,能够满足开发者对自动化任务的各种需求。其核心设计贴合模块化、统一化的架构理念,各个阶段的逻辑清晰、代码可追溯,开发者可以通过修改配置文件灵活调整任务策略,也可以通过扩展核心函数,实现自定义的定时任务逻辑,进一步提升系统的扩展性。定时任务系统与消息处理、Pi Agent等模块的协同工作,使得OpenClaw的自动化能力得到极大提升,成为一款功能全面、高效实用的个人AI助手。
五、整体架构总结与核心设计理念
通过对OpenClaw消息处理流程、Web UI消息链路、Pi Agent核心能力以及定时任务系统的全面解析,我们可以清晰地看到这款个人AI助手的底层架构逻辑------以"模块化设计、统一化管理"为核心,以"灵活扩展、安全可靠"为目标,将各个核心功能拆分为独立模块,同时通过统一的网关服务、路由机制和配置管理,实现模块间的无缝协同,构成一个完整、高效的系统。
从整体架构来看,OpenClaw的核心优势体现在三个方面:一是模块化与解耦设计,无论是外部渠道适配、Agent执行,还是定时任务调度,都采用独立模块实现,模块间通过标准化的接口交互,降低了代码耦合度,方便开发者扩展新功能、修改现有逻辑;二是统一化的核心机制,路由解析、回复处理、配置管理等核心逻辑对所有模块统一生效,确保系统行为的一致性,同时降低了开发和维护成本;三是灵活的扩展性与适配性,支持多种外部渠道、多种LLM模型、多种定时任务类型,开发者可以通过配置文件或插件扩展,适配自己的使用场景,满足个性化需求。
在核心设计理念上,OpenClaw始终围绕"开发者友好"和"实用性"展开:源码结构清晰,核心文件和关键函数定位明确,方便开发者阅读、调试和二次开发;提供多样化的功能和管理方式,无论是消息交互、AI调用,还是定时任务,都能满足开发者在工作和开发中的实际需求;完善的安全机制(本地命令白名单、沙箱执行、权限分级)和容错机制,确保系统运行的安全性和可靠性,避免因误操作或恶意命令造成损失。
对于开发者而言,理解OpenClaw的底层架构,不仅能够更好地使用这款AI助手提升工作效率,还能借鉴其模块化设计、路由机制、任务调度等核心实现逻辑,应用到自己的AI助手开发项目中。未来,随着AI技术的不断发展,OpenClaw也可能会在现有架构的基础上,新增更多功能模块(如多语言支持、更丰富的工具类型),进一步优化核心逻辑,提升系统的性能和扩展性。