RoPE(Rotary Position Embedding,旋转位置编码)是当前大语言模型(LLM)中最主流的位置编码方案(LLaMA/Qwen/GPT-NeoX 等均采用),核心解决了传统位置编码 "只抓绝对位置、长序列泛化差" 的痛点。下面从「核心作用→通俗原理→数学简化→核心优势」层层拆解,新手也能彻底理解。
一、RoPE 的核心作用
先明确:Transformer 本身是位置无关的(输入 token 打乱顺序,输出也会乱),必须通过 "位置编码" 给 token 注入位置信息,RoPE 的核心价值是:
- 编码「相对位置」而非绝对位置:两个 token 的语义关联只和它们的相对距离有关(比如 "我吃苹果" 中,"苹果" 和 "吃" 的距离是 1,不管整句话多长,这个相对关系不变),这更符合人类语言的逻辑;
- 超长上下文泛化能力:训练时用 4096 长度的序列,推理时能无缝扩展到 128k 甚至更长(比如 Qwen3 的 128k 上下文),无需重新训练;
- 无额外参数开销:只是对 Transformer 的 Query/Key 向量做 "旋转操作",不新增可训练参数,计算效率高。
对比传统位置编码(比如 GPT 的绝对位置嵌入):
- 传统方案:给每个位置分配一个固定向量,加到 token 的 Embedding 上,长序列(超过训练长度)泛化极差;
- RoPE:通过数学旋转实现位置编码,天然支持任意长度的序列。
二、RoPE 的算法原理(从通俗到数学)
1. 通俗理解:向量旋转的思想
把每个 token 的特征向量(比如 Attention 层的 Query/Key 向量)想象成二维平面上的向量,RoPE 的核心逻辑是:
- 不同位置的 token,其特征向量会被旋转不同的角度;
- 两个 token 向量的内积(Attention 计算的核心),只和它们的旋转角度差(即相对位置)有关,和绝对位置无关。
举个例子 - 位置 0 的 token 向量:旋转 0°;
- 位置 1 的 token 向量:旋转 θ°;
- 位置 2 的 token 向量:旋转 2θ°;
- 位置 1 和位置 0 的内积 → 角度差 θ°;
- 位置 2 和位置 1 的内积 → 角度差 θ°;
→ 不管绝对位置在哪,只要相对距离是 1,内积结果就一致,完美捕捉相对位置!
2. 数学简化(核心公式,新手友好版)
RoPE 的数学推导基于复数空间,但实际实现时只需要掌握核心步骤:
步骤 1:特征维度分组
Transformer 的 Attention 层中,每个头的特征维度是head_dim(比如 LLaMA2 是 128),RoPE 将维度两两分组(如第 0&1 维、第 2&3 维、...),每组共享一个旋转角度。
步骤 2:计算旋转角度
旋转角度由「位置 ID × 逆频率」决定,逆频率(inv_freq)的公式:
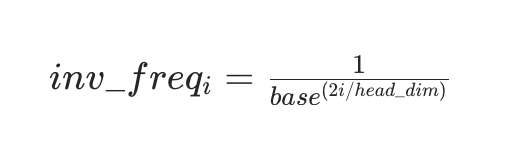
- base:超参数,默认 10000(RoPE 原始论文值);
- i:分组索引(0,1,2...,共head_dim/2组);
- head_dim:注意力头的维度。
位置pos的第i组旋转角度:
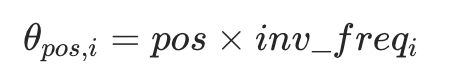
步骤 3:对 Query/Key 向量做旋转
对每组的两个维度(x, y)做旋转操作:
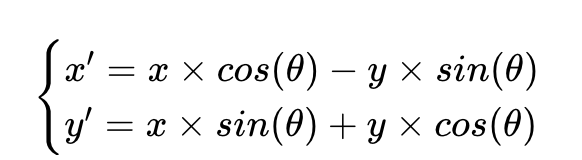
- (x,y):原始特征向量的某一组维度;
- (x',y'):旋转后的特征向量;
- θ:该位置对应的旋转角度。
3. 工程实现逻辑(呼应你之前看的Qwen3代码)
- 提前计算并缓存inv_freq(逆频率),避免每次推理重复计算;
- 输入序列的position_ids(每个token的位置ID)和inv_freq做矩阵乘法,得到每个位置的旋转角度;
- 计算角度的cos和sin矩阵(就是你之前代码中forward方法的输出);
- 用cos/sin矩阵对Attention层的Query/Key向量做旋转,完成位置信息注入。
三、RoPE的核心优势(为什么成为LLM标配)
- 相对位置感知:Attention计算的核心是Query和Key的内积,RoPE保证内积只依赖两个token的相对位置,而非绝对位置,更符合语言规律;
- 长度泛化性:训练时用短序列(如4096),推理时可处理超长序列(如128k),因为旋转角度是线性增长的,无需重新训练;
- 计算高效:仅需额外的cos/sin计算和向量旋转,无新增参数,对算力开销几乎可忽略;
- 兼容性强:可无缝集成到现有Transformer架构中,无需大幅修改模型结构。
四、RoPE的变体(拓展知识,面试高频)
为了适配更长的上下文,工业界衍生出RoPE的变体(比如Qwen3用到的):
- Dynamic RoPE:动态调整inv_freq,让长序列的旋转角度增长更平缓;
- NTK-Aware RoPE:修改base参数,提升超长序列的推理效果;
- ALiBi:RoPE的简化版,用偏置代替旋转,计算更轻量(Mistral模型采用)。
五、总结
- RoPE的核心作用:给LLM的token特征向量注入相对位置信息,解决传统位置编码长序列泛化差的问题;
- 核心原理:通过对特征向量做"旋转操作",让Attention内积只依赖token间的相对位置,旋转角度由「位置ID × 逆频率」计算;
- 核心优势:相对位置感知、超长上下文泛化、无额外参数、计算高效,成为LLaMA/Qwen等主流LLM的标配位置编码方案。
六、为什么能只感知相对位置
Transformer 注意力计算的核心是 Query (Q) 和 Key (K) 的内积,RoPE 通过数学设计,让旋转后的 Q_pos_i 和 K_pos_j 的内积,只依赖于位置差 j - i,和 i/j 的绝对位置无关。
下面从「通俗逻辑→数学证明→对比绝对编码」三层拆解,彻底讲透这个核心设计。
一、先明确:什么是 "相对位置编码"?
先给 "相对位置" 下一个可量化的定义,避免概念模糊:
- 绝对位置:token 的位置是 "孤立的"(比如 pos=3 就是第 3 个 token,和其他 token 无关);
- 相对位置:两个 token 的关联只和「位置差」有关(比如 token A 在 pos=1,token B 在 pos=3,位置差是 2;哪怕把 A 移到 pos=5、B 移到 pos=7,位置差还是 2,它们的语义关联应该不变)。
RoPE 的目标就是让:
- Attention(Q_pos_i, K_pos_j) = f(j - i)(只和位置差有关)
而非:
- Attention(Q_pos_i, K_pos_j) = f(i, j)(和两个绝对位置都有关)。
二、RoPE 实现相对位置的核心逻辑(数学 + 通俗)
我们用二维简化版(高维是二维分组的扩展,原理完全一致)证明,这也是 RoPE 原始论文的核心推导。
步骤 1:回顾 RoPE 的旋转公式(二维)
对位置为pos的 Q/K 向量(二维:x,y),RoPE 的旋转操作是:
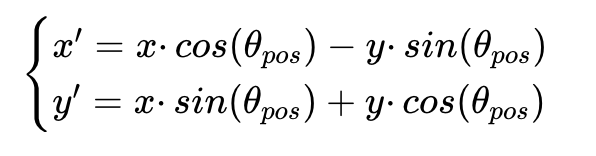
其中旋转角度 θpos=pos⋅θ(θ 是该维度组的基础角度,由逆频率决定)。
步骤 2:计算旋转后 Q 和 K 的内积(关键!)
假设:
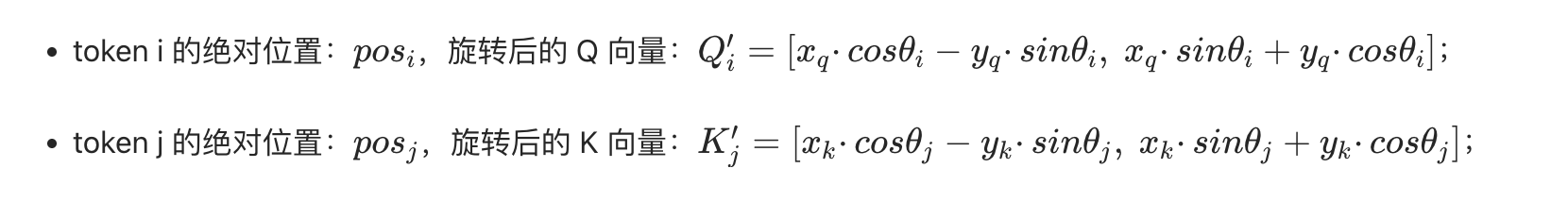
计算两者的内积 Qi′⋅Kj′:需要结合三角函数进行转换
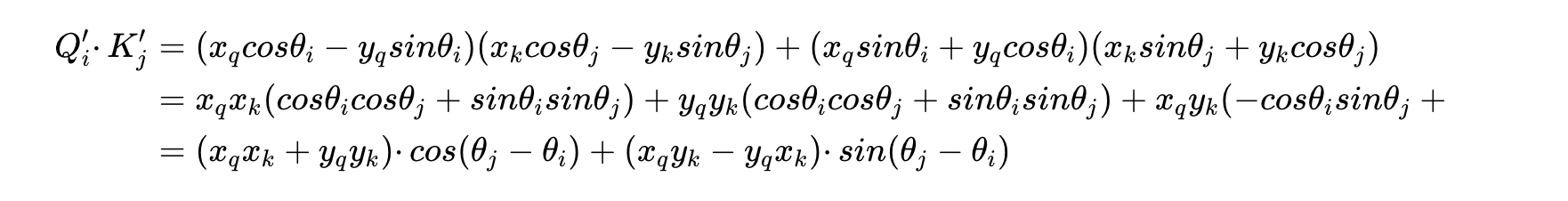
步骤 3:关键结论

三、对比绝对位置编码:为什么它做不到?
传统绝对位置编码(比如 GPT 的做法)是:
- 给每个绝对位置 pos 分配一个固定的位置向量 PEpos;
- 把 PEpos 加到 token 的 Embedding 上,得到 Embtoken+PEpos。
这种方式的问题:
- 内积结果是
Qi⋅Kj=(Embq+PEi)⋅(Embk+PEj)=Embq⋅Embk+Embq⋅PEj+PEi⋅Embk+PEi⋅PEj;
- 结果依赖 PEi 和 PEj(两个绝对位置的向量),而非位置差;
- 当序列长度超过训练时的 max_len(比如训练 4096,推理 128k),PE128k 从未见过,模型完全无法处理。
四、RoPE 的 "巧思" 总结
RoPE 没有新增任何参数,只是通过向量旋转的数学性质,让 Q/K 的内积天然只依赖位置差:
- 旋转角度和绝对位置成线性关系(θpos=pos⋅θ);
- 三角函数的和差公式,让内积结果最终只保留 "位置差" 的信息;
- 高维场景下,只需把特征维度两两分组,每组执行相同的旋转逻辑即可(这也是你之前看到 Qwen3 代码中torch.cat((freqs, freqs), dim=-1)的原因)。
总结
RoPE 实现相对位置编码的核心:旋转后的 Q/K 内积仅依赖「位置差」,而非绝对位置,这是三角函数和差公式的直接数学结果;
对比绝对编码:绝对编码的内积依赖两个绝对位置向量,RoPE 则通过旋转消去了绝对位置的影响;
工程上:只需提前计算 cos/sin 矩阵,对 Q/K 做简单的旋转运算,就能低成本实现相对位置感知,且支持超长序列泛化。
c
q = q * cosE + rotate_half(q) * sinE
q = (xq * cosi - yq * sini, xq * sini + yq * cosi)
k = (xk * cosj - yk * sinj, xk * sinj + yk * cosj)
q * k = (xq * cosi - yq * sini) * (xk * cosj - yk * sinj) + (xq * sini + yq * cosi) * (xk * sinj + yk * cosj)
= xq xk cosi cosj - xq yk cosi sinj - xk yq sini cosj + yq yk sini sinj
+ xq xk sini sinj + xq yk sini cosj + xk yq cosi sinj + yq yk cosi cosj
= xq xk (cosi cosj + sini sinj) + xq yk (sini cosj - cosi sinj) - xk yq (-cosi sinj + sini cosj) + yq yk (sini sinj + cosi cosj)
= (xq xk + yq yk) (cosi cosj + sini sinj) + (xq yk - xk yq) (sini cosj - cosi sinj)
= (xq xk + yq yk) cos(i -j) + (xq yk - xk yq) sin(i -j)
c
import torch
from torch import nn
class RopeEmbedding:
inv_feq: torch.Tensor
def __init__(self, head_dim):
base = 1E10
self.inv_feq = 1/ (base ** (torch.arange(0, head_dim, 2)/head_dim))
def forward(self, x, pos):
inv_freq_expend = self.inv_feq.unsqueeze(dim=-1)
freqs = torch.cat([inv_freq_expend, inv_freq_expend])
emb = (freqs @ pos.float()).transpose(1, 0)
cos = emb.cos()
sin = emb.sin()
return cos, sin
def retrayHalf(x):
x1 = x[..., 0:x.shape[-1]//2]
x2 = x[..., x.shape[-1]//2:]
return nn.cat([-x2, x1])
def applay_rope_embedding(q, k, cos, sin):
q_r = cos * q + retrayHalf(q) * sin
k_r = cos * k + retrayHalf(k) * sin
return q_r, k_r
head_dim = 16
pos = torch.arange(0, 10, 1).unsqueeze(dim=0).float()
print(pos)
ropeEmbedding = RopeEmbedding(head_dim)
cos, sin = ropeEmbedding.forward(None, pos)
print(cos)
print(sin)