快速导航
- 新建项目 "015-DrawInstanced"
- 纹理数组
-
- 纹理数组资源的创建
- 纹理数组到默认堆的复制
- [纹理数组 SRV 描述符的创建](#纹理数组 SRV 描述符的创建)
- [SRV StructuredBuffer 结构化缓冲](#SRV StructuredBuffer 结构化缓冲)
-
- 结构化缓冲资源的创建与复制
- [结构化缓冲到 SRV 根描述符的绑定](#结构化缓冲到 SRV 根描述符的绑定)
- 硬件实例化
-
- 什么是实例化
- 批绘制 (Batch Draw)
- 硬件实例化 (GPU Instancing)
- [IA 多槽输入与实例化资源的创建](#IA 多槽输入与实例化资源的创建)
- [Shader 着色器部分与渲染](#Shader 着色器部分与渲染)
- 第十五章全代码
教程代码资源:
dgaf 的 《DirectX 12 快速教程》配套代码 (A Sample of dgaf's DirectX 12 Quick Beginner Tutorial)

欢迎来到进阶篇第一章!在第 7-8 章,我们先后实现了画火柴盒与画玻璃,然而每画一个方块 (甚至画一个方块面) 就要切换一次 SRV 和 Draw Call。然而实际游戏的方块量比这多得多,用这种方法渲染的话会有很大的性能开销,造成游戏卡顿,最主要的原因就是频繁 Draw Call 产生高额的 CPU 固定开销和 GPU 流水线停顿。怎样才能尽可能的减少 DrawCall 呢?

不得不说,新版本更新对游戏的优化效果不错,ojang 这一回也当了一次人
新建项目 "015-DrawInstanced"
纹理数组
减少 DrawCall 的第一步,就是减少 SetGraphicsRootDescriptorTable 切换纹理到寄存器的次数!为什么呢?虽然这玩意的开销并不高,但是 DrawCall 期间寄存器是不能换绑纹理的!要么你就在下一次 DrawCall 之前调用 SetGraphicsRootDescriptorTable 切换纹理 (第 7-8 章我们所使用的方法,遇到工作台,熔炉这些三个面的方块,我们分三次渲染,每个方块三次 DrawCall):
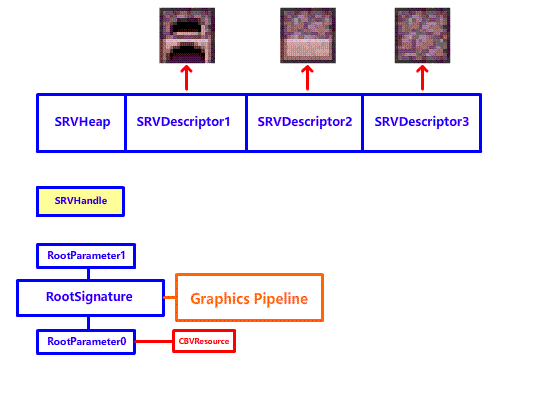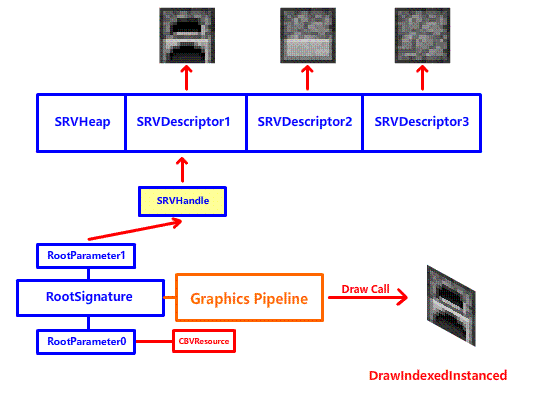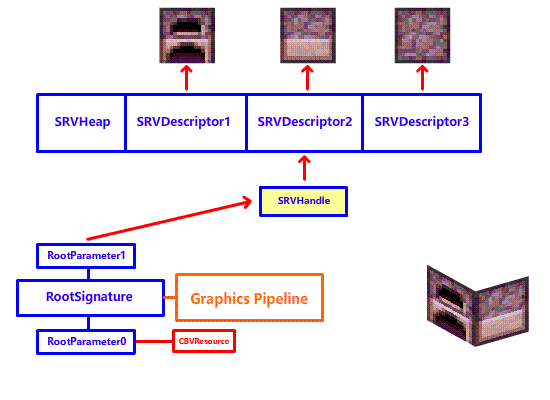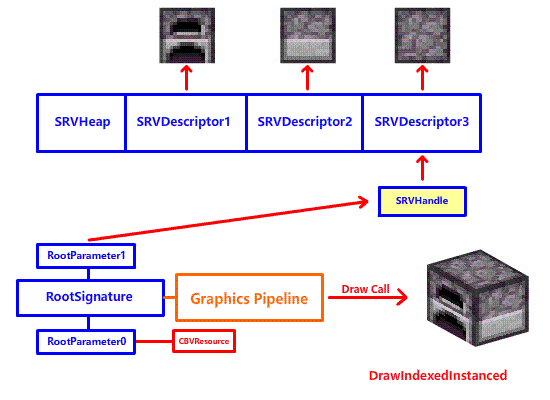
要么你就要用寄存器去堆,给所有用到的纹理都安排一个专用寄存器,然后一次 DrawCall:

很明显,两种方法都不行,前者会产生大量的 DrawCall,后者会浪费寄存器资源。看起来是一个进退两难的问题,这该怎么解决呢?
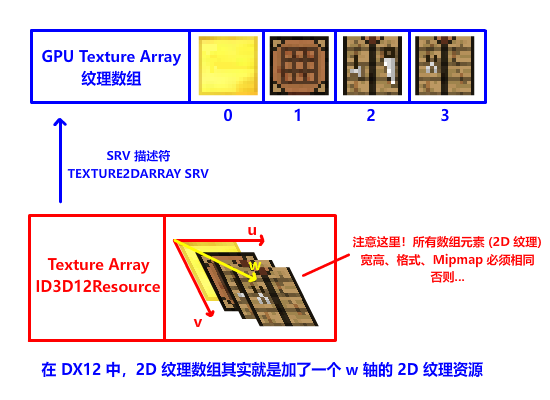
在此郑重介绍一位重量级解决方法:Texture Array 纹理数组,顾名思义,由多个纹理组成的数组。在 DX12 中,纹理数组其实是加了一个 w 深度轴的 2D 多层纹理,如果要在纹理数组中采样不同的纹理,只需要改变 w 坐标就行!
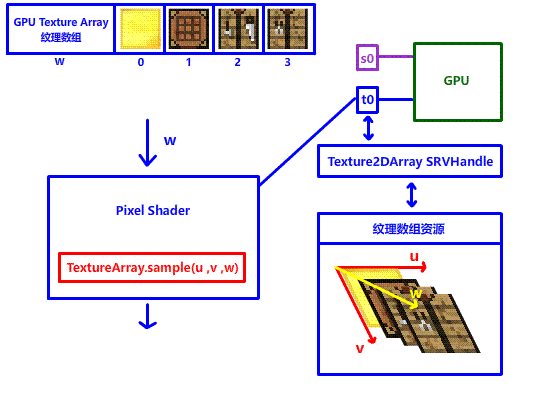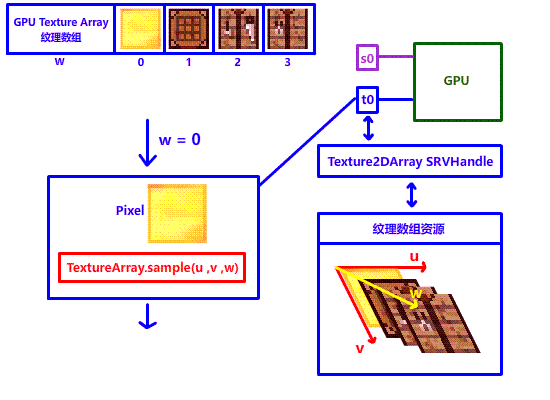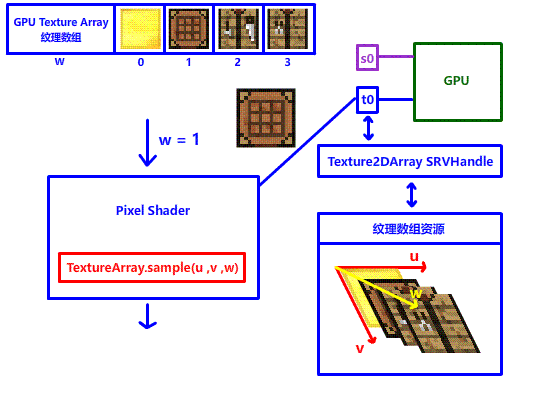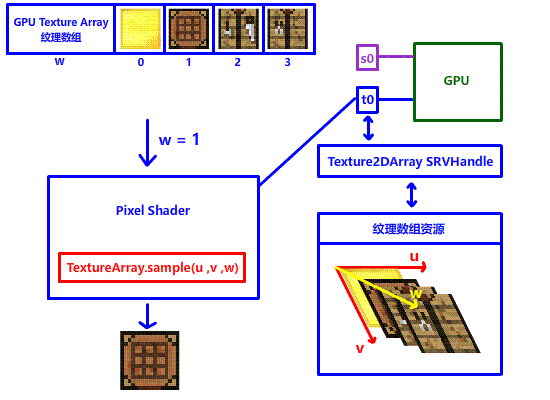
有了纹理数组,就意味着我们可以直接在 shader 上实现纹理的切换,不需要切换 SRV 句柄,更不需要占用这么多寄存器,只需要一个寄存器,只需要一个 SRV 句柄!!我们就能完美解决上面的问题!!!
纹理数组也是很多游戏 (特别是移动端) 加速渲染的常用方案,很多游戏引擎都会内置纹理数组功能:
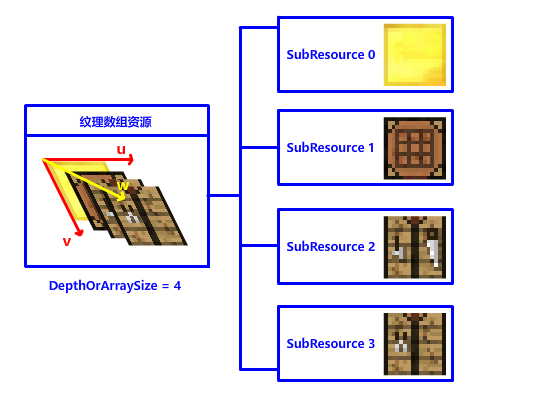
纹理数组资源的创建
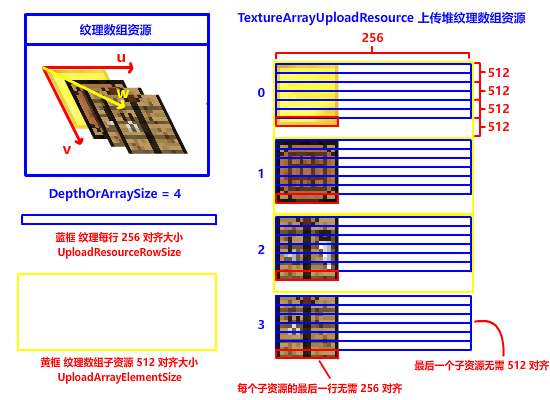
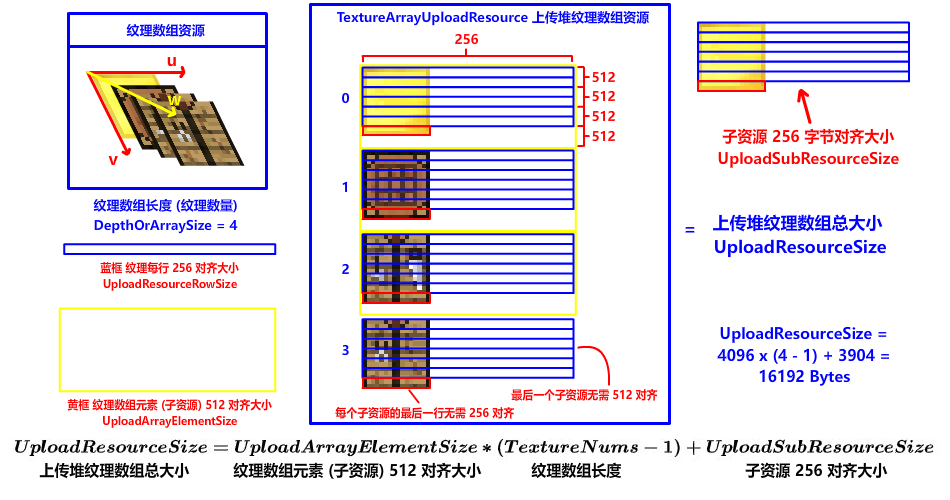
在纹理数组中,每个数组元素叫 SubResource 子资源,进行纹理数组复制的时候,硬件对齐有新的要求。对,你没听错,有新的要求。上传堆资源每个数组元素 (子资源) 之间还要进行 512 字节对齐 (D3D12_DEFAULT_RESOURCE_PLACEMENT_ALIGNMENT = 512),这样 DX12 API 才能正确复制并索引纹理:


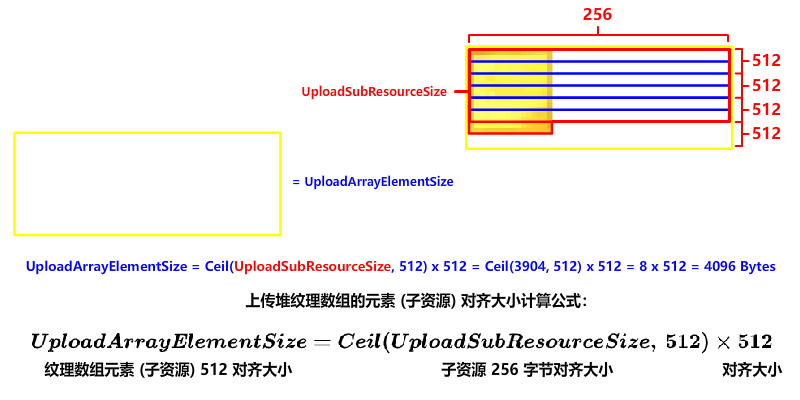
cpp
// 获取纹理每行所占的真实字节数,1 Byte = 8 Bits
BytePerRowSize = TextureWidth * BitsPerPixel / 8;
// 获取纹理真实总大小
TextureSize = BytePerRowSize * TextureHeight;
// DX12 API 要求在上传堆的纹理资源每行必须 256 字节对齐,这样能方便硬件批量复制
// D3D12_TEXTURE_DATA_PITCH_ALIGNMENT = 256
UploadResourceRowSize = Ceil(BytePerRowSize, 256) * 256;
// 计算纹理数组单个元素实际需要的上传堆资源大小,最后一行无需对齐,直接复制
UploadSubResourceSize = UploadResourceRowSize * (TextureHeight - 1) + BytePerRowSize;
// 你以为算出 UploadSubResourceSize * TextureGroup.size() 就可以了吗?大错特错!
// 实际上,DX12 API 还有一个硬性要求:Texture Array 在上传堆每个元素必须 512 对齐,这样才能方便硬件正确寻址并复制每个纹理元素
// Texture Array 占上传堆的空间大小,比多个单独的纹理资源占上传堆还要大一点,不过这样保证了纹理资源的连续性
// 硬件复制资源的速度实际上更快了,这就是 GPU Texture Array "纹理数组" 名字的由来
// 我们要在算出 UploadSubResourceSize 的基础上,再进行一次 512 对齐,算出纹理数组每个元素在上传堆所占的真实大小
// 为每个纹理元素做一个 "安全的小屋",在上传堆 "互不打扰",硬件正确偏移到每个元素的起始点。仍然是最后一个元素无需对齐,直接复制
// D3D12_DEFAULT_RESOURCE_PLACEMENT_ALIGNMENT = 512
UploadArrayElementSize = Ceil(UploadSubResourceSize, 512) * 512;
// 最后计算上传堆资源所需要的总大小,公式和上面的 UploadSubResourceSize 计算是一样的
UploadResourceSize = UploadArrayElementSize * (TextureGroup.size() - 1) + UploadSubResourceSize;获取到 纹理 (子资源) 宽高、DXGI 格式、纹理数量 (纹理数组长度)、各种资源大小 之后,我们就可以填写资源结构体,创建上传堆与默认堆资源了:
cpp
// 用于中转纹理的上传堆资源结构体
D3D12_RESOURCE_DESC UploadResourceDesc = {};
UploadResourceDesc.Dimension = D3D12_RESOURCE_DIMENSION_BUFFER; // 资源类型,上传堆的资源类型都是 buffer 缓冲
UploadResourceDesc.Layout = D3D12_TEXTURE_LAYOUT_ROW_MAJOR; // 资源布局,指定资源的存储方式,上传堆的资源都是 row major 按行线性存储
UploadResourceDesc.Width = UploadResourceSize; // 资源宽度,上传堆的资源宽度是资源的总大小,注意资源大小必须只多不少
UploadResourceDesc.Height = 1; // 资源高度,上传堆仅仅是传递线性资源的,所以高度必须为 1
UploadResourceDesc.Format = DXGI_FORMAT_UNKNOWN; // 资源格式,上传堆资源的格式必须为 UNKNOWN
UploadResourceDesc.DepthOrArraySize = 1; // 资源深度,上传堆资源必须为 1
UploadResourceDesc.MipLevels = 1; // Mipmap 等级,上传堆资源必须为 1
UploadResourceDesc.SampleDesc.Count = 1; // 资源采样次数,上传堆资源都是填 1
// 创建上传堆资源
m_D3D12Device->CreateCommittedResource(&UploadHeapDesc, D3D12_HEAP_FLAG_NONE, &UploadResourceDesc,
D3D12_RESOURCE_STATE_GENERIC_READ, nullptr, IID_PPV_ARGS(&m_TextureArrayUploadResource));
// 默认堆资源结构体
D3D12_RESOURCE_DESC DefaultResourceDesc = {};
DefaultResourceDesc.Dimension = D3D12_RESOURCE_DIMENSION_TEXTURE2D; // 资源类型选 Texture 2D (下文的描述符会描述它是一个纹理数组)
DefaultResourceDesc.Layout = D3D12_TEXTURE_LAYOUT_UNKNOWN; // 纹理资源的布局都是 UNKNOWN
DefaultResourceDesc.DepthOrArraySize = TextureGroup.size(); // 资源深度 = 纹理数组长度
DefaultResourceDesc.SampleDesc.Count = 1; // 资源采样次数,这里我们填 1 就行
// 创建纹理数组,我们以 TextureGroup 中第一个纹理的宽高、格式和 Mipmap 为准,看渲染结果,尝试用"妙妙工具"分析,想想为什么会这样? 应该如何优化?
DefaultResourceDesc.Width = TextureWidth; // 资源宽度,这里填单个纹理的宽度 (单位:像素)
DefaultResourceDesc.Height = TextureHeight; // 资源高度,这里填单个纹理的高度 (单位:像素)
DefaultResourceDesc.Format = TextureFormat; // 资源格式,这里填纹理格式,要和纹理数组一样
DefaultResourceDesc.MipLevels = 1; // Mipmap 等级,我们暂时不使用 Mipmap (只有一层 Mipmap),所以填 1
// 创建默认堆资源
m_D3D12Device->CreateCommittedResource(&DefaultHeapDesc, D3D12_HEAP_FLAG_NONE, &DefaultResourceDesc,
D3D12_RESOURCE_STATE_COPY_DEST, nullptr, IID_PPV_ARGS(&m_TextureArrayDefaultResource));纹理数组到默认堆的复制
由于我们复制的是纹理数组,复制的时候还要多留个心眼,每复制完成一个子资源,要遵循 512 对齐要求偏移到正确的位置!否则会绘制不出纹理 (或者画错了)!这种渲染错误调试层可不会报错,一定要注意!
cpp
// 用于暂时存储纹理数据的指针,这里要用 malloc 分配空间
BYTE* TextureData = (BYTE*)malloc(TextureSize);
// 用于传递资源的指针
BYTE* TransferPointer = nullptr;
// Map 开始映射,Map 方法会得到上传堆资源的地址 (在共享内存上),传递给指针,这样我们就能通过 memcpy 操作复制数据了
m_TextureArrayUploadResource->Map(0, nullptr, reinterpret_cast<void**>(&TransferPointer));
// 循环复制 TextureGroup 每个 WIC 资源到上传堆,然后逐一释放,i 是纹理数组元素索引
for (UINT i = 0; i < TextureGroup.size(); i++)
{
// 对于每个纹理元素,将整块纹理数据读到 TextureData 中,方便下面的 memcpy 复制操作
TextureGroup[i].WICBitmapSource->CopyPixels(nullptr, BytePerRowSize, TextureSize, TextureData);
// 向上传堆资源逐行复制纹理数据 (CPU 高速缓存 -> 共享内存),j 是复制的行数
for (UINT j = 0; j < TextureHeight; j++)
{
// 复制一行
memcpy(TransferPointer, TextureData, BytePerRowSize);
// 纹理指针偏移到下一行
TextureData += BytePerRowSize;
// 上传堆资源指针偏移到下一行,注意偏移长度不同!
TransferPointer += UploadResourceRowSize;
}
// 单个元素复制完毕,纹理 WIC 资源指针复用,恢复到最开始的位置,准备下一次 CopyPixels
TextureData -= TextureSize;
// 上传堆资源指针回到本数组元素的起点
TransferPointer -= UploadResourceRowSize * TextureHeight;
// 上传堆资源指针偏移到下一个数组元素的位置
// 请大家认真想一想下面的等式成立吗? (反正作者被下面的大小偏移坑爆了,渲染不出来盯了三小时 + 一遍遍问 deepseek 才改出来)
// UploadResourceRowSize * TextureHeight == UploadSubResourceSize == UploadArrayElementSize
TransferPointer += UploadArrayElementSize;
// 每个元素复制完,重置并释放 WIC 位图资源,防止它占内存
TextureGroup[i].WICBitmapSource.Reset();
}
// Unmap 结束映射,让上传堆处于只读状态
m_TextureArrayUploadResource->Unmap(0, nullptr);
// 释放上文 malloc 分配的空间,后面我们用不到它,做一个干净的程序员
free(TextureData);我们复制到上传堆后,下一步就是复制到默认堆了,最重要的两个函数是 ID3D12Device::GetCopyableFootprints (获取复制资源脚本) 和 ID3D12CommandList::CopyTextureRegion (添加复制纹理命令)
GetCopyableFootprints 获取纹理复制脚本和其他附带信息
第一个参数 pResourceDesc 复制目标资源结构体指针,获取脚本需要得到目标资源的相关信息,我们需要复制到默认堆资源,所以要填默认堆资源结构体
第二个参数 FirstSubresource 要复制的资源起始索引,这里我们填 0 ,从第一个子资源开始
第三个参数 NumSubresources 资源中的子资源数,这里我们要填纹理数组的长度
第四个参数 BaseOffset 资源偏移量 (单位:字节),这里填 0
第五个参数 pLayouts 被复制资源的脚本结构体指针 (SrcLocation.PlacedFootprint),这里一定要注意!对于纹理数组,函数会根据第一个和第三个参数,自动填充要输出的复制脚本数组信息 (每个函数都要调用一遍 CopyTextureRegion,所以函数会填充一个数组的信息,不要忘记设置复制脚本数组哦!)
第六个参数 pNumRows 要输出的资源行数 (可选),相当于 TextureHeight 纹理高度 ,我们这里填 nullptr
第七个参数 pRowSizeInBytes 要输出的资源每行大小 (可选),相当于 BytePerRowSize 纹理每行大小 ,我们这里填 nullptr
第八个参数 pTotalBytes 要输出的资源存储所需大小 (可选),相当于 UploadResourceSize 上传堆资源大小 ,我们这里填 nullptr
CopyTextureRegion 复制纹理 (pSrc -> pDst)第一个参数 pDst 复制目标脚本结构体指针 (DstLocation),对于纹理数组,复制目标结构体需要带上对应数组元素的 SubResourceIndex 纹理数组索引
第二个参数 DstX 目标资源左上角 x 坐标,这里填 0
第三个参数 DstY 目标资源左上角 y 坐标,这里填 0
第四个参数 DstZ 目标资源左上角 z 坐标 (用于 3D 纹理),这里填 0
第五个参数 pSrc 复制源脚本结构体指针 (SrcLocation),对于纹理数组,复制源结构体需要带上对应数组元素的 PlacedFootprint 复制脚本
第六个参数 pSrcBox 要复制的纹理区域,nullptr 表示复制整块纹理
对于纹理数组,每个数组元素 (纹理子资源) 都要执行一遍 CopyTextureRegion,每复制一个元素就必须指定对应的 SubResourceIndex 复制目标 (默认堆纹理数组) 子资源索引 和 PlacedFootprint 复制源 (上传堆纹理数组) 某个元素的复制脚本,这样才能正确复制纹理到默认堆。
但是每个子资源的 PlacedFootprint 怎么获得呢?这个时候第 4 章被我们一笔带过的 GetCopyableFootprints 就大显神威了,只需要填充正确输入 (第一个参数 pResourceDesc 纹理数组默认堆资源结构体、第三个参数 NumSubResources 纹理数组长度) 与输出参数 (第五个参数 pLayouts 要填充到的复制脚本缓冲指针)、这个函数就会自动帮你填充。全程有贵人协助,想写错都很难。
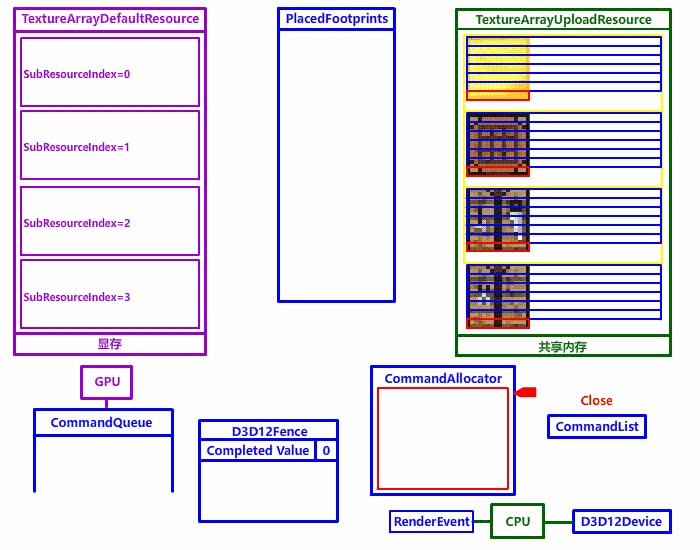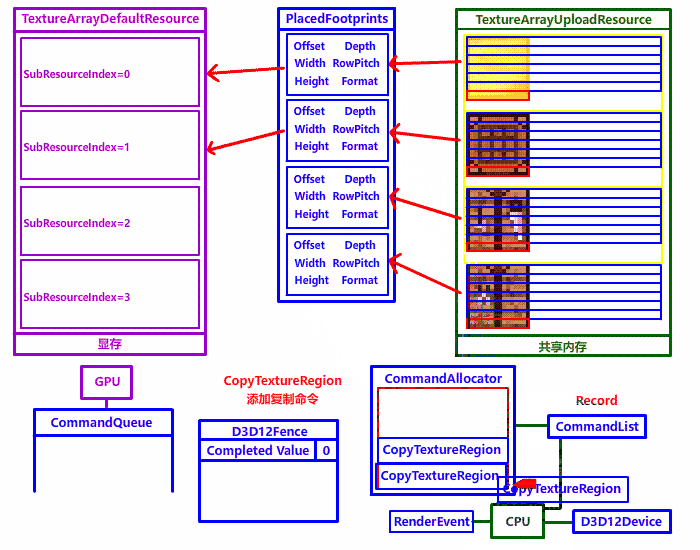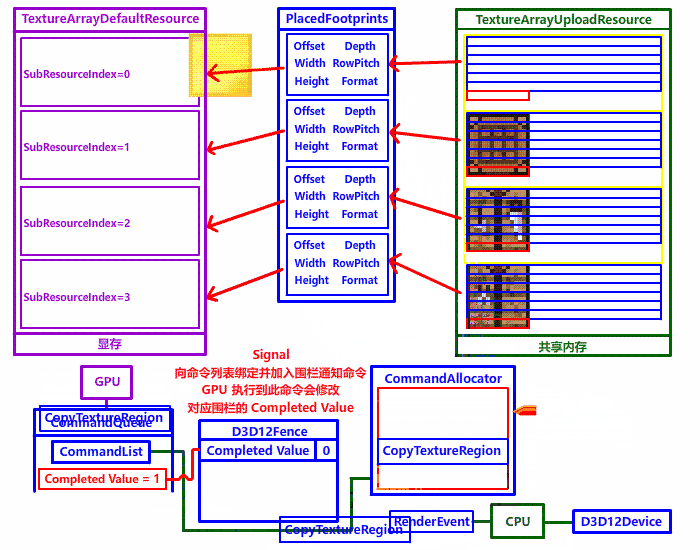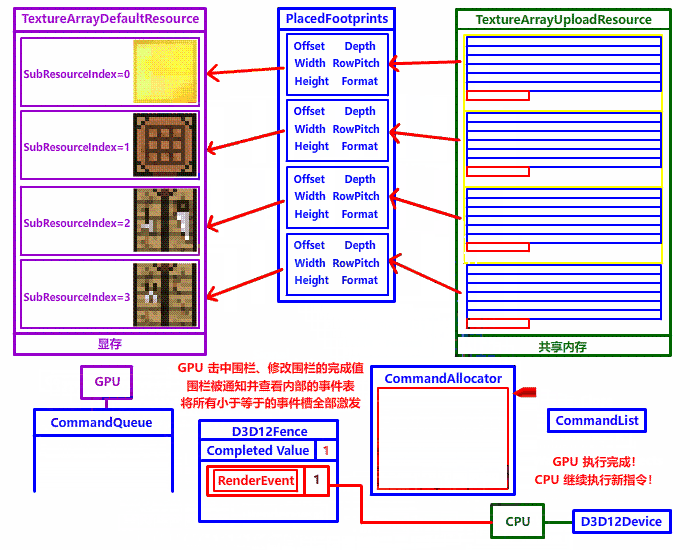
原本用 Flash cs6 弄的,用 ScreenToGif 后期处理了一下掉色了,强迫症患者请见谅
cpp
// 资源脚本,用来描述要复制的资源。如果复制目标是纹理数组,每个子资源 (纹理数组元素) 各复制一次,各需要一个资源脚本
// 如果复制纹理数组只用一个脚本,下文 GPU 执行 CopyTextureRegion 会寻址出界,报 Stack Corrupted,调试层不会提示这个信息
std::vector<D3D12_PLACED_SUBRESOURCE_FOOTPRINT> PlacedFootprints(TextureGroup.size());
D3D12_RESOURCE_DESC DefaultResourceDesc = m_TextureArrayDefaultResource->GetDesc(); // 默认堆资源结构体
// 获取纹理复制脚本,用于下文的纹理复制,注意第三个参数!第三个参数是目标资源的子资源数量!我们复制的是纹理数组,要填数组长度!
// 当你填了 DefaultResourceDesc 和 TextureGroup.size(),这个函数会自动填充每个资源脚本的各种参数
m_D3D12Device->GetCopyableFootprints(&DefaultResourceDesc, 0, TextureGroup.size(), 0,
&PlacedFootprints[0], nullptr, nullptr, nullptr);
// 复制资源需要使用 GPU 的 CopyEngine 复制引擎,所以需要向命令队列发出复制命令
m_CommandAllocator->Reset(); // 先重置命令分配器
m_CommandList->Reset(m_CommandAllocator.Get(), nullptr); // 再重置命令列表,复制命令不需要 PSO 状态,所以第二个参数填 nullptr
// 注意!复制纹理数组到默认堆,每个子资源 (纹理数组元素) 都要调用一次 CopyTextureRegion 指令
// DstLocation.SubresourceIndex 和 SrcLocation.PlacedFootprint 的参数也要跟着变!这样才能正确复制
for (UINT i = 0; i < TextureGroup.size(); i++)
{
D3D12_TEXTURE_COPY_LOCATION DstLocation = {}; // 复制目标位置 (默认堆资源) 结构体
DstLocation.Type = D3D12_TEXTURE_COPY_TYPE_SUBRESOURCE_INDEX; // 纹理复制类型,这里必须指向纹理
DstLocation.SubresourceIndex = i; // 指定要复制的子资源索引 (第 i 个元素)
DstLocation.pResource = m_TextureArrayDefaultResource.Get(); // 要复制到的资源 (默认堆资源)
D3D12_TEXTURE_COPY_LOCATION SrcLocation = {}; // 复制源位置 (上传堆资源) 结构体
SrcLocation.Type = D3D12_TEXTURE_COPY_TYPE_PLACED_FOOTPRINT; // 纹理复制类型,这里必须指向缓冲区
SrcLocation.PlacedFootprint = PlacedFootprints[i]; // 指定要复制的资源脚本信息 (用第 i 个资源脚本)
SrcLocation.pResource = m_TextureArrayUploadResource.Get(); // 被复制数据的缓冲 (上传堆资源)
// 记录复制第 i 个子资源 (纹理数组元素) 到默认堆的命令 (共享内存 -> 显存)
m_CommandList->CopyTextureRegion(&DstLocation, 0, 0, 0, &SrcLocation, nullptr);
}
// 关闭命令列表
m_CommandList->Close();
// 用于传递命令用的临时 ID3D12CommandList 数组
ID3D12CommandList* _temp_cmdlists[] = { m_CommandList.Get() };
// 提交复制命令!GPU 开始复制!
m_CommandQueue->ExecuteCommandLists(1, _temp_cmdlists);
// 将围栏预定值设定为下一帧,注意复制资源也需要围栏等待,否则会发生资源冲突!
FenceValue++;
// 在命令队列 (命令队列在 GPU 端) 设置围栏预定值,此命令会加入到命令队列中
m_CommandQueue->Signal(m_Fence.Get(), FenceValue);
// 设置围栏的预定事件,当复制完成时,围栏被"击中",激发预定事件,将事件由无信号状态转换成有信号状态
m_Fence->SetEventOnCompletion(FenceValue, RenderEvent);
// 让主线程强制等待复制完成,经过此函数后 RenderEvent 会自动重置到无信号状态 (CreateEvent 第二个参数)
WaitForSingleObject(RenderEvent, INFINITE);纹理数组 SRV 描述符的创建
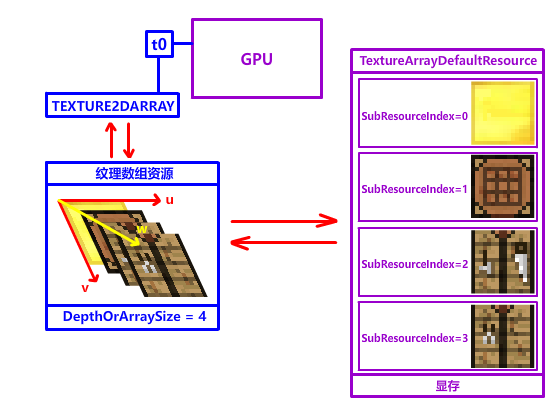
最后创建 SRV 描述堆,只需要创建一个 SRV 就行,将 SRV 类型设置成 D3D12_SRV_DIMENSION_TEXTURE2DARRAY,ArraySize 设置成 纹理数组长度 就可以创建成功了:
cpp
// RenderShader.hlsl
// 纹理数组 2D Texture Array,实际上只是一个记录特殊信息,合并多个纹理的大纹理资源,UVW 这三个分量都用到了
Texture2DArray m_TextureArray : register(t0, space0);
cpp
D3D12_DESCRIPTOR_HEAP_DESC SRVHeapDesc = {}; // SRV 描述符堆信息结构体
SRVHeapDesc.NumDescriptors = 1; // 只有一个 TEXTURE2DARRAY SRV
SRVHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV; // 类型是 CBV/SRV/UAV 描述符都可以放
SRVHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLE; // 着色器需要引用 SRV 资源,就必须设置着色器可见标志
// 创建 SRV 描述符堆
m_D3D12Device->CreateDescriptorHeap(&SRVHeapDesc, IID_PPV_ARGS(&m_SRVHeap));
cpp
// Texture Array 的 SRV 信息结构体,我们要通过 SRV 告知 GPU 这个资源的类型与用法
D3D12_SHADER_RESOURCE_VIEW_DESC SRVTextureArrayDesc = {};
// SRV 描述符的维度 (类型),我们这里选 TEXTURE2DARRAY (2D 纹理数组)
SRVTextureArrayDesc.ViewDimension = D3D12_SRV_DIMENSION_TEXTURE2DARRAY;
// 格式要填纹理数组的纹理格式
SRVTextureArrayDesc.Format = TextureFormat;
// RGBA 4 分量顺序不改变
SRVTextureArrayDesc.Shader4ComponentMapping = D3D12_DEFAULT_SHADER_4_COMPONENT_MAPPING;
// 纹理数组的起始索引,在 2D 纹理数组中,Slice 切片表示一个数组元素 (一个 2D 纹理)
SRVTextureArrayDesc.Texture2DArray.FirstArraySlice = 0;
// 纹理数组的长度 (纹理的数量)
SRVTextureArrayDesc.Texture2DArray.ArraySize = TextureGroup.size();
// 只有一层 Mipmap,填 1
SRVTextureArrayDesc.Texture2DArray.MipLevels = 1;
// 获取 CPU 句柄
SRVTextureArray_CPUHandle = m_SRVHeap->GetCPUDescriptorHandleForHeapStart();
// 获取 GPU 句柄
SRVTextureArray_GPUHandle = m_SRVHeap->GetGPUDescriptorHandleForHeapStart();
// 创建 SRV 描述符
m_D3D12Device->CreateShaderResourceView(m_TextureArrayDefaultResource.Get(), &SRVTextureArrayDesc, SRVTextureArray_CPUHandle);SRV StructuredBuffer 结构化缓冲
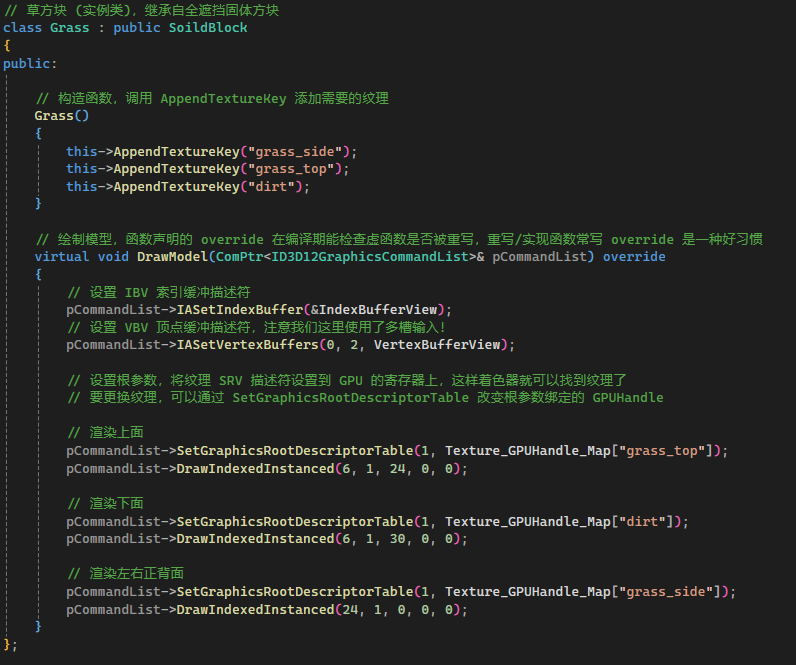
有了纹理数组还不够,每种方块六个面贴的纹理不一定是相同的,我们可能会画有两幅纹理 (例如橡木原木)、有三幅纹理 (例如熔炉)、甚至每面都有不同纹理 (例如黑曜石),我们怎么给不同的方块贴上正确的纹理呢?
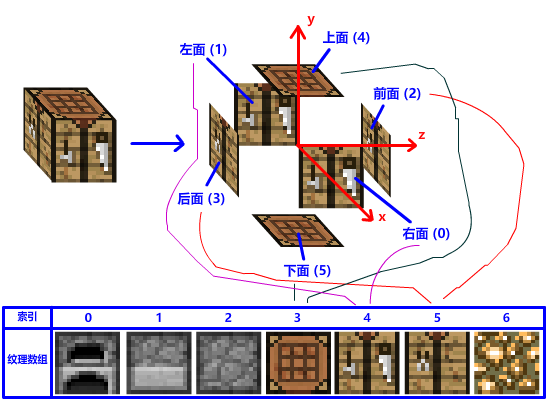
我们把方块六个面分别做个记号:0 号是右面 (+X),1 号是左面 (-X),2 号是前面 (+Z),3 号是后面 (-Z),4 号是上面 (+Y),5 号是下面 (-Y),每个面对应纹理数组中的某一个元素。
你们想到了什么呢?
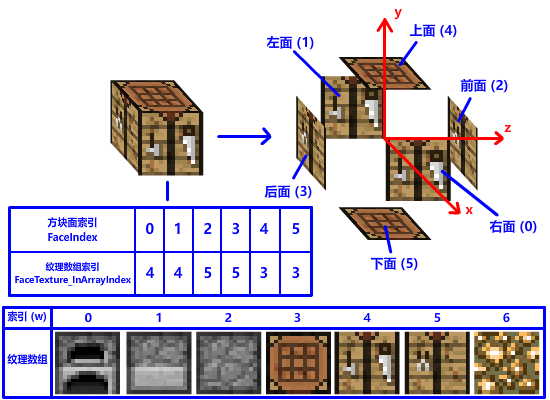
没错!我们可以弄一个 UINT 数组来描述它们的对应关系,这个数组长度是 6 (方块有 6 个面),数组索引是对应方块面的记号 (面索引),数组元素的值是纹理数组对应的一个元素 (数组元素索引):
cpp
// 立方体面结构体,只有一个 UINT 数组成员
// 数组索引表示对应的立方体面索引,数组元素值表示对应立方体面的纹理在 Texture Array 的位置
struct CUBEFACE
{
// 六个立方体面对应的纹理在 Texture Array 中的位置
// 数组索引 0-5 分别对应右面 (+X),左面 (-X),前面 (+Z),后面 (-Z),上面 (+Y),下面 (-Y)
UINT FaceTexture_InArrayIndex[6];
};
// 方块类型-纹理索引组,每个 vector 索引表示不同的方块类型,每个 vector 元素值表示对应方块六个面的纹理数据索引数据
// 在 shader 会根据 逐实例数据 (方块类型) 和 逐顶点数据 (方块每个面对应的纹理索引) 来索引对应的纹理,这样就不用反复换绑 SRV 了
std::vector<CUBEFACE> BlockCubeTexture_IndexGroup =
{
// 一个完整方块有六个面,右面 (+X),左面 (-X),前面 (+Z),后面 (-Z),上面 (+Y),下面 (-Y),我们以右面是方块正面为准
{0, 0, 0, 0, 0, 0}, // 0.蓝冰
{1, 1, 1, 1, 1, 1}, // 1.圆石
{2, 2, 2, 2, 2, 2}, // 2.绿宝石块
{3, 4, 4, 4, 5, 5}, // 3.熔炉 (三个面)
{6, 6, 6, 6, 6, 6}, // 4.金矿
{7, 7, 7, 7, 7, 7}, // 5.金块
{8, 8, 8, 8, 8, 8}, // 6.音符盒
{10, 10, 10, 10, 11, 9}, // 7.活塞 (三个面)
{12, 12, 12, 12, 12, 12}, // 8.红石块
{13, 13, 13, 13, 13, 13}, // 9.激活状态的红石灯
{15, 15, 15, 15, 16, 14}, // 10.TNT (三个面)
{17, 17, 17, 17, 17, 17}, // 11.基岩
{18, 18, 18, 18, 33, 33}, // 12.书架 (两个面)
{19, 19, 19, 19, 19, 19}, // 13.命令方块
{20, 20, 21, 21, 22, 22}, // 14.工作台 (三个面)
{23, 9, 9, 9, 9, 9}, // 15.水平发射器 (三个面)
{9, 9, 9, 9, 24, 9}, // 16.垂直发射器 (三个面)
{25, 9, 9, 9, 9, 9}, // 17.水平投掷器 (三个面)
{9, 9, 9, 9, 26, 9}, // 18.垂直投掷器 (三个面)
{27, 27, 27, 27, 27, 27}, // 19.绿宝石原矿
{28, 28, 28, 28, 28, 28}, // 20.玻璃
{29, 29, 29, 29, 29, 29}, // 21.萤石
{30, 30, 30, 30, 30, 30}, // 22.铁矿
{31, 31, 31, 31, 32, 32}, // 23.橡木原木 (两个面)
{31, 31, 31, 31, 31, 31}, // 24.橡树木
{33, 33, 33, 33, 33, 33}, // 25.橡木木板
{34, 34, 34, 34, 34, 34}, // 26.沙子
{35, 35, 35, 35, 35, 35}, // 27.石砖
{36, 36, 36, 36, 36, 36}, // 28.平滑石
{38, 38, 38, 38, 39, 37} // 29.石英块 (三个面)
};可是我们怎么才能让 shader 用这个 BlockCubeTexture_IndexGroup 呢?类似让 shader 获取并使用 CPU 端传来 MVP 矩阵数据的常量缓冲和 CBV Resource 常量缓冲资源,我们也可以弄一个缓冲来存储 BlockCubeTexture_IndexGroup 的数据。
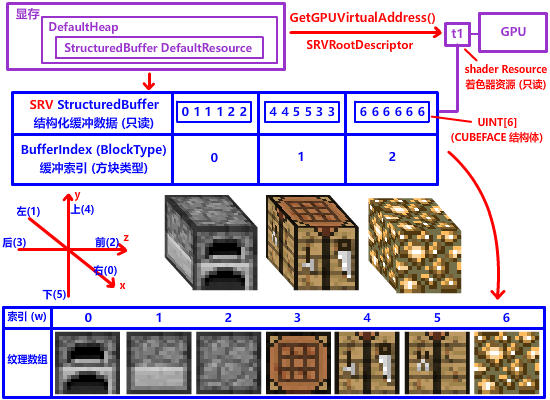
这个六面坐标在后续教程的 CubeMap 立方体贴图 也还会再见到一次
相比常量缓冲,功能相似的 SRV StructuredBuffer 着色器资源结构化缓冲 是更好的人选!结构化缓冲区是一块缓冲,它和常量缓冲功能很相似,都能向着色器传递结构化数组。为什么呢?我给出下面的表格,大家一起来思考一下:
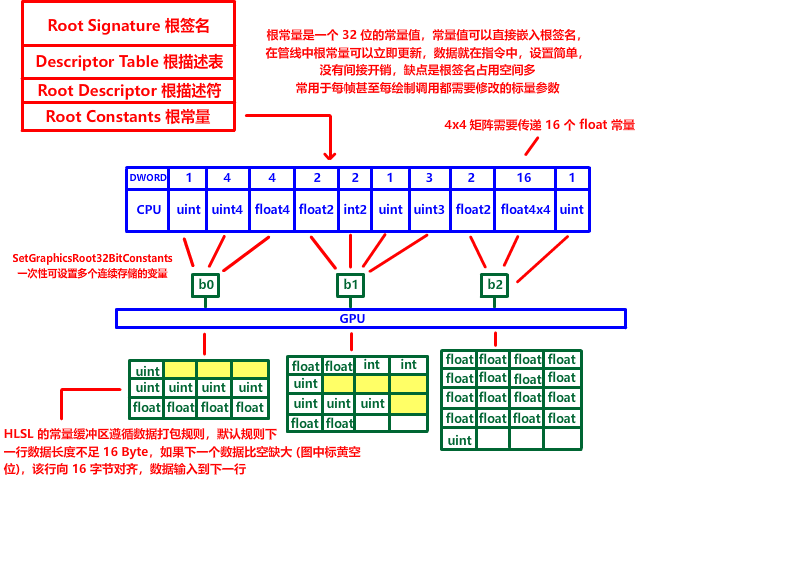
| 比较类别 | Constant Buffer 常量缓冲 | SRV StructuredBuffer 结构化缓冲 |
|---|---|---|
| 资源位置 | 一般是上传堆资源 (共享内存) | 一般是默认堆资源 (显存) |
| 资源对齐要求 | 整块资源 256 对齐 | 无对齐要求 |
| 资源布局规则 | HLSL 常量数据打包规则 (资源内部每行 16 字节对齐) | 无资源内部对齐规则 |
| 缓冲大小限制 | 单个上限 64 KB | 无大小限制 |
| 绑定描述符 | CBV (cbuffer) | SRV (StructuredBuffer) 或 UAV (RWStructuredBuffer) |
| 资源特点 | 小数据、高频率、高度统一访问 | 海量数据、随机访问、GPU 可读写 |
想一想,如果换成常量缓冲又应该怎样写呢?
经常动手画结构图是非常重要的技能哦!可以更好帮我们梳理架构!
结构化缓冲资源的创建与复制
结构化缓冲和纹理的资源创建和复制流程是一样的,改动部分结构体参数和指令就行。注意后面就不用再 WaitForSingalObject 了,否则后面会卡在 MsgWaitForMultipleObjects 导致窗口一直白屏!
cpp
// Structured Buffer 中转资源的上传堆信息结构体,填法和顶点/索引缓冲一样
D3D12_RESOURCE_DESC StructuredBufferUploadDesc = {};
StructuredBufferUploadDesc.Dimension = D3D12_RESOURCE_DIMENSION_BUFFER;
StructuredBufferUploadDesc.Layout = D3D12_TEXTURE_LAYOUT_ROW_MAJOR;
StructuredBufferUploadDesc.Width = BlockCubeTexture_IndexGroup.size() * sizeof(CUBEFACE); // 宽度是整个结构化缓冲的大小
StructuredBufferUploadDesc.Height = 1;
StructuredBufferUploadDesc.Format = DXGI_FORMAT_UNKNOWN;
StructuredBufferUploadDesc.DepthOrArraySize = 1;
StructuredBufferUploadDesc.MipLevels = 1;
StructuredBufferUploadDesc.SampleDesc.Count = 1;
// 创建上传堆资源
m_D3D12Device->CreateCommittedResource(&UploadHeapDesc, D3D12_HEAP_FLAG_NONE, &StructuredBufferUploadDesc,
D3D12_RESOURCE_STATE_GENERIC_READ, nullptr, IID_PPV_ARGS(&m_StructuredBufferUploadResource));
// Structured Buffer 中转资源的默认堆信息结构体
D3D12_RESOURCE_DESC StructuredBufferDefaultDesc = {};
StructuredBufferDefaultDesc.Dimension = D3D12_RESOURCE_DIMENSION_BUFFER; // 注意这里类型是缓冲
StructuredBufferDefaultDesc.Layout = D3D12_TEXTURE_LAYOUT_ROW_MAJOR; // 线性资源
StructuredBufferDefaultDesc.Width = BlockCubeTexture_IndexGroup.size() * sizeof(CUBEFACE); // 宽度是整个结构化缓冲的大小
StructuredBufferDefaultDesc.Height = 1;
StructuredBufferDefaultDesc.Format = DXGI_FORMAT_UNKNOWN;
StructuredBufferDefaultDesc.DepthOrArraySize = 1;
StructuredBufferDefaultDesc.MipLevels = 1;
StructuredBufferDefaultDesc.SampleDesc.Count = 1;
// 创建默认堆资源
m_D3D12Device->CreateCommittedResource(&DefaultHeapDesc, D3D12_HEAP_FLAG_NONE, &StructuredBufferDefaultDesc,
D3D12_RESOURCE_STATE_COPY_DEST, nullptr, IID_PPV_ARGS(&m_StructuredBufferDefaultResource));
// 用于传递资源的指针
BYTE* TransferPointer = nullptr;
// Map 映射,获取上传堆资源的地址并传递到 TransferPointer
m_StructuredBufferUploadResource->Map(0, nullptr, reinterpret_cast<void**>(&TransferPointer));
// 直接 memcpy 复制 (CPU 高速缓存 -> 共享内存)
memcpy(TransferPointer, &BlockCubeTexture_IndexGroup[0], BlockCubeTexture_IndexGroup.size() * sizeof(CUBEFACE));
// UnMap 结束映射,下一步就要复制到默认堆
m_StructuredBufferUploadResource->Unmap(0, nullptr);
// 复制资源需要使用 GPU 的 CopyEngine 复制引擎,所以需要向命令队列发出复制命令
m_CommandAllocator->Reset(); // 先重置命令分配器
m_CommandList->Reset(m_CommandAllocator.Get(), nullptr); // 再重置命令列表,复制命令不需要 PSO 状态,所以第二个参数填 nullptr
// 发送复制到默认堆的指令,注意这里用的是 CopyBufferRegion 复制缓冲指令,不用填麻烦的结构体,直接填参数上传 (共享内存 -> GPU 显存)
m_CommandList->CopyBufferRegion(m_StructuredBufferDefaultResource.Get(), 0,
m_StructuredBufferUploadResource.Get(), 0, BlockCubeTexture_IndexGroup.size() * sizeof(CUBEFACE));
// 关闭命令列表
m_CommandList->Close();
// 用于传递命令用的临时 ID3D12CommandList 数组
ID3D12CommandList* _temp_cmdlists[] = { m_CommandList.Get() };
// 提交复制命令!GPU 开始复制!
m_CommandQueue->ExecuteCommandLists(1, _temp_cmdlists);
// 将围栏预定值设定为下一帧,注意复制资源也需要围栏等待,否则会发生资源冲突!
FenceValue++;
// 在命令队列 (命令队列在 GPU 端) 设置围栏预定值,此命令会加入到命令队列中
m_CommandQueue->Signal(m_Fence.Get(), FenceValue);
// 设置围栏的预定事件,当复制完成时,围栏被"击中",激发预定事件,将事件由无信号状态转换成有信号状态
m_Fence->SetEventOnCompletion(FenceValue, RenderEvent);
// 下一个等待就是 RenderLoop 的 MsgWaitForMultipleObjects,不需要用 WaitForSingleObject 了
// 这里再用一次 WaitForSingleObject 就会使事件变成无信号 (CreateEvent 第二个参数)
// 导致在 MsgWaitForMultipleObjects 那里卡死,永远返回 1,窗口白屏,完全进不去 case 0 渲染函数CopyBufferRegion 复制缓冲 (pSrcBuffer -> pDstBuffer)
第一个参数 pDstBuffer 指向复制目标资源的指针
第二个参数 DstOffset 目标资源复制起始点,这里填 0
第三个参数 pSrcBuffer 指向复制源的指针
第四个参数 SrcOffset 复制源复制起始点,这里填 0
第五个参数 NumBytes 要复制的大小 (单位:字节),这里填结构体变量总大小
结构化缓冲到 SRV 根描述符的绑定
由于结构化缓冲只是描述了总大小、步长的一块缓冲资源,没有复杂的资源布局,我们这里直接用 SRV RootDescriptor 根描述符 绑定资源地址就行:
cpp
// RenderShader.hlsl
// 立方体面结构体,数组索引表示对应的立方体面,数组元素值表示 对应面所用纹理 指向 纹理数组 的索引
struct CUBEFACE
{
// 数组索引 0-5 分别对应右面 (+X),左面 (-X),前面 (+Z),后面 (-Z),上面 (+Y),下面 (-Y)
uint FaceTexture_InArrayIndex[6];
};
// GPU 上的方块类型-纹理索引组 (SRV Structured Buffer)
// HLSL 也有类似 C++ 一样的模板类,StructuredBuffer<Type> 相当于 C++ 的 std::array<type> 静态数组
// 数组索引表示不同的方块类型,数组元素值表示对应方块六个面的纹理数据索引数据
StructuredBuffer<CUBEFACE> BlockCubeTexture_IndexGroup : register(t1, space0);
cpp
// 设置第二个根参数:SRV 根描述符 (结构化缓冲),注意这里设置的是默认堆资源的 GPU 地址!
m_CommandList->SetGraphicsRootShaderResourceView(1, m_StructuredBufferDefaultResource->GetGPUVirtualAddress());时刻牢记,纹理资源不能用于 SRV 根描述符!
硬件实例化
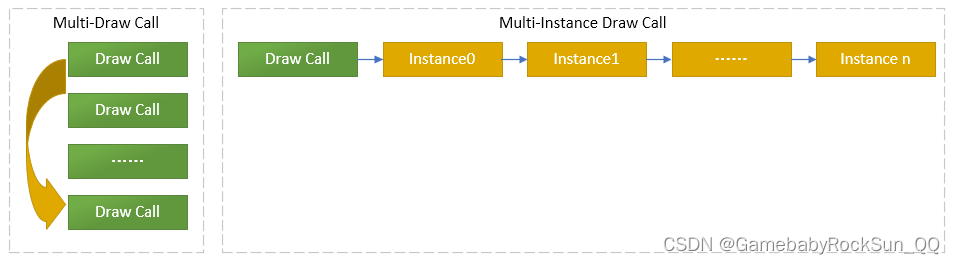
接下来是最为重点的部分!之前我们都是一个方块 1-3 次 DrawCall,我们现在要画 1125 个位置和类型各不相同的方块,算下来至少 3000 次 DrawCall!这样渲染一定会导致游戏卡顿!
有什么方法只用一次 DrawCall 就可以完成所有方块的渲染呢?如你所愿,接下来我们真正的主角:GPU Instancing 硬件实例化 正式登场!
什么是实例化
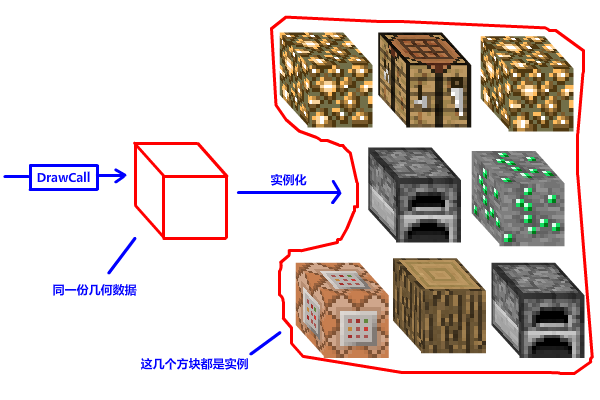
实例化,简单来说,就是一次 DrawCall、多次渲染!
Instance 实例,是指同一份几何数据 (如一个方块的顶点和索引) 的多个独立副本。你可以把实例理解成 "同一个模具生产出的多个产品"
模具: 就是一个 3D 模型 (顶点、索引、纹理 UV 等固定数据)。
产品: 就是每个实例,它们共享相同的"模具",但可以有不同的位置、颜色、纹理索引、大小等属性。
批绘制 (Batch Draw)
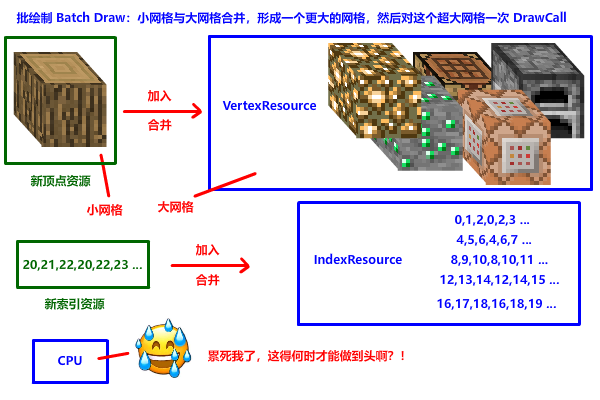
早期没有实例化的时代,开发者都会通过一个叫 Batch Draw 批绘制 的方法来优化 DrawCall,批绘制的原理很简单,就是小网格合并到大网格,然后对这个超大网格一次 DrawCall。

easyx 的 BatchDraw 本质上是 "双缓冲 + 批绘制"
批绘制实现简单,但 CPU 开销极大,内存占用高,GPU 性能损失严重 (没用上 GPU 并行计算的特性),拓展性很差。
硬件实例化 (GPU Instancing)
随着专用图形硬件的发展, GPU Instacing 硬件实例化 这一技术也初见端倪。硬件实例化是一种通过硬件支持高效绘制多个对象或将操作系统功能直接集成到硬件中的技术,以减少 CPU 开销并提升性能。简单的来说,就是实例化的工作交给了 GPU 等图形硬件,CPU 只负责传递数据和发送指令,一次 DrawCall 多次渲染,这样可以平衡开销并加速渲染,不会出现高额的 CPU 固定开销和 GPU 流水线停顿。
早在 1990 年代后期,随着场景复杂度提升,图形学研究者就开始探讨如何高效绘制大量重复物体。一些学术论文中已经出现了类似的思想,即在一次绘制调用中传递一份几何数据和多份变换矩阵/材质属性,由硬件或着色器进行复用。

2004 年,DirectX 9.0c 以打补丁的形式加入到 Windows XP 中 (DirectX 9 是 2002 年,这是它的一个最重要的小版本),它实验性地引入了硬件实例化 (IDirect3DDevice9::SetStreamSourceFreq,它的作用是为指定的顶点流 (Stream) 设置"频率除数"。简单来说,就是告诉显卡,这个流里的数据应该多久被读取一次),这是微软在 API 层面对硬件实例化支持的最早尝试:


2006 年 Windows Vista 的发布附带的 DirectX 10 才真正把硬件实例化引入到 API 原生架构支持。DX10 将实例化深度融入了渲染管线的起点 ------ 输入装配器 (Input Assembler, IA)。IA 是整个图形管线的数据入口,它原生支持识别和处理每实例数据。
DX10 引入了 DrawInstanced 和 DrawIndexedInstanced 这样的专用 API 接口函数 (没错,它们就是从 DX10 开始有了,别再问为什么函数名带 Instanced 了)。开发者只需调用一次这样的函数,就能告诉 GPU 绘制指定数量的物体实例,CPU 不再需要为每个物体发起单独的绘制命令。
描述顶点数据的输入布局 (D3D10_INPUT_ELEMENT_DESC) 中,新增了一个字段 (结构体成员) InputSlotClass。开发者可以通过将其设置为 D3D10_INPUT_PER_INSTANCE_DATA,来明确告诉 GPU 某个数据流 (比如世界矩阵、颜色) 是"每实例"的,而不是"每顶点"的。这个过程比 DX9 的 SetStreamSourceFreq 要清晰和直接得多。
如果说 DX9 的实例化是在"老房子"里加盖的"功能间",那么 DX10 的实例化就是在一张白纸上全新设计的"原生别墅"。

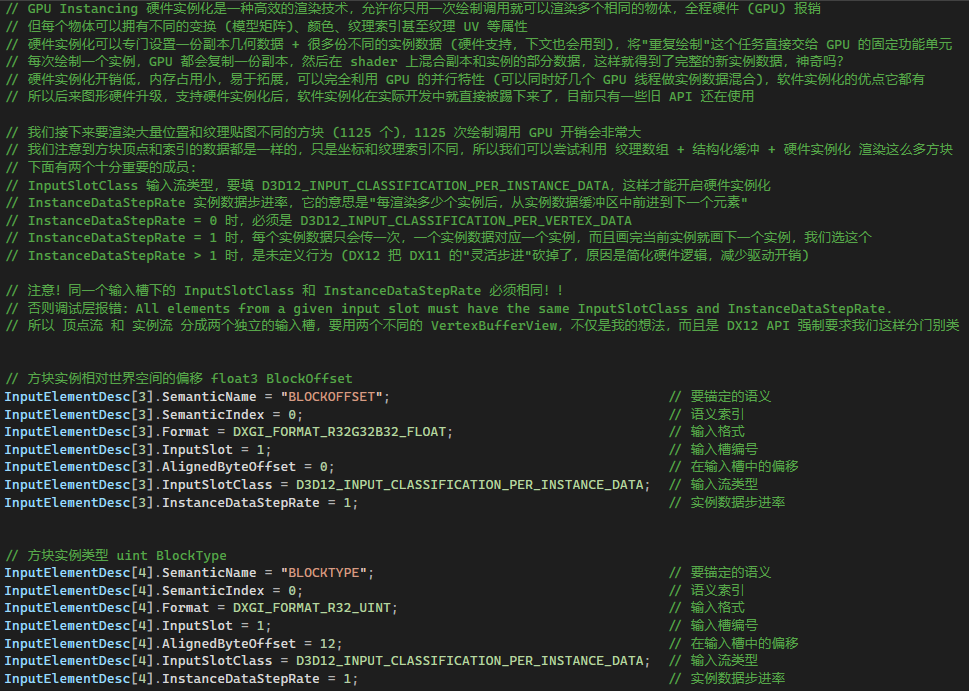
DX11 完善了 DX10 挖的坑,新增了 InstanceDataStepRate 字段 (结构体成员),允许一份实例数据驱动多个实例,实现更灵活的数据复用。


DX11 是驱动帮你做"算术题",但 DX12 不是,"没有魔法,只有你"。
DX11 硬件实例化的背后,驱动在硬件层面帮你维护了一个"隐形的指针"和一个计数器。每绘制一个实例,计数器加 1,当达到 N 时,指针才移动。这个逻辑对开发者是透明的,很方便,但驱动必须插入额外的指令来维护这个状态,并且这个状态是不可见、不可控的。
DX12 的设计目标是"降低驱动开销,提供硬件级控制"。它认为不应该有任何驱动帮你做的"隐形操作"。所以如果设置硬件实例化,InstanceDataStepRate 必须为 1,它在 DX12 更多的是一个对数据布局的描述。实际上,DX12 期望你绝大多数时候把它设为 1。
因为设为 1 意味着"每份数据对应一个实例",这是最简单、最符合硬件直接寻址的模式。当你想实现"每 N 个实例共享一份数据"的效果时,DX12 不希望你依赖驱动去帮你重复数据,它希望读者你们开动脑筋自己实现 (可以用 SV_InstanceID,这个系统语义会让 GPU 自动生成当前绘制实例的索引,也可以用各种奇形怪状的缓冲资源)。

IA 多槽输入与实例化资源的创建
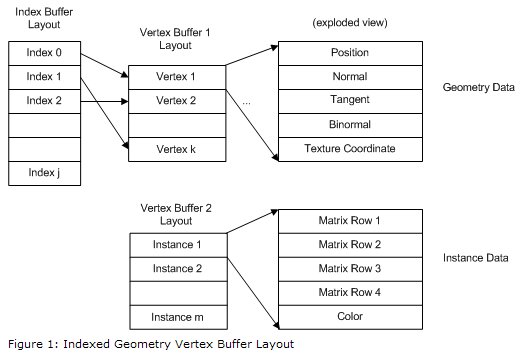
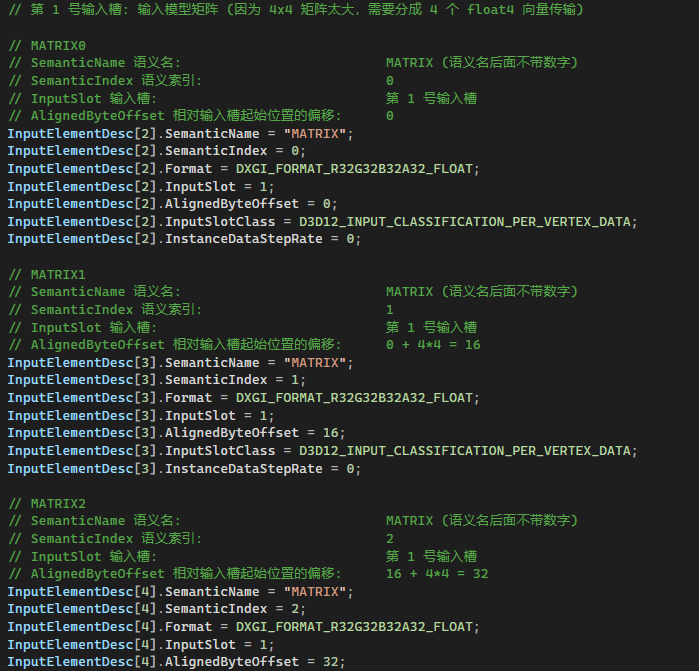
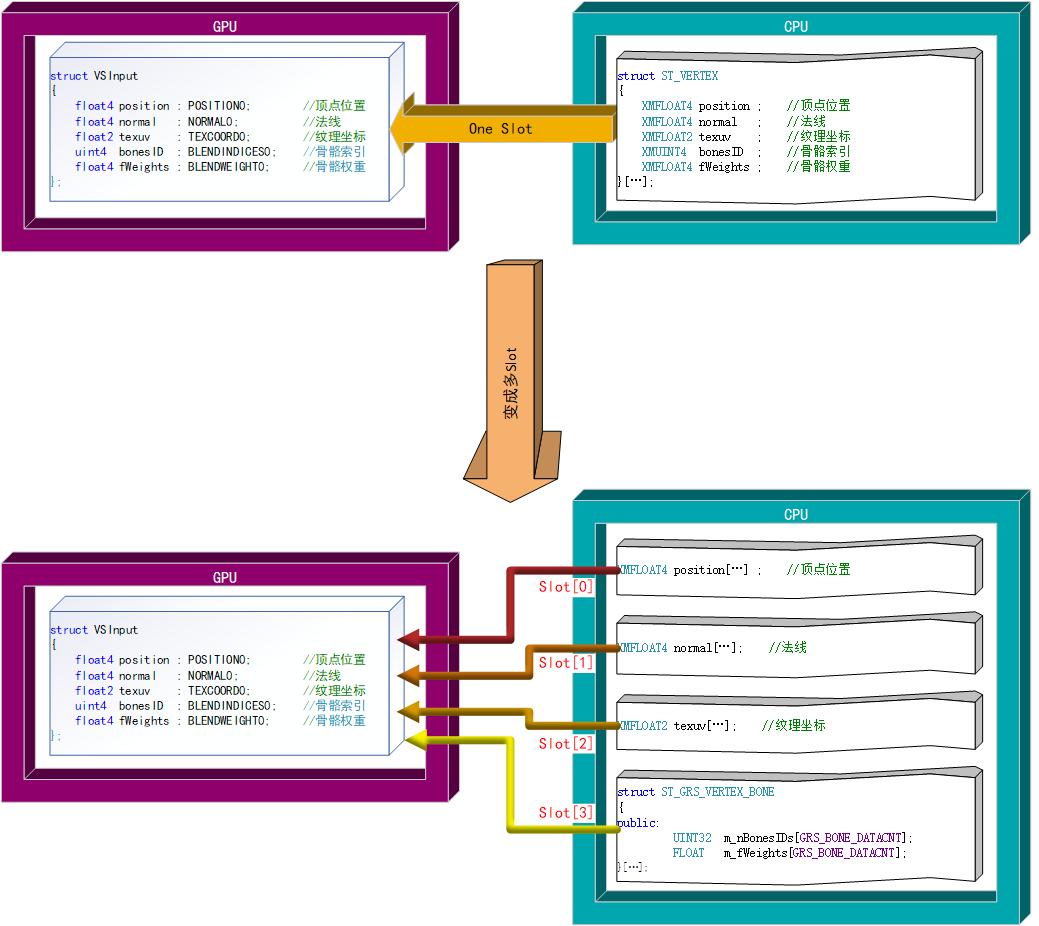
首先我们要填 IA 输入布局,我们分成两个输入流:Vertex Stream 顶点流 与 Instance Stream 实例流,这两个输入流关联不同的 IA 输入参数,使用不同的 Vertex Buffer View 顶点资源描述符 (这就是为什么 ID3D12GraphicsCommandList::IASetVertexBufferView 有三个参数,它是为 IA 多槽并行输入而设计的!),使用不同的顶点资源。
我们在第 7-8 章也使用了 IA 多槽并行输入,多槽输入的优点很多,方便实用,一个输入槽对应一个 D3D12 资源,遇到复杂输入数据是毫无压力的,还能提升数据传输到渲染管线的效率,强烈建议大家一定要熟练掌握并多加使用!
图片出处:GameBabyRockSun_QQ DirectX12(D3D12)基础教程(十七)------让小姐姐翩翩起舞(3D骨骼动画渲染【6】) https://blog.csdn.net/u014038143/article/details/118875765

cpp
// Input Assembler 输入装配阶段
D3D12_INPUT_LAYOUT_DESC InputLayoutDesc = {}; // 输入样式信息结构体
D3D12_INPUT_ELEMENT_DESC InputElementDesc[5] = {}; // 输入元素信息结构体数组
// Input Slot 0: Vertex Stream 顶点流,逐顶点输入
// 顶点位置 float4 Position
InputElementDesc[0].SemanticName = "POSITION";
InputElementDesc[0].SemanticIndex = 0;
InputElementDesc[0].Format = DXGI_FORMAT_R32G32B32A32_FLOAT;
InputElementDesc[0].InputSlot = 0;
InputElementDesc[0].AlignedByteOffset = 0;
InputElementDesc[0].InputSlotClass = D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA;
InputElementDesc[0].InstanceDataStepRate = 0;
// 纹理 UV 坐标 float2 texcoordUV
InputElementDesc[1].SemanticName = "TEXCOORD";
InputElementDesc[1].SemanticIndex = 0;
InputElementDesc[1].Format = DXGI_FORMAT_R32G32_FLOAT;
InputElementDesc[1].InputSlot = 0;
InputElementDesc[1].AlignedByteOffset = 16;
InputElementDesc[1].InputSlotClass = D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA;
InputElementDesc[1].InstanceDataStepRate = 0;
// 顶点所属立方体索引 uint FaceIndex
InputElementDesc[2].SemanticName = "FACEINDEX";
InputElementDesc[2].SemanticIndex = 0;
InputElementDesc[2].Format = DXGI_FORMAT_R32_UINT;
InputElementDesc[2].InputSlot = 0;
InputElementDesc[2].AlignedByteOffset = 24;
InputElementDesc[2].InputSlotClass = D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA;
InputElementDesc[2].InstanceDataStepRate = 0;
// Input Slot 1: Instance Stream 实例流,逐实例输入
// 方块实例相对世界空间的偏移 float3 BlockOffset
InputElementDesc[3].SemanticName = "BLOCKOFFSET";
InputElementDesc[3].SemanticIndex = 0;
InputElementDesc[3].Format = DXGI_FORMAT_R32G32B32_FLOAT;
InputElementDesc[3].InputSlot = 1;
InputElementDesc[3].AlignedByteOffset = 0;
InputElementDesc[3].InputSlotClass = D3D12_INPUT_CLASSIFICATION_PER_INSTANCE_DATA;
InputElementDesc[3].InstanceDataStepRate = 1;
// 方块实例类型 uint BlockType
InputElementDesc[4].SemanticName = "BLOCKTYPE";
InputElementDesc[4].SemanticIndex = 0;
InputElementDesc[4].Format = DXGI_FORMAT_R32_UINT;
InputElementDesc[4].InputSlot = 1;
InputElementDesc[4].AlignedByteOffset = 12;
InputElementDesc[4].InputSlotClass = D3D12_INPUT_CLASSIFICATION_PER_INSTANCE_DATA;
InputElementDesc[4].InstanceDataStepRate = 1;
InputLayoutDesc.NumElements = 5; // 输入元素个数
InputLayoutDesc.pInputElementDescs = InputElementDesc; // 输入元素结构体数组指针
PSODesc.InputLayout = InputLayoutDesc; // 设置渲染管线 IA 阶段的输入样式我们还需要创建 Instance 实例资源和对应的 VBV 描述符:
cpp
// 方块实例结构体
struct BLOCKINSTANCE
{
XMFLOAT3 BlockOffset; // 每个方块实例距离世界中心 (0, 0, 0) 的位移
UINT BlockType; // 方块类型
};
// 方块实例组,存储每一个方块实例
std::vector<BLOCKINSTANCE> BlockGroup;
// 设置随机种子
srand(time(0));
// 方块实例组 (std::vector) 先 resize 大小,这是一个很重要的优化技巧,可以减少 push_back 带来的空间扩容开销!
BlockGroup.resize(1125);
// 随机生成方块实例
for (int y = -13; y <= 13; y += 6)
{
for (int z = -25; z <= 25; z += 6)
{
for (int x = 0; x < 25; x++)
{
float BlockX = 2 * x - 25;
float BlockY = y + 2 * (x % 3) - 2;
float BlockZ = z;
UINT BlockTypeIndex = rand() % BlockCubeTexture_IndexGroup.size();
// 方块实例组新增方块数据,这样我们就得到了一个新的方块实例
BlockGroup.push_back({ XMFLOAT3(BlockX, BlockY, BlockZ), BlockTypeIndex });
}
}
}
// 总共生成 5 x 9 x 25 = 1125 个方块实例
// 上传堆实例资源结构体
D3D12_RESOURCE_DESC InstanceResourceDesc = {};
InstanceResourceDesc.Dimension = D3D12_RESOURCE_DIMENSION_BUFFER;
InstanceResourceDesc.Layout = D3D12_TEXTURE_LAYOUT_ROW_MAJOR;
InstanceResourceDesc.Width = BlockGroup.size() * sizeof(BLOCKINSTANCE);
InstanceResourceDesc.Height = 1;
InstanceResourceDesc.Format = DXGI_FORMAT_UNKNOWN;
InstanceResourceDesc.DepthOrArraySize = 1;
InstanceResourceDesc.MipLevels = 1;
InstanceResourceDesc.SampleDesc.Count = 1;
// 创建实例资源
m_D3D12Device->CreateCommittedResource(&UploadHeapDesc, D3D12_HEAP_FLAG_NONE, &InstanceResourceDesc,
D3D12_RESOURCE_STATE_GENERIC_READ, nullptr, IID_PPV_ARGS(&m_BlockInstanceResource));
// 将数据复制到上传堆
BYTE* TransferPointer = nullptr;
m_BlockInstanceResource->Map(0, nullptr, reinterpret_cast<void**>(&TransferPointer));
memcpy(TransferPointer, &BlockGroup[0], BlockGroup.size() * sizeof(BLOCKINSTANCE));
m_BlockInstanceResource->Unmap(0, nullptr);
// 填写 VBV1 结构体
VertexBufferView[1].BufferLocation = m_BlockInstanceResource->GetGPUVirtualAddress();
VertexBufferView[1].StrideInBytes = sizeof(BLOCKINSTANCE);
VertexBufferView[1].SizeInBytes = BlockGroup.size() * sizeof(BLOCKINSTANCE);Shader 着色器部分与渲染
最后,我们照着硬件实例化的原理修改 GPU 端的 shader 和 CPU 端的 Render 函数 代码即可:
cpp
// RenderShader.hlsl: 渲染方块的 shader
// 用于 MVP 矩阵的常量缓冲
cbuffer GlobalData : register(b0, space0)
{
row_major float4x4 MVPMatrix; // 摄像机提供 MVP 矩阵,将顶点从世界空间变换到齐次裁剪空间
}
// 立方体面结构体,数组索引表示对应的立方体面,数组元素值表示 对应面所用纹理 指向 纹理数组 的索引
struct CUBEFACE
{
// 数组索引 0-5 分别对应右面 (+X),左面 (-X),前面 (+Z),后面 (-Z),上面 (+Y),下面 (-Y)
uint FaceTexture_InArrayIndex[6];
};
// GPU 上的方块类型-纹理索引组 (SRV Structured Buffer)
StructuredBuffer<CUBEFACE> BlockCubeTexture_IndexGroup : register(t0, space0);
// (IA 输入装配 -> VS 顶点着色器) 的 VS 输入参数结构体
struct IA_To_VS
{
// 输入槽 0 (顶点流)
float4 Position : POSITION; // 顶点位置
float2 TexcoordUV : TEXCOORD; // 纹理 UV
uint FaceIndex : FACEINDEX; // 顶点所属的立方体面索引
// 输入槽 1 (实例流)
float3 BlockOffset : BLOCKOFFSET; // 每个方块实例距离世界中心 (0, 0, 0) 的位移
uint BlockType : BLOCKTYPE; // 方块实例类型
};
// (VS 顶点着色器 -> PS 像素着色器) 的 VS 输出,PS 输入参数结构体
struct VS_To_PS
{
float4 NDCPosition : SV_Position; // NDC 空间坐标
float2 TexcoordUV : TEXCOORD; // 纹理 UV
// 像素最终要采样的纹理,在纹理数组的索引 (nointerpolation 表示此参数禁止在光栅化阶段插值)
nointerpolation uint FinalSampleTexture_InArrayIndex : ARRAYINDEX;
};
// 顶点着色器
VS_To_PS VSMain(IA_To_VS VSInput)
{
// VS 输出到 PS 的结构体
VS_To_PS VSOutput;
// 顶点累加偏移,这样就得到了实例顶点相对世界空间的坐标
VSInput.Position.xyz += VSInput.BlockOffset;
// 顶点累乘 MVP 矩阵,变换到齐次裁剪空间,光栅化会进行透视除法变换到 NDC 空间,然后插值
VSOutput.NDCPosition = mul(VSInput.Position, MVPMatrix);
// 纹理 UV 不变,直接赋值,光栅化会进行插值
VSOutput.TexcoordUV = VSInput.TexcoordUV;
// 得到该顶点最终用于采样的纹理索引
VSOutput.FinalSampleTexture_InArrayIndex =
BlockCubeTexture_IndexGroup[VSInput.BlockType].FaceTexture_InArrayIndex[VSInput.FaceIndex];
// 输出顶点到光栅化阶段
return VSOutput;
}
// 纹理数组 2D Texture Array
Texture2DArray m_TextureArray : register(t1, space0);
// 采样器 (邻近点过滤)
SamplerState m_sampler : register(s0, space0);
// 像素着色器
float4 PSMain(VS_To_PS PSInput) : SV_Target
{
// 根据采样器和纹理 UVW 进行纹理采样,W 坐标是纹理在数组中的索引 (Slice Index 切片索引)
return m_TextureArray.Sample(m_sampler, float3(PSInput.TexcoordUV, PSInput.FinalSampleTexture_InArrayIndex));
}
cpp
// 渲染
void Render()
{
......
// 第二次设置根签名,本次检测 PSO 根签名的合法性 (引用资源是否匹配),检测成功会开启显存与寄存器的映射通道
m_CommandList->SetGraphicsRootSignature(m_RootSignature.Get());
// 设置 PSO 渲染管线状态
m_CommandList->SetPipelineState(m_RenderBlockPSO.Get());
// 设置第一个根参数:CBV 描述符 (MVP 缓冲)
m_CommandList->SetGraphicsRootConstantBufferView(0, m_CBVResource->GetGPUVirtualAddress());
// 设置第二个根参数:SRV 根描述符 (结构化缓冲),注意这里设置的是默认堆资源的 GPU 地址!
m_CommandList->SetGraphicsRootShaderResourceView(1, m_StructuredBufferDefaultResource->GetGPUVirtualAddress());
// 用于设置描述符堆用的临时 ID3D12DescriptorHeap 数组
ID3D12DescriptorHeap* _temp_DescriptorHeaps[] = { m_SRVHeap.Get() };
// 设置描述符堆
m_CommandList->SetDescriptorHeaps(1, _temp_DescriptorHeaps);
// 设置 SRV 句柄 (第三个根参数),我们设置了一个纹理数组,只设置了一次哦!切换纹理索引都在 shader 中进行
m_CommandList->SetGraphicsRootDescriptorTable(2, SRVTextureArray_GPUHandle);
// 设置图元拓扑 (输入装配阶段),我们这里设置三角形列表
m_CommandList->IASetPrimitiveTopology(D3D_PRIMITIVE_TOPOLOGY_TRIANGLELIST);
// 设置 VBV 顶点缓冲描述符数组,两个 VBV 都会被设置 (输入装配阶段)
m_CommandList->IASetVertexBuffers(0, 2, VertexBufferView);
// 设置 IBV 索引缓冲描述符 (输入装配阶段)
m_CommandList->IASetIndexBuffer(&IndexBufferView);
// Draw Call 渲染所有目标实例!我们只用了一次 Draw Call 就完成了 1125 个方块的渲染!
m_CommandList->DrawIndexedInstanced(PreBlockIndexData.size(), BlockGroup.size(), 0, 0, 0);
......
}第十五章全代码
main.cpp
cpp
// (15) DrawInstanced: 学会 DirectX 12 的纹理数组、SRV Structured Buffer 结构化缓冲的创建与使用,以及多实例渲染的应用,一次性快速渲染大量方块
#include<Windows.h> // Windows 窗口编程核心头文件
#include<d3d12.h> // DX12 核心头文件
#include<dxgi1_6.h> // DXGI 头文件,用于管理与 DX12 相关联的其他必要设备,如 DXGI 工厂和 交换链
#include<DirectXColors.h> // DirectX 颜色库
#include<DirectXMath.h> // DirectX 数学库
#include<d3dcompiler.h> // DirectX Shader 着色器编译库
#include<wincodec.h> // WIC 图像处理框架,用于解码编码转换图片文件
#include<wrl.h> // COM 组件模板库,方便写 DX12 和 DXGI 相关的接口
#include<string> // C++ 标准 string 库
#include<sstream> // C++ 字符串流处理库
#include<functional> // C++ 标准函数对象库,用于下文的 std::function 函数包装器与 std::bind 绑定回调函数
#include<fstream> // C++ 文件流处理库
#include<vector> // C++ STL vector 容器库
#include<codecvt> // C++ 字符编码转换库,用于 string 转 wstring
#pragma comment(lib,"d3d12.lib") // 链接 DX12 核心 DLL
#pragma comment(lib,"dxgi.lib") // 链接 DXGI DLL
#pragma comment(lib,"dxguid.lib") // 链接 DXGI 必要的设备 GUID
#pragma comment(lib,"d3dcompiler.lib") // 链接 DX12 需要的着色器编译 DLL
#pragma comment(lib,"windowscodecs.lib") // 链接 WIC DLL
using namespace Microsoft;
using namespace Microsoft::WRL; // 使用 wrl.h 里面的命名空间,我们需要用到里面的 Microsoft::WRL::ComPtr COM智能指针
using namespace DirectX; // DirectX 命名空间
// ---------------------------------------------------------------------------------------------------------------
// 命名空间 DX12TextureHelper 包含了帮助我们转换纹理图片格式的结构体与函数
namespace DX12TextureHelper
{
// 纹理转换用,不是 DX12 所支持的格式,DX12 没法用
// Standard GUID -> DXGI 格式转换结构体
struct WICTranslate
{
GUID wic;
DXGI_FORMAT format;
};
// WIC 格式与 DXGI 像素格式的对应表,该表中的格式为被支持的格式
static WICTranslate g_WICFormats[] =
{
{ GUID_WICPixelFormat128bppRGBAFloat, DXGI_FORMAT_R32G32B32A32_FLOAT },
{ GUID_WICPixelFormat64bppRGBAHalf, DXGI_FORMAT_R16G16B16A16_FLOAT },
{ GUID_WICPixelFormat64bppRGBA, DXGI_FORMAT_R16G16B16A16_UNORM },
{ GUID_WICPixelFormat32bppRGBA, DXGI_FORMAT_R8G8B8A8_UNORM },
{ GUID_WICPixelFormat32bppBGRA, DXGI_FORMAT_B8G8R8A8_UNORM },
{ GUID_WICPixelFormat32bppBGR, DXGI_FORMAT_B8G8R8X8_UNORM },
{ GUID_WICPixelFormat32bppRGBA1010102XR, DXGI_FORMAT_R10G10B10_XR_BIAS_A2_UNORM },
{ GUID_WICPixelFormat32bppRGBA1010102, DXGI_FORMAT_R10G10B10A2_UNORM },
{ GUID_WICPixelFormat16bppBGRA5551, DXGI_FORMAT_B5G5R5A1_UNORM },
{ GUID_WICPixelFormat16bppBGR565, DXGI_FORMAT_B5G6R5_UNORM },
{ GUID_WICPixelFormat32bppGrayFloat, DXGI_FORMAT_R32_FLOAT },
{ GUID_WICPixelFormat16bppGrayHalf, DXGI_FORMAT_R16_FLOAT },
{ GUID_WICPixelFormat16bppGray, DXGI_FORMAT_R16_UNORM },
{ GUID_WICPixelFormat8bppGray, DXGI_FORMAT_R8_UNORM },
{ GUID_WICPixelFormat8bppAlpha, DXGI_FORMAT_A8_UNORM }
};
// GUID -> Standard GUID 格式转换结构体
struct WICConvert
{
GUID source;
GUID target;
};
// WIC 像素格式转换表
static WICConvert g_WICConvert[] =
{
// 目标格式一定是最接近的被支持的格式
{ GUID_WICPixelFormatBlackWhite, GUID_WICPixelFormat8bppGray }, // DXGI_FORMAT_R8_UNORM
{ GUID_WICPixelFormat1bppIndexed, GUID_WICPixelFormat32bppRGBA }, // DXGI_FORMAT_R8G8B8A8_UNORM
{ GUID_WICPixelFormat2bppIndexed, GUID_WICPixelFormat32bppRGBA }, // DXGI_FORMAT_R8G8B8A8_UNORM
{ GUID_WICPixelFormat4bppIndexed, GUID_WICPixelFormat32bppRGBA }, // DXGI_FORMAT_R8G8B8A8_UNORM
{ GUID_WICPixelFormat8bppIndexed, GUID_WICPixelFormat32bppRGBA }, // DXGI_FORMAT_R8G8B8A8_UNORM
{ GUID_WICPixelFormat2bppGray, GUID_WICPixelFormat8bppGray }, // DXGI_FORMAT_R8_UNORM
{ GUID_WICPixelFormat4bppGray, GUID_WICPixelFormat8bppGray }, // DXGI_FORMAT_R8_UNORM
{ GUID_WICPixelFormat16bppGrayFixedPoint, GUID_WICPixelFormat16bppGrayHalf }, // DXGI_FORMAT_R16_FLOAT
{ GUID_WICPixelFormat32bppGrayFixedPoint, GUID_WICPixelFormat32bppGrayFloat }, // DXGI_FORMAT_R32_FLOAT
{ GUID_WICPixelFormat16bppBGR555, GUID_WICPixelFormat16bppBGRA5551 }, // DXGI_FORMAT_B5G5R5A1_UNORM
{ GUID_WICPixelFormat32bppBGR101010, GUID_WICPixelFormat32bppRGBA1010102 }, // DXGI_FORMAT_R10G10B10A2_UNORM
{ GUID_WICPixelFormat24bppBGR, GUID_WICPixelFormat32bppRGBA }, // DXGI_FORMAT_R8G8B8A8_UNORM
{ GUID_WICPixelFormat24bppRGB, GUID_WICPixelFormat32bppRGBA }, // DXGI_FORMAT_R8G8B8A8_UNORM
{ GUID_WICPixelFormat32bppPBGRA, GUID_WICPixelFormat32bppRGBA }, // DXGI_FORMAT_R8G8B8A8_UNORM
{ GUID_WICPixelFormat32bppPRGBA, GUID_WICPixelFormat32bppRGBA }, // DXGI_FORMAT_R8G8B8A8_UNORM
{ GUID_WICPixelFormat48bppRGB, GUID_WICPixelFormat64bppRGBA }, // DXGI_FORMAT_R16G16B16A16_UNORM
{ GUID_WICPixelFormat48bppBGR, GUID_WICPixelFormat64bppRGBA }, // DXGI_FORMAT_R16G16B16A16_UNORM
{ GUID_WICPixelFormat64bppBGRA, GUID_WICPixelFormat64bppRGBA }, // DXGI_FORMAT_R16G16B16A16_UNORM
{ GUID_WICPixelFormat64bppPRGBA, GUID_WICPixelFormat64bppRGBA }, // DXGI_FORMAT_R16G16B16A16_UNORM
{ GUID_WICPixelFormat64bppPBGRA, GUID_WICPixelFormat64bppRGBA }, // DXGI_FORMAT_R16G16B16A16_UNORM
{ GUID_WICPixelFormat48bppRGBFixedPoint, GUID_WICPixelFormat64bppRGBAHalf }, // DXGI_FORMAT_R16G16B16A16_FLOAT
{ GUID_WICPixelFormat48bppBGRFixedPoint, GUID_WICPixelFormat64bppRGBAHalf }, // DXGI_FORMAT_R16G16B16A16_FLOAT
{ GUID_WICPixelFormat64bppRGBAFixedPoint, GUID_WICPixelFormat64bppRGBAHalf }, // DXGI_FORMAT_R16G16B16A16_FLOAT
{ GUID_WICPixelFormat64bppBGRAFixedPoint, GUID_WICPixelFormat64bppRGBAHalf }, // DXGI_FORMAT_R16G16B16A16_FLOAT
{ GUID_WICPixelFormat64bppRGBFixedPoint, GUID_WICPixelFormat64bppRGBAHalf }, // DXGI_FORMAT_R16G16B16A16_FLOAT
{ GUID_WICPixelFormat48bppRGBHalf, GUID_WICPixelFormat64bppRGBAHalf }, // DXGI_FORMAT_R16G16B16A16_FLOAT
{ GUID_WICPixelFormat64bppRGBHalf, GUID_WICPixelFormat64bppRGBAHalf }, // DXGI_FORMAT_R16G16B16A16_FLOAT
{ GUID_WICPixelFormat128bppPRGBAFloat, GUID_WICPixelFormat128bppRGBAFloat }, // DXGI_FORMAT_R32G32B32A32_FLOAT
{ GUID_WICPixelFormat128bppRGBFloat, GUID_WICPixelFormat128bppRGBAFloat }, // DXGI_FORMAT_R32G32B32A32_FLOAT
{ GUID_WICPixelFormat128bppRGBAFixedPoint, GUID_WICPixelFormat128bppRGBAFloat }, // DXGI_FORMAT_R32G32B32A32_FLOAT
{ GUID_WICPixelFormat128bppRGBFixedPoint, GUID_WICPixelFormat128bppRGBAFloat }, // DXGI_FORMAT_R32G32B32A32_FLOAT
{ GUID_WICPixelFormat32bppRGBE, GUID_WICPixelFormat128bppRGBAFloat }, // DXGI_FORMAT_R32G32B32A32_FLOAT
{ GUID_WICPixelFormat32bppCMYK, GUID_WICPixelFormat32bppRGBA }, // DXGI_FORMAT_R8G8B8A8_UNORM
{ GUID_WICPixelFormat64bppCMYK, GUID_WICPixelFormat64bppRGBA }, // DXGI_FORMAT_R16G16B16A16_UNORM
{ GUID_WICPixelFormat40bppCMYKAlpha, GUID_WICPixelFormat64bppRGBA }, // DXGI_FORMAT_R16G16B16A16_UNORM
{ GUID_WICPixelFormat80bppCMYKAlpha, GUID_WICPixelFormat64bppRGBA }, // DXGI_FORMAT_R16G16B16A16_UNORM
{ GUID_WICPixelFormat32bppRGB, GUID_WICPixelFormat32bppRGBA }, // DXGI_FORMAT_R8G8B8A8_UNORM
{ GUID_WICPixelFormat64bppRGB, GUID_WICPixelFormat64bppRGBA }, // DXGI_FORMAT_R16G16B16A16_UNORM
{ GUID_WICPixelFormat64bppPRGBAHalf, GUID_WICPixelFormat64bppRGBAHalf }, // DXGI_FORMAT_R16G16B16A16_FLOAT
{ GUID_WICPixelFormat128bppRGBAFloat, GUID_WICPixelFormat128bppRGBAFloat }, // DXGI_FORMAT_R32G32B32A32_FLOAT
{ GUID_WICPixelFormat64bppRGBAHalf, GUID_WICPixelFormat64bppRGBAHalf }, // DXGI_FORMAT_R16G16B16A16_FLOAT
{ GUID_WICPixelFormat64bppRGBA, GUID_WICPixelFormat64bppRGBA }, // DXGI_FORMAT_R16G16B16A16_UNORM
{ GUID_WICPixelFormat32bppRGBA, GUID_WICPixelFormat32bppRGBA }, // DXGI_FORMAT_R8G8B8A8_UNORM
{ GUID_WICPixelFormat32bppBGRA, GUID_WICPixelFormat32bppBGRA }, // DXGI_FORMAT_B8G8R8A8_UNORM
{ GUID_WICPixelFormat32bppBGR, GUID_WICPixelFormat32bppBGR }, // DXGI_FORMAT_B8G8R8X8_UNORM
{ GUID_WICPixelFormat32bppRGBA1010102XR, GUID_WICPixelFormat32bppRGBA1010102XR },// DXGI_FORMAT_R10G10B10_XR_BIAS_A2_UNORM
{ GUID_WICPixelFormat32bppRGBA1010102, GUID_WICPixelFormat32bppRGBA1010102 }, // DXGI_FORMAT_R10G10B10A2_UNORM
{ GUID_WICPixelFormat16bppBGRA5551, GUID_WICPixelFormat16bppBGRA5551 }, // DXGI_FORMAT_B5G5R5A1_UNORM
{ GUID_WICPixelFormat16bppBGR565, GUID_WICPixelFormat16bppBGR565 }, // DXGI_FORMAT_B5G6R5_UNORM
{ GUID_WICPixelFormat32bppGrayFloat, GUID_WICPixelFormat32bppGrayFloat }, // DXGI_FORMAT_R32_FLOAT
{ GUID_WICPixelFormat16bppGrayHalf, GUID_WICPixelFormat16bppGrayHalf }, // DXGI_FORMAT_R16_FLOAT
{ GUID_WICPixelFormat16bppGray, GUID_WICPixelFormat16bppGray }, // DXGI_FORMAT_R16_UNORM
{ GUID_WICPixelFormat8bppGray, GUID_WICPixelFormat8bppGray }, // DXGI_FORMAT_R8_UNORM
{ GUID_WICPixelFormat8bppAlpha, GUID_WICPixelFormat8bppAlpha } // DXGI_FORMAT_A8_UNORM
};
// 查表确定兼容的最接近格式是哪个
bool GetTargetPixelFormat(const GUID* pSourceFormat, GUID* pTargetFormat)
{
*pTargetFormat = *pSourceFormat;
for (size_t i = 0; i < _countof(g_WICConvert); ++i)
{
if (InlineIsEqualGUID(g_WICConvert[i].source, *pSourceFormat))
{
*pTargetFormat = g_WICConvert[i].target;
return true;
}
}
return false; // 找不到,就返回 false
}
// 查表确定最终对应的 DXGI 格式是哪一个
DXGI_FORMAT GetDXGIFormatFromPixelFormat(const GUID* pPixelFormat)
{
for (size_t i = 0; i < _countof(g_WICFormats); ++i)
{
if (InlineIsEqualGUID(g_WICFormats[i].wic, *pPixelFormat))
{
return g_WICFormats[i].format;
}
}
return DXGI_FORMAT_UNKNOWN; // 找不到,就返回 UNKNOWN
}
}
// 用于绑定回调函数的中间层
class CallBackWrapper
{
public:
// 用于保存 DX12Engine 类的成员回调函数的包装器
inline static std::function<LRESULT(HWND, UINT, WPARAM, LPARAM)> Broker_Func;
// 用于传递到 lpfnWndProc 的静态成员函数,内部调用保存 DX12Engine::CallBackFunc 的函数包装器
// 静态成员函数属于类,不属于类实例对象,所以没有 this 指针,可以直接赋值给 C-Style 的函数指针
static LRESULT CALLBACK CallBackFunc(HWND hwnd, UINT msg, WPARAM wParam, LPARAM lParam)
{
return Broker_Func(hwnd, msg, wParam, lParam);
}
};
// 摄像机类
class Camera
{
private:
XMVECTOR EyePosition = XMVectorSet(4, 4, 2, 1); // 摄像机在世界空间下的位置
XMVECTOR FocusPosition = XMVectorSet(0, 0, 0, 1); // 摄像机在世界空间下观察的焦点位置
XMVECTOR UpDirection = XMVectorSet(0, 1, 0, 0); // 世界空间垂直向上的向量
// 摄像机观察方向的单位向量,用于前后移动
XMVECTOR ViewDirection = XMVector3Normalize(FocusPosition - EyePosition);
// 焦距,摄像机原点与焦点的距离,XMVector3Length 表示对向量取模
float FocalLength = XMVectorGetX(XMVector3Length(FocusPosition - EyePosition));
// 摄像机向右方向的单位向量,用于左右移动,XMVector3Cross 求两向量叉乘
// 注意叉乘不符合交换律,交换后结果方向相反,如果左右移动方向反了,可能需要检查一下叉乘
XMVECTOR RightDirection = XMVector3Normalize(XMVector3Cross(UpDirection, ViewDirection));
POINT LastCursorPoint = {}; // 上一次鼠标的位置
float FovAngleY = XM_PIDIV4; // 垂直视场角
float AspectRatio = 16.0 / 9.0; // 投影窗口宽高比
float NearZ = 0.1; // 近平面到原点的距离
float FarZ = 1000; // 远平面到原点的距离
XMMATRIX ModelMatrix; // 模型矩阵,模型空间 -> 世界空间
XMMATRIX ViewMatrix; // 观察矩阵,世界空间 -> 观察空间
XMMATRIX ProjectionMatrix; // 投影矩阵,观察空间 -> 齐次裁剪空间
XMMATRIX MVPMatrix; // MVP 矩阵,类外需要用公有方法 GetMVPMatrix 获取
public:
Camera() // 摄像机的构造函数
{
// 模型矩阵,这里设置成单位矩阵,是因为模型导入的时候已经是 y 轴朝上的了,无需再进行旋转
ModelMatrix = XMMatrixIdentity();
// 观察矩阵,注意前两个参数是点,第三个参数才是向量
ViewMatrix = XMMatrixLookAtLH(EyePosition, FocusPosition, UpDirection);
// 投影矩阵 (注意近平面和远平面距离不能 <= 0!)
ProjectionMatrix = XMMatrixPerspectiveFovLH(FovAngleY, AspectRatio, NearZ, FarZ);
}
// 摄像机前后移动,参数 Stride 是移动速度 (步长),正数向前移动,负数向后移动
void Walk(float Stride)
{
EyePosition += Stride * ViewDirection;
FocusPosition += Stride * ViewDirection;
}
// 摄像机左右移动,参数 Stride 是移动速度 (步长),正数向右移动,负数向左移动
void Strafe(float Stride)
{
EyePosition += Stride * RightDirection;
FocusPosition += Stride * RightDirection;
}
// 鼠标在屏幕空间 y 轴上移动,相当于摄像机以向右的向量 RightDirection 向上向下旋转,人眼往上下看
void RotateByY(float angleY)
{
// 以向右向量为轴构建旋转矩阵,旋转 ViewDirection 和 UpDirection
XMMATRIX R = XMMatrixRotationAxis(RightDirection, angleY);
UpDirection = XMVector3TransformNormal(UpDirection, R);
ViewDirection = XMVector3TransformNormal(ViewDirection, R);
// 利用 ViewDirection 观察向量、FocalLength 焦距,更新焦点位置
FocusPosition = EyePosition + ViewDirection * FocalLength;
}
// 鼠标在屏幕空间 x 轴上移动,相当于摄像机绕世界空间的 y 轴向左向右旋转,人眼往左右看
void RotateByX(float angleX)
{
// 以世界坐标系下的 y 轴 (0,1,0,0) 构建旋转矩阵,三个向量 ViewDirection, UpDirection, RightDirection 都要旋转
XMMATRIX R = XMMatrixRotationY(angleX);
UpDirection = XMVector3TransformNormal(UpDirection, R);
ViewDirection = XMVector3TransformNormal(ViewDirection, R);
RightDirection = XMVector3TransformNormal(RightDirection, R);
// 利用 ViewDirection 观察向量、FocalLength 焦距,更新焦点位置
FocusPosition = EyePosition + ViewDirection * FocalLength;
}
// 更新上一次的鼠标位置
void UpdateLastCursorPos()
{
GetCursorPos(&LastCursorPoint);
}
// 当鼠标左键长按并移动时,旋转摄像机视角
void CameraRotate()
{
POINT CurrentCursorPoint = {};
GetCursorPos(&CurrentCursorPoint); // 获取当前鼠标位置
// 根据鼠标在屏幕坐标系的 x,y 轴的偏移量,计算摄像机旋转角
float AngleX = XMConvertToRadians(0.25 * static_cast<float>(CurrentCursorPoint.x - LastCursorPoint.x));
float AngleY = XMConvertToRadians(0.25 * static_cast<float>(CurrentCursorPoint.y - LastCursorPoint.y));
// 旋转摄像机
RotateByY(AngleY);
RotateByX(AngleX);
UpdateLastCursorPos(); // 旋转完毕,更新上一次的鼠标位置
}
// 更新 MVP 矩阵
void UpdateMVPMatrix()
{
// 主要是更新观察矩阵
ViewMatrix = XMMatrixLookAtLH(EyePosition, FocusPosition, UpDirection);
MVPMatrix = ModelMatrix * ViewMatrix * ProjectionMatrix;
}
// 获取 MVP 矩阵
inline XMMATRIX& GetMVPMatrix()
{
// 每次返回前,都更新一次
UpdateMVPMatrix();
return MVPMatrix;
}
// 获取观察矩阵的逆矩阵 (观察空间 -> 世界空间)
inline XMMATRIX GetInverseViewMatrix()
{
UpdateMVPMatrix();
// 矩阵求逆,这个函数还可以顺带算行列式,第一个参数是原矩阵的行列式,如果需要的话可以用个变量接着
return XMMatrixInverse(nullptr, ViewMatrix);
}
// 获取投影矩阵的逆矩阵 (齐次裁剪空间 -> 观察空间)
inline XMMATRIX GetInverseProjectionMatrix()
{
UpdateMVPMatrix();
return XMMatrixInverse(nullptr, ProjectionMatrix);
}
// 设置摄像机位置
inline void SetEyePosition(XMVECTOR pos)
{
EyePosition = pos;
// 改变位置后,观察向量、焦距、右方向向量也要改变,否则会发生视角瞬移
ViewDirection = XMVector3Normalize(FocusPosition - EyePosition);
FocalLength = XMVectorGetX(XMVector3Length(FocusPosition - EyePosition));
RightDirection = XMVector3Normalize(XMVector3Cross(UpDirection, ViewDirection));
}
// 设置摄像机焦点
inline void SetFocusPosition(XMVECTOR pos)
{
FocusPosition = pos;
// 改变位置后,观察向量、焦距、右方向向量也要改变,否则会发生视角瞬移
ViewDirection = XMVector3Normalize(FocusPosition - EyePosition);
FocalLength = XMVectorGetX(XMVector3Length(FocusPosition - EyePosition));
RightDirection = XMVector3Normalize(XMVector3Cross(UpDirection, ViewDirection));
}
// 设置摄像机的模型矩阵
inline void SetModelMatrix(XMMATRIX ModelMatrix)
{
this->ModelMatrix = ModelMatrix;
}
};
// ---------------------------------------------------------------------------------------------------------------
// DX12 引擎
class DX12Engine
{
private:
int WindowWidth = 1280; // 窗口宽度
int WindowHeight = 720; // 窗口高度
HWND m_hwnd; // 窗口句柄
ComPtr<ID3D12Debug> m_D3D12DebugDevice; // D3D12 调试层设备
UINT m_DXGICreateFactoryFlag = NULL; // 创建 DXGI 工厂时需要用到的标志
ComPtr<IDXGIFactory5> m_DXGIFactory; // DXGI 工厂
ComPtr<IDXGIAdapter1> m_DXGIAdapter; // 显示适配器 (显卡)
ComPtr<ID3D12Device4> m_D3D12Device; // D3D12 核心设备
ComPtr<ID3D12CommandQueue> m_CommandQueue; // 命令队列
ComPtr<ID3D12CommandAllocator> m_CommandAllocator; // 命令分配器
ComPtr<ID3D12GraphicsCommandList> m_CommandList; // 命令列表
ComPtr<IDXGISwapChain3> m_DXGISwapChain; // DXGI 交换链
ComPtr<ID3D12DescriptorHeap> m_RTVHeap; // RTV 描述符堆
ComPtr<ID3D12Resource> m_RenderTarget[3]; // 渲染目标数组,每一副渲染目标对应一个窗口缓冲区
D3D12_CPU_DESCRIPTOR_HANDLE RTVHandle; // RTV 描述符句柄
UINT RTVDescriptorSize = 0; // RTV 描述符的大小
UINT FrameIndex = 0; // 帧索引,表示当前渲染的第 i 帧 (第 i 个渲染目标)
ComPtr<ID3D12Fence> m_Fence; // 围栏
UINT64 FenceValue = 0; // 用于围栏等待的围栏值
HANDLE RenderEvent = NULL; // GPU 渲染事件
D3D12_RESOURCE_BARRIER beg_barrier = {}; // 渲染开始的资源屏障,呈现 -> 渲染目标
D3D12_RESOURCE_BARRIER end_barrier = {}; // 渲染结束的资源屏障,渲染目标 -> 呈现
ComPtr<ID3D12DescriptorHeap> m_DSVHeap; // DSV 描述符堆
D3D12_CPU_DESCRIPTOR_HANDLE DSVHandle; // DSV 描述符句柄
ComPtr<ID3D12Resource> m_DepthStencilBuffer; // DSV 深度模板缓冲资源
DXGI_FORMAT DSVFormat = DXGI_FORMAT_D24_UNORM_S8_UINT; // DSV 资源的格式
ComPtr<ID3D12Resource> m_CBVResource; // 常量缓冲资源,用于存放 MVP 矩阵,MVP 矩阵每帧都要更新,所以需要存储在常量缓冲区中
struct CBuffer // 常量缓冲结构体
{
XMFLOAT4X4 MVPMatrix; // MVP 矩阵,用于将顶点数据从顶点空间变换到齐次裁剪空间
};
CBuffer* MVPBuffer = nullptr; // 常量缓冲结构体指针,里面存储的是 MVP 矩阵信息,下文 Map 后指针会指向 CBVResource 的地址
Camera m_FirstCamera; // 第一人称摄像机
// 视口
D3D12_VIEWPORT ViewPort = D3D12_VIEWPORT{ 0, 0, float(WindowWidth), float(WindowHeight), D3D12_MIN_DEPTH, D3D12_MAX_DEPTH };
// 裁剪矩形
D3D12_RECT ScissorRect = D3D12_RECT{ 0, 0, WindowWidth, WindowHeight };
// ---------------------------------------------------------------------------------------------------------------
ComPtr<IWICImagingFactory> m_WICFactory; // WIC 工厂
ComPtr<IWICBitmapDecoder> m_WICBitmapDecoder; // 位图解码器
ComPtr<IWICBitmapFrameDecode> m_WICBitmapDecodeFrame; // 由解码器得到的单个位图帧
ComPtr<IWICFormatConverter> m_WICFormatConverter; // 位图转换器
// 纹理结构体
struct Texture
{
std::wstring TextureName; // 纹理的名字
std::wstring FilePath; // 图像文件的位置
ComPtr<IWICBitmapSource> WICBitmapSource; // 每张纹理的 WIC 位图资源,用于获取位图数据
};
// 纹理资源组,用于临时加载并存储渲染需要用到纹理资源,这些纹理资源会加入到纹理数组中
// 当资源全部加载到上传堆,全部 WIC 位图临时资源都会被释放,不再让它们占内存
std::vector<Texture> TextureGroup =
{
{L"蓝冰", L"resource/ice_packed.png"}, // 0
{L"圆石", L"resource/cobblestone.png"}, // 1
{L"绿宝石块", L"resource/emerald_block.png"}, // 2
{L"熔炉正面", L"resource/furnace_front_off.png"}, // 3
{L"熔炉侧面", L"resource/furnace_side.png"}, // 4
{L"熔炉顶面", L"resource/furnace_top.png"}, // 5
{L"金矿", L"resource/gold_ore.png"}, // 6
{L"金块", L"resource/gold_block.png"}, // 7
{L"音符盒", L"resource/noteblock.png"}, // 8
{L"活塞底面", L"resource/piston_bottom.png"}, // 9
{L"活塞侧面", L"resource/piston_side.png"}, // 10
{L"活塞顶面", L"resource/piston_top_normal.png"}, // 11
{L"红石块", L"resource/redstone_block.png"}, // 12
{L"红石灯激活状态", L"resource/redstone_lamp_on.png"}, // 13
{L"TNT底面", L"resource/tnt_bottom.png"}, // 14
{L"TNT侧面", L"resource/tnt_side.png"}, // 15
{L"TNT顶面", L"resource/tnt_top.png"}, // 16
{L"基岩", L"resource/bedrock.png"}, // 17
{L"书架", L"resource/bookshelf.png"}, // 18
{L"命令方块", L"resource/command_block.png"}, // 19
{L"工作台正面", L"resource/crafting_table_front.png"}, // 20
{L"工作台侧面", L"resource/crafting_table_side.png"}, // 21
{L"工作台顶面", L"resource/crafting_table_top.png"}, // 22
{L"水平发射器正面", L"resource/dispenser_front_horizontal.png"}, // 23
{L"垂直发射器顶面", L"resource/dispenser_front_vertical.png"}, // 24
{L"水平投掷器正面", L"resource/dropper_front_horizontal.png"}, // 25
{L"垂直投掷器顶面", L"resource/dropper_front_vertical.png"}, // 26
{L"绿宝石原矿", L"resource/emerald_ore.png"}, // 27
{L"玻璃", L"resource/glass.png"}, // 28
{L"萤石", L"resource/glowstone.png"}, // 29
{L"铁矿", L"resource/iron_ore.png"}, // 30
{L"橡木原木侧面", L"resource/log_oak.png"}, // 31
{L"橡木原木顶面", L"resource/log_oak_top.png"}, // 32
{L"橡木木板", L"resource/planks_oak.png"}, // 33
{L"沙子", L"resource/sand.png"}, // 34
{L"石砖", L"resource/stonebrick.png"}, // 35
{L"平滑石", L"resource/stone_slab_top.png"}, // 36
{L"石英块底面", L"resource/quartz_block_bottom.png"}, // 37
{L"石英块侧面", L"resource/quartz_block_side.png"}, // 38
{L"石英块顶面", L"resource/quartz_block_top.png"}, // 39
};
// 纹理数组所有纹理的 DXGI 格式
DXGI_FORMAT TextureFormat = DXGI_FORMAT_UNKNOWN;
// Texture Array 纹理数组默认堆资源,顾名思义,可以存储多个纹理的数组,但是 GPU Texture Array,绝大部分手游端游都在用它
// 和我们之前理解的 Texture Group 不同,我们要创建的是 GPU 上可供使用的纹理数组,之前我们一直用的是 cpp 端的 vector, array 这些弄的
// 所以你就会见到画一个纹理就要 SetGraphicsRootDescriptorTable 一次,就比如一个熔炉方块要换三张纹理图片,要 Set 三次
// 对于有大量纹理要切换的情况,这种方法肯定不合适,开销太大了,而且接下来要讲的多实例渲染也不适合这种方法 (会占很多寄存器)
// 所以我们需要 GPU Texture Array 来存储这些纹理,对于纹理数组,一次 SetGraphicsRootDescriptorTable 就水到渠成了
// 纹理数组需要所有元素都要有相同的属性 (纹理宽度高度相等,格式,Mipmap 相等),否则会渲染错误
ComPtr<ID3D12Resource> m_TextureArrayDefaultResource;
// GPU Texture Array 的上传堆资源,用于中转
ComPtr<ID3D12Resource> m_TextureArrayUploadResource;
UINT BitsPerPixel = 0; // 纹理数组所有纹理的图像深度 (单位:比特)
UINT TextureWidth = 0; // 纹理数组所有纹理的宽度 (单位:像素)
UINT TextureHeight = 0; // 纹理数组所有纹理的高度 (单位:像素)
UINT64 BytePerRowSize = 0; // 纹理数组单个纹理每行所占的字节数,用于纹理复制 (单位:字节)
UINT64 TextureSize = 0; // 纹理数组单个纹理的真实大小 (单位:字节)
UINT64 UploadResourceRowSize = 0; // 对于单个纹理,上传堆资源每行对齐需要的大小 (单位:字节,需要 256 字节对齐)
UINT64 UploadSubResourceSize = 0; // 对于单个纹理,上传堆资源所需要分配的总大小 (单位:字节)
UINT64 UploadArrayElementSize = 0; // 硬件偏移寻址纹理数组每个元素,上传堆资源分配对齐需要的大小 (单位:字节,需要 512 字节对齐)
UINT64 UploadResourceSize = 0; // 对于整个纹理数组,上传堆资源最终要分配的总大小 (单位:字节)
D3D12_HEAP_PROPERTIES UploadHeapDesc = { D3D12_HEAP_TYPE_UPLOAD }; // 上传堆属性结构体
D3D12_HEAP_PROPERTIES DefaultHeapDesc = { D3D12_HEAP_TYPE_DEFAULT }; // 默认堆属性结构体
ComPtr<ID3D12DescriptorHeap> m_SRVHeap; // SRV 描述符堆
D3D12_CPU_DESCRIPTOR_HANDLE SRVTextureArray_CPUHandle; // 纹理数组的 CPU 句柄,用于 CPU 端创建 SRV 描述符
D3D12_GPU_DESCRIPTOR_HANDLE SRVTextureArray_GPUHandle; // 纹理数组的 GPU 句柄,用于 GPU 端着色器引用资源
// ---------------------------------------------------------------------------------------------------------------
// 立方体面结构体,只有一个 UINT 数组成员
// 数组索引表示对应的立方体面索引,数组元素值表示对应立方体面的纹理在 Texture Array 的位置
struct CUBEFACE
{
// 六个立方体面对应的纹理在 Texture Array 中的位置
// 数组索引 0-5 分别对应右面 (+X),左面 (-X),前面 (+Z),后面 (-Z),上面 (+Y),下面 (-Y)
UINT FaceTexture_InArrayIndex[6];
};
// 方块类型-纹理索引组,每个 vector 索引表示不同的方块类型,每个 vector 元素值表示对应方块六个面的纹理数据索引数据
// 在 shader 会根据 逐实例数据 (方块类型) 和 逐顶点数据 (方块每个面对应的纹理索引) 来索引对应的纹理,这样就不用反复换绑 SRV 了
std::vector<CUBEFACE> BlockCubeTexture_IndexGroup =
{
// 一个完整方块有六个面,右面 (+X),左面 (-X),前面 (+Z),后面 (-Z),上面 (+Y),下面 (-Y),我们以右面是方块正面为准
{0, 0, 0, 0, 0, 0}, // 0.蓝冰
{1, 1, 1, 1, 1, 1}, // 1.圆石
{2, 2, 2, 2, 2, 2}, // 2.绿宝石块
{3, 4, 4, 4, 5, 5}, // 3.熔炉 (三个面)
{6, 6, 6, 6, 6, 6}, // 4.金矿
{7, 7, 7, 7, 7, 7}, // 5.金块
{8, 8, 8, 8, 8, 8}, // 6.音符盒
{10, 10, 10, 10, 11, 9}, // 7.活塞 (三个面)
{12, 12, 12, 12, 12, 12}, // 8.红石块
{13, 13, 13, 13, 13, 13}, // 9.激活状态的红石灯
{15, 15, 15, 15, 16, 14}, // 10.TNT (三个面)
{17, 17, 17, 17, 17, 17}, // 11.基岩
{18, 18, 18, 18, 33, 33}, // 12.书架 (两个面)
{19, 19, 19, 19, 19, 19}, // 13.命令方块
{20, 20, 21, 21, 22, 22}, // 14.工作台 (三个面)
{23, 9, 9, 9, 9, 9}, // 15.水平发射器 (三个面)
{9, 9, 9, 9, 24, 9}, // 16.垂直发射器 (三个面)
{25, 9, 9, 9, 9, 9}, // 17.水平投掷器 (三个面)
{9, 9, 9, 9, 26, 9}, // 18.垂直投掷器 (三个面)
{27, 27, 27, 27, 27, 27}, // 19.绿宝石原矿
{28, 28, 28, 28, 28, 28}, // 20.玻璃
{29, 29, 29, 29, 29, 29}, // 21.萤石
{30, 30, 30, 30, 30, 30}, // 22.铁矿
{31, 31, 31, 31, 32, 32}, // 23.橡木原木 (两个面)
{31, 31, 31, 31, 31, 31}, // 24.橡树木
{33, 33, 33, 33, 33, 33}, // 25.橡木木板
{34, 34, 34, 34, 34, 34}, // 26.沙子
{35, 35, 35, 35, 35, 35}, // 27.石砖
{36, 36, 36, 36, 36, 36}, // 28.平滑石
{38, 38, 38, 38, 39, 37} // 29.石英块 (三个面)
};
// SRV Structured Buffer 的上传堆资源
ComPtr<ID3D12Resource> m_StructuredBufferUploadResource;
// SRV Structured Buffer 的默认堆资源
ComPtr<ID3D12Resource> m_StructuredBufferDefaultResource;
// ---------------------------------------------------------------------------------------------------------------
ComPtr<ID3D12RootSignature> m_RootSignature; // 根签名
ComPtr<ID3D12PipelineState> m_RenderBlockPSO; // 渲染管线状态
// Vertex Buffer View (VBV) 顶点缓冲描述符数组, VBV0 是逐顶点流,VBV1 是逐实例流
D3D12_VERTEX_BUFFER_VIEW VertexBufferView[2] = {};
// Index Buffer View (IBV) 索引缓冲描述符
D3D12_INDEX_BUFFER_VIEW IndexBufferView = {};
// 方块顶点结构体
struct VERTEX
{
XMFLOAT4 Position; // 顶点在方块自身的模型空间的位置
XMFLOAT2 TexcoordUV; // 顶点纹理 UV
UINT FaceIndex; // 顶点所属的立方体面索引
};
// 每个方块实例共用的顶点数据 (逐顶点流),这一回我们吸取第 7-8 章的经验,将方块中心放在模型空间中心 (0, 0, 0),注意绕序!
std::vector<VERTEX> PreBlockVertexData =
{
// 一个完整方块有六个面,右面 (+X),左面 (-X),前面 (+Z),后面 (-Z),上面 (+Y),下面 (-Y),我们以右面是方块正面为准
// 顺序遵循 左上角 -> 右上角 -> 右下角 -> 左下角
// 右面 (+X, FaceIndex = 0)
{ XMFLOAT4(1, 1, -1, 1), XMFLOAT2(0, 0), 0 },
{ XMFLOAT4(1, 1, 1, 1), XMFLOAT2(1, 0), 0 },
{ XMFLOAT4(1, -1, 1, 1), XMFLOAT2(1, 1), 0 },
{ XMFLOAT4(1, -1, -1, 1), XMFLOAT2(0, 1), 0 },
// 左面 (-X, FaceIndex = 1)
{ XMFLOAT4(-1, 1, 1, 1), XMFLOAT2(0, 0), 1 },
{ XMFLOAT4(-1, 1, -1, 1), XMFLOAT2(1, 0), 1 },
{ XMFLOAT4(-1, -1, -1, 1), XMFLOAT2(1, 1), 1 },
{ XMFLOAT4(-1, -1, 1, 1), XMFLOAT2(0, 1), 1 },
// 前面 (+Z, FaceIndex = 2)
{ XMFLOAT4(1, 1, 1, 1), XMFLOAT2(0, 0), 2 },
{ XMFLOAT4(-1, 1, 1, 1), XMFLOAT2(1, 0), 2 },
{ XMFLOAT4(-1, -1, 1, 1), XMFLOAT2(1, 1), 2 },
{ XMFLOAT4(1, -1, 1, 1), XMFLOAT2(0, 1), 2 },
// 后面 (-Z, FaceIndex = 3)
{ XMFLOAT4(-1, 1, -1, 1), XMFLOAT2(0, 0), 3 },
{ XMFLOAT4(1, 1, -1, 1), XMFLOAT2(1, 0), 3 },
{ XMFLOAT4(1, -1, -1, 1), XMFLOAT2(1, 1), 3 },
{ XMFLOAT4(-1, -1, -1, 1), XMFLOAT2(0, 1), 3 },
// 上面 (+Y, FaceIndex = 4)
{ XMFLOAT4(-1, 1, -1, 1), XMFLOAT2(0, 0), 4 },
{ XMFLOAT4(-1, 1, 1, 1), XMFLOAT2(1, 0), 4 },
{ XMFLOAT4(1, 1, 1, 1), XMFLOAT2(1, 1), 4 },
{ XMFLOAT4(1, 1, -1, 1), XMFLOAT2(0, 1), 4 },
// 下面 (-Y, FaceIndex = 5)
{ XMFLOAT4(-1, -1, -1, 1), XMFLOAT2(0, 0), 5 },
{ XMFLOAT4(-1, -1, 1, 1), XMFLOAT2(1, 0), 5 },
{ XMFLOAT4(1, -1, 1, 1), XMFLOAT2(1, 1), 5 },
{ XMFLOAT4(1, -1, -1, 1), XMFLOAT2(0, 1), 5 },
};
// 每个方块实例共用的索引数据
std::vector<UINT> PreBlockIndexData =
{
// 右面
0, 1, 2, 0, 2, 3,
// 左面
4, 5, 6, 4, 6, 7,
// 前面
8, 9, 10, 8, 10, 11,
// 后面
12, 13, 14, 12, 14, 15,
// 上面
16, 17, 18, 16, 18, 19,
// 下面
20, 21, 22, 20, 22, 23
};
// 上传堆顶点资源
ComPtr<ID3D12Resource> m_BlockVertexResource;
// 上传堆索引资源
ComPtr<ID3D12Resource> m_BlockIndexResource;
// 上传堆实例资源
ComPtr<ID3D12Resource> m_BlockInstanceResource;
// 方块实例结构体
struct BLOCKINSTANCE
{
XMFLOAT3 BlockOffset; // 每个方块实例距离世界中心 (0, 0, 0) 的位移
UINT BlockType; // 方块类型
};
// 方块实例组,存储每一个方块实例 (实例以及实例化的知识在 STEP20_CreatePSO 那里)
std::vector<BLOCKINSTANCE> BlockGroup;
// ---------------------------------------------------------------------------------------------------------------
public:
// 初始化窗口
void STEP01_InitWindow(HINSTANCE hins)
{
WNDCLASS wc = {}; // 用于记录窗口类信息的结构体
wc.hInstance = hins; // 窗口类需要一个应用程序的实例句柄 hinstance
// 绑定回调函数,利用 std::bind,将 DX12Engine::CallBackFunc 绑定到 CallBackWrapper 的函数包装器上
CallBackWrapper::Broker_Func = std::bind(&DX12Engine::CallBackFunc, this,
std::placeholders::_1, std::placeholders::_2, std::placeholders::_3, std::placeholders::_4);
wc.lpfnWndProc = CallBackWrapper::CallBackFunc; // 窗口类需要一个回调函数,用于处理窗口产生的消息,注意这里传递的是中间层的回调函数
wc.lpszClassName = L"DX12 Game"; // 窗口类的名称
RegisterClass(&wc); // 注册窗口类,将窗口类录入到操作系统中
// 使用上文的窗口类创建窗口
m_hwnd = CreateWindow(wc.lpszClassName, L"Minecraft", WS_SYSMENU | WS_OVERLAPPED,
10, 10, WindowWidth, WindowHeight,
NULL, NULL, hins, NULL);
// 因为指定了窗口大小不可变的 WS_SYSMENU 和 WS_OVERLAPPED,应用不会自动显示窗口,需要使用 ShowWindow 强制显示窗口
ShowWindow(m_hwnd, SW_SHOW);
}
// 创建调试层
void STEP02_CreateDebugDevice()
{
::CoInitialize(nullptr); // 注意这里!DX12 的所有设备接口都是基于 COM 接口的,我们需要先全部初始化为 nullptr
#if defined(_DEBUG) // 如果是 Debug 模式下编译,就执行下面的代码
// 获取调试层设备接口
D3D12GetDebugInterface(IID_PPV_ARGS(&m_D3D12DebugDevice));
// 开启调试层
m_D3D12DebugDevice->EnableDebugLayer();
// 开启调试层后,创建 DXGI 工厂也需要 Debug Flag
m_DXGICreateFactoryFlag = DXGI_CREATE_FACTORY_DEBUG;
#endif
}
// 创建设备
bool STEP03_CreateDevice()
{
// 创建 DXGI 工厂
CreateDXGIFactory2(m_DXGICreateFactoryFlag, IID_PPV_ARGS(&m_DXGIFactory));
// DX12 支持的所有功能版本,你的显卡最低需要支持 11.0
const D3D_FEATURE_LEVEL dx12SupportLevel[] =
{
D3D_FEATURE_LEVEL_12_2, // 12.2
D3D_FEATURE_LEVEL_12_1, // 12.1
D3D_FEATURE_LEVEL_12_0, // 12.0
D3D_FEATURE_LEVEL_11_1, // 11.1
D3D_FEATURE_LEVEL_11_0 // 11.0
};
// 用 EnumAdapters1 先遍历电脑上的每一块显卡
// 每次调用 EnumAdapters1 找到显卡会自动创建 DXGIAdapter 接口,并返回 S_OK
// 找不到显卡会返回 ERROR_NOT_FOUND
for (UINT i = 0; m_DXGIFactory->EnumAdapters1(i, &m_DXGIAdapter) != ERROR_NOT_FOUND; i++)
{
// 找到显卡,就创建 D3D12 设备,从高到低遍历所有功能版本,创建成功就跳出
for (const auto& level : dx12SupportLevel)
{
// 创建 D3D12 核心层设备,创建成功就返回 true
if (SUCCEEDED(D3D12CreateDevice(m_DXGIAdapter.Get(), level, IID_PPV_ARGS(&m_D3D12Device))))
{
DXGI_ADAPTER_DESC1 adap = {};
m_DXGIAdapter->GetDesc1(&adap);
OutputDebugStringW(L"当前使用的显卡:");
OutputDebugStringW(adap.Description);
OutputDebugStringW(L"\n");
return true;
}
}
}
// 如果找不到任何能支持 DX12 的显卡,就退出程序
if (m_D3D12Device == nullptr)
{
MessageBox(NULL, L"找不到任何能支持 DX12 的显卡,请升级电脑上的硬件!", L"错误", MB_OK | MB_ICONERROR);
return false;
}
}
// 创建命令三件套
void STEP04_CreateCommandComponents()
{
// 队列信息结构体,这里只需要填队列的类型 type 就行了
D3D12_COMMAND_QUEUE_DESC queueDesc = {};
// D3D12_COMMAND_LIST_TYPE_DIRECT 表示将命令都直接放进队列里,不做其他处理
queueDesc.Type = D3D12_COMMAND_LIST_TYPE_DIRECT;
// 创建命令队列
m_D3D12Device->CreateCommandQueue(&queueDesc, IID_PPV_ARGS(&m_CommandQueue));
// 创建命令分配器,它的作用是开辟内存,存储命令列表上的命令,注意命令类型要一致
m_D3D12Device->CreateCommandAllocator(D3D12_COMMAND_LIST_TYPE_DIRECT, IID_PPV_ARGS(&m_CommandAllocator));
// 创建图形命令列表,注意命令类型要一致
m_D3D12Device->CreateCommandList(0, D3D12_COMMAND_LIST_TYPE_DIRECT, m_CommandAllocator.Get(),
nullptr, IID_PPV_ARGS(&m_CommandList));
// 命令列表创建时处于 Record 录制状态,我们需要关闭它,这样下文的 Reset 才能成功
m_CommandList->Close();
}
// 创建渲染目标,将渲染目标设置为窗口
void STEP05_CreateRenderTarget()
{
// 创建 RTV 描述符堆 (Render Target View,渲染目标描述符)
D3D12_DESCRIPTOR_HEAP_DESC RTVHeapDesc = {};
RTVHeapDesc.NumDescriptors = 3; // 渲染目标的数量
RTVHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_RTV; // 描述符堆的类型:RTV
// 创建一个 RTV 描述符堆,创建成功后,会自动开辟三个描述符的内存
m_D3D12Device->CreateDescriptorHeap(&RTVHeapDesc, IID_PPV_ARGS(&m_RTVHeap));
// 创建 DXGI 交换链,用于将窗口缓冲区和渲染目标绑定
DXGI_SWAP_CHAIN_DESC1 swapchainDesc = {};
swapchainDesc.BufferCount = 3; // 缓冲区数量
swapchainDesc.Width = WindowWidth; // 缓冲区 (窗口) 宽度
swapchainDesc.Height = WindowHeight; // 缓冲区 (窗口) 高度
swapchainDesc.Format = DXGI_FORMAT_R8G8B8A8_UNORM; // 缓冲区格式,指定缓冲区每个像素的大小
swapchainDesc.SwapEffect = DXGI_SWAP_EFFECT_FLIP_DISCARD; // 交换链类型,有 FILP 和 BITBLT 两种类型
swapchainDesc.BufferUsage = DXGI_USAGE_RENDER_TARGET_OUTPUT;// 缓冲区的用途,这里表示把缓冲区用作渲染目标的输出
swapchainDesc.SampleDesc.Count = 1; // 缓冲区像素采样次数
// 临时低版本交换链接口,用于创建高版本交换链,因为下文的 CreateSwapChainForHwnd 不能直接用于创建高版本接口
ComPtr<IDXGISwapChain1> _temp_swapchain;
// 创建交换链,将窗口与渲染目标绑定
m_DXGIFactory->CreateSwapChainForHwnd(m_CommandQueue.Get(), m_hwnd,
&swapchainDesc, nullptr, nullptr, &_temp_swapchain);
// 通过 As 方法,将低版本接口的信息传递给高版本接口
_temp_swapchain.As(&m_DXGISwapChain);
// 创建完交换链后,我们还需要令 RTV 描述符 指向 渲染目标
// 因为 ID3D12Resource 本质上只是一块数据,它本身没有对数据用法的说明
// 我们要让程序知道这块数据是一个渲染目标,就得创建并使用 RTV 描述符
// 获取 RTV 堆指向首描述符的句柄
RTVHandle = m_RTVHeap->GetCPUDescriptorHandleForHeapStart();
// 获取 RTV 描述符的大小
RTVDescriptorSize = m_D3D12Device->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_RTV);
for (UINT i = 0; i < 3; i++)
{
// 从交换链中获取第 i 个窗口缓冲,创建第 i 个 RenderTarget 渲染目标
m_DXGISwapChain->GetBuffer(i, IID_PPV_ARGS(&m_RenderTarget[i]));
// 创建 RTV 描述符,将渲染目标绑定到描述符上
m_D3D12Device->CreateRenderTargetView(m_RenderTarget[i].Get(), nullptr, RTVHandle);
// 偏移到下一个 RTV 句柄
RTVHandle.ptr += RTVDescriptorSize;
}
}
// 创建围栏和资源屏障,用于 CPU-GPU 的同步
void STEP06_CreateFenceAndBarrier()
{
// 创建 CPU 上的等待事件,注意第二个参数填 false 表示自动重置,第三个初始状态参数填 false 表示无信号状态,防止资源竞争
RenderEvent = CreateEvent(nullptr, false, false, nullptr);
// 创建围栏,设定初始值为 0
m_D3D12Device->CreateFence(FenceValue, D3D12_FENCE_FLAG_NONE, IID_PPV_ARGS(&m_Fence));
// 设置资源屏障
// beg_barrier 起始屏障:Present 呈现状态 -> Render Target 渲染目标状态
beg_barrier.Type = D3D12_RESOURCE_BARRIER_TYPE_TRANSITION; // 指定类型为转换屏障
beg_barrier.Transition.StateBefore = D3D12_RESOURCE_STATE_PRESENT;
beg_barrier.Transition.StateAfter = D3D12_RESOURCE_STATE_RENDER_TARGET;
// end_barrier 终止屏障:Render Target 渲染目标状态 -> Present 呈现状态
end_barrier.Type = D3D12_RESOURCE_BARRIER_TYPE_TRANSITION;
end_barrier.Transition.StateBefore = D3D12_RESOURCE_STATE_RENDER_TARGET;
end_barrier.Transition.StateAfter = D3D12_RESOURCE_STATE_PRESENT;
}
// 创建 DSV 深度模板描述符堆 (Non-Shader Visible)
void STEP07_CreateDSVHeap()
{
D3D12_DESCRIPTOR_HEAP_DESC DSVHeapDesc = {}; // DSV 描述符堆结构体
DSVHeapDesc.NumDescriptors = 1; // 描述符只有 1 个,因为我们只有一个渲染目标
DSVHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_DSV; // 描述符堆类型
// 创建 DSV 描述符堆 (Depth Stencil View,深度模板描述符),用于深度测试与模板测试
m_D3D12Device->CreateDescriptorHeap(&DSVHeapDesc, IID_PPV_ARGS(&m_DSVHeap));
// 获取 DSV 的 CPU 句柄
DSVHandle = m_DSVHeap->GetCPUDescriptorHandleForHeapStart();
}
// 创建深度与模板缓冲,用于开启深度测试,渲染物体正确的深度与遮挡关系
void STEP08_CreateDepthStencilBuffer()
{
D3D12_RESOURCE_DESC DSVResourceDesc = {}; // 深度模板缓冲资源信息结构体
DSVResourceDesc.Dimension = D3D12_RESOURCE_DIMENSION_TEXTURE2D; // 深度缓冲其实也是一块纹理
DSVResourceDesc.Format = DSVFormat; // 资源纹理格式
DSVResourceDesc.Layout = D3D12_TEXTURE_LAYOUT_UNKNOWN; // 深度缓冲的布局也是 UNKNOWN
DSVResourceDesc.Width = WindowWidth; // 宽度和渲染目标一致
DSVResourceDesc.Height = WindowHeight; // 高度和渲染目标一致
DSVResourceDesc.MipLevels = 1; // Mipmap 层级,设置为 1 就行
DSVResourceDesc.DepthOrArraySize = 1; // 纹理数组大小 (3D 纹理深度),设置为 1 就行
DSVResourceDesc.SampleDesc.Count = 1; // 采样次数,设置为 1 就行
DSVResourceDesc.SampleDesc.Quality = 0; // 采样质量,设置为 0 就行
DSVResourceDesc.Flags = D3D12_RESOURCE_FLAG_ALLOW_DEPTH_STENCIL; // 资源标志
D3D12_CLEAR_VALUE DepthStencilBufferClearValue = {}; // 用于清空深度缓冲的信息结构体,DX12 能对这个进行优化
DepthStencilBufferClearValue.DepthStencil.Depth = 1.0f; // 要清空到的深度值,清空后会重置到该值
DepthStencilBufferClearValue.DepthStencil.Stencil = 0; // 要清空到的模板值,清空后会重置到该值
DepthStencilBufferClearValue.Format = DSVFormat; // 要清空缓冲的格式,要和上文一致
// 默认堆属性,深度缓冲也是一块纹理,所以用默认堆
D3D12_HEAP_PROPERTIES DefaultProperties = { D3D12_HEAP_TYPE_DEFAULT };
// 创建资源,深度缓冲只会占用很少资源,所以直接 CreateCommittedResource 隐式堆创建即可,让操作系统帮我们管理
m_D3D12Device->CreateCommittedResource(&DefaultProperties, D3D12_HEAP_FLAG_NONE, &DSVResourceDesc,
D3D12_RESOURCE_STATE_DEPTH_WRITE, &DepthStencilBufferClearValue, IID_PPV_ARGS(&m_DepthStencilBuffer));
}
// 创建 DSV 描述符,DSV 描述符用于描述深度模板缓冲区,这个描述符才是渲染管线要设置的对象
void STEP09_CreateDSV()
{
D3D12_DEPTH_STENCIL_VIEW_DESC DSVViewDesc = {};
DSVViewDesc.Format = DSVFormat; // DSV 描述符格式要和资源一致
DSVViewDesc.ViewDimension = D3D12_DSV_DIMENSION_TEXTURE2D; // 深度缓冲本质也是一块 2D 纹理
DSVViewDesc.Flags = D3D12_DSV_FLAG_NONE; // 这个 Flag 是用来设置读写权限的,深度值和模板值均可以读写
// 创建 DSV 描述符 (Depth Stencil View,深度模板描述符)
m_D3D12Device->CreateDepthStencilView(m_DepthStencilBuffer.Get(), &DSVViewDesc, DSVHandle);
}
// 上取整算法,对 A 向上取整,判断至少要多少个长度为 B 的空间才能容纳 A,用于内存对齐
inline UINT Ceil(UINT A, UINT B)
{
return (A + B - 1) / B;
}
// 创建用于摄像机的 Constant Buffer Resource 常量缓冲资源
void STEP10_CreateCameraCBVResource()
{
// 常量资源宽度,这里填整个结构体的大小。注意!硬件要求,常量缓冲需要 256 字节对齐!所以这里要进行 Ceil 向上取整,进行内存对齐!
// D3D12_CONSTANT_BUFFER_DATA_PLACEMENT_ALIGNMENT = 256
UINT CBufferWidth = Ceil(sizeof(CBuffer), 256) * 256;
D3D12_RESOURCE_DESC CBVResourceDesc = {}; // 常量缓冲资源信息结构体
CBVResourceDesc.Dimension = D3D12_RESOURCE_DIMENSION_BUFFER; // 上传堆资源都是缓冲
CBVResourceDesc.Layout = D3D12_TEXTURE_LAYOUT_ROW_MAJOR; // 上传堆资源都是按行存储数据的 (一维线性存储)
CBVResourceDesc.Width = CBufferWidth; // 常量缓冲区资源宽度 (要分配显存的总大小)
CBVResourceDesc.Height = 1; // 上传堆资源都是存储一维线性资源,所以高度必须为 1
CBVResourceDesc.Format = DXGI_FORMAT_UNKNOWN; // 上传堆资源的格式必须为 DXGI_FORMAT_UNKNOWN
CBVResourceDesc.DepthOrArraySize = 1; // 资源深度,这个是用于纹理数组和 3D 纹理的,上传堆资源必须为 1
CBVResourceDesc.MipLevels = 1; // Mipmap 等级,这个是用于纹理的,上传堆资源必须为 1
CBVResourceDesc.SampleDesc.Count = 1; // 资源采样次数,上传堆资源都是填 1
// 上传堆属性的结构体,上传堆位于 CPU 和 GPU 的共享内存
D3D12_HEAP_PROPERTIES UploadHeapDesc = { D3D12_HEAP_TYPE_UPLOAD };
// 创建常量缓冲资源
m_D3D12Device->CreateCommittedResource(&UploadHeapDesc, D3D12_HEAP_FLAG_NONE, &CBVResourceDesc,
D3D12_RESOURCE_STATE_GENERIC_READ, nullptr, IID_PPV_ARGS(&m_CBVResource));
// 常量缓冲直接 Map 映射到结构体指针就行即可
m_CBVResource->Map(0, nullptr, reinterpret_cast<void**>(&MVPBuffer));
}
// ---------------------------------------------------------------------------------------------------------------
// 将所需要的所有图片文件全部加载到内存中
bool STEP11_LoadTextureGroup()
{
// 创建 WIC 工厂
CoCreateInstance(CLSID_WICImagingFactory, nullptr, CLSCTX_INPROC_SERVER, IID_PPV_ARGS(&m_WICFactory));
// 循环将图片文件载入到 TextureGroup 的 WIC 位图中
for (UINT i = 0; i < TextureGroup.size(); i++)
{
// 先创建图片解码器,并将图片文件加载到内存
HRESULT hr = m_WICFactory->CreateDecoderFromFilename(TextureGroup[i].FilePath.c_str(), nullptr, GENERIC_READ,
WICDecodeMetadataCacheOnDemand, &m_WICBitmapDecoder);
// 用于格式化字符串
std::wostringstream output_str;
// 如果创建失败,就检查 HRESULT 返回值并提示信息
switch (hr)
{
case S_OK: break; // 解码成功,直接 break 进入下一步即可
case HRESULT_FROM_WIN32(ERROR_FILE_NOT_FOUND): // 文件找不到
output_str << L"找不到文件 " << TextureGroup[i].FilePath << L" !请检查文件路径是否有误!";
MessageBox(NULL, output_str.str().c_str(), L"错误", MB_OK | MB_ICONERROR);
return false;
case HRESULT_FROM_WIN32(ERROR_FILE_CORRUPT): // 文件句柄正在被另一个应用进程占用
output_str << L"文件 " << TextureGroup[i].FilePath << L" 已经被另一个应用进程打开并占用了!请先关闭那个应用进程!";
MessageBox(NULL, output_str.str().c_str(), L"错误", MB_OK | MB_ICONERROR);
return false;
case WINCODEC_ERR_COMPONENTNOTFOUND: // 找不到可解码的组件,说明这不是有效的图像文件
output_str << L"文件 " << TextureGroup[i].FilePath << L" 不是有效的图像文件,无法解码!请检查文件是否为图像文件!";
MessageBox(NULL, output_str.str().c_str(), L"错误", MB_OK | MB_ICONERROR);
return false;
default: // 发生其他未知错误
output_str << L"文件 " << TextureGroup[i].FilePath << L" 解码失败!发生了其他错误,错误码:" << hr << L" ,请查阅微软官方文档。";
MessageBox(NULL, output_str.str().c_str(), L"错误", MB_OK | MB_ICONERROR);
return false;
}
// 从解码器中获取一帧图片
m_WICBitmapDecoder->GetFrame(0, &m_WICBitmapDecodeFrame);
// 获取图片格式,并将它转化为 DX12 能接受的纹理格式
WICPixelFormatGUID SourceFormat = {}; // 源图格式
GUID TargetFormat = {}; // 目标格式
m_WICBitmapDecodeFrame->GetPixelFormat(&SourceFormat); // 获取源图格式
// 获取目标格式,如果没有可支持的目标格式,就返回 false 并提示信息
if (DX12TextureHelper::GetTargetPixelFormat(&SourceFormat, &TargetFormat) == false)
{
::MessageBox(NULL, L"此纹理不受支持!", L"提示", MB_OK);
return false;
}
// 获取目标格式后,将纹理转换为目标格式,使其能被 DX12 使用
m_WICFactory->CreateFormatConverter(&m_WICFormatConverter);
// 初始化转换器,实际上是把位图进行了转换
m_WICFormatConverter->Initialize(m_WICBitmapDecodeFrame.Get(), TargetFormat, WICBitmapDitherTypeNone,
nullptr, 0.0f, WICBitmapPaletteTypeCustom);
// 将位图数据继承到 WIC 位图资源,我们等会要在 WIC 位图资源上获取信息
m_WICFormatConverter.As(&TextureGroup[i].WICBitmapSource);
}
// 全部位图都加载成功了,就返回 true
return true;
}
// 获取纹理数组的各种属性,以第一个元素为准,后面的元素这些属性基本上是一样的 (?)
void STEP12_GetTextureArrayElementsProperties()
{
// 获取第一个纹理的 DXGI 格式
WICPixelFormatGUID WICPixelFormat = {};
TextureGroup[0].WICBitmapSource->GetPixelFormat(&WICPixelFormat);
TextureFormat = DX12TextureHelper::GetDXGIFormatFromPixelFormat(&WICPixelFormat);
// 获取图像深度
ComPtr<IWICComponentInfo> _temp_WICComponentInfo = {}; // 用于获取 BitsPerPixel 纹理图像深度
ComPtr<IWICPixelFormatInfo> _temp_WICPixelInfo = {}; // 用于获取 BitsPerPixel 纹理图像深度
m_WICFactory->CreateComponentInfo(WICPixelFormat, &_temp_WICComponentInfo);
_temp_WICComponentInfo.As(&_temp_WICPixelInfo);
_temp_WICPixelInfo->GetBitsPerPixel(&BitsPerPixel); // 获取 BitsPerPixel 图像深度
// 获取纹理宽高
TextureGroup[0].WICBitmapSource->GetSize(&TextureWidth, &TextureHeight);
// 获取纹理每行所占的真实字节数,1 Byte = 8 Bits
BytePerRowSize = TextureWidth * BitsPerPixel / 8;
// 获取纹理真实总大小
TextureSize = BytePerRowSize * TextureHeight;
// DX12 API 要求在上传堆的纹理资源每行必须 256 字节对齐,这样能方便硬件批量复制
// D3D12_TEXTURE_DATA_PITCH_ALIGNMENT = 256
UploadResourceRowSize = Ceil(BytePerRowSize, 256) * 256;
// 计算纹理数组单个元素实际需要的上传堆资源大小,最后一行无需对齐,直接复制
UploadSubResourceSize = UploadResourceRowSize * (TextureHeight - 1) + BytePerRowSize;
// 你以为算出 UploadSubResourceSize * TextureGroup.size() 就可以了吗?大错特错!
// 实际上,DX12 API 还有一个硬性要求:Texture Array 在上传堆每个元素必须 512 对齐,这样才能方便硬件正确寻址并复制每个纹理元素
// Texture Array 占上传堆的空间大小,比多个单独的纹理资源占上传堆还要大一点,不过这样保证了纹理资源的连续性
// 硬件复制资源的速度实际上更快了,这就是 GPU Texture Array "纹理数组" 名字的由来
// 我们要在算出 UploadSubResourceSize 的基础上,再进行一次 512 对齐,算出纹理数组每个元素在上传堆所占的真实大小
// 为每个纹理元素做一个 "安全的小屋",在上传堆 "互不打扰",硬件正确偏移到每个元素的起始点。仍然是最后一个元素无需对齐,直接复制
// D3D12_DEFAULT_RESOURCE_PLACEMENT_ALIGNMENT = 512
UploadArrayElementSize = Ceil(UploadSubResourceSize, 512) * 512;
// 最后计算上传堆资源所需要的总大小,公式和上面的 UploadSubResourceSize 计算是一样的
UploadResourceSize = UploadArrayElementSize * (TextureGroup.size() - 1) + UploadSubResourceSize;
}
// 创建纹理数组需要的上传堆资源与默认堆资源
void STEP13_CreateTextureArrayResource()
{
// 用于中转纹理的上传堆资源结构体
D3D12_RESOURCE_DESC UploadResourceDesc = {};
UploadResourceDesc.Dimension = D3D12_RESOURCE_DIMENSION_BUFFER; // 资源类型,上传堆的资源类型都是 buffer 缓冲
UploadResourceDesc.Layout = D3D12_TEXTURE_LAYOUT_ROW_MAJOR; // 资源布局,指定资源的存储方式,上传堆的资源都是 row major 按行线性存储
UploadResourceDesc.Width = UploadResourceSize; // 资源宽度,上传堆的资源宽度是资源的总大小,注意资源大小必须只多不少
UploadResourceDesc.Height = 1; // 资源高度,上传堆仅仅是传递线性资源的,所以高度必须为 1
UploadResourceDesc.Format = DXGI_FORMAT_UNKNOWN; // 资源格式,上传堆资源的格式必须为 UNKNOWN
UploadResourceDesc.DepthOrArraySize = 1; // 资源深度,上传堆资源必须为 1
UploadResourceDesc.MipLevels = 1; // Mipmap 等级,上传堆资源必须为 1
UploadResourceDesc.SampleDesc.Count = 1; // 资源采样次数,上传堆资源都是填 1
// 创建上传堆资源
m_D3D12Device->CreateCommittedResource(&UploadHeapDesc, D3D12_HEAP_FLAG_NONE, &UploadResourceDesc,
D3D12_RESOURCE_STATE_GENERIC_READ, nullptr, IID_PPV_ARGS(&m_TextureArrayUploadResource));
// 默认堆资源结构体
D3D12_RESOURCE_DESC DefaultResourceDesc = {};
DefaultResourceDesc.Dimension = D3D12_RESOURCE_DIMENSION_TEXTURE2D; // 资源类型选 Texture 2D (下文的描述符会描述它是一个纹理数组)
DefaultResourceDesc.Layout = D3D12_TEXTURE_LAYOUT_UNKNOWN; // 纹理资源的布局都是 UNKNOWN
DefaultResourceDesc.DepthOrArraySize = TextureGroup.size(); // 资源深度 = 纹理数组长度
// 创建纹理数组,我们以 TextureGroup 中第一个纹理的宽高、格式和 Mipmap 为准,看渲染结果,尝试用"妙妙工具"分析,想想为什么会这样? 应该如何优化?
DefaultResourceDesc.Width = TextureWidth; // 资源宽度,这里填单个纹理的宽度 (单位:像素)
DefaultResourceDesc.Height = TextureHeight; // 资源高度,这里填单个纹理的高度 (单位:像素)
DefaultResourceDesc.Format = TextureFormat; // 资源格式,这里填纹理格式,要和纹理数组一样
DefaultResourceDesc.MipLevels = 1; // Mipmap 等级,我们暂时不使用 Mipmap (只有一层 Mipmap),所以填 1
DefaultResourceDesc.SampleDesc.Count = 1; // 资源采样次数,这里我们填 1 就行
// 创建默认堆资源
m_D3D12Device->CreateCommittedResource(&DefaultHeapDesc, D3D12_HEAP_FLAG_NONE, &DefaultResourceDesc,
D3D12_RESOURCE_STATE_COPY_DEST, nullptr, IID_PPV_ARGS(&m_TextureArrayDefaultResource));
}
// 将纹理数组资源逐步复制到默认堆资源中
void STEP14_CopyTextureArrayToDefaultResource()
{
// 用于暂时存储纹理数据的指针,这里要用 malloc 分配空间
BYTE* TextureData = (BYTE*)malloc(TextureSize);
// 用于传递资源的指针
BYTE* TransferPointer = nullptr;
// Map 开始映射,Map 方法会得到上传堆资源的地址 (在共享内存上),传递给指针,这样我们就能通过 memcpy 操作复制数据了
m_TextureArrayUploadResource->Map(0, nullptr, reinterpret_cast<void**>(&TransferPointer));
// 循环复制 TextureGroup 每个 WIC 资源到上传堆,然后逐一释放,i 是纹理数组元素索引
for (UINT i = 0; i < TextureGroup.size(); i++)
{
// 对于每个纹理元素,将整块纹理数据读到 TextureData 中,方便下面的 memcpy 复制操作
TextureGroup[i].WICBitmapSource->CopyPixels(nullptr, BytePerRowSize, TextureSize, TextureData);
// 向上传堆资源逐行复制纹理数据 (CPU 高速缓存 -> 共享内存),j 是复制的行数
for (UINT j = 0; j < TextureHeight; j++)
{
// 复制一行
memcpy(TransferPointer, TextureData, BytePerRowSize);
// 纹理指针偏移到下一行
TextureData += BytePerRowSize;
// 上传堆资源指针偏移到下一行,注意偏移长度不同!
TransferPointer += UploadResourceRowSize;
}
// 单个元素复制完毕,纹理 WIC 资源指针复用,恢复到最开始的位置,准备下一次 CopyPixels
TextureData -= TextureSize;
// 上传堆资源指针回到本数组元素的起点
TransferPointer -= UploadResourceRowSize * TextureHeight;
// 上传堆资源指针偏移到下一个数组元素的位置
// 请大家认真想一想下面的等式成立吗? (反正作者被下面的大小偏移坑爆了,渲染不出来盯了三小时 + 一遍遍问 deepseek 才改出来)
// UploadResourceRowSize * TextureHeight == UploadSubResourceSize == UploadArrayElementSize
TransferPointer += UploadArrayElementSize;
// 每个元素复制完,重置并释放 WIC 位图资源,防止它占内存
TextureGroup[i].WICBitmapSource.Reset();
}
// Unmap 结束映射,让上传堆处于只读状态
m_TextureArrayUploadResource->Unmap(0, nullptr);
// 释放上文 malloc 分配的空间,后面我们用不到它,做一个干净的程序员
free(TextureData);
// 资源脚本,用来描述要复制的资源。如果复制目标是纹理数组,每个子资源 (纹理数组元素) 各复制一次,各需要一个资源脚本
// 如果复制纹理数组只用一个脚本,下文 GPU 执行 CopyTextureRegion 会寻址出界,报 Stack Corrupted,调试层不会提示这个信息
std::vector<D3D12_PLACED_SUBRESOURCE_FOOTPRINT> PlacedFootprints(TextureGroup.size());
D3D12_RESOURCE_DESC DefaultResourceDesc = m_TextureArrayDefaultResource->GetDesc(); // 默认堆资源结构体
// 获取纹理复制脚本,用于下文的纹理复制,注意第三个参数!第三个参数是目标资源的子资源数量!我们复制的是纹理数组,要填数组长度!
// 当你填了 DefaultResourceDesc 和 TextureGroup.size(),这个函数会自动填充每个资源脚本的各种参数
m_D3D12Device->GetCopyableFootprints(&DefaultResourceDesc, 0, TextureGroup.size(), 0,
&PlacedFootprints[0], nullptr, nullptr, nullptr);
// 复制资源需要使用 GPU 的 CopyEngine 复制引擎,所以需要向命令队列发出复制命令
m_CommandAllocator->Reset(); // 先重置命令分配器
m_CommandList->Reset(m_CommandAllocator.Get(), nullptr); // 再重置命令列表,复制命令不需要 PSO 状态,所以第二个参数填 nullptr
// 注意!复制纹理数组到默认堆,每个子资源 (纹理数组元素) 都要调用一次 CopyTextureRegion 指令
// DstLocation.SubresourceIndex 和 SrcLocation.PlacedFootprint 的参数也要跟着变!这样才能正确复制
for (UINT i = 0; i < TextureGroup.size(); i++)
{
D3D12_TEXTURE_COPY_LOCATION DstLocation = {}; // 复制目标位置 (默认堆资源) 结构体
DstLocation.Type = D3D12_TEXTURE_COPY_TYPE_SUBRESOURCE_INDEX; // 纹理复制类型,这里必须指向纹理
DstLocation.SubresourceIndex = i; // 指定要复制的子资源索引 (第 i 个元素)
DstLocation.pResource = m_TextureArrayDefaultResource.Get(); // 要复制到的资源 (默认堆资源)
D3D12_TEXTURE_COPY_LOCATION SrcLocation = {}; // 复制源位置 (上传堆资源) 结构体
SrcLocation.Type = D3D12_TEXTURE_COPY_TYPE_PLACED_FOOTPRINT; // 纹理复制类型,这里必须指向缓冲区
SrcLocation.PlacedFootprint = PlacedFootprints[i]; // 指定要复制的资源脚本信息 (用第 i 个资源脚本)
SrcLocation.pResource = m_TextureArrayUploadResource.Get(); // 被复制数据的缓冲 (上传堆资源)
// 记录复制第 i 个子资源 (纹理数组元素) 到默认堆的命令 (共享内存 -> 显存)
m_CommandList->CopyTextureRegion(&DstLocation, 0, 0, 0, &SrcLocation, nullptr);
}
// 关闭命令列表
m_CommandList->Close();
// 用于传递命令用的临时 ID3D12CommandList 数组
ID3D12CommandList* _temp_cmdlists[] = { m_CommandList.Get() };
// 提交复制命令!GPU 开始复制!
m_CommandQueue->ExecuteCommandLists(1, _temp_cmdlists);
// 将围栏预定值设定为下一帧,注意复制资源也需要围栏等待,否则会发生资源冲突!
FenceValue++;
// 在命令队列 (命令队列在 GPU 端) 设置围栏预定值,此命令会加入到命令队列中
// 围栏对象会关联命令队列,围栏对象内部会根据这个围栏值开辟 Event Slot 事件槽,并将围栏值填进去
// 当 Command Queue 执行完成,会修改相关联的围栏对象的 CompletedValue 任务值,然后通知围栏对象
m_CommandQueue->Signal(m_Fence.Get(), FenceValue);
// 设置围栏的预定事件,当复制完成时,围栏被"击中",激发预定事件,将事件由无信号状态转换成有信号状态
// 实际上是将 CPU 端的信号事件句柄,通过围栏值寻址到对应的 Event Slot 事件槽,然后将其绑定
// 当 GPU 端的 CommandQueue 的任务执行完成,自身会修改与其相关联所有围栏对象内部的 CompletedValue 任务值
// 然后激发相关联的围栏对象,绑定到 CommandQueue 的多个围栏对象 (一个 CommandQueue 可以绑多个围栏,一个围栏可以绑多个围栏值)
// 在接收到信号后,围栏会查看自身的 CompletedValue 和对象内部所有的 Event Slot 事件槽
// 如果与某个事件槽的 Event Slot 的 FenceValue 对上了 (FenceValue == CompletedValue),就会将对应事件设置成有信号状态
// 然后 GPU Command Queue 继续执行剩下未完成的任务,以此类推。这就是 DX12 CPU 与 GPU 之间的同步与异步
m_Fence->SetEventOnCompletion(FenceValue, RenderEvent);
// 让主线程强制等待复制完成,经过此函数后 RenderEvent 会自动重置到无信号状态 (CreateEvent 第二个参数)
WaitForSingleObject(RenderEvent, INFINITE);
}
// 创建 Shader Resource View Heap 着色器资源描述符堆
void STEP15_CreateSRVHeap()
{
D3D12_DESCRIPTOR_HEAP_DESC SRVHeapDesc = {}; // SRV 描述符堆信息结构体
SRVHeapDesc.NumDescriptors = 1; // 只有一个 TEXTURE2DARRAY SRV
SRVHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV; // 类型是 CBV/SRV/UAV 描述符都可以放
SRVHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLE; // 着色器需要引用 SRV 资源,就必须设置着色器可见标志
// 创建 SRV 描述符堆
m_D3D12Device->CreateDescriptorHeap(&SRVHeapDesc, IID_PPV_ARGS(&m_SRVHeap));
}
// 用上文创建的 m_TextureArrayDefaultResource 创建 SRV 描述符,注意我们这里只创建一个 TEXTURE2DARRAY SRV
void STEP16_CreateTextureArraySRV()
{
// Texture Array 的 SRV 信息结构体,我们要通过 SRV 告知 GPU 这个资源的类型与用法
D3D12_SHADER_RESOURCE_VIEW_DESC SRVTextureArrayDesc = {};
// SRV 描述符的维度 (类型),我们这里选 TEXTURE2DARRAY (2D 纹理数组)
SRVTextureArrayDesc.ViewDimension = D3D12_SRV_DIMENSION_TEXTURE2DARRAY;
// 格式要填纹理数组的纹理格式
SRVTextureArrayDesc.Format = TextureFormat;
// RGBA 4 分量顺序不改变
SRVTextureArrayDesc.Shader4ComponentMapping = D3D12_DEFAULT_SHADER_4_COMPONENT_MAPPING;
// 纹理数组的起始索引,在 2D 纹理数组中,Slice 切片表示一个数组元素 (一个 2D 纹理)
SRVTextureArrayDesc.Texture2DArray.FirstArraySlice = 0;
// 纹理数组的长度 (纹理的数量)
SRVTextureArrayDesc.Texture2DArray.ArraySize = TextureGroup.size();
// 只有一层 Mipmap,填 1
SRVTextureArrayDesc.Texture2DArray.MipLevels = 1;
// 获取 CPU 句柄
SRVTextureArray_CPUHandle = m_SRVHeap->GetCPUDescriptorHandleForHeapStart();
// 获取 GPU 句柄
SRVTextureArray_GPUHandle = m_SRVHeap->GetGPUDescriptorHandleForHeapStart();
// 创建 SRV 描述符
m_D3D12Device->CreateShaderResourceView(m_TextureArrayDefaultResource.Get(), &SRVTextureArrayDesc, SRVTextureArray_CPUHandle);
}
// ---------------------------------------------------------------------------------------------------------------
// 创建 SRV Structured Buffer (结构化缓冲区),结构化缓冲区是一块缓冲,它和常量缓冲功能很相似,都能向着色器传递结构化数组
// 但不同的是常量缓冲专为"小数据、高频率、高度统一访问"而优化,结构化缓冲区是为"海量数据、随机访问、GPU 读写"而设计
// 每个常量缓冲有大小限制,最大 64KB;结构化缓冲区没有大小限制
// 常量缓冲在 GPU 端有 16 字节对齐规则 (HLSL 打包规则),在 CPU 端有 256 字节内存对齐规则;结构化缓冲区无对齐规则
// 常量缓冲区需要绑定 CBV (通常是上传堆);而结构化缓冲可以绑定 SRV 或 UAV (必须是默认堆)
// 常量缓冲区常用于访问小规模高频变动资源 (如 MVP 矩阵,骨骼矩阵,光照常量数据);而结构化缓冲区用于访问大规模静态或低频变动资源
// 我们这里要传递立方体面纹理索引数据 (静态资源),所以用 SRV Structured Buffer (用常量缓冲做这个也可以,想想应该怎么改? 改了有什么不同?)
void STEP17_CreateStructuredBufferResource()
{
// Structured Buffer 中转资源的上传堆信息结构体,填法和顶点/索引缓冲一样
D3D12_RESOURCE_DESC StructuredBufferUploadDesc = {};
StructuredBufferUploadDesc.Dimension = D3D12_RESOURCE_DIMENSION_BUFFER;
StructuredBufferUploadDesc.Layout = D3D12_TEXTURE_LAYOUT_ROW_MAJOR;
StructuredBufferUploadDesc.Width = BlockCubeTexture_IndexGroup.size() * sizeof(CUBEFACE); // 宽度是整个结构化缓冲的大小
StructuredBufferUploadDesc.Height = 1;
StructuredBufferUploadDesc.Format = DXGI_FORMAT_UNKNOWN;
StructuredBufferUploadDesc.DepthOrArraySize = 1;
StructuredBufferUploadDesc.MipLevels = 1;
StructuredBufferUploadDesc.SampleDesc.Count = 1;
// 创建上传堆资源
m_D3D12Device->CreateCommittedResource(&UploadHeapDesc, D3D12_HEAP_FLAG_NONE, &StructuredBufferUploadDesc,
D3D12_RESOURCE_STATE_GENERIC_READ, nullptr, IID_PPV_ARGS(&m_StructuredBufferUploadResource));
// Structured Buffer 中转资源的默认堆信息结构体
D3D12_RESOURCE_DESC StructuredBufferDefaultDesc = {};
StructuredBufferDefaultDesc.Dimension = D3D12_RESOURCE_DIMENSION_BUFFER; // 注意这里类型是缓冲
StructuredBufferDefaultDesc.Layout = D3D12_TEXTURE_LAYOUT_ROW_MAJOR; // 线性资源
StructuredBufferDefaultDesc.Width = BlockCubeTexture_IndexGroup.size() * sizeof(CUBEFACE); // 宽度是整个结构化缓冲的大小
StructuredBufferDefaultDesc.Height = 1;
StructuredBufferDefaultDesc.Format = DXGI_FORMAT_UNKNOWN;
StructuredBufferDefaultDesc.DepthOrArraySize = 1;
StructuredBufferDefaultDesc.MipLevels = 1;
StructuredBufferDefaultDesc.SampleDesc.Count = 1;
// 创建默认堆资源
m_D3D12Device->CreateCommittedResource(&DefaultHeapDesc, D3D12_HEAP_FLAG_NONE, &StructuredBufferDefaultDesc,
D3D12_RESOURCE_STATE_COPY_DEST, nullptr, IID_PPV_ARGS(&m_StructuredBufferDefaultResource));
}
// 将 SRV Structured Buffer Resource 逐步复制到默认堆资源中,注意 SRV Structured Buffer 不需要 SRVHeap
// 和 CBVResource 一样,直接使用 SRV RootDescriptor (还记得 SRV 描述符使用的注意事项吗?)
void STEP18_CopyStructuredBufferToDefaultResource()
{
// 用于传递资源的指针
BYTE* TransferPointer = nullptr;
// Map 映射,获取上传堆资源的地址并传递到 TransferPointer
m_StructuredBufferUploadResource->Map(0, nullptr, reinterpret_cast<void**>(&TransferPointer));
// 直接 memcpy 复制 (CPU 高速缓存 -> 共享内存)
memcpy(TransferPointer, &BlockCubeTexture_IndexGroup[0], BlockCubeTexture_IndexGroup.size() * sizeof(CUBEFACE));
// UnMap 结束映射,下一步就要复制到默认堆
m_StructuredBufferUploadResource->Unmap(0, nullptr);
// 复制资源需要使用 GPU 的 CopyEngine 复制引擎,所以需要向命令队列发出复制命令
m_CommandAllocator->Reset(); // 先重置命令分配器
m_CommandList->Reset(m_CommandAllocator.Get(), nullptr); // 再重置命令列表,复制命令不需要 PSO 状态,所以第二个参数填 nullptr
// 发送复制到默认堆的指令,注意这里用的是 CopyBufferRegion 复制缓冲指令,不用填麻烦的结构体,直接填参数上传 (共享内存 -> GPU 显存)
m_CommandList->CopyBufferRegion(m_StructuredBufferDefaultResource.Get(), 0,
m_StructuredBufferUploadResource.Get(), 0, BlockCubeTexture_IndexGroup.size() * sizeof(CUBEFACE));
// 关闭命令列表
m_CommandList->Close();
// 用于传递命令用的临时 ID3D12CommandList 数组
ID3D12CommandList* _temp_cmdlists[] = { m_CommandList.Get() };
// 提交复制命令!GPU 开始复制!
m_CommandQueue->ExecuteCommandLists(1, _temp_cmdlists);
// 将围栏预定值设定为下一帧,注意复制资源也需要围栏等待,否则会发生资源冲突!
FenceValue++;
// 在命令队列 (命令队列在 GPU 端) 设置围栏预定值,此命令会加入到命令队列中
m_CommandQueue->Signal(m_Fence.Get(), FenceValue);
// 设置围栏的预定事件,当复制完成时,围栏被"击中",激发预定事件,将事件由无信号状态转换成有信号状态
m_Fence->SetEventOnCompletion(FenceValue, RenderEvent);
// 下一个等待就是 RenderLoop 的 MsgWaitForMultipleObjects,不需要用 WaitForSingleObject 了
// 这里再用一次 WaitForSingleObject 就会使事件变成无信号 (CreateEvent 第二个参数)
// 导致在 MsgWaitForMultipleObjects 那里卡死,永远返回 1,窗口白屏,完全进不去 case 0 渲染函数
}
// ---------------------------------------------------------------------------------------------------------------
// 创建根签名,根签名声明了着色器 (渲染管线) 所需要的资源
void STEP19_CreateRootSignature()
{
// 根参数 + 静态采样器列表
// Para 0: (Type = Root Descriptor, 2 DWORD) (b0, space0) CBV 根描述符,用于 MVP 缓冲
// Para 1: (Type = Root Descriptor, 2 DWORD) (t0, space0) SRV 根描述符,用于结构化缓冲区
// Para 2: (Type = Descriptor Table, 1 DWORD) (t1, space0) SRV 描述符表,用于纹理数组
//
// Sampler 0: (Type = Static Sampler) (s0, space0) 静态采样器 (邻近点过滤),用于纹理数组采样
ComPtr<ID3DBlob> SignatureBlob; // 根签名字节码
ComPtr<ID3DBlob> ErrorBlob; // 错误字节码
D3D12_ROOT_PARAMETER RootParameters[3] = {}; // 根参数数组
// 把更新频率高的根参数放前面,低的放后面,可以优化性能 (微软官方文档建议)
// 因为 DirectX API 能对根签名进行 Version Control 版本控制,在根签名越前面的根参数,访问速度更快
// 第一个根参数:CBV 根描述符 (MVP 矩阵),根描述符是内联描述符,所以下文绑定根参数时,只需要传递常量缓冲资源的地址即可
D3D12_ROOT_DESCRIPTOR CBVRootDescriptorDesc = {}; // CBV 根描述符信息结构体
CBVRootDescriptorDesc.ShaderRegister = 0; // 要绑定的寄存器编号,这里对应 HLSL 的 b0 寄存器
CBVRootDescriptorDesc.RegisterSpace = 0; // 要绑定的命名空间,这里对应 HLSL 的 space0
RootParameters[0].ShaderVisibility = D3D12_SHADER_VISIBILITY_ALL; // 常量缓冲对整个渲染管线都可见
RootParameters[0].ParameterType = D3D12_ROOT_PARAMETER_TYPE_CBV; // 根参数的类型:CBV 根描述符
RootParameters[0].Descriptor = CBVRootDescriptorDesc; // 填上文的结构体
// 第二个根参数:SRV 根描述符 (结构化缓冲区),注意!SRV 根描述符不能用于纹理!
D3D12_ROOT_DESCRIPTOR SRVRootDescriptorDesc = {}; // SRV 根描述符信息结构体
SRVRootDescriptorDesc.ShaderRegister = 0; // t0
SRVRootDescriptorDesc.RegisterSpace = 0; // space0
RootParameters[1].ShaderVisibility = D3D12_SHADER_VISIBILITY_ALL; // 结构化缓冲对整个渲染管线都可见
RootParameters[1].ParameterType = D3D12_ROOT_PARAMETER_TYPE_SRV; // 根参数的类型:SRV 根描述符
RootParameters[1].Descriptor = SRVRootDescriptorDesc; // 填上文的结构体
// 第三个根参数:根描述表 (Range: SRV)
D3D12_DESCRIPTOR_RANGE SRVDescriptorRangeDesc = {}; // Range 描述符范围结构体,一块 Range 表示一堆连续的同类型描述符
SRVDescriptorRangeDesc.RangeType = D3D12_DESCRIPTOR_RANGE_TYPE_SRV; // Range 类型,这里指定 SRV 类型,CBV_SRV_UAV 在这里分流
SRVDescriptorRangeDesc.NumDescriptors = 1; // Range 里面的描述符数量 N,一次可以绑定多个描述符到多个寄存器槽上
SRVDescriptorRangeDesc.BaseShaderRegister = 1; // Range 要绑定的起始寄存器槽编号 i,绑定范围是 [t(i),t(i+N)],我们绑定 t1
SRVDescriptorRangeDesc.RegisterSpace = 0; // Range 要绑定的寄存器空间,整个 Range 都会绑定到同一寄存器空间上,我们绑定 space0
SRVDescriptorRangeDesc.OffsetInDescriptorsFromTableStart = 0; // Range 到根描述表开头的偏移量 (单位:描述符),根签名需要用它来寻找 Range 的地址,我们这填 0 就行
D3D12_ROOT_DESCRIPTOR_TABLE RootDescriptorTableDesc = {}; // RootDescriptorTable 根描述表信息结构体,一个 Table 可以有多个 Range
RootDescriptorTableDesc.pDescriptorRanges = &SRVDescriptorRangeDesc; // Range 描述符范围指针
RootDescriptorTableDesc.NumDescriptorRanges = 1; // 根描述表中 Range 的数量
RootParameters[2].ShaderVisibility = D3D12_SHADER_VISIBILITY_PIXEL; // 根参数在着色器中的可见性,这里指定仅在像素着色器可见 (只有像素着色器用到了纹理)
RootParameters[2].ParameterType = D3D12_ROOT_PARAMETER_TYPE_DESCRIPTOR_TABLE; // 根参数类型,这里我们选 Table 根描述表,一个根描述表占用 1 DWORD
RootParameters[2].DescriptorTable = RootDescriptorTableDesc; // 根参数指针
D3D12_STATIC_SAMPLER_DESC StaticSamplerDesc = {}; // 静态采样器结构体,静态采样器不会占用根签名
StaticSamplerDesc.ShaderRegister = 0; // 要绑定的寄存器槽,对应 s0
StaticSamplerDesc.RegisterSpace = 0; // 要绑定的寄存器空间,对应 space0
StaticSamplerDesc.ShaderVisibility = D3D12_SHADER_VISIBILITY_PIXEL; // 静态采样器在着色器中的可见性,这里指定仅在像素着色器可见 (只有像素着色器用到了纹理采样)
StaticSamplerDesc.Filter = D3D12_FILTER_COMPARISON_MIN_MAG_MIP_POINT; // 纹理过滤类型,这里我们直接选 邻近点采样 就行
StaticSamplerDesc.AddressU = D3D12_TEXTURE_ADDRESS_MODE_BORDER; // 在 U 方向上的纹理寻址方式
StaticSamplerDesc.AddressV = D3D12_TEXTURE_ADDRESS_MODE_BORDER; // 在 V 方向上的纹理寻址方式
StaticSamplerDesc.AddressW = D3D12_TEXTURE_ADDRESS_MODE_BORDER; // 在 W 方向上的纹理寻址方式 (3D 纹理会用到)
StaticSamplerDesc.MinLOD = 0; // 最小 LOD 细节层次,这里我们默认填 0 就行
StaticSamplerDesc.MaxLOD = D3D12_FLOAT32_MAX; // 最大 LOD 细节层次,这里我们默认填 D3D12_FLOAT32_MAX (没有 LOD 上限)
StaticSamplerDesc.MipLODBias = 0; // 基础 Mipmap 采样偏移量,我们这里我们直接填 0 就行
StaticSamplerDesc.MaxAnisotropy = 1; // 各向异性过滤等级,我们不使用各向异性过滤,需要默认填 1
StaticSamplerDesc.ComparisonFunc = D3D12_COMPARISON_FUNC_NEVER; // 这个是用于阴影贴图的,我们不需要用它,所以填 D3D12_COMPARISON_FUNC_NEVER
D3D12_ROOT_SIGNATURE_DESC rootsignatureDesc = {}; // 根签名信息结构体,上限 64 DWORD,静态采样器不占用根签名
rootsignatureDesc.NumParameters = 3; // 根参数数量
rootsignatureDesc.pParameters = RootParameters; // 根参数指针
rootsignatureDesc.NumStaticSamplers = 1; // 静态采样器数量
rootsignatureDesc.pStaticSamplers = &StaticSamplerDesc; // 静态采样器指针
// 根签名标志,可以设置渲染管线不同阶段下的输入参数状态。注意这里!我们要从 IA 阶段输入顶点数据,所以要通过根签名,设置渲染管线允许从 IA 阶段读入数据
rootsignatureDesc.Flags = D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT;
// 编译根签名,让根签名先编译成 GPU 可读的二进制字节码
D3D12SerializeRootSignature(&rootsignatureDesc, D3D_ROOT_SIGNATURE_VERSION_1_0, &SignatureBlob, &ErrorBlob);
if (ErrorBlob) // 如果根签名编译出错,ErrorBlob 可以提供报错信息
{
OutputDebugStringA((const char*)ErrorBlob->GetBufferPointer());
OutputDebugStringA("\n");
}
// 用这个二进制字节码创建根签名对象
m_D3D12Device->CreateRootSignature(0, SignatureBlob->GetBufferPointer(), SignatureBlob->GetBufferSize(), IID_PPV_ARGS(&m_RootSignature));
}
// 创建 PSO 渲染管线状态对象
void STEP20_CreatePSO()
{
// PSO 信息结构体
D3D12_GRAPHICS_PIPELINE_STATE_DESC PSODesc = {};
// Input Assembler 输入装配阶段
D3D12_INPUT_LAYOUT_DESC InputLayoutDesc = {}; // 输入样式信息结构体
D3D12_INPUT_ELEMENT_DESC InputElementDesc[5] = {}; // 输入元素信息结构体数组
// Input Slot 0: Vertex Stream 顶点流,逐顶点输入
// 顶点位置 float4 Position
InputElementDesc[0].SemanticName = "POSITION"; // 要锚定的语义
InputElementDesc[0].SemanticIndex = 0; // 语义索引
InputElementDesc[0].Format = DXGI_FORMAT_R32G32B32A32_FLOAT; // 输入格式
InputElementDesc[0].InputSlot = 0; // 输入槽编号
InputElementDesc[0].AlignedByteOffset = 0; // 在输入槽中的偏移
InputElementDesc[0].InputSlotClass = D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA; // 输入流类型
InputElementDesc[0].InstanceDataStepRate = 0; // 实例数据步进率
// 纹理 UV 坐标 float2 texcoordUV
InputElementDesc[1].SemanticName = "TEXCOORD"; // 要锚定的语义
InputElementDesc[1].SemanticIndex = 0; // 语义索引
InputElementDesc[1].Format = DXGI_FORMAT_R32G32_FLOAT; // 输入格式
InputElementDesc[1].InputSlot = 0; // 输入槽编号
InputElementDesc[1].AlignedByteOffset = 16; // 在输入槽中的偏移
InputElementDesc[1].InputSlotClass = D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA; // 输入流类型
InputElementDesc[1].InstanceDataStepRate = 0; // 实例数据步进率
// 顶点所属立方体索引 uint FaceIndex
InputElementDesc[2].SemanticName = "FACEINDEX"; // 要锚定的语义
InputElementDesc[2].SemanticIndex = 0; // 语义索引
InputElementDesc[2].Format = DXGI_FORMAT_R32_UINT; // 输入格式
InputElementDesc[2].InputSlot = 0; // 输入槽编号
InputElementDesc[2].AlignedByteOffset = 24; // 在输入槽中的偏移
InputElementDesc[2].InputSlotClass = D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA; // 输入流类型
InputElementDesc[2].InstanceDataStepRate = 0; // 实例数据步进率
// Input Slot 1: Instance Stream 实例流,逐实例输入
// Instance 实例,是指同一份几何数据 (如一个方块的顶点和索引) 的多个独立副本
// 你可以把实例理解成 "同一个模具生产出的多个产品" (类似 C++ 的类与对象,类是模具,对象是产品)
// 模具: 就是一个 3D 模型 (顶点、索引、纹理 UV 等固定数据)
// 产品: 就是每个实例,它们共享相同的"模具",但可以有不同的位置、颜色、纹理索引、大小等属性
// Draw Call 绘制调用对渲染效率影响很大,越少的 Draw Call 画出越多的东西,渲染效率越高
// Draw Call 会带来 CPU 和 GPU 的双重开销,包括 CPU 端的固定成本和 GPU 端的流水线停顿
// 为了提高渲染效率,于是就诞生了 Instance 实例化技术
// 早期的优化技术叫 Batch Draw 批绘制,它是一种 Software Approximate Instancing 软件伪实例化技术
// 它的原理是将多个实例的数据,全部复制到大的顶点和索引缓冲区中,让它们合并成一个包含多实例的"超大网格"
// Draw Call 只需要绘制这个超大网格就行。实现简单,但 CPU 开销极大,内存占用高,GPU 性能损失严重 (没用上 GPU 并行计算的特性),拓展性很差
// GPU Instancing 硬件实例化是一种高效的渲染技术,允许你只用一次绘制调用就可以渲染多个相同的物体,全程硬件 (GPU) 报销
// 但每个物体可以拥有不同的变换 (模型矩阵)、颜色、纹理索引甚至纹理 UV 等属性
// 硬件实例化可以专门设置一份副本几何数据 + 很多份不同的实例数据 (硬件支持,下文也会用到),将"重复绘制"这个任务直接交给 GPU 的固定功能单元
// 每次绘制一个实例,GPU 都会复制一份副本,然后在 shader 上混合副本和实例的部分数据,这样就得到了完整的新实例数据,神奇吗?
// 硬件实例化开销低,内存占用小,易于拓展,可以完全利用 GPU 的并行特性 (可以同时好几个 GPU 线程做实例数据混合),软件实例化的优点它都有
// 所以后来图形硬件升级,支持硬件实例化后,软件实例化在实际开发中就直接被踢下来了,目前只有一些旧 API 还在使用
// 我们接下来要渲染大量位置和纹理贴图不同的方块 (1125 个),1125 次绘制调用 GPU 开销会非常大
// 我们注意到方块顶点和索引的数据都是一样的,只是坐标和纹理索引不同,所以我们可以尝试利用 纹理数组 + 结构化缓冲 + 硬件实例化 渲染这么多方块
// 下面有两个十分重要的成员:
// InputSlotClass 输入流类型,要填 D3D12_INPUT_CLASSIFICATION_PER_INSTANCE_DATA,这样才能开启硬件实例化
// InstanceDataStepRate 实例数据步进率,它的意思是"每渲染多少个实例后,从实例数据缓冲区中前进到下一个元素"
// InstanceDataStepRate = 0 时,必须是 D3D12_INPUT_CLASSIFICATION_PER_VERTEX_DATA
// InstanceDataStepRate = 1 时,每个实例数据只会传一次,一个实例数据对应一个实例,而且画完当前实例就画下一个实例,我们选这个
// InstanceDataStepRate > 1 时,是未定义行为 (DX12 把 DX11 的"灵活步进"砍掉了,原因是简化硬件逻辑,减少驱动开销)
// 注意!同一个输入槽下的 InputSlotClass 和 InstanceDataStepRate 必须相同!!
// 否则调试层报错:All elements from a given input slot must have the same InputSlotClass and InstanceDataStepRate.
// 所以 顶点流 和 实例流 分成两个独立的输入槽,要用两个不同的 VertexBufferView,不仅是我的想法,而且是 DX12 API 强制要求我们这样分门别类
// 方块实例相对世界空间的偏移 float3 BlockOffset
InputElementDesc[3].SemanticName = "BLOCKOFFSET"; // 要锚定的语义
InputElementDesc[3].SemanticIndex = 0; // 语义索引
InputElementDesc[3].Format = DXGI_FORMAT_R32G32B32_FLOAT; // 输入格式
InputElementDesc[3].InputSlot = 1; // 输入槽编号
InputElementDesc[3].AlignedByteOffset = 0; // 在输入槽中的偏移
InputElementDesc[3].InputSlotClass = D3D12_INPUT_CLASSIFICATION_PER_INSTANCE_DATA; // 输入流类型
InputElementDesc[3].InstanceDataStepRate = 1; // 实例数据步进率
// 方块实例类型 uint BlockType
InputElementDesc[4].SemanticName = "BLOCKTYPE"; // 要锚定的语义
InputElementDesc[4].SemanticIndex = 0; // 语义索引
InputElementDesc[4].Format = DXGI_FORMAT_R32_UINT; // 输入格式
InputElementDesc[4].InputSlot = 1; // 输入槽编号
InputElementDesc[4].AlignedByteOffset = 12; // 在输入槽中的偏移
InputElementDesc[4].InputSlotClass = D3D12_INPUT_CLASSIFICATION_PER_INSTANCE_DATA; // 输入流类型
InputElementDesc[4].InstanceDataStepRate = 1; // 实例数据步进率
InputLayoutDesc.NumElements = 5; // 输入元素个数
InputLayoutDesc.pInputElementDescs = InputElementDesc; // 输入元素结构体数组指针
PSODesc.InputLayout = InputLayoutDesc; // 设置渲染管线 IA 阶段的输入样式
ComPtr<ID3DBlob> VertexShaderBlob; // 顶点着色器二进制字节码
ComPtr<ID3DBlob> PixelShaderBlob; // 像素着色器二进制字节码
ComPtr<ID3DBlob> ErrorBlob; // 错误字节码
// 编译顶点着色器 Vertex Shader
D3DCompileFromFile(L"RenderShader.hlsl", nullptr, nullptr, "VSMain", "vs_5_1", NULL, NULL, &VertexShaderBlob, &ErrorBlob);
if (ErrorBlob) // 如果着色器编译出错,ErrorBlob 可以提供报错信息
{
OutputDebugStringA((const char*)ErrorBlob->GetBufferPointer());
OutputDebugStringA("\n");
}
// 编译像素着色器 Pixel Shader
D3DCompileFromFile(L"RenderShader.hlsl", nullptr, nullptr, "PSMain", "ps_5_1", NULL, NULL, &PixelShaderBlob, &ErrorBlob);
if (ErrorBlob) // 如果着色器编译出错,ErrorBlob 可以提供报错信息
{
OutputDebugStringA((const char*)ErrorBlob->GetBufferPointer());
OutputDebugStringA("\n");
}
PSODesc.VS.pShaderBytecode = VertexShaderBlob->GetBufferPointer(); // VS 字节码数据指针
PSODesc.VS.BytecodeLength = VertexShaderBlob->GetBufferSize(); // VS 字节码数据长度
PSODesc.PS.pShaderBytecode = PixelShaderBlob->GetBufferPointer(); // PS 字节码数据指针
PSODesc.PS.BytecodeLength = PixelShaderBlob->GetBufferSize(); // PS 字节码数据长度
// Rasterizer 光栅化
PSODesc.RasterizerState.CullMode = D3D12_CULL_MODE_NONE; // 不进行剔除,渲染的方块有玻璃,有深度缓冲和混合兜底
PSODesc.RasterizerState.FillMode = D3D12_FILL_MODE_SOLID; // 纯色填充
// 第一次设置根签名!本次设置是将根签名与 PSO 绑定,生成对应版本的根签名适配 PSO,设置渲染管线的输入参数状态
PSODesc.pRootSignature = m_RootSignature.Get();
// 设置深度测试状态
PSODesc.DSVFormat = DSVFormat; // 设置深度缓冲的格式
PSODesc.DepthStencilState.DepthEnable = true; // 开启深度缓冲
PSODesc.DepthStencilState.DepthFunc = D3D12_COMPARISON_FUNC_LESS; // 深度缓冲的比较方式
PSODesc.DepthStencilState.DepthWriteMask = D3D12_DEPTH_WRITE_MASK_ALL; // 深度缓冲的读写权限
// 开启混合
PSODesc.BlendState.RenderTarget[0].BlendEnable = true;
// 让上层色彩乘上 SrcA,Src * SrcA
PSODesc.BlendState.RenderTarget[0].SrcBlend = D3D12_BLEND_SRC_ALPHA;
// 让下层色彩乘上 1 - SrcA,Dest * (1 - SrcA)
PSODesc.BlendState.RenderTarget[0].DestBlend = D3D12_BLEND_INV_SRC_ALPHA;
// 两种色彩相加,ResultRGB = Src * SrcA + Dest * (1 - SrcA)
PSODesc.BlendState.RenderTarget[0].BlendOp = D3D12_BLEND_OP_ADD;
// 下面的三个选项控制 Alpha 通道的混合,Alpha 通道与 RGB 通道的混合是分开的,这一点请留意!
// ResultA = SrcA * 1 + DstA * 1
// 让上层色彩透明度乘 1,表示使用 SrcA
PSODesc.BlendState.RenderTarget[0].SrcBlendAlpha = D3D12_BLEND_ONE;
// 让下层色彩透明度乘 0,表示不使用 DstA
PSODesc.BlendState.RenderTarget[0].DestBlendAlpha = D3D12_BLEND_ZERO;
// 最终要混合的色彩 alpha 是 ResultA
PSODesc.BlendState.RenderTarget[0].BlendOpAlpha = D3D12_BLEND_OP_ADD;
// 设置基本图元,这里我们设置三角形面
PSODesc.PrimitiveTopologyType = D3D12_PRIMITIVE_TOPOLOGY_TYPE_TRIANGLE;
// 设置渲染目标数量,我们只有一副渲染目标 (颜色缓冲) 需要进行渲染,所以填 1
PSODesc.NumRenderTargets = 1;
// 设置渲染目标的格式,这里要和交换链指定窗口缓冲的格式一致,这里的 0 指的是渲染目标的索引
PSODesc.RTVFormats[0] = DXGI_FORMAT_R8G8B8A8_UNORM;
// 设置混合阶段 (输出合并阶段) 下 RGBA 颜色通道的开启和关闭,D3D12_COLOR_WRITE_ENABLE_ALL 表示 RGBA 四色通道全部开启
PSODesc.BlendState.RenderTarget[0].RenderTargetWriteMask = D3D12_COLOR_WRITE_ENABLE_ALL;
// 设置采样次数,我们这里填 1 就行
PSODesc.SampleDesc.Count = 1;
// 设置采样掩码,这个是用于多重采样的,我们直接填全采样 (UINT_MAX,就是将 UINT 所有的比特位全部填充为 1) 就行
PSODesc.SampleMask = UINT_MAX;
// 最终创建 PSO 对象
m_D3D12Device->CreateGraphicsPipelineState(&PSODesc, IID_PPV_ARGS(&m_RenderBlockPSO));
}
// 创建顶点流的顶点缓冲和索引缓冲,用的是 VBV0 和 IBV
void STEP21_CreatePerVertexAndIndexBuffer()
{
// 上传堆顶点资源结构体
D3D12_RESOURCE_DESC VertexResourceDesc = {};
VertexResourceDesc.Dimension = D3D12_RESOURCE_DIMENSION_BUFFER;
VertexResourceDesc.Layout = D3D12_TEXTURE_LAYOUT_ROW_MAJOR;
VertexResourceDesc.Width = PreBlockVertexData.size() * sizeof(VERTEX);
VertexResourceDesc.Height = 1;
VertexResourceDesc.Format = DXGI_FORMAT_UNKNOWN;
VertexResourceDesc.DepthOrArraySize = 1;
VertexResourceDesc.MipLevels = 1;
VertexResourceDesc.SampleDesc.Count = 1;
// 创建顶点资源
m_D3D12Device->CreateCommittedResource(&UploadHeapDesc, D3D12_HEAP_FLAG_NONE, &VertexResourceDesc,
D3D12_RESOURCE_STATE_GENERIC_READ, nullptr, IID_PPV_ARGS(&m_BlockVertexResource));
// 上传堆索引资源结构体
D3D12_RESOURCE_DESC IndexResourceDesc = {};
IndexResourceDesc.Dimension = D3D12_RESOURCE_DIMENSION_BUFFER;
IndexResourceDesc.Layout = D3D12_TEXTURE_LAYOUT_ROW_MAJOR;
IndexResourceDesc.Width = PreBlockIndexData.size() * sizeof(UINT);
IndexResourceDesc.Height = 1;
IndexResourceDesc.Format = DXGI_FORMAT_UNKNOWN;
IndexResourceDesc.DepthOrArraySize = 1;
IndexResourceDesc.MipLevels = 1;
IndexResourceDesc.SampleDesc.Count = 1;
// 创建索引资源
m_D3D12Device->CreateCommittedResource(&UploadHeapDesc, D3D12_HEAP_FLAG_NONE, &IndexResourceDesc,
D3D12_RESOURCE_STATE_GENERIC_READ, nullptr, IID_PPV_ARGS(&m_BlockIndexResource));
// 将数据复制到上传堆
BYTE* TransferPointer = nullptr;
m_BlockVertexResource->Map(0, nullptr, reinterpret_cast<void**>(&TransferPointer));
memcpy(TransferPointer, &PreBlockVertexData[0], PreBlockVertexData.size() * sizeof(VERTEX));
m_BlockVertexResource->Unmap(0, nullptr);
m_BlockIndexResource->Map(0, nullptr, reinterpret_cast<void**>(&TransferPointer));
memcpy(TransferPointer, &PreBlockIndexData[0], PreBlockIndexData.size() * sizeof(UINT));
m_BlockIndexResource->Unmap(0, nullptr);
// 填写 VBV0,IBV 结构体
VertexBufferView[0].BufferLocation = m_BlockVertexResource->GetGPUVirtualAddress();
VertexBufferView[0].StrideInBytes = sizeof(VERTEX);
VertexBufferView[0].SizeInBytes = PreBlockVertexData.size() * sizeof(VERTEX);
IndexBufferView.BufferLocation = m_BlockIndexResource->GetGPUVirtualAddress();
IndexBufferView.Format = DXGI_FORMAT_R32_UINT;
IndexBufferView.SizeInBytes = PreBlockIndexData.size() * sizeof(UINT);
}
// 创建实例流缓冲,用的是 VBV1
void STEP22_CreatePerInstanceBuffer()
{
// 设置随机种子
srand(time(0));
// 方块实例组 (std::vector) 先 resize 大小,这是一个很重要的优化技巧,可以减少 push_back 带来的空间扩容开销!
BlockGroup.resize(1125);
// 随机生成方块实例,一共生成 5 个平面的方块,每个平面互相距离 6 格,从最低平面 (Y = -13) 开始生成
for (int y = -13; y <= 13; y += 6)
{
// 每个平面生成 9 条方块线,每条线互相距离 6 格,从最低坐标 (Z = -25) 开始生成
for (int z = -25; z <= 25; z += 6)
{
// 每条方块线是一个个分离的"小斜线",每条线长度是 25 个方块,每移动一个方块距离 (2 * x) 就根据"斜线"偏移 y 坐标
// 对 Y 轴还要偏移一次,是为了和相邻的方块隔开,方便看到所有方块的全部 6 个面
for (int x = 0; x < 25; x++)
{
float BlockX = 2 * x - 25; // 每个方块向 x 轴偏移一个方块距离,从最低坐标 (X = -25) 开始
float BlockY = y + 2 * (x % 3) - 2; // 根据 x 计算"斜线"对应的 y 坐标
float BlockZ = z; // z 坐标直接填
UINT BlockTypeIndex = rand() % BlockCubeTexture_IndexGroup.size(); // 随机选择一个方块类型
// 方块实例组新增方块数据,这样我们就得到了一个新的方块实例
BlockGroup.push_back({ XMFLOAT3(BlockX, BlockY, BlockZ), BlockTypeIndex });
}
}
}
// 总共生成 5 x 9 x 25 = 1125 个方块实例
// 上传堆实例资源结构体
D3D12_RESOURCE_DESC InstanceResourceDesc = {};
InstanceResourceDesc.Dimension = D3D12_RESOURCE_DIMENSION_BUFFER;
InstanceResourceDesc.Layout = D3D12_TEXTURE_LAYOUT_ROW_MAJOR;
InstanceResourceDesc.Width = BlockGroup.size() * sizeof(BLOCKINSTANCE);
InstanceResourceDesc.Height = 1;
InstanceResourceDesc.Format = DXGI_FORMAT_UNKNOWN;
InstanceResourceDesc.DepthOrArraySize = 1;
InstanceResourceDesc.MipLevels = 1;
InstanceResourceDesc.SampleDesc.Count = 1;
// 创建实例资源
m_D3D12Device->CreateCommittedResource(&UploadHeapDesc, D3D12_HEAP_FLAG_NONE, &InstanceResourceDesc,
D3D12_RESOURCE_STATE_GENERIC_READ, nullptr, IID_PPV_ARGS(&m_BlockInstanceResource));
// 将数据复制到上传堆
BYTE* TransferPointer = nullptr;
m_BlockInstanceResource->Map(0, nullptr, reinterpret_cast<void**>(&TransferPointer));
memcpy(TransferPointer, &BlockGroup[0], BlockGroup.size() * sizeof(BLOCKINSTANCE));
m_BlockInstanceResource->Unmap(0, nullptr);
// 填写 VBV1 结构体
VertexBufferView[1].BufferLocation = m_BlockInstanceResource->GetGPUVirtualAddress();
VertexBufferView[1].StrideInBytes = sizeof(BLOCKINSTANCE);
VertexBufferView[1].SizeInBytes = BlockGroup.size() * sizeof(BLOCKINSTANCE);
}
// ---------------------------------------------------------------------------------------------------------------
// 更新常量缓冲区,将每帧新的 MVP 矩阵传递到常量缓冲区中,这样就能看到动态的 3D 画面了
void UpdateConstantBuffer()
{
// 将更新后的矩阵,存储到共享内存上的常量缓冲,这样 GPU 就可以访问到 MVP 矩阵了
XMStoreFloat4x4(&MVPBuffer->MVPMatrix, m_FirstCamera.GetMVPMatrix());
}
// 渲染
void Render()
{
// 每帧渲染开始前,调用 UpdateConstantBuffer() 更新常量缓冲区
UpdateConstantBuffer();
// 获取 RTV 堆首句柄
RTVHandle = m_RTVHeap->GetCPUDescriptorHandleForHeapStart();
// 获取当前渲染的后台缓冲序号
FrameIndex = m_DXGISwapChain->GetCurrentBackBufferIndex();
// 偏移 RTV 句柄,找到对应的 RTV 描述符
RTVHandle.ptr += FrameIndex * RTVDescriptorSize;
// 先重置命令分配器
m_CommandAllocator->Reset();
// 再重置命令列表,Close 关闭状态 -> Record 录制状态
m_CommandList->Reset(m_CommandAllocator.Get(), nullptr);
// 将起始转换屏障的资源指定为当前渲染目标
beg_barrier.Transition.pResource = m_RenderTarget[FrameIndex].Get();
// 调用资源屏障,将渲染目标由 Present 呈现(只读) 转换到 RenderTarget 渲染目标(只写)
m_CommandList->ResourceBarrier(1, &beg_barrier);
// 设置视口 (光栅化阶段),用于光栅化里的屏幕映射
m_CommandList->RSSetViewports(1, &ViewPort);
// 设置裁剪矩形 (光栅化阶段)
m_CommandList->RSSetScissorRects(1, &ScissorRect);
// 清空后台的深度模板缓冲,将深度重置为初始值 1,记住上文创建深度缓冲资源的时候,要填 ClearValue
// 否则会报 D3D12 WARNING: The application did not pass any clear value to resource creation.
m_CommandList->ClearDepthStencilView(DSVHandle, D3D12_CLEAR_FLAG_DEPTH, 1, 0, 0, nullptr);
// 清空当前渲染目标的背景为天蓝色
m_CommandList->ClearRenderTargetView(RTVHandle, DirectX::Colors::SkyBlue, 0, nullptr);
// 用 RTV 句柄设置渲染目标,同时用 DSV 句柄设置深度模板缓冲,开启深度测试
m_CommandList->OMSetRenderTargets(1, &RTVHandle, false, &DSVHandle);
// 第二次设置根签名,本次检测 PSO 根签名的合法性 (引用资源是否匹配),检测成功会开启显存与寄存器的映射通道
m_CommandList->SetGraphicsRootSignature(m_RootSignature.Get());
// 设置 PSO 渲染管线状态
m_CommandList->SetPipelineState(m_RenderBlockPSO.Get());
// 设置第一个根参数:CBV 描述符 (MVP 缓冲)
m_CommandList->SetGraphicsRootConstantBufferView(0, m_CBVResource->GetGPUVirtualAddress());
// 设置第二个根参数:SRV 根描述符 (结构化缓冲),注意这里设置的是默认堆资源的 GPU 地址!
m_CommandList->SetGraphicsRootShaderResourceView(1, m_StructuredBufferDefaultResource->GetGPUVirtualAddress());
// 用于设置描述符堆用的临时 ID3D12DescriptorHeap 数组
ID3D12DescriptorHeap* _temp_DescriptorHeaps[] = { m_SRVHeap.Get() };
// 设置描述符堆
m_CommandList->SetDescriptorHeaps(1, _temp_DescriptorHeaps);
// 设置 SRV 句柄 (第三个根参数),我们设置了一个纹理数组,只设置了一次哦!切换纹理索引都在 shader 中进行
// 相比每纹理单独绑定,用纹理数组的好处是没有切换开销,GPU 缓冲命中率很高,减少描述符堆压力,可以用于硬件实例化!
// 用纹理数组 + 结构化缓冲/常量缓冲 + 硬件实例化,可以快速绘制大量不同的方块实例 (甚至是其他东西!)
// 本质上是利用了 GPU Instancing 硬件实例化技术,设备上下文切换只需要一次
// 而且还能减少 CPU 需要传递的数据,增加带宽,相比第 7-8 章的写法要快很多 (不信可以用 PIX 测帧数)
// 缺点是灵活性低,每个纹理元素的长宽,Mipmap,纹理格式等等必须相同
m_CommandList->SetGraphicsRootDescriptorTable(2, SRVTextureArray_GPUHandle);
// 设置图元拓扑 (输入装配阶段),我们这里设置三角形列表
m_CommandList->IASetPrimitiveTopology(D3D_PRIMITIVE_TOPOLOGY_TRIANGLELIST);
// 设置 VBV 顶点缓冲描述符数组,两个 VBV 都会被设置 (输入装配阶段)
m_CommandList->IASetVertexBuffers(0, 2, VertexBufferView);
// 设置 IBV 索引缓冲描述符 (输入装配阶段)
m_CommandList->IASetIndexBuffer(&IndexBufferView);
// Draw Call 渲染所有目标实例!我们只用了一次 Draw Call 就完成了 1125 个方块的渲染!
m_CommandList->DrawIndexedInstanced(PreBlockIndexData.size(), BlockGroup.size(), 0, 0, 0);
// 将终止转换屏障的资源指定为当前渲染目标
end_barrier.Transition.pResource = m_RenderTarget[FrameIndex].Get();
// 再通过一次资源屏障,将渲染目标由 RenderTarget 渲染目标(只写) 转换到 Present 呈现(只读)
m_CommandList->ResourceBarrier(1, &end_barrier);
// 关闭命令列表,Record 录制状态 -> Close 关闭状态,命令列表只有关闭才可以提交
m_CommandList->Close();
// 用于传递命令用的临时 ID3D12CommandList 数组
ID3D12CommandList* _temp_cmdlists[] = { m_CommandList.Get() };
// 执行上文的渲染命令!
m_CommandQueue->ExecuteCommandLists(1, _temp_cmdlists);
// 向命令队列发出交换缓冲的命令,此命令会加入到命令队列中,命令队列执行到该命令时,会通知交换链交换缓冲
m_DXGISwapChain->Present(1, NULL);
// 将围栏预定值设定为下一帧
FenceValue++;
// 在命令队列 (命令队列在 GPU 端) 设置围栏预定值,此命令会加入到命令队列中
// 命令队列执行到这里会修改围栏值,表示渲染已完成,"击中"围栏
m_CommandQueue->Signal(m_Fence.Get(), FenceValue);
// 设置围栏的预定事件,当渲染完成时,围栏被"击中",激发预定事件,将事件由无信号状态转换成有信号状态
m_Fence->SetEventOnCompletion(FenceValue, RenderEvent);
}
// 渲染循环
void STEP23_RenderLoop()
{
bool isExit = false; // 是否退出
MSG msg = {}; // 消息结构体
while (isExit != true)
{
// MsgWaitForMultipleObjects 用于多个线程的无阻塞等待,返回值是激发事件 (线程) 的 ID
// 经过该函数后 RenderEvent 也会自动重置为无信号状态,因为我们创建事件的时候指定了第二个参数为 false
DWORD ActiveEvent = ::MsgWaitForMultipleObjects(1, &RenderEvent, false, INFINITE, QS_ALLINPUT);
switch (ActiveEvent - WAIT_OBJECT_0)
{
case 0: // ActiveEvent 是 0,说明渲染事件已经完成了,进行下一次渲染
{
Render();
}
break;
case 1: // ActiveEvent 是 1,说明渲染事件未完成,CPU 主线程同时处理窗口消息,防止界面假死
{
// 查看消息队列是否有消息,如果有就获取。 PM_REMOVE 表示获取完消息,就立刻将该消息从消息队列中移除
while (PeekMessage(&msg, NULL, 0, 0, PM_REMOVE))
{
// 如果程序没有收到退出消息,就向操作系统发出派发消息的命令
if (msg.message != WM_QUIT)
{
TranslateMessage(&msg); // 翻译消息,当键盘按键发出信号 (WM_KEYDOWN),将虚拟按键值转换为对应的 ASCII 码,同时产生 WM_CHAR 消息
DispatchMessage(&msg); // 派发消息,通知操作系统调用回调函数处理消息
}
else
{
isExit = true; // 收到退出消息,就退出消息循环
}
}
}
break;
case WAIT_TIMEOUT: // 渲染超时
{
}
break;
}
}
}
// 回调函数,处理窗口产生的消息
// WASD 键 ------ 摄像机前后左右移动
// 鼠标长按左键移动 ------ 摄像机视角旋转
// 关闭窗口 ------ 窗口关闭,程序进程退出
LRESULT CALLBACK CallBackFunc(HWND hwnd, UINT msg, WPARAM wParam, LPARAM lParam)
{
// 用 switch 将第二个参数分流,每个 case 分别对应一个窗口消息
switch (msg)
{
case WM_DESTROY: // 窗口被销毁 (当按下右上角 X 关闭窗口时)
{
PostQuitMessage(0); // 向操作系统发出退出请求 (WM_QUIT),结束消息循环
}
break;
case WM_CHAR: // 获取键盘产生的字符消息,TranslateMessage 会将虚拟键码翻译成字符码,同时产生 WM_CHAR 消息
{
switch (wParam) // wParam 是按键对应的字符 ASCII 码
{
case 'w':
case 'W': // 向前移动
m_FirstCamera.Walk(0.2);
break;
case 's':
case 'S': // 向后移动
m_FirstCamera.Walk(-0.2);
break;
case 'a':
case 'A': // 向左移动
m_FirstCamera.Strafe(-0.2);
break;
case 'd':
case 'D': // 向右移动
m_FirstCamera.Strafe(0.2);
break;
}
}
break;
case WM_MOUSEMOVE: // 获取鼠标移动消息
{
switch (wParam) // wParam 是鼠标按键的状态
{
case MK_LBUTTON: // 当用户长按鼠标左键的同时移动鼠标,摄像机旋转
m_FirstCamera.CameraRotate();
break;
// 按键没按,鼠标只是移动也要更新,否则就会发生摄像机视角瞬移
default: m_FirstCamera.UpdateLastCursorPos();
}
}
break;
// 如果接收到其他消息,直接默认返回整个窗口
default: return DefWindowProc(hwnd, msg, wParam, lParam);
}
return 0; // 注意这里!default 除外的分支都会运行到这里,因此需要 return 0,否则就会返回系统随机值,导致窗口无法正常显示
}
// 运行窗口
static void Run(HINSTANCE hins)
{
DX12Engine engine;
engine.STEP01_InitWindow(hins);
engine.STEP02_CreateDebugDevice();
engine.STEP03_CreateDevice();
engine.STEP04_CreateCommandComponents();
engine.STEP05_CreateRenderTarget();
engine.STEP06_CreateFenceAndBarrier();
engine.STEP07_CreateDSVHeap();
engine.STEP08_CreateDepthStencilBuffer();
engine.STEP09_CreateDSV();
engine.STEP10_CreateCameraCBVResource();
engine.STEP11_LoadTextureGroup();
engine.STEP12_GetTextureArrayElementsProperties();
engine.STEP13_CreateTextureArrayResource();
engine.STEP14_CopyTextureArrayToDefaultResource();
engine.STEP15_CreateSRVHeap();
engine.STEP16_CreateTextureArraySRV();
engine.STEP17_CreateStructuredBufferResource();
engine.STEP18_CopyStructuredBufferToDefaultResource();
engine.STEP19_CreateRootSignature();
engine.STEP20_CreatePSO();
engine.STEP21_CreatePerVertexAndIndexBuffer();
engine.STEP22_CreatePerInstanceBuffer();
engine.STEP23_RenderLoop();
}
};
// 主函数
int WINAPI WinMain(HINSTANCE hins, HINSTANCE hPrev, LPSTR cmdLine, int cmdShow)
{
DX12Engine::Run(hins);
}RenderShader.hlsl
cpp
// (15) DrawInstanced: 学会 DirectX 12 的纹理数组、SRV Structured Buffer 结构化缓冲的创建与使用,以及多实例渲染的应用,一次性快速渲染大量方块
// RenderShader.hlsl: 渲染方块的 shader
// 用于 MVP 矩阵的常量缓冲
cbuffer GlobalData : register(b0, space0)
{
row_major float4x4 MVPMatrix; // 摄像机提供 MVP 矩阵,将顶点从世界空间变换到齐次裁剪空间
}
// 立方体面结构体,数组索引表示对应的立方体面,数组元素值表示 对应面所用纹理 指向 纹理数组 的索引
struct CUBEFACE
{
// 数组索引 0-5 分别对应右面 (+X),左面 (-X),前面 (+Z),后面 (-Z),上面 (+Y),下面 (-Y)
uint FaceTexture_InArrayIndex[6];
};
// GPU 上的方块类型-纹理索引组 (SRV Structured Buffer)
// HLSL 也有类似 C++ 一样的模板类,StructuredBuffer<Type> 相当于 C++ 的 std::array<type> 静态数组
// 数组索引表示不同的方块类型,数组元素值表示对应方块六个面的纹理数据索引数据
StructuredBuffer<CUBEFACE> BlockCubeTexture_IndexGroup : register(t0, space0);
// (IA 输入装配 -> VS 顶点着色器) 的 VS 输入参数结构体,注意语义要逐一锚定,不然参数会传递失败!
struct IA_To_VS
{
// 输入槽 0 (顶点流)
float4 Position : POSITION; // 顶点位置
float2 TexcoordUV : TEXCOORD; // 纹理 UV
uint FaceIndex : FACEINDEX; // 顶点所属的立方体面索引 (在 FaceTextureInArrayIndex 上的索引)
// 输入槽 1 (实例流)
float3 BlockOffset : BLOCKOFFSET; // 每个方块实例距离世界中心 (0, 0, 0) 的位移
uint BlockType : BLOCKTYPE; // 方块实例类型 (在 BlockCubeTextureIndexGroup 上的索引)
};
// (VS 顶点着色器 -> PS 像素着色器) 的 VS 输出,PS 输入参数结构体,注意语义要逐一锚定,不然参数会传递失败!
struct VS_To_PS
{
float4 NDCPosition : SV_Position; // NDC 空间坐标
float2 TexcoordUV : TEXCOORD; // 纹理 UV
// 像素最终要采样的纹理,在纹理数组的索引 (nointerpolation 表示此参数禁止在光栅化阶段插值)
nointerpolation uint FinalSampleTexture_InArrayIndex : ARRAYINDEX;
};
// 顶点着色器 (逐顶点输入,IA 输入装配 -> VS 顶点着色器 -> RS 光栅化)
// 任务:将顶点变换到齐次裁剪空间,并根据 当前实例 和 面索引 计算最终用于纹理采样的索引,之后都传入到下一个阶段
// 输入顶点的数量由 IA 阶段决定:
// 我们现在用的三角形列表,有索引缓冲区的情况下,顶点数量 = 索引数量;没有索引缓冲区,顶点数量 = 顶点缓冲区的顶点数量
// 如果用的是其他图元拓扑类型,IA 顶点传递会更加复杂,以后用到再讨论
VS_To_PS VSMain(IA_To_VS VSInput)
{
// VS 输出到 PS 的结构体
VS_To_PS VSOutput;
// 顶点累加偏移,这样就得到了实例顶点相对世界空间的坐标 (其实这个位移是丐版 ModelMatrix),注意 w 分量不累加
// (实例混合,将副本的 Position 数据与实例部分数据 BlockOffset 混合)
VSInput.Position.xyz += VSInput.BlockOffset;
// 顶点累乘 MVP 矩阵,变换到齐次裁剪空间,光栅化会进行透视除法变换到 NDC 空间,然后插值
VSOutput.NDCPosition = mul(VSInput.Position, MVPMatrix);
// 纹理 UV 不变,直接赋值,光栅化会进行插值
// (实例混合,直接使用副本的 TexcoordUV 数据)
VSOutput.TexcoordUV = VSInput.TexcoordUV;
// 得到该顶点最终用于采样的纹理索引,我们指定 nointerpolation 之后光栅化就不会对这个参数插值了
// (实例混合,将副本数据 FaceIndex 与实例部分数据 BlockType 混合)
VSOutput.FinalSampleTexture_InArrayIndex =
BlockCubeTexture_IndexGroup[VSInput.BlockType].FaceTexture_InArrayIndex[VSInput.FaceIndex];
// 输出顶点到光栅化阶段
return VSOutput;
}
// 纹理数组 2D Texture Array,实际上只是一个记录特殊信息,合并多个纹理的大纹理资源,UVW 这三个分量都用到了
Texture2DArray m_TextureArray : register(t1, space0);
// 采样器 (邻近点过滤)
SamplerState m_sampler : register(s0, space0);
// 像素着色器 (逐像素输入,RS 光栅化 -> PS 像素着色器 -> OM 输出合并)
// 任务:采样对应纹理并得到颜色,之后连带像素的其他信息传入到输出合并阶段
float4 PSMain(VS_To_PS PSInput) : SV_Target
{
// 根据采样器和纹理 UVW 进行纹理采样,W 坐标是纹理在数组中的索引 (Slice Index 切片索引)
// 如果 W 坐标有小数部分,HLSL 会强制截断取整,不会进行插值或报错
return m_TextureArray.Sample(m_sampler, float3(PSInput.TexcoordUV, PSInput.FinalSampleTexture_InArrayIndex));
}
想一想,为什么渲染结果会变成这样呢?
下一章,我们将了解一个新的东西:同样也是微软 DirectX 家族的 Direct 2D,并学会 D2D 与 D3D12 之间的互动,以及如何用 D2D 绘制简单的 2D UI 界面。