当n个客户访问一台服务器,服务器处理不过来,导致服务器挂掉,则需要LVS技术来提升服务器的处理能力。
LVS、HAProxy、Keepalived、高性能web服务器Nginx、web应用服务器TOMCAT都是高性能web集群
一、集群和·分布式简介
1. 系统性能扩展方式
-
Scale UP:向上扩展,增强
-
Scale Out:向外扩展,增加设备,调度分配问题,Cluster
2. 集群Cluster
Cluster: 集群是为了解决某个特定问题将堕胎计算机组合起来形成的单个系统
Cluster常见的三种类型:
LB:LoadBalancing(负载均衡)由多个主机组成,每个主机只承担一部分访问
HA:High Availiablity(高可用)SPOF(single Point Of failure)
- MTBF:Mean Time Between Failure 平均无故障时间,正常时间
- MTTR:Mean Time To Restoration( repair)平均恢复前时间,故障时间
- A=MTBF/(MTBF+MTTR) (0,1):99%, 99.5%, 99.9%, 99.99%, 99.999% 、
- SLA:Service level agreement(服务等级协议)是在一定开销下为保障服务的性能和可用性,服务提供商与用户间定义的一种双方认可的协定。
- 停机时间又分为两种,一种是计划内停机时间,一种是计划外停机时间,而运维则主要关注计划外 停机时间
HPC:High-performance computing(高性能计算,国家战略资源,不在课程范围内)
3. 分布式
分布式存储:Ceph,GlusterFs,FastDFS,MogileFs
分布式计算:hadoop,Spark
分布式常见应用
- 分布式应用-服务按照功能拆分,使用微服务
- 分布式静态资源--静态资源放在不同的存储集群上
- 分布式数据和存储--使用key-value缓存系统
- 分布式计算--对特殊业务使用分布式计算,比如Hadoop集群
4. 集群和分布式
- 集群:同一个业务系统,部署在多台服务器上,集群中,每一台服务器实现的功能没有差别,数据 和代码都是一样的
- 分布式:一个业务被拆成多个子业务,或者本身就是不同的业务,部署在多台服务器上。
- 分布式 中,每一台服务器实现的功能是有差别的,数据和代码也是不一样的,分布式每台服务器功能加起 来,才是完整的业务 分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数 来提升效率
- 对于大型网站,访问用户很多,实现一个群集,在前面部署一个负载均衡服务器,后面几台服务器 完成同一业务。如果有用户进行相应业务访问时,负载均衡器根据后端哪台服务器的负载情况,决 定由给哪一台去完成响应,并且台服务器垮了,其它的服务器可以顶上来。分布式的每一个节点, 都完成不同的业务,如果一个节点垮了,那这个业务可能就会失败
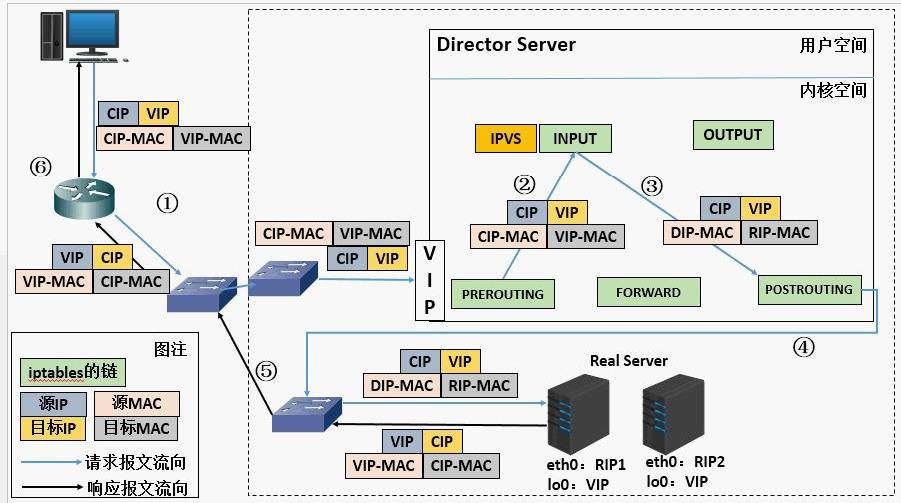
二、LVS运行原理
1. LVS简介
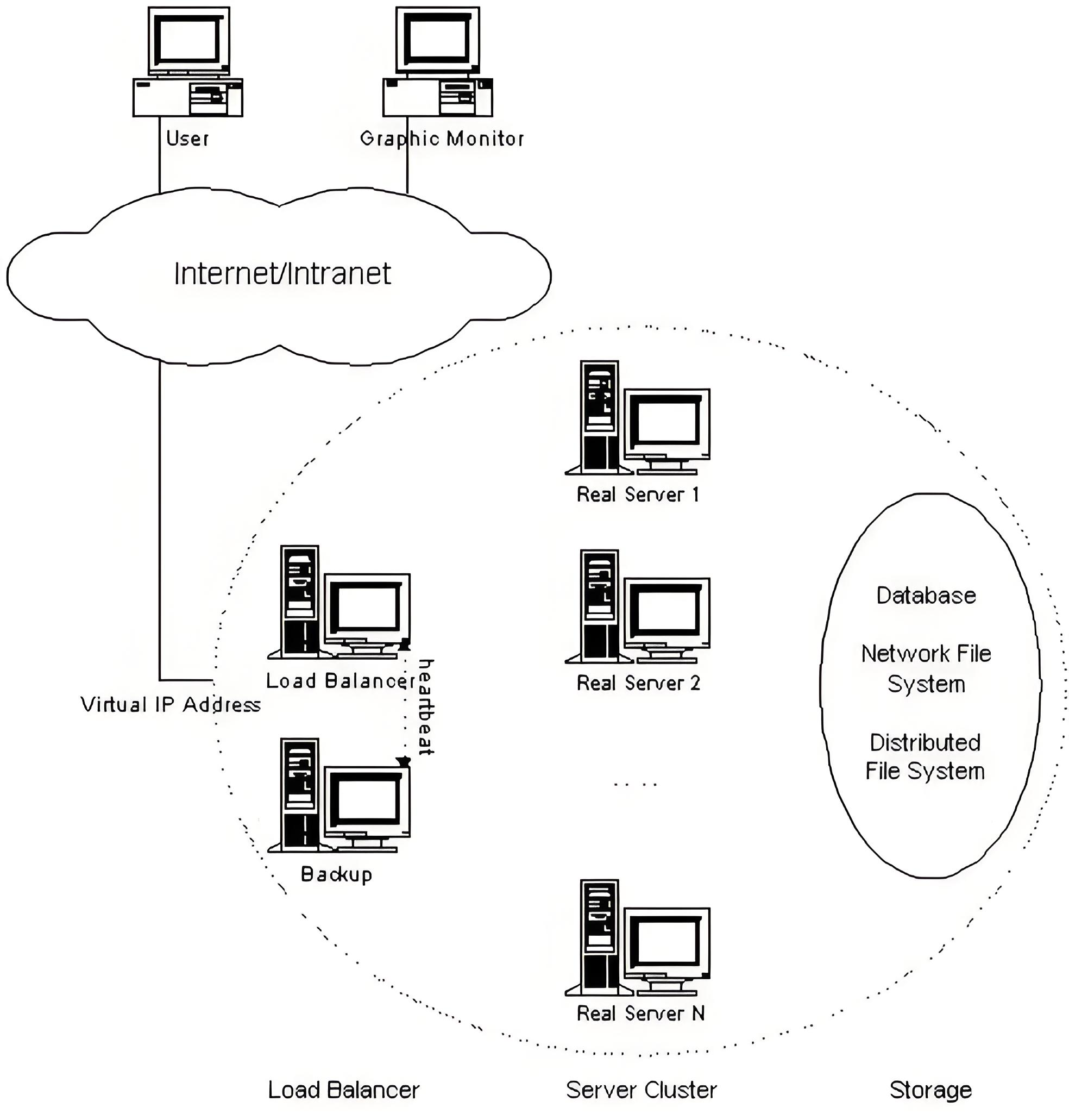
LVS(Linux Virtual Server)是Linux内核层实现高性能、高可用的负载均衡集群技术。核心是将前端(调度器VS)的请求数据分发到后端多台真实服务器(RS),从而提升服务的并发处理能力和可用性
- VS: Virtual Server,负责调度
- RS:RealServer,负责真正提供服务
LVS 官网:http://www.linuxvirtualserver.org/
2. LVS集群结构
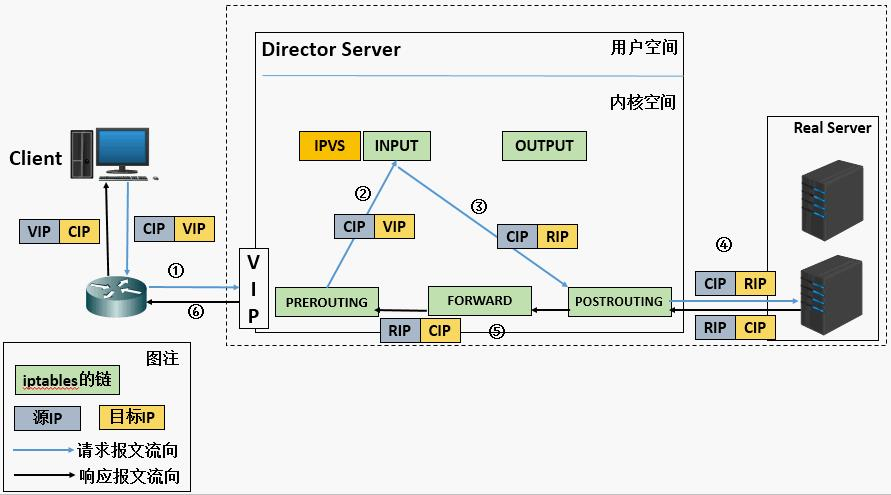
工作原理: VS根据请求报文的目标IP和目标协议及端口将其调度转发至某RS,根据调度算法来挑选RS
VS:Virtual Server(调度器)
RS:Real Server (真实业务主机)
CIP:Client IP (客户端主机的ip)
VIP: Virtual serve IP VS外网的IP (对外开放的让客户访问的ip)
DIP: Director IP VS内网的IP (调度器负责访问内网的ip)
RIP: Real server IP (真实业务主机IP)
访问流程:CIP <------>VIP == DIP<------> RIP
3. lvs集群的类型
lvs-nat: 修改请求报文的目标IP,多目标IP的DNAT
lvs-dr: 操纵封装新的MAC地址
lvs-tun: 在原请求IP报文之外新加一个IP首部
lvs-fullnat: 修改请求报文的源和目标IP
(1)NAT模式
第一层(物理层),第二层(MAC),第三层(IP),第四层(端口)
nat模式走的是第三层,修改ip地址,可以跨网络
# 真实nat环境下,后台服务器(rs)建议不超过10台,不然会导致调度器响应不过来
Ivs-nat:
- 本质是多目标IP的DNAT,通过将请求报文中的目标地址和目标端口修改为某挑出的RS的RIP和 PORT实现转发
- RIP和DIP应在同一个IP网络,且应使用私网地址;RS的网关要指向DIP
- 请求报文和响应报文都必须经由Director转发,Director易于成为系统瓶颈
- 支持端口映射,可修改请求报文的目标PORT
- VS必须是Linux系统,RS可以是任意OS系统
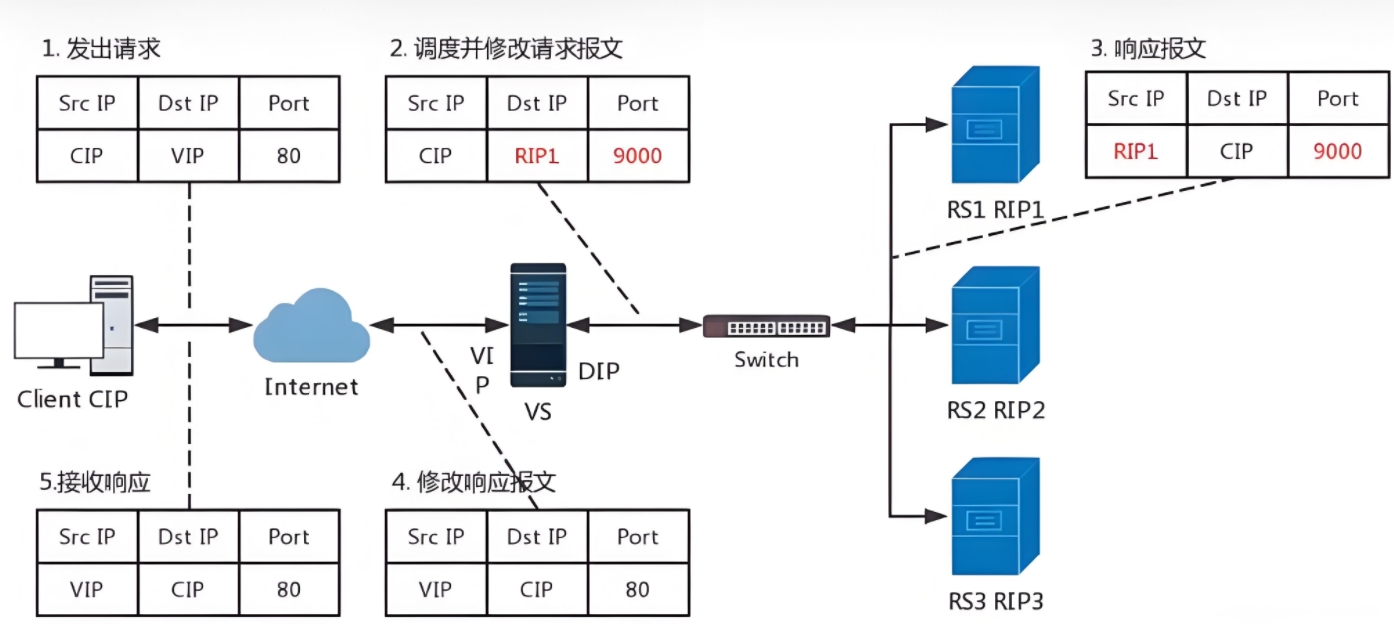 # 访问流程
# 访问流程
- 客户端发送访问请求,请求数据包中含有请求来源(cip),访问目标地址(VIP)访问目标端口 (9000port)
- VS服务器接收到访问请求做DNAT把请求数据包中的目的地由VIP换成RS的RIP和相应端口
- RS1相应请求,发送响应数据包,包中的相应保温为数据来源(RIP1)响应目标(CIP)相应端口 (9000port)
- VS服务器接收到响应数据包,改变包中的数据来源(RIP1-->VIP),响应目标端口(9000-->80)
- VS服务器把修改过报文的响应数据包回传给客户端
- lvs的NAT模式接收和返回客户端数据包时都要经过lvs的调度机,所以lvs的调度机容易阻塞
(2)DR模式
在nat模式下,数据来回传输都要通过调度器,所以当后台服务器超过10台时会导致调度器响应不过来;因此出现dr模式
dr模式下,rs收到请求后不会将数据传回给vs,而是直接传给用户,所以rs和vs上同时有vip
dr模式和nat模式不一样,dr模式走的是第二层,修改mac地址,不能跨网络
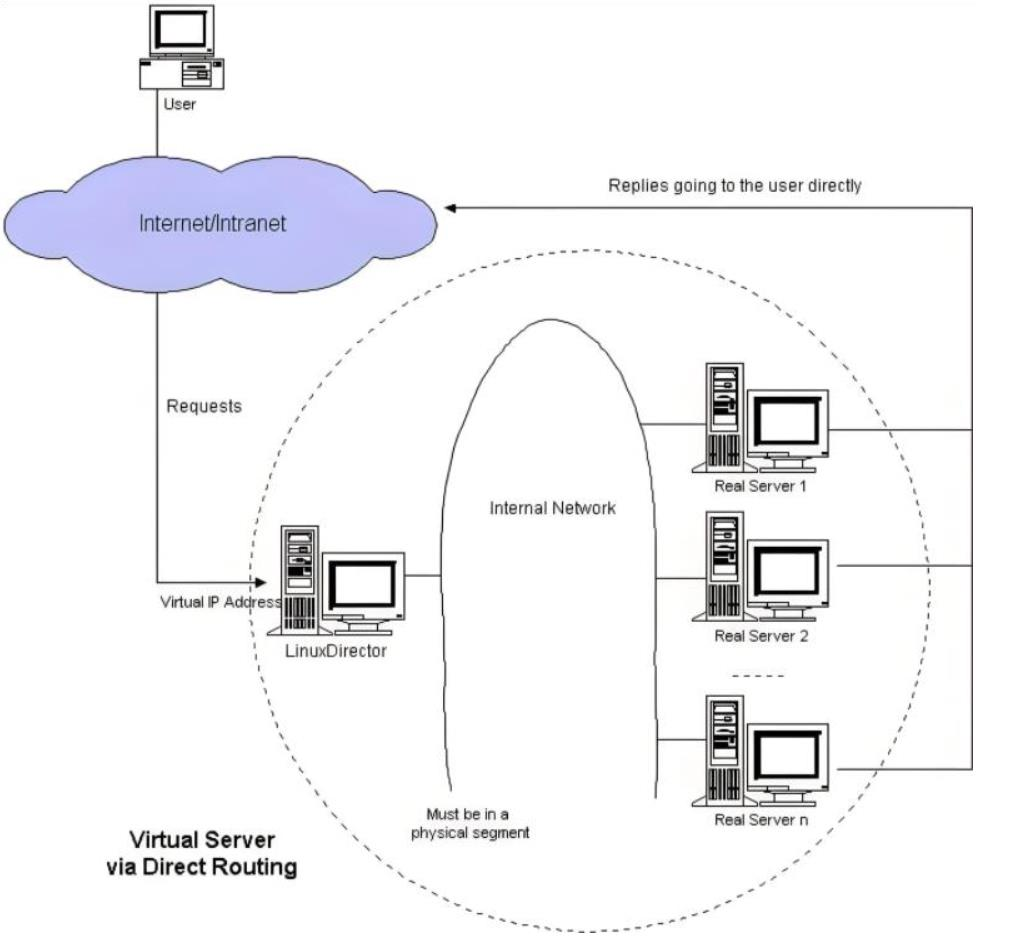
访问流程
- 客户端发送数据帧给vs调度主机帧中内容为客户端IP+客户端的MAC+VIP+VIP的MAC
- VS调度主机接收到数据帧后把帧中的VIP的MAC该为RS1的MAC,此时帧中的数据为客户端IP+客户端 的MAC+VIP+RS1的MAC
- RS1得到2中的数据包做出响应回传数据包,数据包中的内容为VIP+RS1的MAC+客户端IP+客户端IP的 MAC
(3)TUN模式
转发方式:不修改请求报文的IP首部(源IP为CIP,目标IP为VIP),而在原IP报文之外再封装一个IP首部 (源IP是DIP,目标IP是RIP),将报文发往挑选出的目标RS;RS直接响应给客户端(源IP是VIP,目标IP 是CIP)
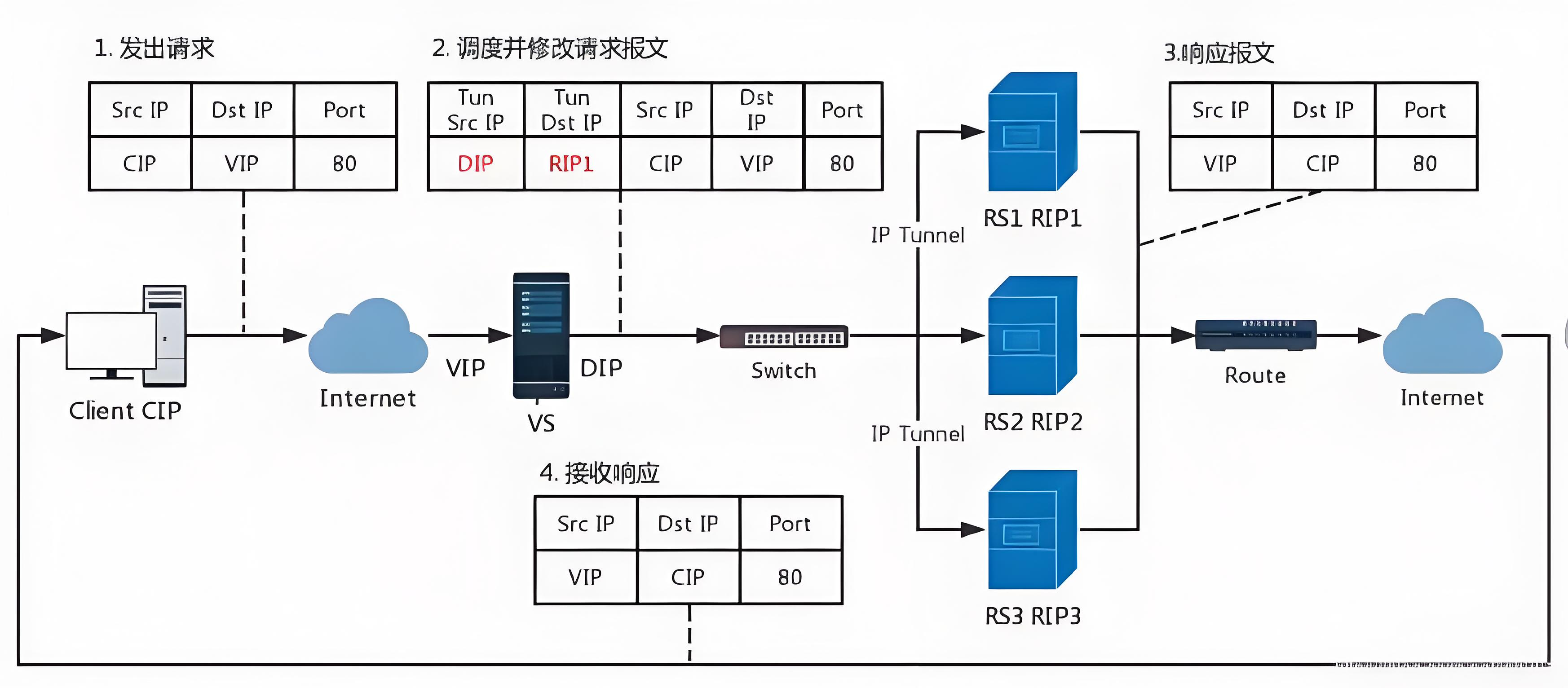
访问流程
- 客户端发送请求数据包,包内有源IP+vip+dport
- 到达vs调度器后对客户端发送过来的数据包重新封装添加IP报文头,新添加的IP报文头中包含 TUNSRCIP(DIP)+TUNDESTIP(RSIP1)并发送到RS1
- RS收到VS调度器发送过来的数据包做出响应,生成的响应报文中包含SRCIP(VIP)+DSTIP(CIP) +port,响应数据包通过网络直接回传给client
特点
- DIP, VIP, RIP都应该是公网地址
- RS的网关一般不能指向DIP
- 请求报文要经由Director,但响应不能经由Director
- 不支持端口映射
- RS的OS须支持隧道功能
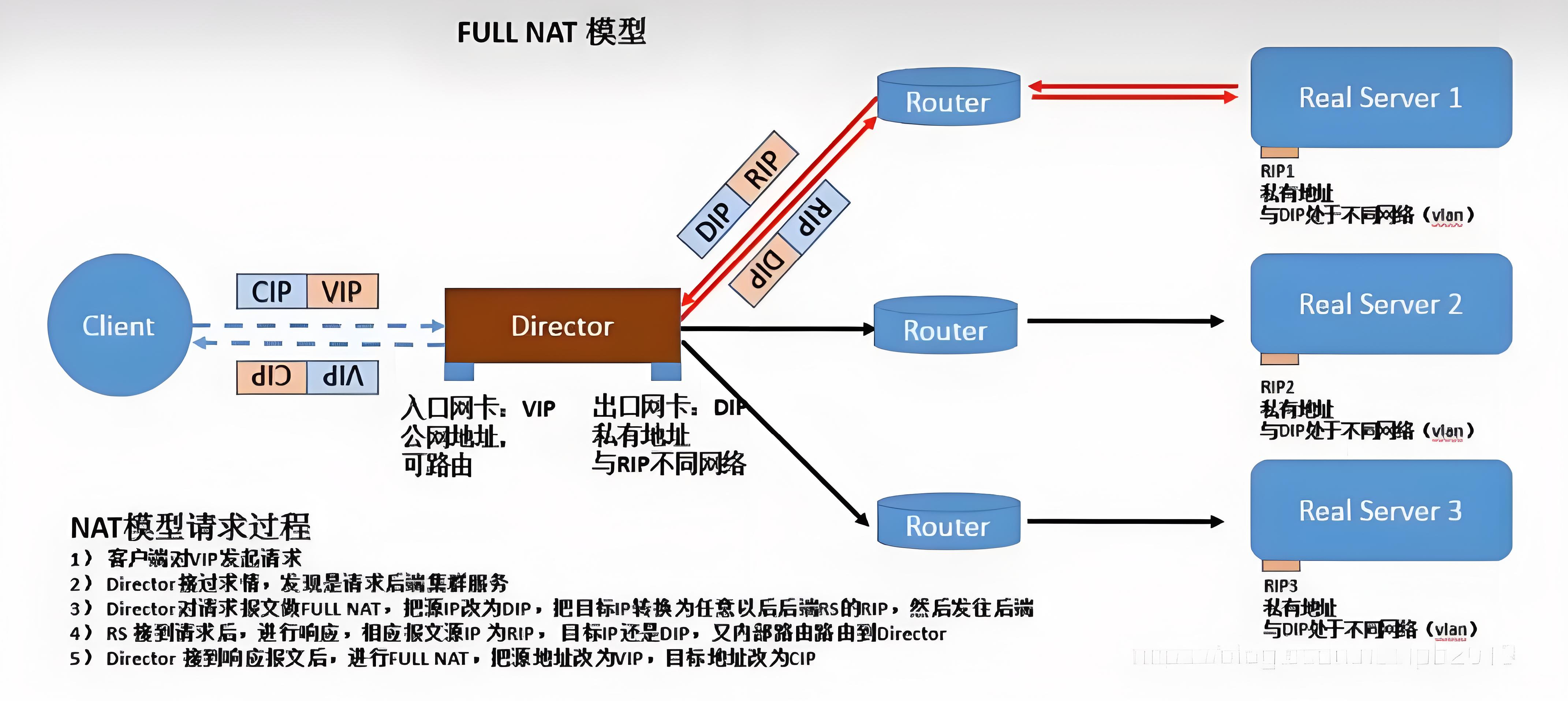
(4)fullnet模式
fullnat:通过同时修改请求报文的源IP地址和目标IP地址进行转发
- CIP --> DIP
- VIP --> RIP
特点
- VIP是公网地址,RIP和DIP是私网地址,且通常不在同一IP网络;因此,RIP的网关一般不会指向DIP
- RS收到的请求报文源地址是DIP,因此,只需响应给DIP;但Director还要将其发往Client
- 请求和响应报文都经由Director
- 支持端口映射
4. LVS调度算法
ipvs scheduler:根据其调度时是否考虑各RS当前的负载状态被分为两种:静态方法和动态方法
静态方法:仅根据算法本身进行调度,不考虑RS的负载情况
动态方法:主要根据每RS当前的负载状态及调度算法进行调度Overhead=value较小的RS将被调度
(1)LVS静态调度算法
- RR:roundrobin 轮询 RS分别被调度,当RS配置有差别时不推荐
- WRR:Weighted RR,加权轮询根据RS的配置进行加权调度,性能差的RS被调度的次数少
- SH:Source Hashing,实现session sticky,源IP地址hash;将来自于同一个IP地址的请求始终发往 第一次挑中的RS,从而实现会话绑定
- DH:Destination Hashing;目标地址哈希,第一次轮询调度至RS,后续将发往同一个目标地址的请 求始终转发至第一次挑中的RS,典型使用场景是正向代理缓存场景中的负载均衡,如:宽带运营商
(2)LVS动态调度算法
- LC:least connections(最少链接发) 适用于长连接应用Overhead(负载值)=activeconns(活动链接数) x 256+inactiveconns(非活 动链接数)
- WLC:Weighted LC(权重最少链接) 默认调度方法Overhead=(activeconns x 256+inactiveconns)/weight
- SED:Shortest Expection Delay, 初始连接高权重优先Overhead=(activeconns+1+inactiveconns) x 256/weight 但是,当node1的权重为1,node2的权重为10,经过运算前几次的调度都会被node2承接
- NQ:Never Queue,第一轮均匀分配,后续SED
- LBLC:Locality-Based LC,动态的DH算法,使用场景:根据负载状态实现正向代理
- LBLCR:LBLC with Replication,带复制功能的LBLC,解决LBLC负载不均衡问题,从负载重的复制 到负载轻的RS
(3)在4.15版本内核以后新增调度算法
FO(Weighted Fai Over)调度算法
- 常用作灰度发布
- 在此FO算法中,遍历虚拟服务所关联的真实服务器链表,找到还未过载(未设置IP_VS_DEST_F OVERLOAD标志)的且权重最高的真实服务器,进行调度
- 当服务器承接大量链接,我们可以对此服务器进行过载标记(IP_VS_DEST_F OVERLOAD),那么vs调度 器就不会把链接调度到有过载标记的主机中。
OVF(Overflow-connection)调度算法
- 基于真实服务器的活动连接数量和权重值实现。
- 将新连接调度到权重值最高的真实服务器,直到其活动 连接数量超过权重值,之后调度到下一个权重值最高的真实服务器,在此OVF算法中,遍历虚拟服务相关 联的真实服务器链表,找到权重值最高的可用真实服务器。
- 一个可用的真实服务器需要同时满足以下条 件: 未过载(未设置IP_VS_DEST_F OVERLOAD标志) 、真实服务器当前的活动连接数量小于其权重值、其权重值不为零
三、NAT实验
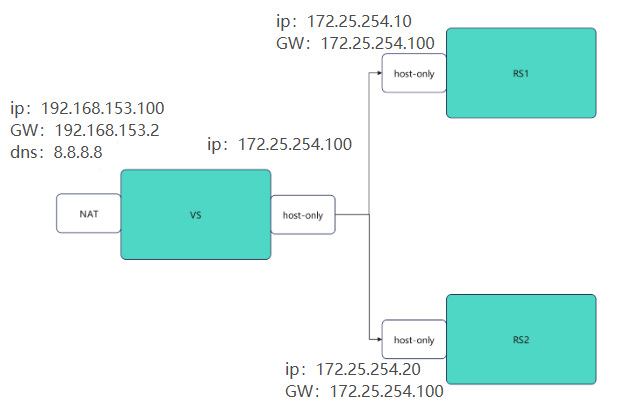
1.NAT的实验环境
实验幻境至少需要3台主机,一台调度器(vsnode),两台真实服务器(rs1和rs2)
vsnode有两张网卡------NAT和仅主机模式的网卡
rs1和rs2都是仅主机模式的网卡
配置vsnode环境
[root@vsnode ~]# ip.sh eth0 192.168.153.100 vsnode
[root@vsnode ~]# ip.sh eth1 172.25.254.100 vsnode noroute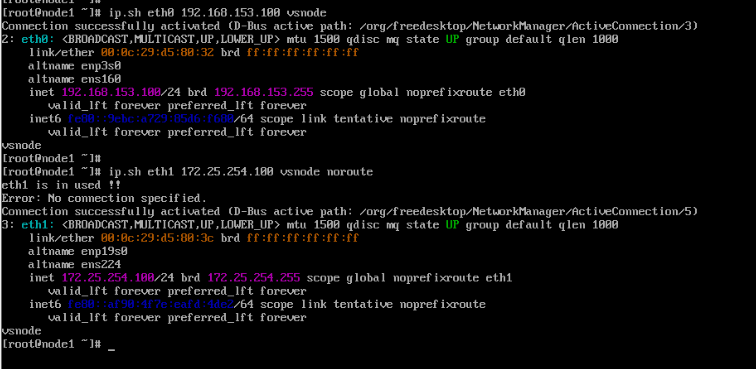
配置rs1环境
[root@rs1 ~]# ip.sh eth0 172.25.254.10 rs1 noroute
[root@rs1 ~]# nmcli connection modify eth0 ipv4.gateway 172.25.254.100
[root@rs1 ~]# nmcli connection reload
[root@rs1 ~]# nmcli connection up eth0
[root@rs1 ~]# cat /etc/NetworkManager/system-connections/eth0.nmconnection
[root@rs1 ~]# route -n
[root@rs1 ~]# dnf install httpd -y
[root@rs1 ~]# systemctl enable --now httpd
[root@rs1 ~]# echo rs1 - 172.25.254.10 > /var/www/html/index.html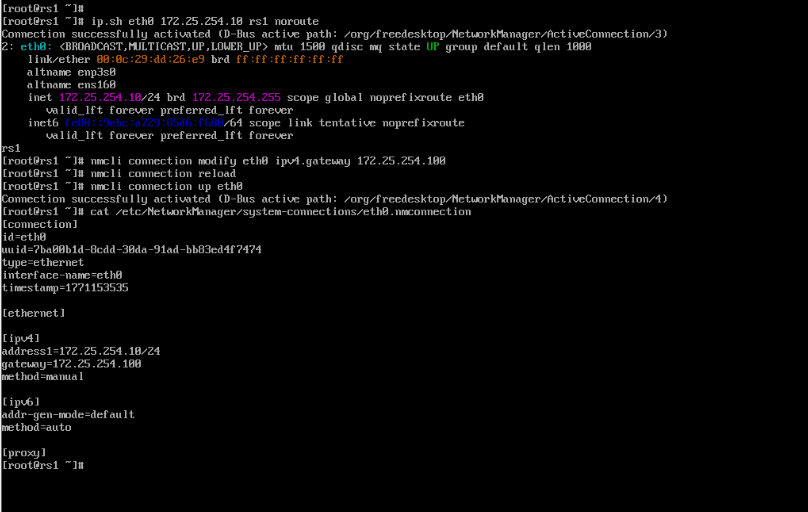
配置rs2环境
[root@rs2 ~]# ip.sh eth0 172.25.254.20 rs2 noroute
[root@rs2 ~]# nmcli connection modify eth0 ipv4.gateway 172.25.254.100
[root@rs2 ~]# nmcli connection reload
[root@rs2 ~]# nmcli connection up eth0
[root@rs2 ~]# cat /etc/NetworkManager/system-connections/eth0.nmconnection
[root@rs2 ~]# route -n
[root@rs2 ~]# dnf install httpd -y
[root@rs2 ~]# systemctl enable --now httpd
[root@rs2 ~]# echo rs2 - 172.25.254.20 > /var/www/html/index.html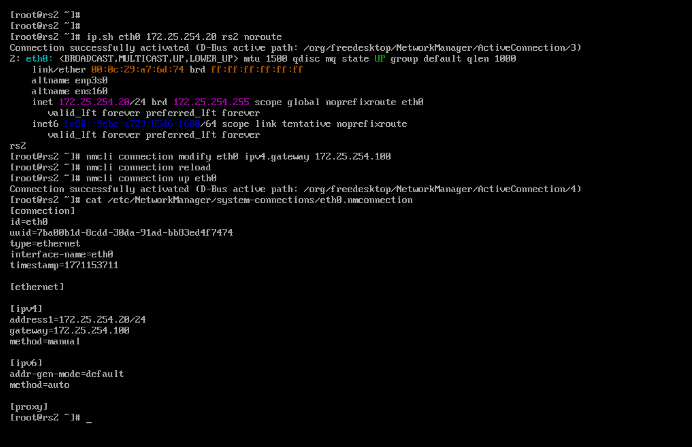
在vsnode上测试网络
[root@vsnode ~]# curl 172.25.254.10
rs1 - 172.25.254.10
[root@vsnode ~]# curl 172.25.254.20
rs2 - 172.25.254.202. NAT模式实现
(1)添加策略
在vsnode做配置,开启内核路由功能,编写策略
[root@vsnode ~]# echo net.ipv4.ip_forward=1 >> /etc/sysctl.conf
[root@vsnode ~]# sysctl -p
[root@vsnode ~]# dnf install ipvsadm-1.31-6.el9.x86_64 -y
[root@vsnode ~]# ipvsadm -C
[root@vsnode ~]# ipvsadm -A -t 192.168.153.100:80 -s wrr
[root@vsnode ~]# ipvsadm -a -t 192.168.153.100:80 -r 172.25.254.10:80 -m -w 1
[root@vsnode ~]# ipvsadm -a -t 192.168.153.100:80 -r 172.25.254.20:80 -m -w 1
[root@vsnode ~]# ipvsadm -Ln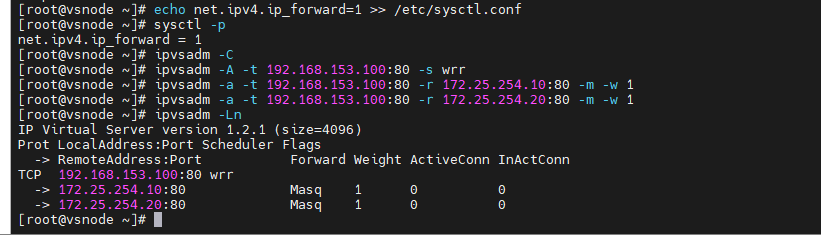
测试
[root@vsnode ~]# for i in {1..10};do curl 192.168.153.100;done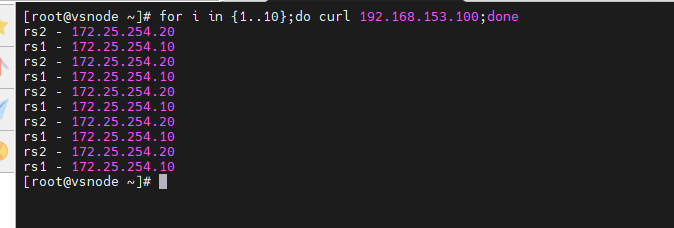
(2)更改权重
更改rs1的权重为3,rs2的权重不变为1,则访问时访问rs1 3次,访问rs2 1次
[root@vsnode ~]# ipvsadm -e -t 192.168.153.100:80 -r 172.25.254.10:80 -m -w 3
[root@vsnode ~]# ipvsadm -Ln
[root@vsnode ~]# for i in {1..10};do curl 192.168.153.100;done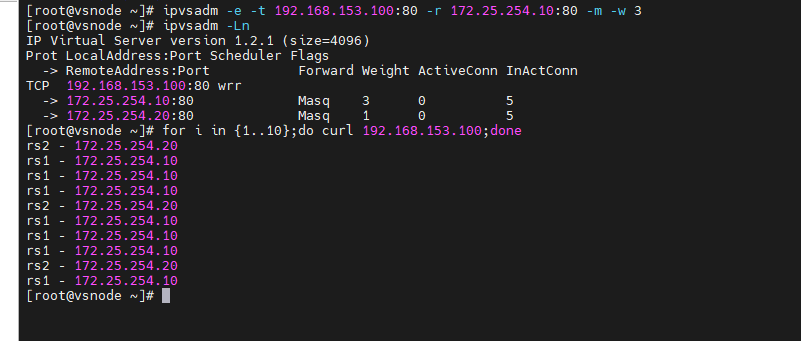
3. 规则持久化
(1)自定义文件持久化
用"ipvsadm-save -n"(-n不做解析)查看IPVS规则,将显示的信息覆盖到这个新建的文件ipvsadm.rule里;在清空规则进行测试
[root@vsnode ~]# ipvsadm-save -n
[root@vsnode ~]# ipvsadm-save -n > /mnt/ipvsadm.rule
[root@vsnode ~]# ipvsadm -C
[root@vsnode ~]# ipvsadm -Ln
[root@vsnode ~]# ipvsadm-restore < /mnt/ipvsadm.rule
[root@vsnode ~]# ipvsadm -Ln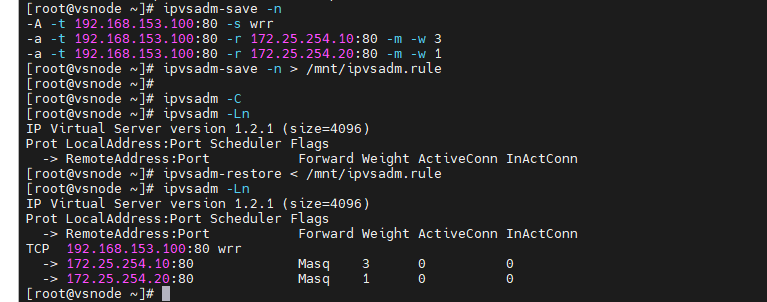
(2)守护进程持久化
在使用自定义文件持久化时,当系统重启后,IPVS规则会自动消失,需要手动恢复规则"ipvsadm-restore < /mnt/ipvsadm.rule"
可以利用守护进程让系统开机时自动读取文件"/etc/sysconfig/ipvsadm"获取规则
[root@vsnode ~]# systemctl restart ipvsadm.service
[root@vsnode ~]# systemctl status ipvsadm.service
[root@vsnode ~]# ipvsadm-save -n > /etc/sysconfig/ipvsadm
[root@vsnode ~]# ipvsadm -Ln
[root@vsnode ~]# ipvsadm -C
[root@vsnode ~]# ipvsadm -Ln
[root@vsnode ~]# systemctl enable --now ipvsadm.service
[root@vsnode ~]# ipvsadm -Ln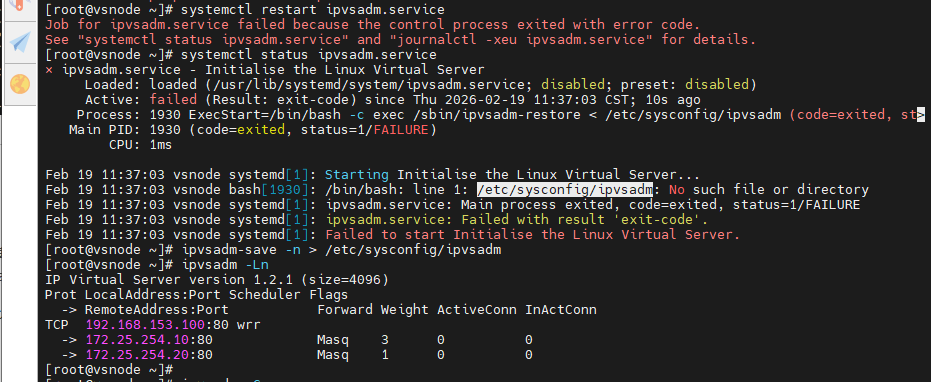
四、DR实验
1. DR的实验环境
实验环境至少需要5台主机,一台客户端(NAT),一台路由器(NAT+仅主机),一台调度器(仅主机),两台真实服务器(rs1和rs2;仅主机)
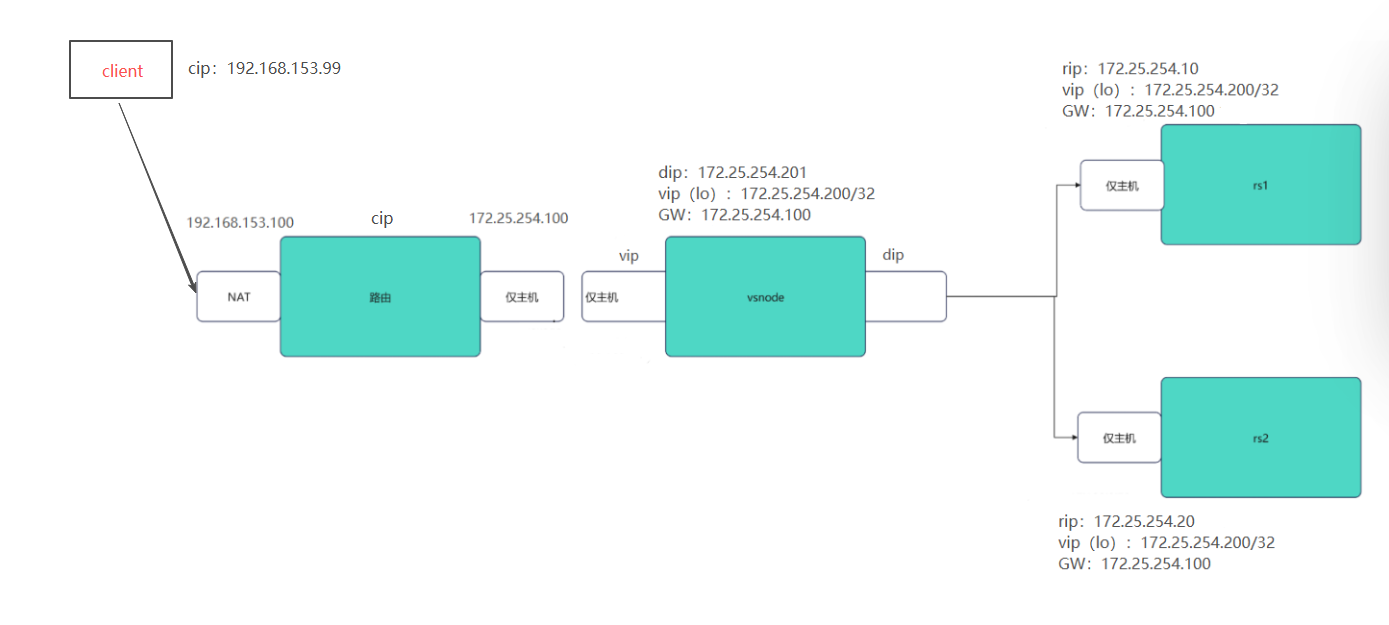
(1)配置客户端环境
配置IP地址,网关配置路由器ip
[root@client ~]# ip.sh eth0 192.168.153.99 client
[root@client ~]# nmcli connection modify eth0 ipv4.gateway 192.168.153.100
[root@client ~]# nmcli connection reload
[root@client ~]# nmcli connection up eth0
[root@client ~]# cat /etc/NetworkManager/system-connections/eth0.nmconnection
[root@client ~]# route -n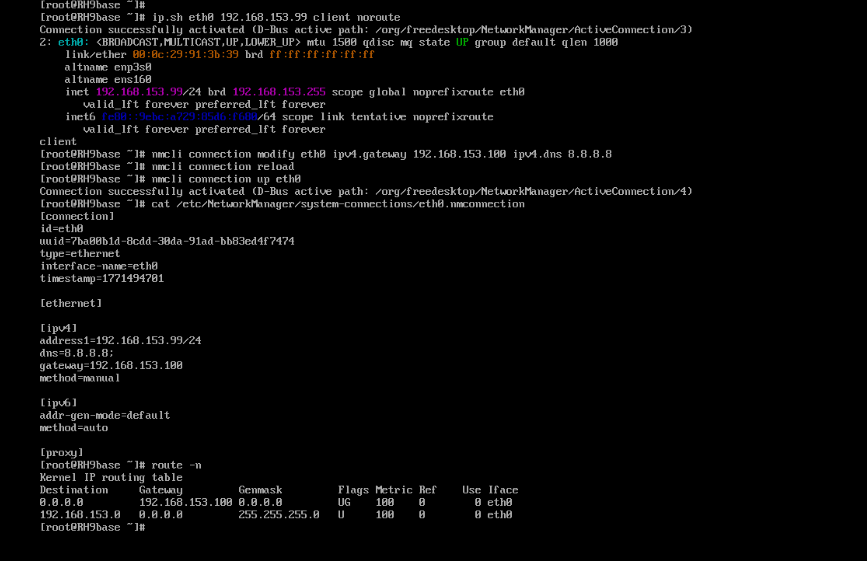
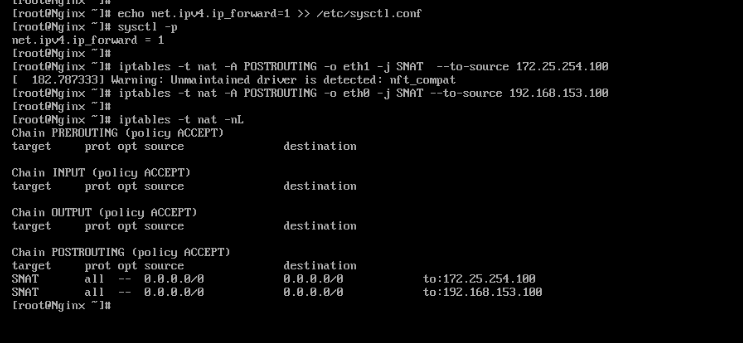
(2)配置路由器环境
配置IP地址,开启内核路由功能,添加数据转发策略
[root@router ~]# ip.sh eth0 192.168.153.100 router
[root@router ~]# ip.sh eth1 172.25.254.100 router noroute
[root@router ~]# echo net.ipv4.ip_forward=1 >> /etc/sysctl.conf
[root@router ~]# sysctl -p
[root@router ~]# iptables -t nat -A POSTROUTING -o eth1 -j SNAT --to-source 172.25.254.100
[root@router ~]# iptables -t nat -A POSTROUTING -o eth0 -j SNAT --to-source 192.168.153.100
[root@router ~]# iptables -t nat -nL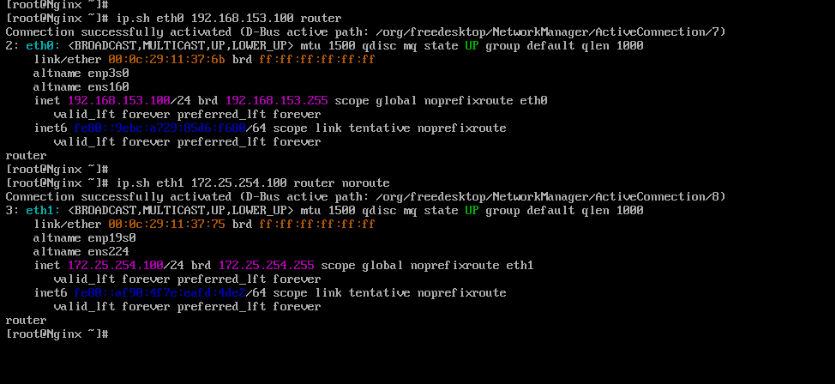
(3)配置调度器环境
配置IP地址,添加网关和vip环回口
[root@vsnode ~]# ip.sh eth0 172.25.254.201 vsnode noroute
[root@vsnode ~]# nmcli connection modify eth0 ipv4.gateway 172.25.254.100
[root@vsnode ~]# nmcli connection modify lo +ipv4.addresses 172.252.54.200/32
[root@vsnode ~]# nmcli connection reload
[root@vsnode ~]# nmcli connection up eth0
[root@vsnode ~]# nmcli connection up lo
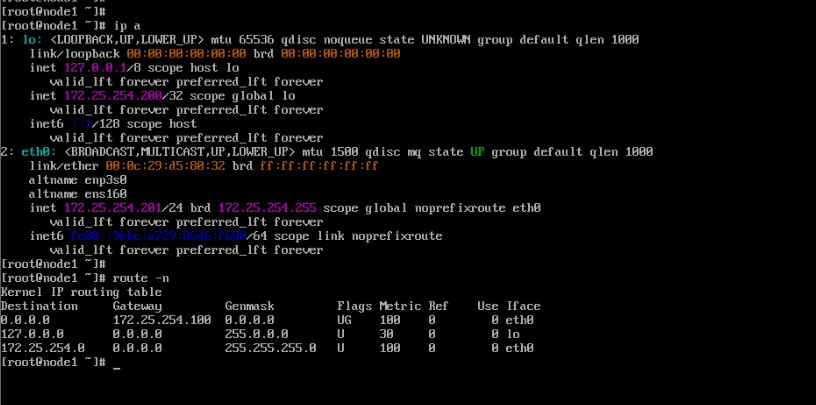
[root@vsnode ~]# ip a
[root@vsnode ~]# route -n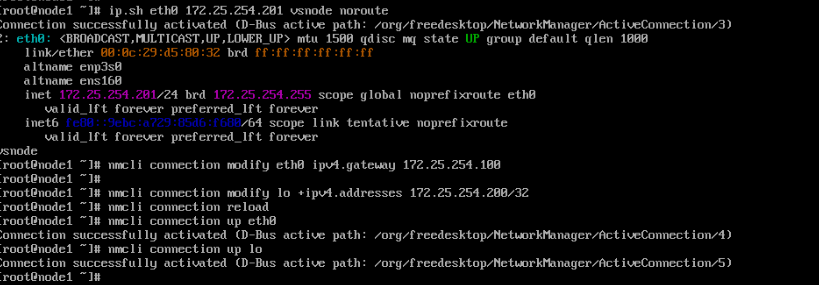
(4)配置rs1环境
配置IP地址,添加网关和vip环回,并添加arp禁止响应
限制响应级别:arp_ignore
- 0:默认值,接收并回复
- 1:接收但不回复
限制通告级别:arp_announce
-
0:默认值,接收并回复
-
1:不接收
-
2:接受但不回复
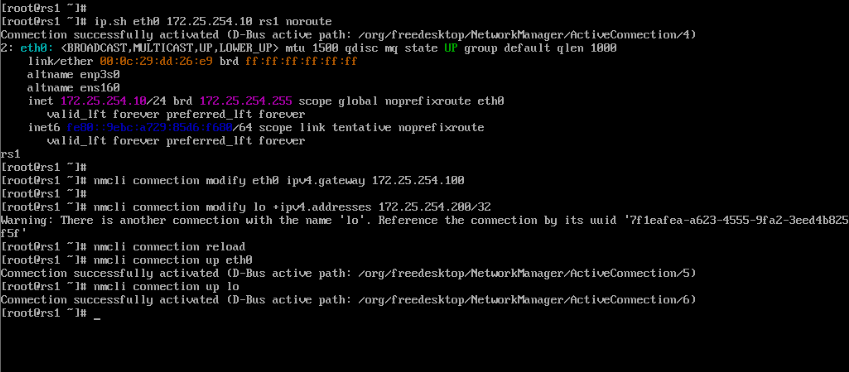
[root@rs1 ~]# ip.sh eth0 172.25.254.10 rs1 noroute
[root@rs1 ~]# nmcli connection modify eth0 ipv4.gateway 172.25.254.100
[root@rs1 ~]# nmcli connection modify lo +ipv4.addresses 172.25.254.200/32
[root@rs1 ~]# nmcli connection reload
[root@rs1 ~]# nmcli connection up eth0
[root@rs1 ~]# nmcli connection up lo
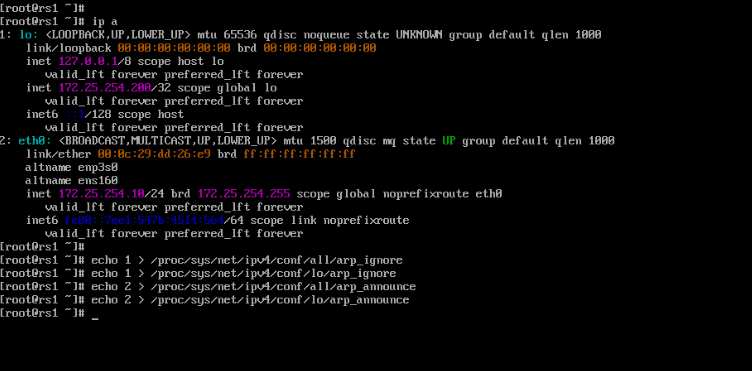
[root@rs1 ~]# ip a
[root@rs1 ~]# echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
[root@rs1 ~]# echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
[root@rs1 ~]# echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
[root@rs1 ~]# echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
(5)配置rs2环境
模仿rs1,配置IP地址,添加网关和vip环回,并添加arp禁止响应
[root@rs2 ~]# ip.sh eth0 172.25.254.20 rs2 noroute
[root@rs2 ~]# nmcli connection modify eth0 ipv4.gateway 172.25.254.100
[root@rs2 ~]# nmcli connection modify lo +ipv4.addresses 172.25.254.200/32
[root@rs2 ~]# nmcli connection reload
[root@rs2 ~]# nmcli connection up eth0
[root@rs2 ~]# nmcli connection up lo
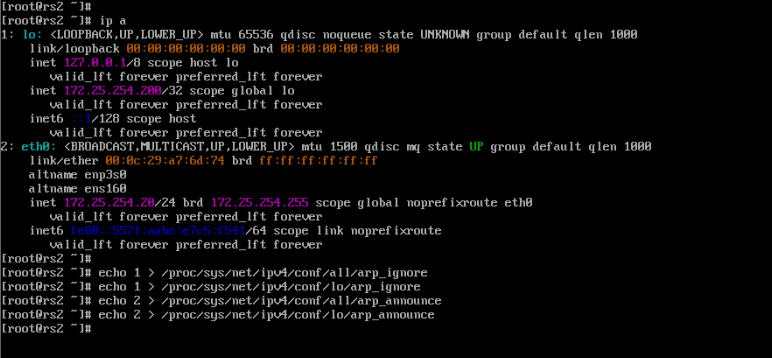
[root@rs2 ~]# ip a
[root@rs2 ~]# echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
[root@rs2 ~]# echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
[root@rs2 ~]# echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
[root@rs2 ~]# echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce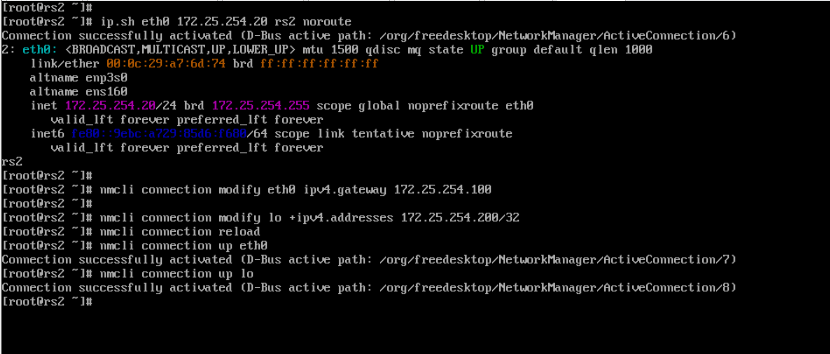
(6)测试环境
测试全网可通
[root@client ~]# ping 172.25.254.10
[root@client ~]# ping 172.25.254.20
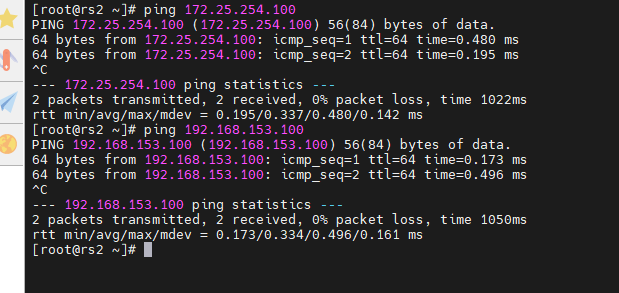
[root@rs2 ~]# ping 172.25.254.100
[root@rs2 ~]# ping 192.168.153.100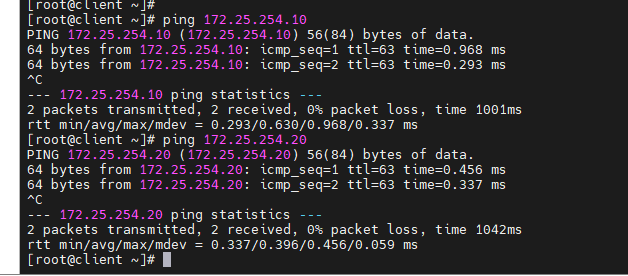
2. DR模式实现
添加轮询算法(rr)
因为dr模式走的是第二层(修改mac地址),指定rs的算法时不能跨端口
[root@vsnode ~]# dnf install ipvsadm-1.31-6.el9.x86_64 -y
[root@vsnode ~]# ipvsadm -C
[root@vsnode ~]# ipvsadm -A -t 172.25.254.200:80 -s rr
[root@vsnode ~]# ipvsadm -a -t 172.25.254.200:80 -r 172.25.254.10:80 -g -w 1
[root@vsnode ~]# ipvsadm -a -t 172.25.254.200:80 -r 172.25.254.20:80 -g -w 1
[root@vsnode ~]# ipvsadm-save -n
[root@vsnode ~]# ipvsadm-save -n > /etc/sysconfig/ipvsadm
[root@vsnode ~]# systemctl restart ipvsadm.service配置apache服务进行测试
最后实现的效果和nat模式大差不差,是因为用的算法类似;但是dr模式最后结果即数据是由rs真实服务器提供的,而nat模式的数据是由vs调度器提供的
[root@rs1 ~]# dnf install httpd -y
[root@rs1 ~]# echo rs1 - 172.25.254.10 > /var/www/html/index.html
[root@rs1 ~]# systemctl restart httpd.service
[root@rs2 ~]# dnf install httpd -y
[root@rs2 ~]# echo rs2 - 172.25.254.20 > /var/www/html/index.html
[root@rs2 ~]# systemctl restart httpd.service
[root@client ~]# for i in {1..10};do curl 172.25.254.200;done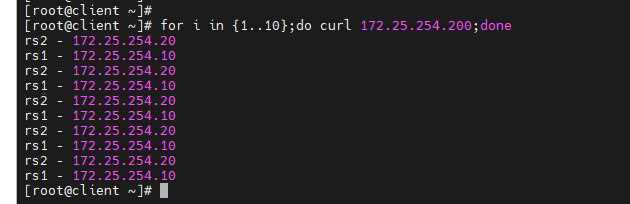
五、LVS实战问题
1. 防火墙标签解决轮询错误
(1)在rs主机中同时开启http和https两种协议
[root@rs1 ~]# dnf install mod_ssl -y
[root@rs1 ~]# systemctl restart httpd
[root@rs2 ~]# dnf install mod_ssl -y
[root@rs2 ~]# systemctl restart httpd(2)在vsnode主机中添加http和https的轮询策略
添加轮询策略
[root@vsnode ~]# ipvsadm -C
[root@vsnode ~]# ipvsadm -A -t 172.25.254.200:80 -s rr
[root@vsnode ~]# ipvsadm -a -t 172.25.254.200:80 -r 172.25.254.10:80 -g
[root@vsnode ~]# ipvsadm -a -t 172.25.254.200:80 -r 172.25.254.20:80 -g
[root@vsnode ~]# ipvsadm -A -t 172.25.254.200:443 -s rr
[root@vsnode ~]# ipvsadm -a -t 172.25.254.200:443 -r 172.25.254.10:443 -g
[root@vsnode ~]# ipvsadm -a -t 172.25.254.200:443 -r 172.25.254.20:443 -g
[root@vsnode ~]# ipvsadm -Ln测试
root@client \~# curl 172.25.254.200;curl -k https://172.25.254.200
rs2 - 172.25.254.20
rs2 - 172.25.254.20
当编写完轮询策略后,http和https(以及多端口)是独立的service,轮询就会出现重复问题
(3)解决轮询错误
利用防火墙标记访问vip的80和443的所有数据包,设定标记为6666,然后再对标记进行负载
"-t mangle"------指定mangle表,"-m multiport"------多端口,"-j MARK --set-mark 6666"------打标签为6666;"-f 6666"------按防火墙标记6666来添加轮询策略
[root@vsnode ~]# iptables -t mangle -A PREROUTING -d 172.25.254.200 -p tcp -m multiport --dports 80,443 -j MARK --set-mark 6666
[root@vsnode ~]# ipvsadm -C
[root@vsnode ~]# ipvsadm -A -f 6666 -s rr
[root@vsnode ~]# ipvsadm -a -f 6666 -r 172.25.254.10 -g
[root@vsnode ~]# ipvsadm -a -f 6666 -r 172.25.254.20 -g
[root@vsnode ~]# ipvsadm -Ln再次测试
[root@client ~]# curl 172.25.254.200;curl -k https://172.25.254.200
rs2 - 172.25.254.20
rs1 - 172.25.254.10### 设置开机自动加载
主机重启时iptables和ipvsadm的规则就会消失,需要重新配置,所以我们可以保存好规则
[root@vsnode ~]# iptables-save
[root@vsnode ~]# iptables-save > /etc/sysconfig/iptables
[root@vsnode ~]# ipvsadm-save -n
[root@vsnode ~]# ipvsadm-save -n > /etc/sysconfig/ipvsadm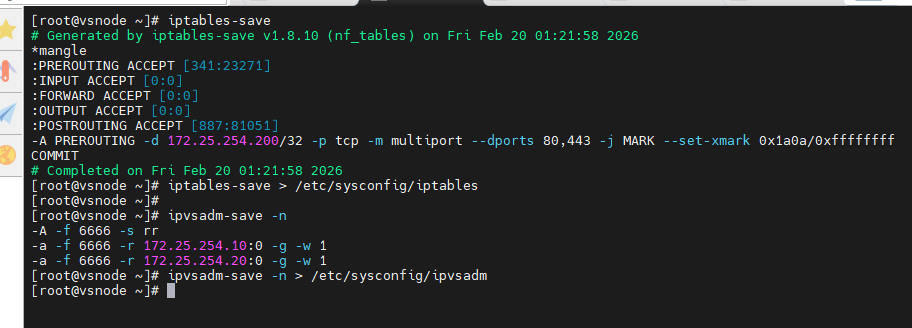
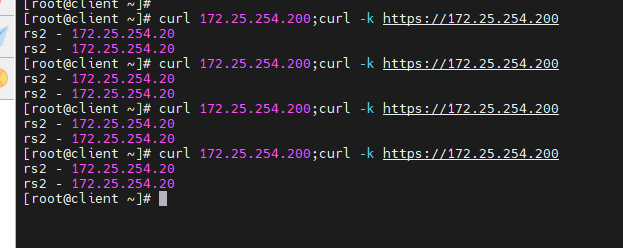
2. 持久化链接实现会话粘滞
在我们客户上网过程中有很多情况下需要和服务器进行交互,客户需要提交响应信息给服务器,如果单纯的进行调度会导致客户填写的表单丢失,为了解决这个问题我们可以用sh算法,但是sh算法比较简单粗暴,可能会导致调度失衡
解决方案
-
在进行调度时,不管用什么算法,只要相同源过来的数据包我们就把他的访问记录在内存中,也就是把 这个源的主机调度到了那个RS上
-
如果在短期(默认360S)内同源再来访问我仍然按照内存中记录的调度信息,把这个源的访问还调度到 同一台RS上。
-
如果过了比较长的时间(默认最长时间360s)同源访问再次来访,那么就会被调度到其他的RS上
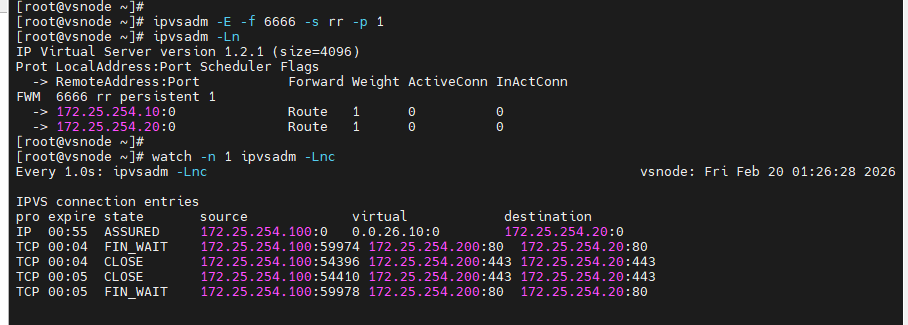
[root@vsnode ~]# ipvsadm -E -f 6666 -s rr -p 1
[root@vsnode ~]# ipvsadm -Ln
[root@vsnode ~]# watch -n 1 ipvsadm -Lnc[root@client ~]# curl 172.25.254.200;curl -k https://172.25.254.200