- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
前言
-
实验环境
python 3.9.2
tensorflow 2.10.0
Jupyter Notebook: 7.4.5
代码实现
设置gpu
python
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")导入数据
python
import pathlib
# 导入数据
data_dir = "./data/"
data_dir = pathlib.Path(data_dir)查看数据
python
# 查看数据集图片数量
image_count = len(list(data_dir.glob('*/*.png')))
print("图片总数为:", image_count)
数据加载
python
from tensorflow import keras
# 基本参数设置
batch_size = 16 # 由于显存不足,这里使用16
img_height = 224
img_width = 224
# 数据加载
# 加载数据集,自动完成:调整尺寸、打乱数据、划分验证集
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
python
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
输出标签
python
class_names = train_ds.class_names
print(class_names)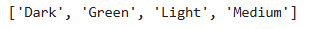
数据可视化
python
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 4)) # 图形的宽为10高为5
for images, labels in train_ds.take(1):
for i in range(10):
ax = plt.subplot(2, 5, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
再次检查数据
python
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break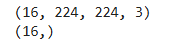
优化数据加载效率
python
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)数据归一化
python
from tensorflow.keras import layers
normalization_layer = layers.experimental.preprocessing.Rescaling(1./255)
train_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
val_ds = val_ds.map(lambda x, y: (normalization_layer(x), y))train_ds和val_ds是tf.data.Dataset对象,每个元素是(image, label)。.map(lambda x, y: (normalization_layer(x), y))表示:对数据集中的每一张图像 x 应用归一化,标签 y 保持不变。
python
import numpy as np
# 验证归一化
image_batch, labels_batch = next(iter(val_ds))
first_image = image_batch[0]
# 查看归一化后的数据
print(np.min(first_image), np.max(first_image))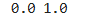
构建模型
- 各层的作用:
- 输入层 (
Input(shape=(img_width, img_height, 3))):- 作用:定义模型的输入张量形状。
- 原理说明:接收 RGB 彩色图像,尺寸为
(img_height, img_width, 3)( 224×224×3),作为整个卷积网络的起点。
- 第1卷积块(block1):
- 卷积层 1 (
Conv2D(64, (3,3), activation='relu', padding='same', name='block1_conv1')):- 作用:提取图像中最基础的局部视觉特征,如边缘、角点和简单纹理。
- 参数解析:
64:使用 64 个 3×3 卷积核,输出 64 通道的特征图;padding='same':保持特征图空间尺寸不变;ReLU激活引入非线性,缓解梯度消失。
- 卷积层 2 (
Conv2D(64, (3,3), activation='relu', padding='same', name='block1_conv2')):- 作用:在第一层特征基础上进一步组合,增强对局部结构的感知能力。
- 特点:通道数保持 64,形成"双卷积"结构,是 VGG 系列标志性设计。
- 池化层 (
MaxPooling2D((2,2), strides=(2,2), name='block1_pool')):- 作用:对特征图进行 2 倍下采样,降低空间分辨率( 224→112),减少后续计算量。
- 工作方式:取每个 2×2 区域的最大值,保留最显著响应。
- 卷积层 1 (
- 第2卷积块(block2):
- 卷积层 1 & 2 (
Conv2D(128, (3,3), ...)):- 作用:学习更复杂的中级语义特征,如纹理组合、局部形状或重复图案。
- 参数变化:通道数翻倍至 128,提升特征表达维度。
- 池化层 (
MaxPooling2D, name='block2_pool'):- 作用:再次 2 倍下采样( 112→56),聚焦更高层次结构信息。
- 卷积层 1 & 2 (
- 第3卷积块(block3):
- 三层卷积 (
Conv2D(256, (3,3), ...)):- 作用:构建更丰富的特征表示,开始捕捉具有类别判别性的局部对象部件(如眼睛、轮子、叶片等)。
- 池化层 (
MaxPooling2D, name='block3_pool'):- 作用:空间维度继续减半( 56→28),压缩冗余信息。
- 三层卷积 (
- 第4卷积块(block4):
- 三层卷积 (
Conv2D(512, (3,3), ...)):- 作用:提取高级语义特征,如整体部件组合、场景上下文或类别专属模式。
- 通道数增至 512,特征图高度抽象,具备强判别性。
- 池化层 (
MaxPooling2D, name='block4_pool'):- 作用:下采样至约 14×14,为最后的语义聚合做准备。
- 三层卷积 (
- 第5卷积块(block5):
- 三层卷积 (
Conv2D(512, (3,3), ...)):- 作用:进一步精炼高层语义,捕捉细微但关键的类别差异(如不同犬种的耳朵形状、车型细节等)。
- 与 block4 相同通道数,强调深度而非宽度。
- 池化层 (
MaxPooling2D, name='block5_pool'):- 作用:最终空间下采样( 14→7),输出尺寸极小但语义密集的特征图(7×7×512)。
- 三层卷积 (
- 全连接分类层:
- Flatten 层 (
Flatten()):- 作用:将 7×7×512 的三维特征张量展平为一维向量(长度 = 7×7×512 = 25,088),供全连接层处理。
- 全连接层 1 (
Dense(4096, activation='relu', name='fc1')):- 作用:对全局特征进行高维非线性融合,实现从局部特征到整体语义的映射。
- 全连接层 2 (
Dense(4096, activation='relu', name='fc2')):- 作用:进一步抽象和压缩特征表示,增强模型判别边界。
- 输出层 (
Dense(nb_classes, activation='softmax', name='predictions')):- 作用:生成每个类别的预测概率分布。
- 结构说明:
- 输出维度等于类别数
nb_classes; softmax激活确保输出为归一化概率(总和为 1);- 最终预测结果通过
argmax获得最高概率类别。
- 输出维度等于类别数
- Flatten 层 (
- 输入层 (
python
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout
def VGG16(nb_classes, input_shape):
input_tensor = Input(shape=input_shape)
# 第1卷积块
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv1')(input_tensor)
x = Conv2D(64, (3,3), activation='relu', padding='same',name='block1_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block1_pool')(x)
# 第2卷积块
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv1')(x)
x = Conv2D(128, (3,3), activation='relu', padding='same',name='block2_conv2')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block2_pool')(x)
# 第3卷积块
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv1')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv2')(x)
x = Conv2D(256, (3,3), activation='relu', padding='same',name='block3_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block3_pool')(x)
# 第4卷积块
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block4_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block4_pool')(x)
# 第5卷积块
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv1')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv2')(x)
x = Conv2D(512, (3,3), activation='relu', padding='same',name='block5_conv3')(x)
x = MaxPooling2D((2,2), strides=(2,2), name = 'block5_pool')(x)
# 全连接分类层
x = Flatten()(x)
x = Dense(4096, activation='relu', name='fc1')(x)
x = Dense(4096, activation='relu', name='fc2')(x)
output_tensor = Dense(nb_classes, activation='softmax', name='predictions')(x)
model = Model(input_tensor, output_tensor)
return model
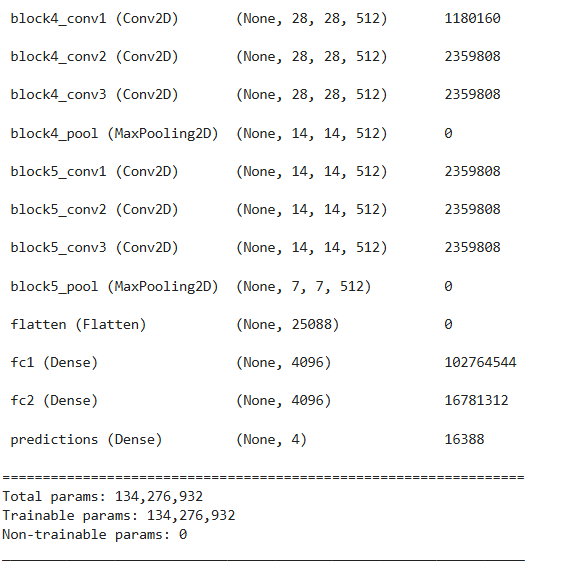
model=VGG16(len(class_names), (img_width, img_height, 3))
model.summary()
编译模型
python
# 设置初始学习率
initial_learning_rate = 1e-4
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=30,
decay_rate=0.92,
staircase=True)
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=initial_learning_rate)
model.compile(optimizer=opt,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['accuracy'])训练模型
python
epochs = 20
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)

模型评估
python
from datetime import datetime
current_time = datetime.now() # 获取当前时间
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time)
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()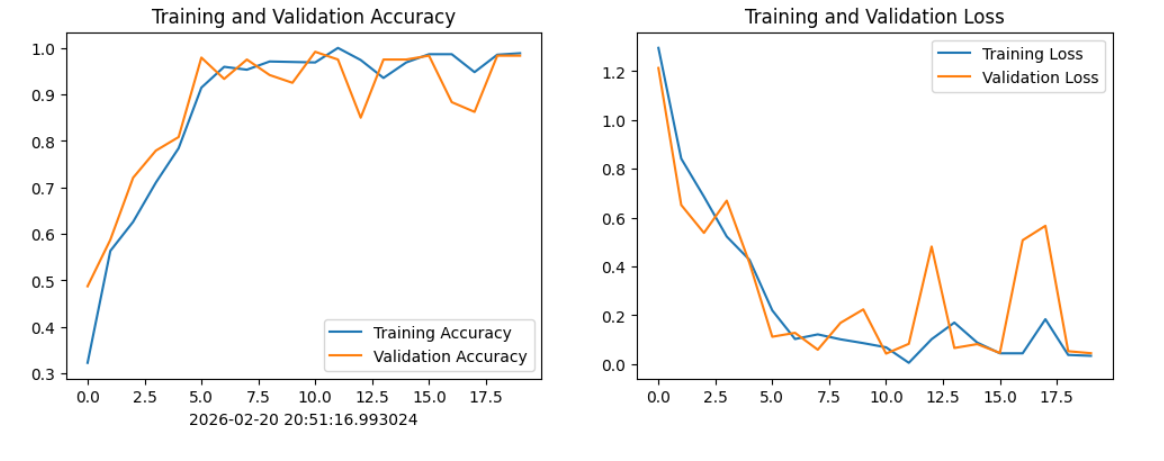
学习总结
-
这次参照指导文档写了一个 VGG-16 模型,开始去思考它的设计目的,比如它全用 3×3 的小卷积核,看起来好像很普通,但其实是有道理的:两个 3×3 卷积叠在一起,感受野就跟一个 5×5 差不多,三个就相当于 7×7,但参数却少很多,而且每层后面都加了 ReLU 激活,非线性更强,模型就更容易学到复杂的特征。
-
另外,VGG-16 的结构特别整齐:先是两层卷积 + 一次池化,再两层(后面变成三层)卷积 + 池化,一路下去,通道数从 64 翻倍到 128、256、512,而图片尺寸却越缩越小(224 → 112 → 56 ... → 7)。这种"越往后,图越小,但信息越浓"的方式,其实就是在模拟人看东西的过程------先看边缘、颜色这些基础东西,再慢慢组合成眼睛、轮子、叶子这种局部部件,最后认出整个物体是什么。最后那两个超大的全连接层(4096 维),就像大脑在做最终判断,把所有看到的细节综合起来投票分类。
-
不过自己跑起来也发现了问题,这模型真的重,光是全连接层就占了绝大部分参数,我 batch size 只敢设 16,不然显存直接爆掉。而且训练时明显过拟合------训练准确率很快就冲的很高,但验证集上忽高忽低,有时候突然掉到 85%,说明它把训练图片"背下来了",而不是真正学会了泛化。