原文发表在知乎,格式可能会更规正一些,可以参考《强化学习Q-chunking算法 》
算法简介
Q-chuking算法:
关于Q-chunking算法,可参考下面两篇文章:
打破单步魔咒:"动作分块"如何革新强化学习,高效解决长时程稀SSE奖励难题
Q-chunking:O2O强化学习,有招胜无招?
对比下面的贝尔曼方程,图一是标准的强化学习递推方程,图二是Q-chunking的递推方程。其中
是discount,就是折扣因子,
就是reward。所以Q-chunking算法的核心就是将action替换为actions。
标准的1步TD
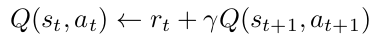
q-chunking
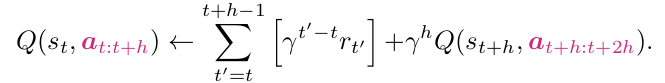
在实操层面,Q chunking与传统的强化学习技术有以下更新点:
将单个action更新为action chunk,跟模仿学习中的action chunk是一致的。论文作者尝试取h=5效果较好。
action chunk所对应的reward就更新为action chunk内所有动作产生的reward的折扣之和。
next_state就是action chunk之后的那个state。
强化学习中的done状态:当action chunk之内只要有一个动作导致episode完成 ,那么整体的action chunk的done状态就为True。
相关模型:
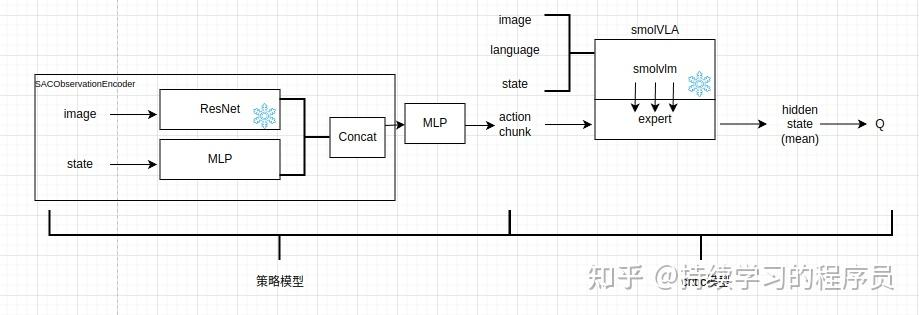
笔者整体上还是基于lerobot中的hil-serl框架进行二次开发,如上图所示,其中action chunk之前的模块为策略模型,action chunk及其之后的模块为critic模型。策略模型基本没有更新,只是将最终输出一个action扩展为了输出多个action(即action chunk)。critic模型整体替换为了smolvla模型(以前是跟策略模型类似的简单小模型),相当于将以前的小模型替换成了较大的vla模型。smolvla模型也是lerobot框架中已经集成好的,所以笔者作一些适配性的工作就可以嵌入到hil-serl中。
其它算法选型:
在整体强化学习算法中,使用的是td3+bc离线强化学习算法。另外,原始的Q chunking算法是在离线或在线强化学习环境中都可以使用了,在本篇文章中,笔者只是在离线环境中复现Q chunking算法的效果。
其实本篇文章工作是前期工作《几种强化学习算法输出的Q值的可视化(hil-serl/td3+bc/td3+bc+distributional/td3+bc+smolvla)》中4.1部分的一个延续,更多的信息也可以参考这篇文章。
数据集:
先说一下训练数据集,笔者前期设计了一个强化学习任务,具体可参考:《具身智能hil-serl强化学习算法在lerobot机械臂上复现-案例2》,在hil-serl算法复现过程的后期,大部分都是策略自动化的下发动作,人工只是在个别的时刻去接管,纠正策略。hil-serl框架会自动保存最近30000个step的数据,这些数据大部分都是策略自动化产生的。笔者统计了一下,共保存了232个episode:
139个成功,平均15秒/episode
93个失败,平均10秒/episode
整体来看,这个数据集的量级,正负样本的比例都可以直接拿来使用。当然,在工作一里面只是生产出了可用的数据集,工作一本身与此数据集没有太大关系,因为hil-serl的训练过程是纯在线的,使用的是历史上8个小时持续交互过程中的操作数据。这个数据集主要是给后面的工作二,工作三来使用。
评测数据集就选取上面数据集的前10个episode,其中有4个(第二,四,六,八个episode)是成功的,其余是失败的。
数据集笔者已经上传到hugging face,地址:MrXuan/push_cube_complex ,有兴趣可自行下载。
代码:
python -m lerobot.rl.learner --config_path rl_train_config.json
结果
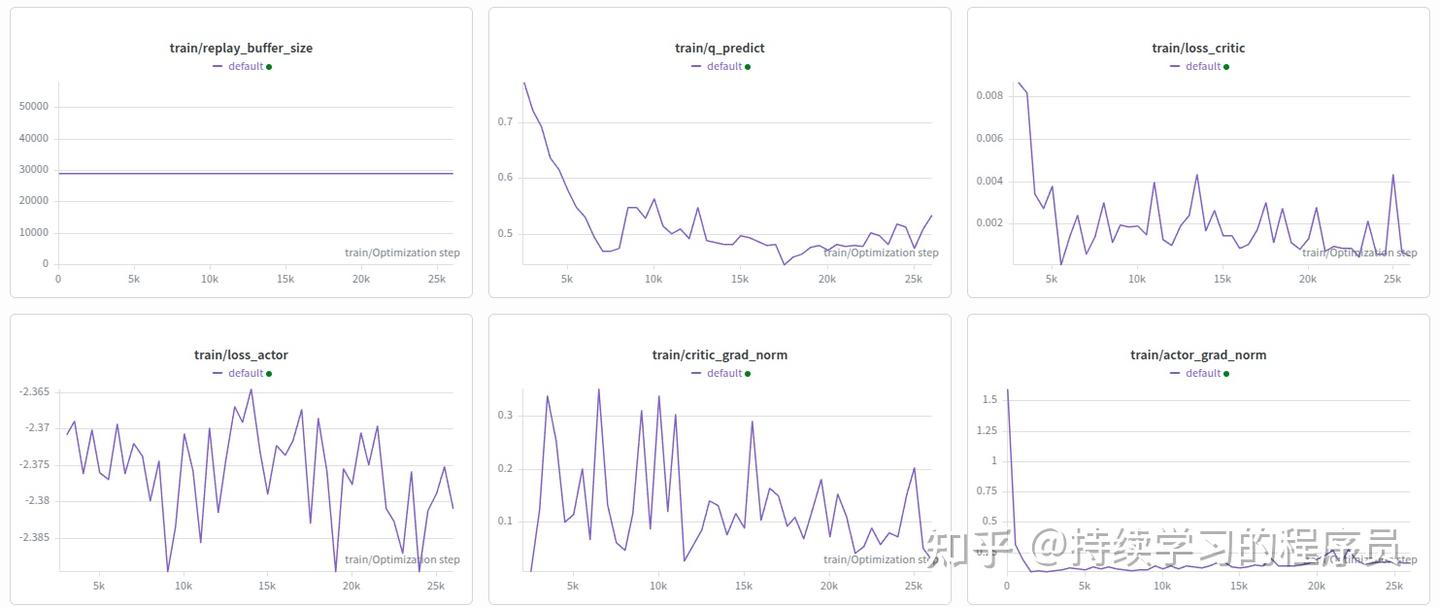
训练过程指标曲线图如下,可以发现整体Q值稳定在0.4左右。跟《几种强化学习算法输出的Q值的可视化(hil-serl/td3+bc/td3+bc+distributional/td3+bc+smolvla)》中工作4.1的值接近。
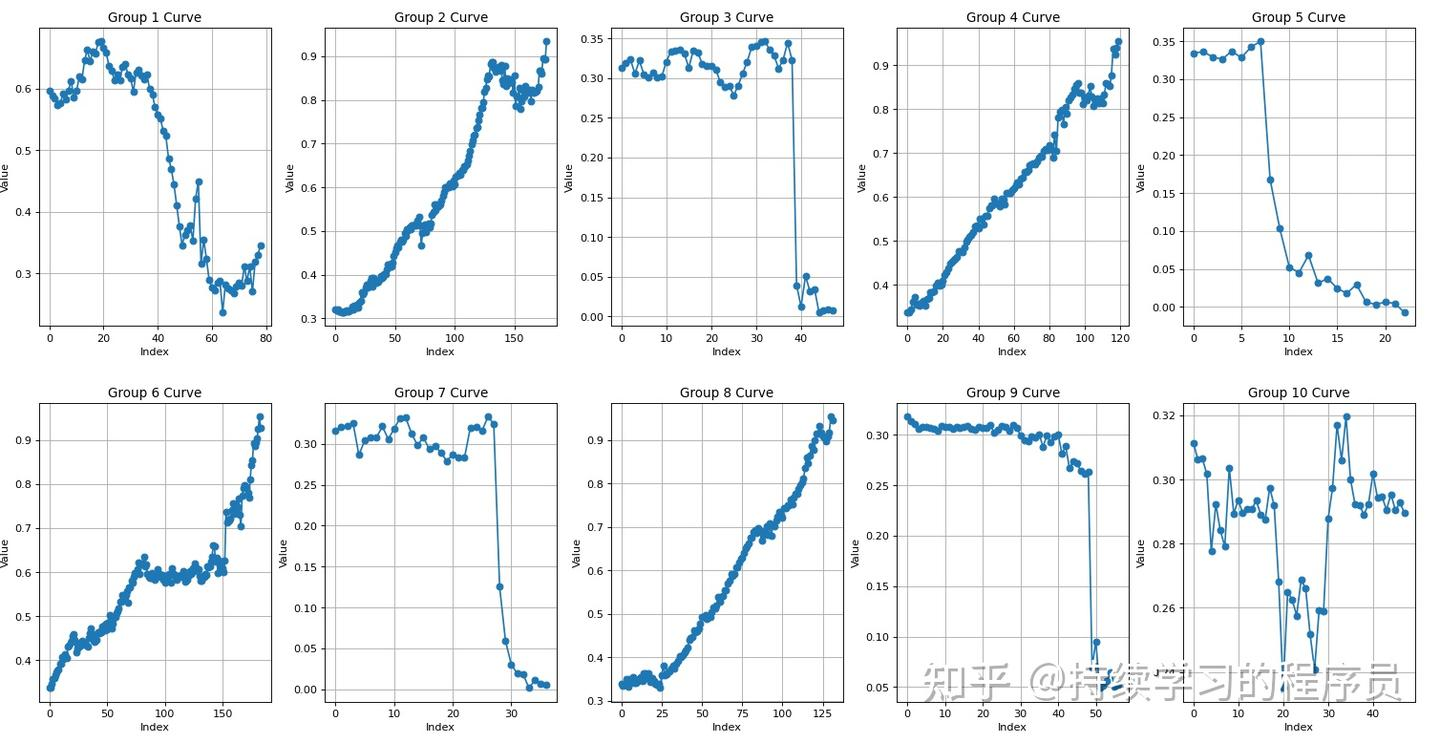
在训练26k的check point上,打印评测的10个episode的Q值的趋势如下,其中成功的episode中(2,4,6,8)趋势上还可以,从较低的0.3到0.9,可以较为清晰的展现此episode从开始到完成的进度。
下图的Group 6 Curve是第六个episode的Q趋势图,可以较为清晰的看到第六个episode中间机械臂的动作出现了一段时间的平稳期(与实际相符,step79-149之间机械臂出现了犹豫徘徊)。
整体上笔者感觉Q-chunking算法的效果也是很不错的。
26k
17k
11k checkpoint: