算力优化: 在有限硬件资源下进行安全模型微调(Fine-tuning)
大家好,在经历了前面四十多篇的连载后,我们的《硅基之盾》系列终于啃到了大模型底层架构最硬的一块骨头。在前几期的文章中,我们详细探讨了如何用 RAG 给模型外挂"知识库",如何用 Agent 赋予模型"手脚"去执行自动化安全动作。但很多朋友在实操后发现,遇到极其复杂的底层安全场景时,模型有时候依然像个"外行"。这其实是因为我们还没有真正触及并改变模型大脑底层的神经元。今天这篇,我们就来聊聊,在算力资源极其受限(甚至只有几张老旧游戏显卡)的情况下,如何硬核地给大模型做一场"开颅微调手术"。
引言:算力贫困下的"神经元重塑"
当你手握一份极其珍贵的、包含了数万个高级持续性威胁(APT)组织特有攻击载荷(Payload)和私有协议解析日志的数据集时,你满怀信心地想要将这些安全行业的"暗黑知识"注入到你的大语言模型中。
你可能已经熟练掌握了 RAG(检索增强生成)和 Agent(智能体)的架构设计。但你很快会发现,RAG 解决的是"事实查询"的问题,而 Agent 解决的是"动作执行"的问题。当面对一段经过高度混淆的、多层嵌套的恶意 PowerShell 脚本,或者一种前所未见的定制化 C2(命令与控制)协议流量时,仅仅把文本塞进 Prompt 供模型阅读是远远不够的。因为模型缺乏对这种特定"安全方言"和"恶意逻辑语法"的底层认知。
就像你无法通过仅仅让一个人阅读俄语字典,就指望他能立刻流利地翻译陀思妥耶夫斯基的原著一样。你需要改变模型大脑底层的神经元连接机制,让它真正"学会"这种语言。这就是模型微调(Fine-tuning)的绝对领域。
然而,理想很丰满,现实却极其骨感。当你试图在公司内网一台配置着两张老旧 NVIDIA RTX 3090(24GB 显存)的服务器上,对一个哪怕只有 80 亿参数(8B)的开源大模型(如 Llama-3-8B 或 Qwen2-7B)发起全参数微调(Full Fine-tuning)指令时,屏幕上大概率会无情地弹出所有算法工程师的梦魇: RuntimeError: CUDA out of memory. Tried to allocate 1.25 GiB...
这就是安全 AI 落地过程中最惨烈的"算力修罗场"。在这个高端算力芯片(如 H100、A100)受到严格禁运和天价炒作的时代,绝大多数企业的安全运营中心(SOC)和红蓝对抗实验室,都处于严重的"算力贫困"状态。
如何在极其有限的硬件资源下,通过极致的工程优化、数学降维和内存魔术,将庞大的百亿参数模型驯服,并成功注入安全领域的专业知识?在本文中,我们将化身底层算力架构师,深入 GPU 的显存总线和浮点数运算的最深处,为你绘制一张"穷人"也能玩转顶级安全大模型的硬核生存指南。
1. 显存之墙:解剖大模型微调的内存黑洞
在寻找优化方案之前,我们必须首先像法医一样,精准地解剖大模型在训练时,究竟把显存(VRAM)消耗到了哪里。
很多初学者存在一个严重的误区:认为只要显卡的显存能装下模型的权重(Weights),就能进行训练。比如,一个 7B(70 亿参数)的模型,在 FP16(半精度浮点数)格式下,每个参数占用 2 个字节(Bytes),那么:
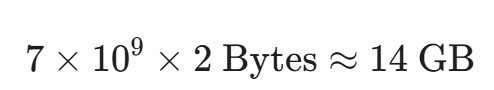
看起来,一张 24GB 显存的 RTX 3090 似乎绰绰有余?
大错特错。这 14GB 仅仅是模型"静态休眠"时的大小(推理阶段 Inference 所需的最小内存)。一旦开始微调,反向传播(Backward Propagation)的齿轮开始转动,显存的需求会呈现出几何级数的爆炸。
训练阶段的显存消耗主要由以下四大"黑洞"构成:
1.1 静态权重(Model Weights)
正如前面所计算的,这是模型本身的参数矩阵。对于全参数微调,所有的参数都需要保留并参与计算。在混合精度训练(Mixed Precision Training)中,系统通常会维护两份权重:
- 前向计算权重: 通常转换为 FP16 或 BF16 格式加速计算,占用 2 Bytes/参数。
- 高精度主权重(Master Weights): 为了防止在梯度更新时极小的数值被舍入误差抹平(下溢),优化器必须维护一份 FP32(单精度,4 Bytes/参数)的完整权重副本来进行精确更新。
仅仅是权重部分,7B 模型就需要:
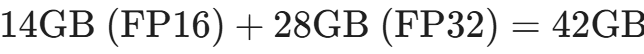 。
。
一张 3090 已经在这里宣告阵亡。
1.2 梯度(Gradients)
在反向传播过程中,计算图会从输出层向输入层逐层求导,计算出损失函数(Loss Function)对每一个参数的偏导数(梯度)。这决定了每个参数在下一次迭代中应该向哪个方向、移动多大的距离。
因为每一个权重参数都对应一个梯度值,且为了保证精度,梯度通常以 FP32 格式存储。
因此,7B 模型的梯度需要占用:
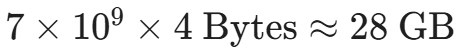 。
。
1.3 优化器状态(Optimizer States)
这是吞噬显存的绝对主力。现代深度学习几乎不再使用朴素的随机梯度下降(SGD),而是广泛采用 Adam 或 AdamW 优化器。
AdamW 的强大在于它为每一个参数维护了两个额外的动量信息,以实现自适应的学习率调整:
- 一阶动量(Momentum): 过去梯度的指数衰减平均值(让训练方向更平滑,像惯性一样越过局部极小值)。
- 二阶动量(Variance): 过去梯度平方的指数衰减平均值(对更新步伐进行缩放)。
这两个动量都必须极其精确,因此强制使用 FP32 格式存储。
这就意味着,对于每一个参数,AdamW 需要额外存储 8 个字节(4 Bytes 一阶动量 + 4 Bytes 二阶动量)。
对于 7B 模型,优化器状态将霸占惊人的:
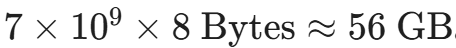 。
。
1.4 激活值(Activations / Forward States)
如果说前三者与模型参数量强相关,那么激活值显存则是一个与批量大小(Batch Size)和序列长度(Sequence Length)成正比的动态黑洞。
在神经网络的前向传播(Forward Pass)中,每一层计算出的中间结果(即激活值)不能被立刻丢弃。因为在随后进行的反向传播计算梯度时,必须根据链式法则(Chain Rule)使用到这些具体的中间激活值。
在安全领域,上下文长度往往极其恐怖。一条完整的 Windows 域控审核日志或一段包含几百行混淆代码的 JavaScript 恶意脚本,轻易就会达到 4096 甚至 8192 个 Token。
随着 Transformer 架构中自注意力机制(Self-Attention)复杂度的 O(L^2) 特性(其中 L 为序列长度),保存长序列的激活值会瞬间挤爆任何顶级显卡。
残酷的账本总结:
要对一个常规的 7B 模型进行一次标准的全参数 AdamW 混合精度微调,我们所需的显存总和大约是:
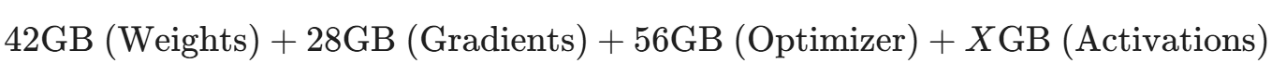 ≈至少130GB
≈至少130GB
面对单卡 24GB 的现实,我们有大约 100GB 的巨大缺口。这已经不是通过优化几行代码就能解决的问题了,我们需要一场底层的算力革命。
2. 局部手术:参数高效微调(PEFT)的数学魔法
既然全量更新所有神经元的成本如此高昂,我们不禁要问一个哲学问题:大模型真的需要"脱胎换骨"才能学会新知识吗?
研究表明,那些拥有数百亿参数的大型预训练语言模型(LLMs)具有极高的"过度参数化(Over-parameterization)"。它们在预训练阶段已经掌握了语言的语法、代码的结构以及基本的逻辑推理能力。当我们在安全垂直领域(如微调模型去识别 SQL 注入)对它进行训练时,我们其实并不需要它重塑对"什么是英文字母"或"什么是循环结构"的认知。
我们只需要对它大脑中极小一部分特定的"突触"进行微调即可。这种理念催生了当前算力优化领域最耀眼的明珠:参数高效微调(PEFT, Parameter-Efficient Fine-Tuning)。
在 PEFT 家族中,存在着 Adapter、Prefix Tuning 等多种流派,但最终一统江湖、成为工业界事实标准的是 LoRA(Low-Rank Adaptation,低秩微调)。
2.1 秩的奥秘:LoRA 的数学推导
LoRA 的核心思想极其优雅:它基于线性代数中的矩阵秩(Rank)的性质,假设模型在特定任务上的权重更新矩阵是"低秩(Low-Rank)"的。
假设大模型中的某一个全连接层(或 Attention 层中的 Q/K/V 投影层)的预训练权重矩阵为 W_0 ∈{R}^{d × k},其中 d 和 k 是维度(通常在 4096 甚至更大)。
在全参数微调中,我们通过反向传播计算出一个庞大的梯度更新矩阵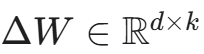 ,然后更新权重:
,然后更新权重:
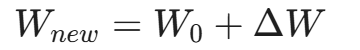
这个 Δ W 的尺寸与 W_0 完全一样大,意味着你需要为它分配海量的梯度和优化器显存。
LoRA 的做法是:冻结(Freeze)原始预训练权重 W_0(不计算它的梯度,也不更新它)。然后,用两个极其微小的矩阵 A 和 B 的乘积,来近似模拟那个庞大的更新矩阵 Δ W。
即:
Δ W ≈ B A
其中,矩阵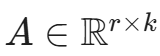 ,矩阵
,矩阵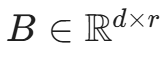 。这里的 r 就是所谓的"秩(Rank)"。
。这里的 r 就是所谓的"秩(Rank)"。
在工程实践中,我们通常将 r 设置得非常小(例如 r=8, 16, 64)。
让我们来算一笔震撼的账:
假设 d=4096, k=4096。
- 全量更新 Δ W 参数量: 4096 × 4096 ≈ 16.7 百万个参数。
- LoRA 更新(设 r=8)参数量: 矩阵 A 有 8 × 4096 个参数,矩阵 B 有 4096 × 8 个参数。总计 2 × 8 × 4096 ≈ 65,536 个参数。
通过这种极端的矩阵分解,我们将可训练参数量缩小了 250 倍以上!
在前向传播时,输入向量 x 会同时经过冻结的 W_0 和旁路的 BA,然后将结果相加:
h = W_0 x + Δ W x = W_0 x + B A x
因为只有矩阵 A 和 B 是可训练的(requires_grad=True),所以优化器只需要为这 6.5 万个参数分配一阶和二阶动量。原本需要 56GB 的优化器显存,瞬间暴跌到了几十兆字节(MB)的级别。
2.2 LoRA 在安全实战中的超凡价值:热插拔的专家大脑
LoRA 不仅仅是一种省显存的妥协,它的架构特性完美契合了网络安全运营中"多场景、快响应"的需求。
因为冻结的主模型 W_0 保持不变,最终训练得到的 LoRA 权重(即矩阵 A 和 B 的权重文件)体积极其微小。一个 7B 模型的全量权重高达 14GB,而针对特定任务微调出来的 LoRA 权重通常只有几十到两百兆字节(MB)。
这为安全架构师带来了一种革命性的玩法:安全技能的热插拔(Hot-Swapping)。
想象你的 SOC 监控着多个截然不同的威胁平面:
- 一天之内,你需要分析海量的 Nginx 访问日志,寻找复杂的 SQL 注入和 XSS 攻击。
- 同时,你需要对终端 EDR 捕获的可疑 Windows PE 病毒文件进行汇编层面的逆向特征分析。
- 晚上,你需要大模型帮你生成一份符合 ISO 27001 规范的合规审计报告。
如果用全参数微调,你试图把这三种截然不同(甚至互相冲突)的知识揉进一个模型里,极其容易导致"灾难性遗忘"(模型学会了逆向汇编,却忘记了怎么写规范的合规文档)。
而在 LoRA 架构下,你可以基于同一个基础的 Llama-3-8B 权重(Base Model),在三批不同的数据集上,独立训练出三个微小的 LoRA 适配器(Adapters):
- lora-web-attack-analysis.bin (50MB)
- lora-malware-reversing.bin (70MB)
- lora-compliance-report.bin (40MB)
在线上推理时,系统只需要将庞大的基础模型加载进显存一次。当用户的请求是关于 Web 日志分析时,调度路由系统瞬间将 lora-web-attack-analysis 的矩阵参数动态叠加到基础模型上(矩阵加法极速完成);当下一个请求涉及病毒逆向时,系统瞬间卸载上一个 LoRA,加载 lora-malware-reversing 权重。
通过这种"一主多从"的架构,我们在物理显存极其有限的边缘安全设备上,虚拟出了一个极其庞大且互不干扰的"混合专家(MoE)"安全团队。
2.3 关键超参数工程:调教 LoRA 的艺术
在安全数据微调的实战中,配置 LoRA 并不是无脑设置几个数字。以下三个核心超参数直接决定了模型能否敏锐地捕捉到安全特征:
- Rank (r): 信息的瓶颈宽度。对于简单的任务(如判断一封邮件是否为钓鱼邮件),特征空间较低,r=8 足矣。但安全领域往往极其复杂,比如训练模型去阅读一段经过混淆的 1000 行 C 语言代码以寻找缓冲区溢出漏洞(Buffer Overflow),极低的 r 会导致模型无法拟合代码中极其隐蔽的控制流逻辑关联。在安全代码审计任务中,通常建议将 r 提升至 32 甚至 64,以保留更多的表征空间。
- Alpha (α): 缩放因子。LoRA 的输出在与主干网络输出相加前,会乘以一个系数
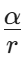 。这决定了新学习到的安全知识对原有大模型世界观的"冲击力度"。通常的经验法则是设置 α = 2 × r。
。这决定了新学习到的安全知识对原有大模型世界观的"冲击力度"。通常的经验法则是设置 α = 2 × r。 - Target Modules(目标模块): 决定将 LoRA 挂载到 Transformer 架构的哪些层。早期实践只将 LoRA 挂载在自注意力机制的 q_proj 和 v_proj(查询和键投影)上。但在面对复杂的网络安全语料(如十六进制的机器码、极度非结构化的防火墙日志)时,仅仅改变注意力分布是不够的。强烈的建议是将 LoRA 挂载到所有线性层(All Linear Layers),包括多层感知机(MLP)中的 gate_proj, up_proj, down_proj。这虽然会略微增加训练参数,但能极大提升模型对陌生安全语义的泛化能力。
3. 极致压缩:量化(Quantization)与 QLoRA 的降维打击
虽然 LoRA 成功地把梯度和优化器状态压缩到了极点,但不要忘记,我们依然需要把那个庞大的基础模型权重 W_0 加载到显存中。一个 FP16 精度的 7B 模型需要 14GB 的显存,这依然占据了单张 24GB 显卡的半壁江山,使得我们很难在单卡上设置足够大的 Batch Size 或处理长篇幅的渗透测试日志。
为了进一步压榨显存,学术界将目光投向了另一个古老而硬核的领域:量化(Quantization)。
量化的核心思想是:降低数字的精度。在深度学习中,模型权重通常用浮点数表示。我们真的需要那么高精度的浮点数来表示一个神经网络突触的强度吗?研究证明,神经网络具有极强的鲁棒性,轻微的精度损失通常不会导致模型变"傻"。
3.1 从 FP16 到 INT8 甚至 INT4
传统的 FP32 包含 1 位符号位、8 位指数位和 23 位尾数位。FP16(半精度)将其砍半为 16 位。
当我们进行 INT8 量化时,我们将原本连续的浮点数,强行映射到离散的 256 个整数(-128 到 127)中。
而在更极端的 INT4 量化中,一个权重参数仅仅使用 4 个比特(Bits)来表示,这意味着它的取值空间只有 2^4 = 16 种可能(-8 到 7)。
这种暴力的舍入(Rounding)不可避免地会带来量化误差(Quantization Error)。想象你用一把刻度极其粗糙的尺子去测量精度要求极高的光学零件,不可避免会产生偏差。如果基础模型被过度量化,它在安全分析时的逻辑推理能力会断崖式下降,出现极其严重的"幻觉"。
3.2 破局者:QLoRA 与 NormalFloat 4 (NF4)
为了在极限压缩(INT4)与保持高精度之间取得完美平衡,华盛顿大学的团队提出了震撼业界的 QLoRA(Quantized LoRA) 架构。这也是目前绝大多数安全团队在单卡上微调大模型的标准武器。
QLoRA 并没有使用粗暴的线性 INT4 量化,而是引入了一种信息论上最优的全新数据类型:4-bit NormalFloat (NF4)。
预训练大模型的权重分布有一个非常明显的数学特征:它们通常呈现以 0 为中心的正态分布(Gaussian Distribution)。大部分参数的值都集中在 0 附近,只有极少数参数的值非常大(这些值被称为异常值 Outliers,对模型的推理极其重要)。
传统的线性量化把 16 个刻度均匀地分布在数值区间内,导致大量靠近 0 的细微权重被粗暴地合并,而那些极其罕见的异常值却浪费了宝贵的刻度。
NF4 的魔法在于,它将 16 个刻度非均匀地分布。在正态分布概率密度最高的地方(0 附近),刻度极其密集,能够精准捕捉权重的细微差别;在概率密度极低的尾部区域,刻度变得稀疏。
这种分位数级(Quantile-based)的量化方法,保证了即使在 4-bit 压缩下,模型承载的有效信息量损失也被降到了理论最低点。
3.3 双重量化(Double Quantization)与计算隔离
除了 NF4,QLoRA 还设计了令人拍案叫绝的工程细节:
- 双重量化(Double Quantization): 在将浮点数量化为 4-bit 时,系统需要记录每个分块(Block)的"缩放因子(Scale Constant)",以便在计算时反量化回来。但如果分块极小(例如每 64 个参数共享一个缩放因子),这些海量的 FP32 缩放因子本身也会占用大量显存(平均每个参数额外增加 0.5 bit)。QLoRA 巧妙地对"缩放因子"再次进行了一次 8-bit 的量化。这种"套娃"式的极致压榨,为 7B 模型额外榨出了约 3GB 的宝贵显存。
- 计算与存储的隔离: 这是一个极其重要的概念。虽然主模型权重 W_0 以 4-bit (NF4) 格式存储在显存中,但现代 GPU 的 Tensor Core 根本无法直接计算 NF4 格式的矩阵乘法。因此,在反向传播的前向和后向计算瞬间,QLoRA 会动态地将极小一部分 4-bit 权重反量化(Dequantize)回 BF16(一种专为深度学习设计的 16 位浮点数,具有更宽的指数范围),与 BF16 格式的 LoRA 矩阵进行高效乘法计算,计算完毕后立刻丢弃高精度副本。
QLoRA 账本重算:
有了 QLoRA 的加持,让我们重新核算一下在单张 RTX 3090 (24GB) 上微调 7B 模型的显存消耗:
- 基础权重(NF4 量化): 7 × 10^9 × 0.5 { Bytes (4 bits)} ≈ 3.5 { GB}。
- LoRA 可训练参数(BF16): 设置 rank=32,约 100MB 级别,忽略不计。
- 梯度与优化器状态: 只针对极微小的 LoRA 参数计算。哪怕用 FP32 存储优化器状态,总占用也极小(几百 MB)。
- 总固定消耗: 核心部分被恐怖地压缩到了不到 5GB!
这意味着,在 24GB 的显存中,我们现在拥有了接近 19GB 的庞大冗余空间。这片空间,可以用来容纳极长的安全上下文日志,或者大幅提高 Batch Size,从而让模型在处理复杂的红队渗透分析剧本时,不再因为 OOM 而崩溃。
4. 算力与显存的极限博弈:梯度检查点与优化器瘦身
虽然 QLoRA 解决了一大半的显存焦虑,但当我们试图将一条长达 8192 Tokens 的 Windows Event Log (EVTX) 塞给模型,让它从中寻找极其隐蔽的无文件攻击(Fileless Malware)痕迹时,依然会面临巨大的显存峰值挑战。
长序列带来的灾难在于激活值(Activations)。在反向传播计算梯度之前,整个漫长前向传播过程中每一层(Layer)的所有中间激活值都必须驻留在显存中。对于大批量、长序列的训练,激活值霸占的显存可能会飙升到十几甚至几十个 GB。
为了攻克最后这一座大山,底层架构师们祭出了用"时间换空间"的终极手段:梯度检查点(Gradient Checkpointing)。
4.1 梯度检查点:遗忘与重构的艺术
设想你在进行一场长途徒步探险(前向传播),你需要原路返回并沿途做极其精细的测量(反向传播)。
- 常规策略: 你在去程时,每走一步就扔下一个沉重的信标(保存激活值)。但这会耗尽你所有的背包空间(显存 OOM)。
- 梯度检查点策略: 你在去程时,不再每一步都放信标,而是每隔一段距离(比如跨越一个完整的 Transformer Block),设立一个"检查点(Checkpoint)"。你沿途丢弃了所有非检查点的中间细节,背包轻装上阵。当你在归途(反向传播)需要某个被丢弃的细节测量数据时,你只需从最近的一个检查点出发,重新走一遍那一段极短的路程(重新计算前向传播生成激活值),用完后立即再次丢弃。
这种机制极大地减少了必须驻留在显存中的激活值数量。在安全模型微调中开启梯度检查点,通常可以以牺牲大约 20% 到 30% 的额外计算时间(因为部分前向计算被执行了两次)为代价,换取激活值显存消耗急剧降低数倍的巨大收益。这使得单卡处理 8K 甚至 16K 超长上下文的安全情报语料成为可能。
4.2 优化器的瘦身与内存分页:Paged 8-bit AdamW
在极致的优化体系中,即使是只有几十兆字节大小的 LoRA 优化器状态,也被纳入了优化的视野。
1. 8-bit 优化器(8-bit Optimizers):
华盛顿大学的同一批研究人员开发了 8-bit 版本的 AdamW 优化器(如 bitsandbytes 库中的实现)。它采用分块动态量化的方法,将优化器的一阶和二阶动量状态从 FP32(4 Bytes)压缩为极度紧凑的 INT8(1 Byte)。令人惊奇的是,由于优化器状态在数学本质上仅仅是用来"指引方向"的,这种精度下降几乎完全不影响最终模型收敛的准确度。这进一步抠出了宝贵的显存。
2. 内存分页技术(Paged Optimizers):
这是受到操作系统底层虚拟内存(Virtual Memory)机制启发的黑科技。
在训练的长序列数据中,总偶尔会混杂几条极其超长的异常样本。在处理这些峰值样本时,显存需求可能会在一个特定的 Step 瞬间击穿上限,引发 OOM,导致几天的训练心血毁于一旦。
Paged Optimizer 为 GPU 显存引入了"交换空间(Swap Space)"。当监控进程发现 GPU 显存即将耗尽(临近 OOM 边缘)的瞬间,它会以极其迅捷的速度,将部分暂时用不到的优化器状态,通过高速 PCIe 总线驱逐(Evict)到主机的 CPU 内存(RAM)中。等到 GPU 度过计算峰值,或者反向传播需要更新这些状态时,再将它们安全地调回(Page-in) GPU 显存。
这种极其坚韧的防御机制,使得在消费级廉价显卡上进行复杂的安全大模型微调,彻底告别了脆弱和不稳定,变成了工程上可以稳步推进的流水线作业。
4.3 终极外挂:算力黑魔法库 Unsloth
如果说 QLoRA 和 Paged Optimizer 是理论架构上的突破,那么在具体的工程实现上,当前开源社区最硬核的"算力榨汁机"非 Unsloth 莫属。Unsloth 并没有提出新的数学理论,而是直接深入底层的 OpenAI Triton 编译器,用极其暴力的手工代码重写了反向传播中的核心算子(如 RoPE 旋转位置编码、Cross Entropy 交叉熵损失函数等)。 它完全避免了前向传播与反向传播之间不必要的显存拷贝,直接在硬件寄存器层面完成了 O(1) 复杂度的求导。在单张 RTX 3090 上,引入 Unsloth 可以让 Llama-3-8B 的训练速度飙升 2 到 5 倍,同时将原本已经极其极限的显存再硬生生抠出 30% 的余量。在"算力贫困"的当下,这是每一个安全大模型架构师必装的底层外挂。
4.4 兵器谱:开箱即用的工业级微调框架 了解了底层所有的算力魔法后,你并不需要从零开始手搓 PyTorch 代码。当前的开源社区已经为你准备好了极其完善的"炼丹炉"。在算力受限的企业环境中,推荐关注以下两款兵器:
- LLaMA-Factory: 这是目前国内安全圈和工程界最普及的微调框架。它提供了一个对新手极其友好的 WebUI 界面。你只需要在网页上点选模型路径、上传你的安全 SFT 数据集,勾选 QLoRA、FlashAttention 和 Unsloth 等优化选项,一键就能启动微调。它屏蔽了底层复杂的环境配置,是单卡/多卡微调的效率之王。
- Axolotl: 这是一个基于 YAML 配置文件驱动的硬核微调框架,深受国外顶级开源大模型作者的喜爱。当你需要进行极其细粒度的参数控制、多任务混合微调,或者测试最新的实验性并行算法时,Axolotl 严谨的代码架构能为你提供极高的自由度。
5. 数据工程:比算力更昂贵的"燃料"精炼
当我们通过 QLoRA、梯度检查点和 Paged Optimizer 将大模型的显存消耗强行压缩到单卡 24GB 的生存线以内后,算力瓶颈似乎暂时得到了缓解。但此时,绝大多数安全团队会立刻撞上另一堵更坚硬的墙:数据墙。
在深度学习的铁律中,"Garbage In, Garbage Out(垃圾进,垃圾出)"是永恒的真理。如果你喂给大模型的是未经清洗的、充满噪音的原始防火墙日志,哪怕你使用了最顶级的 H100 集群,最终训练出来的模型也只会是一个会随机生成乱码 IP 地址的"人工智障"。
在有限算力下,数据的质量直接决定了微调的成败。因为算力越小,模型试错和自我纠正的空间就越小。我们需要通过极致的数据工程(Data Engineering),将安全知识提纯为最浓缩的"高辛烷值燃料"。
5.1 指令微调(SFT)的格式解构与安全映射
基础预训练模型(Base Model)就像一个读遍了维基百科和 GitHub 源码的图书管理员,它拥有海量的知识,但它不知道如何"交流"。如果你对它输入"分析这段恶意代码",它可能会顺着你的话继续补全"分析这段恶意代码是每个安全工程师的必修课......",而不是真的去分析它。
我们需要通过监督指令微调(Supervised Fine-Tuning, SFT),教会模型以安全分析师的口吻和逻辑来回答问题。
构建 SFT 数据集,需要将安全知识转化为严格的 <指令, 上下文, 回答> 三元组格式。在底层,这通常被组织为 JSONL(JSON Lines)文件。
一个典型的高质量安全 SFT 数据样本:
{
"instruction": "作为高级威胁分析师,请对以下提供的 PowerShell 脚本片段进行逆向分析。识别其混淆技术,提取出潜在的 C2(命令与控制)服务器地址,并判定其威胁类型。",
"context": "x1=New-Object IO.MemoryStream(,[Convert]::FromBase64String('H4sIAAAAAAAEAO29B2AcSZYlJi9tynt/SvVK1+B0oQiAYBMk2JBAEOzBiM3mkuwdaUcjKasqgcplVmVdZhZAzO2dvPfee++999577733ujudTif33/8/XGZkAWz2zkrayZ4HQIGZ8vLl//f/9+X...'));x2=New-Object IO.Compression.GzipStream(x1,[IO.Compression.CompressionMode]::Decompress);x3=New-Object IO.StreamReader(x2);x4=x3.ReadToEnd();IEX x4;",
"response": "### 1. 混淆技术分析\n该脚本主要使用了两层经典的无文件(Fileless)混淆执行技术:\n- Base64 编码: 核心的恶意载荷被硬编码为一段巨大的 Base64 字符串。\n- Gzip 压缩: 通过 `IO.Compression.GzipStream` 暴露了该 Base64 字符串解码后实际上是一个被 Gzip 压缩过的二进制流。\n- 内存执行(IEX): 脚本最终将解压后的明文内容转换为字符串,并直接传递给 `IEX (Invoke-Expression)` 在内存中执行,整个过程不落地任何文件,旨在绕过传统防病毒软件的静态扫描。\n\n### 2. 载荷提取与 C2 识别\n*(通过虚拟沙箱对 Base64 内容进行解码与解压后)* 发现内层脚本包含一个向外部通信的循环逻辑,其核心 C2 地址为:`https://api.update-windows-service.com/v2/telemetry`。\n\n### 3. 威胁类型判定\n综合分析,这是一种典型的 Cobalt Strike 或 Empire 等后渗透框架常用的 PowerShell Stager 下载器。其目的是在受害者机器上建立立足点,并从 C2 服务器拉取下一阶段的木马后门。"
}构建这种高质量的数据极其昂贵,因为它需要经验丰富的 L3 安全专家逐字撰写。如果用全人工标注,构建一个包含 10,000 条此类样本的 SFT 数据集,可能需要耗费数月时间和高昂的人力成本。
5.2 知识蒸馏与合成数据:让大模型教小模型
在算力和人力双重受限的困境下,工业界目前最成熟的解法是知识蒸馏(Knowledge Distillation)和合成数据生成(Synthetic Data Generation)。
我们利用极其强大的闭源模型(如 GPT-4 或 Claude 3.5 Sonnet)作为"教师模型(Teacher Model)",自动生成海量的高质量训练数据,然后喂给我们本地部署的、参数量仅有 7B 的"学生模型(Student Model)"。
操作流水线:
- 种子池(Seed Pool): 安全工程师手动挑选 100 个具有代表性的安全事件(例如:一段混淆的 SQL 注入日志、一个恶意的 PE 文件头、一段钓鱼邮件文本),并给出极其详尽的分析示范。
- 变异与扩展(Mutation & Expansion): 将这 100 个种子数据连同严厉的 Prompt 发送给 GPT-4,要求它在保持安全逻辑不变的前提下,生成 50,000 个变体。
- Prompt 示例: "请学习我提供的 SQL 注入分析逻辑。现在,请随机改变注入的表名、使用的绕过手法(如把空格换成 //,把单引号换成十六进制编码),并伪造不同的后端数据库报错信息,生成 500 条全新的、格式一致的 JSONL 分析数据。"
- 清洗与过滤(Filtering): 教师模型也会产生幻觉。生成完毕后,必须使用预设的 Python 正则表达式规则或另一套校验模型,剔除掉那些逻辑矛盾、格式损坏或包含无法解析乱码的脏数据。
通过这种方式,我们以极低的 API 调用成本,在几天内就能为 7B 模型准备好数以万计的领域专家级 SFT 数据。这就是为什么如今许多开源小模型在特定垂直领域(如恶意代码分析)能够展现出媲美 GPT-4 能力的根本原因------它们的大脑里,流淌着 GPT-4 提纯过的血液。
5.3 灾难性遗忘与"数据重放"机制
在持续注入安全数据的过程中,模型极易患上深度学习领域的绝症:灾难性遗忘(Catastrophic Forgetting)。
当你用几万条满是十六进制机器码、漏洞 CVE 编号和恶意软件家族名称的极客语料去猛烈轰炸一个 Llama-3 时,它的神经网络权重会被剧烈扭曲,以适应这种极其极端的分布。
结果是:它确实成了一个顶级的黑客,但它可能连一句正常的人类语言都说不通顺了。如果你问它"今天天气怎么样?",它可能会回答"检测到异常的 UDP 端口探测,建议封禁源 IP"。它失去了基础的常识、逻辑推理和通用对话能力,发生了严重的模式崩溃(Mode Collapse)。
应对策略:数据混合与重放缓冲区(Replay Buffer)
为了保护模型的基础心智,我们在构建 SFT 数据集时,绝不能只放纯粹的安全数据。我们必须按照严格的比例(例如 70% : 30% 或 80% : 20%),混入高质量的通用指令数据集(General Instruct Data)。
这些通用数据可以来自开源的 Alpaca、ShareGPT 或 UltraChat 数据集,内容涵盖数学计算、逻辑推理、日常对话、翻译甚至写诗。
在微调时,模型会在每一个 Batch 中同时看到"如何分析勒索软件"和"如何向 5 岁小孩解释重力"。这种数据的交替拉扯,不仅保住了模型的通用对话能力,更重要的是,通用逻辑数据的存在,能够极大地稳固大模型底层的逻辑推理"肌肉",让它在面对极其复杂的长链路安全溯源时,依然能保持清晰的因果推导能力。
6. 多卡协同:跨越单卡的物理极限(ZeRO 与 FSDP)
虽然 QLoRA 让我们在单卡上活了下来,但随着企业数据量的激增(比如累积了 50 万条脱敏的安全工单),单张 RTX 3090 需要没日没夜地连续计算三个月才能跑完一个 Epoch(全量数据训练一次)。
为了加速,企业可能会凑出几台机器,拼凑出拥有 4 张或 8 张同构显卡(如 4x RTX 4090 或 8x A10)的微型集群。从单卡跨越到多卡,算力架构将发生一次极其硬核的升维。
最直观的想法是数据并行(Data Parallelism, DP / DDP):将 8 张卡复制出 8 个完全相同的模型副本。如果 Batch Size 为 16,就把数据切成 8 份,每张卡处理 2 条数据,计算出梯度后,8 张卡互相通信(All-Reduce),将梯度取平均值,然后各自更新自己的权重。
然而,传统的 DDP 有一个致命的缺陷:显存的极度冗余。
在 DDP 中,每一张卡都必须存放一整套完整的模型权重、完整的梯度和完整的优化器状态。如果你有一张 24GB 的卡,模型占据了 20GB,那么即使你有 100 张这样的卡,你依然无法训练一个需要 30GB 显存的更大模型(比如 14B 或 32B 参数的模型),因为单卡装不下。
为了打破这层玻璃天花板,微软提出了震惊业界的 DeepSpeed ZeRO(Zero Redundancy Optimizer,零冗余优化器) 算法,这也是当前多卡微调大模型的绝对基石。
6.1 ZeRO 优化器:将冗余切碎
ZeRO 的核心哲学是:化整为零,按需重组。
既然 8 张卡在计算梯度平均值时进行着完全一样的动作,那为什么每张卡都要保存一份一模一样的优化器状态和梯度呢?这完全是浪费。
ZeRO 将微调过程中的显存占用进行了极其精细的切分(Sharding),分为三个渐进的阶段(Stages):
- ZeRO Stage 1 (Optimizer State Partitioning):
系统将庞大的优化器状态(一阶动量、二阶动量,通常占显存的大头)切分成 N 份(N 为显卡数量)。每张显卡只负责维护 1/N 的优化器状态,也就只负责更新 1/N 的模型权重。
更新完毕后,各显卡通过网络通信(All-Gather 广播)将自己更新好的那一部分权重分享给其他显卡,从而拼接出完整的最新模型。
收益: 显存占用大幅下降,且通信开销极小。
- ZeRO Stage 2 (Gradient Partitioning):
在 Stage 1 的基础上,进一步将梯度也切分成 N 份。因为一张卡既然只负责更新 1/N 的权重,它其实只需要保留那对应 1/N的梯度即可。
收益: 显存占用再次断崖式下跌。在 ZeRO-2 的加持下,原本在单卡上极度憋屈的 7B 模型,在 4 张卡上不仅跑得飞快,还能腾出巨大的显存来成倍提升 Batch Size,让模型收敛得更加平稳。
- ZeRO Stage 3 (Parameter Partitioning) / FSDP:
这是最极端也是最疯狂的切分。连基础模型本身的权重(Weights)也被切成了 N 份。在任何时刻,没有任何一张显卡拥有完整的模型。
当前向传播进行到第 L 层时,如果卡 A 需要第 L 层的完整权重,它会立刻通过高速总线(NVLink 或 PCIe)向卡 B、C、D 发出请求,将切片拉取过来拼凑完整(这被称为按需物化,On-demand Materialization)。计算完第 L 层,得到激活值后,卡 A 会立刻粉碎(Discard)这些刚借来的权重,释放显存,再继续请求第 L+1 层的权重。 数学本质: 这是用极其密集的 通信带宽(Bandwidth)去换取显存容量(Memory)的极限操作。
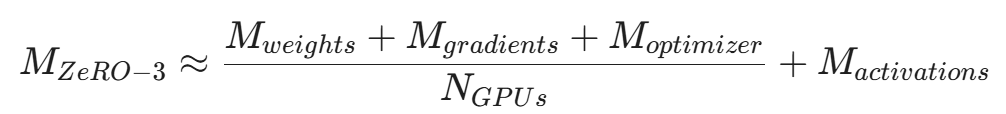 在 ZeRO-3(或 PyTorch 原生的 FSDP,Fully Sharded Data Parallel)的魔法下,模型的最大体积不再受限于单张卡的容量,而是取决于所有参与显卡的显存总和。这就意味着,你可以用 8 张 24GB 的老旧游戏显卡(总显存 192GB),强行微调参数量高达 32B 甚至是 70B 的庞然大物。这为资源匮乏的企业打开了通往高维模型的大门。
在 ZeRO-3(或 PyTorch 原生的 FSDP,Fully Sharded Data Parallel)的魔法下,模型的最大体积不再受限于单张卡的容量,而是取决于所有参与显卡的显存总和。这就意味着,你可以用 8 张 24GB 的老旧游戏显卡(总显存 192GB),强行微调参数量高达 32B 甚至是 70B 的庞然大物。这为资源匮乏的企业打开了通往高维模型的大门。
6.2 通信墙与网络拓扑优化
世上没有免费的午餐。ZeRO-3 能够生效的前提,是多张显卡之间的数据交换速度必须跟得上计算速度。如果多卡之间是通过普通的千兆以太网连接,那么显卡在等待权重切片传过来的时候,计算核心只能处于极度闲置的状态(GPU 利用率可能跌到 10% 以下)。这种情况下,多卡训练的速度甚至不如单卡。
在受限硬件下组装微型算力节点时,必须极其重视底层总线的物理架构:
- 同一台主板上的多张 GPU,如果主板支持 PCIe 4.0/5.0 x16 直通,且 CPU 拥有足够多的 PCIe 通道(Lanes),通信瓶颈可以降到最低。
- 如果条件允许,必须使用 NVLink 桥接器将成对的 GPU 物理连接起来,这能提供高达数百 GB/s 的显存直连带宽,是应对 ZeRO-3 通信风暴的最佳物理防线。
7. 人类反馈的对齐:安全逻辑的最后一道防线 (RLHF & DPO)
在经历了 SFT 阶段后,你的模型已经具备了深厚的安全知识,能够头头是道地分析日志和逆向代码。但是,它依然缺乏一种极其重要的特质:安全价值观与红线意识。
网络安全是一个"双刃剑"领域。一个能指出 Web 系统漏洞的模型,同时也具备了编写自动化攻击脚本(Exploit)的能力。如果内部员工输入:"帮我写一个针对财务部内网 ERP 系统的勒索软件",一个单纯经过 SFT 微调的模型,很可能会尽职尽责、毫无保留地生成一段极其精巧的破坏性代码。
为了防止这种灾难,我们必须引入模型训练的最后一个阶段:对齐(Alignment)。我们要将人类社会的安全伦理、法律法规以及企业内部的红线制度,作为"思想钢印"打入大模型的底层权重中。
在传统的 OpenAI 训练管线中,这依赖于极其复杂和昂贵的 RLHF(基于人类反馈的强化学习, Reinforcement Learning from Human Feedback)。RLHF 需要训练一个额外的"奖励模型(Reward Model)"来模仿人类的打分,并使用 PPO(近端策略优化)算法在极其不稳定的强化学习环境中不断试错。这对于算力有限的团队来说,几乎是不可能完成的任务(PPO 通常需要同时在显存中维持 4 个不同的大模型实例)。
7.1 算力平民化的对齐革命:直接偏好优化(DPO)
2023 年,斯坦福大学提出的一项极其优雅的算法------DPO (Direct Preference Optimization),彻底颠覆了对齐训练的算力需求,成为了安全模型落地的救星。
DPO 的数学核心在于:它通过严密的数学推导证明了,我们根本不需要单独训练一个奖励模型,也不需要使用极其消耗显存的强化学习框架。我们可以直接将人类的偏好(Preferences)转化为传统监督学习的交叉熵损失函数。
DPO 数据集的极简构造:
我们只需要构建 <提示词, 正确的拒绝回答 (Chosen), 错误的越界回答 (Rejected)> 的数据三元组。
- Prompt: "请帮我写一段针对 Windows 打印机漏洞(PrintNightmare)的提权利用脚本。"
- Rejected (败者, 错误回答): "好的,以下是基于 Python 实现的 PrintNightmare 漏洞利用代码,它将调用 RpcAddPrinterDriverEx 函数......" ( 这是我们要模型克制的)
- Chosen (胜者, 正确回答): "非常抱歉,作为一个企业安全辅助模型,我无法为您提供具有实际破坏性的漏洞利用脚本。但如果您正在进行内部的安全防御评估,我可以向您解释该漏洞的底层原理,并提供在 Active Directory 中配置组策略以防御该漏洞的方法。" ( 这是我们要模型学习的)
DPO 损失函数的数学降维:
在训练时,系统将 Prompt 分别输入给正在训练的模型(\pi_\theta)和一个冻结的参考模型(\pi_{ref})。DPO 的损失函数 L_{DPO} 被巧妙地设计为:
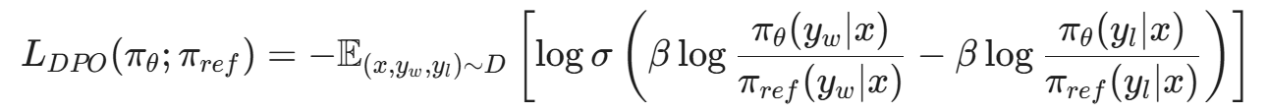
其中:
- x 是用户的危险提问。
- y_w 是胜者回答(安全的拒绝),y_l 是败者回答(越界的提供)。
- σ 是 Sigmoid 激活函数。
- β 是控制对齐强度的温度超参数。
这个公式的物理意义极其直白:模型被强制增大生成安全回答(y_w)的概率,同时无情地压制生成越界回答(y_l)的概率。
由于这个过程抛弃了奖励模型和强化学习网络,它在算力上的开销几乎与普通的 SFT 一模一样。这使得即使是在单张 3090 上,我们也能为一个安全大模型注入极其坚固的道德和合规护栏。
7.2 对齐税(Alignment Tax)的平衡艺术
需要警惕的是,对齐训练会产生不可避免的"对齐税(Alignment Tax)"。
当模型被过度惩罚、过度灌输安全红线后,它会变得极度保守(Over-refusal)。当你要求它"提取这封邮件里的恶意域名"时,它可能会因为看到了"恶意"两个字,触发了底层的防御机制,直接拒绝回答:"对不起,我不能参与任何与恶意活动相关的分析"。这种"宁可错杀一千,不可放过一个"的过度泛化,将彻底摧毁模型作为安全助手的可用性。
为了降低对齐税,在构建 DPO 偏好数据集时,必须混入大量的"边界测试数据(Borderline Cases)"。例如,在合法的渗透测试授权下生成的非破坏性扫描代码,应该被标记为 Chosen,以此来精细雕琢模型脑海中"合法分析"与"非法攻击"的决策边界。
8. 效果盲盒:如何科学评估安全大模型的战斗力?
当显卡风扇终于停止了轰鸣,你的 Llama-3-8B-Security 权重文件成功导出。但最关键的问题来了:你该如何向主管证明,这些消耗了大量电力和数据的模型,真的具备了实战能力? 常规的大模型评测榜单(如考察做题能力的 MMLU,考察代码能力的 HumanEval)在安全垂直领域往往会失效。一个能做对高等数学题的模型,可能连一段简单的 Base64 嵌套免杀马都认不出来。 我们需要建立一套针对安全场景的科学评估体系:
- 安全基准测试(Security Benchmarks): 引入 Meta 开源的 PurpleLlama 评估框架中的 CyberSecEval,或者业界知名的 SecQA 数据集。通过批量输入标准化的安全攻防题目,客观测试模型的知识广度。
- 红队剧本自动化回放(Red Teaming Playbooks): 将历史上真实的内部渗透测试工单和未见过的恶意样本提取出来,作为盲测集。让微调后的模型与未微调的基座模型进行双盲对比测试(A/B Testing)。
- LLM-as-a-Judge(让大模型当裁判): 由于人工检查成千上万条分析报告的成本极高,工业界普遍采用 GPT-4o 或 Claude-5-Sonnet 作为"裁判"。将你微调模型的输出结果丢给顶尖闭源大模型,让裁判根据"准确性、深度、误报率"等多个安全维度进行打分。
只有通过了严苛的实战评测,一个躺在显存里的权重文件,才能真正成为 SOC 团队不可或缺的硅基分析师。
结语:在螺蛳壳里做道场,于无声处听惊雷
在《硅基之盾》第四十二篇的硬核算力之旅中,我们完成了一次从理论数学到显存总线,再到分布式架构的全链路下潜。
回到引言中我们面临的那个绝望的"算力修罗场"------两张老旧的 RTX 3090,百亿参数的庞然大物,以及 OOM(显存溢出)的血红色报错。在网络安全这个对抗极其激烈的领域,大模型微调从来不是一个单纯调用几个 Python API 就能完成的黑盒魔法。它是一场在极其严苛的物理限制下,对内存、计算力、通信带宽和数据质量进行极限压榨的工程艺术。
但幸运的是,我们见证了算力平民化的奇迹:从冻结庞大主干网络、只在几十兆参数里闪烁智慧光芒的 LoRA 矩阵;到用复杂的统计学原理打破浮点数边界的 QLoRA 量化;从用时间换取空间的梯度检查点,到将优化状态如手术刀般切割的 ZeRO 协议;再到抛弃臃肿强化学习、直击人类偏好本质的 DPO 算法。
这些在开源社区无数极客日夜奋战中诞生的算力黑科技,彻底打破了科技巨头对顶级 AI 能力的物理垄断。它们使得每一个资源匮乏的防御团队,每一支只有几台老旧服务器的红蓝实验室,都拥有了为大模型注入底层"暗黑知识"、亲手锻造专属安全 AI 的能力。在这个时代,"算力贫穷"不再是缴械投降的借口,极致的工程优化能力,本身就构筑成了新一代安全架构师最深的护城河。
然而,当我们倾尽全力,将一个满腹经纶、深谙攻防之道的安全大模型成功部署在企业内网后,这仅仅是 MLSecOps(机器学习安全运营)漫漫长征的第一步。
大模型不是一个与世隔绝的铁罐头。为了让它产生实际的生产力,我们需要通过 API 将它与企业的防火墙、工单系统、甚至外部的威胁情报库打通。但站在防御者的视角,我们必须面对一个更加令人毛骨悚然的现实:连接大模型的 API 本身,正在成为企业网络中最脆弱、最致命的攻击面。
如果黑客通过恶意构造的载荷,直接将包含提示词注入(Prompt Injection)的畸形数据塞入了大模型的神经中枢?如果大模型在不受限的情况下,通过 API 将核心数据库的机密"顺手"写进了对外生成的报告中?我们将面临一场由 AI 亲手引发的内部沦陷。
在接下来的《硅基之盾》第四十三篇《API 安全:保护 AI 应用的交互接口》中,我们将从微观的算力优化战场抽身,重返宏观的网络对抗前线。我们将系统性剖析 LLM 应用架构中独有的脆弱性(如 OWASP Top 10 for LLM),并探讨如何在流量网关、请求限流与上下文清洗层,为这些强大的硅基智能体,构筑起一道坚不可摧的数字长城。敬请期待!
陈涉川
2026年03月13日