01. 什么是 Keepalived?它解决了什么痛点?
在没有 Keepalived 之前,我们的架构通常是这样的:客户端访问一台 Nginx 或 HAProxy,这台代理服务器再把流量分给后端的 Web 服务器。
- 痛点: 这台代理服务器就是整个集群的"阿喀琉斯之踵"。一旦它宕机、断网或硬件损坏,整个系统直接瘫痪,后端有再多服务器也无济于事。
Keepalived 的登场: Keepalived 是一款用 C 语言编写的路由软件,它的核心目标是提供高可用性 (High Availability)。它通过在多台代理服务器之间虚拟出一个或多个 IP(VIP,Virtual IP),让客户端只认识这个 VIP。当主服务器挂掉时,备用服务器会瞬间接管 VIP,整个过程对客户端几乎是透明的。
02. 核心灵魂:VRRP 协议详解
要彻底搞懂 Keepalived,就必须理解它赖以生存的底层协议------VRRP (Virtual Router Redundancy Protocol,虚拟路由冗余协议)。
VRRP 最初是为了解决路由器单点故障设计的,Keepalived 完美地借用了这个思想。
VRRP 的工作机制(通俗版):
-
角色划分: 在一个 Keepalived 集群中,服务器被划分为 Master (主节点) 和 Backup (备节点)。
-
虚拟 IP (VIP): 它们共同持有一个或多个 VIP。正常情况下,VIP 绑定在 Master 的网卡上,所有流量都由 Master 处理。
-
心跳检测 (组播): Master 会以极高的频率(通常是每秒 1 次)向网络中发送 VRRP 组播包(默认地址是
224.0.0.18),告诉所有人:"我还活着,我是老大"。 -
无缝接管 (Failover): Backup 节点会一直安静地监听这些心跳包。如果 Backup 在设定好的时间(超时时间)内没有收到 Master 的心跳,它就会认为 Master 已经挂了。此时,优先级最高的 Backup 会立刻挺身而出,抢占 VIP,成为新的 Master,继续接客。
-
原主恢复: 当原来的 Master 修复并重新上线后,如果它的配置优先级更高,它会重新夺回 VIP(这是抢占模式,也可以配置为非抢占模式避免来回切换的抖动)。
03. Keepalived 的两大核心组件
很多人以为 Keepalived 只能做 VIP 飘移,其实它不仅是个"接盘侠",还是个优秀的"监工"。它由两大核心模块组成:
-
VRRP Stack (VRRP 协议栈): 负责上面提到的 VIP 选举、心跳发送和故障接管。专门解决前端负载均衡器的高可用问题。
-
Checkers (健康检查模块): 负责探测后端真实服务器(Real Server)或者本地业务(如本机 Nginx 进程)的存活状态。
-
如果后端某台 Web 服务器挂了,Checkers 会自动把它从负载均衡池里踢出。
-
如果恢复了,再自动加回来。
-
它可以执行 TCP 连接测试、HTTP 状态码获取、甚至是自定义的 Shell 脚本。
-
04. Keepalived 的黄金搭档 (经典架构)
在实际生产环境中,Keepalived 很少单打独斗,它通常有两类黄金搭档:
-
Keepalived + LVS: 这是绝配(也是 Keepalived 最初设计的初衷)。Keepalived 内部原生支持 LVS 配置,你甚至不需要手动去敲
ipvsadm命令,直接在 Keepalived 的配置文件里写几行,它就会自动帮你生成 LVS 规则。 -
Keepalived + Nginx / HAProxy: 这是目前七层 Web 架构中最主流的高可用方案。Keepalived 负责管理 VIP,辅以自定义脚本(vrrp_script)去监控 Nginx 或 HAProxy 的进程状态。如果 Nginx 死掉,脚本触发 Keepalived 自行降级,从而实现主备切换。
05.实验讲解
一、环境配置
1. 实验架构规划
我们需要准备两台虚拟机作为 Keepalived 节点,并规划一个漂移的虚拟 IP (VIP)。
| 角色 | 主机名 | IP 地址 (NAT网卡) | 操作系统 | 备注 |
|---|---|---|---|---|
| 测试机 (Client) | client |
172.25.254.100 |
RHEL | 用于发起测试请求 |
| Keepalived 主节点 | ka1.timinglee.org |
172.25.254.10 |
RHEL | Master 节点 |
| Keepalived 备节点 | ka2.timinglee.org |
172.25.254.20 |
RHEL | Backup 节点 |
| 虚拟 IP (VIP) | 无 | 172.25.254.200 |
无 | 客户端最终访问的 IP |
2. 基础环境配置 (在 ka1 和 ka2 上分别执行)
第一步:配置主机名
清晰的主机名是集群管理的第一步。
在 Node 1 执行:
bash
hostnamectl set-hostname ka1.timinglee.org在 Node 2 执行:
bash
hostnamectl set-hostname ka2.timinglee.org第二步:配置静态 IP 网络
在 ka1 (Node 1) 上执行:
bash
# 修改 IP、网关和 DNS,并将获取方式改为手动 (manual)
nmcli connection modify eth0 ipv4.addresses 172.25.254.10/24 ipv4.gateway 172.25.254.2 ipv4.dns 114.114.114.11 ipv4.method manual
# 重新激活网卡使配置生效
nmcli connection up eth0在 ka2 (Node 2) 上执行:
bash
nmcli connection modify eth0 ipv4.addresses 172.25.254.20/24 ipv4.gateway 172.25.254.2 ipv4.dns 114.114.114.11 ipv4.method manual
nmcli connection up eth0第三步:关闭安全限制 (避免实验干扰)
在学习高可用协议时,SELinux 和防火墙常常会拦截 VRRP 组播包。为了集中精力学习 Keepalived,我们先将它们关闭。
在两台机器上都执行:
bash
# 1. 临时并永久关闭 SELinux
setenforce 0
sed -i 's/^SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
# 2. 关闭并禁用 Firewalld
systemctl stop firewalld
systemctl disable firewalld第四步:时间同步 (可选但推荐)
集群环境对时间一致性有要求,虽然基础 VIP 漂移影响不大,但养成好习惯很重要。
bash
# RHEL 9 默认使用 chrony
systemctl enable --now chronyd3. 软件安装
提前配置好本地 YUM/DNF 仓库(或者如果你已经能连外网),直接使用包管理器安装 Keepalived。RHEL 9 官方仓库中自带了稳定版的 Keepalived。
在 ka1 和 ka2 上都执行:
bash
dnf install keepalived -y安装完成后,可以通过以下命令确认版本:
bash
keepalived -v
二、主备虚拟路由
这是 Keepalived 最经典、也是最基础的实验:主备模式(Master-Backup)的 VIP 漂移。
在这个实验中,我们要实现的目标是:让 ka1 和 ka2 共同争夺 172.25.254.200 这个虚拟 IP (VIP)。正常情况下 VIP 绑定在 ka1 上;如果 ka1 宕机,VIP 瞬间无缝切换到 ka2。
1. 配置 KA1 (Master 主节点)
在 ka1 (172.25.254.10) 上编辑 Keepalived 的主配置文件。RHEL 9 安装后默认会提供一个示例文件,我们可以直接清空重写,保持干净。
bash
vim /etc/keepalived/keepalived.conf
bash
! Configuration File for keepalived
# 1. 全局配置
global_defs {
router_id KA1_NODE # 路由 ID,集群内唯一,通常写主机名
}
# 2. VRRP 实例配置 (定义一个高可用集群)
vrrp_instance VI_1 {
state MASTER # 初始状态定义为 MASTER (主)
interface eth0 # 绑定 VIP 的物理网卡 (如果是 ens160 请修改)
virtual_router_id 50 # 虚拟路由 ID (VRID),同一个集群的主备节点必须保持一致!(0-255)
priority 100 # 优先级。数字越大优先级越高,Master 的优先级必须大于 Backup
advert_int 1 # 心跳包发送间隔,默认 1 秒
# 通信认证机制 (防止同一个局域网内其他人的 Keepalived 捣乱)
authentication {
auth_type PASS # 密码认证模式
auth_pass 1111 # 集群内的主备节点密码必须一致
}
# 声明 VIP 地址
virtual_ipaddress {
172.25.254.200/24 dev eth0 label eth0:1 # 绑定在 eth0 上,并打上标签方便查看
}
}2. 配置 KA2 (Backup 备节点)
在 ka2 (172.25.254.20) 上编辑配置文件。备节点的配置与主节点几乎一样,只有三个关键点不同。
bash
! Configuration File for keepalived
global_defs {
router_id KA2_NODE # 路由 ID 改为节点 2 的名字
}
vrrp_instance VI_1 {
state BACKUP # 初始状态必须定义为 BACKUP (备)
interface eth0
virtual_router_id 50 # 必须与 Master 相同 (50)
priority 80 # 优先级必须比 Master 低 (比如设为 80)
advert_int 1
authentication {
auth_type PASS
auth_pass 1111 # 密码必须与 Master 相同
}
virtual_ipaddress {
172.25.254.200/24 dev eth0 label eth0:1
}
}3. 启动服务与验证 (见证 VIP 漂移)
配置完成后,我们来启动服务并模拟故障。
第一步:启动并检查 Master (KA1)
在 ka1 上启动 Keepalived:
bash
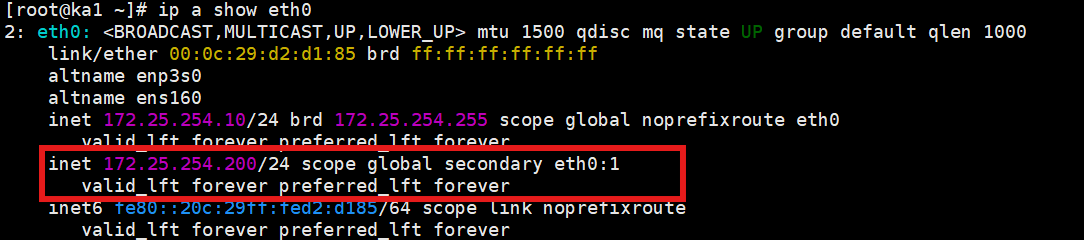
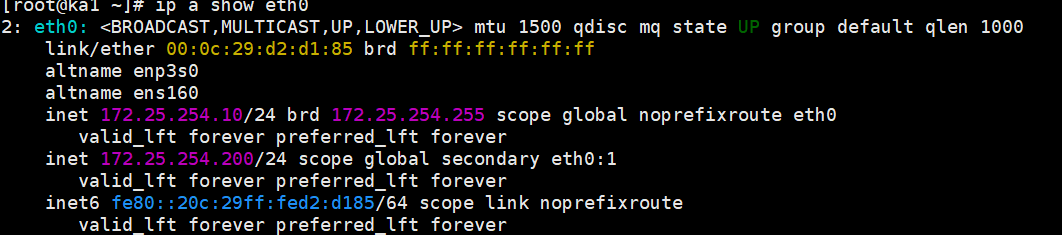
systemctl enable --now keepalived检查 VIP 是否成功绑定:
bash
ip a show eth0在输出中能看到**
inet 172.25.254.200/24 scope global secondary eth0:1**这说明 KA1 成功拿到了 VIP。
第二步:启动并检查 Backup (KA2)
在 ka2 上启动 Keepalived:
bash
systemctl enable --now keepalived检查 VIP:
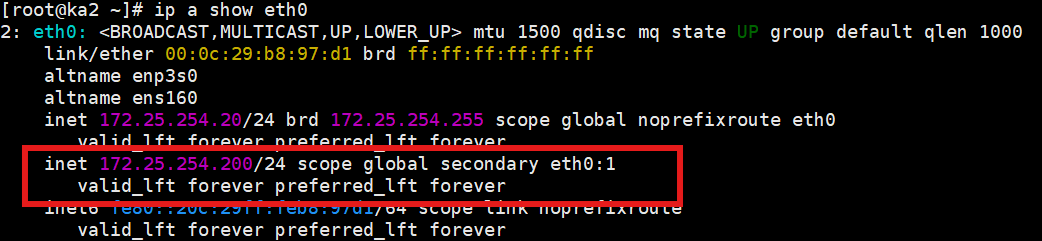
bash
ip a show eth0你不应该看到 200 这个 IP。因为目前 KA1 活着,KA2 作为小弟只能安静地待着。

第三步:模拟故障,测试 VIP 漂移 (Failover)
现在,我们把 KA1 的服务停掉,模拟宕机。
在 KA1 上执行:
bash
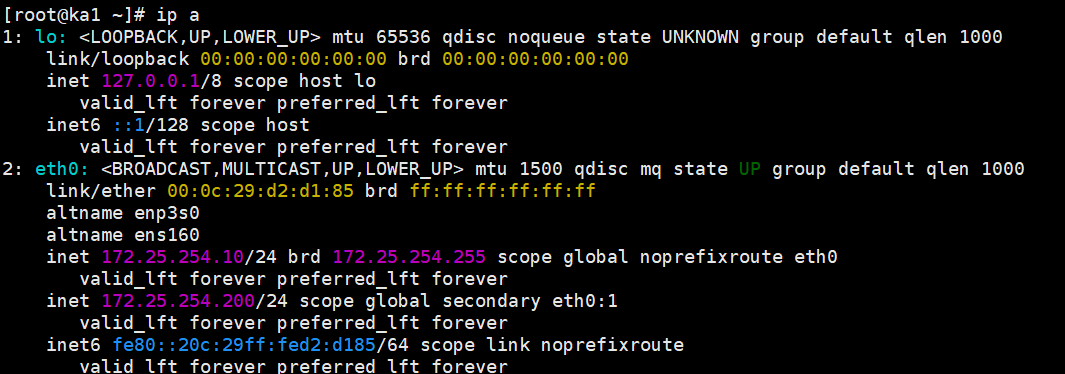
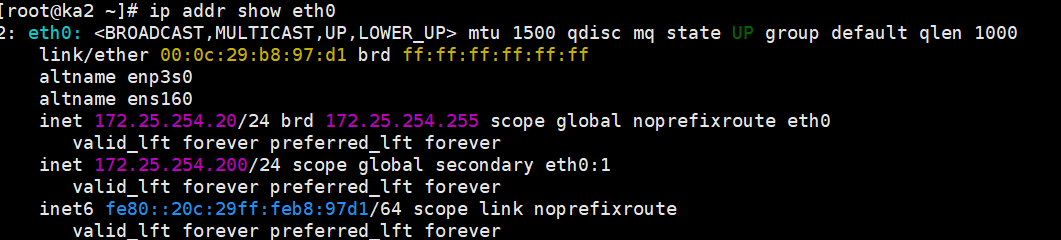
systemctl stop keepalived去 KA2 上查看:
bash
ip a show eth0此时
172.25.254.200出现在了 KA2 的网卡上!接管成功。
第四步:模拟修复,测试抢占 (Preemption)
把 KA1 修好,重新启动服务。
在 KA1 上执行:
bash
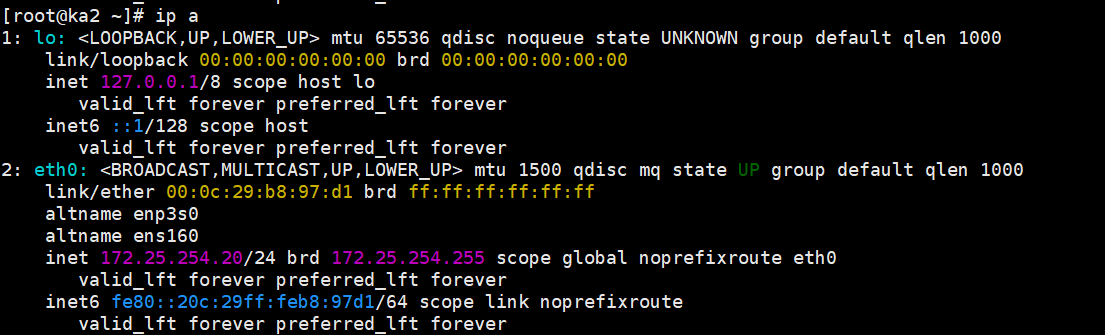
systemctl start keepalived再次去 KA1 和 KA2 上用 ip a 查看
VIP
172.25.254.200又从 KA2 回到了 KA1 身上。默认情况下,Keepalived 工作在抢占模式(Preempt)。KA1 恢复后,发现当前发心跳的 KA2 优先级(80)比自己(100)低,于是毫不客气地抢回了 VIP。
第五步、抓包看底层原理:
在客户端 (172.25.254.100) 或者任意节点上执行抓包(过滤 VRRP 协议)
bash
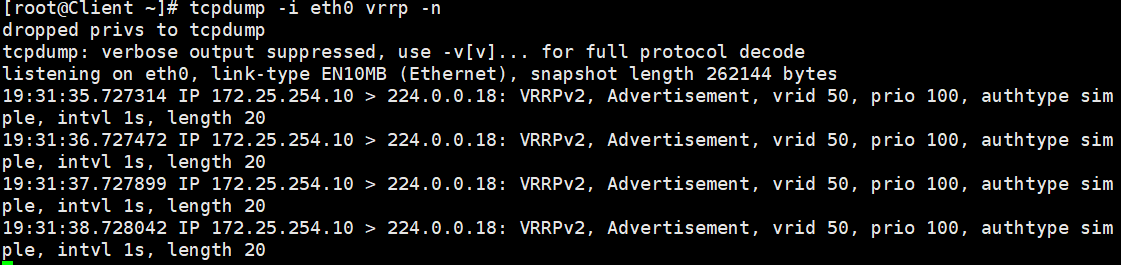
tcpdump -i eth0 vrrp -n你会看到类似这样的输出:
172.25.254.10 > 224.0.0.18: vrrp 172.25.254.10 vrid 50 prio 100 authtype simple intvl 1s这证明了 Master 正在以每秒 1 次的频率向224.0.0.18组播地址发送心跳包。
三、日志分离
在默认情况下,Keepalived 会把所有的日志信息(包括心跳发送、状态切换、报错等)全部塞进系统的全局日志文件 /var/log/messages 里。
痛点: 当系统里跑着几十个服务时,/var/log/messages 里的信息会像瀑布一样刷屏。一旦发生主备切换或者脑裂故障,你想从这海量的系统日志里去翻找 Keepalived 的故障点,简直是"大海捞针"。
目标: 让 Keepalived 的日志"独立门户",单独输出到 /var/log/keepalived.log 中。
在 RHEL 9.6 中,这个操作主要分为两步:修改 Keepalived 的启动参数 和 配置 rsyslog 路由。
1. 修改 Keepalived 启动参数 (指定日志通道)
我们需要告诉 Keepalived:"以后你的日志别随便丢,统统发给 local0 这个专门的设施(facility)。"
在 KA1 和 KA2 上分别执行:
编辑 Keepalived 的系统环境变量配置文件:
bash
vim /etc/sysconfig/keepalived找到 KEEPALIVED_OPTIONS 这一行,把它修改为:
bash
KEEPALIVED_OPTIONS="-D -S 0"参数解释:
-
-D: 详细日志输出 (Detailed logging)。 -
-S 0: 指定 syslog 的 facility 为local0(0 代表 local0,1 代表 local1,以此类推,最大到 7)。
2. 配置 Rsyslog (路由日志到独立文件)
现在 Keepalived 已经把日志发给 local0 了,接下来我们要告诉系统的日志管家(rsyslog):"凡是收到 local0 的日志,都给我存到指定的文件夹里。"
编辑 rsyslog 的主配置文件:
bash
vim /etc/rsyslog.conf进行两处修改:
1.定义 Keepalived 的专属日志路径: 在文件的末尾(或者任何空白处)加上这一行:
bash
local0.* /var/log/keepalived.log
(意思是:local0 设施的所有级别日志,都写入 /var/log/keepalived.log)2.防止日志"一鱼两吃"(关键细节!): 如果不做这一步,日志虽然去了 keepalived.log,但依然会 出现在 /var/log/messages 里。 找到记录 /var/log/messages 的那一行(大约在第 48 行左右),在后面追加 local0.none:
修改前:
bash
*.info;mail.none;authpriv.none;cron.none /var/log/messages修改后:
bash
*.info;mail.none;authpriv.none;cron.none;local0.none /var/log/messages3. 重启服务并验证
配置完成后,重启相关的两个服务让配置生效。
bash
# 先重启日志服务,再重启 keepalived
systemctl restart rsyslog
systemctl restart keepalived见证奇迹的时刻:
1.查看专属日志文件是否生成:
bash
ls -l /var/log/keepalived.log

2.实时查看 Keepalived 日志:
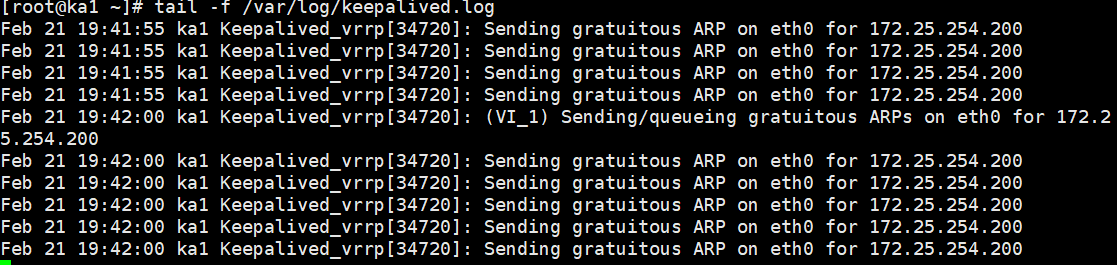
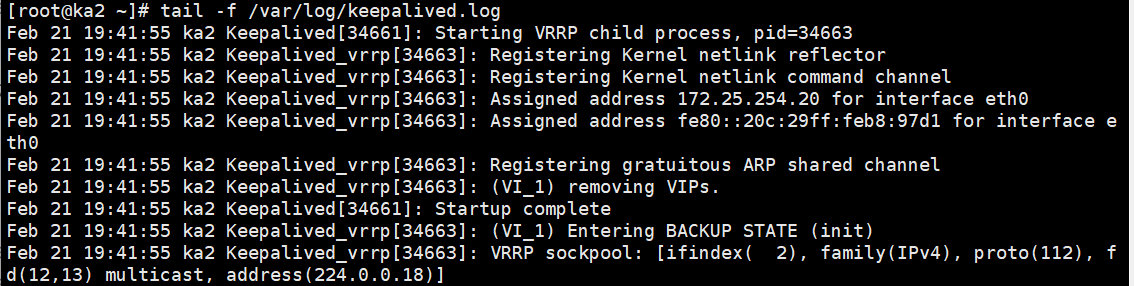
bash
tail -f /var/log/keepalived.log你应该能清晰地看到类似这样的输出,干干净净,全是 Keepalived 自己的事
3.测试 VIP 漂移日志:
将KA1关闭,到KA2检查日志
可以非常清晰地看到 KA2 发现老大挂了,然后自己 **
Entering MASTER STATE**的全过程

四、独立子配置文件
在企业级环境中,一台 Keepalived 服务器可能需要管理几十个 VIP,甚至还要结合 LVS 挂载上百个真实的后端节点(Real Server)。如果把所有配置都塞进主配置文件 /etc/keepalived/keepalived.conf 里,这个文件会变得又臭又长,极难维护,且容易因为改错一行代码导致全局崩溃。
目标: 利用 include 指令,将主配置文件进行"瘦身",把不同的业务(例如不同的 VIP 或 VRRP 实例)拆分到独立的子配置文件中。
1. 创建子配置目录
为了规范管理,我们需要在 Keepalived 的配置目录下创建一个专门存放子配置文件的文件夹(类似于 Nginx 的 conf.d)。
在 KA1 和 KA2 上分别执行:
bash
mkdir -p /etc/keepalived/conf.d2. 拆分配置:编写子配置文件
我们将之前写在主配置文件里的 vrrp_instance VI_1 整个代码块"剥离"出来,放进独立的文件中。 为了见名知意,我们通常用 VIP 的地址或者业务名称来命名子文件。
在 KA1 (Master) 上执行: 创建并编辑子配置文件:
bash
vim /etc/keepalived/conf.d/172.25.254.200.conf粘贴 vrrp_instance 块(保留 Master 的属性):
bash
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.25.254.200/24 dev eth0 label eth0:1
}
}在 KA2 (Backup) 上执行同样的操作:
bash
vim /etc/keepalived/conf.d/172.25.254.200.conf粘贴 Backup 的配置:
bash
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 50
priority 80
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.25.254.200/24 dev eth0 label eth0:1
}
}3. "瘦身"主配置文件并引入子配置
现在,我们要把主配置文件里臃肿的代码删掉 ,只保留全局配置,并使用 include 指令把刚才的目录包含进来。
在 KA1 和 KA2 上修改主配置文件:
bash
vim /etc/keepalived/keepalived.conf修改后的内容应该非常精简,长这样:
bash
! Configuration File for keepalived
# 1. 全局配置保持不变
global_defs {
router_id KA1_NODE # 注意:KA2 上这里是 KA2_NODE
}
# 2. 引入子配置文件 (核心指令)
# 这一行告诉 Keepalived:去这个目录下把所有以 .conf 结尾的文件都加载进来
include /etc/keepalived/conf.d/*.conf4. 验证拆分是否成功
重启 Keepalived 让配置生效。
bash
systemctl restart keepalived查看日志:
bash
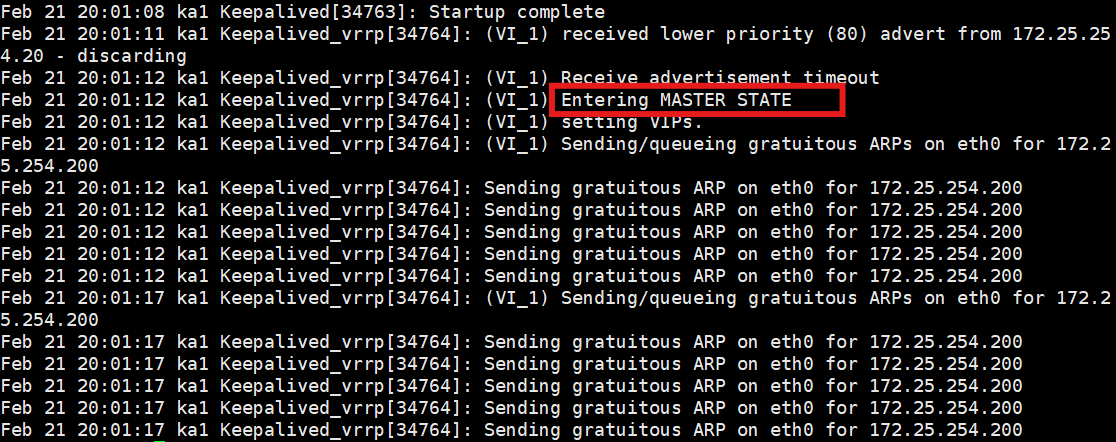
tail -20 /var/log/keepalived.log如果在 KA1 的日志里没有报错,并且平滑地输出了
Entering MASTER STATE,说明主配置成功加载了子配置文件!
检查 VIP 是否依然存在:
bash
ip a show eth0如果 KA1 上依然牢牢绑定着
172.25.254.200,恭喜你,你的集群架构现在已经具备了企业级的可扩展性!
附言: 在 DevOps 和自动化运维时代,独立子配置 是必备技巧。想象一下,当我们使用 Ansible 或 CI/CD 流水线去自动部署一个新的高可用业务时,我们绝不想去用复杂的正则替换去修改主配置文件。有了 include,自动化脚本只需要把新业务的 .conf 文件丢进 conf.d/ 目录,然后 **systemctl reload keepalived**即可,0 风险,高效率!
五、非抢占模式及延迟抢占
在默认的抢占模式(Preempt)下,如果原 Master(KA1)宕机,VIP 会飘到 Backup(KA2)。当 KA1 修复并重启后,由于它优先级高,它会立刻把 VIP 抢回来。
- 痛点: 这种"立刻抢回"会导致网络产生两次剧烈抖动(KA1死掉抖一次,KA1复活又抖一次)。而且,如果 KA1 刚开机,后端的业务进程(比如 Java 或数据库缓存)还没完全启动好,流量一过来直接全部报错(这叫"业务未预热")。
为了解决这个问题,Keepalived 提供了两种优雅的方案:非抢占模式(Nopreempt) 和 延迟抢占(Preempt Delay)。
方案 A:非抢占模式 (Nopreempt)
核心逻辑: "谁拿到 VIP 谁就一直当老大,除非老大死了,否则原配复活了也不能抢。"
踩坑预警:
配置非抢占模式有一个极其重要的前提 :集群中所有节点的初始状态(state)必须全部设置为 BACKUP !如果你把 KA1 设置为 MASTER,即使加了 nopreempt 参数,它复活后依然会强行抢占。
配置步骤
修改我们上一个实验分离出来的子配置文件:
在 KA1 (172.25.254.10) 上执行:
bash
vim /etc/keepalived/conf.d/172.25.254.200.conf
bash
vrrp_instance VI_1 {
state BACKUP # 【关键修改 1】强行改为 BACKUP
interface eth0
virtual_router_id 50
priority 100 # 优先级依然是 100,保持最高
nopreempt # 【关键修改 2】添加非抢占指令
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.25.254.200/24 dev eth0 label eth0:1
}
}在 KA2 (172.25.254.20) 上执行:
KA2 本来就是 BACKUP,优先级 80,理论上加不加 nopreempt 都可以,但为了规范,建议也加上。
bash
vrrp_instance VI_1 {
state BACKUP # 保持 BACKUP
interface eth0
virtual_router_id 50
priority 80 # 优先级 80
nopreempt # 添加非抢占指令
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.25.254.200/24 dev eth0 label eth0:1
}
}测试验证
重启两台机器的 Keepalived:systemctl restart keepalived
因为 KA1 优先级高,最开始启动时,VIP 依然会被 KA1 拿到。
模拟宕机: 停掉 KA1 (systemctl stop keepalived),VIP 飘到 KA2。
见证奇迹: 启动 KA1 (systemctl start keepalived)。
去 KA1 和 KA2 上分别敲 ip a show eth0。
VIP 依然牢牢绑定在 KA2 上!KA1 即使优先级高,也只能乖乖当小弟,直到 KA2 宕机。

方案 B:延迟抢占 (Preempt Delay)
核心逻辑: "原配复活后,先等一段时间(比如 30 秒),让本地的 Nginx/Java 等业务完全启动预热完毕,然后再把 VIP 抢回来。"
这也是生产环境中最常用的妥协方案,既保证了主节点最终能接管流量,又给了它喘息(预热)的时间。
配置步骤
注意: 延迟抢占的生效前提同样是两台机器必须都是 BACKUP 状态!
我们需要把刚才的 nopreempt 替换为 preempt_delay。
修改 KA1 的子配置文件:
bash
vim /etc/keepalived/conf.d/172.25.254.200.conf
bash
vrrp_instance VI_1 {
state BACKUP # 必须是 BACKUP
interface eth0
virtual_router_id 50
priority 100
# nopreempt # 把上一节的这行删掉或注释掉
preempt_delay 30 # 【关键修改】延迟抢占,等待 30 秒
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.25.254.200/24 dev eth0 label eth0:1
}
}KA2 的配置保持 BACKUP 和优先级 80 即可,不需要做特殊修改。
测试验证
建议准备两个终端窗口,一边看日志,一边查 IP。
重启双方服务:systemctl restart keepalived。KA1 拿到 VIP。
停掉 KA1:systemctl stop keepalived。VIP 飘到 KA2。
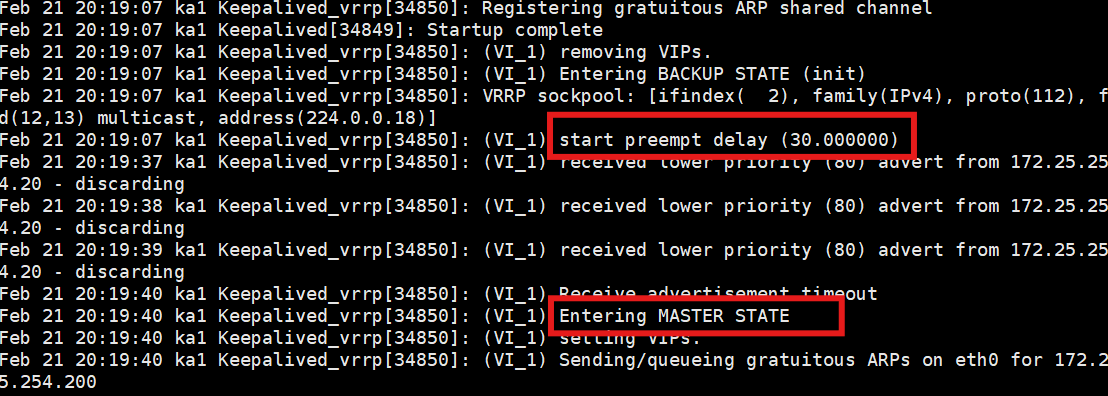
关键操作: 启动 KA1 (systemctl start keepalived),然后立即 去 KA1 上看 VIP (ip a)!
第 1~29 秒: KA1 上没有 VIP。此时流量依然在 KA2 上处理。
在 KA1 上实时监控日志:tail -f /var/log/keepalived.log。
第 30 秒: 你会在日志里看到倒计时结束,KA1 强制进入 MASTER 状态并接管 VIP!
在企业实际生产中,选哪种模式?
-
双机性能完全一致: 推荐非抢占模式 (
nopreempt)。反正谁干活都一样,没必要来回切产生抖动。 -
主备性能差异大: (比如主节点是 64核,备节点是 16核用来应急的),推荐延迟抢占 (
preempt_delay 300)。备节点扛不住太久,主节点修好后必须拿回控制权,但要留出 3-5 分钟的业务预热时间。
六、单播模式和告警
在真实的生产环境中,我们经常会遇到两个棘手的问题:
-
网络限制(脑裂元凶): 很多公有云(比如阿里云、腾讯云、AWS)或者安全管控严格的机房,默认是完全屏蔽组播流量的(包括 VRRP 的 224.0.0.18) 。这会导致 Keepalived 节点之间互相听不到心跳,纷纷认为对方死了,从而同时抢占 VIP,造成严重的**"脑裂 (Split-Brain)"**。
-
缺乏感知: VIP 悄悄发生了漂移,业务虽然没断,但运维人员如果没看日志就完全不知道。等真正出大故障时,往往已经错过了最佳排查时机。
今天我们就来用单播模式 (Unicast) 解决网络限制,用邮件/脚本告警 (Notify) 解决状态感知!
第一部分:配置单播模式 (Unicast)
核心逻辑: 既然大喇叭(组播)不让喊,那我们就给对方直接打电话(点对点单播)。
1. 修改 KA1 的子配置文件
bash
vim /etc/keepalived/conf.d/172.25.254.200.conf在 vrrp_instance VI_1 块中,加入单播的源 IP 和目标 IP(注意:删除或注释掉之前的多余测试配置,保持简洁):
bash
vrrp_instance VI_1 {
state MASTER # 恢复为 MASTER (为了方便测试)
interface eth0
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
# === 单播模式核心配置 ===
unicast_src_ip 172.25.254.10 # 本机 IP (发送心跳的源 IP)
unicast_peer {
172.25.254.20 # 对端 IP (发给谁?如果有多个备节点,分行写)
}
# ==========================
virtual_ipaddress {
172.25.254.200/24 dev eth0 label eth0:1
}
}2. 修改 KA2 的子配置文件
bash
vrrp_instance VI_1 {
state BACKUP # 保持 BACKUP
interface eth0
virtual_router_id 50
priority 80
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
# === 单播模式核心配置 ===
unicast_src_ip 172.25.254.20 # 本机 IP 变成了 KA2
unicast_peer {
172.25.254.10 # 对端 IP 变成了 KA1
}
# ==========================
virtual_ipaddress {
172.25.254.200/24 dev eth0 label eth0:1
}
}3. 抓包验证单播是否生效
重启双方服务:systemctl restart keepalived
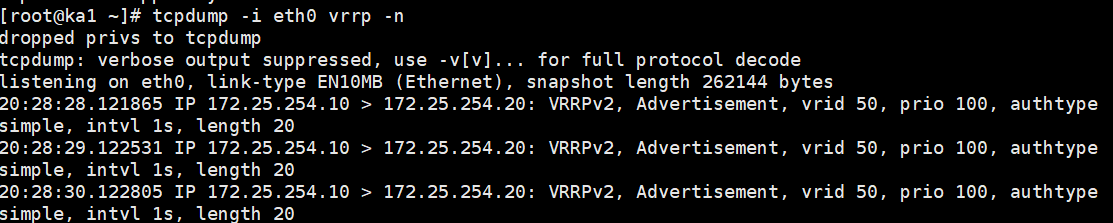
在 KA1 或 KA2 上执行极其关键的抓包命令:
bash
tcpdump -i eth0 vrrp -n以前你会看到发往
224.0.0.18的包,现在你会清晰地看到点对点的通信
第二部分:配置状态切换告警 (Notify)
Keepalived 提供了一个非常强大的接口:当节点状态发生变化(变成 MASTER、变成 BACKUP、或者 FAULT 故障)时,可以自动触发执行一个本地的 Shell 脚本。
1. 编写全能告警脚本
我们写一个脚本,让它在状态切换时,把告警信息写入一个专门的日志文件(在生产中,你可以把写入日志的代码换成发送钉钉/企业微信机器人消息,或者发邮件的命令)。
在 KA1 和 KA2 上创建脚本目录和文件:
bash
mkdir -p /etc/keepalived/scripts
vim /etc/keepalived/scripts/notify.sh粘贴以下通用告警脚本:
bash
#!/bin/bash
# 接收 Keepalived 传过来的参数
# $1 = "GROUP"|"INSTANCE"
# $2 = 实例名称 (比如 VI_1)
# $3 = 切换后的状态 ("MASTER"|"BACKUP"|"FAULT")
TYPE=$1
NAME=$2
STATE=$3
# 获取当前时间
TIME=$(date "+%Y-%m-%d %H:%M:%S")
# 获取本机 IP
IP=$(hostname -I | awk '{print $1}')
# 定义告警动作 (这里以记录到文件为例,你也可以改成 curl 发送钉钉 webhook)
LOGFILE="/var/log/keepalived_notify.log"
echo "[${TIME}] [ALERT] 节点 ${IP} 的 ${TYPE} ${NAME} 状态已切换为: ${STATE} !!!" >> ${LOGFILE}赋予脚本执行权限(必做,否则 Keepalived 无法执行):
bash
chmod +x /etc/keepalived/scripts/notify.sh2. 在 Keepalived 中调用脚本
打开刚才单播实验用到的子配置文件:
bash
vim /etc/keepalived/conf.d/172.25.254.200.conf在 vrrp_instance VI_1 块的最下方(virtual_ipaddress 下面)加入通知指令:
bash
virtual_ipaddress {
172.25.254.200/24 dev eth0 label eth0:1
}
# === 状态告警触发器 ===
notify_master "/etc/keepalived/scripts/notify.sh INSTANCE VI_1 MASTER"
notify_backup "/etc/keepalived/scripts/notify.sh INSTANCE VI_1 BACKUP"
notify_fault "/etc/keepalived/scripts/notify.sh INSTANCE VI_1 FAULT"
}
(KA1 和 KA2 都要加上这段 notify 配置,记得重启 systemctl restart keepalived 让他们生效)3. 模拟故障,测试告警
现在,激动人心的测试时刻到了!
停掉 KA1 的 Keepalived:systemctl stop keepalived
迅速去 KA2 上查看我们自定义的告警日志:
bash
cat /var/log/keepalived_notify.log预期结果: 你会看到 KA2 大声喊出自己变成了 MASTER!
[2026-02-21 20:36:08] [ALERT] 节点 172.25.254.20 的 INSTANCE VI_1 状态已切换为: MASTER !!!

再启动 KA1:systemctl start keepalived
去 KA1 上看日志:cat /var/log/keepalived_notify.log
预期结果: KA1 记录了自己夺回权力的过程:
[2026-02-21 20:37:24] [ALERT] 节点 172.25.254.10 的 INSTANCE VI_1 状态已切换为: MASTER !!!同时 KA2 的日志里会增加一条降级为BACKUP的记录。

第三部分:结合mailx和SMTP服务完成真实邮箱告警
1. 准备工作:获取邮箱的"授权码"(推荐使用网易邮箱)
在使用第三方脚本发邮件时,绝对不能使用你的邮箱登录密码,必须使用"授权码"。
-
登录网易 163 邮箱网页版。
-
点击顶部的 "设置" -> "POP3/SMTP/IMAP"。
-
确保 SMTP 服务 已开启。
-
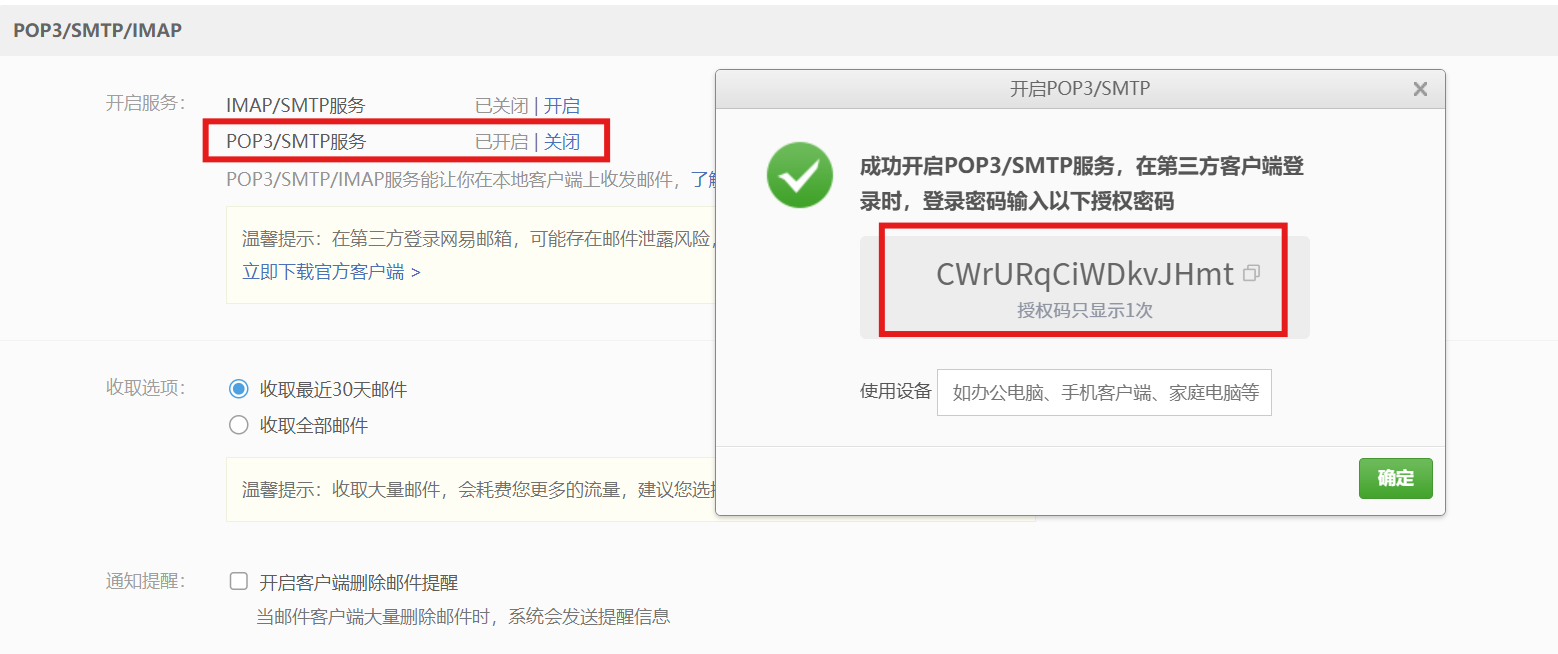
点击 "新增授权码" (或者管理授权码),按照提示用手机发个短信,系统会给你生成一串字母密码(比如:
ABCDEFGHIJKLMN)。 请把这串授权码复制保存下来,下面马上要用。
2. 配置 Linux 的发邮件工具 (mailx)
我们需要告诉 Linux 系统,如何使用你的 163 邮箱账号来往外发邮件。
在 KA1 和 KA2 上分别执行以下操作:
第一步:安装 mailx(如果还没安装)
bash
dnf install s-nail -y
#因为 RHEL 9 将底层工具换成了 s-nail,配置文件的位置没变,依然是 /etc/mail.rc。第二步:修改邮件配置文件
bash
vim /etc/mail.rc在此之前,赋予 Keepalived 最高执行权限
编辑 ka1 和 ka2 的主配置文件:vim /etc/keepalived/keepalived.conf
在 global_defs 模块中,加上一行 script_user root:
bash
global_defs {
router_id KA1_NODE
script_user root # <--- 加上这一行,强制以 root 身份执行所有外部脚本
}记得重启:systemctl restart keepalived
bash
# 开启 s-nail 的新版语法兼容
set v15-compat
# 你的 163 邮箱
set from=你的邮箱@163.com
# 【核心修改点】使用 mta 变量并加上 smtp:// 协议头!
set mta=smtp://smtp.163.com
# 认证配置保持不变
set smtp-auth=login
set smtp-auth-user=你的邮箱@163.com
set smtp-auth-password=你的真实授权码第三步:测试邮件发送 (必须先跑通这一步)
在终端里敲以下命令给自己发一封测试邮件:
bash
echo "这是一封来自 Keepalived 服务器的测试邮件。" | mail -s "Linux 邮件配置测试" 你的邮箱账号@163.com
3. 修改 Keepalived 告警脚本
现在,我们把之前写在 /etc/keepalived/scripts/notify.sh 里的代码升级一下,让它既写本地日志,又发邮件。
在 KA1 和 KA2 上修改脚本:
bash
vim /etc/keepalived/scripts/notify.sh将内容替换为以下进阶版脚本:
bash
#!/bin/bash
# 接收 Keepalived 传过来的参数
TYPE=$1
NAME=$2
STATE=$3
# 获取当前时间和本机 IP
TIME=$(date "+%Y-%m-%d %H:%M:%S")
IP=$(hostname -I | awk '{print $1}')
# === 邮件配置区 ===
# 接收告警的邮箱 (可以填你自己的 163 邮箱,也可以填 QQ 邮箱、公司邮箱)
TO_EMAIL="你的接收邮箱@xxx.com"
# 定义邮件的标题和正文
SUBJECT="[紧急告警] Keepalived 状态切换通知 - ${IP}"
BODY="[${TIME}] 监控节点 ${IP} 的 ${TYPE} ${NAME} 状态已发生切换!
当前最新状态为: 【 ${STATE} 】。
请运维人员立即登录服务器排查是否发生故障或网络抖动!"
# 1. 记录到本地日志备查
echo "[${TIME}] [ALERT] 节点 ${IP} 状态切换为 ${STATE}" >> /var/log/keepalived_notify.log
# 2. 触发邮件发送
echo "${BODY}" | mail -s "${SUBJECT}" ${TO_EMAIL}保存退出后,确保脚本依然有执行权限:
bash
chmod +x /etc/keepalived/scripts/notify.sh4. 终极故障演练
打开你的邮箱:
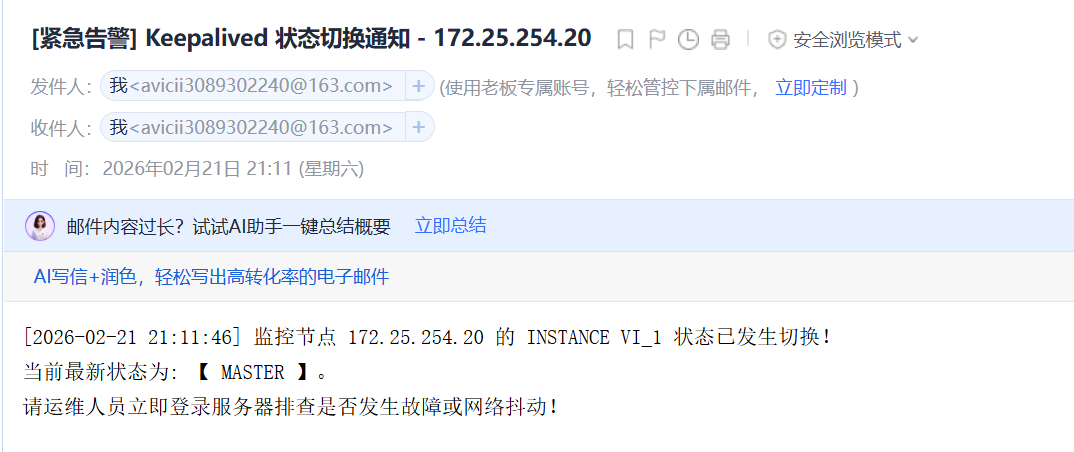
模拟灾难: 停掉 KA1 的 Keepalived
bash
systemctl stop keepalived查收邮件: 大约几秒钟后,你的邮箱就会收到一封标题为 [紧急告警] Keepalived 状态切换通知 - 172.25.254.20 的邮件,正文会告诉你它变成了 MASTER
恢复服务: 重新启动 KA1 的 Keepalived:
bash
systemctl start keepalived再次查收: 你会收到两封新邮件,一封是 KA1 宣布夺回主权(变回 MASTER),另一封是 KA2 委屈地宣布降级(变成 BACKUP)。
**附言:**在云计算时代,很多老旧的教程依然在教你使用组播模式,殊不知这在阿里云、AWS 等环境中会导致灾难性的'脑裂'。通过将 Keepalived 切换为单播模式 (Unicast),我们跨越了底层网络环境的限制。而结合 Notify 机制,我们将原本被动的日志查询,变成了主动的故障告警。配合邮箱、钉钉、飞书等 webhook,哪怕在半夜,当 VIP 发生漂移时,运维人员的手机也能第一时间收到救援信号。这,才是现代化高可用架构应有的姿态。
七、双主模式
在之前的**主备模式(Master-Backup)**中,无论配置得多好,总有一台备用服务器(KA2)在绝大多数时间里是在"睡大觉"的。老板花钱买了两台高配服务器,结果只有一台在干活,这显然是不划算的。
**双主模式(互为主备 / Active-Active)**就是为了解决"资源闲置"问题而诞生的。
1. 核心设计思路
它的原理非常巧妙:我们不在 Keepalived 里只跑一个 VRRP 实例,而是同时跑两个(甚至多个)实例。
-
实例 1 (VI_1): KA1 是老大(Master),KA2 是小弟(Backup)。负责管理 VIP 1。
-
实例 2 (VI_2): KA2 是老大(Master),KA1 是小弟(Backup)。负责管理 VIP 2。
最终效果: 正常情况下,KA1 拿着 VIP 1,KA2 拿着 VIP 2,两台机器都在干活(前端通过 DNS 轮询将域名解析到这两个 VIP 上)。 如果 KA1 宕机了,KA2 会瞬间接管 VIP 1,此时 KA2 一个人同时扛起 VIP 1 和 VIP 2,保证所有业务不断线!
2. 实验参数规划
为了不干扰之前的实验,我们规划两个全新的 VIP,并为它们分配不同的虚拟路由 ID (VRID)。
| 节点 | 实例 1 (VRID: 50) | 实例 2 (VRID: 60) |
|---|---|---|
| VIP 地址 | 172.25.254.200 |
172.25.254.201 |
| KA1 (172.25.254.10) | MASTER (优先级 100) | BACKUP (优先级 80) |
| KA2 (172.25.254.20) | BACKUP (优先级 80) | MASTER (优先级 100) |
3. 编写双主配置文件
既然我们使用了子配置文件的架构,那就把这两个实例分别写到两个文件里,这样管理起来最清晰。
第一步:配置 KA1 (172.25.254.10)
编辑实例 1 (KA1 是主): vim /etc/keepalived/conf.d/vip_200.conf
bash
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 50 # 实例 1 的 VRID 是 50
priority 100 # KA1 在这里是老大
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
unicast_src_ip 172.25.254.10
unicast_peer {
172.25.254.20
}
virtual_ipaddress {
172.25.254.200/24 dev eth0 label eth0:1
}
}编辑实例 2 (KA1 是备): vim /etc/keepalived/conf.d/vip_201.conf
bash
vrrp_instance VI_2 { # 实例名必须不同
state BACKUP # KA1 在这里是小弟
interface eth0
virtual_router_id 60 # 实例 2 的 VRID 必须与实例 1 不同!
priority 80 # 优先级降低
advert_int 1
authentication {
auth_type PASS
auth_pass 2222 # 密码可以不同
}
unicast_src_ip 172.25.254.10
unicast_peer {
172.25.254.20
}
virtual_ipaddress {
172.25.254.201/24 dev eth0 label eth0:2
}
}第二步:配置 KA2 (172.25.254.20)
完全镜像的操作,只是身份对调。
编辑实例 1 (KA2 是备): vim /etc/keepalived/conf.d/vip_200.conf
bash
vrrp_instance VI_1 {
state BACKUP # KA2 在这里是小弟
interface eth0
virtual_router_id 50
priority 80 # 优先级 80
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
unicast_src_ip 172.25.254.20
unicast_peer {
172.25.254.10
}
virtual_ipaddress {
172.25.254.200/24 dev eth0 label eth0:1
}
}编辑实例 2 (KA2 是主): vim /etc/keepalived/conf.d/vip_201.conf
4. 测试环节
配置完成后,分别在 KA1 和 KA2 上重启服务:
bash
systemctl restart keepalived测试 1:查看正常状态下的"和平分工"
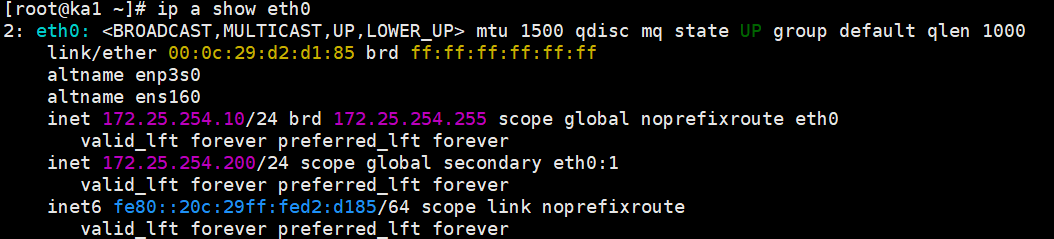
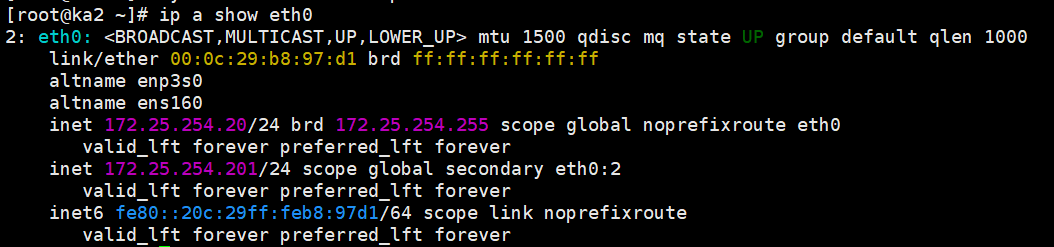
在 KA1 上敲 ip a show eth0,你应该只能看到 172.25.254.200。
在 KA2 上敲 ip a show eth0,你应该只能看到 172.25.254.201。
测试 2:模拟灾难,见证"一人分饰两角"
停掉 KA1 的服务,假装它宕机了:systemctl stop keepalived
立刻去 KA2 上查看 IP:ip a show eth0
预期结果: 你会在 KA2 的网卡上,同时看到
172.25.254.201和刚刚从 KA1 飘过来的172.25.254.200! KA2 成功接管了全盘业务!
如果在测试时,你收到了之前配置的告警邮件,那就说明整个高可用监控告警体系已经完全闭环了

八、IPVS高可用
Keepalived 名字里的 "Keep alive"(保持存活),最初不仅仅是为了保持代理服务器自身的存活,更是为了配合 LVS (IPVS) 去检查后端真实服务器(Real Server)的死活。
在这个实验中,我们将 Keepalived 与底层的 IPVS 内核模块结合。Keepalived 不仅要负责 VIP 的漂移,还要自动生成 LVS 负载均衡规则 ,并对后端 Web 服务器进行健康检查(如果后端挂了,自动踢出集群;恢复了,自动加回)。
1. 实验架构规划 (LVS-DR 模式)
为了最贴近生产环境,我们使用 LVS 性能最强悍的 DR(Direct Routing,直接路由)模式。
你需要额外准备两台充当后端的 Web 服务器(如果你没有额外的虚拟机,可以用你之前的其他测试机代替,只要能装 httpd/nginx 即可)。
-
LVS 调度器 Master (KA1):
172.25.254.10 -
LVS 调度器 Backup (KA2):
172.25.254.20 -
虚拟 IP (VIP):
172.25.254.200 -
真实服务器 1 (RS1): 假设为
172.25.254.11(需安装 httpd 并启动) -
真实服务器 2 (RS2): 假设为
172.25.254.12(需安装 httpd 并启动)
2. 后端真实服务器 (RS) 的核心配置 (防 ARP 冲突)
在 LVS-DR 模式下,有一个著名的**"ARP 抑制"** 问题**:VIP (.200) 不仅要绑定在 KA1/KA2 上,还** 必须绑定在后端的 RS1 和 RS2 的隐藏网卡(回环网卡 lo)上,否则后端无法直接把包回给客户端。
请在两台真实服务器 (RS1 / 172.25.254.11 和 RS2 / 172.25.254.12) 上执行以下操作:
安装并启动 Web 服务,写入测试页:
bash
dnf install httpd -y
systemctl enable --now httpd
# 写入不同的内容,方便测试轮询效果
echo "This is Real Server: $(hostname -I)" > /var/www/html/index.html

配置 VIP 绑定与 ARP 抑制 (极其关键): 直接复制这整段脚本在 RS1 和 RS2 终端执行:
bash
# 绑定 VIP 到回环网卡 (子网掩码必须是 32 位,即单主机 IP)
ip addr add 172.25.254.200/32 dev lo
# 修改内核参数,进行 ARP 抑制 (不响应针对 VIP 的 ARP 询问)
echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce3. 配置 Keepalived 调度器 (KA1 和 KA2)
现在回到我们的主战场 ka1 和 ka2。我们需要在 Keepalived 配置文件中追加 virtual_server 模块。
第一步:安装 ipvsadm 工具(用于查看规则)
虽然 Keepalived 会自动管理规则,但我们需要这个工具来验收成果。
bash
dnf install ipvsadm -y第二步:修改 Keepalived 子配置文件
我们继续修改之前建立的 172.25.254.200.conf 文件(为了避免太复杂,建议你先把双主模式的另一个 VIP 实例停掉或注释掉,专注这一个)。
在 KA1 (172.25.254.10) 上编辑: vim /etc/keepalived/conf.d/172.25.254.200.conf
在 vrrp_instance 块的下面 ,新增 virtual_server 块:
bash
# --- 上半部分是之前的 VIP 漂移配置 ---
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
unicast_src_ip 172.25.254.10
unicast_peer {
172.25.254.20
}
virtual_ipaddress {
172.25.254.200/24 dev eth0 label eth0:1
}
}
# --- 下半部分是新增的 LVS 负载均衡与健康检查 ---
# 定义一个虚拟服务器,监听 VIP 172.25.254.200 的 80 端口
virtual_server 172.25.254.200 80 {
delay_loop 6 # 健康检查的时间间隔 (秒)
lb_algo rr # LVS 调度算法 (rr 轮询,wrr 加权轮询等)
lb_kind DR # LVS 工作模式 (DR 直接路由,NAT,TUN)
protocol TCP # 转发协议
# 定义真实服务器 RS1
real_server 172.25.254.11 80 {
weight 1 # 权重
# TCP 健康检查配置
TCP_CHECK {
connect_timeout 3 # 连接超时时间 3 秒
retry 3 # 重试次数 3 次
delay_before_retry 3 # 每次重试间隔 3 秒
}
}
# 定义真实服务器 RS2
real_server 172.25.254.12 80 {
weight 1
TCP_CHECK {
connect_timeout 3
retry 3
delay_before_retry 3
}
}
}KA2 (172.25.254.20) 的配置: 完全复制上面的 virtual_server 块,追加到 KA2 的配置文件中(别忘了 KA2 的 vrrp_instance 状态是 BACKUP,优先级是 80)。
4. 终极测试与验证
配置完成后,在 KA1 和 KA2 上重启 Keepalived:
bash
systemctl restart keepalived测试 1:检查 LVS 规则是否自动生成
在 KA1 上敲击命令(它是当前的 MASTER):
bash
ipvsadm -Ln预期结果: 你会看到 Keepalived 像魔法一样,自动帮你写好了 IPVS 的轮询规则

测试 2:访问负载均衡
到你的 Client 测试机(172.25.254.100)上,使用 curl 访问 VIP:
预期结果: 你应该能看到 RS1 和 RS2 的内容交替出现(因为我们配置了
rr轮询)

测试 3:自动健康检查剔除
去 RS1 (172.25.254.11) 上,强行把 Web 服务关掉:systemctl stop httpd
迅速回到 KA1 上,敲击 ipvsadm -Ln。 预期结果: .11 节点从 LVS 的列表中消失了!Keepalived 发现它连不上 80 端口,自动把它踢出去了。

在 Client 上再次 curl,你会发现流量全部分配给了存活的 RS2,业务完全没有中断。

去 RS1 上重新启动服务 systemctl start httpd,再回 KA1 看,.11 节点又神奇地加回来了!

九、编写VRRP脚本并实现HaProxy高可用
在前面的实验中,Keepalived 作为"主导者",直接在内核层面操控了 LVS。但在实际生产中,我们更多使用的是 HAProxy 或 Nginx 作为第七层(应用层)的反向代理负载均衡器。
核心痛点: Keepalived 默认只会监控"网卡和网络"的死活。如果 KA1 上的 HAProxy 进程崩溃了,但网卡没坏、机器没断电,Keepalived 是不知道的!它依然会傻傻地把 VIP 绑在 KA1 上,导致所有用户的请求全部打向一个死掉的服务(这就是可怕的"流量黑洞")。
解决神技:vrrp_script (自定义脚本监控) Keepalived 提供了一个探针机制:允许我们写一个 Shell 脚本,Keepalived 会每隔几秒钟执行一次这个脚本。如果脚本返回失败(Exit Code 非 0),Keepalived 就会主动降低自己的优先级,或者直接进入 FAULT 状态,从而触发 VIP 漂移!
1. 扫清障碍:内核参数"避坑"准备
在使用 HAProxy + Keepalived 架构时,有一个极其经典的"坑": 正常情况下,Linux 不允许程序绑定一个当前不在自己网卡上的 IP。 这意味着,在 KA2(备节点)上,因为它目前没有 172.25.254.200 这个 VIP,如果 HAProxy 的配置文件里写了监听这个 VIP,KA2 的 HAProxy 就会启动失败!
解决办法:开启"允许绑定非本地 IP"内核参数。
在 KA1 和 KA2 上分别执行:
bash
# 临时生效
sysctl -w net.ipv4.ip_nonlocal_bind=1
# 写入配置文件,永久生效
echo "net.ipv4.ip_nonlocal_bind = 1" >> /etc/sysctl.conf
sysctl -p2. 安装并配置 HAProxy
我们需要在两台 Keepalived 节点上都装上 HAProxy,让它们负责真正的流量分发。为了干净,建议你先把上一个实验的 LVS (virtual_server 部分) 从 Keepalived 配置中删掉或注释掉,然后重启 Keepalived 释放 80 端口。
在 KA1 和 KA2 上执行:
安装 HAProxy:
bash
dnf install haproxy -y编写最简高可用配置:
清空默认配置并写入我们自己的测试规则(将流量代理到刚才的 RS1 和 RS2):
bash
cat << 'EOF' > /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local2
maxconn 4000
daemon
defaults
mode http
log global
option httplog
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
# 定义前端监听 (直接绑定 VIP 的 80 端口)
frontend http-in
bind 172.25.254.200:80
default_backend web_servers
# 定义后端真实服务器组
backend web_servers
balance roundrobin
server RS1 172.25.254.11:80 check inter 2000 rise 2 fall 3
server RS2 172.25.254.12:80 check inter 2000 rise 2 fall 3
EOF启动并设置开机自启:
bash
systemctl enable --now haproxy3. 编写 Keepalived 监控探针脚本
我们需要写一个极其简单的脚本,用来判断 HAProxy 进程是否还活着。
在 KA1 和 KA2 上操作:
创建脚本:
bash
vim /etc/keepalived/scripts/check_haproxy.sh
bash
#!/bin/bash
# 检查 haproxy 服务是否活跃
if systemctl is-active --quiet haproxy; then
exit 0 # 存活,返回 0 (成功)
else
exit 1 # 死了,返回 1 (失败)
fi赋予执行权限:
bash
chmod +x /etc/keepalived/scripts/check_haproxy.sh4. 修改 Keepalived 配置文件,呼叫探针
这是最关键的一步,我们需要在 Keepalived 的配置中定义这个探针,并在 VIP 实例中调用它。
编辑 KA1 (Master) 的子配置文件: vim /etc/keepalived/conf.d/172.25.254.200.conf
在文件最上方加入:
bash
vrrp_script chk_haproxy {
script "/etc/keepalived/scripts/check_haproxy.sh" # 脚本绝对路径
interval 2 # 每隔 2 秒钟执行一次
weight -30 # 【核心逻辑】:如果脚本返回失败(1),KA1 的优先级立刻减去 30 (变成 100 - 30 = 70)
fall 2 # 连续失败 2 次,才认为真的死了,触发扣分 (防止网络防抖)
rise 2 # 连续成功 2 次,认为满血复活,分数加回来
}KA2 的配置逻辑一样,把 vrrp_script 块加到最上面,然后在实例内部加 track_script。 (注意: KA2 的 state 是 BACKUP,priority 是 80。如果 KA1 挂了被扣 30 分,KA1 会变成 70 分。此时 KA2 的 80 分 > 70 分,KA2 就会名正言顺地抢走 VIP!)
bash
track_script {
chk_haproxy # 调用上面定义的 chk_haproxy 探针
}5. 最终测试
配置完毕后,在 KA1 和 KA2 上重启 Keepalived:
bash
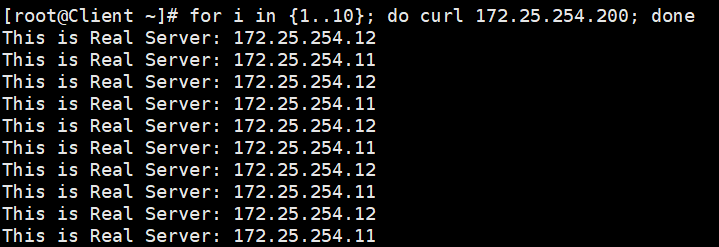
systemctl restart keepalived第一阶段:日常运行 在 Client 客户端 (.100) 疯狂请求 VIP:
bash
for i in {1..10}; do curl 172.25.254.200; done请求会经过 KA1 上的 HAProxy,完美分发给 RS1 和 RS2
第二阶段:模拟应用层崩溃
现在,不要关机,也不要停 Keepalived。我们只把 KA1 上的 HAProxy 搞死:
bash
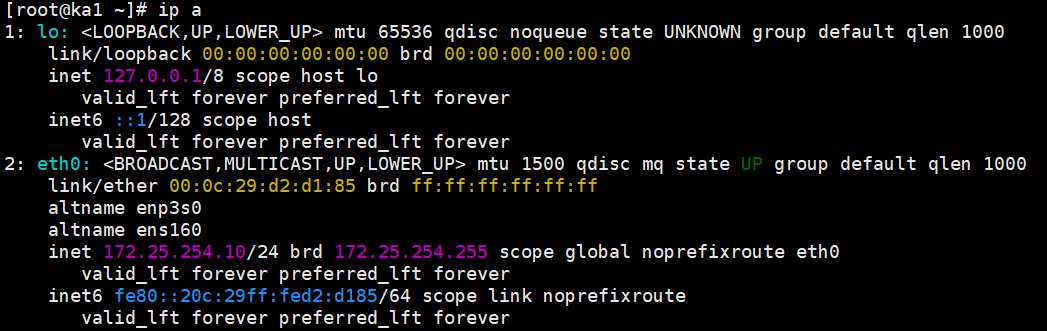
systemctl stop haproxy第三阶段:探针发威
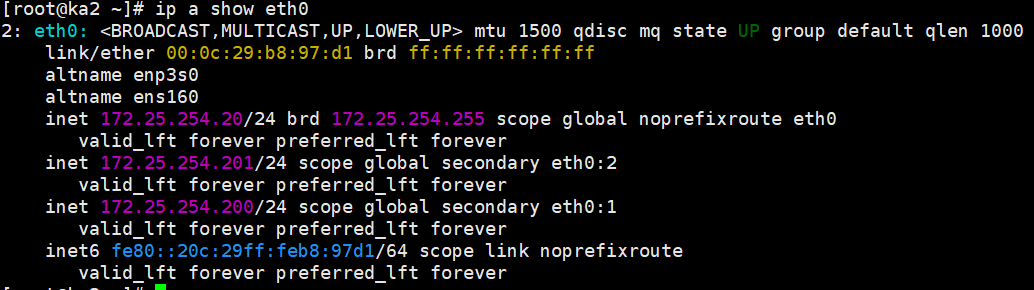
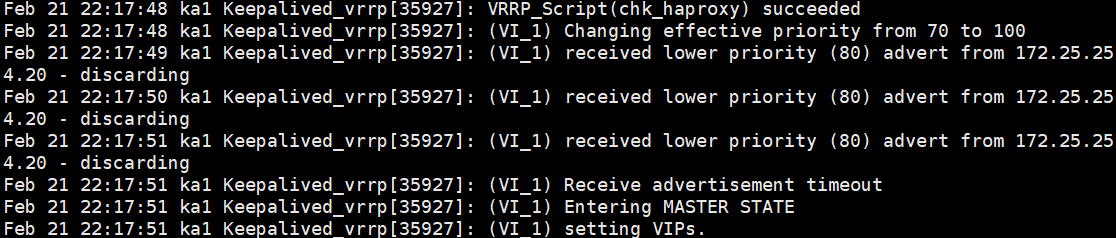
迅速去 KA1 上看 VIP (ip a) -> VIP 不见了!
去 KA2 上看 VIP (ip a) -> VIP 漂移过来了!
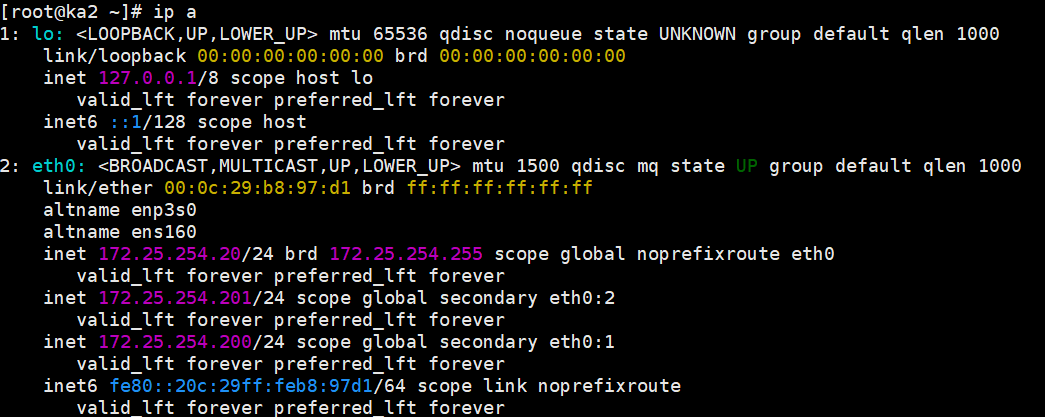
去查阅 /var/log/keepalived.log
因为你配了降分逻辑(
weight -30),KA1 的分数掉到了 70,低于 KA2 的 80,VIP 被果断剥夺

第四阶段:应用修复
在 KA1 上把服务修好:
bash
systemctl start haproxy再次查询日志
探针连续两次探测成功 (
rise 2),把扣掉的 30 分加了回来(恢复到 100 分)。KA1 凭借最高分,再次抢回了 VIP
结语:
经过这一系列长达十余个实验的深度跋涉,我们拨开了 Keepalived 的层层面纱。我们见证了 VRRP 协议如何在毫秒间完成 VIP 的无缝切换,体验了从嘈杂的系统日志中分离出纯净监控数据的畅快,更通过脚本与探针,让冷冰冰的底层协议拥有了感知应用层(LVS/HAProxy)温度的能力。
Keepalived 不仅仅是一个工具,更是一种高可用的设计思维。在云原生时代,虽然有各种复杂的 Service Mesh 和全新的负载均衡方案,但 Keepalived 凭借其简单、稳定、极其可靠的特性,依然是在物理机、虚拟化以及私有云环境中构建"永远在线"服务的基石。
掌握了这些配置只是第一步。在真实的生产环境中,如何根据业务特性精细调整心跳间隔、如何编写更健壮的 vrrp_script 监控脚本、如何在网络抖动和快速故障转移之间找到平衡点,将是每一位 SRE 工程师持续探索的课题。希望这份实战笔记能成为你构建稳定架构的有力武器。