文章目录
- [1 why distributed inference](#1 why distributed inference)
- [2 DP EP PP TP](#2 DP EP PP TP)
-
- [2.1 TP](#2.1 TP)
-
- [2.1.1 工程层面怎么通信](#2.1.1 工程层面怎么通信)
- [2.1.2 算法层面](#2.1.2 算法层面)
- [2.2 PP](#2.2 PP)
- [2.3 EP](#2.3 EP)
- [2.4 DP](#2.4 DP)
- 参考文献
这篇博客是在看EP02精剪版分布式推理优化,vllm源码解读这个学习视频时做的简单笔记,感兴趣的可以直接去看原视频。
1 why distributed inference
其实就是因为一张卡跑大模型跑不开了,还有其他原因就是分布式推理能够加快模型的推理优化。
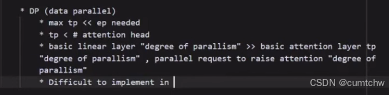
2 DP EP PP TP
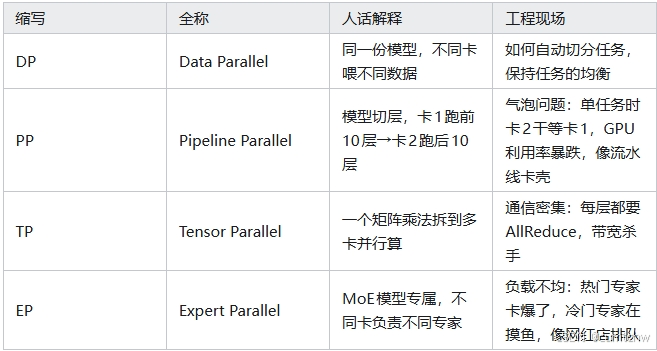
2.1 TP
vllm/vllm/distributed/parallel_state.py这个文件里面有为传统的parallel提供的一系列接口,
下面的这个数据结构就是用来分布式通信的
python
# message queue broadcaster is only used in tensor model parallel group
_TP = init_model_parallel_group(group_ranks,
get_world_group().local_rank,
backend,
use_message_queue_broadcaster=True,
group_name="tp")然后实际上用的是这个类class GroupCoordinator:。
下面的参数是他的属性
python
# available attributes:
rank: int # global rank
ranks: list[int] # global ranks in the group
world_size: int # size of the group
# difference between `local_rank` and `rank_in_group`:
# if we have a group of size 4 across two nodes:
# Process | Node | Rank | Local Rank | Rank in Group
# 0 | 0 | 0 | 0 | 0
# 1 | 0 | 1 | 1 | 1
# 2 | 1 | 2 | 0 | 2
# 3 | 1 | 3 | 1 | 3
local_rank: int # local rank used to assign devices
rank_in_group: int # rank inside the group
cpu_group: ProcessGroup # group for CPU communication
device_group: ProcessGroup # group for device communication
use_device_communicator: bool # whether to use device communicator
device_communicator: DeviceCommunicatorBase # device communicator
mq_broadcaster: Optional[Any] # shared memory broadcaster2.1.1 工程层面怎么通信
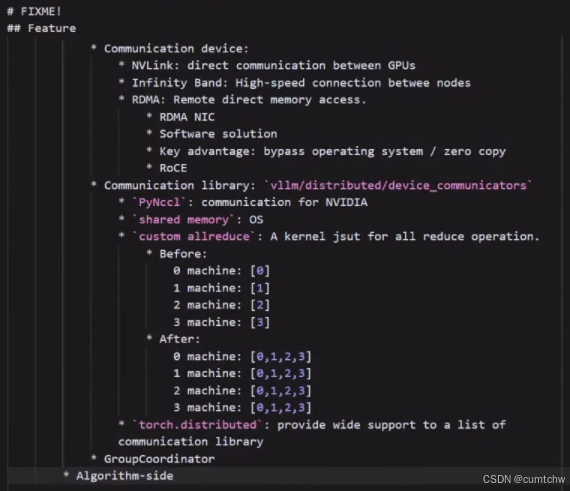
2.1.2 算法层面
vllm/vllm/distributed/device_communicators这个目录里面是通信相关的代码,
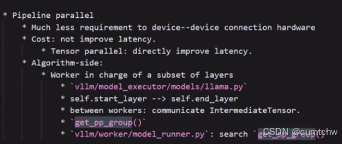
还可以看一下vllm/vllm/model_executor/models/llama.py这里面的管宇TP PP的代码,初学者学代码先用llama要比用deepseek更好,
deepseek模型结构更复杂

2.2 PP
2.3 EP
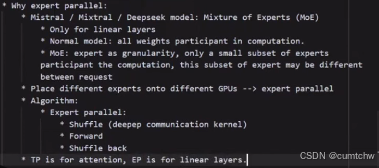
2.4 DP