向量数据库:AI的"长期记忆"是如何实现的?
从"ChatGPT忘记昨天聊过什么"说起
如果你连续两天和ChatGPT聊天,会发现一个奇怪的现象:
- 第一天你告诉它"我喜欢科幻电影",它会推荐《星际穿越》;
- 第二天你问"上次推荐的电影叫什么",它可能会说"抱歉,我不记得之前的对话了"。
这是因为大语言模型(LLM)的"短期记忆"有限------就像人类大脑只能记住最近说的几句话,聊得太久就会"断片"。
而向量数据库(Vector Database) 的出现,就像给AI装了一个"外接硬盘",让它能永久存储和快速检索海量知识。今天我们就用"图书馆索引"的例子,揭开向量数据库如何让AI拥有"长期记忆"的秘密。
为什么AI需要"外接记忆"?
大语言模型的"失忆症"
大语言模型(如GPT、LLaMA)的工作原理是"一次性处理输入":
- 你输入的文字会被转换成向量(数字数组),模型根据这些向量生成回答
- 但模型本身不存储历史对话,对话结束后,向量就会被"清空"
- 就像你用计算器算完题后,屏幕会归零,不会记住上一次的计算过程
这导致两个问题:
- 上下文窗口有限:GPT-4最多只能记住8000个词左右,超过就会"忘事"
- 知识滞后:训练数据截止到2023年的模型,永远不知道2024年发生的事
传统数据库的"关键词陷阱"
有人说:"把知识存在MySQL里不就行了?"但传统数据库用"关键词匹配",就像用字典查字------必须知道精确的词才能找到结果:
- 你搜"苹果手机",它找不到"iPhone"
- 你问"推荐一部太空题材的电影",它无法理解"太空题材"的语义
而AI需要的是语义理解:即使你说"有没有关于星际旅行的片子",它也能联想到《星际穿越》。
向量数据库:给数据"拍X光片"
什么是"向量"?数据的"数字指纹"
向量(Vector)是一串数字,代表数据的"语义特征"。就像每个人的指纹独一无二,每段文字、每张图片也有独特的"数字指纹":
- 文字"猫"的向量可能是 0.2, 0.5, -0.3, ...(512个数字)
- 文字"狗"的向量可能是 0.3, 0.4, -0.2, ...
- 相似的语义,向量会更"像"(数字差异小)
生成向量的过程叫"嵌入(Embedding)",就像给数据拍X光片------表面看是文字/图片,实际是一串能被AI理解的数字。
用"图书馆索引"理解向量数据库
想象一个超级图书馆,有100万本书:
- 传统图书馆:按书名首字母排序,找《三体》要先查"三"在哪个书架
- 向量图书馆:给每本书生成"内容指纹"(向量),然后按"指纹相似度"排书架------《三体》会和《星际穿越》《沙丘》放在一起
向量数据库就是这个"智能书架":
- 存储:把文字、图片转换成向量存起来(相当于给每本书贴指纹标签)
- 索引:按向量相似度排列数据(相当于把相似内容的书放在相邻书架)
- 搜索:输入"太空歌剧小说",生成向量后,在书架上找最相似的书(语义匹配)
核心技术:如何快速找到"相似的向量"?
暴力搜索:像在字典里逐页翻
最直接的方法是"暴力匹配":
- 输入一个向量,和数据库里所有向量算"距离"(差异度)
- 距离越小,相似度越高
但如果有10亿个向量,这种方法就像在10亿页的字典里找一个字------慢到无法忍受。
索引算法:给图书馆建"导览图"
向量数据库用近似最近邻(ANN)索引解决速度问题,就像图书馆的"主题导览图":
- HNSW(层次化 navigable small world):想象图书馆分多层,第一层是大类(科幻、历史),第二层是子类(硬科幻、软科幻),快速缩小范围
- IVF(倒排文件):把向量分成1000个"桶",先判断输入向量属于哪个桶,再在桶内搜索
这些算法能把搜索时间从小时级缩短到毫秒级,让AI能实时找到需要的知识。
相似度计算:怎么判断"像不像"?
常用两种"距离"衡量向量相似度:
- 余弦相似度:判断向量"方向"是否一致(如"猫"和"猫咪"方向几乎相同)
- 欧氏距离:判断向量"位置"是否接近(如"苹果手机"和"iPhone"位置很近)
就像判断两个人像不像:余弦相似度看脸型是否相似,欧氏距离看五官位置是否接近。
向量数据库的"超能力":让AI"博古通今"
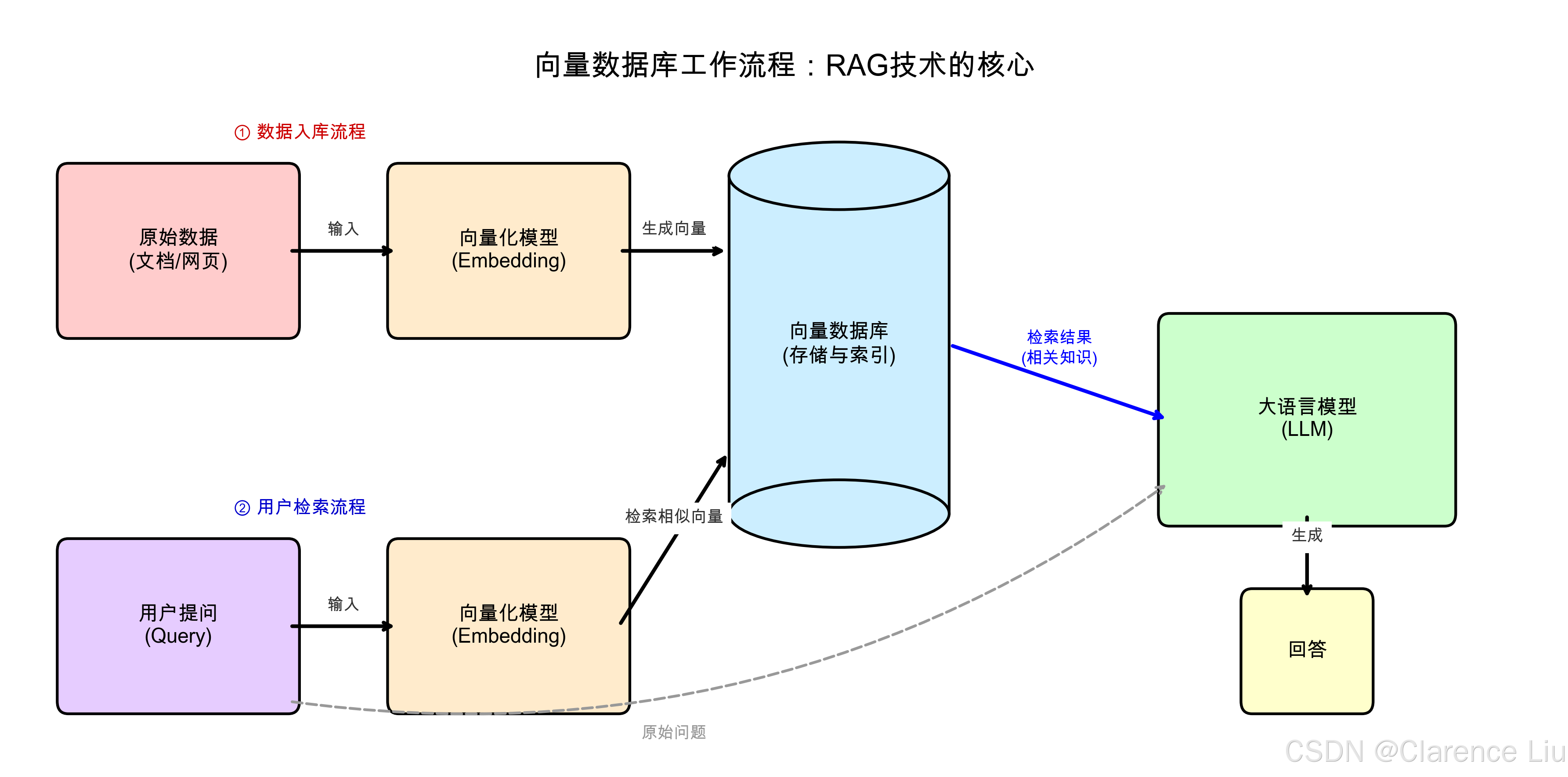
能力1:给大模型"喂知识"(RAG技术)
检索增强生成(RAG) 是向量数据库最核心的应用:
- 把公司文档、书籍、论文转换成向量存进数据库
- 用户提问时,先在数据库里找相关知识(如"公司年假政策")
- 把知识和问题一起喂给大模型,让它基于新信息回答
这样AI就不会"胡说八道",因为所有回答都能追溯到原始文档------相当于给学生考试时提供"开卷资料"。
能力2:实现"长期对话记忆"
把每次对话内容转换成向量存起来:
- 你说"我喜欢科幻电影",向量数据库记住这个偏好
- 一周后问"推荐一部电影",AI会从记忆中检索"科幻偏好",推荐《流浪地球》
就像你的手机备忘录,随时能翻看过去的聊天记录。
能力3:跨模态搜索(文字找图片、图片找文字)
向量数据库能存储任何类型数据的向量:
- 输入文字"红色的猫",能找到所有红色猫的图片
- 输入一张风景照,能找到描述类似风景的诗句
这是因为文字和图片的向量在高维空间中会"语义对齐"------描述猫的文字向量和猫的图片向量会靠得很近。
生活中的向量数据库:你每天都在间接使用
案例1:抖音的"猜你喜欢"
你刷到的每个视频,背后都有向量数据库在工作:
- 你的观看历史被转换成"偏好向量"(喜欢美食、讨厌恐怖)
- 新视频也被转换成"内容向量"
- 系统快速找到和你偏好向量最相似的视频推荐给你
案例2:电商平台的"相似商品"
当你看"无线耳机"时,平台会推荐"相似款":
- 每个商品的描述、图片被转换成向量
- 向量数据库找出和当前商品向量最接近的其他商品
案例3:智能客服的"秒答"
客服机器人能快速回答复杂问题:
- 公司FAQ文档被转换成向量存进数据库
- 用户提问时,实时检索相关文档片段,生成答案
主流向量数据库:各有所长的"记忆专家"
| 数据库 | 特点 | 适用场景 |
|---|---|---|
| Milvus | 开源、支持百亿级向量、适合企业级应用 | 大规模RAG、多模态搜索 |
| Pinecone | 云服务、开箱即用、无需运维 | 快速原型开发、中小规模应用 |
| FAISS | Facebook开源、轻量高效、适合单机部署 | 科研、本地测试 |
| Weaviate | 支持 GraphQL查询、自带语义理解 | 开发者友好、快速集成 |
未来挑战:AI的"记忆"会越来越聪明吗?
挑战1:记忆太多会"混乱"
向量数据库存的知识越多,搜索速度可能越慢,就像图书馆书太多,找书会变难。解决办法是分层存储:常用知识放"书架"(内存),冷门知识放"仓库"(硬盘)。
挑战2:记忆需要"更新"
新的知识(如2024年新电影)需要及时加入向量数据库,就像图书馆需要不断采购新书。实时更新向量的技术(如动态索引)是当前研究热点。
挑战3:记忆要"准确"
偶尔会出现"张冠李戴"------把A的向量误认为B的向量。这需要更精准的嵌入模型和更智能的索引算法。
小问题:向量数据库会让AI拥有"自我意识"吗?
(提示:不会。向量数据库只是"记忆工具",就像人类的笔记本------笔记本里存满知识,不代表拥有自我意识。AI的"思考"本质还是对向量的数学运算,而非真正的"理解"。)
下一篇预告:《AI伦理:为什么"算法偏见"比你想的更可怕?》------用真实案例讲透AI决策背后的公平性问题。