
目录
[性能与负载均衡能力 Haproxy专为高并发负载均衡设计,支持TCP和HTTP层代理,会话保持能力优于Nginx。](#性能与负载均衡能力 Haproxy专为高并发负载均衡设计,支持TCP和HTTP层代理,会话保持能力优于Nginx。)
[功能特性差异 Haproxy提供丰富的健康检查策略和ACL规则,适合复杂路由场景。](#功能特性差异 Haproxy提供丰富的健康检查策略和ACL规则,适合复杂路由场景。)
[适用场景 Haproxy适合需要精细流量管理的企业级负载均衡。](#适用场景 Haproxy适合需要精细流量管理的企业级负载均衡。)
一、概述
1.1.Haproxy的定义
Haproxy(High Availability Proxy)是一款开源的高性能负载均衡器和代理服务器,专注于处理TCP和HTTP流量。其设计目标是提供高可用性、高性能的解决方案,适用于现代分布式系统架构。Haproxy通过分发请求到多个后端服务器,优化资源利用率并提升系统稳定性。
1.2.Haproxy的核心功能
负载均衡
支持多种负载均衡算法,如轮询(Round Robin)、最小连接(Least Connections)、源IP哈希(Source IP Hash)等,确保流量合理分配到后端服务器集群。
高可用性
通过健康检查机制实时监控后端服务器状态,自动剔除故障节点并将流量重定向至健康服务器,避免单点故障影响服务连续性。
TCP/HTTP代理
支持四层(TCP)和七层(HTTP)代理模式,可灵活配置路由规则、SSL/TLS终止、HTTP头部修改等高级功能。
性能优化
采用事件驱动架构和零拷贝技术,单实例可处理数十万并发连接,适合高吞吐量场景如Web应用、API网关和微服务架构。
扩展性与灵活性
提供ACL(访问控制列表)和丰富的配置选项,支持动态调整策略,满足复杂业务需求
1.3.应用场景
负载均衡
haproxy常用于分发网络流量到多个服务器,确保高可用性和性能优化。在Web服务器、数据库服务器和应用服务器集群中,haproxy通过轮询、最小连接数等算法分配请求,避免单点过载。
高可用性
haproxy通过健康检查机制监控后端服务器的状态,自动剔除故障节点,确保服务持续可用。在金融、电商等领域的高并发系统中,haproxy的高可用特性被广泛采用。
SSL/TLS终止
haproxy支持SSL/TLS终止功能,可以集中处理加密和解密操作,减轻后端服务器的负担。在需要安全传输的场景中,如支付网关或API网关,haproxy的这一功能尤为重要。
微服务架构
在微服务架构中,haproxy作为API网关或服务网格的入口,负责路由请求到不同的微服务。其灵活的配置和低延迟特性使其成为微服务架构的理想选择。
内容缓存
haproxy可以配置为缓存代理,加速静态内容的传输。在CDN或内容分发网络中,haproxy通过缓存频繁访问的资源,显著提升响应速度。
**1.4.**Haproxy与Nginx、LVS的对比分析
性能与负载均衡能力
- Haproxy专为高并发负载均衡设计,支持TCP和HTTP层代理,会话保持能力优于Nginx。
- Nginx的七层处理更灵活,但并发连接数低于Haproxy。
- LVS基于Linux内核,性能最高但仅支持四层转发。
功能特性差异
- Haproxy提供丰富的健康检查策略和ACL规则,适合复杂路由场景。
- Nginx集成Web服务器功能,反向代理配置更简洁。
- LVS无应用层解析能力,需配合其他工具实现高级功能。
适用场景
- Haproxy适合需要精细流量管理的企业级负载均衡。
- Nginx更适合Web应用加速和简单反向代理。
- LVS常用于数据中心基础架构的高性能四层负载。
二、核心特性
- 高性能与低延迟
- 支持TCP/HTTP/HTTPS协议
- ACL(访问控制列表)与流量管理
- 健康检查机制
三、haproxy七层代理
3.1.负载均衡
3.1.1.什么是负载均衡
负载均衡(Load Balancing)技术通过智能分配网络流量和计算任务到多个服务器资源,有效提升系统性能。它能优化资源利用率、提高吞吐量、缩短响应时间,并防止单节点过载。该技术将客户端请求合理分发至各类后端服务器(包括Web服务器、数据库服务器等),从而实现资源的高效利用和系统的高可用性。
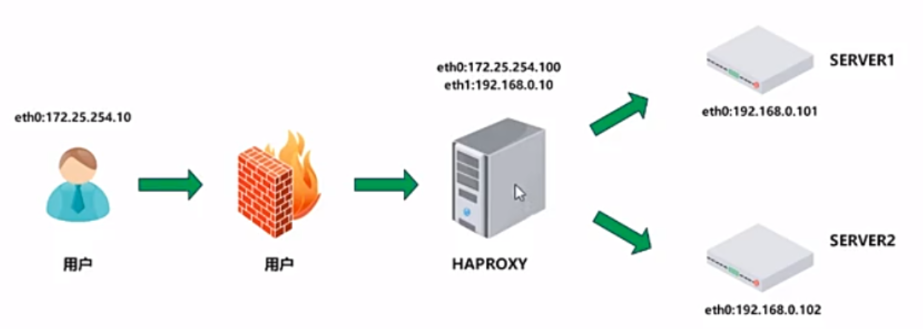
3.1.2.为什么用负载均衡
- web服务器的动态水平扩展 ------> 对用户无感知
- 增加业务并发访问及处理能力 ------> 解决单服务器瓶颈问题
- 节约公网IP地址 ------> 降低IT支出成本
- 隐藏内部服务器IP ------> 提高内部服务器的安全性
- 配置简单 ------> 固定格式的配置文件
- 功能丰富 ------> 支持七层和四层,支持动态下线主机
- 性能较强 ------> 并发数万甚至数十万
3.1.3.负载均衡类型
1.硬件
|-----------|----------|---------------------------------------------------------------------------------------------------------------------------------------------------|
| FS | 美国FS网络公司 | https://fs.com/zh |
| Netscaler | 美国思杰公司 | https://www.citrix.com.cn/products/citrix-adc/ |
| Array | 华耀 | https://www.arraynetworks.com.cn/ |
| AD-1000 | 深信服 | https://www.sangfor.com.cn/ |
2.四层负载均衡
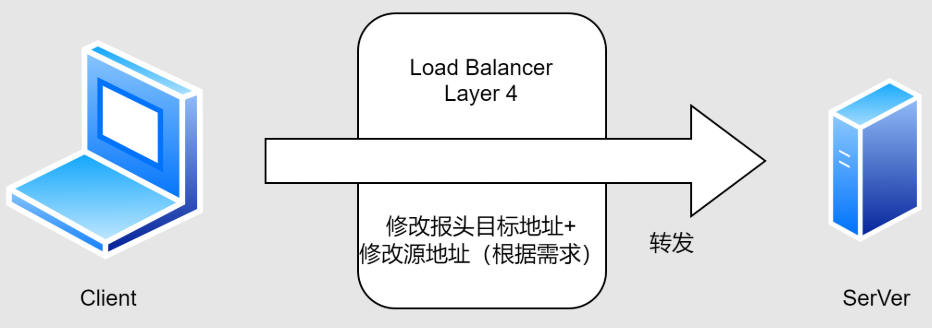
1.通过ip+port决定负载均衡去向
2.对流量请求进行NAT处理,转发至后台服务器
3.记录tcp、udp流量分别是由哪台服务器处理,后续该请求连接的流量都通过该服务器处理
4.支持四层的软件:
lvs:重量级四层负载均衡器
nginx:轻量级负载均衡器,可缓存。(nginx四层是通过upstream模块)
haproxy:模拟四层转发
3.七层负载均衡
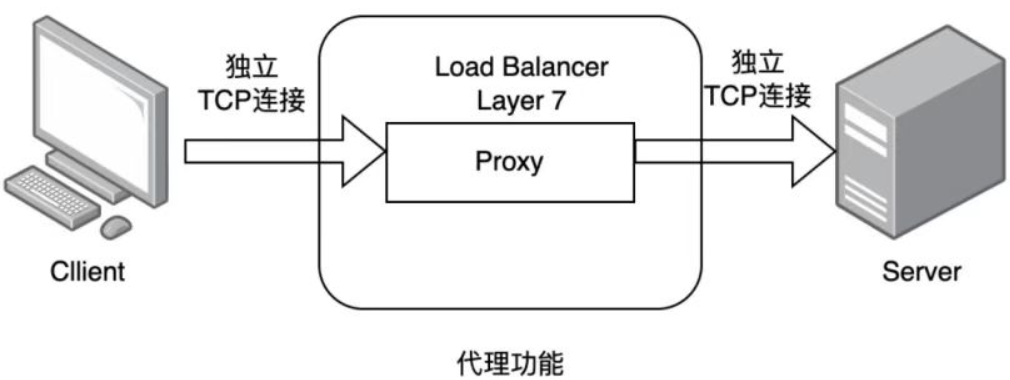
1.通过虚拟url或主机ip进行流量识别,根据应用层信息进行解析,决定是否需要进行负载均衡
2.代理后台服务器与客户端建立连接,如nginx可代理前后端,与前端客户端tcp连接,与后端服务器建立tcp连接
3.支持七层代理的软件:
nginx:基于http协议(nginx七层是通过proxy_pass)
haproxy:七层代理,会话保持、标记、路径转移等
4.四层和七层的区别
| 对比项 | 四层负载均衡(L4) | 七层负载均衡(L7) |
|---|---|---|
| 工作层次 | 传输层(TCP/UDP)及以下 | 应用层(HTTP/HTTPS)及以下 |
| 看懂什么 | 只认 IP + 端口 | 能看懂域名、URL、Cookie、请求头 |
| 转发方式 | 直接转发数据包 | 代理:先收再发,两端独立连接 |
| 是否解析应用内容 | 不解析 | 完整解析 |
| 性能 | 网络吞吐量与信息处理能力上极高 | 可支持解析应用层报文消息内容,识别URL、Cookie、HTTP header等信息 |
| 支持协议 | 所有 TCP/UDP 协议 | 主要 HTTP/HTTPS |
| 能否做 HTTPS 卸载 | 不能 | 能 |
| 典型产品 | LVS、F5 | Nginx、HAProxy |
| 安全性 | 无法识别DDOS攻击 | 可以防御SYN、Cookie/Flood攻击 |
3.2.haproxy的实验环境与软件安装
3.2.1.软件安装
软件包下载地址:
https://github.com/haproxy/wiki/wiki/Packageshttps://github.com/haproxy/wiki/wiki/Packages
3.2.2.实验环境
|-----------------|------------------------------------------------------|
| 功能 | IP |
| 客户端 | eth0: 192.168.174.200 |
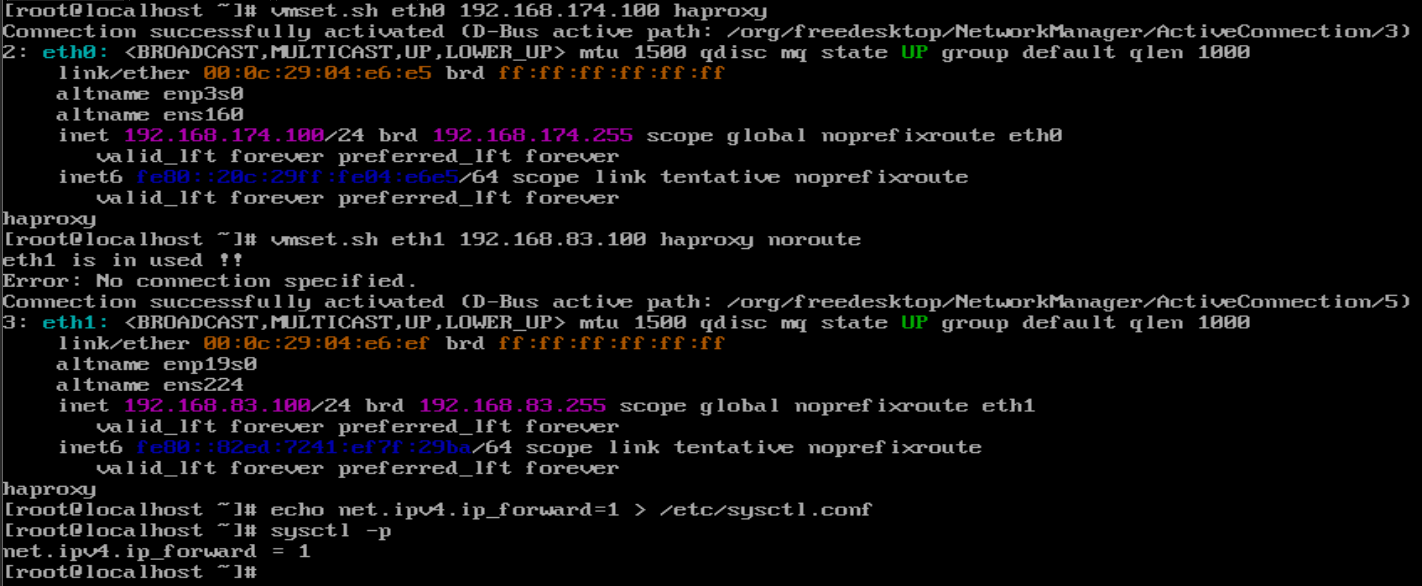
| 调度器haproxy(双网卡) | eth0(NAT): 192.168.174.100 eth1(仅主机): 192.168.83.100 |
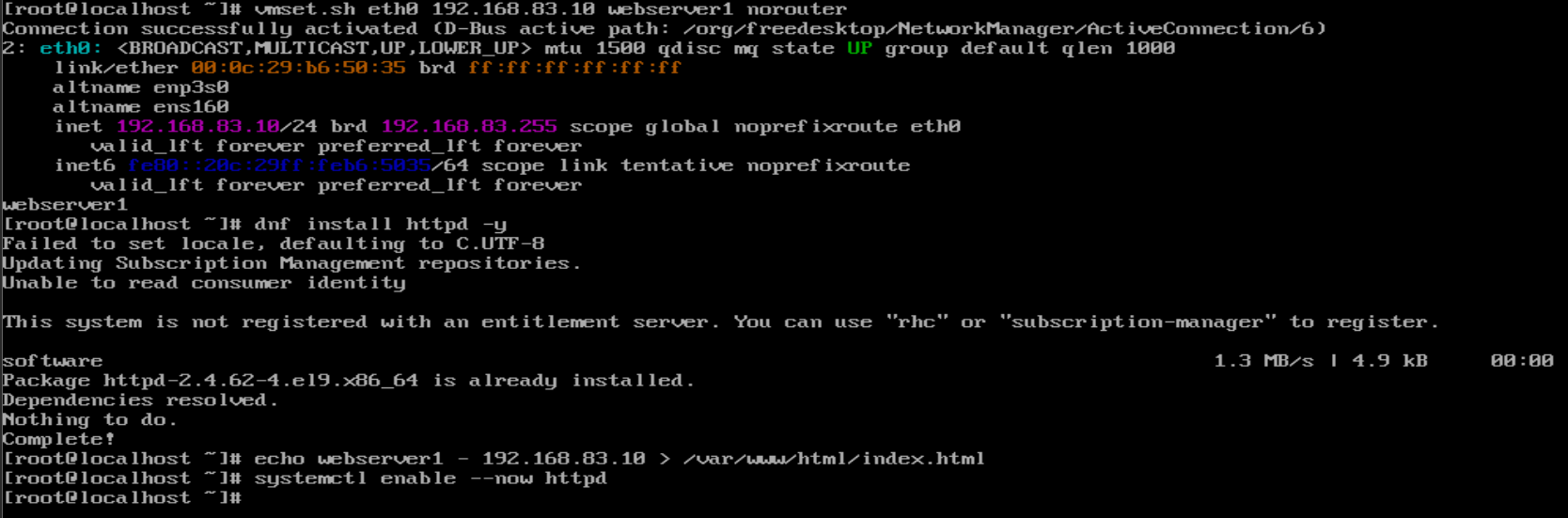
| webserver1 | eth0(仅主机): 192.168.83.10 |
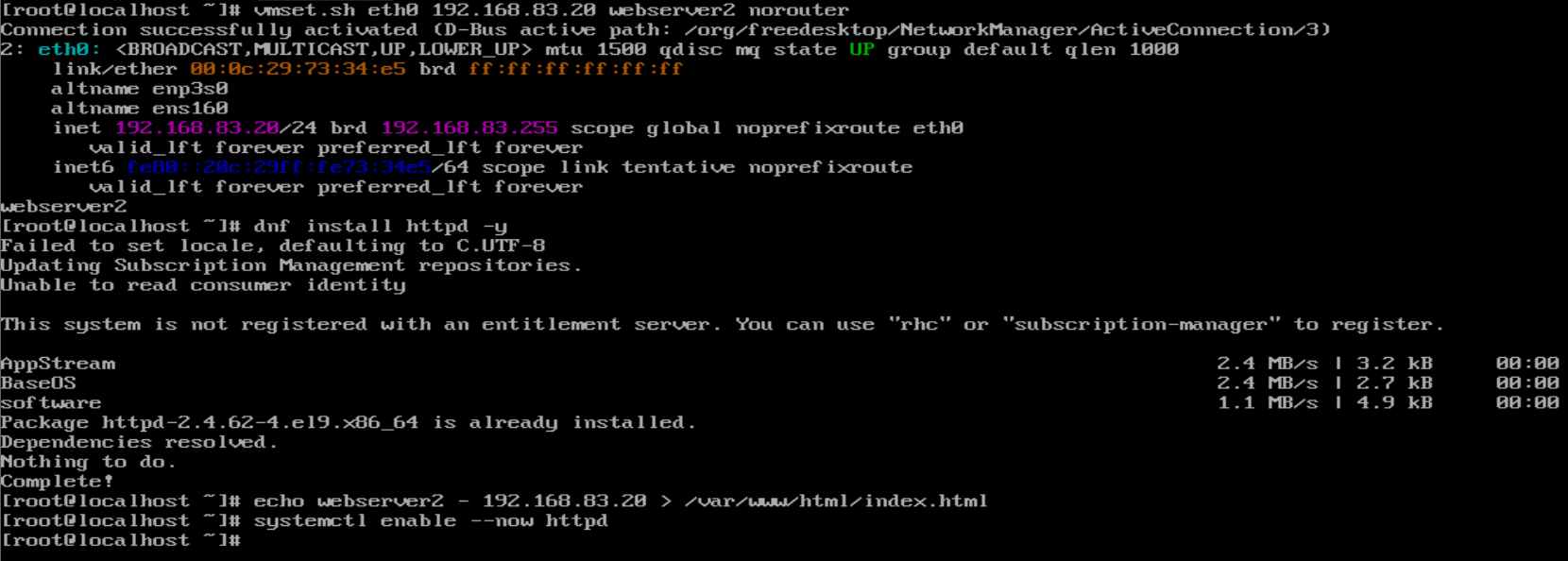
| webserver2 | eth0(仅主机): 192.168.83.20 |
搭建实验环境
1.新建三个虚拟机haproxy、webserver1、webserver2。在虚拟机haproxy中添加一个网卡并设置模式为仅主机;webserver1、webserver2的网卡模式改为仅主机模式
haproxy:
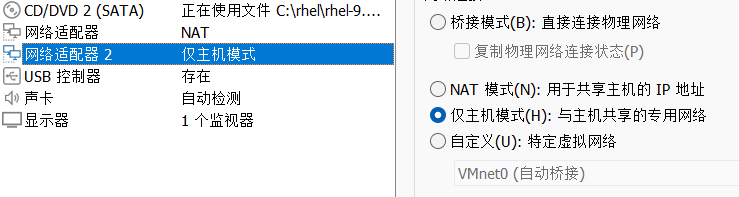
webserver1、webserver2:
2.给每台主机配置ip,并配置路由内核功能
haproxy:
webserver1:
webserver2:
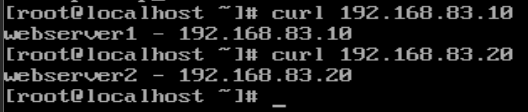
3.在haproxy中验证环境
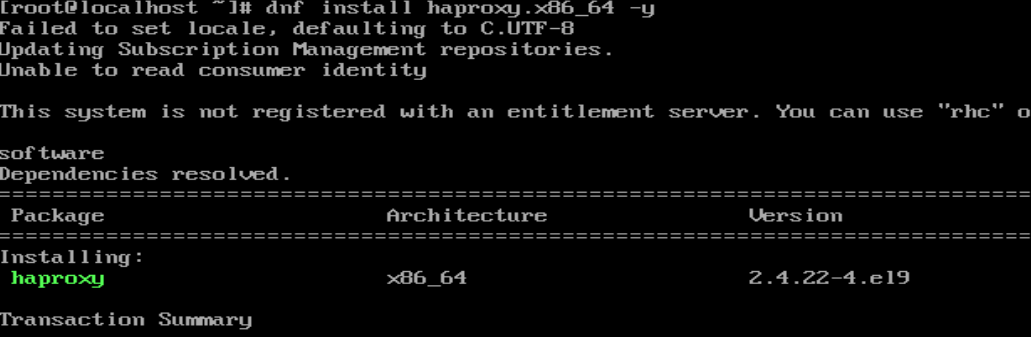
4.在虚拟机haproxy中安装haproxy软件,启动haproxy服务

3.3.haproxy的基本配置信息
官方文档:https://cbonte.github.io/haproxy-dconv/
haproxy的配置文件haproxy.cfg由两大部分组成,分别是:
global:全局配置段
- 进程及安全配置相关的参数
- 性能调整相关参数
- Debug参数
proxies:代理配置段
- defaults:为frontend、backend、listen提供默认配置
- frontend:前端,相当于nginx中的server {}
- backend:后端,相当于nginx中的upstream {}
- listen:同时拥有前端和后端配置,配置简单,生产推荐使用
3.3.1.haproxy的参数详解实验
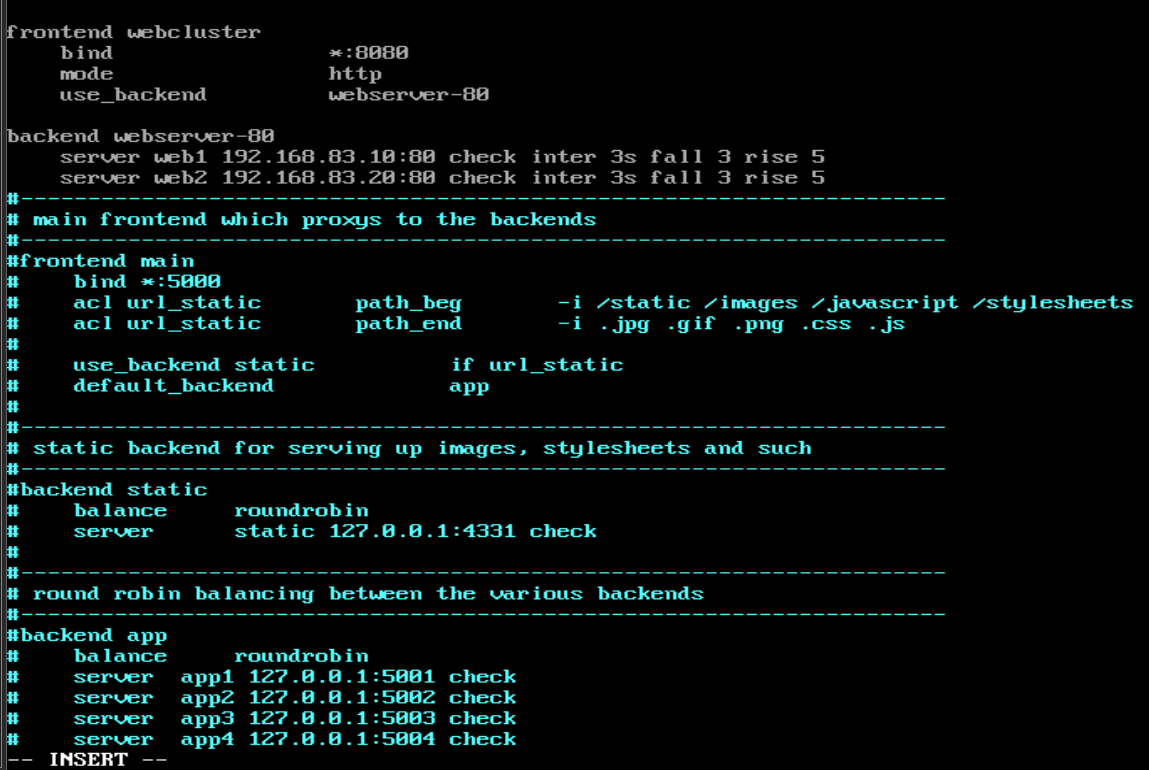
1.实现最基本的负载
方法一:前后端分开设定

添加webserver1和webserver2的ip,检测后端的83.10和83.20是否运行正常,3s一次,如果连续检测3次都出现异常,说明这个ip就下线了;如果突然又能连上了,就继续检测5次,若都能连上,说明这个ip又在线了**(其中 bind *:80 这里是已经提前关闭了apache服务,为了防止和haproxy服务抢占80端口;然后这个 * 表示我这台调度器上的所有ip别人都能够去访问,如果只想让别人去访问某一个ip,就把 * 改成那个ip即可)**
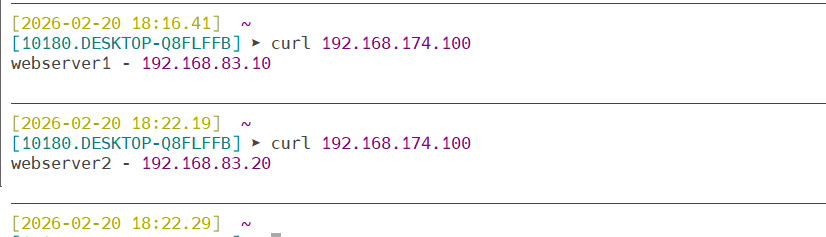
重启haproxy服务,检测是否正常

测试一下能否访问到调度器
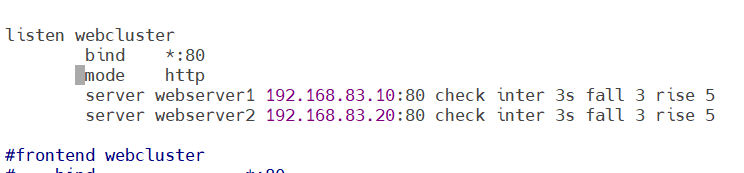
方法二:用listen方式书写负载均衡
继续去到haproxy的配置文件haproxy.cfg里面编写

**把上个方法配置的内容注释掉再写入命令。**其中,server后接的webserver1、webserver2都可以改成其他名字,只要后面的ip地址是正确的即可。后面的命令(check inter 3s fall 3 rise 5)其用法和方法一的用法也是一样的。保存退出,重启haproxy服务

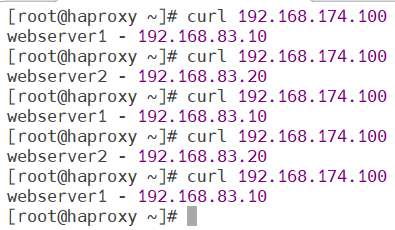
测试能否访问到调度器
3.3.2.global配置
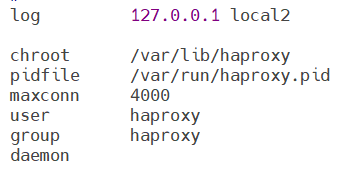
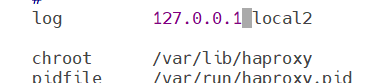
- log 127.0.0.1 local2 ------ 定义全局的syslog服务器,日志服务器需要开启UDP协议,最多可以定义两个
- chroot /var/lib/haproxy ------ 锁定运行目录
- pidfile /var/run/haproxy.pid ------ 指定pid文件
- maxconn 4000 ------ 指定最大连接数
- user haproxy ------ 指定haproxy的运行用户
- group haproxy ------ 指定haproxy的运行组
- daemon ------ 指定haproxy以守护进程方式运行
**实验:**尝试把日志指定发送到192.168.83.10上去
1.在192.168.83.10上进入到rsyslog.conf文件去开启接收日志的端口(在UDP这段内容里面去掉 module 和 input 前面的 # 即可),保存退出后重启 rsyslog 服务
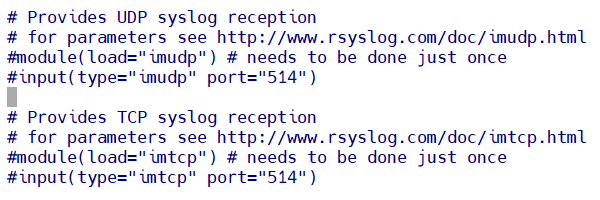
module(load="imudp") ------使用UDP协议接收日志
input(type="imudp" port="514") ------从514端口发送日志
2.在webserver1(192.168.83.10)中测试接收日志端口是否开启(出现了514端口说明开启了)

3.在haproxy中去到haproxy.cfg文件里修改指定地点来设定日志发送消息,保存退出,重启haproxy服务
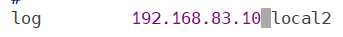
4.新建一个会话去访问haproxy调度器产生日志
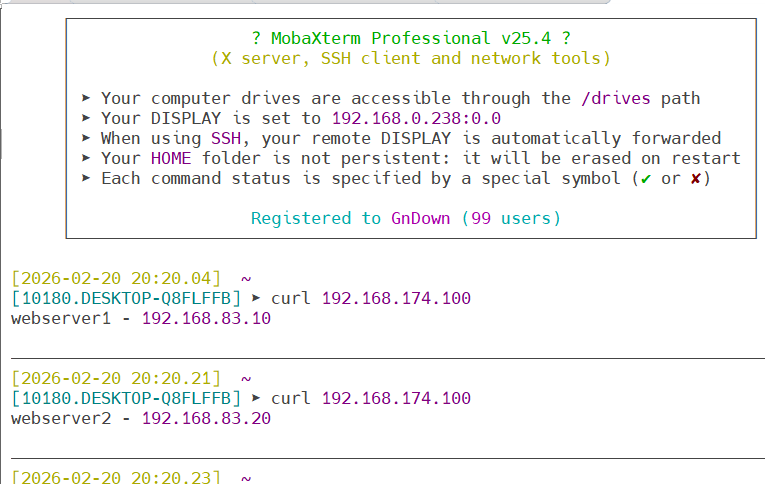
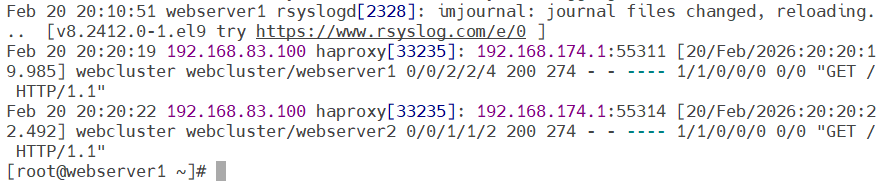
5.验证:在webserver1(被指定接收日志的虚拟机)中查看日志信息(出现了haproxy的ip地址说明成功)

- 记得把接收日志的地址改回127.0.0.1
实现haproxy的多进程
默认haproxy是单进程的

在haproxy.cfg中添加参数(nbproc 2)修改进程数,保存退出,重启服务
nbproc 2 ------ 开启2个进程

再次查看进程验证
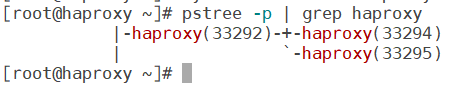
haproxy多进程绑定
haproxy 多进程绑定的核心目的:haproxy 开启多进程后,默认情况下多个进程会争抢同一个端口 / CPU 资源,就像多个人抢同一个水龙头接水 ------ 效率低、还容易出问题。绑定操作就是给每个进程分配专属 "资源",让它们各司其职、互不干扰。 最常见的 2 种具体绑定场景就是:CPU 绑定(进程绑核)、套接字绑定(进程绑套接字)
1.CPU 绑定(进程绑核)

cpu-map 1 0 ------ 进程1绑CPU核心0
cpu-map 2 1 ------ 进程2绑CPU核心1
记得保存退出,重启服务
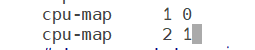
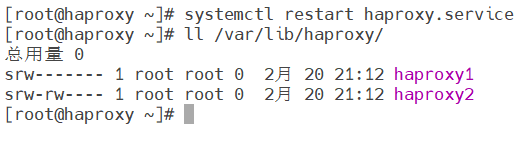
2.套接字绑定(进程绑套接字):为不同进程准备不同套接字
先关闭haproxy服务,清空套接字记录,再次进入到haproxy.cfg文件进行配置

mode 600 level admin process 1
mode:套接字权限
level:这个指定的套接字能够实现的事情,比如有管理员admin的权限
process 1:表示这条stats socket配置只作用于编号为 1 的 haproxy 进程

保存退出,重启服务,验证
实现haproxy的多线程(多进程与多线程互斥,二者不能同时开启,只能启用一个!!!)
查看当前haproxy的子进程信息,进一步查看子进程的线程信息
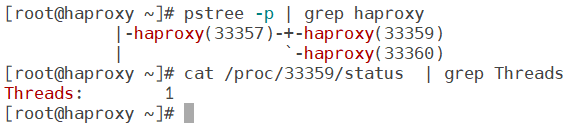
在haproxy.cfg文件中注释掉之前配置的多进程命令,然后添加多线程命令,保存退出,重启服务 查看线程,验证
查看线程,验证

3.3.3.proxies配置
1.proxies参数说明proxies
|-----------------------|---------|---------------------------------------------------------|
| 参数 | 类型 | 作用 |
| defaults \
| frontend <name> | proxies | 前端servername,类似于Nginx的一个虚拟主机server和LVS服务集群 |
| backend <name> | proxies | 后端服务器组,等于Nginx的upstream和LVS中的RS服务器 |
| listen <name> | proxies | 将frontend和backend合并在一起配置,相对于frontend和backend配置更加简洁,生产常用 |
name字段只能使用大小写字母,数字,'-'(dash),'_'(underscore),'.'(dot),':'(colon),并且严格区分大小写
2.proxies配置defaults
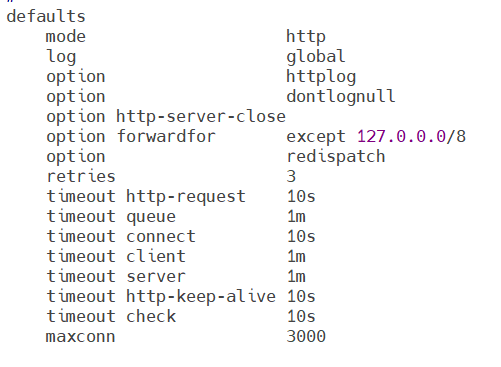
bash
defaults
mode http #haproxy实例使用的连接协议
log global #指定日志地址和记录日志条目的syslog/rsyslog日
#志设备,此处的global表示使用global配置段中设
#定的log值
option httplog #日志记录选项,httplog表示记录与http会话相关
#的各种属性值,包括http请求、会话状态、连接数
#、源地址以及连接
option dontlognull #dontlognull表示不记录空会话连接日志
option http-server-close #等待客户端完整http请求时间,此处为等待10s
option forwardfor except 127.0.0.0/8 #透传客户端真实ip至后端web服务器
#在apache配置文件中加入:<br>%{x-For
# warded-For}i
#后在webserver中看日志即可看到地址透
#传信息
option redispatch #当server id对应的服务器挂掉后,强制
#定向到其他健康的服务器,重新派发
retries 3 #连接后服务器失败次数
timeout http-request 10s #等待客户端请求完全被接收和处理的最长
#时间
timeout queue 1m #设置删除连接和客户端收到503或服务不可
#用等提示信息前的等待时间
timeout connect 10s #设置等待服务器连接成功的时间
timeout client 1m #设置允许客户端处于非活动状态,即既不发
#发送数据也不接收数据的时间
timeout server 1m #设置服务器超时时间,即允许服务器处于既
#不接收也不发送数据的非活动时间
timeout http-keep-alive 10s #session会话保持超时时间,此时间段内会
#转发到相同的后端服务器
timeout check 10s #指定后端服务器健康检查的超时时间
maxconn 3000实验:透传信息
透传取消的情况下:
注释掉option forwardfor except 127.0.0.0/8这段命令,保存退出,重启服务生效
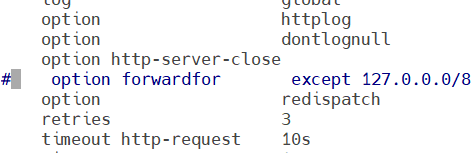
验证:新开一个页面尝试连接haproxy,再在webserver1中查看access_log


开启透传的情况下
把刚刚注释了的option forwardfor except 127.0.0.0/8这段命令取消注释,保存退出,重启服务生效
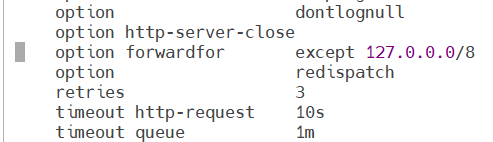
设定webserver1采集日志的模式

在201行添加 \"%{x-Forwarded-For}i 这段命令,保存退出,重启httpd服务生效
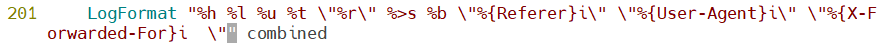
验证:在新页面上尝试连接haproxy,再在webserver1中查看access_log

3.proxies配置frontened
frontened配置参数
bind:指定haproxy监听地址,可以是ipv4或者ipv6,可以同时监听多个端口或ip,可以同时用于listen字段中
格式:bind \
注意:如果需要绑定在非本机的IP,需要开启内核参数:net.ipv4.ip_nonlocal_bind=1
backlog < backlog > #针对所有server配置,当前的端服务器的连接数达到上限后的后援队列长度,注意:不支持backend
4.proxies配置backend
定义一组后端服务器,backend服务器将被fronotend进行调用
注意:backend的名称必须唯一,并且必须在listen或frontend中事先定义才能被使用,否则服务无法被启用
mode #指定负载协议类型,相对应的frontend必须类型一致
log #配置选项
option #定义后端real server,必须指定IP和端口
注意:option后面加httpchk、smtpchk、mysql-check、pgsql-check、ssl-hello-chk方法可用于实现更多应用层检测功能
5.server配置
bash
#针对一个sever配置
check #对指定real进行健康状态检查,如果不加此设置,默认不开启检查,只有check后面没有其他
#配置也可以启用检查功能
#默认对相应的后端服务器IP和端口,利用tcp连接进行周期性健康性检查,注意必须指定端口
#才能实现健康性检查
addr <ip> #可指定的健康状态监测IP,可以是专门的数据网段,减少业务网络的流量
port <num> #指定的健康状态监测端口
inter <num> #健康状态检测间隔时间,默认2000ms
fall <num> #后端服务器从线上转为线下的检测的连接失败次数,默认为3
rise <num> #后端服务器从下线恢复到上线的检测的连续有效次数,默认为2
weight <weight> #默认为1,最大值为256,weight=0时状态为蓝色,表示不参与负载均衡,但仍接受持
#久连接
backup #将后端服务器标记为备份状态,只在所有非备份的主机宕机时提供服务,类似sorry server
disabled #将后端服务器标记为不可用状态,即维护状态,除了持久模式
#不再接受连接,状态为深黄色,优雅下线,不再接受新用户的请求
redirect prefix http://www.baidu.com/ #将请求临时(302)重定向至其他URL,只适用于http模式
maxconn <maxconn> #当前后端server的最大并发连接数