文章目录
- 前言
- [1. 正则表达式的定义](#1. 正则表达式的定义)
- [2. 正则表达式的语法规则](#2. 正则表达式的语法规则)
-
- [2.1 匹配什么字符](#2.1 匹配什么字符)
- [2.2 匹配多少次](#2.2 匹配多少次)
- [2.3 在哪里匹配](#2.3 在哪里匹配)
- [2.4 匹配指定格式的字符](#2.4 匹配指定格式的字符)
- 3.单行模式与多行模式
- [4. 贪婪模式和懒惰模式](#4. 贪婪模式和懒惰模式)
- [5. match函数和search函数](#5. match函数和search函数)
-
- [5.1 match函数](#5.1 match函数)
- [5.2 re.search函数](#5.2 re.search函数)
- [6. findall函数 和 sub函数](#6. findall函数 和 sub函数)
-
- [6.1 findall 函数](#6.1 findall 函数)
-
- [6.2 sub 函数](#6.2 sub 函数)
- [7. split 函数 和 compile 函数](#7. split 函数 和 compile 函数)
-
- [7.1 split函数](#7.1 split函数)
- [7.2 compile函数](#7.2 compile函数)
- 总结
前言
正则表达式是每一位开发者必须掌握的文本处理利器,它能以简洁语法高效完成复杂匹配任务。本文系统介绍正则表达式的核心语法与实战应用,涵盖基础匹配规则、单多行模式、贪婪懒惰模式等关键概念,并结合Python re模块的常用方法进行代码演示。通过在线工具regex101.com可以边学边练,助你快速掌握这一实用技能
1. 正则表达式的定义
正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、
regexp或RE),是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特
殊字符(称为"元字符")。正则表达式使用单个字符串来描述、匹配一系列符合某个
句法规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。通俗
的说,正则表达式就是一种语法规则,用来匹配文本中的文本。
正则表达式非常强大,不仅在UNIX系统中应用广泛,近二十年来,在Windows系统
中也得到极大的发展,现如今主流的操作系统包括Linux、Unix、Windows和主流的
开发语言包括C/C++、Java、JavaScript、C#、Python、Go、PHP等。
这里有一个可以测试正则表达式的小工具,可以实操一下
https://regex101.com/
基本功能如下
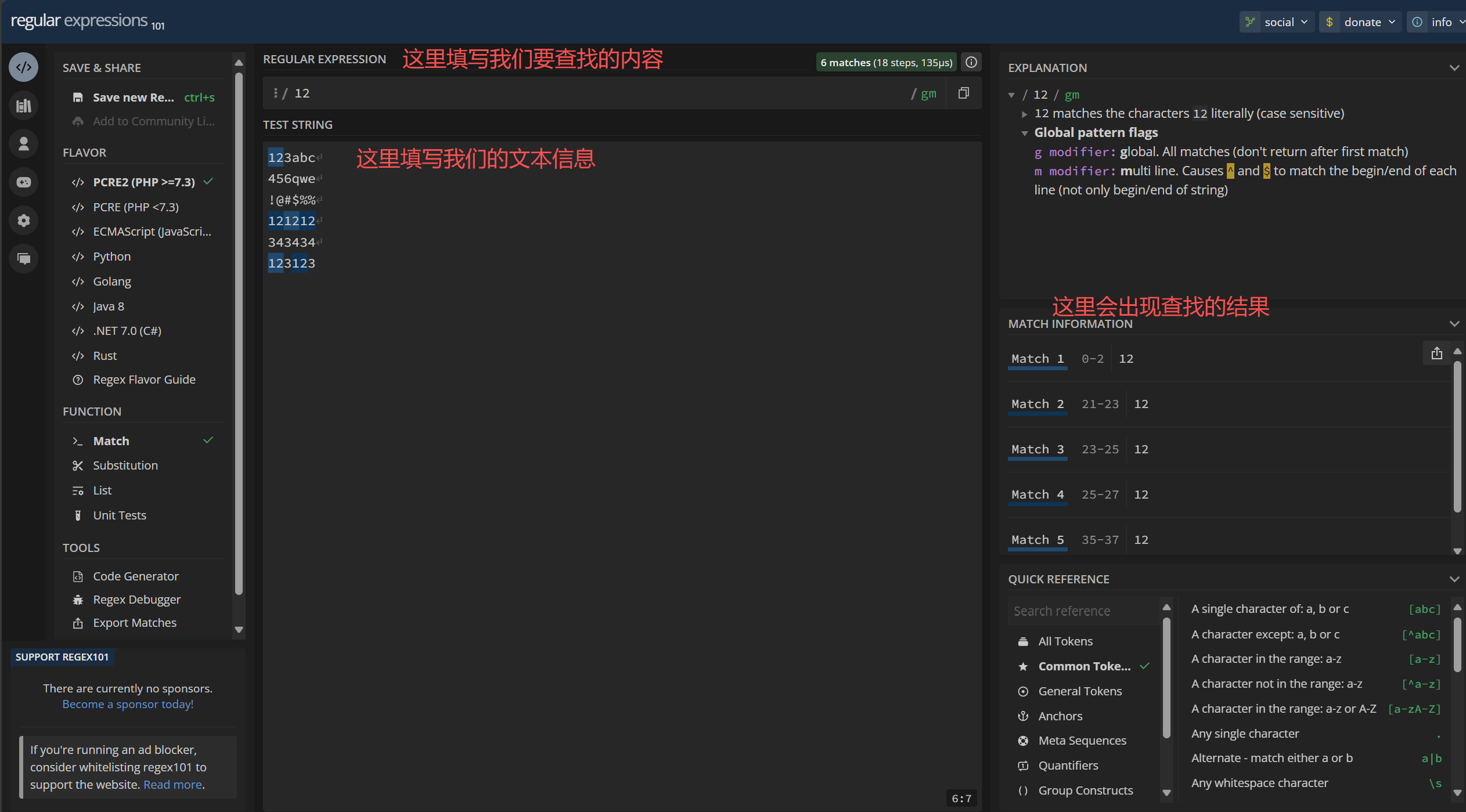
2. 正则表达式的语法规则
2.1 匹配什么字符
1. .:匹配任意的字符(换行符除外)
2. \d:匹配数字字符
3. \D:匹配非数字字符
4. \w:匹配单词字符(英文、数字、下划线)
5. \W:匹配非单词字符
6. \s:匹配空白符(包括换行符、Tab键、空格)
7. \S:匹配非空白字符2.2 匹配多少次
1. *: 出现0次或多次(贪婪)
2. +:出现1次或多次(贪婪)
3. ?:出现0次或1次(懒惰)
4. {n}:出现n次
5. {n, m}:出现n~m次
6. {n,}:出现n次以上2.3 在哪里匹配
1. ^:在行首的位置匹配
2. $:在行尾的位置匹配
3. \b:表示匹配单词边界。(比如\bword,可以匹配word、words,但不会匹配
sword)2.4 匹配指定格式的字符
使用()匹配指定格式的字符,比如:
(ab):表示在文本中只匹配ab这两个字符,且必须相邻
(a|b):表示在文本中匹配a或者b这两个字符,不一定相邻使用\[\]匹配指定类别的字符串,比如
[abcd]:表示匹配a或匹配b或匹配c或匹配d
[a-d]:表示匹配a或匹配b或匹配c或匹配d
[a-zA-Z0-9]:表示匹配所有的大小写英文和数字
[^0-9]:表示匹配除了数字之外的所有字符3.单行模式与多行模式
概念定义
单行模式:
在单行模式下,.(小数点)可以匹配任何的字符,包括换行符,并且整个文本会被认为是一个完整的文本,使用^和$只能匹配到文本的开头和结尾。
多行模式:
在多行模式下,.就不可以匹配换行符了,使用^和$可以匹配到每一行的开始和结束。4. 贪婪模式和懒惰模式
概念定义
在正则表达式中,
贪婪匹配和懒惰匹配是两种不同的数量匹配策略。它们决定了量词
(比如*、+、?、{n,m}等)如何匹配尽可能多的或尽可能少的字符。
1.贪婪模式:指在正则表达式中的量词会尽可能多地匹配字符。
2.懒惰模式:指在正则表达式中的量词会尽可能少地匹配字符。(需要手动设置)** ? 的作用**
1.
?作为限定符,表示其修饰对象只能出现0次或1次。
2.
?放在量词前,表示将匹配模式改为懒惰匹配模式。
3.
(?=pattern):表示匹配位置后面必须跟着pattern模式的字符,匹配结果并不包括这个模式的字符串。
4.
(?!pattern):表示匹配位置后面不能跟着pattern模式的字符,匹配结果并不包括这个模式的字符串。
5.
(?<=pattern):表示匹配位置前面必须跟着pattern模式的字符,匹配结果并不包括这个模式的字符串。
6.
(?<!pattern):表示匹配位置前面不能跟着pattern模式的字符,匹配结果并不包括这个模式的字符串。
7.
(?:pattern):表示将pattern包含在一个分组中,但不把这个分组的匹配结果保存到分组编号中。5. match函数和search函数
5.1 match函数
re.match 是 Python 标准库 re 模块中的一个函数,用于从字符串的起始位置匹配正则表达式。如果匹配成功,返回一个匹配对象;否则返回 None。
函数原型为:
re.match(pattern,string,flags)pattern:正则表达式的格式
string:被匹配的文本
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写、设置多行匹配模式等
适用场景
1. 验证输入格式:检查用户输入是否符合特定的格式,例如电子邮件、电话号码、
日期等。
2. 提取信息:从字符串的开始位置提取符合正则表达式模式的字串,如提取文件名
等。
3. 数据解析:在处理日志文件或配置文件时,可以用来解析每行的开始部分,获取
关键信息。使用match函数校检邮箱格式是否正确
python
import re#首先要用import导入这个re
while True:#定义一个死循环
email = input('请输入有效的邮箱:')
pattern = r'[0-9a-zA-Z+-_.]+@[0-9a-zA-Z.-]+\.[a-zA-Z]{2,}'#用正则表达式定义一个正确的邮箱格式
res = re.match(pattern, email)
if res:
print('您的邮箱格式正确')
break
else:
print('您的邮箱格式有误,请重新输入')输出结果:
python
#当我输入一个正确的邮箱格式
请输入有效邮箱:1234567891@ww.cn
这是正确的邮箱
#当我输出一个错误的邮箱格式,它会输出报错,并且程序不会停止,会让你再输入,
#直到输入格式正确,然后输出这是正确的邮箱
请输入有效邮箱:132
你输入的邮箱格式有误,请重新输入
请输入有效邮箱:5.2 re.search函数
定义概念
re.search是Python标准库re模块中的一个函数,用于在字符串中搜索正则表达式匹配的第一个位置。与re.match不同,re.search会扫描整个字符串,而不仅限于从字符串开头匹配。
函数原型:
re.search(pattern,string,flags=0)pattern:正则表达式的模式。
string:要搜索的字符串。
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写、
设置多行匹配模式等.
适用场景
1. 验证字符串包含特定模式:检查一个字符串是否包含某个特定的文本。
2. 提取字符串中的特定部分:从字符串中的任意位置提取信息,例如从一个文本段落中提取所有提
到的日期。
3. 搜索替换操作:在某文件中查找特定的消息或事件。用re.search函数获取一个符合表达式的字符的位置
python
import re
text = '''
dkjsahdkasd
15780742078
25752577555
24522425323
faffdasfasd
'''
pattern = r'^[1]{1}[3589]{1}[0-9]{9}$'
res = re.search(pattern,text,re.M)
if res:
print(res.group())
print(res.start())#返回匹配开始的位置,因为11个字母后还有换行符所以为13输出结果为:
python
15780742078
136. findall函数 和 sub函数
6.1 findall 函数
概念定义
findall 是 Python re 模块中的函数,用于在字符串中匹配所有符合正则表达式模式的子串,并以列表形式返回结果。
语法:
re.findall(pattern, string, flags=0)参数作用:
pattern:正则表达式字符串。
string:待匹配的原始字符串。
flags(可选):控制匹配方式的标志(如 re.IGNORECASE 忽略大小写)。返回值:
返回所有非重叠匹配的子串列表。若正则包含分组,则返回分组元组的列表;若无匹配则返回空列表。
findall函数的使用
python
import re
text = "a1b2c3"
matches = re.findall(r'\d', text) # 匹配所有数字
print(matches) 输出结果为:
python
['1','2','3']6.2 sub 函数
概念定义
sub 是 re 模块中用于替换字符串中匹配正则表达式部分的内容的函数。
语法:
re.sub(pattern, repl, string, count=0, flags=0)参数作用
pattern:正则表达式字符串。
repl:替换的字符串或函数(若为函数,需接收匹配对象并返回替换字符串)。
string:待处理的原始字符串。
count(可选):最大替换次数(默认为0,表示全部替换)。
flags(可选):匹配标志用sub函数进行替换
python
import re
#原始字符串
text = "Hello 123 World 456"
#定义一个正则表达式,匹配数字
pattern = r'\d+'
#定义一个替换函数
def replace(match):
#将匹配到的数字乘以2
number = int(match.group())
return str(number*2)#使用re.sub和替换函数
new_text = re.sub(pattern, replace, text)
print(new_text)输出结果为:
python
Hello 246 World 9127. split 函数 和 compile 函数
7.1 split函数
定义概念
re.split 用于根据正则表达式模式分割字符串,分割后结果放在列表中返回
语法
re.split(pattern, string, maxsplit=0, flags=0)参数说明
pattern:正则表达式模式。
string:需要分割的字符串。
maxsplit:最大分割次数,默认为 0(表示不限制)。
flags:正则表达式标志(如 re.IGNORECASE)代码示例
python
import re
text = "apple,banana,orange,watermelon"
fruits = re.split(r',\s',text)
print(fruits)输出结果为:
python
['apple,banana,orange,watermelon']7.2 compile函数
定义概念
re.compile 用于将正则表达式模式编译为一个正则表达式对象,以便重复使用。
语法
re.compile(pattern, flags=0)参数说明
pattern:正则表达式模式。
flags:正则表达式标志(如 re.IGNORECASE)代码示例
python
import re
email_pattern = re.compile(r'apple(?= banana)')
#使用编译后的模式进行多次匹配
text ='''
apple
apple banana
apple orange
'''
emails = email_pattern.findall(text)
print(emails)输出结果为:
python
['apple']总结
本文系统讲解了正则表达式的核心知识体系:从基础字符匹配(如\d, \w, \s)到量词使用(*, +, ?, {n,m}),从位置匹配(^, $, \b)到高级模式选择。通过Python re模块的match、search、findall、sub等函数实战演示,展现了正则表达式在文本处理中的强大能力。掌握正则表达式需要多多练习,建议读者在实际项目中灵活运用,必将大幅提升开发效率。