note
文章目录
一、Qwen3-VL微调训练数据
数据集汇总
| 数据集 | 样本数 | 大小 | 字段 |
|---|---|---|---|
| alpaca-gpt4-data-zh | 48,818 | 30.69 MB | instruction, input, output |
| la_te_x_ocr | 1,200 | 15.49 MB | image, text |
| video_chat_gpt | 1,996 | 0.71 MB | video_name, question, answer |
| 总计 | 52,014 | ~47 MB | - |
样例展示
1. alpaca-gpt4-data-zh (中文指令数据)
- 纯文本问答对,如:
instruction: 保持健康的三个提示→output: 1.保持身体活动...
2. la_te_x_ocr (LaTeX公式OCR)
- 图像+文本对,如:公式图片 →
z_{1} = r_{1}(\cos\theta_{1} + i\sin\theta_{1})
3. video_chat_gpt (视频对话)
- 视频+问答对,如:
video: v_hFi6S_guB7I+question: 视频开头女舞者的外观?→answer: 五位穿不同颜色肚皮舞服装的女舞者...
二、模型训练和推理
两阶段训练vl模型(训练 Aligner 层 + 训练整个模型):https://swift.readthedocs.io/zh-cn/latest/BestPractices/Rapidly-Training-VL-model.html
- 训练 Aligner 层:仅训练视觉到语言的对齐层(Aligner),冻结 ViT 和 LLM 部分
- 训练整个模型:解冻所有模块,联合训练以增强模型的整体视觉理解能力
Lora微调:
python
model_path="./model/Qwen3-VL-8B-Instruct"
# 2 * 21GiB
PYTORCH_CUDA_ALLOC_CONF='expandable_segments:True' \
IMAGE_MAX_TOKEN_NUM=1024 \
VIDEO_MAX_TOKEN_NUM=128 \
FPS_MAX_FRAMES=16 \
NPROC_PER_NODE=2 \
CUDA_VISIBLE_DEVICES=0,1 \
swift sft \
--model $model_path \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#10000' \
'AI-ModelScope/LaTeX_OCR:human_handwrite#5000' \
'swift/VideoChatGPT:Generic#2000' \
--load_from_cache_file true \
--split_dataset_ratio 0.01 \
--tuner_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--attn_impl flash_attn \
--padding_free true \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--freeze_aligner true \
--packing true \
--gradient_checkpointing true \
--vit_gradient_checkpointing false \
--gradient_accumulation_steps 2 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 4096 \
--output_dir output \
--warmup_ratio 0.05 \
--deepspeed zero2 \
--dataset_num_proc 4 \
--dataloader_num_workers 41、LaTeX OCR数据集推理测试例子:
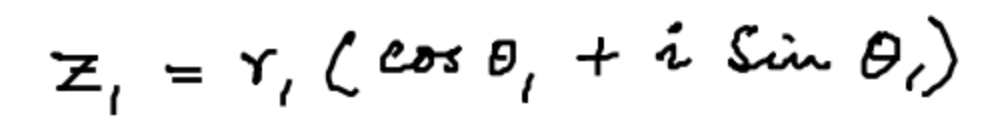
真值和推理结果如下所示:
python
📋 Ground Truth: z _ { 1 } = r _ { 1 } ( \cos \theta _ { 1 } + i \sin \theta _ { 1 } )
🤖 模型预测: $$z _ { i } = r _ { i } ( \cos \theta _ { i } + i \sin \theta _ { i } )$$2、GUI agent任务(computer use)推理测试:query=打开浏览器并搜索天气
图中左上角有个浏览器
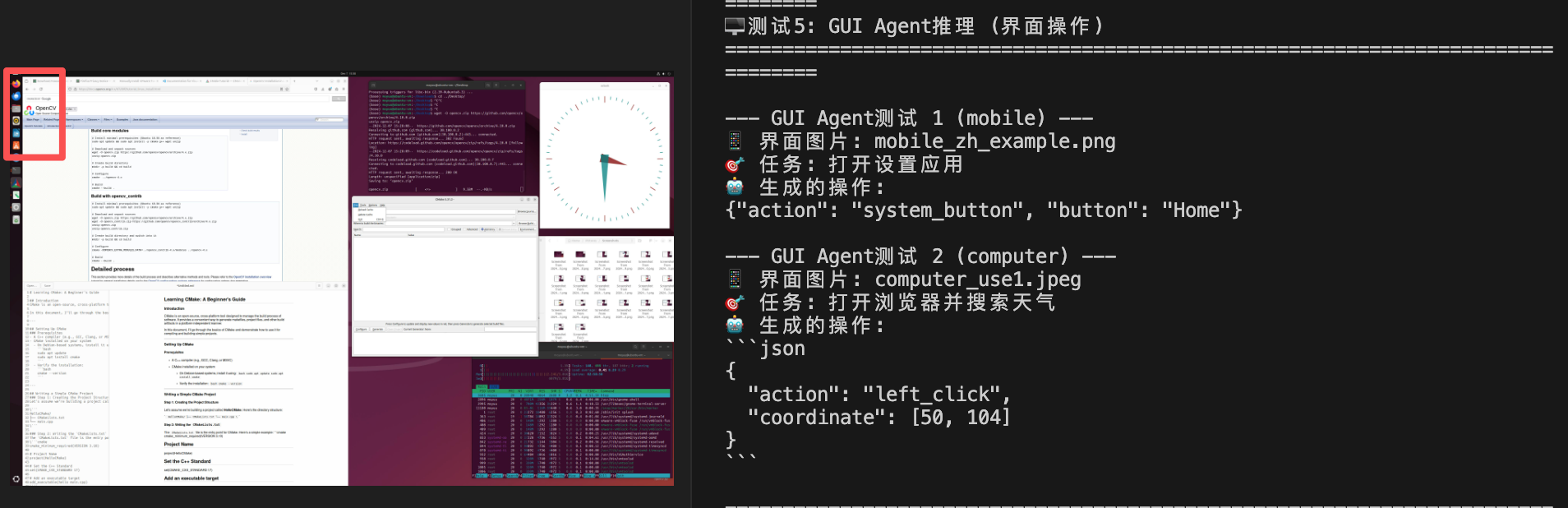
3、function call测试:对着手机某无关app的截图,query=我想查看北京今天的天气情况
这种情况图中也不会有实时更新天气数据,所以还是会function call。
python
📋 可用工具列表:
• search_web: 在网上搜索信息,参数: query(搜索关键词)
• get_weather: 获取天气信息,参数: city(城市名)
• open_app: 打开应用程序,参数: app_name(应用名称)
• send_message: 发送消息,参数: recipient(收件人), content(内容)
• take_screenshot: 截取当前屏幕,无参数
• navigate_to: 导航到指定位置,参数: destination(目的地)
--- Function Call测试 1 ---
🖼️ 图片: mobile_zh_example.png
❓ 用户问题: 我想查看北京今天的天气情况
🤖 工具调用:
{
"thought": "用户想查看北京今天的天气情况,这是一个获取天气信息的需求。图片内容与天气无关,因此需要调用获取天气的工具。",
"tool_name": "get_weather",
"tool_args": {
"city": "北京"
}
}Reference
1 两阶段训练vl模型(训练 Aligner 层 + 训练整个模型):https://swift.readthedocs.io/zh-cn/latest/BestPractices/Rapidly-Training-VL-model.html
2 https://swift.readthedocs.io/zh-cn/latest/BestPractices/Qwen3-VL-Best-Practice.html