双向注意力是同时建模两个序列之间双向信息流动的注意力机制,广泛应用于机器翻译、问答系统、多模态融合等任务。以下是深度解析:
1. 核心概念与原理
- 什么是双向注意力?
- 定义:双向注意力同时计算两个方向的信息流动:
- 方向 1:序列 A → 序列 B(A 作为 Query,B 作为 Key/Value)
- 方向 2:序列 B → 序列 A(B 作为 Query,A 作为 Key/Value)
shell
序列 A: [a1, a2, a3, ..., aN]
↓↑ ↓↑ ↓↑
序列 B: [b1, b2, b3, ..., bM]
双向注意力 = Attention(A→B) + Attention(B→A)2. 数学形式化
标准注意力(单向)
py
# A → B 的单向注意力
Attention(Q=A, K=B, V=B) = softmax(QK^T/√d) · V双向注意力(双向)
py
# 双向注意力 = 两个单向注意力的组合
BidirectionalAttention(A, B) = {
# 方向 1: A → B
attn_A_to_B = softmax(A · B^T / √d) · B # [N, D]
# 方向 2: B → A
attn_B_to_A = softmax(B · A^T / √d) · A # [M, D]
# 合并输出(可选)
output = concat(attn_A_to_B, attn_B_to_A) # 或其他融合方式
}3、双向注意力的类型
3.1. 对称双向注意力(Symmetric Bidirectional Attention)
特点:两个方向使用相同的参数
适用场景:对称任务(如语义相似度计算)
py
class SymmetricBidirectionalAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super().__init__()
self.attn = nn.MultiheadAttention(embed_dim, num_heads, batch_first=True)
def forward(self, A, B):
# A → B
attn_A_to_B, _ = self.attn(A, B, B)
# B → A(使用相同的参数)
attn_B_to_A, _ = self.attn(B, A, A)
return attn_A_to_B, attn_B_to_A3.2. 非对称双向注意力(Asymmetric Bidirectional Attention)
• 特点:两个方向使用独立的参数
• 适用场景:非对称任务(如机器翻译、问答)
py
class AsymmetricBidirectionalAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super().__init__()
# 独立的注意力头
self.attn_A_to_B = nn.MultiheadAttention(embed_dim, num_heads, batch_first=True)
self.attn_B_to_A = nn.MultiheadAttention(embed_dim, num_heads, batch_first=True)
def forward(self, A, B):
# A → B
attn_A_to_B, _ = self.attn_A_to_B(A, B, B)
# B → A
attn_B_to_A, _ = self.attn_B_to_A(B, A, A)
return attn_A_to_B, attn_B_to_A3.3. 交叉双向注意力(Cross Bidirectional Attention)
- 特点:在 Transformer 层中交替使用两个方向
- 适用场景:多模态融合(如视觉-语言)
py
class CrossBidirectionalAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super().__init__()
self.attn_A_to_B = nn.MultiheadAttention(embed_dim, num_heads, batch_first=True)
self.attn_B_to_A = nn.MultiheadAttention(embed_dim, num_heads, batch_first=True)
self.norm1 = nn.LayerNorm(embed_dim)
self.norm2 = nn.LayerNorm(embed_dim)
def forward(self, A, B):
# 第一层:A → B
attn_A_to_B, _ = self.attn_A_to_B(A, B, B)
A_enhanced = self.norm1(A + attn_A_to_B)
# 第二层:B → A(使用增强后的 A)
attn_B_to_A, _ = self.attn_B_to_A(B, A_enhanced, A_enhanced)
B_enhanced = self.norm2(B + attn_B_to_A)
return A_enhanced, B_enhanced3. 与其他注意力机制对比
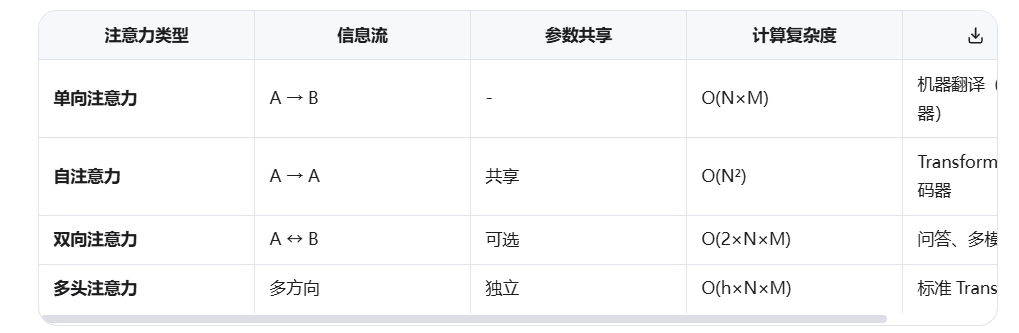
4.完整实现示例
- 基础双向注意力层
py
import torch
import torch.nn as nn
import torch.nn.functional as F
class BidirectionalAttention(nn.Module):
"""
双向注意力层:同时建模 A→B 和 B→A 的信息流动
"""
def __init__(self, embed_dim, num_heads=8, dropout=0.1):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
# 独立的注意力头(非对称)
self.attn_A_to_B = nn.MultiheadAttention(
embed_dim, num_heads, dropout=dropout, batch_first=True
)
self.attn_B_to_A = nn.MultiheadAttention(
embed_dim, num_heads, dropout=dropout, batch_first=True
)
# LayerNorm 和 Dropout
self.norm_A = nn.LayerNorm(embed_dim)
self.norm_B = nn.LayerNorm(embed_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, A, B, attn_mask_A=None, attn_mask_B=None):
"""
Args:
A: (batch_size, seq_len_A, embed_dim)
B: (batch_size, seq_len_B, embed_dim)
attn_mask_A: (batch_size, seq_len_A) - 可选
attn_mask_B: (batch_size, seq_len_B) - 可选
Returns:
A_enhanced: (batch_size, seq_len_A, embed_dim)
B_enhanced: (batch_size, seq_len_B, embed_dim)
"""
# 方向 1: A → B
attn_A_to_B, attn_weights_A_to_B = self.attn_A_to_B(
query=A,
key=B,
value=B,
key_padding_mask=attn_mask_B
)
A_enhanced = self.norm_A(A + self.dropout(attn_A_to_B))
# 方向 2: B → A
attn_B_to_A, attn_weights_B_to_A = self.attn_B_to_A(
query=B,
key=A_enhanced, # 使用增强后的 A
value=A_enhanced,
key_padding_mask=attn_mask_A
)
B_enhanced = self.norm_B(B + self.dropout(attn_B_to_A))
return A_enhanced, B_enhanced, attn_weights_A_to_B, attn_weights_B_to_A- 堆叠双向注意力(Transformer 风格)
py
class BidirectionalAttentionEncoder(nn.Module):
"""
堆叠多层双向注意力
"""
def __init__(self, embed_dim, num_layers=6, num_heads=8, dropout=0.1):
super().__init__()
self.layers = nn.ModuleList([
BidirectionalAttention(embed_dim, num_heads, dropout)
for _ in range(num_layers)
])
self.norm_A = nn.LayerNorm(embed_dim)
self.norm_B = nn.LayerNorm(embed_dim)
def forward(self, A, B, attn_mask_A=None, attn_mask_B=None):
"""
逐层堆叠双向注意力
"""
for layer in self.layers:
A, B, _, _ = layer(A, B, attn_mask_A, attn_mask_B)
A = self.norm_A(A)
B = self.norm_B(B)
return A, B- 完整的双向注意力模型
py
class BidirectionalAttentionModel(nn.Module):
"""
完整的双向注意力模型(以问答为例)
"""
def __init__(self, vocab_size, embed_dim=512, num_layers=6, num_heads=8):
super().__init__()
# Embedding 层
self.embedding = nn.Embedding(vocab_size, embed_dim)
# 双向注意力编码器
self.encoder = BidirectionalAttentionEncoder(
embed_dim=embed_dim,
num_layers=num_layers,
num_heads=num_heads
)
# 输出层
self.output_proj = nn.Linear(embed_dim, vocab_size)
def forward(self, question_ids, document_ids, question_mask=None, document_mask=None):
"""
Args:
question_ids: (batch_size, seq_len_q)
document_ids: (batch_size, seq_len_d)
question_mask: (batch_size, seq_len_q) - padding mask
document_mask: (batch_size, seq_len_d) - padding mask
"""
# Embedding
question_embed = self.embedding(question_ids) # [B, Q, D]
document_embed = self.embedding(document_ids) # [B, D, D]
# 双向注意力编码
question_enhanced, document_enhanced = self.encoder(
question_embed, document_embed, question_mask, document_mask
)
# 输出(以问题增强表示为例)
logits = self.output_proj(question_enhanced) # [B, Q, vocab_size]
return logits, question_enhanced, document_enhanced