大家在做AI应用开发过程中,一般都需要将内部文档进行知识化分割与存储,最常用的方法之一就是构建知识库,知识库构建方法有多种技术,比如基于成熟应用开发平台提供的知识构建功能创建知识库、通过编写程序操作向量库实现知识库构建、通过n8n的工作流机制构建知识库等等。本文主要介绍最后一种,即如何基于n8n编写一个用于RAG的知识库构建的工作流,实现将散落的文档、内部文件和历史记录转化为基于大模型(LLM)的私有知识库(即 RAG 系统的底层),本质上是构建了一个"企业/专家的数字大脑"。基于 n8n 构建知识库(通常是构建 RAG,即"检索增强生成"工作流的第一步)是一个非常高效的选择,n8n中高度可视化的方式能够灵活实现知识库的构建和应用,具体如下。
一、主要流程设计
一个标准的知识库构建工作流主要包含以下几个核心步骤:触发启动 → 获取数据源 → 读取与提取 → 文本分割 → 向量化 (Embedding) → 存入向量数据库。以下是一个典型的轻量级知识库构建链路,主要流程如下图。
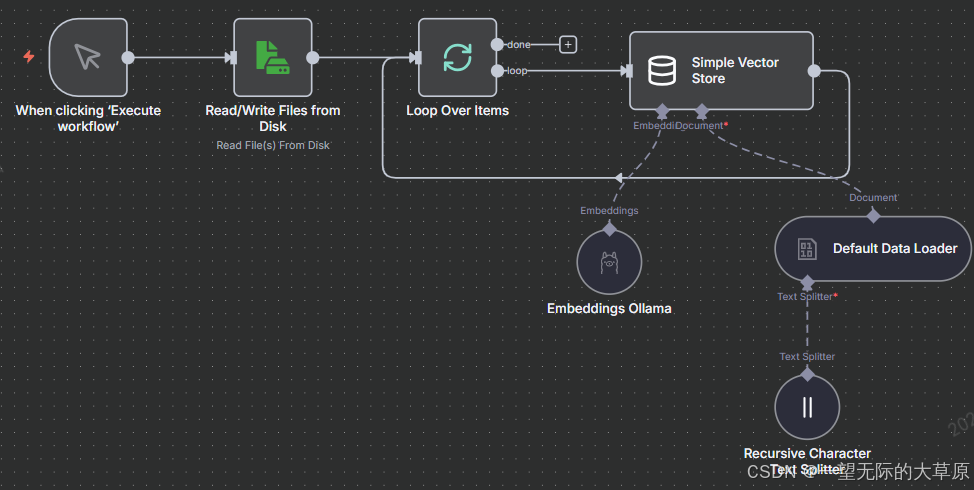
1.Read/Write Files from Disk节点
Operation选择 Read File from disk
File Selector选择存放文件的目录,读取所有文件夹及子文件夹下的所有文件。
2.Simple Vector Store节点
Operation Mode选择 Insert Documents
Memory Key 设置要创建的向量库名称,这个名称在后续的agent工作流中使用该key访问,并设置embedding size为200
Embedding 选择 Embedding Ollama
Document 选择 Default Data Loader
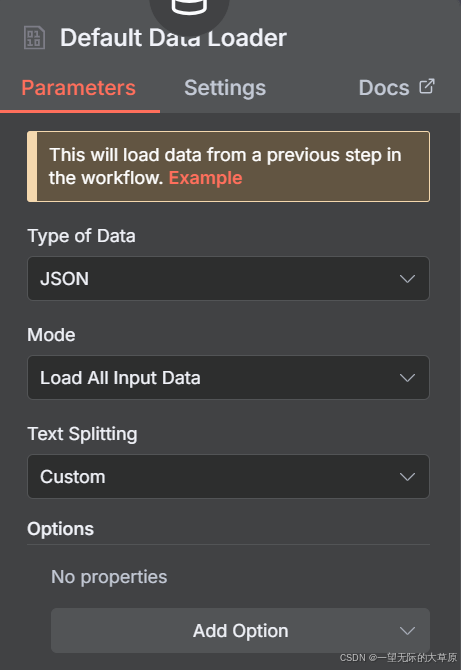
3.Default Data Loader节点
参数设置见下图
4.Text Splitter节点
选择Recursive Character Text Splitter
Chunk Size 设置 4000
Chunk Overlap 设置 200
二、主要应用场景
这种基于 n8n 构建的知识库工作流主要应用于工业与能源领域的数字化转型、企业内部运营与知识服务等方面。具体如下。
1.复杂设备运维辅助
将成千上万页的设备操作手册、维修日志和安全生产标准(HSE)存入向量数据库。一线工程师在现场遇到问题时,可以通过语音或文字描述故障现象,AI 会立刻检索手册并给出精准的排障步骤。
2.赋能数字孪生 (Digital Twin) 与 AI Agent
数字孪生系统虽然能呈现设备的三维状态和实时传感器数据,但缺乏"操作智慧"。通过 API 将知识库与 AI 智能体(Agent)结合,当系统报警时,Agent 不仅能看到报警代码,还能自动检索历史类似事故的处置预案,生成辅助决策报告给指挥中心。
3.IT 与 管理制度服务台 (Helpdesk)
将公司所有的 IT 故障排查指南、软件使用说明(包括各类技术栈如 Python、C++ 环境配置的常见问题)、管理制度建立知识库。员工遇到问题先问 AI,拦截 80% 的重复性基础工单。
4.投标与科研方案辅助撰写
将公司过去所有成功的中标标书、技术方案、产品白皮书进行向量化。销售或方案工程师在撰写新方案时,可以快速让 AI 检索类似案例的架构描述或公司资质介绍,拼装成初步草稿。
三、应用价值
这种基于 n8n 构建的知识库工作流带来的价值主要体现在以下3个方面:
1.打破信息孤岛,实现知识资产化
日常工作中,大量的关键信息散落在 PDF 报告、Word 培训材料、长篇邮件和设备手册中。传统的关键词搜索常常找不到所需内容。知识库通过"向量化"提取了文本的语义,让知识可以被跨格式、跨部门地精准检索,真正变成了企业的数字资产。
2.复刻专家经验,降低对核心人员的依赖
资深员工的经验往往是隐性的。通过将资深人员编写的培训材料、处理过的复杂案例记录存入知识库,新员工可以像请教老专家一样,随时向 AI 提问并获得带有上下文的专业解答,大幅缩短人才培养周期。
3.从"人找信息"到"信息找人"
传统模式下,员工需要阅读几十页文档去寻找一个条款。有了知识库,员工只需用自然语言提问(例如:"根据最新的合规手册,这笔差旅费可以报销吗?"),AI 会直接阅读相关片段并总结出答案,同时附上引用来源,极大地提升了决策和工作效率。
总而言之,使用 n8n 构建的知识库,就是为 AI 应用建设铺设了一条通往你私有数据的高速公路。一旦公路建好,上面跑的就可以是各种各样的智能体(Agents)和自动化工作流。