
干货:
1、kafka客户端(图形)工具(如:CMAK、Kafka-map等)上看到的消息不管实际队列中有没有压缩,展示到界面上的都是解压后的(如果存储的是压缩后的数据工具会自动解压后展示到界面上)
2、命令:kafka-topics.sh --describe *** 看到消息信息不一定能看到实际的压缩信息(验证不了是否被压缩)
3、命令:kafka-console-consumer.sh *** 的 print-storage-info 参数在kafka3.4版本开始就废弃了,所以之后的版本无法使用该参数验证其是否被压缩
4、验证压缩最权威的方法就是直接读取 Broker 上的日志文件,展示每条消息的压缩状态
在Apache Kafka中,数据压缩是一种常见的优化手段,特别是在传输大量数据时。压缩可以显著减少网络带宽的使用,提高数据传输的效率。Kafka支持多种压缩格式,如GZIP、Snappy、LZ4等。验证Kafka队列中的数据是否被压缩,可以通过以下几种方法来实现:
1. 使用Kafka命令行工具
Kafka提供了kafka-console-consumer命令行工具,可以用来查看队列中的数据。你可以在消费数据时指定压缩格式,以便查看是否启用了压缩。
例如,如果你知道消息使用了GZIP压缩,你可以在消费时指定压缩格式:
bash
kafka-console-consumer --bootstrap-server <broker-list> --topic <topic-name> --from-beginning --property print.key=true --property print.value=true --property print.timestamp=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.ByteArrayDeserializer --property compression.type=gzip2. 使用Kafka API
如果你正在使用Kafka的Java客户端或其他编程语言客户端(如Python、C#等),你可以在配置消费者时指定压缩格式,并检查接收到的消息是否已经解压。
Java 示例:
java
Properties props = new Properties();
props.put("bootstrap.servers", "<broker-list>");
props.put("group.id", "test");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.ByteArrayDeserializer");
props.put("compression.type", "gzip"); // 如果已知压缩类型
KafkaConsumer<String, byte[]> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("<topic-name>"));
while (true) {
ConsumerRecords<String, byte[]> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, byte[]> record : records) {
// 在这里,你可以检查record的值是否是你期望的解压后的数据格式
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), new String(record.value()));
}
}3. 检查Kafka主题配置
你也可以检查Kafka主题的配置,看看是否启用了压缩。可以通过Kafka命令行工具kafka-configs来查看主题的配置:
bash
kafka-configs --bootstrap-server <broker-list> --entity-type topics --entity-name <topic-name> --describe | grep compression.type这将显示该主题的压缩类型设置。
4. 查看Broker日志或监控工具
在某些情况下,你也可以查看Kafka broker的日志或使用监控工具(如Kafka Manager, Confluent Control Center等)来查看主题的配置和性能指标,间接确认是否使用了压缩。
通过上述方法,你可以有效地验证Kafka队列中的数据是否被压缩,并了解如何处理或消费这些压缩后的数据。
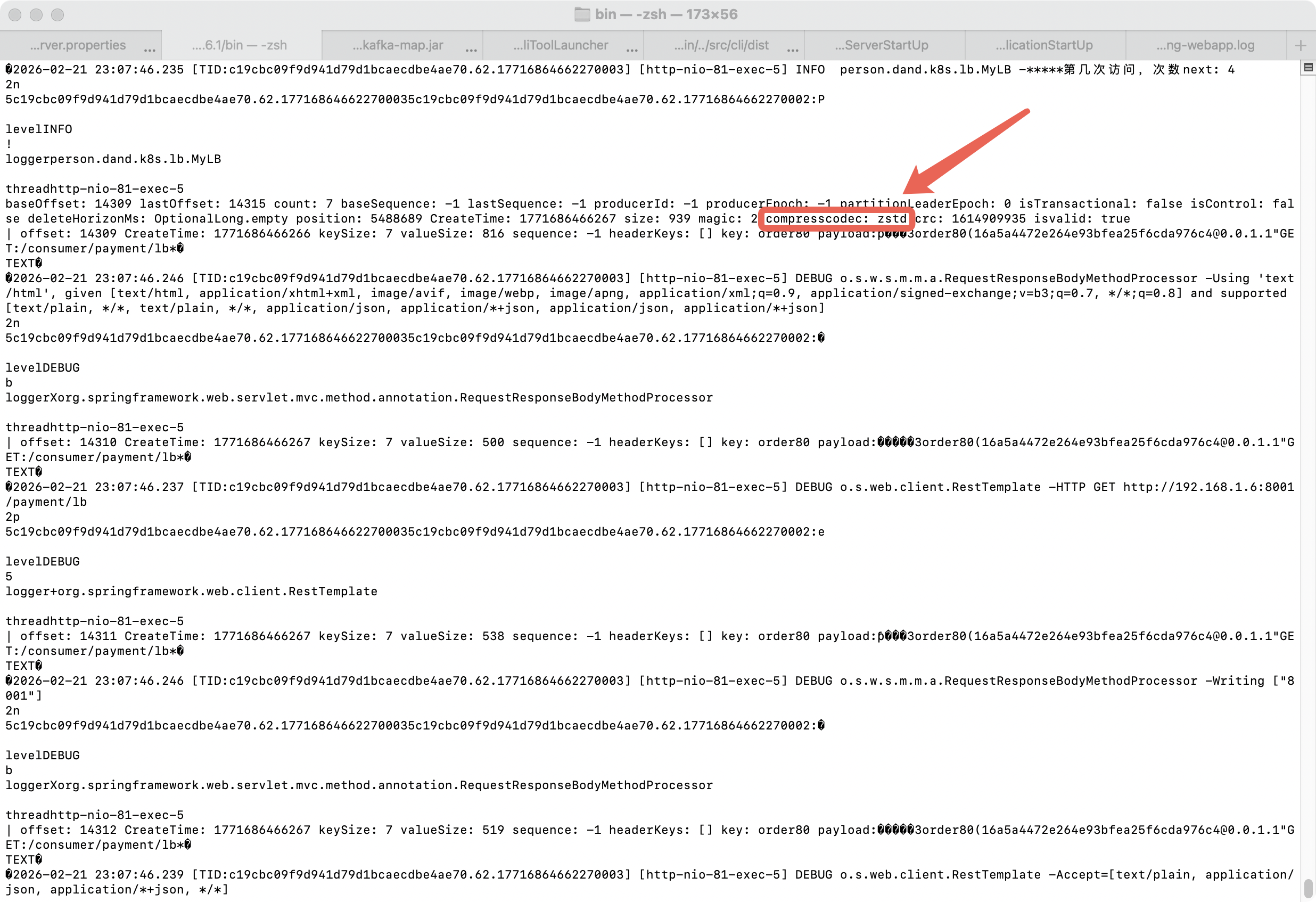
附件一:查看Broker日志验证举例
bash
./kafka-dump-log.sh \
--files /private/tmp/kraft-combined-logs/skywalking-logs-0/00000000000000000000.log \
--print-data-log下面是作者在MacOS上通过查看Broker日志验证过程举例:
附件二:Kafka可视化管理工具
-) Kafka Map -- 国产、开源,通过配置kafka地址实现管理(作者使用)
kafka-map: 一个美观简洁且强大的kafka web管理工具。
-) kafka CMAK -- 通过配置zookeeper地址实现管理(作者使用)
GitHub - yahoo/CMAK: CMAK is a tool for managing Apache Kafka clusters
-) kafka-monitor -- 开源
https://github.com/linkedin/kafka-monitor/wiki
-) kafka-eagle -- 商业软件(收费)
等等
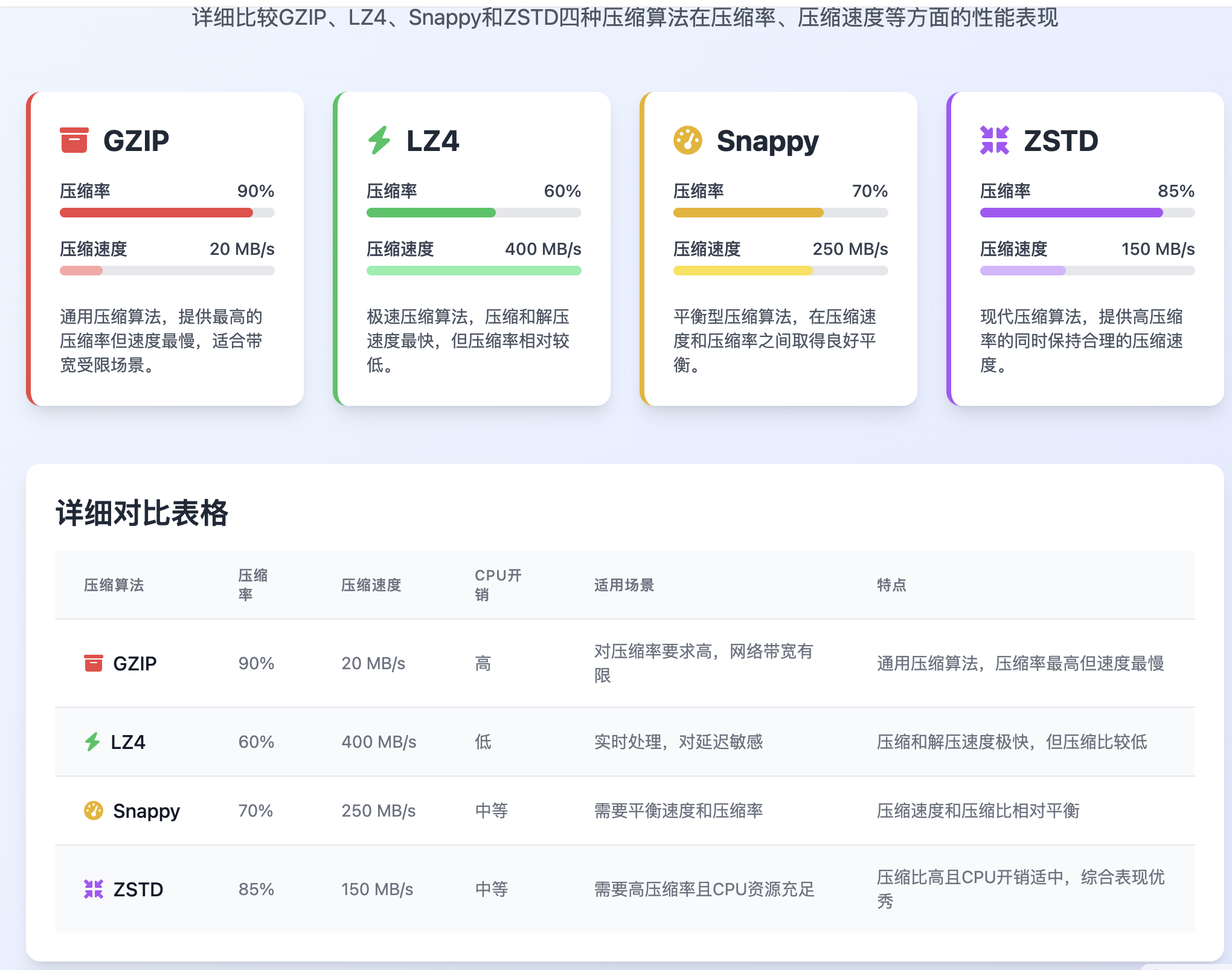
附件三:几种压缩算法对比
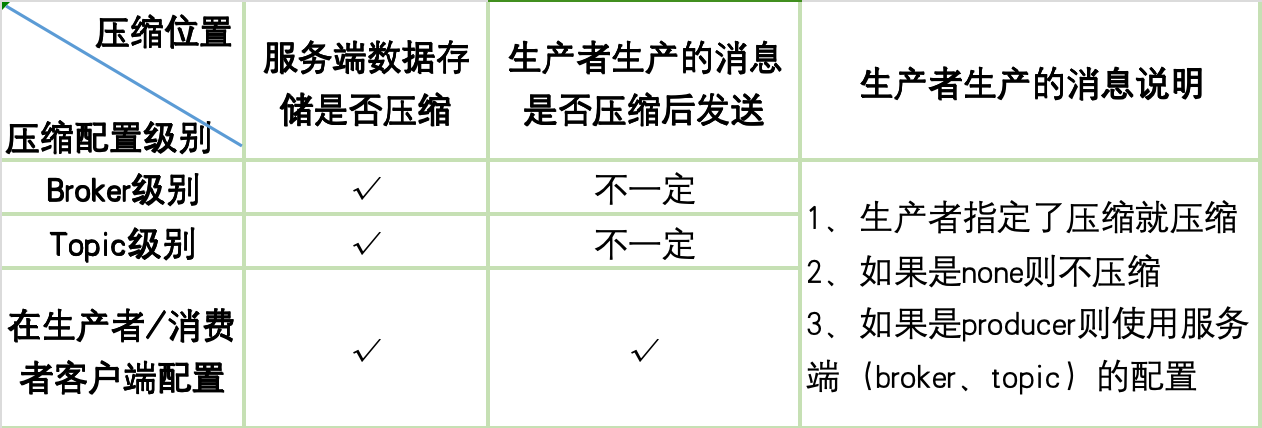
附件四:数据压缩--图表总结
附件五:Kafka几项核心的底层技术
Kafka 的高性能、高可靠性和高吞吐量,源于其一系列精妙的底层设计技术。以下是几项核心的底层技术:
1. 分区(Partition)与并行处理
Kafka 将每个主题(Topic)划分为多个分区,每个分区是一个有序的、不可变的消息日志。这种设计是 Kafka 实现高吞吐量和水平扩展的基础。
- 并行读写:生产者可以将消息并行写入不同的分区,消费者也可以并行地从多个分区拉取消息,极大地提升了系统的并发处理能力。
- 负载均衡:分区可以分布在集群中的不同 Broker 上,实现了数据的分布式存储和负载均衡。
- 顺序性保证 :Kafka 保证了分区内消息的严格顺序,虽然跨分区的消息顺序无法保证,但对于大多数场景,分区内有序已足够。
**2. 顺序写入与零拷贝(Zero-Copy)**
Kafka 充分利用了磁盘和操作系统的特性来优化性能。
- 顺序写入:消息被追加(Append)到分区日志文件的末尾,这种顺序写入方式避免了磁盘频繁的寻道操作,使得 Kafka 在普通机械硬盘上也能实现极高的写入吞吐量。
- 零拷贝技术 :当消费者读取消息时,Kafka 利用操作系统的
sendfile系统调用,直接将数据从磁盘文件缓冲区传输到网络缓冲区,避免了数据在内核态与用户态之间的多次拷贝。这显著降低了 CPU 开销,提升了网络传输效率。
3. 副本机制(Replication)与 ISR
为了保证数据的高可用性和可靠性,Kafka 引入了副本机制。
- Leader/Follower:每个分区有多个副本,其中一个被选举为 Leader,负责处理所有生产者和消费者的读写请求;其他副本为 Follower,仅从 Leader 异步拉取数据进行同步。
- ISR(In-Sync Replicas) :Kafka 维护一个"同步副本"列表(ISR),只有那些与 Leader 副本同步延迟在可接受范围内的 Follower 才会被包含在 ISR 中。**只有当消息被写入 ISR 列表中的所有副本后,生产者才会收到确认(ack=-1)**,这确保了即使 Leader 宕机,数据也不会丢失。
- 高可用性:当 Leader 宕机时,Kafka 会从 ISR 列表中选举出一个新的 Leader,保证服务不中断。
4. 批量处理与消息压缩
Kafka 通过批量操作来 amortize(分摊)网络和磁盘 I/O 开销。
- 批量发送 :生产者会将多条消息缓存起来,达到一定大小(
batch.size)或等待一定时间(linger.ms)后,再一次性发送给 Broker,减少了网络请求次数。 - 消息压缩:生产者可以在发送前对消息批次进行压缩(如 gzip、snappy、lz4),减少了网络传输的数据量和磁盘存储空间。Broker 在存储和传输时也以压缩格式处理,消费者在消费时再解压。
5. 分段日志(Segment)与索引
为了管理庞大的日志文件并实现高效的消息查找,Kafka 采用了分段和索引机制。
- **分段(Segment)**:每个分区的日志文件被切割成多个大小固定的段(Segment)文件。当一个段文件达到预设大小(如 1GB)时,Kafka 会创建一个新的段文件。这使得日志文件的管理和清理(如删除过期数据)更加高效。
- 索引文件 :每个段文件对应两个索引文件------偏移量索引 (.index)和时间戳索引(.timeindex)。偏移量索引采用稀疏存储方式,通过二分查找可以快速定位到消息在日志文件中的物理位置,实现了 O(log n) 的消息查找时间复杂度。
6. 消费者位移(Offset)管理
Kafka 将消费进度(即位移)的管理权交给了消费者,而非 Broker。
- 消费者自主管理 :消费者在消费消息后,会定期将自己消费到的位移(Offset)提交并保存(可保存在 Kafka 内部主题
__consumer_offsets或外部存储如 Redis 中)。 - 容错与重放:如果消费者宕机,重启后可以从最后一次提交的位移处继续消费,保证了"至少一次"(At-Least-Once)的语义。这种设计也允许消费者灵活地重放历史消息。