导言:本文主要介绍langchain出现的原因与背景
一、AI时代下的编程
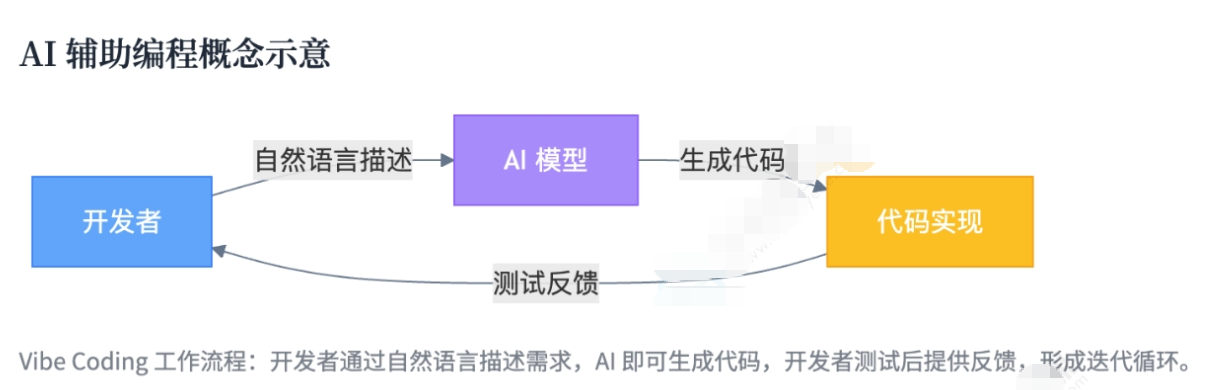
1.1Vibe Coding
AI时代下,低代码与无代码开发冲上热点,最近Vibe Coding(氛围编程)被人们熟知,其是⼀种依赖⼈⼯智能的计算机编程实践,其核⼼在于:开发者使⽤⾃然语⾔提⽰向针对代码优化的⼤语⾔模型(LLM)描述问题,由 LLM ⽣成软件,从⽽使程序员摆脱编写和调试底层代码的需要。
1.2局限性
• 代码质量与架构的"⿊箱"困境
AI 的⽬标是⽣成功能上可运⾏的代码,但它⽆法理解什么是"优雅"、"可维护"、"可扩展"的代码架构。• 上下⽂⻓度的"⾦⻥记忆"与知识滞后性
有限的上下⽂窗⼝:即使上下⽂⻓度在不断增⻓,LLM 也⽆法记住并理解⼀个庞⼤项⽬的全部代码。在开发过程中,后期的⼀个需求可能需要修改前期⽣成的代码。AI 由于"忘记"了之前的完整上下⽂,很可能会⽣成与现有架构冲突或重复的代码,导致系统腐化。知识截⽌与"幻觉":LLM 的训练数据有截⽌⽇期,它可能⽆法使⽤最新的语⾔特性、库版本或最佳实践。更危险的是,它可能会"幻觉"出⼀些不存在的 API、库函数或参数,⽣成看似正确实则⽆法运⾏的代码,这对开发者甄别能⼒提出了极⾼要求。
• 安全性与可靠性的"隐形地雷"
这是Vibe Coding在企业级应⽤中最致命的弱点。
安全漏洞的⽆声引⼊:AI没有 "安全" 意识。它可能会轻松地⽣成含有 SQL 注⼊、XSS 攻击、硬编码密码、不当的权限设置等安全漏洞的代码。对于安全⾄关重要的系统(如⾦融、医疗),这是⼀个不可接受的⻛险。可靠性难以保障:⽣成的代码缺乏经过严格测试的可靠性。它可能在⼩规模数据下运⾏良好,但在⾼并发、⼤数据量或边缘案例下表现不稳定甚⾄崩溃。缺乏完善的⽇志、监控和熔断机制,使得线上排查问题变得极其困难
二、AI开发框架
2.1背景
⼤语⾔模型(LLM)如 ChatGPT 的崛起,不仅改变了⼈机交互的⽅式,更彻底重塑了软件开发的游戏规则。如今,构建⼀个 AI 应⽤早已不再是简单地调⽤ API,⽽是需要应对数据处理、模型交互、任务编排和状态管理等复杂挑战。
即使 AI 代码⽣成⼯具(Vibe Coding)⽇益强⼤,但它们⽣成的代码往往只是"能⽤"⽽⾮"优秀"。真正的专业开发者需要理解架构设计、系统权衡与⼯程最佳实践⸺这正是框架学习的核⼼价值。
2.2原则
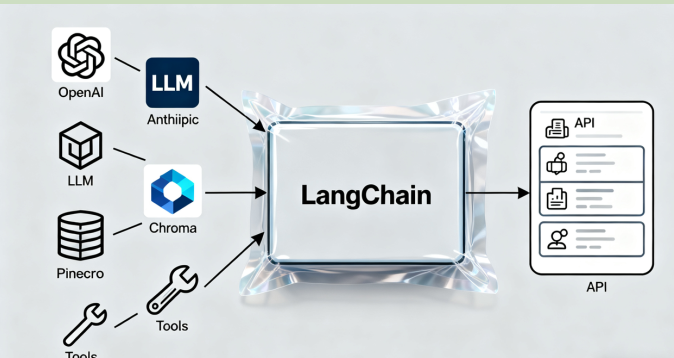
(1)抽象与封装,如LangChain:封装了与不同 LLM(OpenAI, Anthropic 等)、向量数据库(Chroma, Pinecone)、⼯具(Tools)交互的复杂性。开发者不需要为每个供应商编写不同的 API 调⽤代码。
(2)模块化与可组装性,如LangChain:核⼼概念就是"链"(Chain),它将不同的模块(LLM, Prompts, Tools, Memory,Output Parsers)像乐⾼积⽊⼀样组合起来,构建复杂的 AI ⼯作流。
三、引入原生大模型的问题
(1)引发幻觉问题,比如答非所问,错误诊断或者在代码方面给出错误接口
(2)需要用户实现统一标准的提示词
(3)不同原生模型间切换困难
(4)对自然语言的解析能力弱,⾮结构化输出难以与程序接⼝交互
(5)大模型的训练是有截止日期的,不具备实时性
(6)对于非常专业的知识,模型的内在知识训练的还是不充分
四、LangChain
4.1概念:
为了解决引入原生大模型造成的问题,langchain作为一款AI开发框架应运而生
LangChain 是⼀个⽤于开发由⼤语⾔模型 (LLM) 驱动的应⽤程序的框架。它通过将⾃然语⾔处理(NLP)流程拆解为标准化组件,让开发者能够⾃由组合并⾼效定制⼯作流。• 组件(Components):⽤来帮助当我们在构建应⽤程序时,提供⼀系列的核⼼构建块,例如语⾔模型、输出解析器、检索器等。
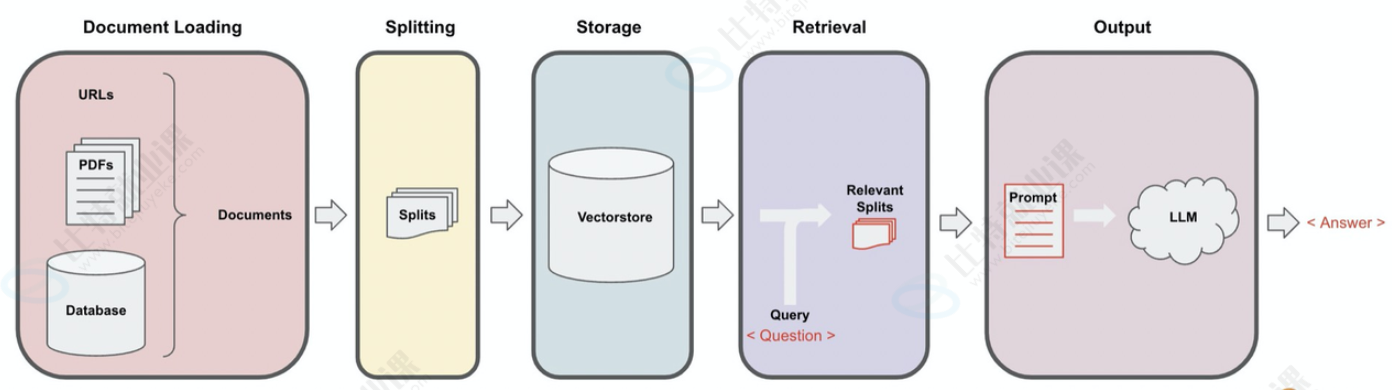
• ⾃然语⾔处理流程(NLP):指的是完成⼀个特定 NLP 任务所需的⼀系列步骤。例如,构建⼀ 个"基于公司⽂档的问答机器⼈"的流程可能包括:读取⽂档、分割⽂本、将⽂本转换为向量 (嵌⼊)、存储向量、接收⽤⼾问题、搜索相关⽂本段、将问题和⽂本段组合发送给⼤语⾔模型(LLM)、解析模型输出并返回答案等。
4.2技术特点
4.2.1技术
LangChain 框架的设计精髓在于以链式(Chain)的⽅式整合多个组件
• 向外提供统⼀的模型调⽤:通过抽象化的接⼝⽀持多种⼤语⾔模型(例如 OpenAI GPT-4/5、AnthropicClaude 等)和嵌⼊模型,使开发者可以灵活切换不同模型供应商。
• 灵活的提⽰词管理:提供提⽰词模板(Prompt Templates),⽀持动态⽣成输⼊内容,并可管理 少样本⽰例与提⽰选择策略,以提升模型响应质量。
• 可组合的任务链(Chains):允许将多个步骤串联成完整流程,如先检索⽂档再⽣成回复,或组合 多次模型调⽤。开发者能够通过⾃定义链实现复杂的任务编排。
• 上下⽂记忆机制(Memory):⽤于存储多轮对话中的状态信息。LangChain 曾提供多种记忆管理 ⽅案(如对话历史记忆和摘要记忆),以实现连贯的交互体验(注:该功能⽬前已由 LangGraph ⽀持,原有实现已过时)。
• 检索与向量存储集成:⽀持从外部加载⽂档,经分割和向量化处理后存储⾄向量数据库,在查询时 检索相关信息并输⼊⼤语⾔模型,帮助构建检索增强⽣成(RAG)类应⽤。LangChain 兼容多种主 流向量数据库(如 FAISS、Pinecone、Chroma)和⽂档加载⼯具,简化知识库应⽤的开发流程。
4.2.2相关概念
调用LLM一般步骤:
接入并定义大模型 -- 定义消息列表 -- 调用大模型 -- 输出结果
不加LangChain:
python
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义消息列表
messages = [
SystemMessage(content="Translate the following from English into Chinese"),
HumanMessage(content="my name is Tom!"),
]
# 调用大模型
result = model.invoke(messages)
print(result)
#字符串输出
parser = StrOutputParser()
print(parser.invoke(result))加上后我们就可以让调用与输出等操作连在一起
python
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义消息列表
messages = [
SystemMessage(content="Translate the following from English into Chinese"),
HumanMessage(content="my name is Tom!"),
]
# 调用大模型
#字符串输出
parser = StrOutputParser()
# 引入链式操作,将调用和字符串输出连在一起
chain = model | parser
result = chain.invoke(messages)
print(result)怎么实现的?
Runnable 接⼝
Runnable 接⼝是使⽤ LangChain Components(组件)的基础。
概念说明:
Components(组件):⽤来帮助当我们在构建应⽤程序时,提供了⼀系列的核⼼构建块,例如语⾔模型、输出解析器、检索器、编译的 LangGraph 图等。
Runnable 定义了⼀个标准接⼝,允许 Runnable 组件:
• Invoked(调⽤): 单个输⼊转换为输出。
• Batched(批处理): 多个输⼊被有效地转换为输出。
• Streamed(流式传输): 输出在⽣成时进⾏流式传输。
• Inspected(检查): 可以访问有关 Runnable 的输⼊、输出和配置的原理图信息。
• spected(检查): 可以访问有关 u able 的输⼊、输出和配置的原理图信息。
• Composed(组合): 可以组合多个 Runnable,以使⽤ LCEL 协同⼯作以创建复杂的管道。
LangChain Expression Language
LangChain Expression Language(LCEL):采⽤声明性⽅法,从现有 Runnable 对象构建新的Runnable 对象。通过 LCEL 构建出的新的 Runnable 对象,被称为 RunnableSequence ,表⽰可运⾏序列。
python
# 引入链式操作,将调用和字符串输出连在一起
chain = model | parser
result = chain.invoke(messages)
print(result)
chain = RunnableSequence(first=model, last=parser)
chain = model.pipe(parser)