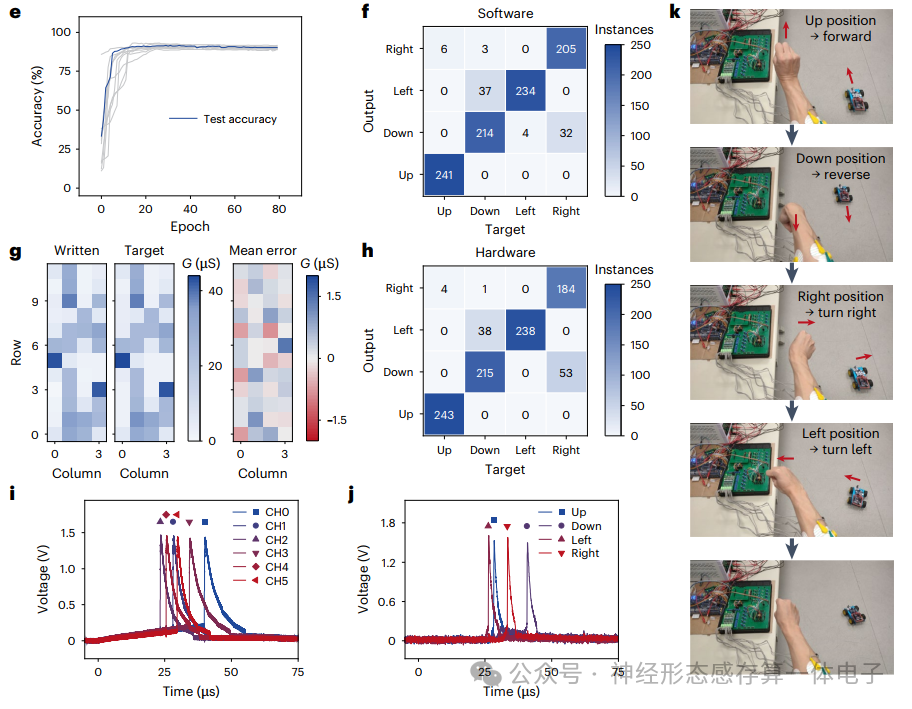
神经形态系统对于智能人机界面的发展至关重要。忆阻硬件可以模拟生物系统的神经元动力学,但通常使用速率编码,而单尖峰编码(其中信息由每个神经元的单个尖峰的放电时间和神经元之间的相对放电时间表示)更快、更节能。在这里,我们报告了一种使用单尖峰编码的鲁棒忆阻硬件系统。对于输入编码和神经处理,我们使用均匀的氧化钒忆阻器来创建一个编码可变性低于1%的单脉冲电路。对于突触计算,我们开发了一种电导巩固策略和映射方案,以限制氧化铪/氧化钽忆阻器芯片中由于弛豫引起的电导漂移,实现标准偏差在1.2以内的弛豫电导状态 μS.我们还开发了一种增量步长和宽度脉冲编程策略,以防止资源浪费。相对于软件基线,组合的端到端硬件单尖峰编码系统的精度下降了1.5%以下。我们表明,这种方法可用于从表面肌电图进行实时车辆控制。仿真表明,我们的系统消耗的能量比传统速率编码系统低约38倍,延迟低约6.4倍。

2026年1月15日,相关研究成果以"An end-to-end memristive hardware system based on single-spike coding for human--machine interfaces"为题发表在国际顶级期刊Nature Electronics上,北京大学杨玉超教授为论文通讯作者。
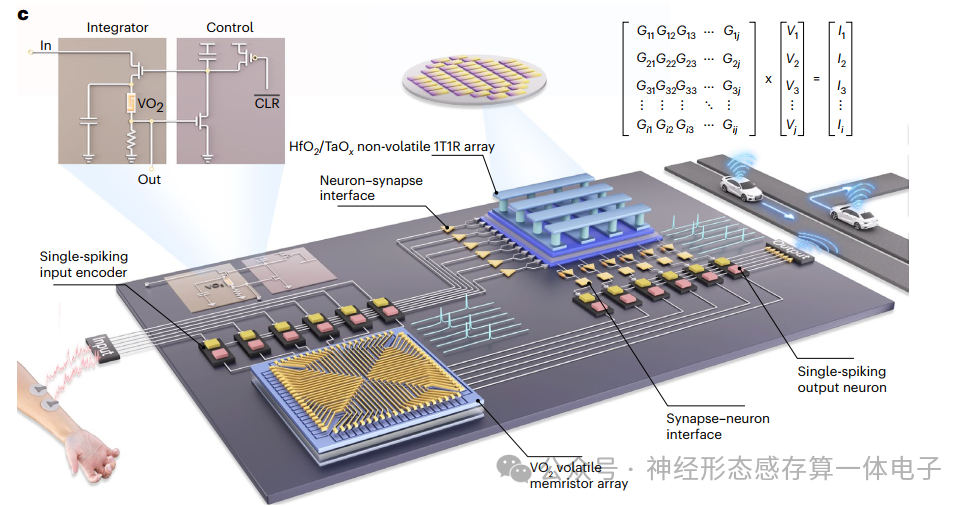
能够从数据中学习并做出判断和决策的人机界面(HMI)可用于虚拟/增强现实、假肢、疾病检测和协作操作等应用。然而,能够在边缘执行复杂的、类似认知功能的HMI的开发将需要具有低功耗预算和快速响应时间的体面计算能力,这超出了传统冯·诺伊曼计算范式的限制。这导致了生物启发神经形态计算等替代方案的探索,通过使用时间尖峰的并行事件驱动计算以低能耗进行稳健的时间处理。
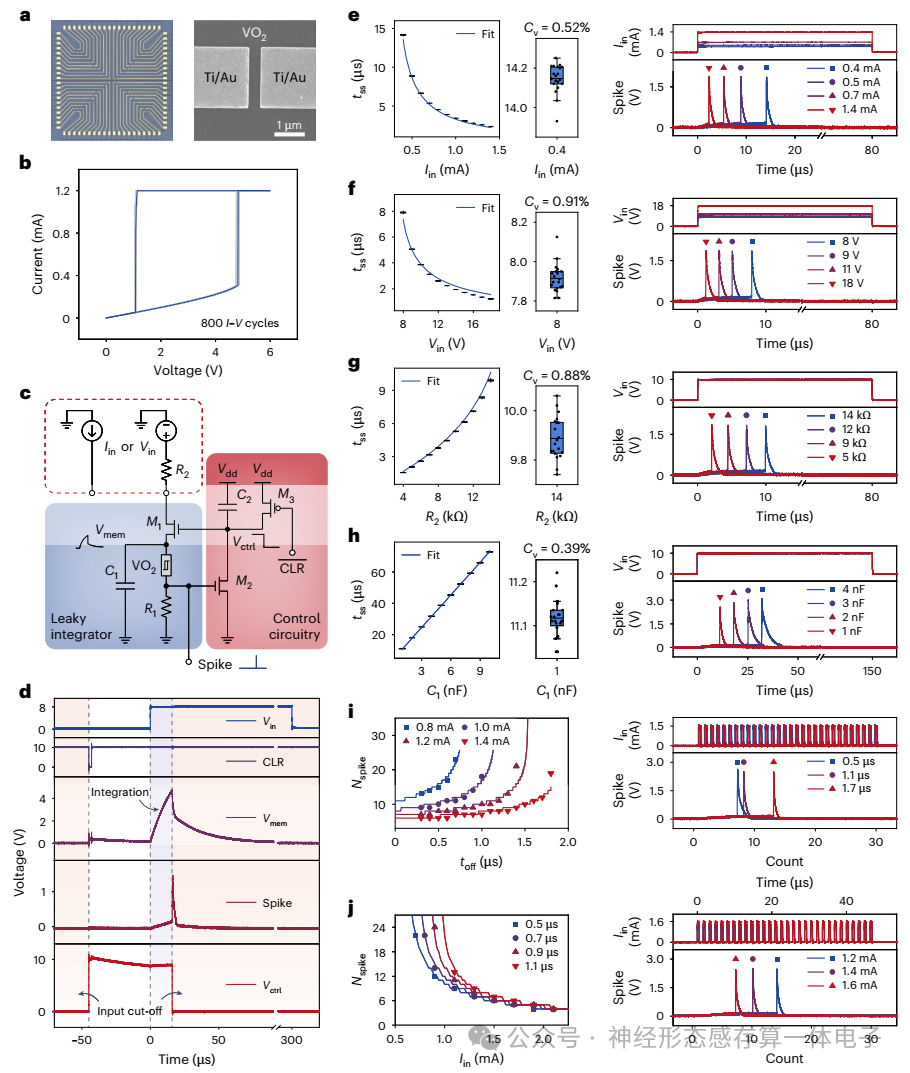
在各种生物神经编码策略中,第一尖峰时间编码策略是嵌入信息最快的方法之一。这种编码策略广泛存在于感觉编码以及体感皮层内的信息处理中,导致生物反应时间比其他编码方法(如速率编码)更快。为了实现高能效,应省略过多和冗余的尖峰,因此,第一尖峰时间编码具有单尖峰编码的形式。已经报道了HMI中首次尖峰时间编码的几种实现方式,但大多数完全依赖于基于互补金属氧化物半导体(CMOS)的电路来模拟神经动力学,导致硬件成本很高。忆阻器表现出类似于生物系统中的神经动力学,因此非常适合实现神经原始性。然而,大多数报道的基于忆阻器的神经形态系统仍然使用高度抽象的速率编码,这忽略了尖峰的内在时间性。尽管已经尝试使用忆阻器实现时间编码,但缺乏用于初始输入编码和下游神经处理的单脉冲、高度均匀和紧凑的实现。
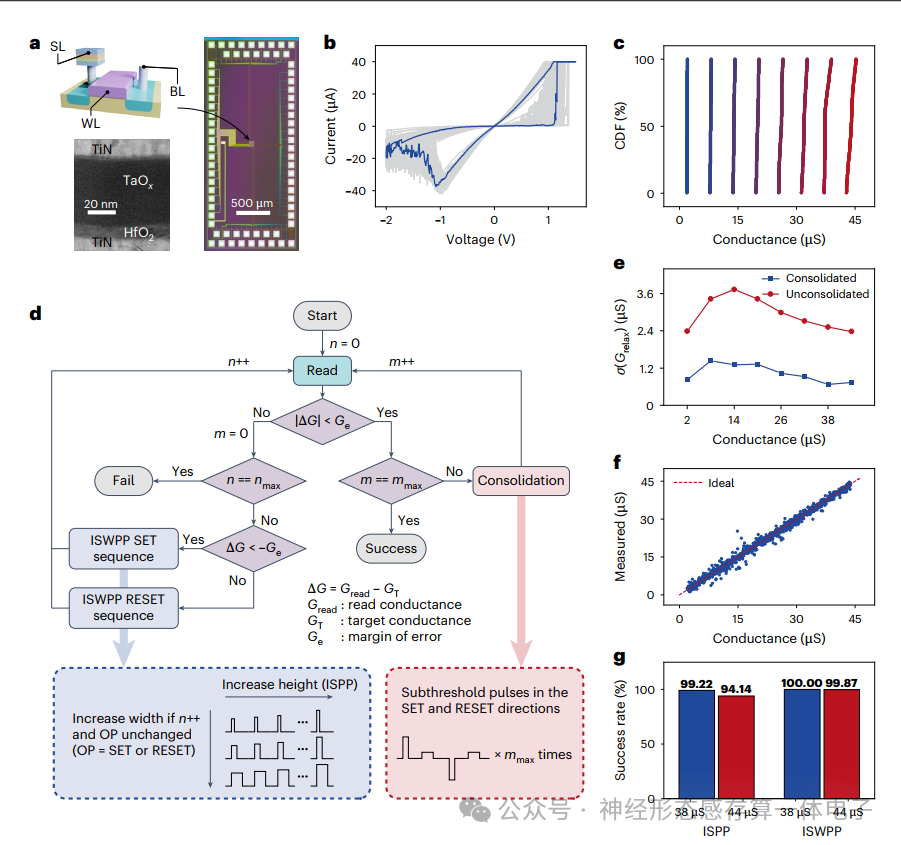
神经形态系统的另一个关键组成部分是人工突触。非易失性忆阻器本质上具有执行突触计算的长期可塑性,这些忆阻器的交叉开关阵列已被用于证明高度并行的内存计算。然而,器件的非理想性,如弛豫引起的电导漂移,已被证明会降低网络性能。当使用信息的压缩表示时,这变得更加有害,阻碍了更有效的神经编码方案的采用。已经提出了几种减少松弛以实现精确权重映射的编程策略。然而,它们抑制放松的能力仍然有限。
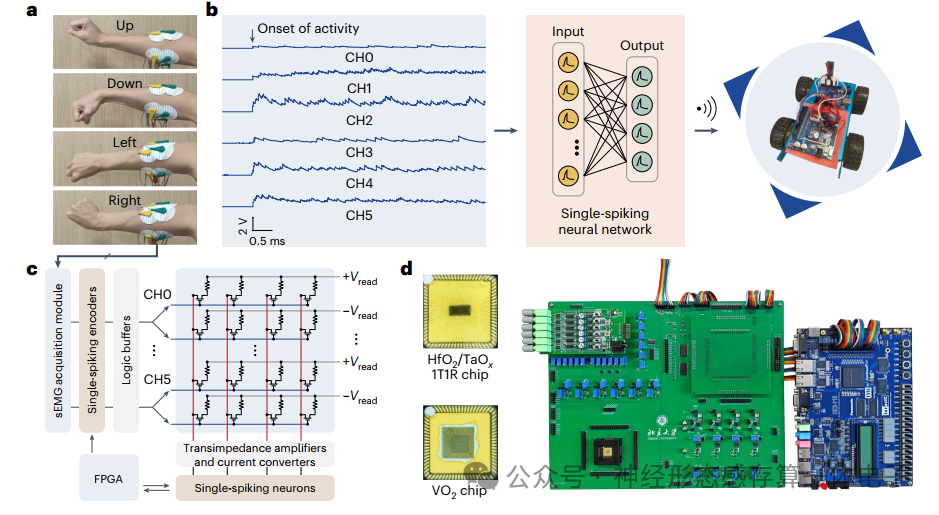
在这篇文章中,研究人员报告了一种在端到端硬件配置中实现的鲁棒忆阻单脉冲系统。我们使用均匀氧化钒(VO2)阈值开关忆阻器来实现单尖峰基元,从而保证高精度编码和将信息压缩到单个尖峰的触发时间。接下来,我们使用氧化铪(HfO2)/氧化钽(TaOx)单晶体管单电阻器(1T1R)阵列作为人工突触,并在编程过程中开发了一个简单的电导巩固步骤,以尽量减少弛豫,进一步在突触计算过程中保存信息。我们用增量步长和宽度脉冲编程(ISWPP)策略来增强编程方法,以最大限度地减少阵列资源的浪费,这是资源有限边缘应用中的一个重要考虑因素。利用单脉冲基元和稳定的1T1R突触,我们构建了一个硬件单脉冲系统,并将其用于表面肌电(EMG)处理任务,以说明其在HMI系统中的潜力。从基于软件的演示转移到基于硬件的演示时,精度下降不到1.5%。对更大的单脉冲网络的进一步仿真研究表明,与传统的速率编码系统相比,能耗降低了约38倍,延迟降低了6.4倍。