1.C++11的简介
在2003年C++标准委员会曾经提交了一份技术勘误表(简称TC1),使得C++03这个名字已经取代了C++98称为C++11之前的最新C++标准名称。不过由于C++03(TC1)主要是对C++98标准中的漏洞进行修复,语言的核心部分则没有改动,因此人们习惯性的把两个标准合并称为C++98/03标准。 从C++0x到C++11,C++标准10年磨一剑,第二个真正意义上的标准珊珊来迟。相比于 C++98/03,C++11则带来了数量可观的变化,其中包含了约140个新特性,以及对C++03标准中 约600个缺陷的修正,这使得C++11更像是从C++98/03中孕育出的一种新语言。相比较而言,C++11能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更 强大,而且能提升程序员的开发效率,公司实际项目开发中也用得比较多,所以我们要作为一个 重点去学习。C++11增加的语法特性非常篇幅非常多,我们这里没办法一一讲解,所以本次博客主要讲解实际中比较实用的语法。
1998年是C++标准委员会成立的第一年,本来计划以后每5年视实际需要更新一次标准,C++国际标准委员会在研究C++ 03的下一个版本的时候,一开始计划是2007年发布,所以最初这个标准叫C++07。但是到06年的时候,官方觉得2007年肯定完不成C++07,而且官方觉得2008年可能也 完不成。最后干脆叫C++0x。x的意思是不知道到底能在07还是08还是09年完成。结果2010年的 时候也没完成,最后在2011年终于完成了C++标准,所以最终定名为C++11。
2.C++11语法介绍
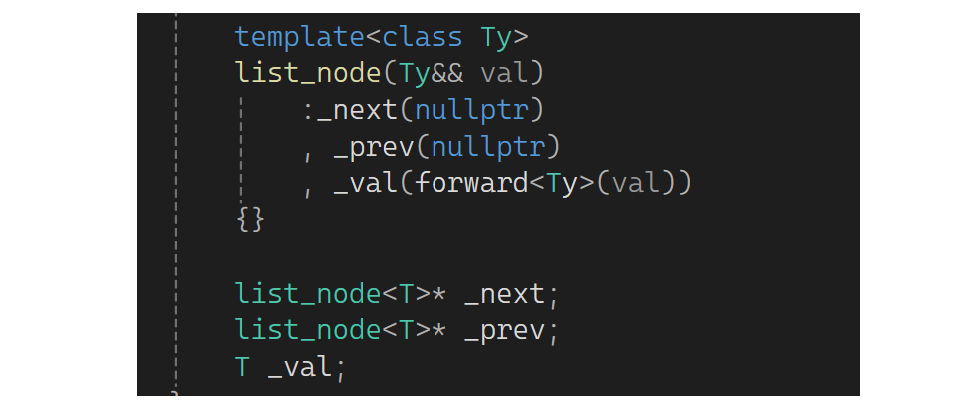
C++11中更新了一些特性是关于初始化,有些地方叫列表初始化,就是用一对花括号去进行初始化:

c语言的初始化列表支持的是数组和结构体。c++11把这个特性进行了一些扩展,首先:

以前的初始化要带等号,现在的初始化可以把等号去了,这表达的是一切皆可用花括号来初始化,可以不写等号,但是不太建议。看一下下图:
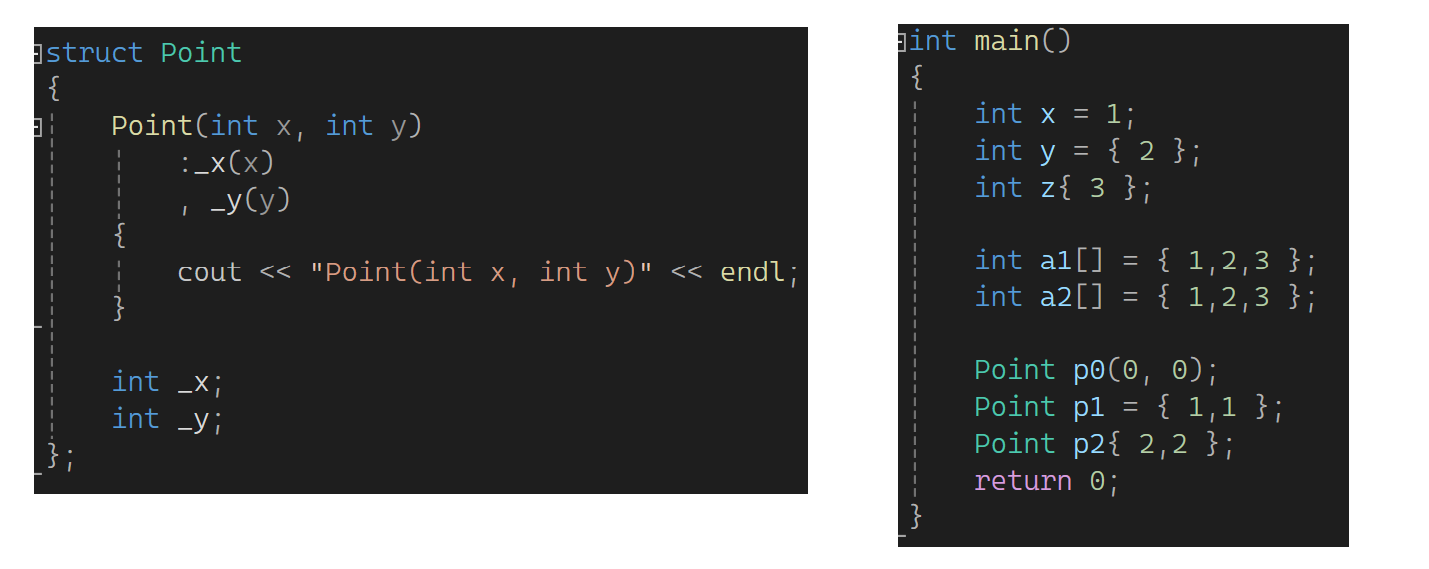
p0没有问题,猜一猜p1和p2这样写调不调用构造函数?会的,意味着编译器识别时虽然识别到是这样写的,但还是会调用构造函数,p0 p1 p2的本质是一样的。还可以支持这样:

第二个会失败,可以这样:
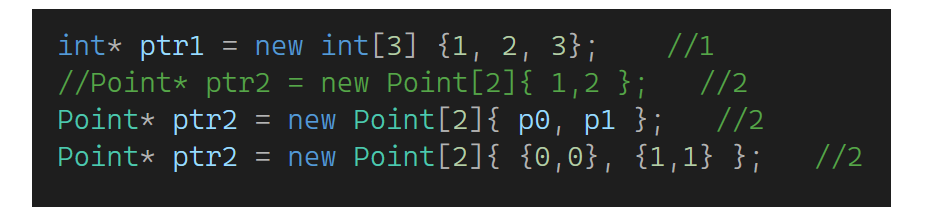
之前说过单参数构造支持隐式类型转换,有了花括号相当于多参数构造也支持隐式类型转换,如:A a = 5,如果没支持要这样写------A a = A(5)或A a(5)。B b = {3, 2,5},如果没支持这样写------B b = B(3, 2.5)或B b(3, 2.5)。同时回顾一下这里:Pointer& r = {3, 3},这样不支持,加const就支持了,因为类型转换都会产生临时对象,临时对象具有常性。再看下一部分:

第44行和45行不是同一个语法,第44行的后面还可以{1,2,3,4,3}这样加各种值;45行不可以,因为它的构造就两个参数。再看下图:
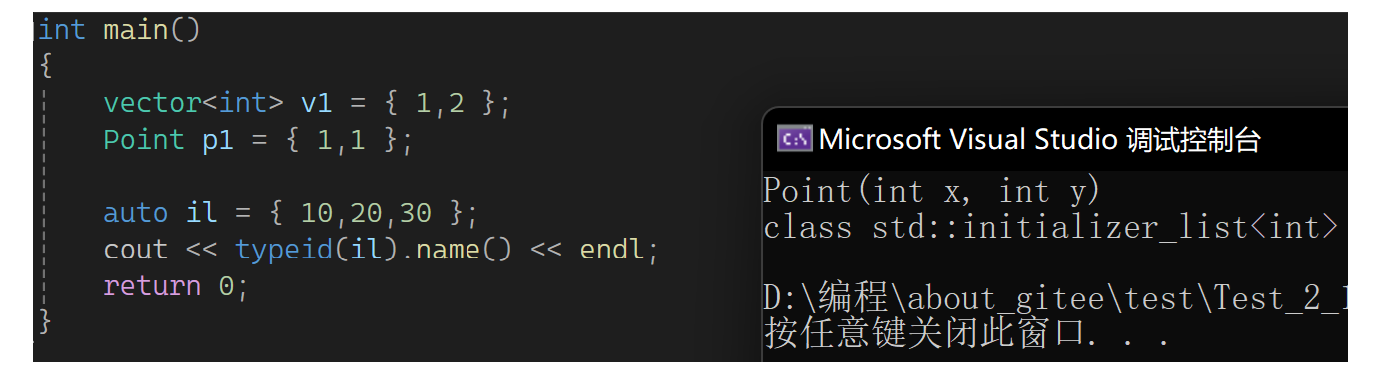
C++11把直接写的列表新增了一个类型叫initializer_list:
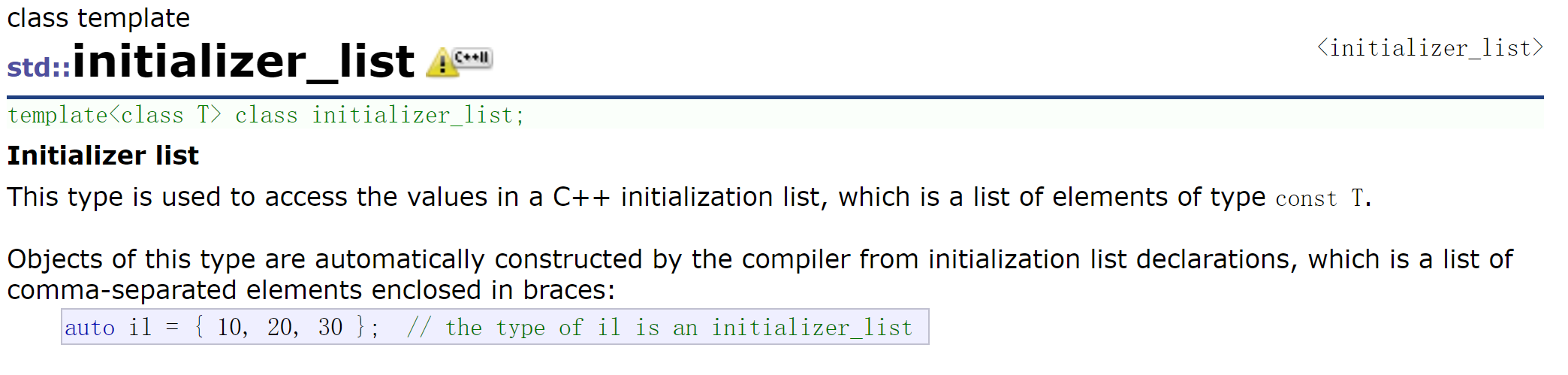
只要是花括号列表括起来的可识别是一个initializer_list:

也可认为它是一个容器。它的原理是:{10,20,30}这是个常量数组,存在常量区的。底层大概是这样:

把常量数组赋值过来,就让_start指向开始,_finish指向结束位置的下一个位置。也可以这样写:initializer_list<int> il = {10,20,30},本质还是调用initializer_list的构造函数,会想办法取到这段空间开始和结束的地址给_start和_finish。那vector<int> v1 = {1,2,3,4}这样是怎么支持的?因为vector写了这样的构造函数:
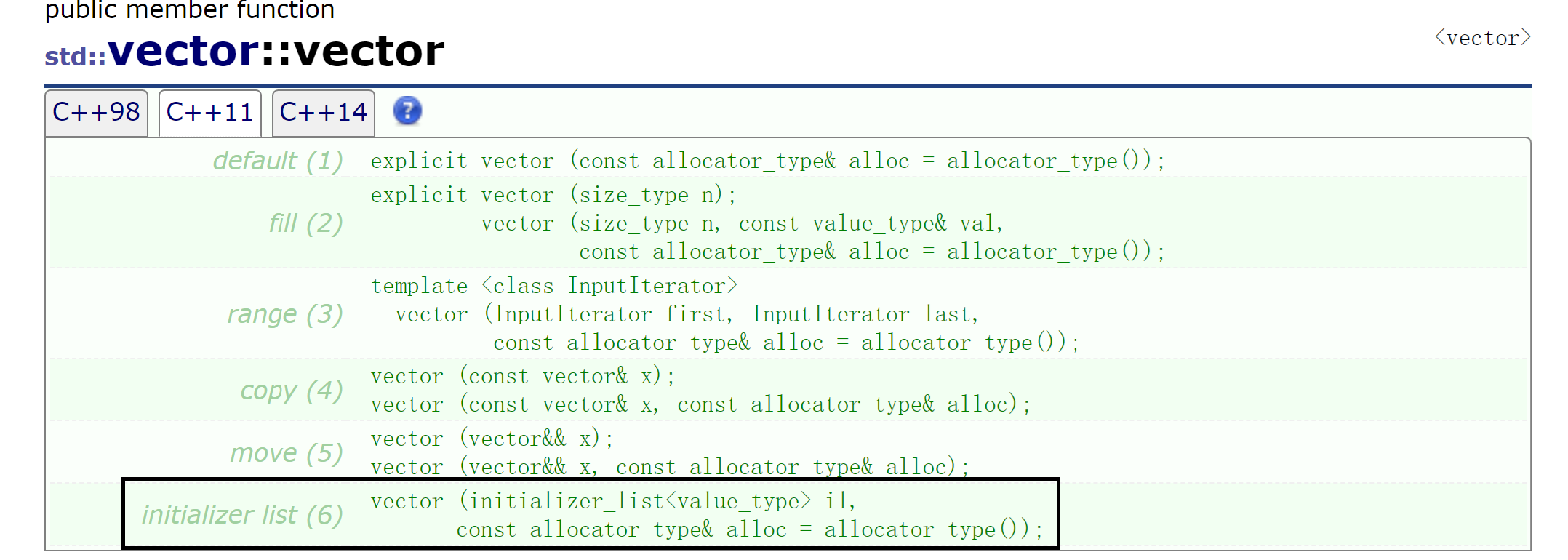
initializer_list没规定构造几个,vector里面应该要reserve(li.size()),initializer_llist支持迭代器也就支持范围for:
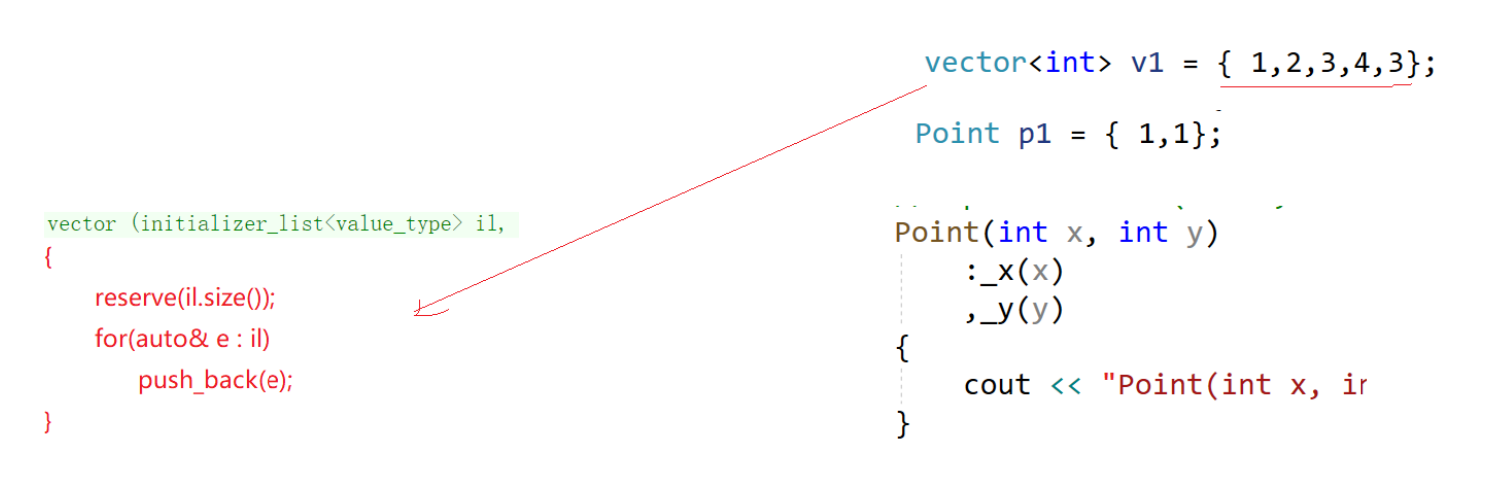
继续看,如果用我们自己写的vector:yxx::vector<int> v1 = {1,2,3,4,5},这样不支持,报错说不能支持类型转换。若想支持就要提供一个构造函数(参数是initializer_list的构造函数),这样才可以编译过:
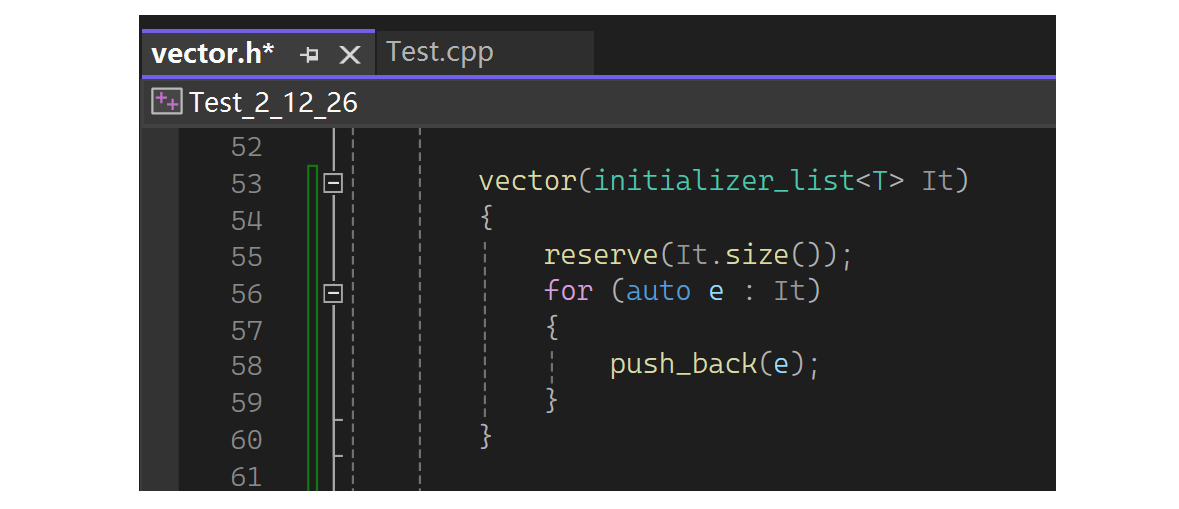
如果是map怎么初始化?直接map<string, string> dict = {"sort","排序","left","左边"}不行,map也支持了initializer_list的构造,但是map这的initializer_list的T是个pair,所以要{ {...}, {...} }这样写包含双重定义,最外的两个括号代表initializer_list,里面的两个可写成pair有名/匿名对象/花括号,若是花括号就类似于又走了一个像Point p1 = {1,13}这个样子。
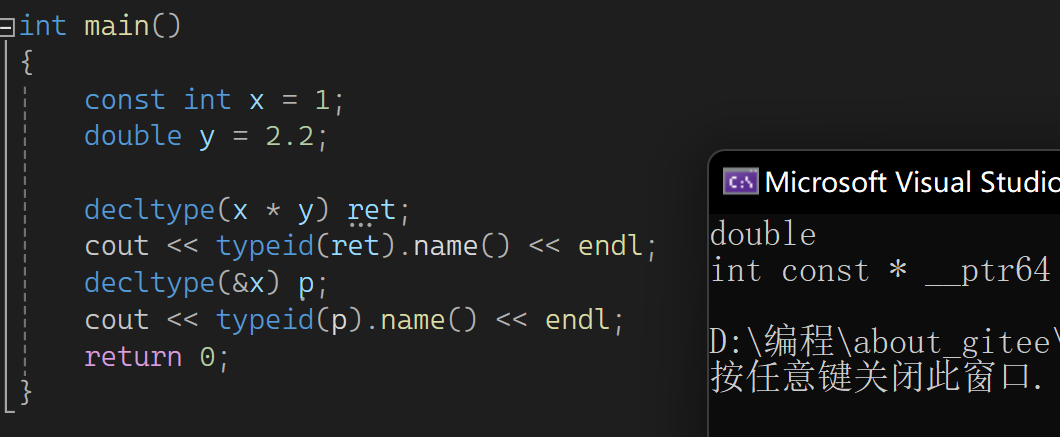
下一部分来看看关于C++11中的一些声明,首先是auto,auto已经用的很多了,可用来自动识别。auto的最多场景还是在范围for中,还有写迭代器太长,可直接用auto推导。下一个来看一个东西叫decltype,它可以用来推导类型:
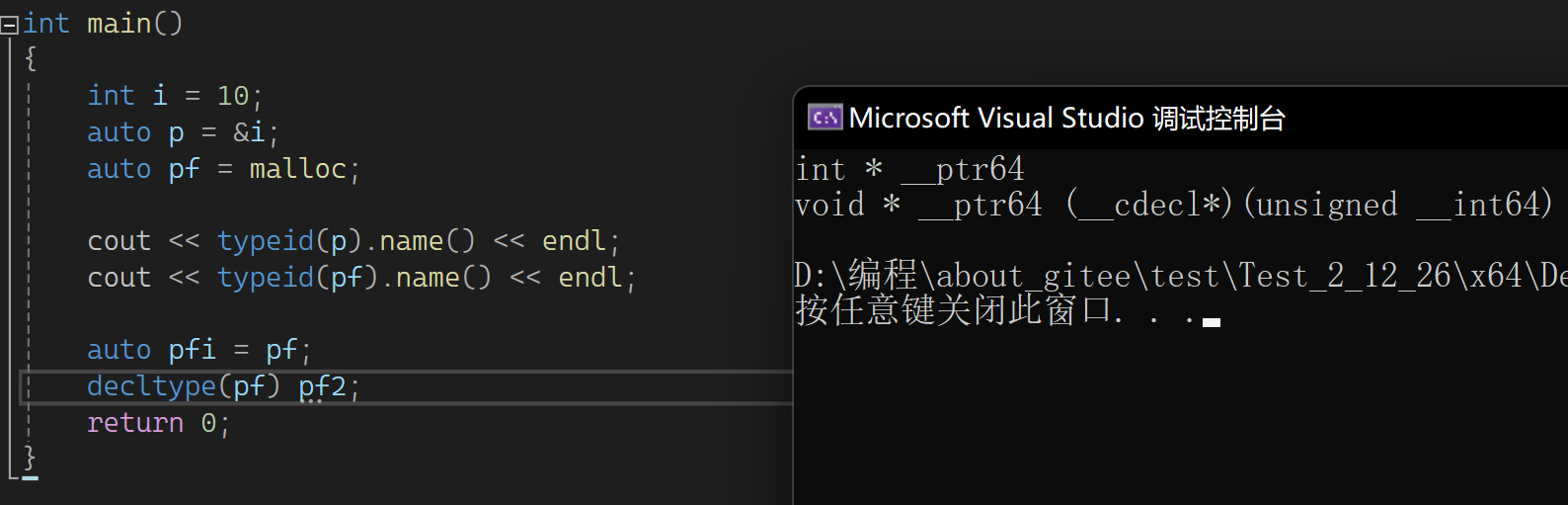
并且能用推导的类型定义一个变量,不用初始化也可以。它可以用于这样的场景:
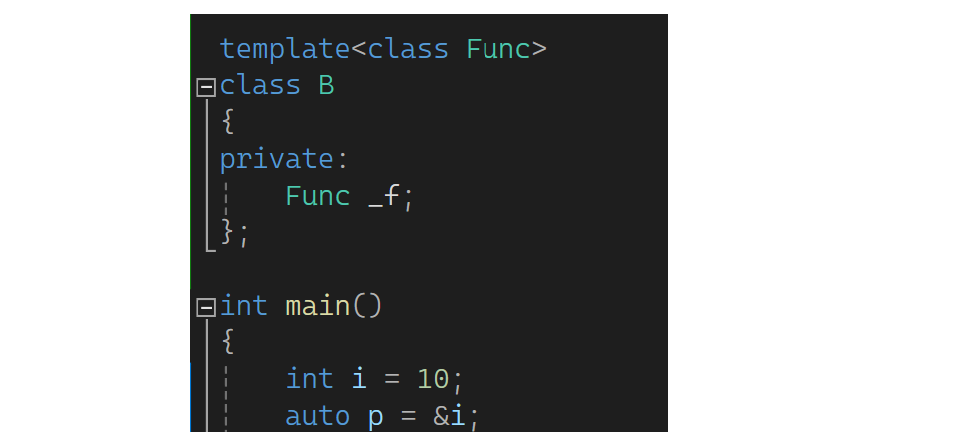
main中传一个类型要去实例化B,如B<>bb,不想写函数指针怎么办?此时可以B<decltype(pf)> bb。typeid推出的类型是一个字符串,只能看不能用;auto不能单独不能初始值定义变量;decltype推出对象的类型,可再定义变量,或者作为模板实参,还可以推一个表达式:
下面是nullptr,它补了C++库定义的一个坑(之前详细说过);范围for也详细说过了,智能指针后面详细说。 下一部分是C++11中stl的一些变化,第一部分是新容器:
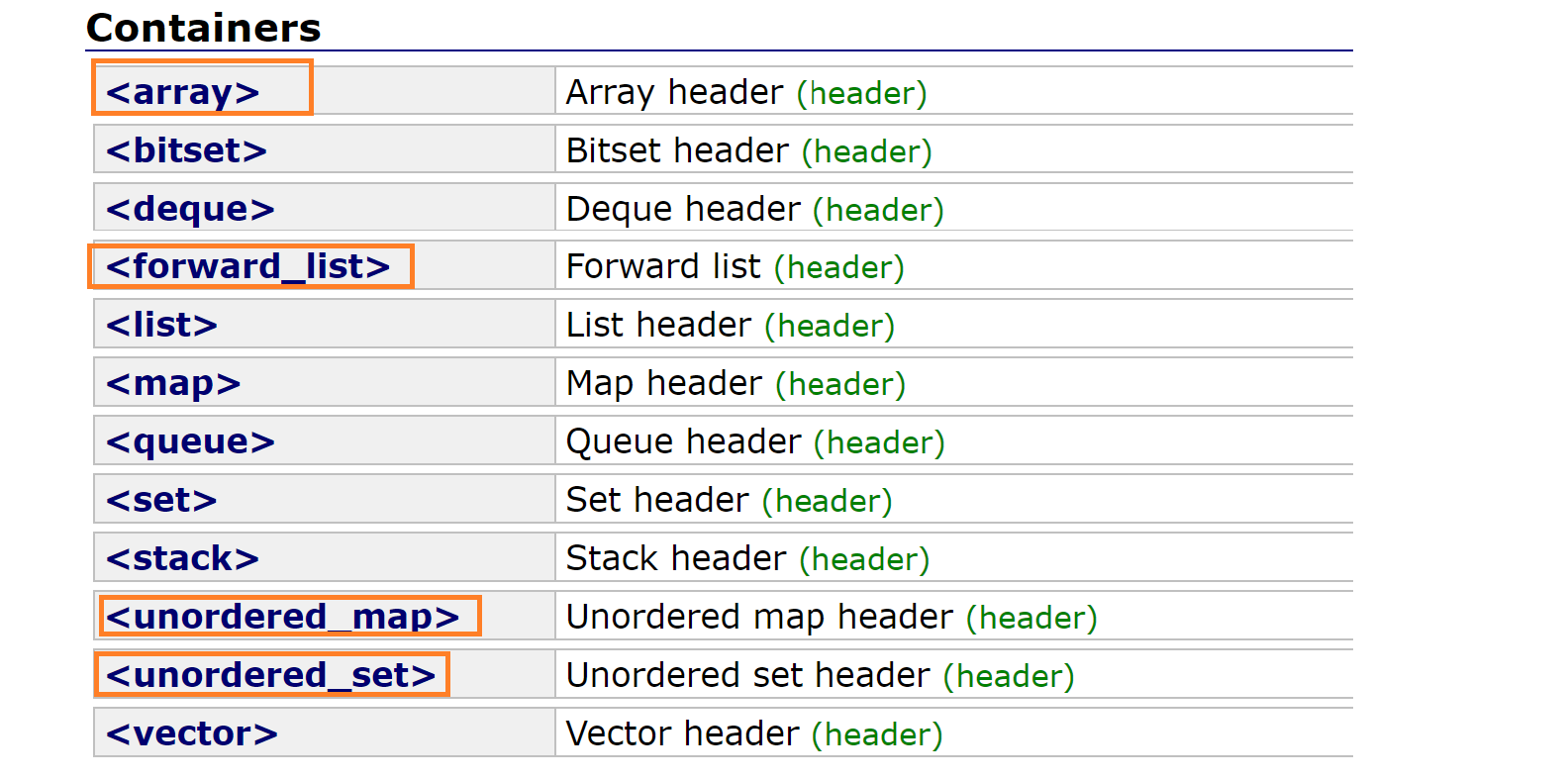
用颜色圈起来的都是C++11新增的,map和set很熟了,array是一个静态数组,用非模板参数定义数组的大小,对比静态数组而言大多没区别,唯一的好处是对越界检查严格:

forward_list是一个单链表:
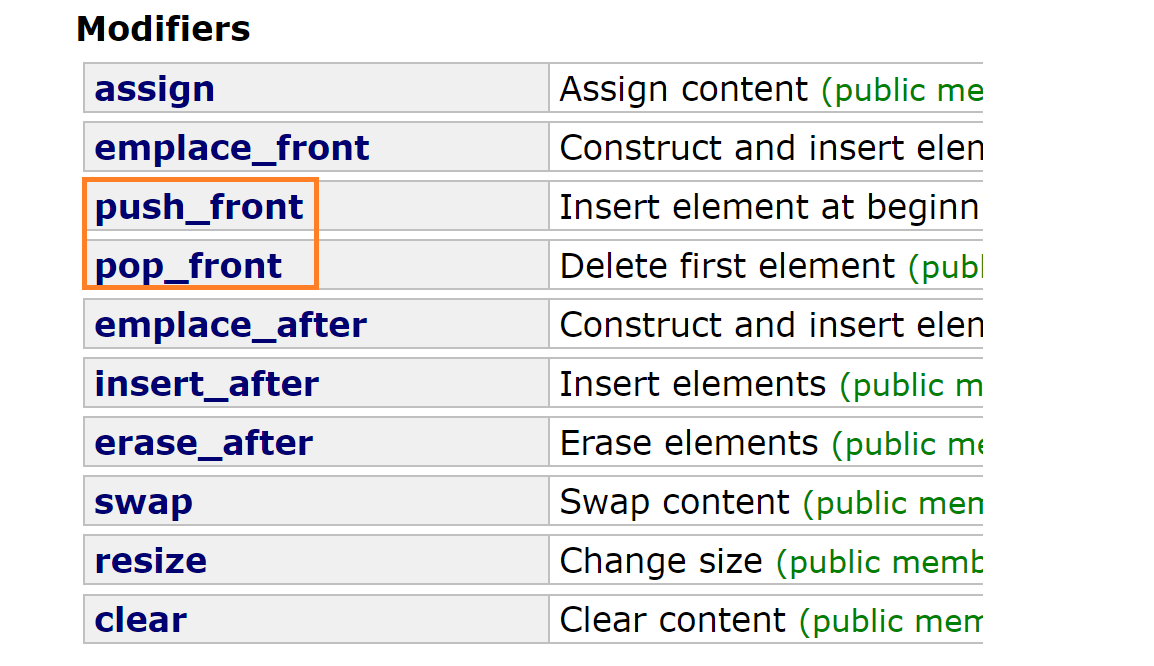
只支持了头插和头删,没有尾插和尾删,因为要找前一个。它的insert和erase也是在当前位置之后插入和删除,非说优势就是每个结点节省了一个指针,总之array和forward_list都很鸡肋。第二部分是还在容器里弄了这些新的关于迭代器的接口:
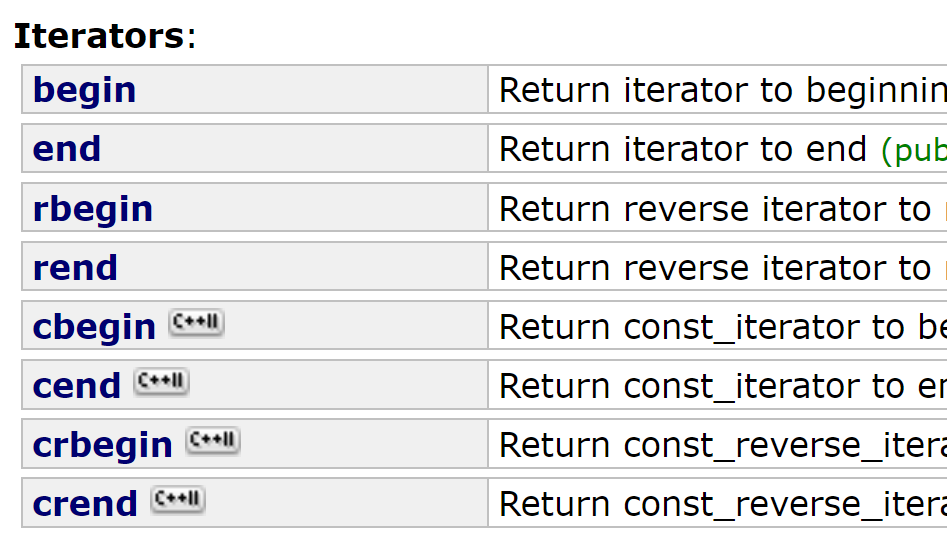
const版本的迭代器弄了个cbegin等,可能是怕区分不清楚,但还是很鸡肋。第三部分说些有用的,所有的容器均支持了用花括号初始化的构造函数。再看下图:

所有容器针对插入的都提供了一个emplace系列的接口,这里涉及了右值引用和模板的可变参数(后面说)。第四部分是还在容器新增了移动构造和移动赋值。
3.右值引用和移动语义
下一部分来看右值引用和移动语义,首先要区分右值引用,我们要对左值和右值有一定的概念。很多人最初认为在赋值符号的左边是左值,右边是右值,这样说对吗?

a是左值10是右值没有问题;下面b是左值a是什么还不一定。那什么是左值呢?

也就是可以取地址,左值可以出现在赋值符号的左边和右边,但右值不能出现在左边。如const int a = 0,a是左值,虽然不能赋值但是可以取地址。比如常见的左值:

那什么是右值呢?

右值的特点是不能取地址,一般在右边,不能出现在右边。比如对应的右值的场景:

了解上述后看个东西,觉得"xxxx"常量字符串是左值还是右值?返回的是首元素的地址,是左值。
下一部分来看看左值引用和右值引用:引用是取别名,左值引用就是给左值取别名,右值引用就是给右值取别名。一个&是左值引用,两个&是右值引用。比如:

那左值引用能否给右值取别名?比如int& r2 = 10,这样不可以,除非const int& r2 = 10可以,const左值引用可以引用右值。那右值引用能否引用左值?

直接给不可以,除非int&& r7 = move(a),右值引用可以引用move以后的左值。左值引用的使用场景有:1.做参数。2.做返回值(价值是可以减少拷贝)。但是局部对象返回不能用左值引用解决,所以只能传值返回。下面继续,写个func函数,里面有左值引用;再写个func函数,里面有右值引用:
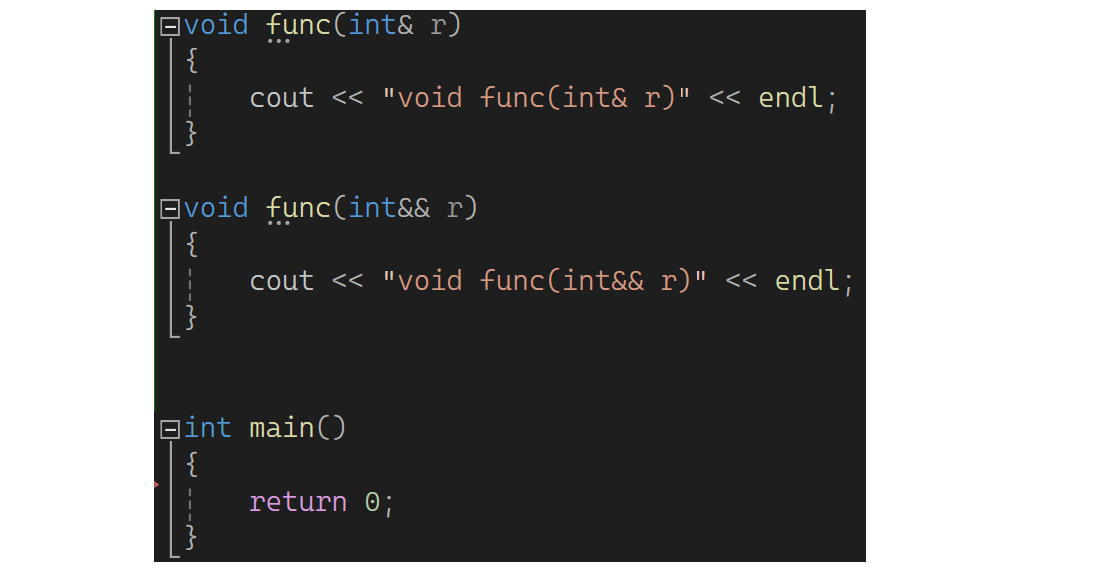
它们是否构成函数重载呢?是的,一个接收左值,一个接收右值。那下图呢?
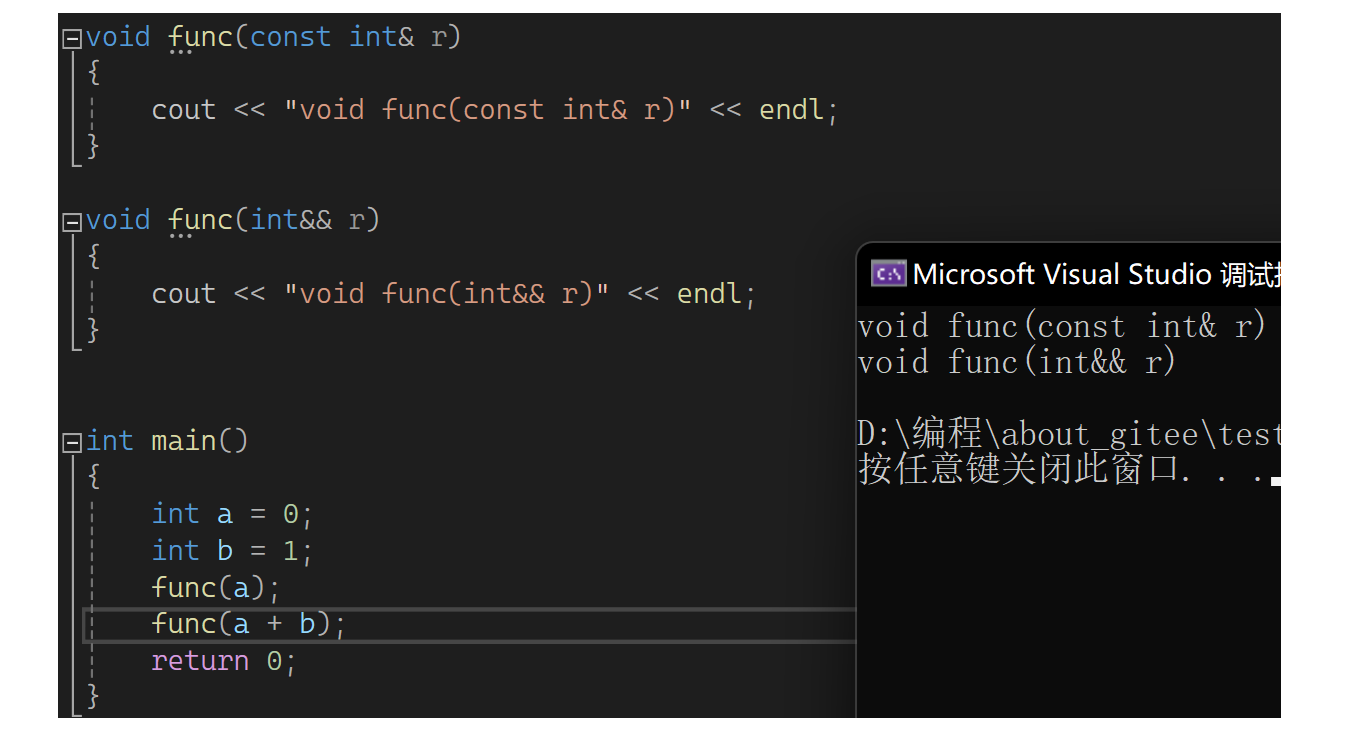
也是构成重载的,没有出现调用歧义,走的是匹配的。继续回到上面:
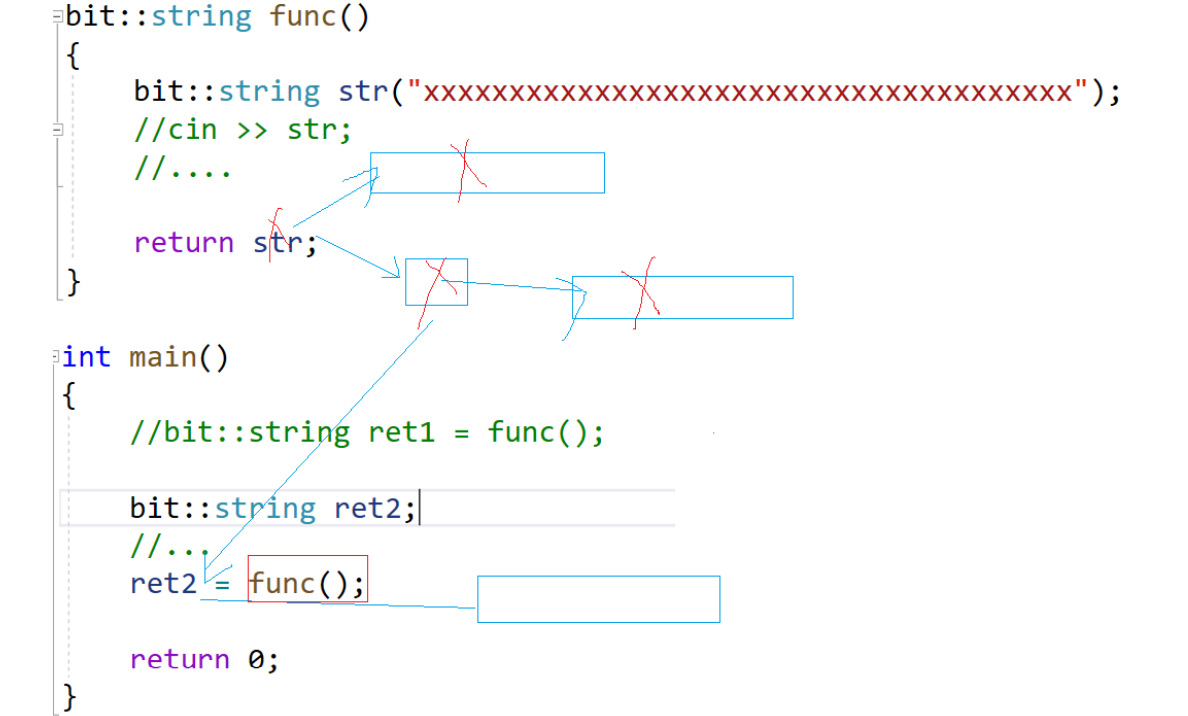
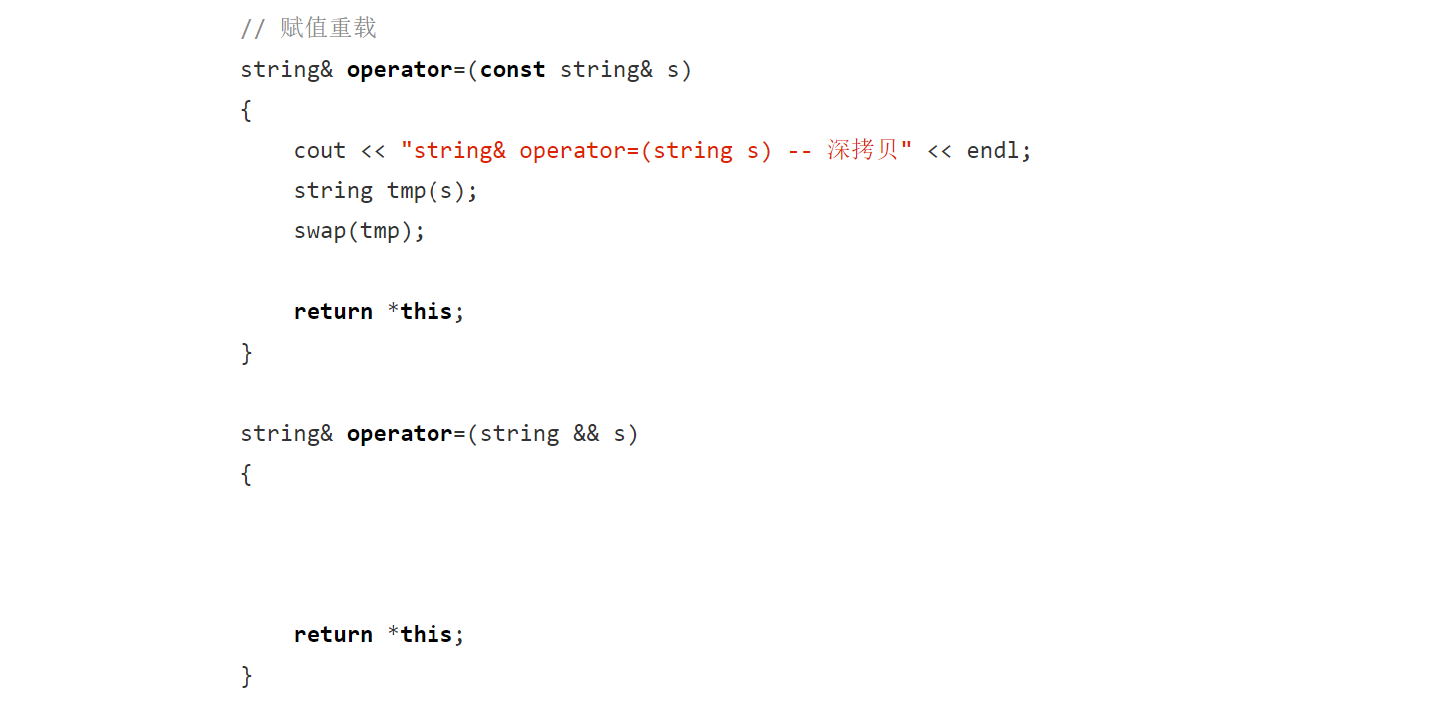
传值返回的代价非常大,要先拷贝构造一个对象,再赋值给ret2,并且中间深拷贝付出了代价最后反而又销毁了。此时可以这样,写一个赋值,与原来赋值构成重载:
如果是左值走上面,是右值走下面(自定义类型右值可能有哪些?可能有函数传值反回)。很多地方为了区分把内置类型右值叫纯右值,自定义类型的右值叫将亡值。比如自定义类型右值存在的地方:表达式s1+s2本质是运算符重载,to_string是函数调用,返回的是临时对象:
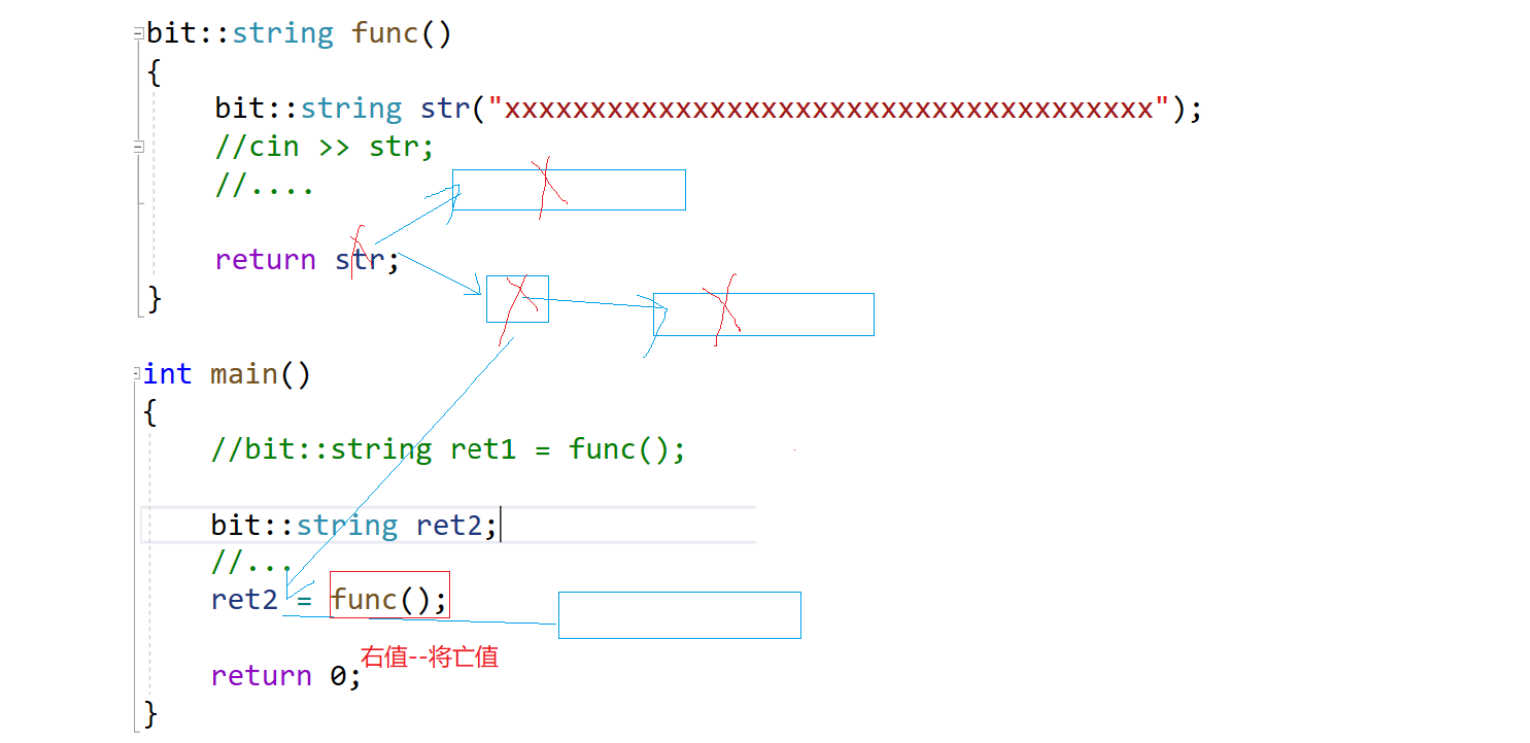
func函数返回的是右值中的将亡值,因为它的生命周期只在ret2 = func()这一行,再往下走就析构了。此时看,ret2 = func()这是个赋值,比如:

是左值只能老实的深拷贝,若是右值将亡值,可用移动拷贝,它可以把资源拷过来。下面看,是右值将亡值可做深拷贝,但还可以做移动拷贝(一交换帮忙带走):
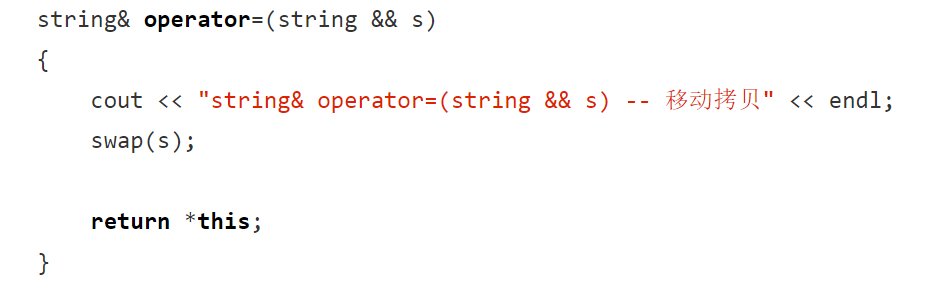
这样代价低了很多,因为它是转移资源。再看下图:

如果传值返回,中间会生成一个临时对象,临时对象是个将亡值,可用移动构造降低拷贝的代价。再看一个场景:
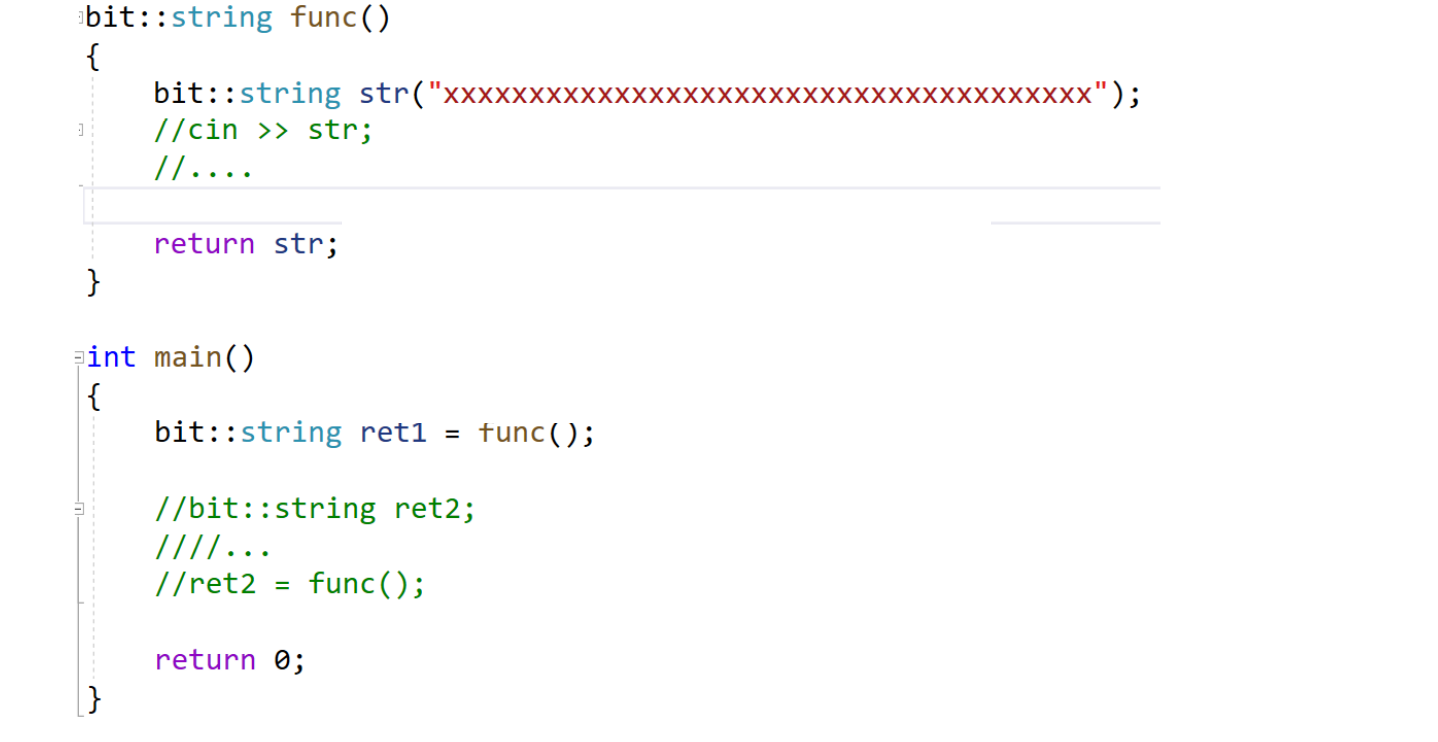
这如果不优化是拷贝生成一个临时对象,临时对象再拷贝给ret1,所以可实现一个移动拷贝:

实现后可以对比一下,如果编译器完全不优化和编译器优化的样子:
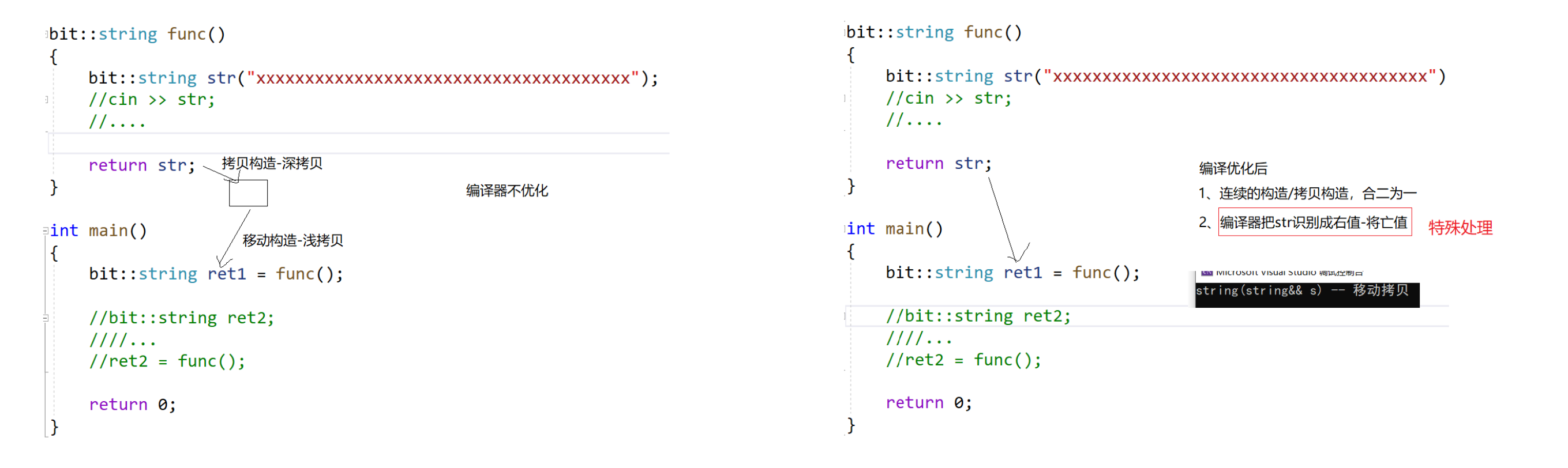
这些调用移动拷贝的效率大大提升比起拷贝构造。此时有人会问编译器不是把返回那里识别为右值了,为啥不能这样:
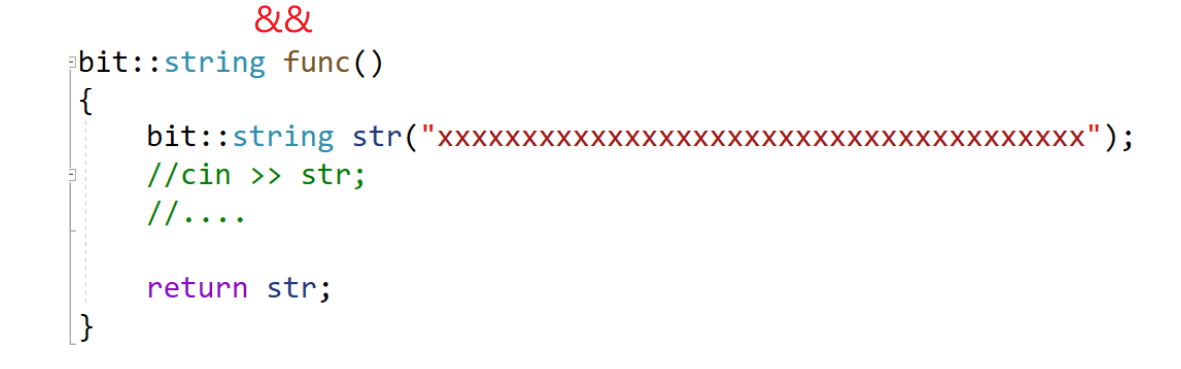
这样返回的是str的别名,它会正常销毁,拿到的是野指针。只有传值返回+优化编译器才能把它强行识别为右值。再看这样的场景:
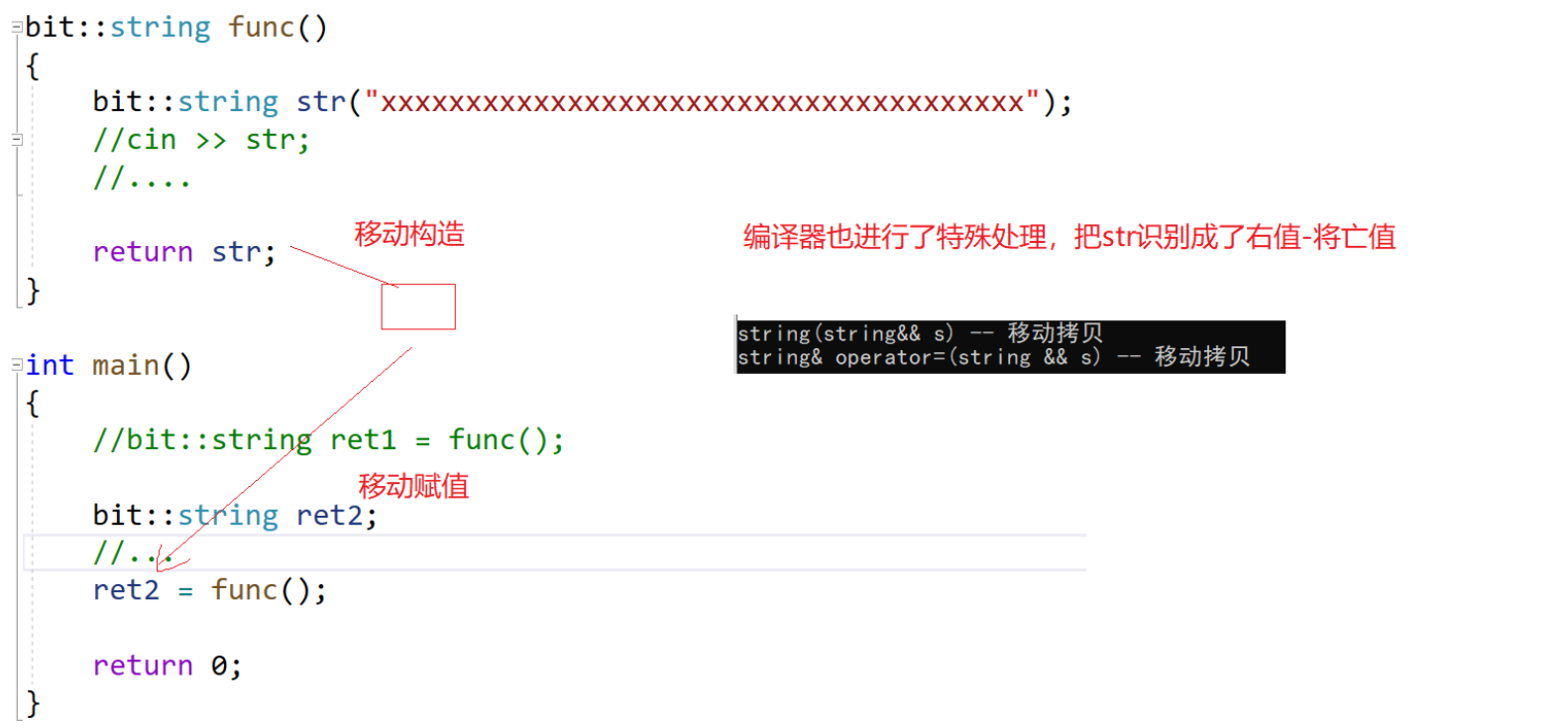
之前两次深拷贝,现在变成了直接转移资源。可以结合以前的杨辉三角例子看看优化:

所以stl的重大变化是给所有容器增加移动构造和移动赋值,这是个大福利,可以提高效率。
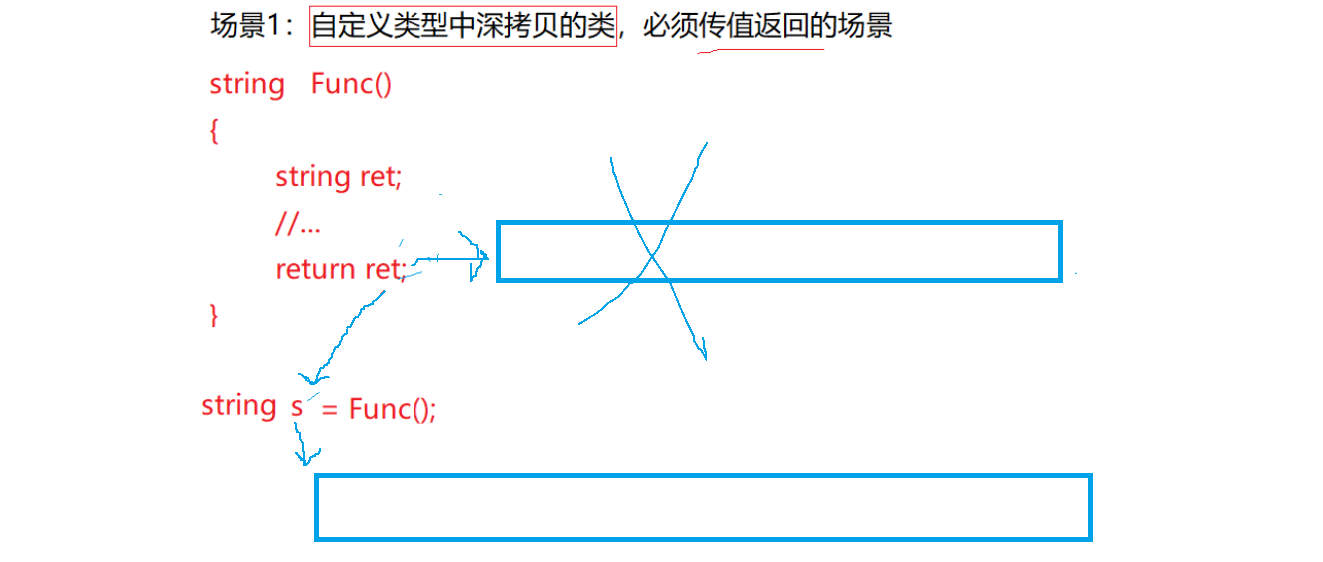
右值引用的核心价值是进一步减少拷贝,弥补左值引用没有解决的场景,比如传值返回。下面看场景1:自定义类型中深拷贝的类必须是传值返回的场景,不是深拷贝的价值不大:

再回顾一下右值引用对场景1的好处:

如果没有移动构造,就算编译器优化都开,也要开一段和ret一样大的空间,把数据拷过来,出作用域后ret那段又销毁了:
这样非常的浪费,现在有了右值引用,它可以很好的和左值引用进行区分。但也不是所有的拷贝都是转移资源,比如:

这不是将亡值,左值就老实拷贝。区分出左值和右值的核心区别到底是什么?对编译器而言是赋予了一个权限,返回一个将亡值意味着你马上就要走了,所以就直接把资源转过来,否则析构时把资源带走了,这里ret就指向空:
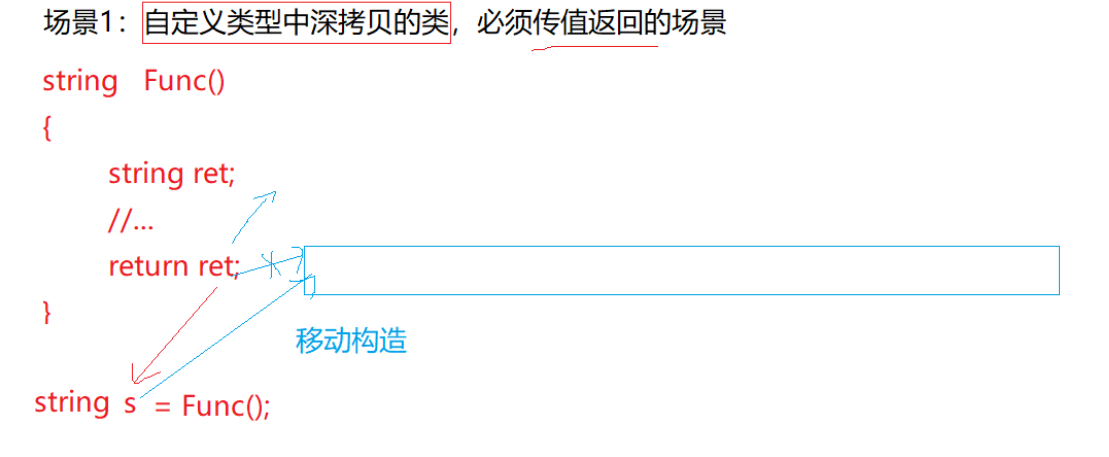
再看下图:

把ret3 move一下会发生什么吗?不会,也就是move一下不会改变ret3的属性。要改变ret3本身的属性需要这样写:
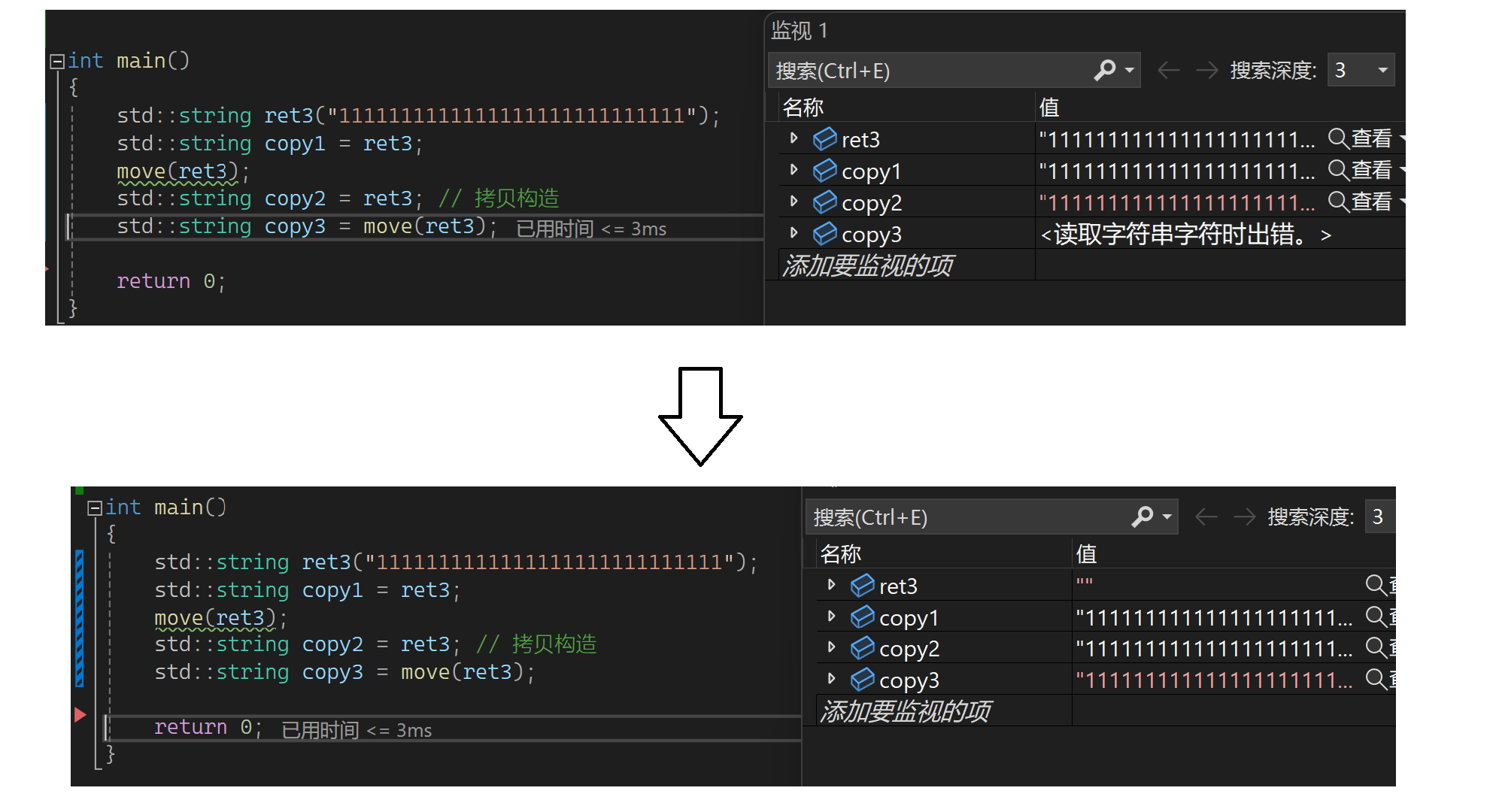
通过这里可猜测一下move(ret3)这里是个函数调用,会返回右值且右值和ret3中的资源是一样的。也可以这样理解,返回的是ret3的引用,但这个值会变为右值,ret3本身没有变右值,返回的是ret3的右值。所以把一个值move以后再去拷贝构造要小心一些,相当于赋予了别人一个权力,可把你的资源给抢走。move的意义就是我想让一个对象资源被别人抢走,就move一下再交给别人,不想就别去动。下面看看场景2(用自己写的,这样方便看拷贝或移动构造),先看结果:
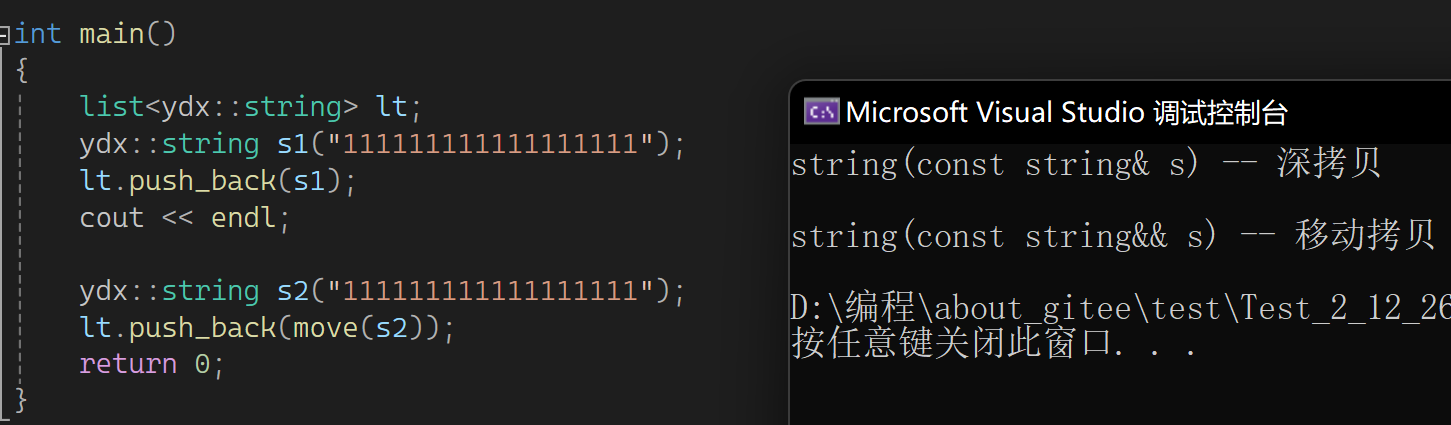
push_back尾插了一个结点,结点里面有一个string,以前是这样的过程:

Node里发生拷贝构造,跟s开一样大的空间。现在push_back一个右值,右值引入一个函数:
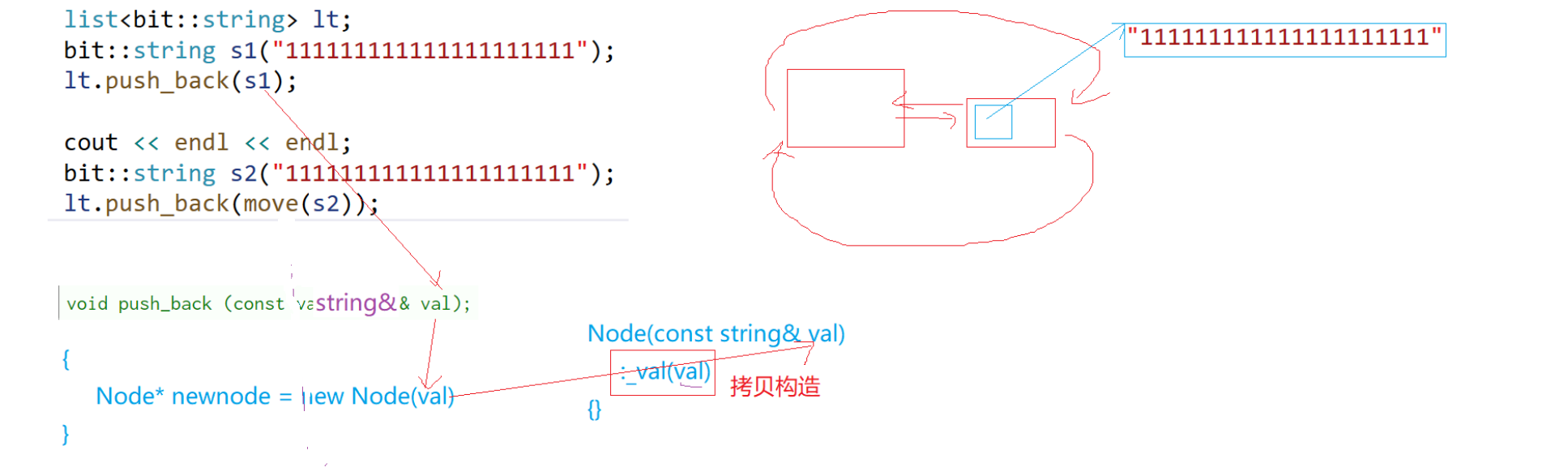
push_back一个右值会调用右值的函数,再走到Node处是右值引用,调移动构造把资源都移过来。日常中会这样写:
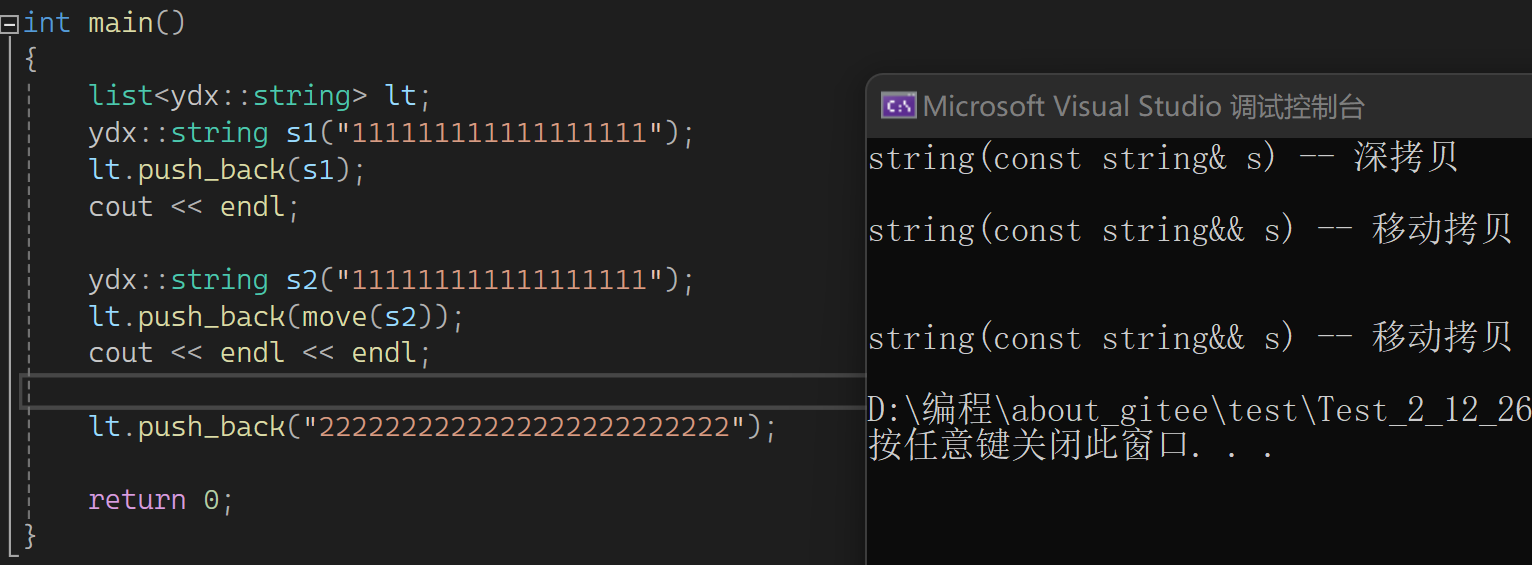
这样写也是一个移动构造,因为不能直接传值给string。先是构造临时或匿名对象,然后传左值过去资源转移。意味着这里比以前方式少拷贝一次,以前是构造+拷贝构造,现在是构造+移动构造。连续拷贝优化在同一行同一步骤,假如屏蔽移动构造,就都是构造+拷贝构造。那屏蔽后威慑右值也是深拷贝?

因为有const的左值引用,可以接收左值和右值。这也体现出右值引用出现的意义是能区分左值和右值。可以再看看没有移动构造和有移动构造的区别:
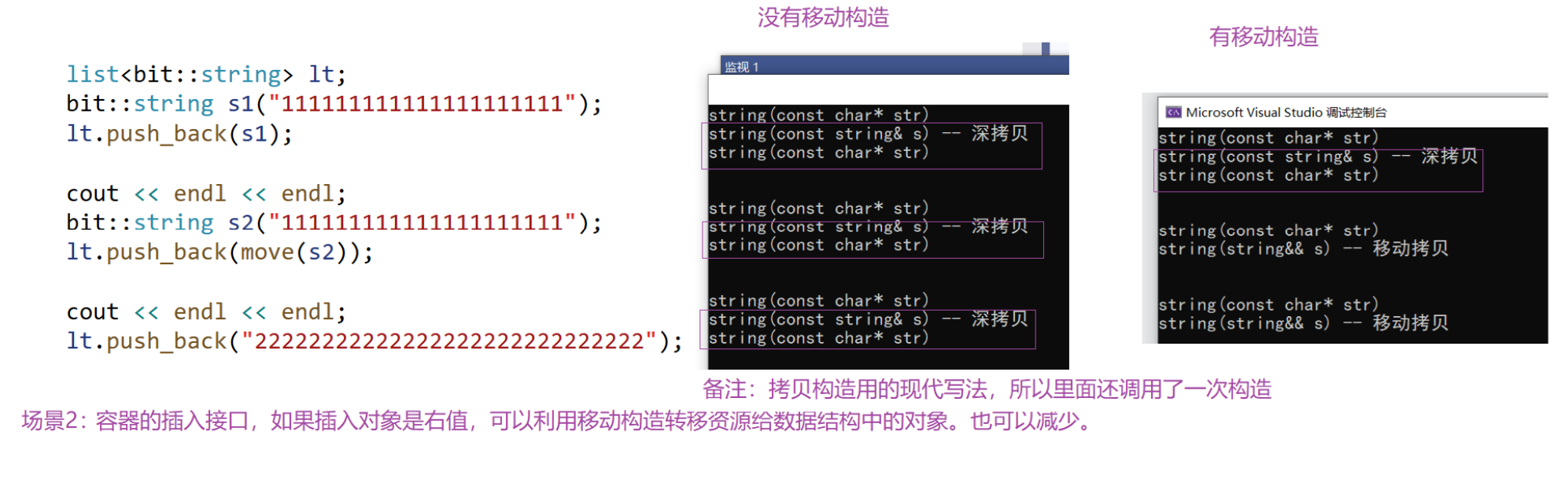
右值引用的1移动语义值的就是,利用右值引用实现移动构造和移动赋值。总结一下场景2:容器的插入接口,如果插入对象是右值,可以利用移动构造转移资源给数据结构中的对象,也可以减少拷贝,所以很多容器的插入实现了右值引用的版本。
下一部分来看看完美转发:
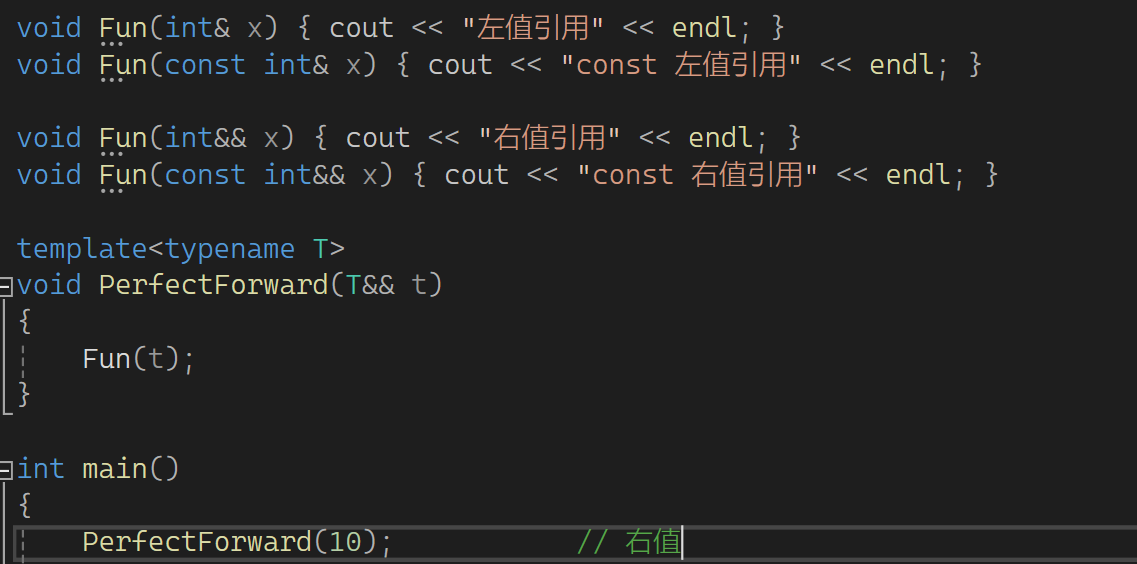
这有左值引用,const左值引用,右值引用,const右值引用。再看下图:
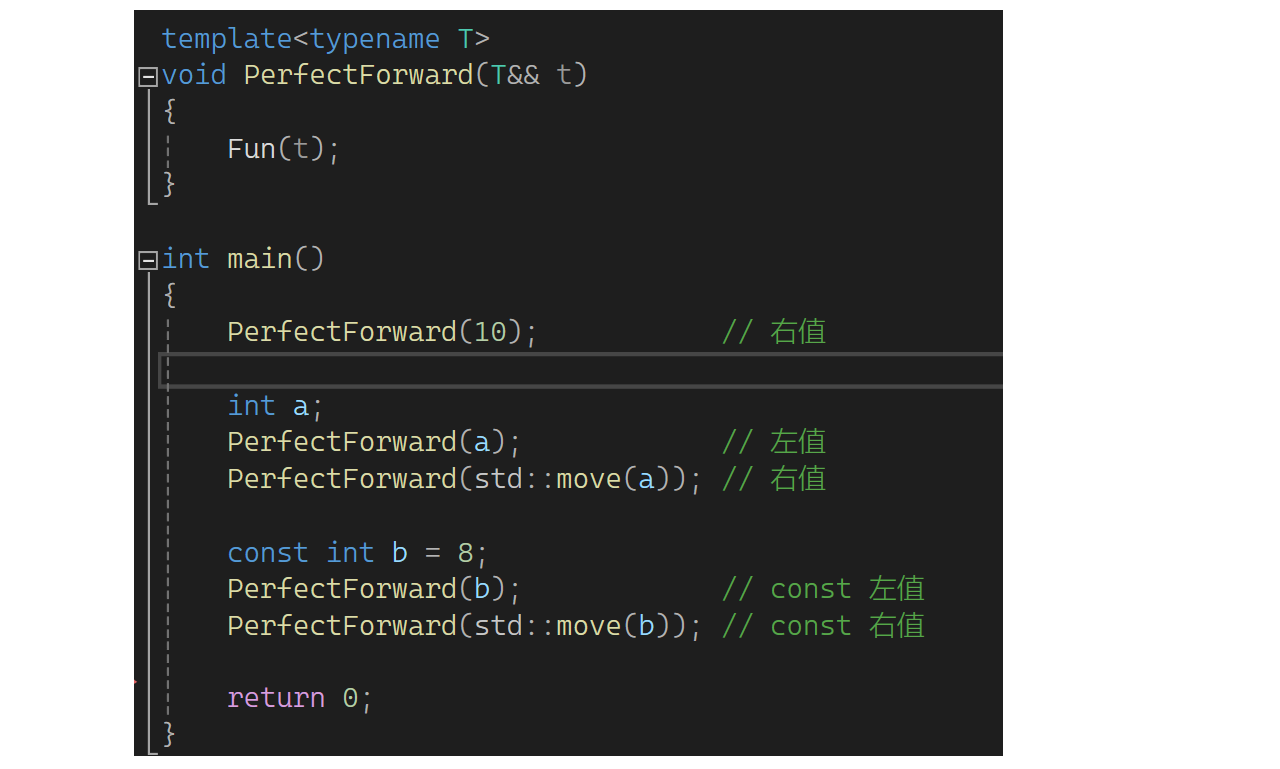
有个函数,函数的参数是右值引用,可以接收右值,那它能接收左值吗?按之前的说法不可以,但是现在可以。模板中T&&不是右值引用,它可以认为是万能引用,意思是既可以接收左值,也可以接收右值。实参是左值,它就是左值引用;实参是右值,它就是右值引用。引用折叠就是比如传左值推出来是int& t这样,两个符号折叠了一下,所以称为引用折叠。下面来看一个问题,Func(t)能否调用上面对应的函数?可以的:
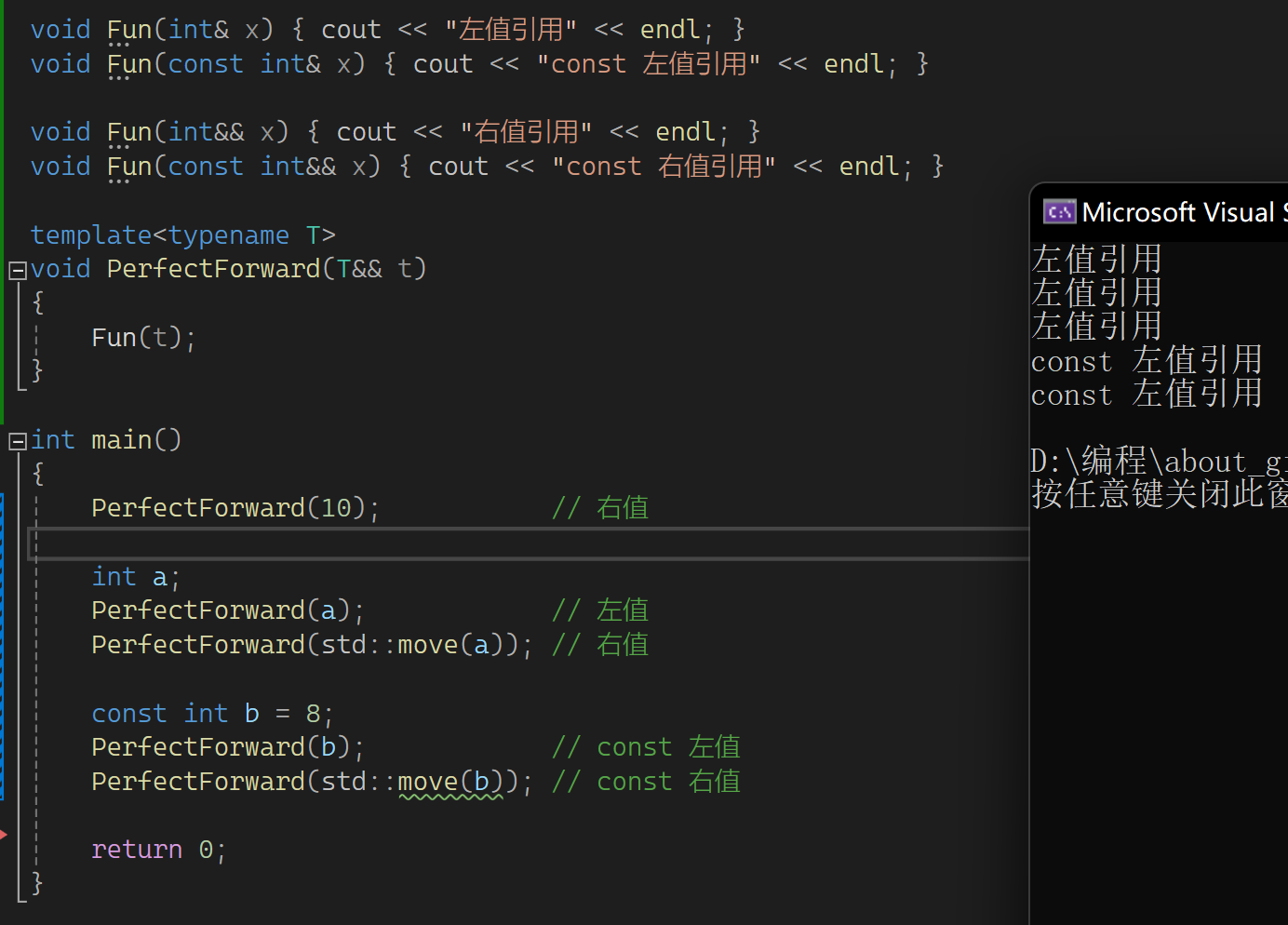
但是结果中调的都是左值引用,难道都折叠了?而且有些地方传的是右值,调用的还是左值引用。再来看下面:

r和rr分别是左值还是右值呢:
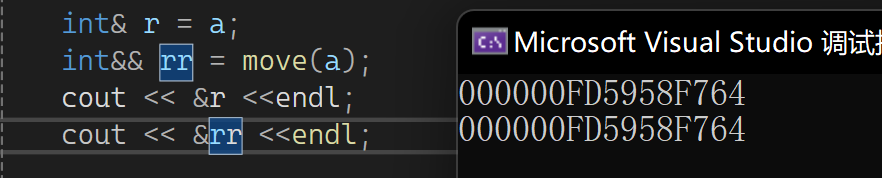
从属性上来说它们都是左值,从地址上来说它们地址一样。可以这样理解:我是右值,我不能修改,你是我的引用,可认为你开了一块空间,把我的值给存起来了,比如:
 现在回头来看:
现在回头来看:
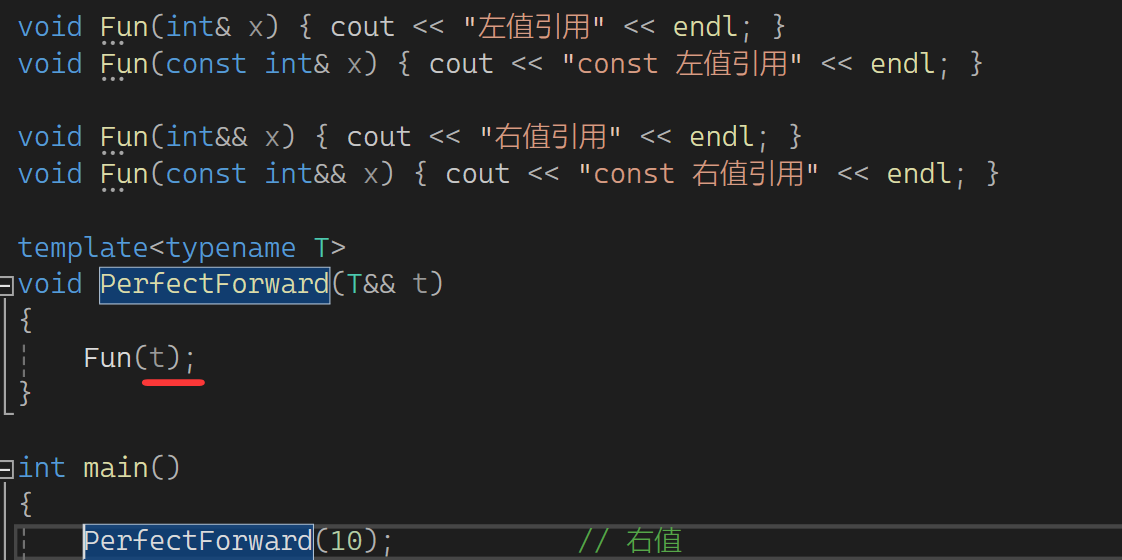
t的属性是左值,因此匹配的是左值引用,这就是为什么匹配的都是左值引用。那如果就想让t保持它原有的属性呢?c++给了我们一个东西可保持它的属性,这个东西叫完美转发,它是库里的一个函数,这样用:
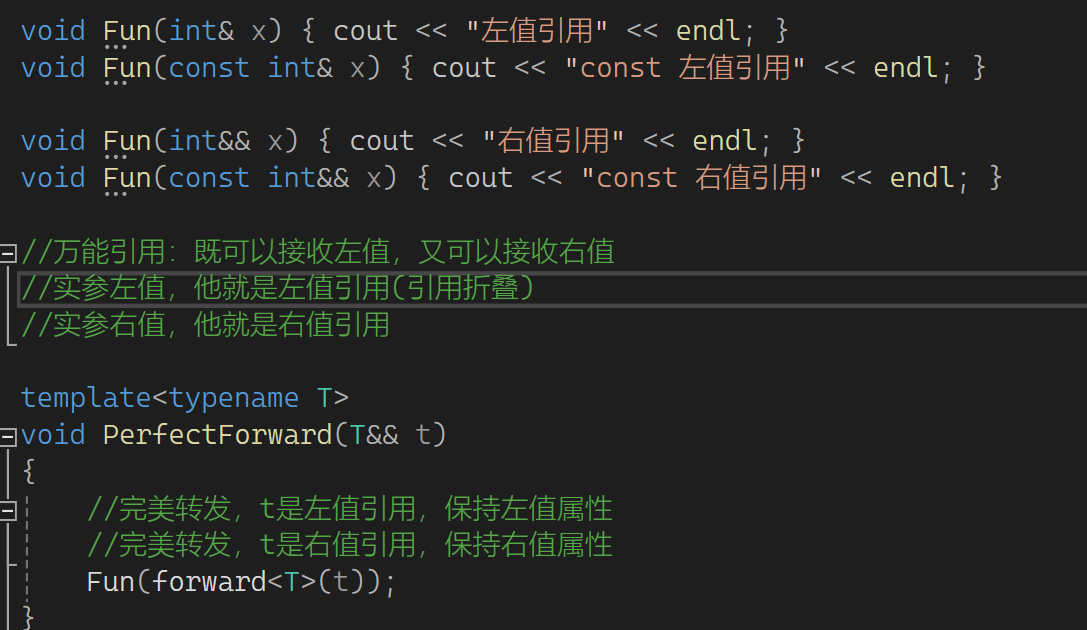
有了这个就非常灵活:

左边这样的情况属性被识别为左值,这样才能完成资源转移;右边这样的情况val被识别为左值,这样会匹配const string& val,但需要它保持右值属性,这里可以利用完美转发,让它匹配到右值调那一个(也就是最开始匹配了左值和右值的,第二次的时候右值变量有了左值的属性)。下面把完美转发利用到链表中感受一下,为了方便测试屏蔽一下,顺便string的拷贝用正常的方式:
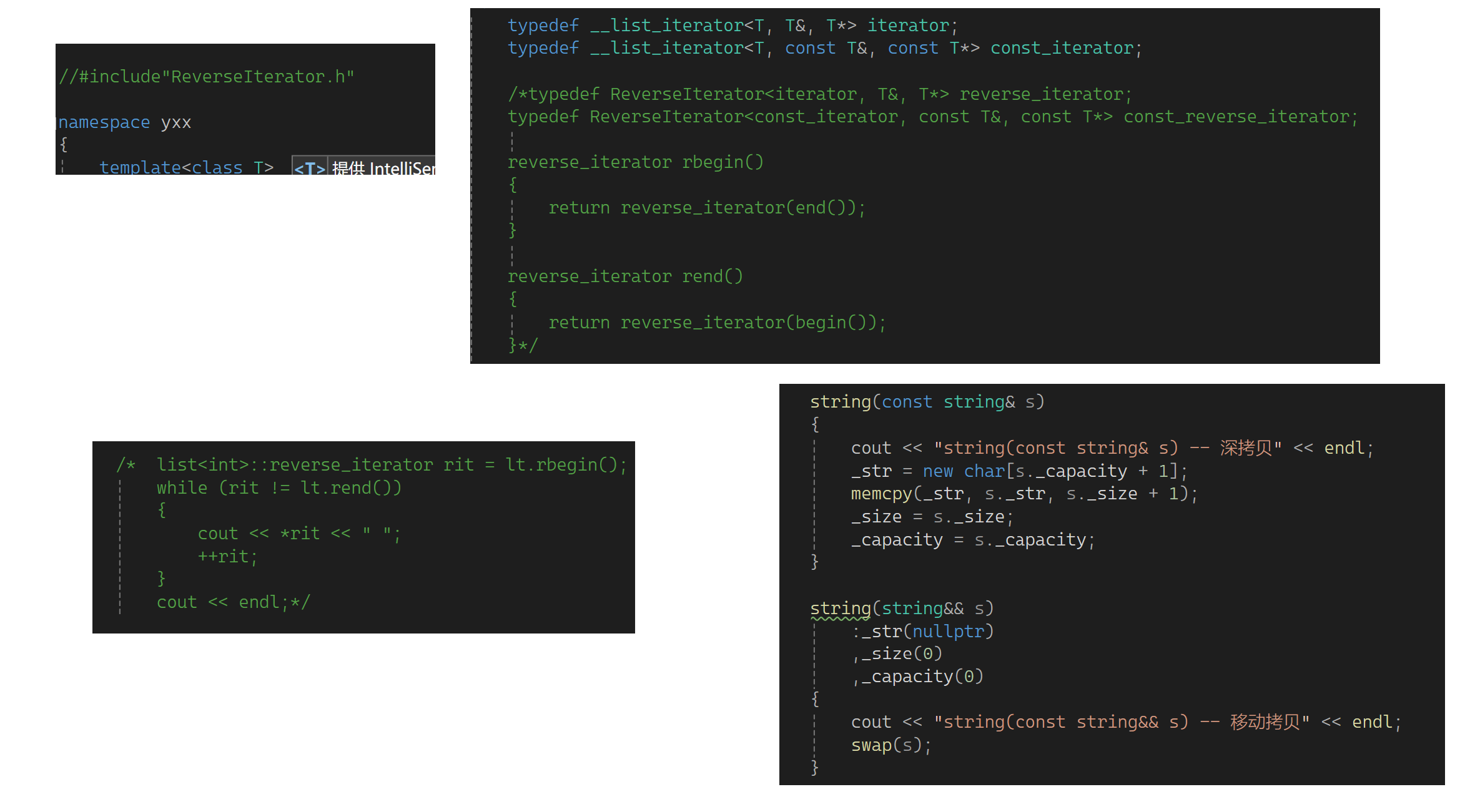
下面开始测试:
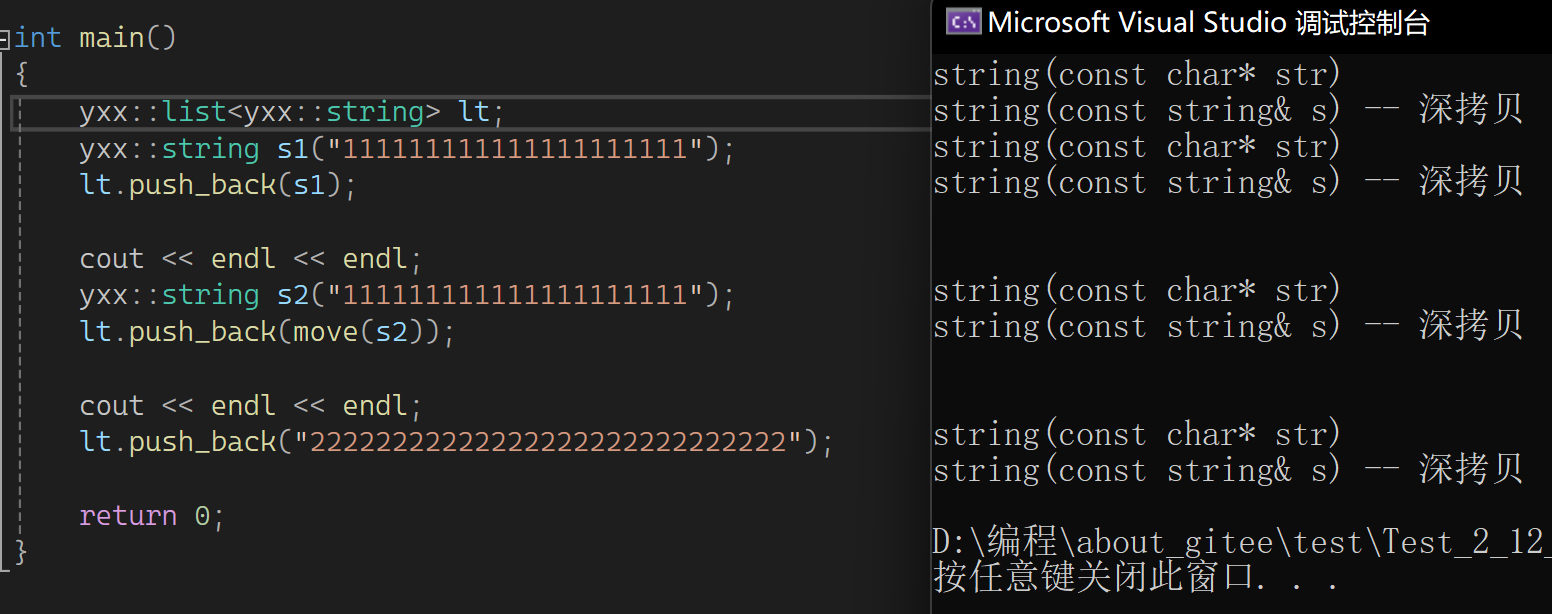
看到都是深拷贝,改一下又变了:
创建lt调用两次和我们的实现有关,这是初始化哨兵位头结点弄的,因为有个T(),先调用了构造,又调用了拷贝构造。继续看上图,第一个左值就不说了,直接看右值的:
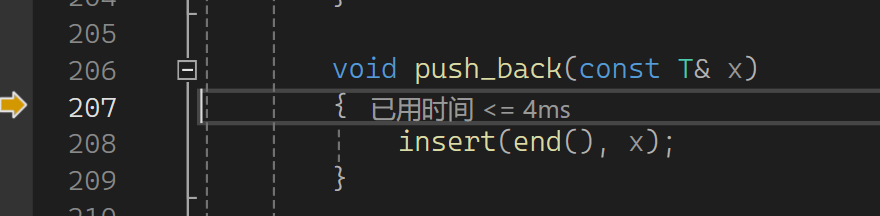
按照以前的版本插入时左值和右值都匹配到左值引用上了,这样就不存在说后面转移资源的概念了,所以在之前的基础上加一个函数来区分左右:

它下一层又调用insert,给insert也加一个:
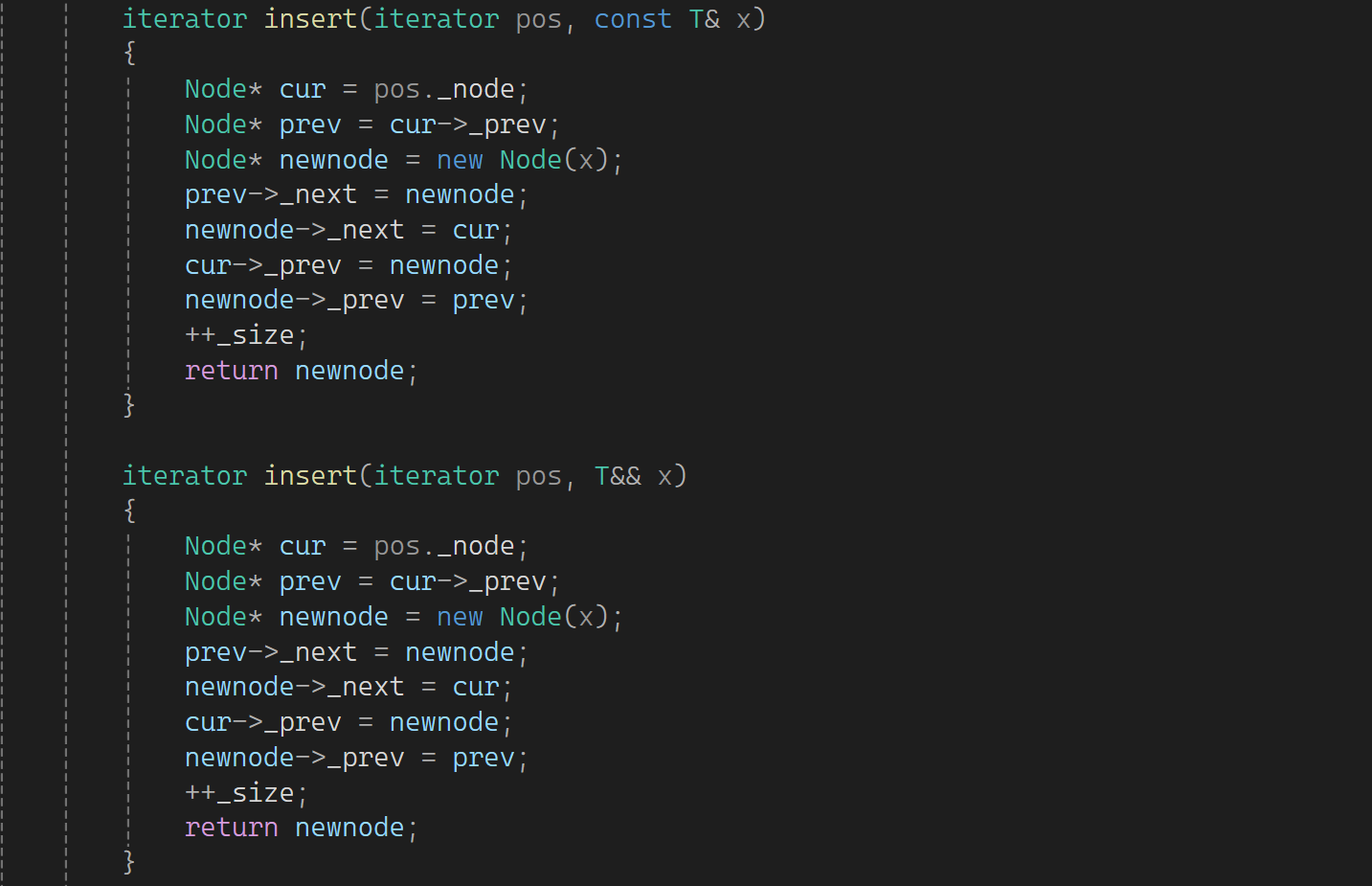
再往下走到Node的构造了,也加一个:
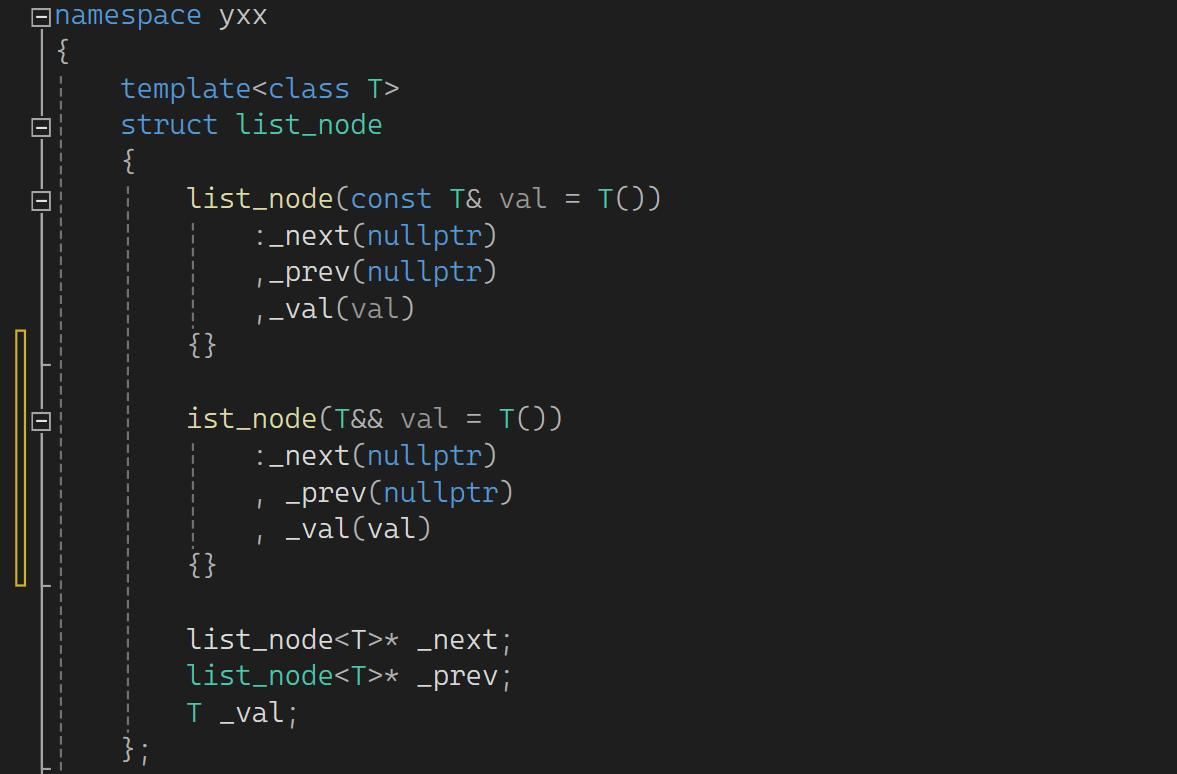
改一下,要不然传参时不知道调哪一个:
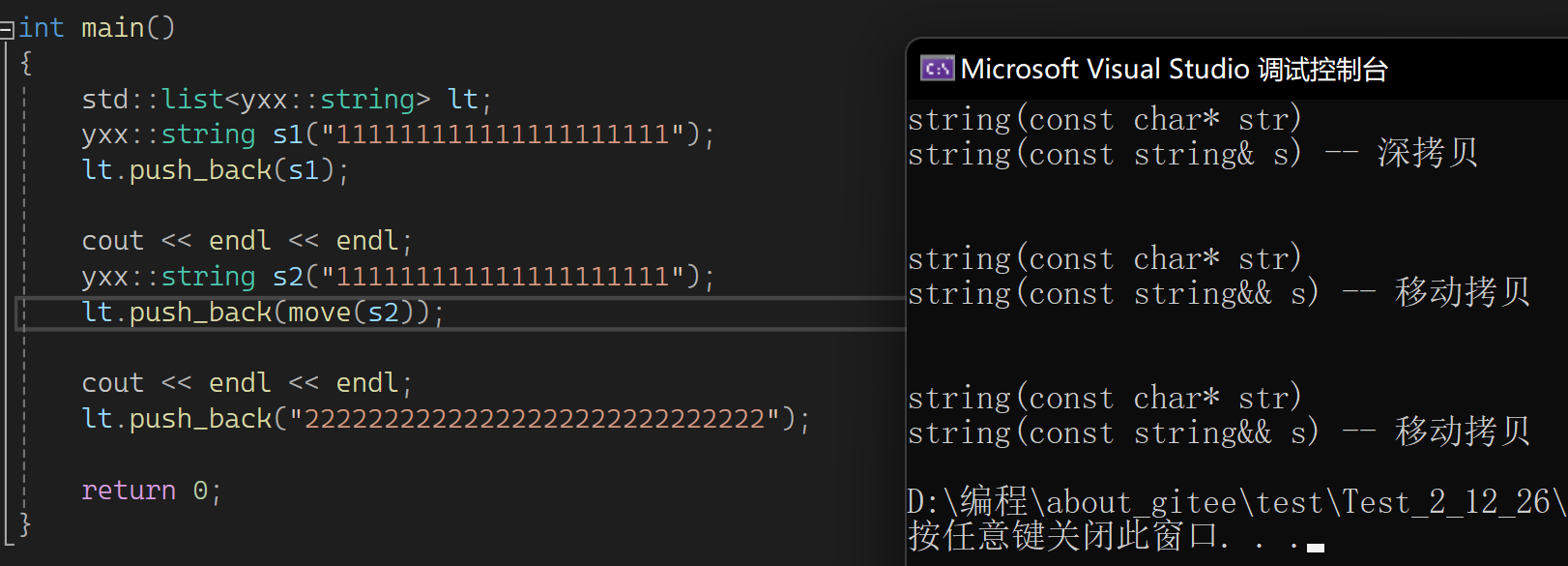
下面测试一下:
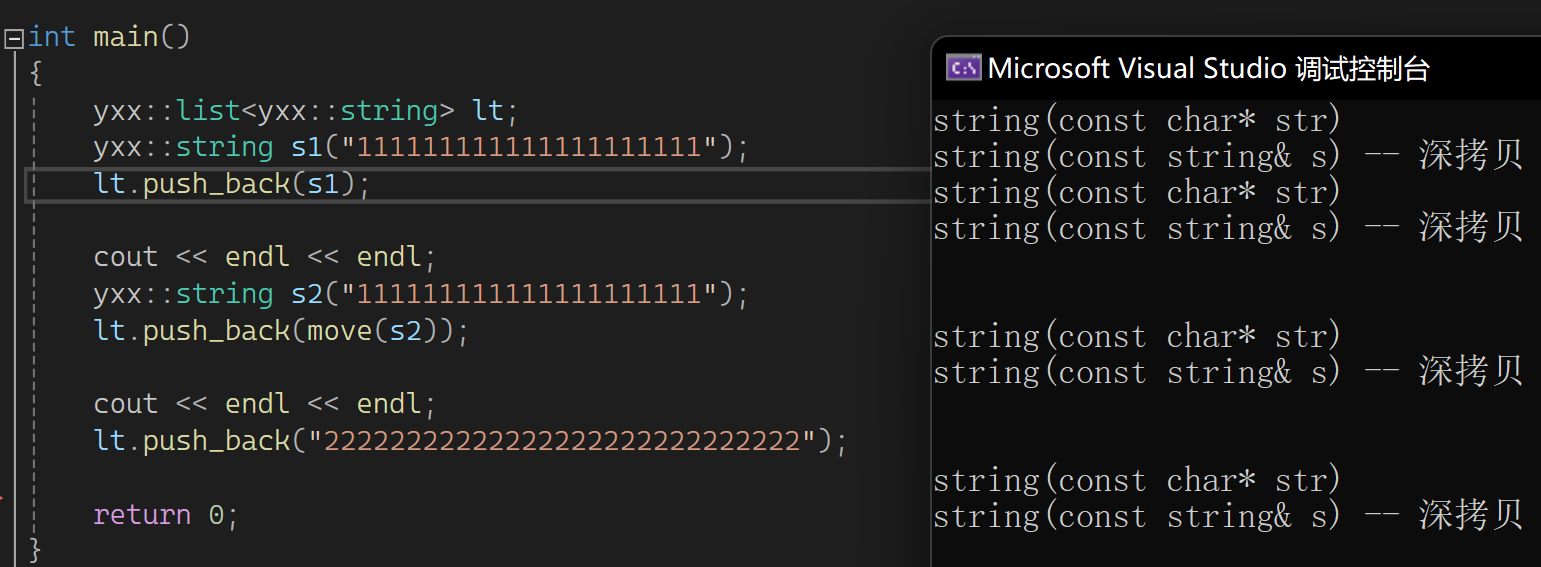
还是没有变,调式push(move(s2)),匹配的是又值,但调insert时调的左值的,因为右值引用的属性会识别为左值。但是我期望右值属性可以保持,所以完美转发一下:
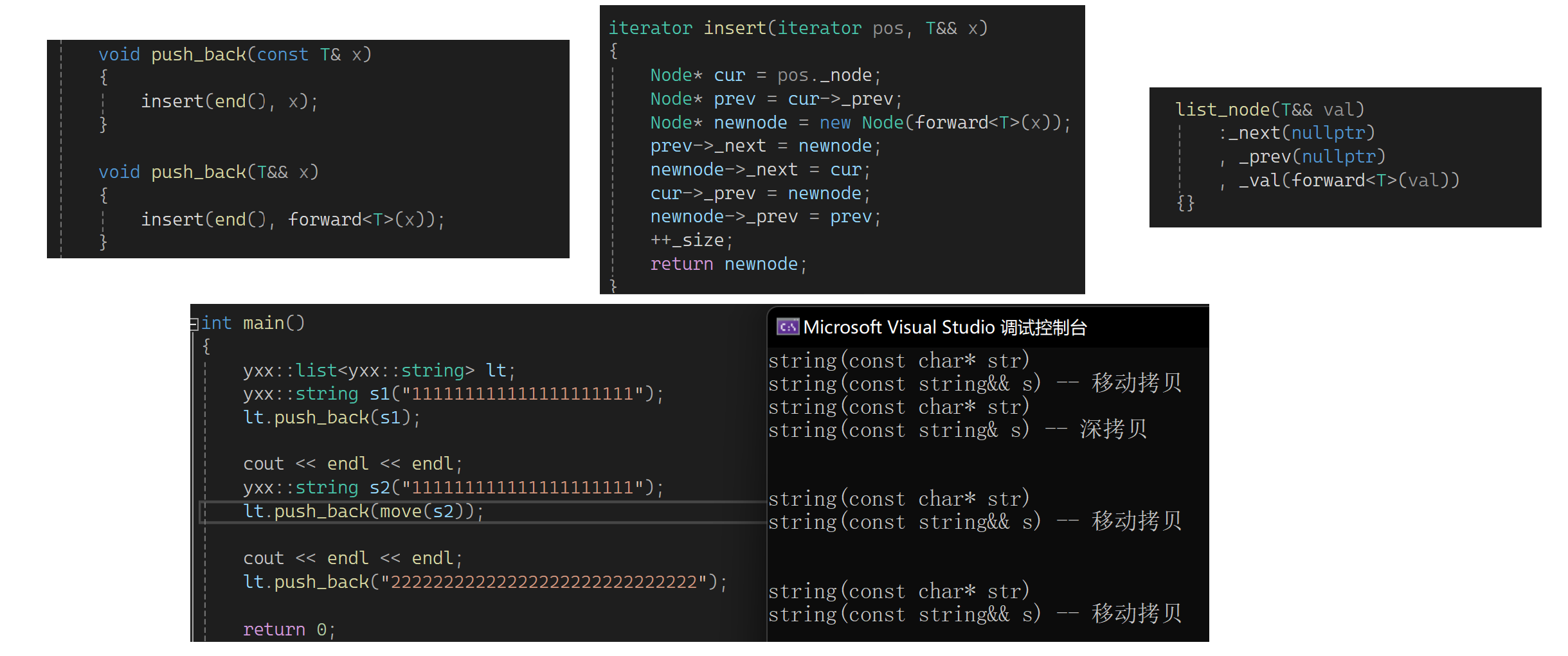
也可以用万能引用的方式: