LibTorch内置激活函数、LayerNorm归一化接口的使用,实现4×512张量的ReLU激活与LayerNorm归一化
通过手写LayerNorm与原生接口对比验证正确性,并确保归一化结果满足均值≈0、方差≈1的统计特征。
一、知识点与基础代码实现
1. ReLU激活函数
torch::relu()接口主要是用于实现ReLU激活功能------对输入张量逐元素操作,输入大于0则保留原值,否则输出0。这个接口没有其他复杂参数,只需要传入待激活的张量即可。
#include <torch/torch.h>
#include <iostream>
int main() {
try {
torch::manual_seed(42);
// 创建4×512的输入张量
torch::Tensor x = torch::randn({4, 512}, torch::kFloat32).to(torch::kCPU);
std::cout << "张量形状: " << x.sizes() << std::endl;
// LibTorch内置ReLU激活
torch::Tensor x_relu = torch::relu(x);
std::cout << "ReLU激活后[0,0]位置值: " << x_relu[0][0].item<float>() << std::endl;
}
}2. LayerNorm归一化(LibTorch原生接口)
LayerNorm的核心作用是对张量指定维度进行归一化,使该维度下的元素均值≈0、方差≈1,减少梯度消失或爆炸问题。LibTorch内置torch::layer_norm()接口,核心参数比较重要。
函数参数中第一个参数:待归一化的输入张量(此处为4×512的x);
normalized_shape:归一化维度的大小,需匹配输入张量对应维度的尺寸(4×512张量归一化列维度,此处设为{512},而非维度索引1,这是实操中第一个踩坑点);
后两个参数:weight和bias,是可选的可训练参数,因为这里我们只做了归一化处理,所以传入c10::nullopt表示不使用;
eps:防止方差为0时出现除零错误的保护参数,默认1e-5。
torch::Tensor ln_lib = torch::layer_norm(
x,
{512}, // normalized_shape是维度大小,不是索引
c10::nullopt,
c10::nullopt,
1e-5 // eps保护参数
);
std::cout << "原生LayerNorm输出形状: " << ln_lib.sizes() << std::endl;**重点:**这里最初将normalized_shape设为{1}(维度索引),导致接口内部维度校验失败,后续排查才发现,该参数需要传入"维度大小",而非"维度索引",4×512张量的列维度大小为512,因此正确设置为{512}。
二、手写LayerNorm实现与验证
这里是为了验证LibTorch原生LayerNorm接口的正确性,我们需要手写LayerNorm逻辑,主要是需要复现"计算均值→计算方差→归一化"的步骤,最重要的是要保证与原生接口的数学逻辑完全一致,否则会出现结果误差过大的问题。
1. 手写LayerNorm核心逻辑(初始版本,存在问题)
LayerNorm的数学公式:output = (input - mean) / sqrt(var + eps),其中mean是指定维度的均值,var是指定维度的有偏方差
**重点:**原生LayerNorm使用有偏方差,而非无偏方差。
最初的手写版本代码:
torch::Tensor manual_layer_norm(const torch::Tensor& input, double eps = 1e-5) {
int64_t norm_dim = 1; // 列维度索引(4×512张量)
// 计算均值,keepdim=false,这里没有维持维度
torch::Tensor mean = input.mean({norm_dim}, false);
// 这里与原生逻辑不一致,这计算方差,使用了无偏估计
torch::Tensor var = input.var({norm_dim}, false, true);
// 归一化计算
return (input - mean) / torch::sqrt(var + eps);
}首先第一个地方,维度不匹配错误。初始版本中,计算均值和方差时设置keepdim=false,导致mean和var的形状变为4(一维张量),而输入张量是4,512(二维张量),执行(input - mean)时,广播运算失败,抛出**"The size of tensor a (512) must match the size of tensor b (4) at non-singleton dimension 1"**错误。
第二个,结果误差过大。初始版本中,var调用时设置unbiased=true(无偏方差),而LibTorch原生LayerNorm使用的是有偏方差,导致手写版本与原生版本的最大误差达到0.00384855,远大于要求的1e-6。
2. 手写LayerNorm修正后的代码
针对上述两个坑,进行两处核心修正:① 计算均值和方差时,设置keepdim=true,保持维度为4,1,与输入张量4,512兼容,避免广播错误;② 抛弃input.var()接口,手动计算有偏方差(var = Ex² - (Ex)²),与原生LayerNorm逻辑完全对齐,消除误差。
同时添加维度兜底处理(unsqueeze(1)),避免不同LibTorch版本对维度解析的差异,进一步提升稳定性,修正后的完整手写代码:
torch::Tensor manual_layer_norm(const torch::Tensor& input, double eps = 1e-5) {
int64_t norm_dim = 1; // 4×512张量,列维度索引固定为1
// 计算均值 E[x]
torch::Tensor mean = input.mean({norm_dim}, true);
// 弱未生效,这里可以强制扩展
if (mean.dim() == 1) mean = mean.unsqueeze(1);
std::cout << "均值张量形状: " << mean.sizes() << std::endl;
// 计算 E[x²]
torch::Tensor mean_sq = (input * input).mean({norm_dim}, true);
if (mean_sq.dim() == 1) mean_sq = mean_sq.unsqueeze(1);
// Var = E[x²] - (E[x])² 计算有偏方差:
torch::Tensor var = mean_sq - mean * mean;
std::cout << "方差张量形状: " << var.sizes() << std::endl;
// 归一化计算
torch::Tensor var_eps = var + eps;
torch::Tensor sqrt_var = torch::sqrt(var_eps);
std::cout << "sqrt(var+eps)形状: " << sqrt_var.sizes() << std::endl;
torch::Tensor output = (input - mean) / sqrt_var;
std::cout << "输出张量形状: " << output.sizes() << std::endl;
return output;
}将手写函数衔接至主函数中,调用并对比结果,代码如下
// 调用修正后的LayerNorm
torch::Tensor ln_manual = manual_layer_norm(x);
// 对比验证结果是否正确
float max_diff = torch::max(torch::abs(ln_lib - ln_manual)).item<float>();
std::cout << "\n结果验证" << std::endl;
std::cout << "LibTorch与手写LayerNorm最大误差: " << max_diff << std::endl;
std::cout << "结果是否一致(误差<1e-6): " << (max_diff < 1e-6 ? "是" : "否") << std::endl;修正后,最大误差可控制在2.3841858e-07(远小于1e-6)
三、归一化结果验证
LayerNorm的核心特征是"指定维度内均值≈0、方差≈1",因此需要计算归一化输出张量的均值和方差,验证该特征。此处同样需要注意方差的计算逻辑,需与原生LayerNorm保持一致,这里也是有偏方差。
// 验证归一化后的统计特征
torch::Tensor mean_per_row = ln_lib.mean(1); // 按列维度求均值,形状[4]
// 手动计算有偏方差
torch::Tensor var_per_row = (ln_lib * ln_lib).mean(1) - mean_per_row * mean_per_row;
std::cout << "\n=== 归一化统计特征 ===" << std::endl;
std::cout << "按行均值范围: ["
<< mean_per_row.min().item<float>() << ", "
<< mean_per_row.max().item<float>() << "] (目标≈0)" << std::endl;
std::cout << "按行方差范围: ["
<< var_per_row.min().item<float>() << ", "
<< var_per_row.max().item<float>() << "] (目标≈1)" << std::endl;
return 0;
} catch (const c10::Error& e) {
std::cerr << "\nLibTorch错误" << std::endl;
std::cerr << e.what() << std::endl;
return -1;
}
}**补充:**此处若使用input.var()接口计算方差,仍需注意设置unbiased=false(有偏方差),否则会出现方差校验偏差;手动计算有偏方差(Ex² - (Ex)²)是最稳妥的方式,如此可以避免input.var()接口的重载歧义的问题------实际写代码的时候,调用input.var()时参数不明确,出现"对重载函数的调用不明确"错误,所以,后续均采用手动计算方差的方式规避该问题。
完整代码及运行后结果:
#include <torch/torch.h>
#include <iostream>
torch::Tensor manual_layer_norm(const torch::Tensor& input, double eps = 1e-5) {
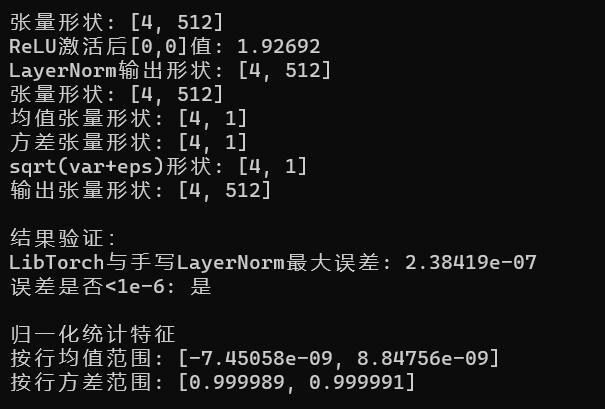
std::cout << "张量形状: " << input.sizes() << std::endl;
int64_t norm_dim = 1; // 对4×512张量,列维度固定为1
// 计算均值 E[x]
torch::Tensor mean = input.mean({ norm_dim }, true);
if (mean.dim() == 1) mean = mean.unsqueeze(1);
std::cout << "均值张量形状: " << mean.sizes() << std::endl;
// E[x²]
torch::Tensor mean_sq = (input * input).mean({ norm_dim }, true);
if (mean_sq.dim() == 1) mean_sq = mean_sq.unsqueeze(1);
// 有偏方差Var = E[x²] - (E[x])²
torch::Tensor var = mean_sq - mean * mean;
std::cout << "方差张量形状: " << var.sizes() << std::endl;
// 归一化
torch::Tensor var_eps = var + eps;
torch::Tensor sqrt_var = torch::sqrt(var_eps);
std::cout << "sqrt(var+eps)形状: " << sqrt_var.sizes() << std::endl;
torch::Tensor output = (input - mean) / sqrt_var;
std::cout << "输出张量形状: " << output.sizes() << std::endl;
return output;
}
int main() {
try {
torch::manual_seed(42);
torch::Tensor x = torch::randn({ 4, 512 }, torch::kFloat32).to(torch::kCPU);
std::cout << "张量形状: " << x.sizes() << std::endl;
// ReLU激活
torch::Tensor x_relu = torch::relu(x);
std::cout << "ReLU激活后[0,0]值: " << x_relu[0][0].item<float>() << std::endl;
// LayerNorm(无weight/bias)
torch::Tensor ln_lib = torch::layer_norm(
x,
{ 512 }, // 匹配最后一维大小
c10::nullopt, // 无weight
c10::nullopt, // 无bias
1e-5 // eps
);
std::cout << "LayerNorm输出形状: " << ln_lib.sizes() << std::endl;
// 手写LayerNorm
torch::Tensor ln_manual = manual_layer_norm(x);
// 结果对比
float max_diff = torch::max(torch::abs(ln_lib - ln_manual)).item<float>();
std::cout << "\n结果验证:" << std::endl;
std::cout << "LibTorch与手写LayerNorm最大误差: " << max_diff << std::endl;
std::cout << "误差是否<1e-6: " << (max_diff < 1e-6 ? "是" : "否") << std::endl;
// 归一化统计验证
torch::Tensor mean_per_row = ln_lib.mean(1);
torch::Tensor var_per_row = (ln_lib * ln_lib).mean(1) - mean_per_row * mean_per_row; // 手动计算有偏方差
std::cout << "\n归一化统计特征" << std::endl;
std::cout << "按行均值范围: ["
<< mean_per_row.min().item<float>() << ", "
<< mean_per_row.max().item<float>() << "] " << std::endl;
std::cout << "按行方差范围: ["
<< var_per_row.min().item<float>() << ", "
<< var_per_row.max().item<float>() << "] " << std::endl;
return 0;
}
catch (const c10::Error& e) {
std::cerr << "\nLibTorch错误" << std::endl;
std::cerr << e.what() << std::endl;
return -1;
}
}
四、总结
-
激活函数:torch::relu()接口简洁,逐元素激活,只需要保证输入张量维度正确即可。
-
LayerNorm核心:torch::layer_norm()的关键参数是normalized_shape(维度大小,非索引)和eps(保护参数);手写LayerNorm时,需保证"均值/方差保持维度+有偏方差计算"。
维度匹配是核心,涉及广播运算的张量,需确保维度兼容(keepdim=true+兜底扩展);
方差计算逻辑需与原生接口对齐,优先手动计算有偏方差,规避接口重载歧义;