论文总结
1、针对传统的CNN和Transformer融合方法,容易受到伪目标信息影响,导致模型注意力分散、漏检或者误检增加,作者提出Fusion-Mamba,在隐藏状态空间内充分交互跨模态特征,同时抑制伪目标信息。
2、Fusion-Mamba组成:
-
采用双流特征提取网络(基于YOLOv5/v8的CSPDarknet骨干网络)。
-
在最后三个阶段(P3、P4、P5)插入Fusion-Mamba Block (FMB),用于跨模态特征融合。
-
融合后的特征输入YOLOv8的Neck和Head进行目标检测。
3、Fusion-Mamba Block (FMB) 组成
-
State Space Channel Swapping (SSCS) 模块
-
通过通道交换操作,将RGB和IR特征在通道维度上交叉组合,实现浅层特征融合。
-
随后经过一个VSS(Visual State Space)块增强交互。
-
-
Dual State Space Fusion (DSSF) 模块
-
将浅层融合特征投影到隐藏状态空间,使用双门控注意力机制。
-
门控参数(z_Ri, z_IRi)调制不同模态的隐藏状态特征,实现深层融合。
-
有效抑制伪目标信息,增强共有特征表示。
-
可堆叠多个DSSF模块(实验中默认8个)。
-
- 最终融合:增强后的RGB和IR特征相加,得到P_i送入检测头。
4、Fusion-Mamba通过隐藏状态空间交叉融合和门控注意力机制,有效抑制伪目标信息,提升跨模态目标检测性能,同时保持线性计算复杂度。未来可以扩展到跨模态图像融合、跨模态目标检测、小样本小目标检测等更具有挑战性任务。
摘要
跨模态目标检测旨在融合来自不同模态的互补信息以提高模型性能,从而实现更广泛的应用。然而,传统的基于CNN或Transformer的跨模态融合方法不能很好地处理伪目标信息问题,导致模型注意力分散从而降低目标检测性能。在本文中,我们研究了一种新的跨模态融合方法,通过在隐藏状态空间中关联跨模态特征,基于改进的Mamba和门控注意力机制。 我们提出了Fusion - Mamba Block ( FMB ),旨在将跨模态特征映射到隐藏的状态空间中进行交互,从而细化模型对真实目标区域的注意力,提升整体性能。FMB包含两个关键模块:状态空间通道交换( State Space Channel Swapping,SSCS )模块,便于浅层特征的融合;双状态空间融合( Dual State Space Fusion,DSSF )模块,能够实现深度融合并有效抑制隐藏状态空间内的伪目标信息。本文提出的方法优于当前最先进的方法,实现了5的改进。9 %、3 . 5 %、2 . 1 % m AP分别在M 3FD、Drone Vehicle和FLIR - Aligned上测定。 据我们所知,这项工作为跨模态目标检测建立了一个新的基线,为该领域的未来研究提供了坚实的基础。
引言
随着多模态传感器技术的飞速发展,多模态图像已经被应用于许多不同的领域。其中,成对的红外( IR )和可见光( RGB )图像已经得到了广泛的应用 1 , 2 , 3 , 4 , 5 ,因为这两种模态的图像可以相互提供互补的信息。例如,红外图像可以提供清晰的物体热结构,而不受亮度的影响,同时缺乏目标的纹理细节。相比之下,可见光图像能够捕获丰富的物体纹理和场景信息,但是光照和天气条件严重影响图像的质量。 因此,许多研究集中于红外和可见光特征的融合,以提高下游高级图像和场景理解任务的性能和鲁棒性,例如,目标检测和图像分割。现有的多光谱融合方法通常使用卷积神经网络( Convolutional Neural Networks,CNNs ) 6 , 7 , 8 或Transformers 9 , 10 来融合跨模态特征。Halfway Fusion 11 被引入来整合来自RGB和IR图像的两个分支的中层特征用于多光谱目标检测。GAFF 12 利用卷积和掩膜操作构建双流中间融合检测器。YOLO-MS 13 引入了两种基于CNN的融合模块来融合YOLOv5主干网络的相邻分支,用于实时目标检测。 在基于具有局部感受野的CNNs的跨模态融合取得巨大成功后,基于Transformer的方法被提出,以有效地学习跨模态特征融合的长距离上下文依赖。CFT 14 是第一个探索Transformer进行中层多模态特征融合的研究。ICAFusion 15 使用了一种双交叉注意力Transformer,有效地捕获了全局特征,有利于提取不同模态之间的互补信息。 尽管CNNs和Transformer的成功应用,但大多数传统的跨模态融合方法主要集中于利用模态之间的互补信息,无法充分解决融合过程中由背景中的噪声或原始模态的复杂光照条件产生的伪目标信息的问题 16 , 17 。这种噪声或复杂的光照通过将注意力集中在不相关的区域,破坏了模型的性能,从而降低了检测精度。如图1 ( b )和( c )所示,我们将热图和探测结果可视化。

图1 .我们Fusion-Mamba的动机。误检目标及其对应的注意区域以红色椭圆为圆心,漏检目标及其对应的注意区域以绿色椭圆为圆心。( a )初始RGB、IR输入图像及其Ground Truth的可视化。( b )可视化三种基于CNN或Transformer的融合方法生成的热图,以及我们提出的方法的结果。( c )检测结果的可视化。我们的方法抑制了伪标签信息,使更多的注意力集中在目标上,减少了漏检和误报的情况。
基于CNN或Transformer架构的三种融合方法用于跨模态目标检测,即YOLO - MS 13 ,ICAFusion 15 和CFT 14 。可以观察到,模型中的误报和漏报主要归因于伪目标信息扰乱了模型的注意力分配。YOLO - MS的注意力被转移到一些背景区域,导致假阳性检测受到噪声目标的干扰。并且,噪声目标信息过度扩大了检测目标(例如, YOLO - MS和ICAFusion中的右下方红色椭圆)上的注意力区域,导致模型对置信度分数较高的个别目标产生重复检测。 从CFT中可以发现,漏检的原因在于模型的注意力被这种伪目标信息分散到背景区域,导致对检测目标本身的注意力不足和置信度得分低,从而无法检测出目标物体。此外,基于CNN的跨模态融合缺乏全局建模能力,而基于Transformer的融合计算量大,时间和空间复杂度均为二次。这促使我们重新考虑:能否设计一种高效的架构,使其能够在抑制融合特征中来自原始模态的伪目标信息的同时,实现更充分的跨模态信息交互。 在本文中,我们为跨模态特征融合开辟了一种新的Fusion - Mamba范式,其目的是在一个隐藏的状态空间中充分融合特征。我们从Mamba 18 , 19 , 20 中得到启发,他们采用线性复杂度的方法来构建隐状态空间。通过集成门控注意力机制,我们增强了这一框架,以实现更深层次和更有效的融合,同时抑制了融合特征中来自原始模态的伪目标信息。Fusion - Mamba的主要创新在于Fusion Mamba Block ( FMB ),如图2所示。在FMB中,我们设计了用于浅层特征融合的状态空间通道交换( State Space Channel Swapping,SSCS )模块,增强了跨模态特征之间的交互。 此外,我们实现了双状态空间融合( Dual State Space Fusion,DSSF )模块构建隐藏状态空间,在有效抑制伪目标信息的同时,实现了跨模态特征的关联互补。这两个模块将两种模态的特征信息逐步融合,最大限度地减少了融合特征中伪目标信息的引入,从而提高了模型的检测性能。如图1 ( b )和( c )所示,热图和检测结果表明,我们的方法实现了更有效的特征融合,减少了伪目标信息,使检测器更准确地聚焦于目标,减少了误报和漏报的情况。
本文的主要贡献如下:
1 )提出的Fusion - Mamba方法挖掘了Mamba在目标检测中跨模态特征融合的潜力。通过改进的门控注意力机制增强的Mamba框架,我们构建了跨模态交互的隐藏状态空间。该方法在有效抑制跨模态伪目标信息的同时,有利于充分的特征交互。
2 )设计了一个即插即用的融合模块- - Mamba Block ( FMB ),该模块包含两个模块:状态空间通道交换( SSCS )模块实现浅层特征融合,双状态空间融合( DSSF )模块实现隐藏状态空间的深层融合。 这两个模块通过浅层特征交换和深层特征融合充分整合了两种模态的特征,并通过门控注意力机制显著降低了伪目标信息的影响。
3 )在三个公开的RGB - IR目标检测数据集上的大量实验表明,我们的方法取得了先进的性能,为跨模态目标检测建立了一个新的基线。
相关工作
多模态目标检测:随着YOLO系列模型 21 、基于Transformer的模型 22 、 23 、 24 等单模态检测器的快速发展,多模态目标检测器应运而生,以很好地利用不同模态的图像。到目前为止,关于多模态目标检测的研究主要集中在两个方向:像素级融合和特征级融合。像素级融合将多模态输入图像组合成单幅融合图像,然后将其输入到积分检测器中。这些方法侧重于利用多模态输入图像信息重建融合图像 25 , 26 , 27 , 28 , 29 并利用融合后的图像进行目标检测。过熔 30 设计了一个具有全局空间注意力和语义信息的网络用于图像融合。CDDFuse 31 为多模态图像融合提出了针对低频全局信息和高频局部信息的目标网络,在融合和下游任务中取得了很好的效果。特征级融合结合了检测器在不同阶段的输出,包括主干(早中期融合 , , , , )提取的早期和中期特征以及最终的检测输出(晚期融合 , , , )。 特征级融合将融合操作作为一个统一的端到端CNN 41 , 42 , 43 或Transformer框架 44 , 45 , 46 集成到检测网络中。C 2 Former-S 2 ANet 46 采用基于Transformer的方法进行主干特征融合,设计了自适应特征采样模块和模态间交叉注意力模块,提升了检测性能。ProEn 38 基于贝叶斯概率规则将两种模态的检测结果进行融合,巧妙地处理了模态对齐和缺失的问题。这些融合方法有效地提高了目标检测性能。但是,它们在抑制融合特征中来自原始模态的伪目标信息方面仍然受到限制。 Mamba:自从Mamba 18 提出在NLP领域中对线性时间序列建模具有全局建模能力以来,它已经被迅速扩展到各种计算机视觉任务中的应用。Vmamba 19 根据图像的特点引入了四通向的扫描算法,构建了基于Mamba的视觉主干,在目标检测、目标分割和目标跟踪方面比Swin Transformer具有更好的性能。VM-UNet 47 和VM - UNetv2 48 在基于UNet框架和Mamba块的医学分割领域大放异彩。之后,许多基于Mamba的深度网络 49 , 50 被提出,用于在医学图像中进行精确分割。 Video Mamba 51 将原始的2D扫描扩展到不同的双向3D扫描,并设计了一个Mamba框架,将mamba用于视频理解区域。与以往的方法不同,我们的工作利用Mamba在跨模态目标检测中进行特征融合,利用其具有线性复杂度的全局建模能力。我们引入了一个精心设计的基于Mamba的结构- - FusionMamba Block ( FMB ),它将跨模态特征集成在一个隐藏的状态空间中,从浅到深逐层递进。这种方法产生了更全面的融合特征,减少了伪目标信息,从而在各种公开的RGB - IR目标检测数据集上的检测性能得到了改善。
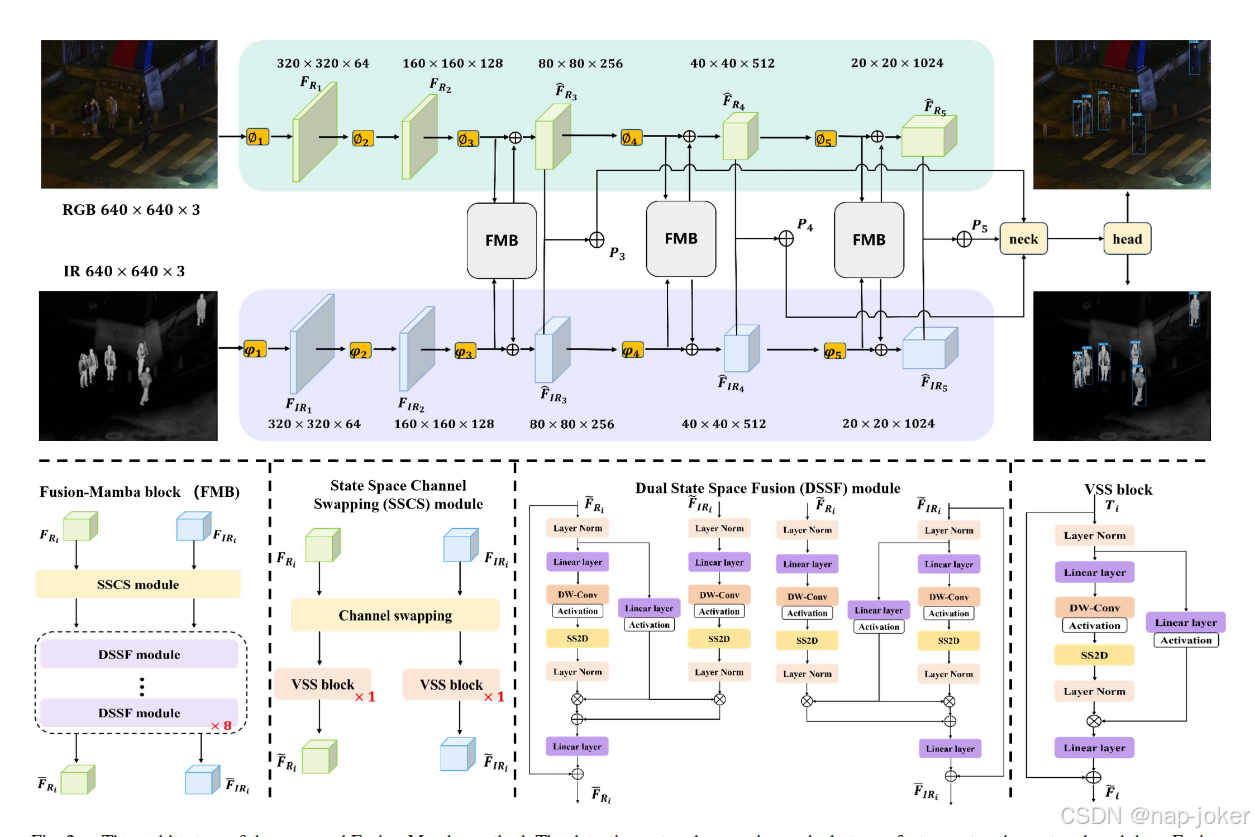
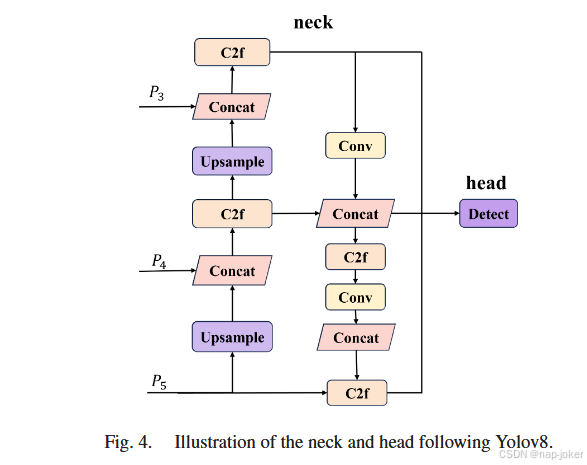
图2 .提出的Fusion - Mamba方法架构。检测网络包括一个双流特征提取网络和3个FusionMamba Blocks ( FMB ),颈部和头部与YOLOv8相同。最上层是我们的检测框架,φ i和φ i是RGB分支和IR分支的卷积模块,分别用于生成FRi和FIRi的特征。F ( Ri和F ( IRi是通过我们的FMB增强的特征图。P3、P4和P5是增强特征图的总和输出,作为后三个阶段颈部的特征金字塔输入。下面展示了我们的FMB的设计细节。
方法
预备知识
状态空间模型:状态空间模型( State Space Models,SSMs )常用来表示线性时不变系统,它通过中间隐状态h ( t )∈RN处理一维输入序列x ( t )∈R,从而产生输出y ( t )∈R。
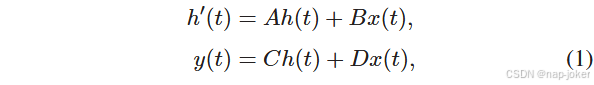
其中系统的行为由一组参数定义,包括状态转移矩阵A∈RN × N,投影参数B,C∈RN × 1和跳跃连接D∈R. Dx ( t )可以很容易地通过设置D = 0来消除.
离散化:( 1 )中SSMs的连续时间特性在深度学习场景中应用时提出了重大挑战,因为大多数训练和测试数据都是离散化的。为了解决这个问题,需要通过离散化的过程对ODEs进行离散化,这也是将ODEs转化为离散函数的关键目的。它对于确保输入数据中的模型和底层信号的采样率之间的对齐至关重要,便于进行有效的计算操作 52 。 考虑输入xk∈RL × D,一个长度为L的信号流中的采样向量 53 ,引入时标参数Δ使得连续参数A和B向离散参数A和B过渡,并遵循零阶保持( ZOH )原则.因此,对式( 1 )进行如下离散化:
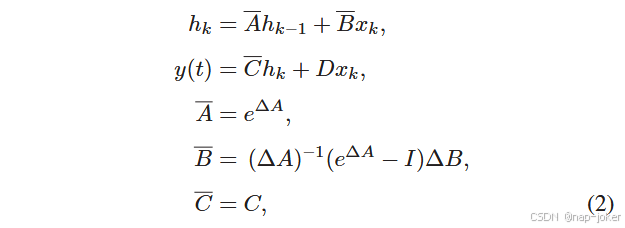
式中:B,C∈RD,I为单位矩阵。离散化后,SSMs由一个结构化卷积核K ~∈RD的全局卷积计算得到:
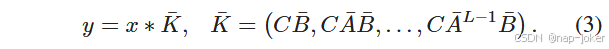
在( 2 )和( 3 )的基础上,Mamba 18 设计了一种简单的选择机制,将Δ,A,B和C的SSM参数根据输入x进行参数化,从而沿着序列长度维度选择性地传播或遗忘信息,用于1D语言序列建模。
2D - Selective - Scan机制:2D视觉数据和1D语言序列之间的不兼容性使得Mamba直接应用于视觉任务是不合适的。例如,虽然2D空间信息在视觉相关的工作中起着至关重要的作用,但它在1D序列建模中起着次要作用。这种差异导致有限的感受野,无法捕获与未探索块的潜在相关性。2D选择性扫描( SS2D )机制在 19 中被引入来解决上述挑战。 SS2D的概述如图3所示。SS2D的第一次扫描将图像块扩展到四个不同的方向,以生成四个独立的序列。这种四向扫描方法保证了特征图中的每个元素都包含了来自不同方向的所有其他位置的信息。因此,它建立了一个全面的全局感受野,而不需要计算复杂度的线性增加。随后,每个特征序列使用选择性扫描空间状态序列模型( S6 ) 18 进行处理。最后,对特征序列进行聚合,重构2D特征图。SS2D作为视觉状态空间( VSS )块的核心元素,如图所示 2,并将用于构建跨模态特征融合的隐藏状态空间。增加更多扫描方向的情况将在第IV ~ C节讨论。
融合Mamba
1 )体系结构:我们的模型的体系结构如图2所示。其检测主干包括一个双流特征提取网络和三个Fusion - Mamba Blocks ( FMB ),而检测网络包含颈部和头部用于跨模态目标检测。特征提取网络便于从RGB和IR图像中提取局部特征,分别用FRi和FIRi表示。之后,我们通过在隐藏状态空间中关联跨模态特征,将这两种特征输入到FMB中,增强了融合特征的表示一致性,抑制了来自原始模态的伪目标信息。 具体而言,这两个局部特征首先经过状态空间通道交换( State Space Channel Swapping,SSCS )模块进行浅层特征融合,得到交互特征F ' Ri和F ' IRi。然后,我们将这些交互特征输入到双状态空间融合( DSSF )模块中进行隐藏状态空间的深度特征融合,从而生成相应的互补特征F Ri和F IRi。通过在互补特征F Ri和F IRi中分别添加原始特征FRi和FIRi,来增强局部特征以生成F ( Ri )和F ( IRi )。随后,将增强后的特征F ( Ri )和F ( IRi )直接相加,生成融合特征Pi。 本文只在后三个阶段加入FMB生成融合特征P3、P4和P5 (如未注明),作为Yolov8检测模型颈部和头部的输入,生成最终的检测结果(如图4所示)。
2 )关键组件:给定输入的RGB图像IR和红外图像IIR,我们将它们输入到一系列的卷积块中,以提取它们的局部特征。
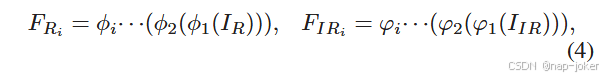
其中φ i和φ i分别表示第i级RGB分支和IR分支的卷积块。为了实现跨模态特征融合,现有的方法 11 , 33 , 38 主要强调空间特征的融合。
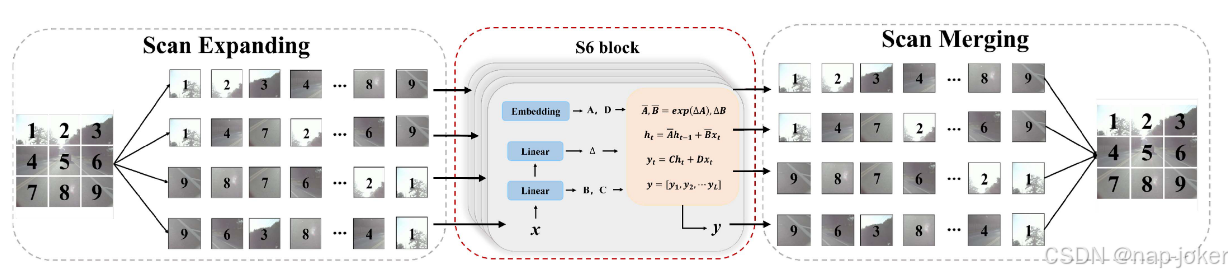
图3 . Rgb图像的二维选择性扫描( Ss2D )示意图。初始时,图像进行扫描扩展,产生4个明显不同的特征序列。随后,这些序列中的每个序列通过S6块独立处理。最后,通过扫描合并将S6块的输出进行合并,生成最终的2D特征图。
没有充分解决由于原始模态的噪声或光照而在融合特征中引入的伪目标信息的问题,从而削弱了模型的表征能力。受Mamba 18 在状态空间中具有强大序列建模能力的启发,我们设计了融合Mamba模块( Fusion-Mamba Block,FMB )来构建跨模态特征交互和关联的隐藏状态空间。相比于传统的CNNs或特征级联后Transformers操作中的交叉注意力方法,我们的Fusion Mamba通过分别处理两种模态来实现更详细的融合。首先,在SSCS模块中进行通道切换,保证每个处理分支都能从另一个模态中获得丰富的信息。 然后,DSSF模块作为核心模块处理来自两个分支的信息。通过隐藏空间中的深度交互,相比于传统方法,实现了更深入的信息融合。更重要的是,DSSF模块引入了门控注意力机制,该机制创新性地将一种模式的特征作为注意力权重来处理另一种模式,从而强化了共同的特征表示,有效地弱化或消除了每种模式特有的伪目标信息。SSCS模块:该模块旨在通过通道交换操作和一个VSS块来增强跨模态特征交互,用于浅层特征融合。 通过整合不同通道的信息构建跨模态特征关联,丰富了通道特征的多样性,以提高融合性能。首先,我们使用通道交换操作来生成RGB TRi和IR TIRi的新的局部特征,可以表示为:
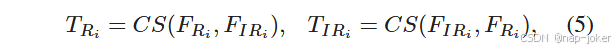
其中CS( · , ·)是通道交换操作,通过通道拆分和级联很容易实现。首先,将局部特征FRi和FIRi沿通道维度均分为4等份。随后,我们从FRi中选取第一和第三部分,从FIRi中选取第二和第四部分,通过部分串联的方式生成新的局部RGB特征TRi。相应地,我们生成了新的局部IR特征TIRi。随后,对TRi和TIRi同时使用VSS块,从浅层融合特征中增强跨模态交互。
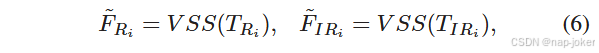
其中V SS ( · )表示VSS块 19 ,如图2所示。F ' Ri和F ' IRi分别为RGB和IR模态浅层融合特征的输出。DSSF模块:为了进一步提高特征融合的充分性,抑制原始模态中的伪目标信息,我们构建了一个隐藏的状态空间用于跨模态特征关联和互补。提出DSSF对跨模态对象相关性进行建模,以利于特征融合。具体来说,我们使用VSS模块将两种模态的特征投影到隐藏状态空间中,并利用门控机制来对偶地构建隐藏状态转移,以实现跨模态深度特征融合。 形式上,在获得浅层融合特征F ' Ri和F ' IRi后,我们首先通过一个没有门控的VSS块将其投影到隐藏状态空间中。
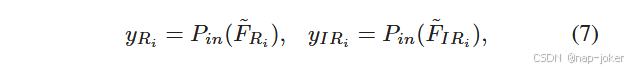
其中Pin ( · )表示将特征投影到隐状态空间的操作。该操作由归一化和线性层组成,然后是深度卷积( DW-Conv )和激活函数。然后通过SS2D操作和额外的归一化步骤得到隐藏的状态特征。由此得到的隐藏状态特征用yRi和yIRi表示。
我们还对F ' Ri和F ' IRi进行投影,得到门控参数zRi和zIRi。

其中y′Ri和y′IRi分别表示特征交互后RGB和IR的隐藏状态特征。具体来说,( 9 )和( 10 )使用门控机制在隐藏状态空间内建立跨模态融合,其中使用双重注意力来增强跨分支信息互补并抑制伪目标信息。随后,我们将y′Ri和y′IRi投影回原始空间并通过残差连接得到互补特征F Ri和F IRi:
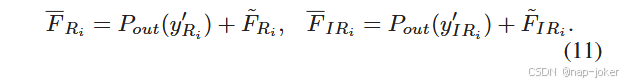
式中:Pout ( · )表示线性变换的投影运算。在实际应用中,我们将多个DSSF模块(即( 7 ) ~ ( 11 ) )进行叠加,以获得更深层次的特征融合,取得了较好的效果。然而,DSSF模块的数量会在某一数值上达到饱和,这在我们的实验中得到了进一步的评估。最后,将互补特征融合到局部特征中,通过加法运算增强特征表示:
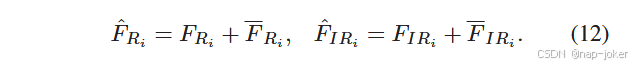
3 )损失函数:在FMB之后,进一步添加来自RGB和IR (即F ( Ri )和F ( IRi )在( 12 ) )的增强特征,生成融合特征Pi作为颈部的输入,以提高检测性能。根据 54 , 55 ,总的检测损失函数可以构造为:

相比于基于Transformer的融合
现有的基于Transformer的跨模态融合方法 14 , 15 往往将两种模态的特征进行扁平化和拼接,随后通过多头交叉注意力进行融合,得到最终的融合特征。这些方法主要集中于互补特征的融合,这限制了它们在融合特征内减轻来自原始模态的伪目标信息影响的能力。我们的FMB对特征进行四个方向的扫描,得到四组序列,有效地保留了全局信息。 然后将这些序列映射到一个隐藏空间进行特征融合,在该空间中使用双向门控注意力,既抑制伪目标信息,又便于跨模态的互补信息融合。因此,所提出的FMB增强了融合特征表示的一致性,同时减轻了来自原始模态的伪目标信息的影响。此外,Transformer的全局注意力的时间复杂度为O ( N 2 ),而Mamba的时间复杂度仅为O ( N ),其中N为序列长度。从实验角度来看,采用相同的检测模型架构,将基于Transformer的融合模块替换为Fusion - Mamba Block,在一对图像上可以节省7 ~ 19 ms的推理时间。 在我们的实验中讨论了更多的细节。
实验
实验配置
数据集:我们的Fusion - Mamba方法在四个公开的不同类型的可见光-红外目标检测基准数据集LLVIP 56 ,M 3FD 57 ,DroneVehicle 58 和FLIR 59 上进行了评估。LLVIP是一个在低光照环境下采集的对齐的可见光( RGB )和红外( IR )数据集,包含15488个RGB - IR图像对。该数据集被广泛应用于检测任务中,用于衡量模型的检测能力。遵循官方标准,我们使用12,025对用于训练,3463对用于测试。M 3F D包含4,200个RGB - IR对齐图像对,这些图像对在不同的环境中采集,包括不同的光照、季节和天气场景。在恶劣天气条件下拍摄的图像对模型检测提出了重大挑战。 它有六类通常出现在自动驾驶和道路监控场景中。该多类检测数据集被广泛用于多模态检测模型在困难条件下的性能评估。由于没有官方的数据集划分方法,我们采用文献 60 提供的训练/测试分割。DroneVehicle是一个用于车辆检测的大规模RGB - IR数据集。它由不同光照条件、视角、高度和场景的无人机采集,由28,439个RGB - IR图像对组成。它有953,087个车辆注释,分为五大类:小汽车、卡车、公共汽车、面包车和货车。 由于图像是自上而下的视角,覆盖多个角度,多模态模型在目标检测方面难以达到较高的性能。根据官方数据集划分时,使用17,990对图像对进行训练,1,469对用于验证,8,980对用于测试。我们在测试部分报告了结果。FLIR是在白天和夜晚的场景中收集的,有五个类别:人、汽车、自行车、狗和其他汽车。根据文献 61 ,我们使用FLIR - Aligned进行训练,有4 129对用于训练,1 013对用于测试。由于数据集中狗的实例数量非常少,我们将"狗"的类别从数据集中移除。这也被广泛认为是一个相对困难的RGB - IR检测数据集。评价指标:对于所有数据集,在目标检测区域使用最常见的评价指标m AP 50和m AP。m AP 50度量表示Io U 0下的平均AP。50,m AP度量表示Io U取值范围为0时的平均AP。 50 ~ 0 . 95,步幅为0 . 05 43 。由于FLIR - Aligned数据集的高难度,我们在该数据集上提供了精确率、召回率和F1分数的额外结果。这些指标的测试值越大,表示模型性能越好。我们还报告了我们的方法在一个A800 GPU上的平均推理时间,在输入大小为640 × 640的情况下运行5次。实现细节:所有的实验都是在双流框架 14 中用单GPU A800实现的。我们的Fusion - Mamba的骨架、颈部和头部结构与YOLOv5 - l或YOLOv8 - l默认设置相同。训练时,将批次大小设置为4,SGD优化器动量设置为0。9,权重衰减为0。001。 对于4个数据集,输入图像大小均为640 × 640,训练历元均设置为150,初始学习率为0。01。FMB中SSCS和DSSF模块数默认设置为1和8,λ coord设置为7。5 .其他训练超参数和数据增强参数与YOLOv8的默认参数相同。
和SOTA方法比较
为了评估我们的Fusion - Mamba的有效性,我们使用了两个特征提取主干,CSPDarknet53v5和CSPDarknet53v8,分别源自YOLOv5和YOLOv8架构。这保证了与其他先进方法的公平比较。后缀' v5 '和' v8 '分别表示以C3和SPP为骨架的YOLOv5和以C2f和SPPF为骨架的YOLOv8。此外,由YOLOv7衍生出的骨架被称为E - ELAN。LLVIP数据集:不同方法在LLVIP上的结果汇总在表1中。我们将所提出的Fusion - Mamba使用两种不同的骨架与12种SOTA多光谱目标检测方法、5种单模态检测方法和2种简单融合方法进行比较。为单模态检测中,仅使用红外图像的检测性能优于仅使用RGB图像的检测性能,因为在低光照条件下,红外模态中的目标信息更加突出。将RGB和IR进行特征融合后,基于ResNet主干网络提升了mAP性能,优于单一的IR模态检测。例如,以ResNet50网络为主干的RSDet 43 比仅使用IR模态的Cascade R- CNN 63 性能提升了4。5 % m AP。然而,一些融合方法在CSPDarknet53v5骨干网上的性能表现不如单模态。例如,一个简单的仅使用IR模态的YOLOv5检测框架 63 实现了61。9 % m AP,较DIVFusion 67 显著提高9 . 9 % m AP。 这表明YOLOv5的主干网络更难与ResNet进行有效的跨模态融合。尽管如此,我们的Fusion - Mamba以CSPDarknet53v5为主干实现了2 . m AP 50提高2 %,a 0 .与仅使用IR模态的YOLOv5检测框架相比,m AP提高了9 %。此外,它比RSDet提高了1 . 0 %,m AP 50为1 . 5 %。在相同的CSPDarknet53v8主干网下,我们的方法至少取得了1 . m AP 50和m AP均比朴素求和和串联提高了6 %。虽然LRAF - Net 68 比我们的Fusion - Mamba在CSPDarknet53v8的基础上提高了0 . 9 % m AP 50时,本文方法显著优于LRAF - Net 4 . 4 % m AP50的FLIR - Aligned数据集(如表4所示)。 这表明我们的Fusion - Mamba对不同的数据集具有很强的泛化能力。M 3FD数据集:我们将我们的方法与7个基于CSPDarknet53v5的SOTA检测器和1个基于E - ELAN的SOTA检测器进行比较。如表II所示,与基于相同CSPDarknet53v5主干的SOTA方法相比,我们的Fusion - Mamba方法在m AP 50和m AP指标上表现最好,而基于CSPDarknet53v8主干的方法在People、Bus、Motorcycle和Truck类别上取得了新的SOTA结果,同时m AP 50和m AP指标进一步提升了3。0 %、4 . 4 %。此外,尽管CSPDarknet53v5主干的特征表示能力相对于E - ELAN较低,但我们的方法比基于E - ELAN的过熔提高了1。5 %。 在相同的CSPDarknet53v8主干网下,与使用加法或级联操作的朴素融合相比,我们的方法取得了显著的性能提升。DroneVehicle Dataset:我们将我们的Fusion - Mamba与11种SOTA方法使用不同的主干进行比较。如表III所示,基于CSPDarknet53v8主干的方法优于SOTA方法1。7 %、3 . 5 %。从更详细的类别来看,我们的模型在Car,Truck,Bus,Van中表现最好,性能提升了1 . 1 %、4 . 3 %、3 . 1 %和2 . 2 %。 虽然我们的模型在Freight _ car类别中表现不佳,但与在该类别中表现良好的模型,如SLBAF - Net 41 和CSOM - ODAF 78 相比,平均检测性能要好得多。特别地,在使用相同的CSPDarknet53v5骨干网络的情况下,我们的模型比SOTA方法提高了1 . 1 %、2 . 8 %。此外,与基于加法和级联的朴素融合方法相比,我们的方法表现出显著的性能提升。在该数据集上的结果从多个角度证明了我们的模型在具有密集标注的航拍图像上的强大检测性能。 此外,与其他融合模块相比,我们的FMB模块更全面地处理了不同模态信息的融合,抑制了更多来自原始模态的伪目标信息。FLIR-Aligned Dataset:为了消除模型参数大小对检测结果的影响,我们选择了几个大参数的单模态和RGB - T检测器进行比较。此外,我们减少了Fusion - Mamba方法中DSSF模块的数量,以生成三个版本的(即: Fusion-Mamba-S , Fusion-Mamba-B , Fusion-Mamba-L),以匹配其他方法的参数大小,从而进行公平的比较。具体而言,Fusion - Mamba - S、Fusion - Mamba - B和Fusion - Mamba - L分别使用了2、4和8个DSSF模块的数量。 注意到Fusion - Mamba - L也被记为Fusion - Mamba作为实验比较的主要模型。如表4所示,与具有大参数体积的单模态检测器相比,我们的方法实现了以可比甚至更少的参数和运行时间获得显著的性能提升。例如,与DDQ - DETR 64 相比,Fusion - Mamba - S节省了54个参数。7 M,运行时间减少55 ms,同时性能提升至少9 . 6 %。对于RGB - T检测器,我们使用与CSPDarkNet53v5相同的主干,我们的模型比CrossFormer 45 的模型性能提高了2。3 % m AP,参数节省95 . 5 %。4 M,运行时间减少19 ms。与DSM - AVD 87 相比,我们的Fusion - Mamba - S达到了相当的参数规模和运行时间,同时将F1、m AP 50和m AP提高了0。6 %、0 . 7 %和0 . 6 %。 当DSSF模块数量进一步增加时,我们的Fusion - Mamba - B和Fusion - Mamba - L模型的性能进一步提升。这些结果表明,我们的方法能够以性能和计算代价之间的最佳折衷来增强融合特征的表示能力。热力图的可视化:为了直观地展示我们模型的高性能,我们从四个实验数据集中各随机选取一副图像对P5进行可视化。热图,并与其他融合方法进行比较。如图5所示,与其他方法相比,我们的模型更专注于目标,而不是分散或专注于不相关的部分。结果表明,与其他特征融合方法相比,我们提出的FMB特征融合模块确实融合得更充分。我们的模型通过隐藏空间融合和门控注意力机制学习更多有用的信息,并抑制原始模态中的伪目标信息。目标检测结果的可视化:为了进一步说明我们模型的高性能,我们从四个实验数据集中各选择了三张成对图像来可视化我们模型和其他融合方法的检测结果。如图所示 6时,我们的Fusion - Mamba减少了误检(橙色椭圆)和漏检(红色椭圆)目标的数量,相比其他方法取得了最好的检测效果。具体来说,我们的模型在低光照、恶劣天气、远距离、密集标注、多视角和严重遮挡的情况下表现得尤为出色。如图6 ( a )所示,我们的模型在低光照条件下检测到更多的行人。在图6 ( b )中,在恶劣的天气条件下,我们检测到了更远距离和模糊的目标。在图6 ( c )中,我们的模型在自上而下的视角下没有丢失标注密集的检测目标。在图6 ( d )中,我们探测到了更严重的被占领目标。然而,其他方法在这种困难的条件下漏检或误检目标较多。 结果表明,我们的模型更好地整合了两种模态的信息,其中RGB信息增强了密集目标的检测,IR信息提高了远距离和遮挡目标的检测。
消融实验
我们在FLIR - Aligned和LLVIP数据集上进行了消融研究,以分别评估SSCS和DSSF模块的有效性。此外,我们还研究了增加SS2D中扫描方向数的影响。在FLIR - Aligned数据集上进行了进一步的分析,以评估FMB位置、DSSF模块数量以及DSSF模块中双重注意力的作用。所有实验均使用CSPDarknet53v8骨干进行。SSCS和DSSF模块的影响:我们在FLIR - Aligned和LLVIP数据集上总结了从FMB中移除SSCS和DSSF模块的结果。当移除SSCS模块(表V中第二行)时,检测器的性能下降了2 . 0 %和0 . 6 %,m AP 50为1 . 1 %、0 . 8 %,在FLIR - Aligned和LLVIP数据集上的m AP分别为0 .这是由于两种模态之间缺乏初始交互和浅层融合,导致后续深度融合阶段特征融合不充分。此外,在没有DSSF模块(表V中第三行)的情况下,单纯的浅层融合无法有效抑制伪目标信息,保证特征交互的全面性。因此,检测器性能下降,下降幅度为2 . 5 %、1 . m AP 50下降0 %,a 2 . 4 %、1 .在FLIR - Aligned和LLVIP数据集上,m AP分别下降了2 %。 当同时移除SSCS和DSSF模块,并通过两个局部模态特征(表V中第四行和第五行)的添加或级联直接获得融合特征时,包括mAP 50、mAP 75和mAP在内的所有评价指标的性能都显著下降。这些结果突出了SSCS和DSSF模块在提高跨模态目标检测性能方面的关键作用。它们证明了在改善特征集成和抑制FMB块内伪目标信息方面的有效性。SS2D中扫描方向数量的影响:为了研究增加扫描方向对特征融合性能的影响,我们引入了四个额外的蛇形扫描方向(如图1所示) 3 ):水平1 (从左上到右下: 1→2→3→6→· · ·→8→9),水平2 (右下至左上: 9→8→7→4→· · ·→2→1),垂直1 (从左上到右下: 1→4→7→8→· · ·→6→9),垂直2 (右下至左上: 9→6→3→2→· · ·→4→1)。实验结果如表6所示,可以看出,在m AP 50、m AP 75和m AP指标下,加入这些额外的扫描方向可以获得与标准4个方向相当的性能。然而,这些附加扫描方向的加入,不仅增加了参数数量,也增加了计算时间。因此,在我们的FusionMamba框架中,我们选择了性能最优的标准四方向扫描通道。
对FMB位置的影响:在工作 14 , 45 的基础上,我们又设置了三个FMB进行特征融合。在这里,我们通过在不同阶段添加FMB来进一步探究FMB位置的影响。我们选择三组多层特征:{ P2,P3,P5 },{ P2,P4,P5 }和{ P3,P4,P5 }进行消融研究,其中Pi是第i阶段使用FMB融合的特征。如表7所示,位置{ P3,P4,P5 }在性能和计算复杂度之间取得了最佳的折衷。因此,我们选择这个位置作为实验的默认位置。对DSSF模块数量的影响:我们在表V中验证了DSSF的有效性。在这里,我们进一步评估了DSSF模块数量的影响,如表VIII所总结的。我们选取了四种DSSF数(即. 2,4,8,16 ),其他模型设置与上述实验一致。我们可以看到,分块数设置为8时,达到了最好的性能。DSSF模块数在8时达到饱和点,说明进一步增加会导致融合性能下降。对DSSF模块双重注意力的影响:为了进一步探究我们的门控机制是否利用DSSF模块的双重注意力的有效性,我们分别去除RGB分支中的IR注意力(即式( 9 )中的zRi · yIRi) ),IR分支中的RGB注意力(即zIRi · yRi在( 10 ) ),以及两者的双重注意力。结果见表IX。去除IR注意或RGB注意,m AP 50下降1 . 6 %或1 . 1 %,分别用于减少两个特征之间的注意交互作用。当两个双注意力都被移除时,DSSF模块变成了VSS块的堆栈,m AP50退化了2 %。值得注意的是,IR和RGB两个注意力分支都与其他分支共享权重,这相当于只添加激活函数和特征添加操作,相比于去除双重注意力。因此,双重注意力的使用对模型参数和运行时间没有显著影响,但显著提高了检测性能。
迁移到跨模态语义分割
为了进一步评估我们的FusionMamba的泛化能力,我们将实验扩展到RGB - IR语义分割任务中。数据集和评价指标:我们选择MSRS 91 数据集,该数据集广泛用于RGB - IR领域的城市场景分割任务。MSRS提供了跨越8个常见对象类别的像素级注释,以及一个额外的未标记类别,使其成为语义分割的一个具有挑战性的基准。我们坚持官方数据拆分,使用1 083张图像对进行训练,361张图像对进行测试。我们使用分割任务中的两个标准度量来评估性能:每个个体类别的交并比( Intersection over Union,IoU )和平均交并比( Mean Intersection over Union,mIoU )。 实现细节:为了将我们的融合框架应用到分割任务中,我们首先将YOLOv8的检测头替换为分割头,并将损失函数修改为( 14 )中的Lseg,λ seg设置为1。5,其他设置与检测任务保持一致。与SOTA方法的比较:我们将我们的融合方法与10种RGB - IR语义分割方法进行比较,如表X所示。我们观察到,与所有其他方法相比,我们的Fusion - Mamba获得了最高的mIoU。例如,我们的Fusion - Mamba使用CSPDarknet53v5和CSPDarknet53v8骨干网络,比LRRNet 90 提高了1 . 0 %、1 . 4 %。对于类别分割,与之前的SOTA结果相比,我们的模型在未标注、Person、Curve、Guardrail和Bump类别上取得了最高的性能,提高了0。4 %、0 . 3 %、4 . 0 %、1 . 4 %、3 . 4 %。 此外,与单模态YOLOv8 - l和基于朴素相加或级联融合的融合方法相比,本文方法的m Io U仍至少提高了8。9 %。
结论
在本文中,我们提出了一种新的Fusion - Mamba框架,结合SSCS和DSSF模块,以促进用于目标检测任务的多模态特征融合。具体来说,SSCS模块通过交换红外和可见光通道特征来实现浅层特征融合。随后,DSSF模块凭借其独特的门控注意力设计,在有效抑制冗余信息的同时,同时增强隐藏状态空间内的特征交互。在四个不同的公开RGB - IR数据集上进行的大量实验表明,与基于Transformer的方法相比,我们的方法取得了更好的检测性能,同时为推理提供了更低的计算成本。 我们的工作突出了Mamba在目标检测任务中推进跨模态融合的潜力。未来,我们计划进一步探索Mamba在跨模态图像融合、跨模态目标跟踪等相关领域的能力,以及跨模态少样本小目标检测等更具挑战性的任务。