文章目录
前言
前面几篇聊了 Kafka 的副本同步、ACK 确认、消费模型这些"数据流转"层面的机制。但有一个更底层的问题一直没展开------消息写到 Broker 之后,到底是怎么存的?存多久?文件怎么组织?什么时候从内存落到磁盘?
这些问题属于 Kafka 的"存储引擎"层面。理解了它们,就能明白为什么 Kafka 的磁盘写入性能能接近内存、为什么过期数据的清理不会影响在线读写、为什么一条消息能被精确定位到文件中的某个字节位置。
本期西瓜带你学Kafka从三个维度拆解 Kafka 的日志存储体系:保留与清理、消息格式、分段与刷新。
一、Kafka 日志存储的 Message 是什么格式
在讲保留和清理之前,先搞清楚 Kafka 到底在存什么。理解了消息的存储格式,后面讲分段和清理时才能知道"删的是什么"、"压缩的是什么"。
整体结构
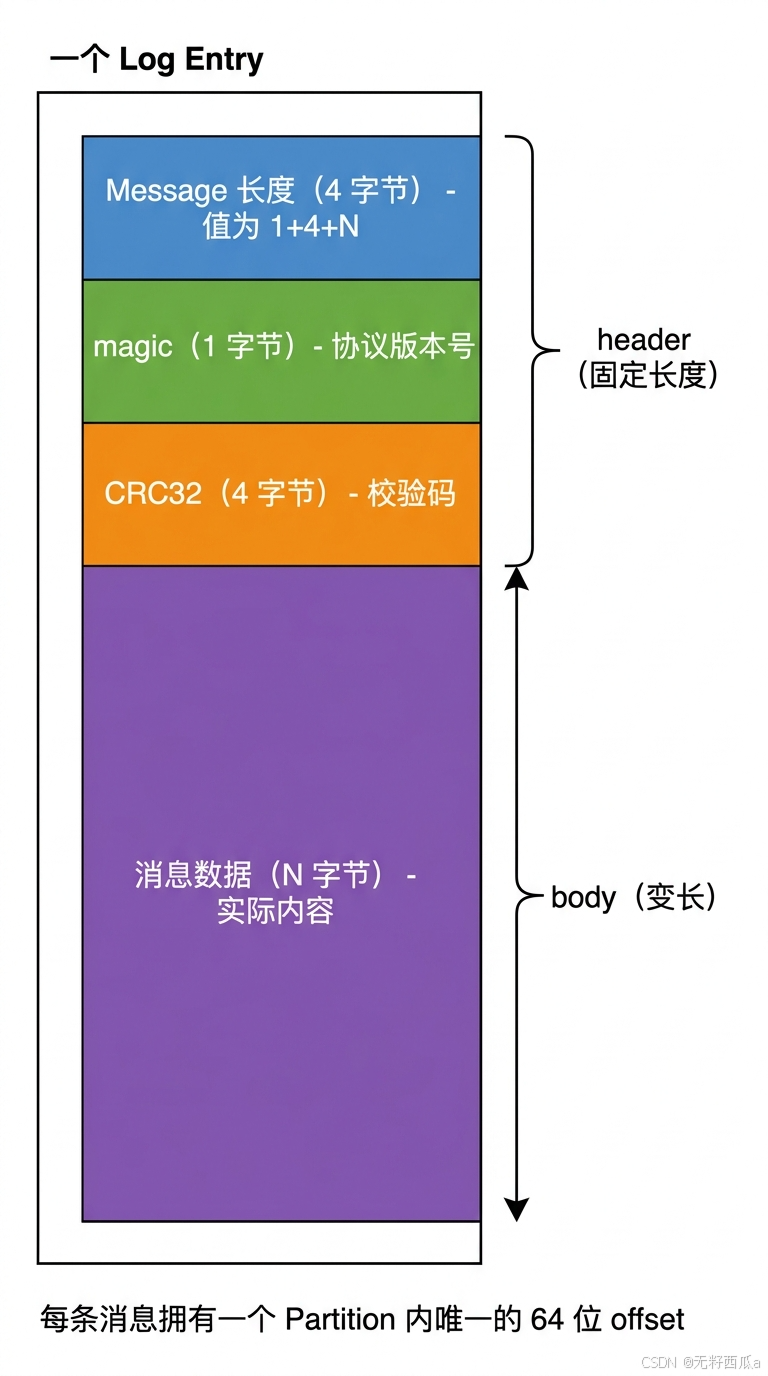
Kafka 一个 Message 由固定长度的 header 和一个变长的消息体 body 组成。
需要注意的是,将 Message 存储在日志时采用的格式不同于 Producer 发送的消息格式。Broker 会对消息做一层封装后再落盘。
每个日志文件的结构
每个日志文件都是一个 log entries(日志项)序列,每一个 log entry 的结构如下:
| 组成部分 | 大小 | 说明 |
|---|---|---|
| Message 长度 | 4 字节(整型) | 值为 1 + 4 + N |
| magic | 1 字节 | 本次发布 Kafka 服务程序协议版本号 |
| CRC32 | 4 字节 | 用于校验 Message 完整性 |
| 消息数据 | N 字节 | 实际的消息内容 |
此外,每条消息都有一个当前 Partition 下唯一的 64 位 offset,这个 offset 是消息在分区中的逻辑位置标识。
消息大小建议
Kafka 没有限定单个消息的大小,但一般推荐消息大小不要超过 1MB ,通常一般消息大小都在 1~10KB 之间。
过大的消息会带来几个问题:
- 增加网络传输延迟
- 影响 Broker 的内存使用效率
- 拖慢副本同步速度
二、Kafka 的日志分段策略与刷新策略
知道了单条消息的格式,接下来看这些消息是怎么组织成文件的,以及什么时候从内存写到磁盘。
日志分段(Segment)策略
一个 Partition 的数据不会全部塞进一个文件,而是按照一定规则切分成多个 Segment 。每个 Segment 由 .index(索引文件)和 .log(数据文件)组成。
触发新 Segment 生成的条件有以下几个,满足任一即触发:
1. 时间维度:log.roll.hours/ms
日志滚动的周期时间。到达指定周期时间时,强制生成一个新的 Segment。
- 默认值:168h(7 天)
2. 大小维度:log.segment.bytes
每个 Segment 的最大容量。到达指定容量时,将强制生成一个新的 Segment。
- 默认值:1GB(-1 代表不限制)
3. 检查周期:log.retention.check.interval.ms
日志段文件检查的周期时间,Kafka 按这个频率去检查是否有 Segment 需要滚动或清理。
- 默认值:60000ms(1 分钟)
日志刷新策略
这是一个容易被忽略但非常重要的机制:Kafka 的日志实际上开始是在缓存中的 ,然后根据实际参数配置的策略定期一批一批写入到日志文件中,以提高吞吐量。
这就是 Kafka 写入性能高的关键原因之一------不是每条消息都立即 fsync 到磁盘,而是利用操作系统的 Page Cache 做缓冲,批量刷盘。
控制刷新行为的参数有三个:
1. log.flush.interval.messages
消息达到多少条时将数据写入到日志文件。
- 默认值:10000 条
2. log.flush.interval.ms
当达到该时间时,强制执行一次 flush。
- 默认值:null(不启用,依赖操作系统自身的刷盘机制)
3. log.flush.scheduler.interval.ms
周期性检查,是否需要将信息 flush。
- 默认值:很大的值(实际上相当于不主动检查,交给前两个条件触发)
分段与刷新的协作关系
消息写入流程:
Producer → Broker 内存(Page Cache)→ 定期 flush → 磁盘上的 Segment 文件
↑
由刷新策略参数控制| 参数 | 维度 | 默认值 | 作用 |
|---|---|---|---|
log.roll.hours |
时间 | 168h | 控制 Segment 滚动周期 |
log.segment.bytes |
大小 | 1GB | 控制单个 Segment 最大容量 |
log.retention.check.interval.ms |
检查频率 | 60000ms | 检查是否需要滚动或清理 |
log.flush.interval.messages |
条数 | 10000 | 累积多少条消息触发刷盘 |
log.flush.interval.ms |
时间 | null | 多久强制刷盘一次 |
log.flush.scheduler.interval.ms |
检查频率 | 很大 | 多久检查一次是否需要刷盘 |
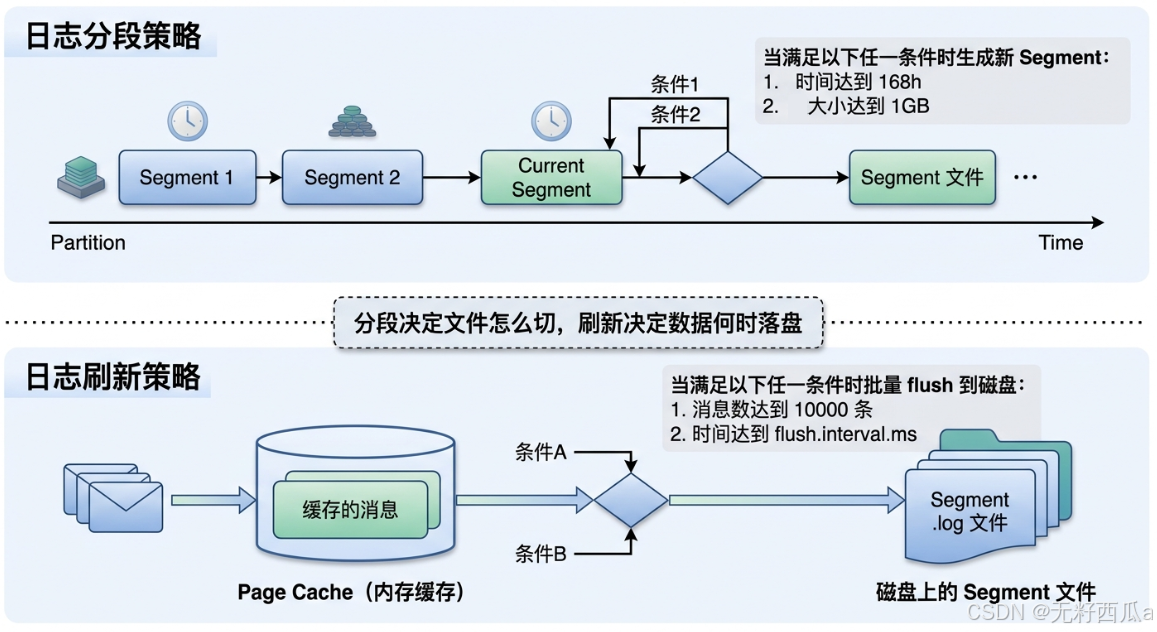
【图片描述词】:流程图分为上下两层。上层标注"日志分段策略",展示一个 Partition 内的多个 Segment 文件按时间线排列,当满足"时间达到 168h"或"大小达到 1GB"任一条件时,箭头指向一个新的 Segment 文件生成。下层标注"日志刷新策略",展示消息先进入"Page Cache(内存缓存)",然后在满足"消息数达到 10000 条"或"时间达到 flush.interval.ms"任一条件时,批量 flush 到磁盘上的 Segment .log 文件。两层之间用虚线连接,标注"分段决定文件怎么切,刷新决定数据何时落盘"。
三、Kafka 的日志保留期与数据清理策略
消息存下来了,文件也切好了,接下来的问题是:这些数据保留多久?过期了怎么处理?
保留期概念
保留期内保留了 Kafka 集群中的所有已发布消息,超过保留期的数据将被按清理策略进行清理。
- 默认保留时间:7 天
- 修改方式 :在
server.properties里更改以下参数的值
properties
# 三个参数优先级从高到低:ms > minutes > hours
log.retention.ms=604800000 # 毫秒级别
log.retention.minutes=10080 # 分钟级别
log.retention.hours=168 # 小时级别(默认 7 天)三个参数同时配置时,粒度越细优先级越高(ms > minutes > hours)。
清理策略一:删除(默认)
properties
log.cleanup.policy=delete表示启用删除策略,这也是默认策略。
删除过程分为两个阶段:
阶段一:标记删除
过期的 Segment 首先被标记为 delete,此时文件还在磁盘上,但无法被索引,Consumer 已经读不到这些数据了。
阶段二:真正删除
只有过了 log.segment.delete.delay.ms 这个参数设置的时间之后,文件才会被真正从磁盘上删除。
这种两阶段设计的好处是:避免在删除文件时影响正在进行的读操作,给系统一个缓冲期。
清理策略二:压缩
properties
log.cleanup.policy=compact表示启用压缩策略。压缩不是 gzip 那种文件压缩,而是数据去重 ------将数据压缩,只保留每个 Key 最后一个版本的数据。
使用前提:首先在 Broker 的配置中设置 log.cleaner.enable=true 启用 cleaner,这个默认是关闭的。
properties
log.cleaner.enable=true # 启用 Log Cleaner
log.cleanup.policy=compact # 启用压缩策略压缩的工作方式
假设一个 Key 先后写入了三个值:
Key=user_001, Value=v1 (offset=0)
Key=user_001, Value=v2 (offset=5)
Key=user_001, Value=v3 (offset=12)压缩后只保留:
Key=user_001, Value=v3 (offset=12)适用场景:数据库变更日志(CDC)、用户状态快照等只关心最新状态的场景。
两种策略对比
| 特性 | 删除策略(delete) | 压缩策略(compact) |
|---|---|---|
| 默认启用 | 是 | 否 |
| 清理依据 | 时间或大小 | Key 的版本 |
| 数据保留 | 过期全部删除 | 每个 Key 保留最新值 |
| 需要额外配置 | 不需要 | 需启用 log.cleaner.enable |
| 适用场景 | 常规消息、日志 | CDC、状态快照 |
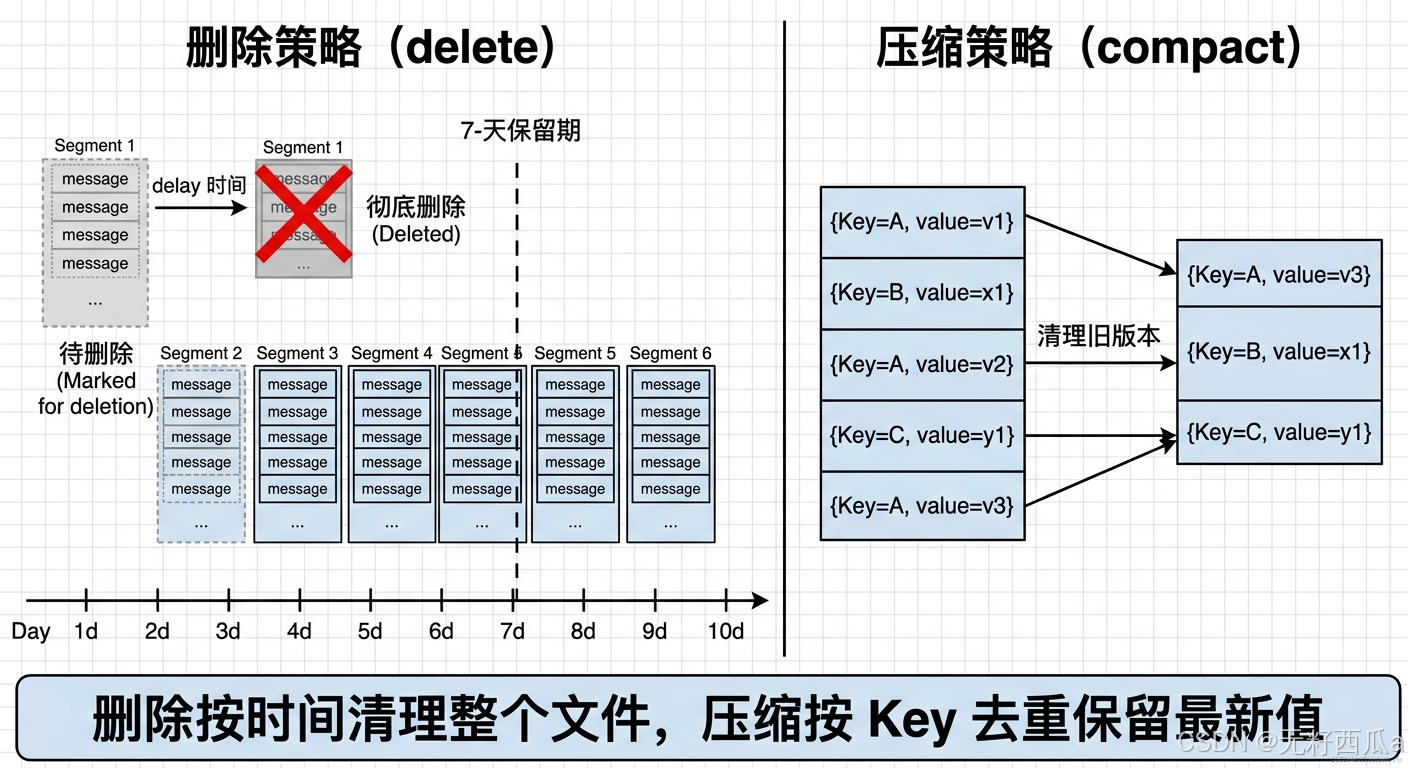
【图片描述词】:左右对比图。左侧标注"删除策略(delete)",展示一个时间轴上的多个 Segment 文件,超过 7 天保留期的 Segment 先被标记为"delete"(灰色虚线框),经过 delay 时间后被彻底删除(红色叉号)。右侧标注"压缩策略(compact)",展示一个 Segment 内有多条消息,其中 Key=A 出现了 3 次(v1、v2、v3),压缩后只保留 Key=A 的 v3(最新版本),旧版本被清除。底部标注"删除按时间清理整个文件,压缩按 Key 去重保留最新值"。
总结
- 消息格式:每条 Message 由 4 字节长度 + 1 字节 magic + 4 字节 CRC32 + N 字节数据组成,每条消息拥有 Partition 内唯一的 64 位 offset
- 分段与刷新:Segment 按时间(7 天)或大小(1GB)滚动切分,消息先写入 Page Cache 再按策略批量刷盘,这是 Kafka 高吞吐的关键
- 保留与清理:默认保留 7 天,删除策略按时间清理整个 Segment 文件(两阶段:标记 → 真删),压缩策略按 Key 去重只保留最新值
这三个机制从微观到宏观构成了完整的存储链路:消息格式决定了"怎么存一条",分段策略决定了"怎么组织成文件",刷新策略决定了"什么时候落盘",保留与清理策略决定了"什么时候删"。