目录
- 前言
- 一、先编译,后解释
- [二、模块对象:.py 文件的 "属性容器"](#二、模块对象:.py 文件的 “属性容器”)
- 三、包的加载
- 三、类对象与实例对象:属性的分层存储
- [四、Python 内存管理的核心原则](#四、Python 内存管理的核心原则)
- 五、总结
前言
这篇博客从内存布局、对象存储、属性管理三个核心维度,总结汇总 Python 的底层内存模型和运行机制
一、先编译,后解释
Python 既非纯编译型也非纯解释型语言,其运行流程可概括为:
python
源代码(.py) → 编译生成字节码(.pyc) → Python虚拟机(PVM)解释执行字节码 → 与操作系统交互- 编译阶段:解释器将源代码转为字节码(中间代码),并缓存到__pycache__目录,重复运行时直接加载字节码提升效率;
- 执行阶段:Python 虚拟机(PVM)逐行解释字节码,翻译成机器指令执行;
- 核心特性:CPython 的 GIL(全局解释器锁)限制同一时刻仅一个线程执行字节码,这也是 Python 多线程在 CPU 密集型任务中效率不高的核心原因。
Python 无 Java 式严格的 "堆、栈、方法区" 物理划分,但从开发者视角可简化为两大核心区域:
| 区域 | 核心作用 | 存储内容 |
|---|---|---|
| 栈帧区 | 临时存储函数调用上下文 | 局部变量、参数的引用(地址) |
| 堆区 | 存储所有实际数据 | 所有对象(实例、类、模块、函数等) |
二、模块对象:.py 文件的 "属性容器"
当我们导入模块或运行.py文件时,Python 解释器会为该文件创建一个模块对象****(module 类型实例),这是模块级内容的核心载体。
- 模块对象的核心特性
- 创建时机 :import模块或运行脚本时自动创建,创建后缓存到sys.modules(字典,key 为模块名,value 为模块对象的引用地址);
- 存储内容 :模块的__dict__属性是其核心,等价于全局命名空间(globals()返回的就是该字典),包含:
- 自定义内容:全局变量、类、函数;
- 内置属性:file (文件路径)、name(模块名)等;
- 特殊场景:直接运行的脚本会被命名为__main__模块,这也是if name == "main"的底层逻辑。
- __file__指向文件路径
__file__并非代码 "查找" 的结果,而是解释器在创建模块对象时,主动将文件路径赋值给模块对象的内置属性 ------ 它是模块对象的 "路径标签",而非运行时动态查找的结果。
三、包的加载
- python在加载模块时,会先加载模块所在的包,当包第一次被导入时,Python 会执行
__init__.py中的所有代码,可以在这里做初始化操作(比如加载配置、初始化常量、检查依赖等) - 当我们执行 import my_package 或 from my_package import utils 时,Python 会按以下步骤把包 / 模块加载成模块对象(Module Object)
- 查找模块 / 包的路径,从sys.path中查找包
- 执行其中的
__init__.py代码,将该包内的__init__.py模块(python文件)构建模块对象,把__init__.py中定义的变量、导入的对象作为__init__.py模块对象的属性(__dict__字典中)
三、类对象与实例对象:属性的分层存储
类和实例对象是 Python 面向对象的核心,二者的属性存储遵循 "分层管理" 原则,核心载体仍是__dict__字典(堆区存储)。
- 类对象:方法与类属性的 "仓库"
- 存储逻辑:类对象(如class Person:定义的Person)作为模块对象的属性存在,其__dict__存储:
- 类属性(如species = "Human");
- 方法(本质是函数对象,如say_hello);
- 继承特性:类属性查找会逐层向上遍历父类的__dict__(如Person继承object,会查找object.dict)。
- 实例对象:独有属性的 "专属空间"
- 存储逻辑:实例(如p = Person())存在堆区,每个实例有独立的__dict__,仅存储实例独有属性(如self.name);
- 属性查找优先级:实例访问属性时,先查自身__dict__ → 查类对象__dict__ → 查父类__dict__ → 抛出AttributeError;
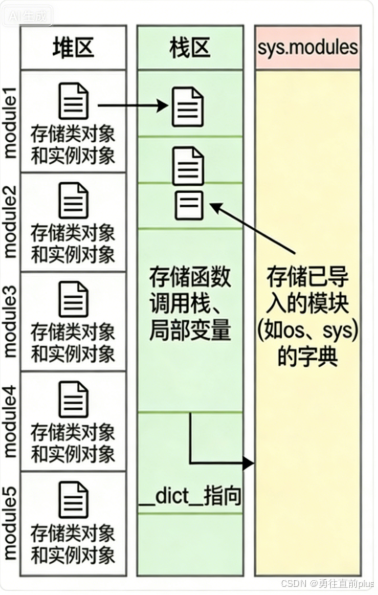
- sys.module 是堆区的一块缓冲区,是个字典,存储所有module对象,key是模块名、value是module对象的引用地址
- 每一个module对象也是通过__dict__ 字典存储着该模块的所有全局变量、类对象、实例对象,key: 属性名(类名、对象名、方法名),value:类、对象、方法的引用地址
- sys.modules 本身是堆区的字典对象,地址固定;类对象、实例对象、模块对象的__dict__也是通过起始地址的固定偏移量计算出来的。
- 编译完模块文件后,先在堆区分配地址,创建存储当前模块的模块对象,初始化其核心属性(dict , file ,name),然后将创建的当前模块对象地址存储到 sys.module 字典缓冲区中,然后解释器会将当前模块地址存储到一个全局的 "模块上下文" (模块执行帧,非栈帧),这个模块上下文会贯穿程序执行的始终,程序会实时从这个模块执行帧中拿到最近的模块对象地址。
四、Python 内存管理的核心原则
- 引用为王:Python 中所有变量赋值、属性存储都是 "引用传递"(存地址),而非 "值传递"(存数据);
- 垃圾回收:堆区对象的生命周期由 "引用计数" 主导(计数为 0 则回收),分代回收补充处理循环引用;
- 分层查找:属性访问遵循 "实例→类→父类" 的优先级,模块对象的__dict__是全局命名空间的核心;
- 缓存优化:小整数(-5~256)、短字符串等常驻 "只读数据区"(堆区子集),全局共享避免重复创建。
五、总结
Python 的内存模型可概括为 "两区域、三对象、一核心":
- 两区域:栈帧区存引用,堆区存所有对象;
- 三对象:模块对象管理文件级内容,类对象管理方法和类属性,实例对象管理独有属性;
- 一核心:所有对象的属性都基于__dict__字典(或优化数组)存储,核心逻辑是 "引用 + 分层查找"。