ElasticStack学习笔记完整版
📅 今日内容预告
- ElasticStack架构设计
- ElasticSearch单点部署
- ES集群常用术语
- ElasticSearch集群部署
- ElasticSearch的DSL语句初体验
- kibana环境部署
- kibana的基本使用
- filebeat环境部署
🏗️ ElasticStack架构设计
1. 什么是ElasticStack
以前业界有一个比较出名的词:ELK
- E: ElasticSearch - 数据存储,简称:es
- L: Logstash - 数据采集,处理
- K: Kibana - 数据展示,可视化
2. 扩展组件
- Beats系列 :
- Filebeat (文本日志采集)
- Metricbeat
- Heartbeat
- XPack : 安全相关的工具包
- 从此ELK Stack,更名为ElasticStack
3. 架构流程
filebeat 负责数据的采集,logstash进行数据的处理,elasticsearch集群负责数据的存储和检索,最后kibana负责数据可视化
4. 工作小技巧
alt + f1 或 f2 机房,alt 1 或 2 xshell可以来回切换窗口
🔧 ElasticSearch单点部署
1. 下载ElasticSearch软件包
bash
[root@elk91 ~]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.29-amd64.deb
# 或(线下)
[root@elk91 ~]# wget http://192.168.16.253/Resources/ElasticStack/softwares/ES7/7.17.29/elasticsearch-7.17.29-amd64.deb注意: 下载后要查看文件大小是否正确
bash
[root@elk91 ~]# ll elasticsearch-7.17.29-amd64.deb
-rw-r--r-- 1 root root 325488012 Aug 27 10:11 elasticsearch-7.17.29-amd64.deb2. 安装ElasticSearch
bash
[root@elk91 ~]# dpkg -i elasticsearch-7.17.29-amd64.deb 3. 修改配置文件
bash
[root@elk91 ~]# egrep -v "^#|^$" /etc/elasticsearch/elasticsearch.yml
cluster.name: oldboyedu-linux99-single
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0 # 监听当前节点的所有ip地址
http.port: 9200
discovery.type: single-node # 这个参数也改一下单点的相关参数说明:
cluster.name: 指定集群的名称path.data: 数据存储路径path.logs: 日志存储路径network.host: 监听的IP地址http.port: 监听的端口discovery.type: 指定工作模式
4. 启动ES服务
bash
[root@elk91 ~]# systemctl enable --now elasticsearch
[root@elk91 ~]# ss -lntup | egrep "92|300"
LISTEN 0 4096 *:9300 *:*
LISTEN 0 4096 *:9200 *:* 5. 访问测试
bash
[root@elk92 ~]# curl 10.0.0.91:9200
{
"name" : "elk91",
"cluster_name" : "oldboyedu-linux99-single",
"cluster_uuid" : "F6SwEY9KQZq9VRpsCVbviw",
"version" : {
"number" : "7.17.29",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "580aff1a0064ce4c93293aaab6fcc55e22c10d1c",
"build_date" : "2025-06-19T01:37:57.847711500Z",
"build_snapshot" : false,
"lucene_version" : "8.11.3",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
bash
[root@elk92 ~]# curl 10.0.0.91:9200/_cat/nodes
10.0.0.91 5 97 5 0.10 0.13 0.05 cdfhilmrstw * elk91
[root@elk92 ~]# curl 10.0.0.91:9200/_cat/nodes?v # 可以把表头信息给你显示出来
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.0.0.91 5 97 0 0.09 0.13 0.05 cdfhilmrstw * elk91🖥️ ElasticSearch集群部署
1. 准备安装包
bash
[root@elk91 ~]# scp elasticsearch-7.17.29-amd64.deb 10.0.0.92:~
[root@elk91 ~]# scp elasticsearch-7.17.29-amd64.deb 10.0.0.93:~2. 所有节点安装ES
bash
[root@elk92 ~]# dpkg -i elasticsearch-7.17.29-amd64.deb
[root@elk93 ~]# dpkg -i elasticsearch-7.17.29-amd64.deb 3. 修改配置文件
bash
[root@elk91 ~]# egrep -v "^#|^$" /etc/elasticsearch/elasticsearch.yml
cluster.name: oldboyedu-linux99-cluster
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["10.0.0.91", "10.0.0.92","10.0.0.93"]
cluster.initial_master_nodes: ["10.0.0.91", "10.0.0.92","10.0.0.93"]相关参数说明:
discovery.seed_hosts: 指定ES集群服务发现列表cluster.initial_master_nodes: 指定ES初始化时的master节点
4. 重置单点配置
bash
[root@elk91 ~]# systemctl stop elasticsearch.service
[root@elk91 ~]# ss -ntl| grep 9200
[root@elk91 ~]# rm -rf /var/{log,lib}/elasticsearch/* # 把刚才的数据做一个清理(单点清理)
[root@elk91 ~]# ll /var/{log,lib}/elasticsearch/
/var/lib/elasticsearch/:
total 8
drwxr-s--- 2 elasticsearch elasticsearch 4096 Aug 27 11:02 ./
drwxr-xr-x 61 root root 4096 Aug 27 10:13 ../
/var/log/elasticsearch/:
total 8
drwxr-s--- 2 elasticsearch elasticsearch 4096 Aug 27 11:02 ./
drwxrwxr-x 10 root syslog 4096 Aug 27 10:13 ../5. 同步配置文件
bash
[root@elk91 ~]# scp /etc/elasticsearch/elasticsearch.yml 10.0.0.92:/etc/elasticsearch/
[root@elk91 ~]# scp /etc/elasticsearch/elasticsearch.yml 10.0.0.93:/etc/elasticsearch/6. 重启ES集群(三个节点都执行)
bash
[root@elk91 ~]# systemctl enable --now elasticsearch
[root@elk91 ~]# ss -ntl | egrep "9200|9300"
LISTEN 0 4096 *:9300 *:*
LISTEN 0 4096 *:9200 *:*
[root@elk92 ~]# systemctl enable --now elasticsearch
[root@elk92 ~]# ss -ntl | egrep "9200|9300"
LISTEN 0 4096 *:9300 *:*
LISTEN 0 4096 *:9200 *:*
[root@elk93 ~]# systemctl enable --now elasticsearch
[root@elk93 ~]# ss -ntl | egrep "9200|9300"
LISTEN 0 4096 *:9200 *:*
LISTEN 0 4096 *:9300 *:* 7. 验证集群状态
bash
[root@elk91 ~]# curl 10.0.0.93:9200/_cat/nodes
10.0.0.92 5 97 9 0.25 0.15 0.06 cdfhilmrstw - elk92
10.0.0.93 22 97 8 0.24 0.12 0.04 cdfhilmrstw - elk93
10.0.0.91 8 91 10 0.17 0.10 0.04 cdfhilmrstw * elk91💡 核心概念理解
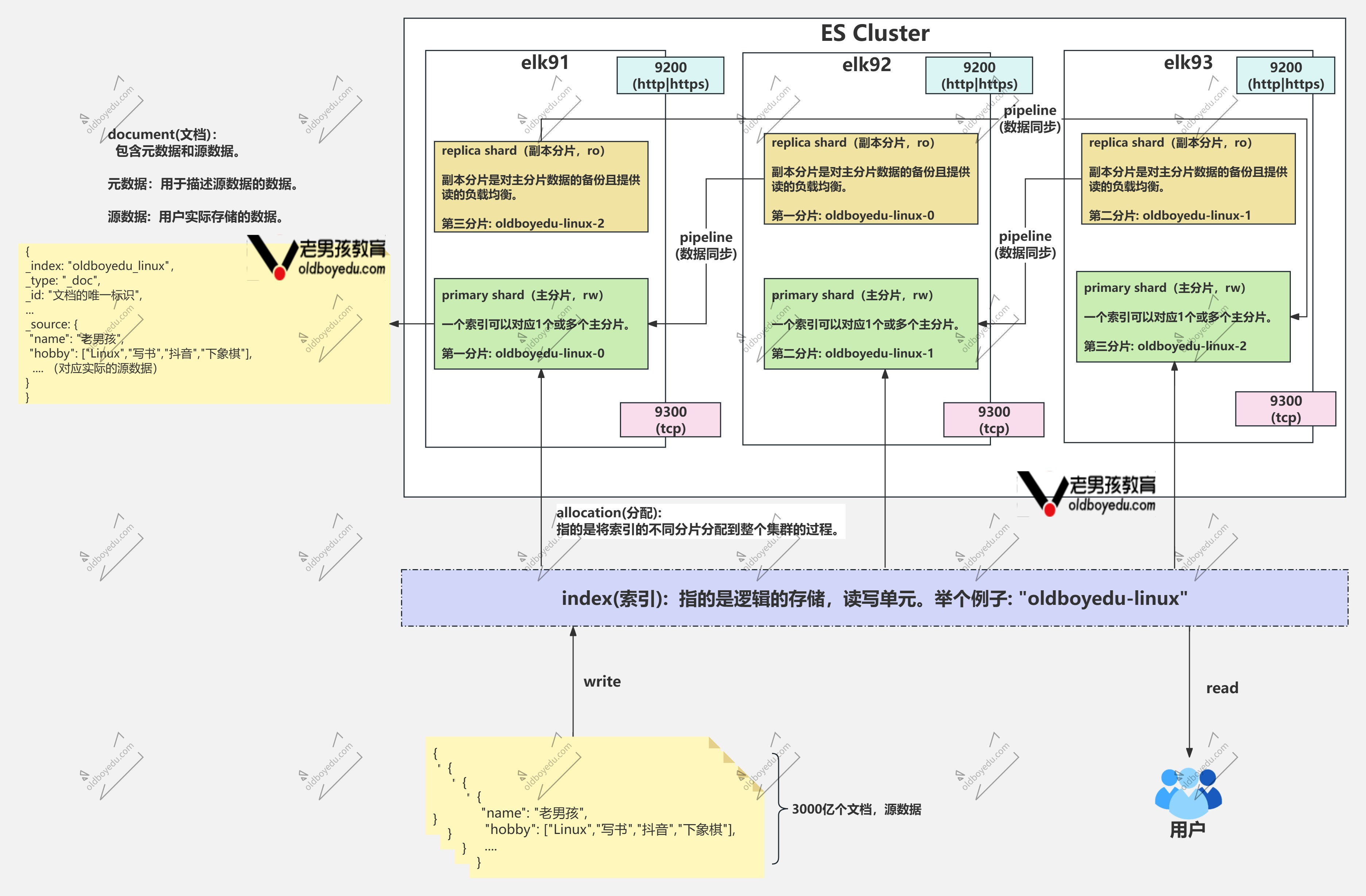
用户层面 vs 运维层面
- 用户层面: 写往索引写,读往索引读
- 运维层面: 索引存的时候分片,分成多份到不同节点,使得存储资源可以得到利用
分片与副本规则
- 每个分片对应一个副本
- 主分片和它的副本不能在同一个节点
- 副本分片给主分片进行备份且实现负载均衡
- 主分片可以读写
集群存活规则
- 集群半数以上才能存活
- 3个最少有两个才能存活
- 生产环境要使用奇数台
- nfs和mysql都是单个节点存储
❓ 面试题
1. ES集群的9200端口和9300端口使用的协议和作用?
- 9200: 使用http或者https协议,对外部用户暴露的端口
- 9300: ES集群数据同步及选举的端口,使用tcp协议
温馨提示: 内部数据同步之后才给用户提供服务呢,9300优于9200端口启动
2. ES集群的颜色分别代表什么含义?
- red: 红色
- 代表有部分主分片无法访问
- 一般情况下不会出现,如果数据量较大时启动时可能会短暂出现
- yellow: 黄色
- 代表有部分副本分片无法访问
- 处于亚健康状态
- green: 绿色
- 代表所有的主分片和副本分片均可以正常访问
📖 ES集群常用术语
索引: index
ES集群数据存储的逻辑单元。对于客户端而言可以进行数据的读写。
分片: shard
一个索引对应一个或多个分片。当该索引的分片数量大于1时,意味着数据可以实现分布式存储。
副本: replica
一个分片可以有0个或多个副本。当分片的数量大于等于1时,就可以对分片进行数据备份。
注意: 副本分片和主分片的数据不能在同一个节点上,主分片负责数据的读写,而副本分片负责备份主分片,且可以负责读的负载均衡。
文档
分片和副本存储的都是文档,文档是用户存储的数据实际载体。
文档分为元数据和源数据:
- 源数据: 指的是用户的实际数据
- 元数据: 是用来描述源数据的数据,比如该文档术语哪个索引,文档的唯一编号等信息
🛠️ ElasticSearch的DSL语句初体验
1. 写入数据
bash
curl --location --request POST 'http://10.0.0.91:9200/_bulk' \
--header 'Content-Type: application/json' \
--data-raw '{ "create" : { "_index" : "oldboyedu-linux99", "_id" : "1001" } }
{ "name" : "猪八戒","hobby": ["猴哥","高老庄"] }
{ "create" : { "_index" : "oldboyedu-linux99", "_id" : "1002" } }
{ "name" : "沙和尚","hobby": ["流沙河","挑行李"] }
{ "create" : { "_index" : "oldboyedu-linux99", "_id" : "1003" } }
{ "name" : "白龙马","hobby": ["大师兄,师傅被妖怪抓走啦"] }
'2. 查询指定文档id的数据
bash
[root@elk93 ~]# apt -y install jq
[root@elk93 ~]# curl -s --location --request GET '10.0.0.93:9200/oldboyedu-linux99/_doc/1003' | jq
{
"_index": "oldboyedu-linux99",
"_type": "_doc",
"_id": "1003",
"_version": 1,
"_seq_no": 2,
"_primary_term": 1,
"found": true,
"_source": {
"name": "白龙马",
"hobby": [
"大师兄,师傅被妖怪抓走啦"
]
}
}
bash
[root@elk93 ~]# curl --location --request GET '10.0.0.93:9200/oldboyedu-linux99/_search' \
--header 'Content-Type: application/json' \
--data-raw '{
"query": {
"match": {
"hobby": "猴哥"
}
}
}'3. 查看所有数据
bash
[root@elk93 ~]# curl -s --location --request GET '10.0.0.93:9200/oldboyedu-linux99/_search' | jq
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "oldboyedu-linux99",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"name": "猪八戒",
"hobby": [
"猴哥",
"高老庄"
]
}
},
{
"_index": "oldboyedu-linux99",
"_type": "_doc",
"_id": "1002",
"_score": 1,
"_source": {
"name": "沙和尚",
"hobby": [
"流沙河",
"挑行李"
]
}
},
{
"_index": "oldboyedu-linux99",
"_type": "_doc",
"_id": "1003",
"_score": 1,
"_source": {
"name": "白龙马",
"hobby": [
"大师兄,师傅被妖怪抓走啦"
]
}
}
]
}
}4. 删除数据
bash
[root@elk93 ~]# curl -s --location --request DELETE '10.0.0.93:9200/oldboyedu-linux99/_doc/1003' | jq
{
"_index": "oldboyedu-linux99",
"_type": "_doc",
"_id": "1003",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}🎨 kibana环境部署(负责数据的查询)
1. kibana下载
bash
[root@elk91 ~]# wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.29-amd64.deb
# 或(线下)
[root@elk91 ~]# wget http://192.168.16.253/Resources/ElasticStack/softwares/ES7/7.17.29/kibana-7.17.29-amd64.deb2. 安装kibana(只需安装在一个节点即可)
bash
[root@elk91 ~]# dpkg -i kibana-7.17.29-amd64.deb3. 修改kibana的配置文件
bash
[root@elk91 ~]# egrep -v "^#|^$" /etc/kibana/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://10.0.0.91:9200","http://10.0.0.92:9200","http://10.0.0.93:9200"]
i18n.locale: "zh-CN"相关参数说明:
server.port: 服务监听的端口server.host: 服务监听的地址elasticsearch.hosts: kibana管理ES集群的地址i18n.locale: kibana的语言
4. 启动kibana服务
bash
[root@elk91 ~]# systemctl enable --now kibana.service
[root@elk91 ~]# ss -ntl | grep 5601
LISTEN 0 511 0.0.0.0:5601 0.0.0.0:* 5. 访问测试
http://10.0.0.91:5601/访问流程:
- 选择自己浏览
- 菜单栏 → Management → Stack Management
- 索引管理 → 索引模式 → 创建索引模式
- 名称
oldboyedu-*→ 创建 - 菜单栏点击 Discover 即可看到数据
📁 filebeat环境部署
1. 下载Filebeat软件包
bash
[root@elk92 ~]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.17.29-amd64.deb
# 或(线下)
[root@elk92 ~]# wget http://192.168.16.253/Resources/ElasticStack/softwares/ES7/7.17.29/filebeat-7.17.29-amd64.deb2. 安装Filebeat
bash
[root@elk92 ~]# dpkg -i filebeat-7.17.29-amd64.deb 3. 修改Filebeat的配置文件
bash
[root@elk92 ~]# mkdir /etc/filebeat/config
[root@elk92 ~]# cat /etc/filebeat/config/01-stdin-to-console.yaml
filebeat.inputs:
- type: stdin
output.console:
pretty: true意思就是标准输入然后标准输出到终端
4. 启动Filebeat程序
bash
[root@elk92 ~]# filebeat -e -c /etc/filebeat/config/01-stdin-to-console.yaml5. 发送测试数据(关注message字段即可)
www.oldboyedu.com # 输入端的数据输出结果:
json
{
"@timestamp": "2025-08-27T07:14:58.722Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "7.17.29"
},
"log": {
"offset": 0,
"file": {
"path": ""
}
},
"message": "www.oldboyedu.com", # 采集到的输入端数据
"input": {
"type": "stdin"
},
"host": {
"name": "elk92"
},
"agent": {
"type": "filebeat",
"version": "7.17.29",
"hostname": "elk92",
"ephemeral_id": "19e67462-eaf5-4fc0-b1c2-a654fdbb4bf5",
"id": "42b53045-d902-4194-a915-da66ad26335a",
"name": "elk92"
},
"ecs": {
"version": "1.12.0"
}
}即可到时候实现日志采集,然后给elastic集群,然后kibana进行分析
首页文档: https://www.elastic.co/guide/index.html
🚀 EFK架构实战案例
filebeat实现日志采集,然后给elastic集群,然后kibana进行分析
1. 编写配置文件
bash
[root@elk92 ~]# cat /etc/filebeat/config/02-tcp-to-es.yaml
filebeat.inputs:
- type: tcp
host: "0.0.0.0:9000"
#output.console:
# pretty: true
# 将数据写入到ES集群
output.elasticsearch:
# 指定ES集群地址
hosts: ["http://10.0.0.91:9200","http://10.0.0.92:9200","http://10.0.0.93:9200"]
# 指定ES的索引名称
index: oldboyedu-filebeat-tcp-xixi
# 禁用索引的生命周期,否则自定义索引名称无效
setup.ilm.enabled: false
# 定义索引模板
setup.template.name: "oldboyedu-filebeat-tcp"
# 定义索引模板的匹配模式
setup.template.pattern: "oldboyedu-filebeat-tcp*"
# 如果索引模板已经存在是否覆盖
setup.template.overwrite: false
# 配置索引模板
setup.template.settings:
# 指定分片数量
index.number_of_shards: 3
# 指定副本数量
index.number_of_replicas: 02. 启动Filebeat实例
bash
[root@elk92 ~]# filebeat -e -c /etc/filebeat/config/02-tcp-to-es.yaml3. 发送测试数据
bash
[root@elk93 ~]# echo www.oldboyedu.com | nc 10.0.0.92 9000发送数据之后:
- 可以回到elastic网站查看到更新
- 然后创建对应的索引模式
- 查看对应的数据discover
数据流向:93节点发给92,92 filebeat去监听,发到elastic当中,kibana查看
可以玩一下,做虚拟网络编辑器的NAT设置,添加映射
📝 今日内容回顾
- ElasticStack架构组成部分:elasticsearch数据存储,kibana数据展示,filebeat数据采集处理
- elasticsearch单点部署
- elasticsearch集群部署
- kibana环境部署
- Filebeat环境部署
- EFK架构数据流走向
📋 今日作业
基础作业:
- 完成课堂的所有练习并整理思维导图
- 使用麒麟系统部署EFK架构
扩展作业:
- 使用ansible一键部署EFK架构:试一试
- 完成Windows科学上网功能,测试站点: