前言
在生产环境中,微服务日志分散在各个服务器上,排查问题需要登录多台机器,效率极低。本文将带你从零开始,搭建一套完整的应用日志 → Kafka → ELK 日志收集管道,实现日志的集中存储、实时搜索与可视化。你将学会:
-
安装配置 Elasticsearch、Kibana、Logstash、Kafka
-
Spring Boot 应用通过 Logback 直连 Kafka 发送 JSON 格式日志
-
Logstash 消费 Kafka 并按日志级别分流写入 Elasticsearch
-
Kibana 中创建数据视图,快速检索日志
最终效果:所有业务日志实时进入 Elasticsearch,可在 Kibana 中秒级搜索。
一、环境准备
1.1 组件版本
为保证兼容性,统一使用 9.3.2 版本(Elastic Stack 各组件版本需一致,Kafka 使用 2.13-3.5.0 或更高)。
| 组件 | 版本 | 端口 |
|---|---|---|
| Elasticsearch | 9.3.2 | 9200 |
| Kibana | 9.3.2 | 5601 |
| Logstash | 9.3.2 | 9600 (API) |
| Kafka | 3.5.0 | 9092 |
| Zookeeper | 3.8.0 | 2181 |
| Spring Boot | 3.5.13 | 8080 |
1.2 下载地址
Elasticsearch 9.3.2
-
Windows ZIP: https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-9.3.2-windows-x86_64.zip
-
Linux tar.gz: https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-9.3.2-linux-x86_64.tar.gz
Kibana 9.3.2
-
Windows ZIP: https://artifacts.elastic.co/downloads/kibana/kibana-9.3.2-windows-x86_64.zip
-
Linux tar.gz: https://artifacts.elastic.co/downloads/kibana/kibana-9.3.2-linux-x86_64.tar.gz
Logstash 9.3.2
-
Windows ZIP: https://artifacts.elastic.co/downloads/logstash/logstash-9.3.2-windows-x86_64.zip
-
Linux tar.gz: https://artifacts.elastic.co/downloads/logstash/logstash-9.3.2-linux-x86_64.tar.gz
Kafka (Scala 2.13) 3.5.0
注:Kafka 依赖 Zookeeper,安装包自带 Zookeeper 启动脚本。
二、安装与启动
2.1 启动 Elasticsearch
解压后进入 bin 目录:
bash
# Windows
elasticsearch.bat
# Linux
./elasticsearch -d验证:访问 http://localhost:9200,应返回 JSON 信息(含版本号)。
2.2 启动 Kibana
解压后修改 config/kibana.yml(关键配置):
bash
server.port: 5601
server.host: "localhost"
elasticsearch.hosts: ["http://localhost:9200"]
elasticsearch.username: "elastic"
elasticsearch.password: "root123" # 如果你设置了密码启动:
bash
# Windows
kibana.bat
# Linux
./kibana &访问 http://localhost:5601 验证。
2.3 启动 Kafka (含 Zookeeper)
解压 Kafka 后,进入根目录:
bash
# 启动 Zookeeper
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
# 启动 Kafka
bin/kafka-server-start.sh -daemon config/server.properties验证:netstat -tulnp | grep 9092 应看到监听。
2.4 启动 Logstash
解压后创建配置文件(见下文),启动:
bash
bin/logstash -f config/logstash-kafka.conf三、Spring Boot 应用配置
3.1 添加依赖
pom.xml 中加入:
XML
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- Logback Kafka Appender -->
<dependency>
<groupId>com.github.danielwegener</groupId>
<artifactId>logback-kafka-appender</artifactId>
<version>0.2.0</version>
</dependency>
<!-- 0.2.0不可用替代 -->
<dependency>
<groupId>com.github.danielwegener</groupId>
<artifactId>logback-kafka-appender</artifactId>
<version>0.2.0-RC2</version>
</dependency>如果 Maven 下载失败,可手动安装:
-
下载 jar 和 pom 从 中央仓库
-
执行
mvn install:install-file -Dfile=xxx.jar -DpomFile=xxx.pom
3.2 配置 application.yml
bash
spring:
elasticsearch:
uris: http://localhost:9200
# 如果需要认证,取消注释下面两行
username: elastic
password: root123
kafka:
bootstrap-servers: 192.168.194.147:9092 # 使用你服务器的实际IP
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: my-group # 消费者组ID,随意命名
auto-offset-reset: earliest # 从最早的消息开始消费
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer3.3 配置 logback-spring.xml
放在 src/main/resources 下,完整内容:
XML
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 控制台输出(供调试) -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<!-- Kafka Appender(异步发送 JSON 日志) -->
<appender name="KAFKA" class="com.github.danielwegener.logback.kafka.KafkaAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<pattern>{"timestamp":"%d{yyyy-MM-dd'T'HH:mm:ss.SSSZZ}","level":"%level","thread":"%thread","logger":"%logger","message":"%msg","exception":"%ex{short}"}%n</pattern>
</encoder>
<topic>app-logs</topic>
<keyingStrategy class="com.github.danielwegener.logback.kafka.keying.NoKeyKeyingStrategy"/>
<deliveryStrategy class="com.github.danielwegener.logback.kafka.delivery.AsynchronousDeliveryStrategy"/>
<producerConfig>bootstrap.servers=192.168.194.147:9092</producerConfig>
<producerConfig>acks=0</producerConfig>
<producerConfig>linger.ms=100</producerConfig>
<producerConfig>max.block.ms=0</producerConfig>
</appender>
<!-- 关键:避免 Kafka 客户端日志进入 Kafka Appender 造成循环 -->
<logger name="org.apache.kafka" level="WARN" additivity="false">
<appender-ref ref="CONSOLE"/>
</logger>
<root level="INFO">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="KAFKA"/>
</root>
</configuration>注意 :将 bootstrap.servers 改为你的 Kafka 实际 IP。
3.4 测试代码
创建一个简单的 Test ,测试代码没必要保持一致主要实现的是日志log.info、log.error
触发日志输出:
java
@SpringBootTest
public class KafkaTests {
@Autowired
private KafkaProducer kafkaProducer;
@Test
public void testKafkaProducer() throws InterruptedException {
for (int i = 0; i < 10; i++) {
String text="afkaProducer Test Message ";
if (i == 5) {
text="fail message";
}
kafkaProducer.sendKafkaMessage("test-topic", String.valueOf(i), text + i);
}
Thread.sleep(5000);
}
}
java
@Slf4j
@Component
@RequiredArgsConstructor
public class KafkaProducer {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
//生产者
public void sendKafkaMessage(String topic, String key, String message) {
kafkaTemplate.send(topic, key, message);
log.info("发送Kafka消息: topic={}, key={}, message={}", topic, key, message);
}
//消费者 业务1
@KafkaListener(topics = "test-topic", groupId = "test1-key")
public void listenKafkaTest1Message(String message) {
if (message.contains("fail")) {
log.error("收到Kafka消息: test1 -> {}", message);
} else{
log.info("收到Kafka消息: test1 -> {}", message);
}
}
//消费者 业务2
@KafkaListener(topics = "test-topic", groupId = "test2-key")
public void listenKafkaTest2Message(String message) {
log.info("收到Kafka消息: test2 -> {}", message);
}
}启动 Spring Boot 应用。
四、Logstash 配置
在 Logstash 的 config 目录下创建 logstash-kafka.conf:
bash
input {
kafka {
bootstrap_servers => "192.168.194.147:9092"
topics => ["app-logs"]
group_id => "logstash-group"
consumer_threads => 3
auto_offset_reset => "earliest"
codec => "json"
}
}
filter {
# 将日志中的 timestamp 字段映射为 @timestamp
if [timestamp] {
date {
match => [ "timestamp", "ISO8601" ]
target => "@timestamp"
}
mutate {
remove_field => [ "timestamp" ]
}
}
}
output {
if [level] == "ERROR" {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "app-logs-error-%{+YYYY.MM.dd}"
user => "elastic"
password => "root123"
}
} else {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "app-logs-info-%{+YYYY.MM.dd}"
user => "elastic"
password => "root123"
}
}
stdout { codec => rubydebug }
}修改 bootstrap_servers 和 Elasticsearch 认证信息(若无密码可去掉 user/password)。
启动 Logstash 后,它就会开始消费 Kafka 中的消息。
五、Kibana 中查看日志
-
访问
http://localhost:5601 -
左侧菜单 → Management → Stack Management → Data Views
-
点击 Create data view
-
Name:
app-info-logs -
Index pattern:
app-logs-info-* -
Timestamp field:
@timestamp(若没有则选I don't want to use the time filter)
-
-
同样创建
app-error-logs,Index pattern:app-logs-error-* -
进入 Discover ,选择数据视图,调整时间范围为 Today,即可看到实时日志。
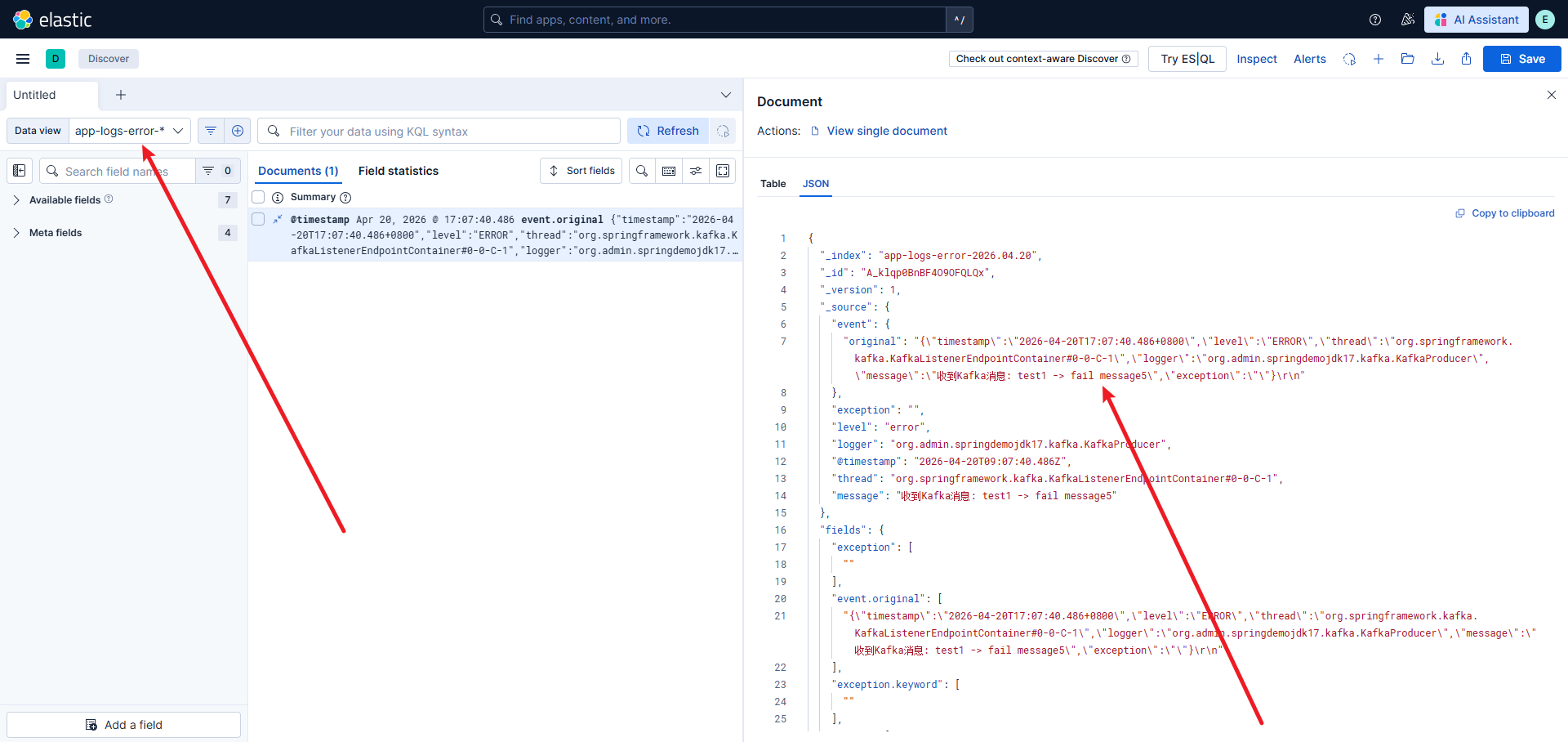
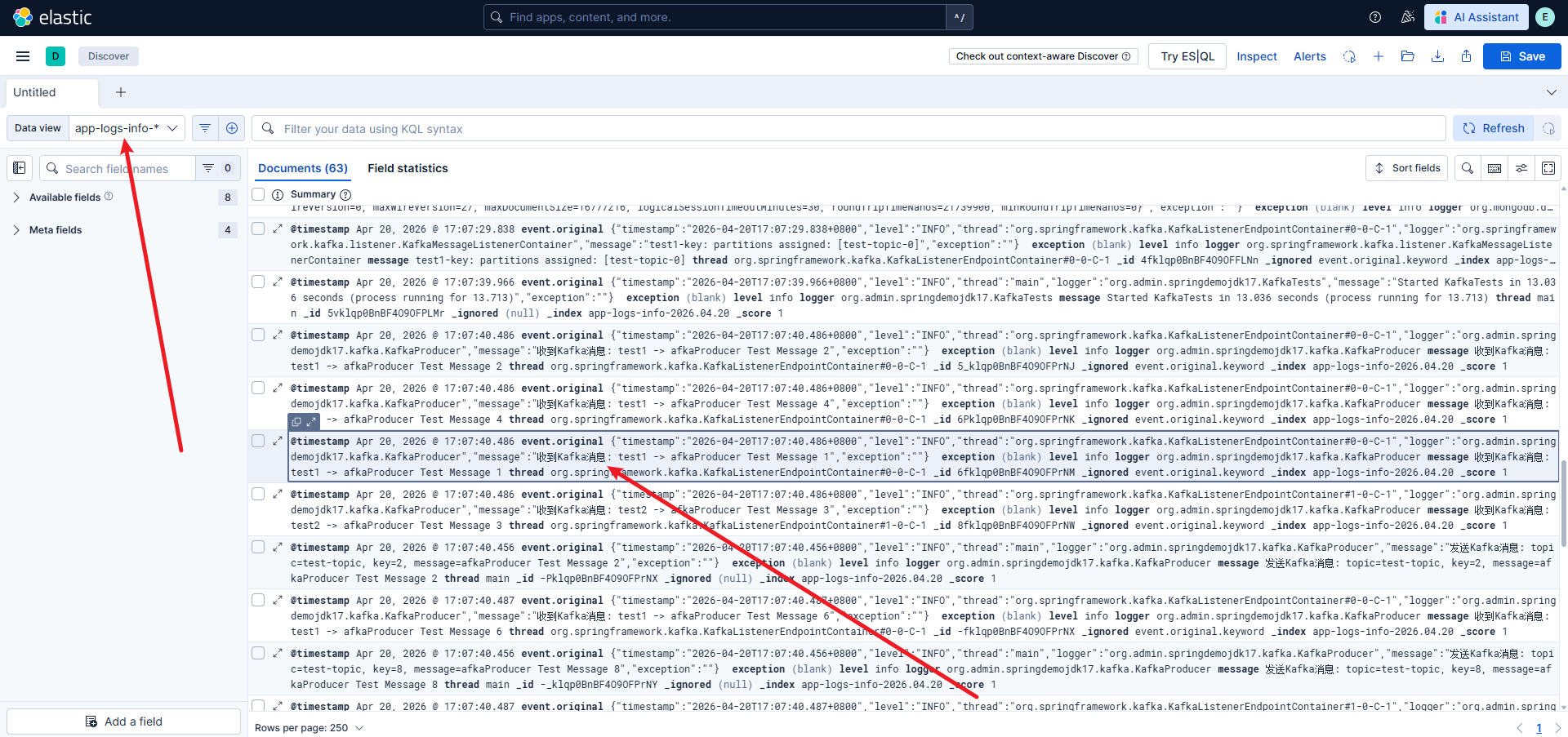
六、验证与测试
-
执行测试产生日志:
java@Autowired private KafkaProducer kafkaProducer; @Test public void testKafkaProducer() throws InterruptedException { for (int i = 0; i < 10; i++) { String text="afkaProducer Test Message "; if (i == 5) { text="fail message"; } kafkaProducer.sendKafkaMessage("test-topic", String.valueOf(i), text + i); } Thread.sleep(5000); }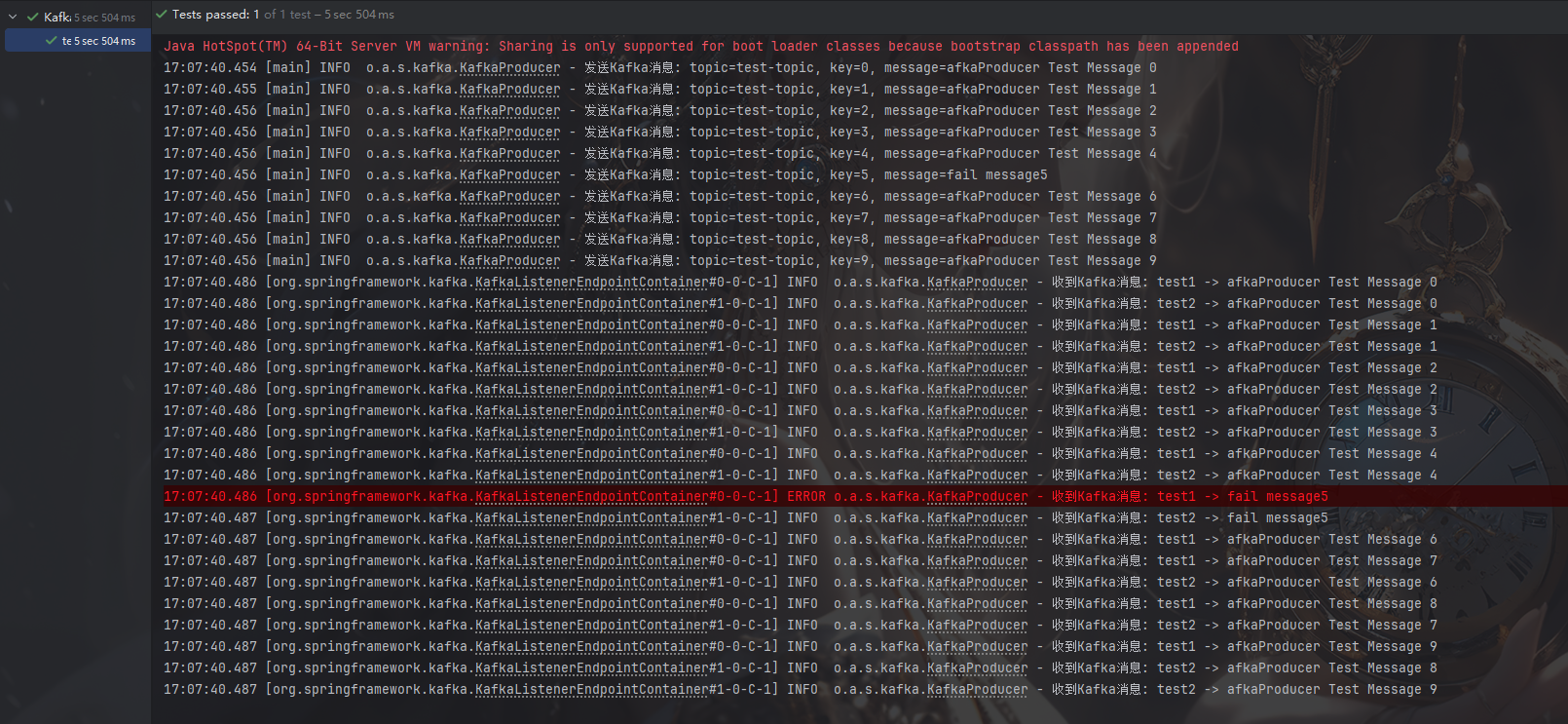
-
观察 Logstash 控制台输出(
stdout会打印每条消息)。 -
在 Kibana Discover 中搜索
level:ERROR,应看到错误日志。 -
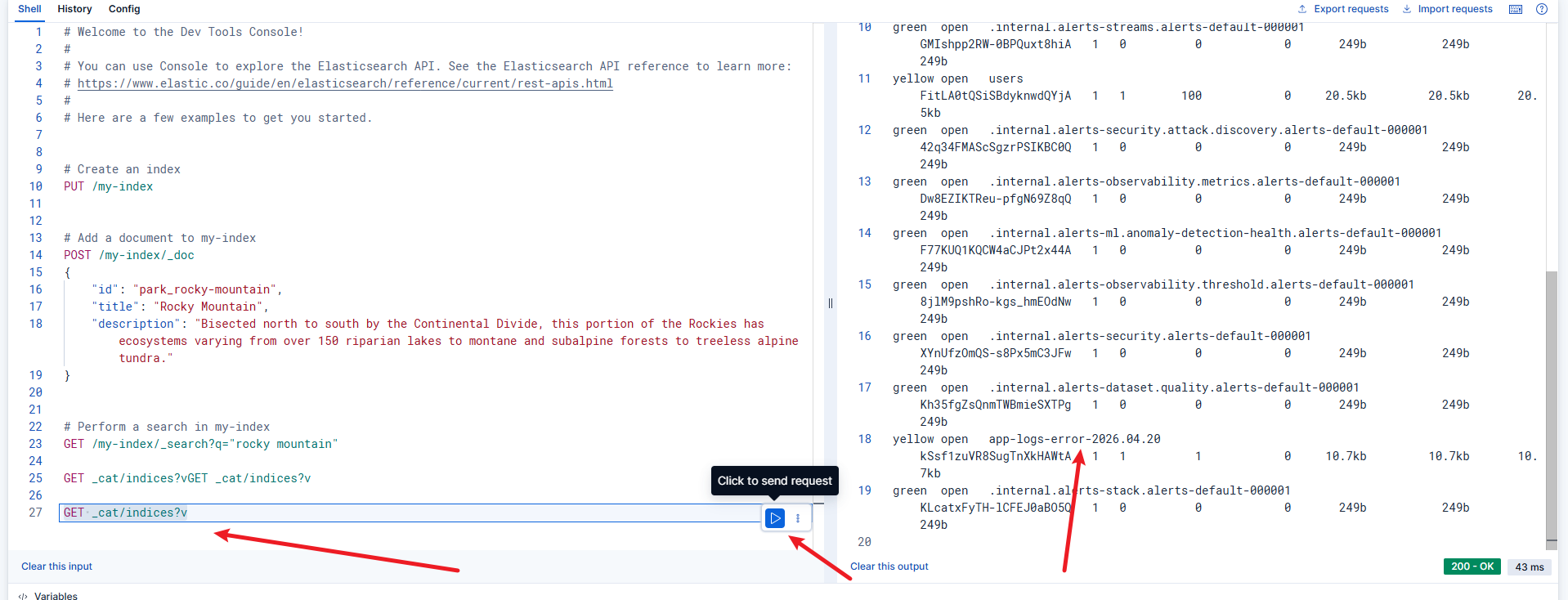
查看 Elasticsearch 索引:
打开 Kibana 界面(http://localhost:5601)
点击左侧菜单栏的 Dev Tools(扳手图标)
在 Console 窗口中输入:
bashGET _cat/indices?v点击右侧的 ▶ 按钮(或按 Ctrl+Enter)执行
下方会返回索引列表,包括 app-logs-info-*、users 等
-
应出现
app-logs-info-2026.04.20和app-logs-error-2026.04.20。
七、常见问题及解决
7.1 StackOverflowError 循环依赖
原因:Kafka 客户端初始化时打印日志,Logback 将其发送到 Kafka Appender,而 Appender 又要创建 Kafka 客户端,无限递归。
解决 :在 logback-spring.xml 中为 org.apache.kafka 包单独配置输出到控制台,且 additivity="false"。
7.2 Logback Kafka Appender 下载失败
阿里云镜像没有该依赖。解决方法:
-
添加中央仓库到
pom.xml的<repositories>中 -
或手动安装 jar 到本地 Maven 仓库
7.3 Logstash 无法连接 Kafka
检查 bootstrap_servers 地址和端口,确保 Kafka 已启动且防火墙允许 9092 端口。
7.4 Kibana 看不到数据
-
确认 Logstash 已成功消费并写入 ES(查看 Logstash 日志)
-
检查索引是否存在(
GET _cat/indices) -
在 Kibana Data View 中点击 Refresh 刷新字段列表
-
扩大时间范围或选择 No time filter
八、总结
通过本文,你已经完成了从零搭建一套企业级日志收集系统。这套架构具备以下优点:
-
高吞吐:Kafka 缓冲,可应对突发流量
-
可靠:Kafka 多副本持久化,Logstash 消费失败可重试
-
解耦:应用只写 Kafka,不依赖后端存储
-
可扩展:增加 Logstash 消费者即可提高处理能力
-
可重放:Kafka 中消息保留多天,支持重置偏移量重新处理
你可以将这套方案应用到自己的项目中,轻松实现日志的集中管理和分析。
九、参考资料
-
Elasticsearch 官方文档:https://www.elastic.co/guide/index.html
-
Kafka 官方文档:https://kafka.apache.org/documentation/
-
Logback Kafka Appender GitHub:https://github.com/danielwegener/logback-kafka-appender
如果觉得本文对你有帮助,欢迎点赞、收藏、转发。遇到任何问题,欢迎在评论区留言交流。