第一模块:视图 ------ 虚拟的"窗口"
1. 概念与区别 大家要记住一句话:视图是虚拟的表,它本身不存储数据,只存储 SQL 查询逻辑。
- 表:实际存储数据的地方(硬盘上)。
- 视图:就像一个窗口,透过窗口看真实的数据。窗口关闭(删除视图),数据还在。
2. 为什么需要视图?
- 复用性:把频繁使用的复杂查询存起来,下次直接用,不用重复写。
- 安全性:只开放视图权限,不开放原表权限,用户只能看到视图里展示的字段。
- 清晰度:把复杂的逻辑封装起来,对外看起来就像操作一张简单的表。
3. 核心语法
- 创建 :
CREATE VIEW 视图名 (列名...) AS <SELECT语句> - 修改 :
ALTER VIEW 视图名 AS <SELECT语句> - 更新/删除 :虽然可以对视图进行
UPDATE或INSERT,但这会直接影响原表数据,且有很多限制(比如包含GROUP BY的视图就不能更新)。工作中通常不建议直接更新视图,而是更新原表。
1.3 视图的核心操作(创建 / 修改 / 更新 / 删除 / 查看)
(1)创建视图【核心】
语法:
sql
cpp
CREATE VIEW <视图名>(列名1,列名2,...) AS <SELECT语句>;- 视图名在数据库中唯一,不能和表 / 其他视图重名;
- SELECT 语句可以是单表查询、联表查询、带聚合的查询;
- 列名可省略,默认使用 SELECT 语句的列名。
示例 1:单表视图(按商品类型统计数量)
台湾 sql
cpp
CREATE VIEW productsum (product_type, cnt_product)
AS
SELECT product_type, COUNT(*)
FROM product
GROUP BY product_type;示例 2:多表视图(联表 product 和 shop_product,查商品类型、售价、商店名)
cpp
CREATE VIEW view_shop_product(product_type, sale_price, shop_name)
AS
SELECT product_type, sale_price, shop_name
FROM product
JOIN shop_product
WHERE product.product_id = shop_product.product_id;创建一个叫 view_shop_product 的视图(虚拟表),把「商品表(product)」和「店铺商品库存表(shop_product)」按「商品 ID」拼在一起,最终视图里只展示「商品类型、商品售价、店铺名称」这三列数据
(2)修改视图
cpp
ALTER VIEW <视图名> AS <新的SELECT语句>;本质是替换视图的查询逻辑,示例:
cpp
ALTER VIEW productsum
AS
SELECT product_type, sale_price
FROM product
WHERE regist_date > '2009-09-11';(3)更新视图内容
视图是虚拟表,更新视图就是更新底层的基础表,语法和更新普通表一致(UPDATE/INSERT/DELETE),但有前提:
- 视图的 SELECT 语句不能包含 GROUP BY、DISTINCT、聚合函数(否则无法更新);
- 只能更新视图 "窗口能看到的内容",底层表中未被视图包含的字段无法通过视图更新。
示例:更新 productsum 视图中办公用品的售价
sql
cpp
UPDATE productsum
SET sale_price = '5000'
WHERE product_type = '办公用品';⚠️ 重要提醒 :实际工作中强烈不推荐更新视图!直接操作视图容易导致底层表数据误改,规范做法是直接操作底层表。
(4)删除视图
语法:
sql
cpp
DROP VIEW <视图名1>[,视图名2...];示例:
sql
cpp
DROP VIEW productsum;(5)查看视图
两种常用方式,推荐第二种(更通用):
sql
cpp
-- 方式1:查指定库下的所有视图
USE shop; -- 切换到视图所在库
SHOW TABLE STATUS WHERE COMMENT = 'view';
-- 方式2:从系统表中查询(推荐)
SELECT * FROM information_schema.views
WHERE TABLE_SCHEMA = 'shop'; -- shop是数据库名1.4 视图的使用禁忌
- 避免多层视图:不要在视图的基础上再创建视图,会大幅降低 SQL 执行效率;
- 不要用视图做数据更新 :仅用视图做查询,更新操作直接针对底层表;
- 视图的 SELECT 语句要简洁:过于复杂的联表 / 聚合会导致视图查询速度变慢。
二、子查询:一次性的 "临时视图"
子查询就是将 SELECT 语句嵌套在另一个 SQL 语句中 ,它和视图的关系非常紧密:子查询是一次性的视图,不存储在数据库中,SQL 执行后就消失。
2.1 子查询与视图的关联
- 视图:将 SELECT 语句永久保存,可反复使用;
- 子查询:将 SELECT 语句临时嵌套,仅本次 SQL 使用,执行后销毁。
比如创建视图的语句CREATE VIEW v AS SELECT ...,把这个SELECT ...直接嵌套到其他 SQL 中,就是子查询。
2.2 子查询的分类与用法
根据使用场景和返回结果,子查询分为嵌套子查询、标量子查询、关联子查询 ,其中标量子查询和关联子查询是实际开发的重点。
(1)嵌套子查询
将子查询嵌套在另一个子查询中,语法上无限制,但层数越多,SQL 越难理解、执行效率越低 ,尽量避免。
示例:查询商品类型数量为 4 的商品类型和数量
sql
cpp
SELECT product_type, cnt_product
FROM (SELECT *
FROM (SELECT product_type, COUNT(*) AS cnt_product
FROM product
GROUP BY product_type) AS productsum
WHERE cnt_product = 4) AS productsum2;这个示例用了两层嵌套,实际可以直接用GROUP BY + HAVING实现,无需嵌套子查询,这也是为什么不推荐嵌套的原因。
(2)标量子查询【核心】
标量 = 单一 ,标量子查询的要求是:返回结果必须是「单一值」(一行一列),比如返回一个数字、一个字符串、一个日期。
核心优势
标量子查询的使用场景无限制 ,任何可以使用常数 / 列名的地方都能使用(SELECT、WHERE、GROUP BY、HAVING、ORDER BY 子句均可),这是它最强大的地方。
经典示例
示例 1:WHERE 子句中使用(查询售价高于平均售价的商品)
sql
sql
SELECT product_id, product_name, sale_price
FROM product
WHERE sale_price > (SELECT AVG(sale_price) FROM product);内层的SELECT AVG(sale_price) FROM product就是标量子查询,返回一个单一的平均售价。
示例 2:SELECT 子句中使用(查询每个商品的售价 + 全表平均售价)
sql
sql
SELECT product_id,
product_name,
sale_price,
(SELECT AVG(sale_price) FROM product) AS avg_price
FROM product;此时平均售价会作为一列,展示在每个商品的右侧,这是基础查询无法实现的。
⚠️ 易错点
标量子查询必须返回且仅返回一个值,如果返回 0 行或多行,都会报语法错误。
(3)关联子查询【核心】
关联子查询是外层查询和内层子查询之间存在关联条件 的子查询,核心解决 **「按分组查条件」** 的需求,比如:查询各商品类型中,售价高于该类型平均售价的商品(基础查询 / 标量子查询无法实现)。
经典示例(按类型查高于该类型均价的商品)
sql
sql
SELECT product_type, product_name, sale_price
FROM product AS p1 -- 外层表起别名p1
WHERE sale_price > (SELECT AVG(sale_price)
FROM product AS p2 -- 内层表起别名p2
WHERE p1.product_type = p2.product_type -- 关联条件:内外层类型一致
GROUP BY product_type);执行逻辑(关键理解)
- 先执行外层查询,取出 p1 的第一条记录(比如 T 恤,衣服类型);
- 根据关联条件
p1.product_type = p2.product_type,内层子查询只计算衣服类型的平均售价; - 判断外层记录的售价是否高于该平均售价,符合则保留;
- 依次遍历外层表的所有记录,重复上述步骤。
核心要点
- 必须给内外层表起不同的别名(如 p1、p2),否则数据库无法区分;
- 关联条件是核心,必须将内外层表的某个字段关联(通常是分组字段)。
三、SQL 内置函数:提升数据处理效率
SQL 提供了大量内置函数,用于快速实现数值计算、字符串处理、日期操作、数据类型转换 ,无需自己写复杂逻辑。函数总数超 200 个,不用死记,掌握 30-50 个常用的即可,其余可按需查阅文档。
函数的通用特点:输入参数→按预设逻辑计算→返回单一值 ,我们按功能分类讲解最常用的函数。
3.1 算术函数:数值计算
针对数值类型的字段做计算,常用的有 3 个:
| 函数 | 语法 | 作用 | 示例 | 结果 |
|---|---|---|---|---|
| ABS | ABS (数值) | 求绝对值 | ABS(-180) | 180 |
| MOD | MOD (被除数,除数) | 求余数(仅整数) | MOD(7,3) | 1 |
| ROUND | ROUND (数值,保留小数位) | 四舍五入 | ROUND(5.555,1) | 5.6 |
3.2 字符串函数:字符串操作
针对字符串类型的字段,实际开发中高频使用,常用的有:
| 函数 | 语法 | 作用 |
|---|---|---|
| CONCAT | CONCAT (字符串 1, 字符串 2,...) | 拼接多个字符串 |
| LENGTH | LENGTH (字符串) | 求字符串长度(字节数) |
| LOWER/UPPER | LOWER (字符串)/UPPER (字符串) | 大小写转换(仅英文) |
| REPLACE | REPLACE (原字符串,旧值,新值) | 替换字符串中的指定内容 |
| SUBSTRING | SUBSTRING (字符串 FROM 起始位 FOR 长度) | 截取字符串(起始位从 1 开始) |
| SUBSTRING_INDEX | SUBSTRING_INDEX (原字符串,分隔符,n) | 按分隔符截取(n 正取前 n 个,n 负取后 n 个) |
经典示例:
sql
sql
-- 拼接:太阳+月亮+火星 → 太阳月亮火星
SELECT CONCAT('太阳','月亮','火星');
-- 截取:从第3位开始取2个字符,abcdef → cd
SELECT SUBSTRING('abcdef' FROM 3 FOR 2);
-- 按分隔符截取:www.mysql.com 按.取前2个 → www.mysql
SELECT SUBSTRING_INDEX('www.mysql.com', '.', 2);3.3 日期函数:日期 / 时间操作
日期处理是开发中的高频需求,SQL 的日期函数能快速提取年 / 月 / 日、获取当前时间,常用的有:
| 函数 | 语法 | 作用 |
|---|---|---|
| CURRENT_DATE | CURRENT_DATE | 获取当前日期(YYYY-MM-DD) |
| CURRENT_TIME | CURRENT_TIME | 获取当前时间(HH:MM:SS) |
| CURRENT_TIMESTAMP | CURRENT_TIMESTAMP | 获取当前日期 + 时间 |
| EXTRACT | EXTRACT (日期元素 FROM 日期) | 提取日期元素(年 / 月 / 日 / 时 / 分 / 秒) |
经典示例:
sql
sql
-- 获取当前日期
SELECT CURRENT_DATE; -- 结果:2026-02-23
-- 提取年/月/日
SELECT EXTRACT(YEAR FROM '2009-09-20') AS year,
EXTRACT(MONTH FROM '2009-09-20') AS month,
EXTRACT(DAY FROM '2009-09-20') AS day;3.4 转换函数:类型 / 值的转换
核心解决数据类型转换 和NULL 值处理 问题,COALESCE 是处理 NULL 的核心函数,必须掌握:
(1)CAST:数据类型转换
语法:
sql
sql
CAST(转换前的值 AS 目标数据类型)常用转换:字符串→数值、字符串→日期、数值→字符串
sql
sql
-- 字符串→整数
SELECT CAST('0001' AS SIGNED INTEGER); -- 结果:1
-- 字符串→日期
SELECT CAST('2009-09-20' AS DATE); -- 结果:2009-09-20(2)COALESCE:将 NULL 转换为指定值
语法:
sql
sql
COALESCE(值1,值2,值3,...)作用 :返回参数中从左到右第一个非 NULL 的值 ,参数个数无限制,是处理 NULL 的最优方案(避免 NULL 参与计算导致结果为 NULL)。
示例:
sql
sql
-- 第一个参数是NULL,返回第二个11
SELECT COALESCE(NULL,11); -- 11
-- 前两个是NULL,返回第三个2026-02-23
SELECT COALESCE(NULL,NULL,'2026-02-23'); -- 2026-02-23
-- 处理字段的NULL:如果purchase_price为NULL,返回0
SELECT product_name, COALESCE(purchase_price,0) FROM product;四、谓词:返回 "真值" 的特殊函数
谓词是 SQL 中专门用于判断条件 的函数,核心特点:返回值为「真值」(TRUE / 假 FALSE / 未知 UNKNOWN),而非普通的数值 / 字符串。
常用的谓词有:LIKE、BETWEEN、IS NULL/IS NOT NULL、IN/NOT IN、EXIST/NOT EXIST,这些是WHERE 子句的核心组成,必须掌握。
4.1 LIKE:模糊查询
用于字符串的部分匹配查询,搭配两个通配符使用,核心解决 "不知道完整字符串,只知道部分内容" 的查询需求:
%:匹配0 个或多个任意字符;_:匹配1 个任意字符(精确匹配 1 个,不能多也不能少)。
三种匹配方式
sql
sql
-- 前方一致:以ddd开头的字符串
SELECT * FROM samplelike WHERE strcol LIKE 'ddd%';
-- 中间一致:包含ddd的字符串(最宽松,结果最多)
SELECT * FROM samplelike WHERE strcol LIKE '%ddd%';
-- 后方一致:以ddd结尾的字符串
SELECT * FROM samplelike WHERE strcol LIKE '%ddd';
-- 匹配任意1个字符:abc后接2个任意字符 → abcdd
SELECT * FROM samplelike WHERE strcol LIKE 'abc__';4.2 BETWEEN:范围查询
用于数值 / 日期的范围查询,语法:
sql
sql
字段 BETWEEN 最小值 AND 最大值⚠️ 关键 :BETWEEN是闭区间 ,包含最小值和最大值 ,如果不想包含临界值,用< >代替。
示例:
sql
sql
-- 查售价100~1000的商品(包含100和1000)
SELECT product_name, sale_price FROM product WHERE sale_price BETWEEN 100 AND 1000;
-- 查售价100~1000的商品(不包含100和1000)
SELECT product_name, sale_price FROM product WHERE sale_price >100 AND sale_price <1000;4.3 IS NULL/IS NOT NULL:判断 NULL
唯一能判断 NULL 值的谓词 ,永远不要用=/!=判断 NULL(因为 NULL 是 "未知值",和任何值比较结果都是 UNKNOWN)。
示例:
sql
sql
-- 查进价为NULL的商品
SELECT product_name, purchase_price FROM product WHERE purchase_price IS NULL;
-- 查进价不为NULL的商品
SELECT product_name, purchase_price FROM product WHERE purchase_price IS NOT NULL;4.4 IN/NOT IN:替代 OR 的批量查询
用于多个值的批量匹配 ,替代多个OR,让 SQL 更简洁,语法:
sql
字段 IN (值1,值2,值3,...); -- 匹配任意一个值
字段 NOT IN (值1,值2,值3,...); -- 不匹配任何一个值基础用法(替代 OR)
sql
sql
-- 用OR:查进价为320/500/5000的商品
SELECT product_name, purchase_price FROM product WHERE purchase_price=320 OR purchase_price=500 OR purchase_price=5000;
-- 用IN:更简洁
SELECT product_name, purchase_price FROM product WHERE purchase_price IN (320,500,5000);高级用法:子查询作为 IN 的参数【核心】
IN 的参数不仅可以是常量,还可以是子查询的结果,这是实际开发的高频场景,解决 **"动态批量匹配"** 问题(比如查大阪门店在售的商品)。
示例:查大阪门店(shop_id='000C')在售的商品名称和售价
sql
sql
SELECT product_name, sale_price
FROM product
WHERE product_id IN (SELECT product_id -- 子查询:查大阪门店的商品ID
FROM shop_product
WHERE shop_id = '000C');优势 :当大阪门店的在售商品变化时,无需修改外层 SQL,子查询会自动获取最新的商品 ID,可维护性大幅提升。
⚠️ 易错点
IN/NOT IN的参数中不能包含 NULL,否则会导致查询结果异常(查不到任何数据)。
4.5 EXIST/NOT EXIST:判断 "记录是否存在"
EXIST 的核心作用:判断子查询中是否存在满足条件的记录,存在则返回 TRUE,不存在则返回 FALSE。
- EXIST:存在→TRUE;
- NOT EXIST:不存在→TRUE。
基础用法(替代 IN)
示例:用 EXIST 实现 "查大阪门店在售的商品",和 IN 的结果一致
sql
sql
SELECT product_name, sale_price
FROM product AS p
WHERE EXISTS (SELECT * -- 子查询:关联商品ID和门店ID
FROM shop_product AS sp
WHERE sp.shop_id = '000C'
AND sp.product_id = p.product_id);核心特点
- EXIST只有一个参数 :通常是关联子查询(内外层表有联表条件);
- 子查询中写
SELECT */SELECT 1都可以,因为 EXIST只关心记录是否存在,不关心返回什么列; - 大数据量下,EXIST 的执行效率远高于 IN(因为 EXIST 找到第一条满足条件的记录就会停止查询,而 IN 会查询所有结果)。
NOT EXIST:替代 NOT IN
示例:查未在东京门店(shop_id='000A')销售的商品
sql
sql
SELECT product_name, sale_price
FROM product AS p
WHERE NOT EXISTS (SELECT *
FROM shop_product AS sp
WHERE sp.shop_id = '000A'
AND sp.product_id = p.product_id);五、CASE 表达式:SQL 的 "条件分支"【重中之重】
CASE 表达式是 SQL 中最强大、最常用 的功能之一,没有之一!它是 SQL 中的条件分支语句 ,能实现 "如果... 那么... 否则..." 的逻辑,解决数据分类、格式转换、行列转换等核心需求。
5.1 核心语法(搜索型 CASE,推荐)
SQL 中有简单型和搜索型 CASE,搜索型包含简单型的所有功能,只需掌握搜索型即可:
sql
sql
CASE
WHEN <求值表达式> THEN <返回值>
WHEN <求值表达式> THEN <返回值>
...
ELSE <返回值> -- 可选,默认NULL
END -- 必须写,不能省略!执行逻辑 :依次判断WHEN后的表达式是否为 TRUE,第一个为 TRUE 的WHEN返回对应THEN的值;如果所有WHEN都为 FALSE,返回ELSE的值(无 ELSE 则返回 NULL)。
5.2 核心特点
- 返回单一值:无论多少个 WHEN 分支,最终只会返回一个值;
- END 不能省:忘记写 END 会报语法错误,这是新手最常见的错误;
- ELSE 可选:但推荐显式写出,避免 NULL 值导致的结果异常;
- 使用场景无限制:可在 SELECT、WHERE、GROUP BY、HAVING、ORDER BY 中使用。
5.3 三大核心应用场景【实际开发高频】
场景 1:列值替换 / 分类(最基础)
将原有列值按条件转换为新的值,比如给商品类型加前缀(衣服→A:衣服,办公用品→B:办公用品)。
示例:
sql
sql
SELECT product_name,
CASE WHEN product_type = '衣服' THEN CONCAT('A : ',product_type)
WHEN product_type = '办公用品' THEN CONCAT('B : ',product_type)
WHEN product_type = '厨房用具' THEN CONCAT('C : ',product_type)
ELSE NULL
END AS abc_product_type
FROM product;场景 2:列方向的聚合统计(核心)
基础的GROUP BY是行方向 的统计(按分组显示一行结果),而 CASE 表达式可以实现列方向的统计(按分组显示一列结果),解决 "多维度一行展示" 的需求。
示例:统计衣服、厨房用具、办公用品的售价总和,一行三列展示
sql
sql
SELECT SUM(CASE WHEN product_type = '衣服' THEN sale_price ELSE 0 END) AS sum_price_clothes,
SUM(CASE WHEN product_type = '厨房用具' THEN sale_price ELSE 0 END) AS sum_price_kitchen,
SUM(CASE WHEN product_type = '办公用品' THEN sale_price ELSE 0 END) AS sum_price_office
FROM product;结果:
| sum_price_clothes | sum_price_kitchen | sum_price_office |
|---|---|---|
| 5000 | 11180 | 600 |
场景 3:行转列(实际开发高频)
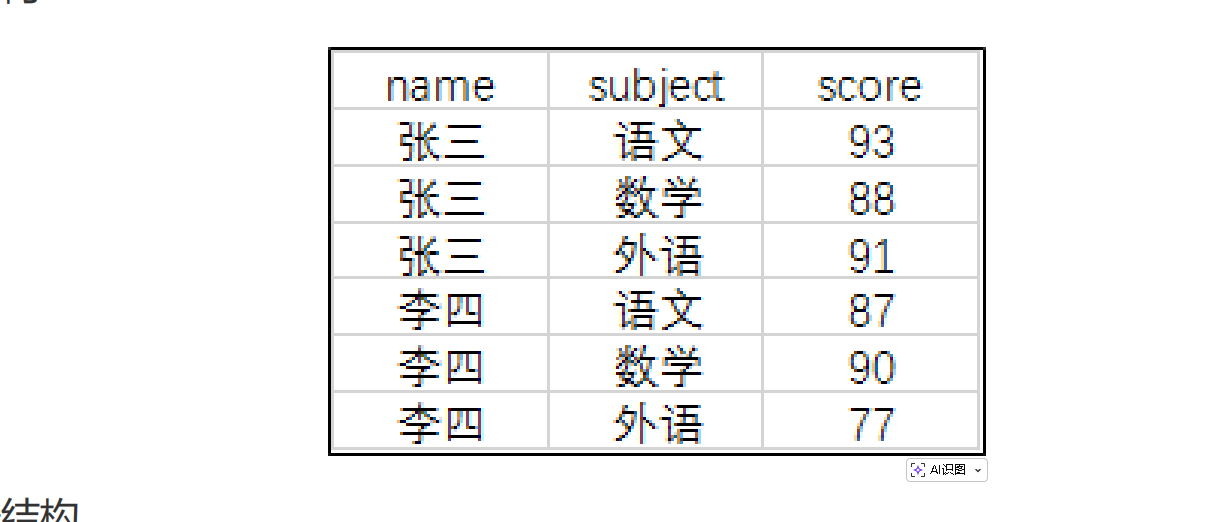
将行式数据 转换为列式数据,比如将学生的成绩行(姓名、科目、分数)转换为成绩表(姓名、语文、数学、外语),这是报表开发的核心需求。
示例:成绩行转列
sql
sql
-- 原始成绩表(score):name, subject, score
-- 行转列后:name, chinese, math, english
SELECT name,
SUM(CASE WHEN subject = '语文' THEN score ELSE NULL END) AS chinese,
SUM(CASE WHEN subject = '数学' THEN score ELSE NULL END) AS math,
SUM(CASE WHEN subject = '外语' THEN score ELSE NULL END) AS english
FROM score
GROUP BY name;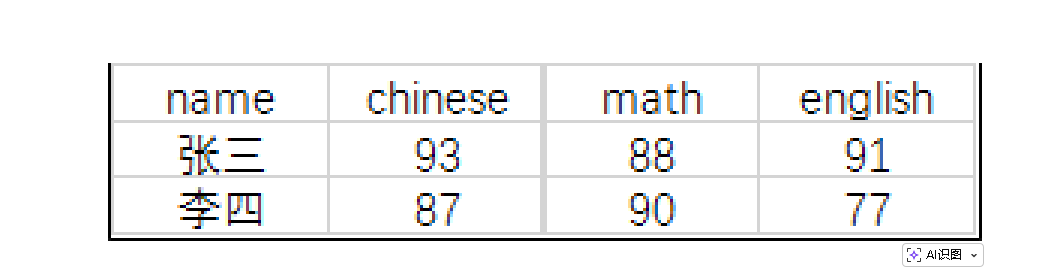
技巧:
- 数字列转列:用
SUM/AVG/MAX/MIN(推荐 SUM); - 文本列转列:用
MAX/MIN(不能用 SUM)。
六、本节课核心小结
今天学的 SQL 复杂查询知识点,不是孤立的,而是相互结合使用的,核心可以总结为 3 点:
- 视图 + 子查询 :解决查询逻辑复用问题,视图用于永久复用,子查询用于临时复用;
- 函数 + 谓词 :解决数据处理和条件筛选问题,函数提升数据处理效率,谓词实现精准的条件判断;
- CASE 表达式 :解决数据分类和格式转换问题,是 SQL 的 "万能工具",几乎所有复杂的取数 / 统计需求都离不开它。
这些知识点是SQL 进阶的基础 ,也是实际开发中每天都会用到 的内容,重点在于多练 :结合product和shop_product表,把每个知识点的示例手动写一遍,再尝试组合使用(比如CASE+聚合+GROUP BY、IN+子查询+谓词),很快就能熟练掌握。