集成学习(ensemble learning)结合多个独立模型来提升预测性能 。它被广泛采用,旨在解决数据集有限带来的问题 。一般来说,组合模型的多样性越高,最终的集成模型就越准确。因此,集成学习可以在不牺牲模型偏差的情况下解决过拟合等回归问题。通过组合多个不同的模型,集成算法可以在保留每个模型自身复杂性和优势的同时,降低总体误差率。模型平均之所以有效,是因为不同的模型通常不会在测试集上产生完全相同的错误。
通常,集成学习涉及在同一数据集上训练多个网络,然后使用每个训练好的模型进行预测,最后以某种方式将这些预测结果组合起来,得出最终结果或预测。
集成学习可权衡偏差--方差 (bias--variance):偏差是指模型中错误假设导致的误差。高偏差模型过于简单,会忽略数据中的重要模式,从而导致欠拟合。偏差越大 ,模型在训练数据集上的预测准确率越低。方差是指模型对训练数据中微小变化的敏感性。高方差模型过于复杂,不仅会学习数据中的模式,还会学习噪声,从而导致过拟合。方差越大,模型在未见过的数据上的预测准确率越低。泛化旨在降低方差。
集成学习方法的类型:集成方法可以从多个方面进行分类
- 基于模型组成:
(1).同质集成(homogeneous ensembles):在同质集成中,所有基础模型类型相同,但使用不同的数据子集或不同的参数进行训练。例如,随机森林由多个决策树组成。
(2).异质集成(heterogeneous ensembles):在异质集成中,基础模型类型不同。例如,可以将决策树、支持向量机和神经网络组合在一起。
2.基于学习方法:如下图所示
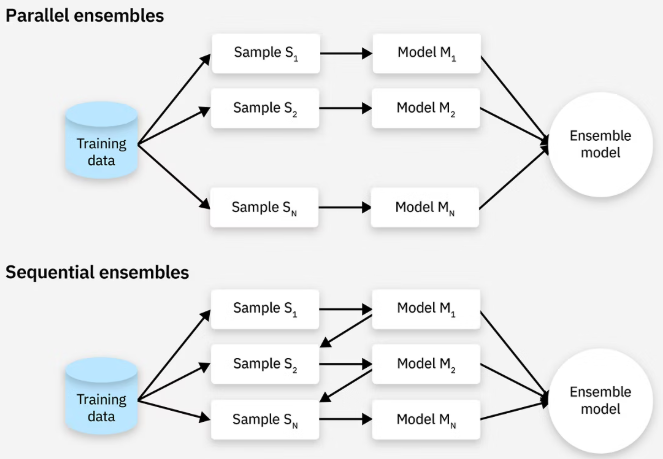
(1).并行集成:并行且独立地训练各个基础模型。
(2).顺序集成:分阶段顺序地构建基础模型。每个新模型都着重改进先前模型所犯的错误。
常用集成技术:
(1).bagging:bootstrap aggregating(自助聚合)的缩写,同质并行方法,在训练数据的不同随机子集上(使用放回的方式创建数据集的随机子集,这意味着同一个样本可能被选中零次、一次或多次)训练同一模型的多个版本,最终的预测结果通常是所有预测结果的平均值(回归模型)或多数投票结果(分类模型)。如随机森林。
使用bagging的场景:基础模型方差过高(过拟合)、数据集包含噪声或异常值、需要提高模型的稳定性和准确率、数据集相对较小。
(2).boosting:序列集成方法,依次训练模型,每个新模型都专注于先前模型分类错误的样本。它为错误分类的样本赋予更高的权重,迫使后续模型更加关注这些分类错误的样本。如AdaBoost、XGBoost、LightGBM。
使用boosting的场景:基础模型偏差较高(欠拟合)、提高模型准确率、数据相对干净,异常值较少、需要捕捉数据中的细微模式、可承担一定程度的过拟合风险以获得更好的性能。
(3).stacking:异质并行方法,通过训练一个元模型(meta-model)来组合多个模型,该元模型学习如何最佳地组合各个模型的预测结果。基础模型独立进行预测,然后元模型使用这些预测结果作为特征来进行最终预测。注:训练元模型时必须使用与训练基础模型不同的数据集。
使用stacking的场景:拥有不同优势的模型、追求尽可能高的准确率、拥有足够的数据来训练基础模型和元模型。
(4).voting:多个模型对最终预测结果进行投票,获得最多投票的类别即被视为集成模型的预测类别。适用于二分类问题。
使用voting的场景:多个性能良好但各不相同的模型、模型具有互补优势、模型来自不同的来源。
集成学习的优势:减少过拟合、提高泛化能力、提高准确率或命中率、能够整合各种深度学习算法。
集成学习的局限性:更高的计算成本、更长的训练时间。
以上内容主要参考:
回归模型集成策略:简单平均法、加权平均法、median、trimmed mean。实现如下:
python
def str2tuple(value):
if not isinstance(value, tuple):
value = ast.literal_eval(value) # str to tuple
return value
class EnsembleModel(nn.Module):
def __init__(self, regression_model, model_names, device, means, stds, strategy=0, weights=None):
super().__init__()
self.device = device
self.model_names = tuple(s.strip() for s in model_names.strip("()").split(","))
self.strategy = strategy
self.weights = weights
if self.weights is not None:
self.weights = np.array(str2tuple(self.weights), dtype=np.float32)
if len(self.weights) != len(self.model_names):
raise ValueError(colorama.Fore.RED + f"weights length mismatch: {len(self.weights)}")
means_ = str2tuple(means)
stds_ = str2tuple(stds)
if len(means_) % 3 != 0 or len(means_) != 3 * len(self.model_names):
raise ValueError(colorama.Fore.RED + f"mean length mismatch: {len(means_)}")
if len(stds_) % 3 != 0 or len(stds_) != 3 * len(self.model_names):
raise ValueError(colorama.Fore.RED + f"std length mismatch: {len(stds_)}")
self.means = [means_[i:i+3] for i in range(0, len(means_), 3)]
self.stds = [stds_[i:i+3] for i in range(0, len(stds_), 3)]
self.models = []
for model_name in self.model_names:
model = regression_model
model.load_state_dict(torch.load(model_name))
model.to(self.device)
model.eval()
self.models.append(model)
def forward(self, x):
preds = []
with torch.no_grad():
for idx, model in enumerate(self.models):
self.preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=self.means[idx], std=self.stds[idx]) # RGB
])
input_tensor = self.preprocess(x) # (c,h,w)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model, (1,c,h,w)
input_batch = input_batch.to(self.device)
output = model(input_batch)
preds.append(output[0,0].item())
if self.strategy == 0: # simple average
final_pred = sum(preds) / len(preds)
elif self.strategy == 1: # weighted average
if self.weights is None:
raise ValueError(colorama.Fore.RED + f"weights cannot be None")
self.weights = self.weights / sum(self.weights)
final_pred = sum(w * p for w, p in zip(self.weights, preds))
elif self.strategy == 2: # median
final_pred = np.median(preds)
elif self.strategy == 3: # trimmed mean
preds = np.asarray(preds)
preds = np.sort(preds)
preds = preds[1 : len(preds) - 1]
final_pred = preds.mean()
else:
raise ValueError(colorama.Fore.RED + f"unsupported ensemble learning strategies: {self.strategy}")
return final_pred单回归模型与集成回归模型量化评估指标:
- MAE(Mean Absolute Error):平均绝对误差,数值越小,说明预测值与真值的偏差越小,模型效果越好
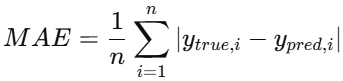
- MSE(Mean Squared Error):均方误差,数值越小,说明预测值与真值的偏差越小,模型效果越好
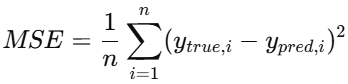
- RMSE(Root Mean Squared Error):均方根误差,数值越小,说明预测值与真值的偏差越小,模型效果越好
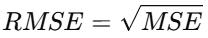
- R^2(R-squared/Coefficient of Determination):决定系数,值越大越好,越接近1,说明模型对数据的拟合程度越高
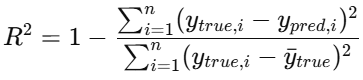
实现如下:
python
class RegressMetrics:
@staticmethod
def convert(y_true, y_pred):
y_true = np.array(y_true)
y_pred = np.array(y_pred)
if len(y_true) != len(y_pred):
raise ValueError(colorama.Fore.RED + f"inconsistent length: {len(y_true)}, {len(y_pred)}")
return y_true, y_pred
@staticmethod
def mae(y_true, y_pred): # Mean Absolute Error
y_true, y_pred = RegressMetrics.convert(y_true, y_pred)
return float(np.mean(np.abs(y_true - y_pred)))
@staticmethod
def mse(y_true, y_pred): # Mean Squared Error
y_true, y_pred = RegressMetrics.convert(y_true, y_pred)
return float(np.mean((y_true - y_pred) ** 2))
@staticmethod
def rmse(y_true, y_pred): # Root Mean Squared Error
return float(np.sqrt(RegressMetrics.mse(y_true, y_pred)))
@staticmethod
def r2(y_true, y_pred): # R-squared/Coefficient of Determination
y_true, y_pred = RegressMetrics.convert(y_true, y_pred)
ss_total = np.sum((y_true - np.mean(y_true)) ** 2)
ss_residual = np.sum((y_true - y_pred) ** 2)
if ss_total == 0:
if ss_residual == 0:
return 1.0
else:
return 0.0
return float(1.0 - (ss_residual / ss_total))
@staticmethod
def metrics(y_true, y_pred):
result = {}
result["MAE"] = float(f"{RegressMetrics.mae(y_true, y_pred):.4f}")
result["MSE"] = float(f"{RegressMetrics.mse(y_true, y_pred):.4f}")
result["RMSE"] = float(f"{RegressMetrics.rmse(y_true, y_pred):.4f}")
result["R2"] = float(f"{RegressMetrics.r2(y_true, y_pred):.4f}")
return result