论文总结
这篇文章发表在neuroimage,是方法型论文。
-
背景:极早产儿认知缺陷诊断通常延迟至3-5岁,错过早期干预窗口。亟需基于早期MRI的预测方法。
-
目标 :提出一种**本体引导的属性划分集成学习(OAP-EL)**模型,利用足月等效年龄的脑结构MRI提取的脑成熟与几何特征,预测2岁时的认知缺陷。
-
方法:
-
提取338个脑区特征(体积、厚度、沟深、曲率、脑回指数、表面积)。
-
基于脑分区和脑几何两个本体构建无权重本体图,通过谱聚类将特征划分为6个非重叠子集。
-
每个子集训练一个XGBoost基分类器,再用神经网络作为元分类器集成。
-
内部验证集207例(CINEPS),外部验证集69例(COEPS),采用SMOTE-ENN处理类别不平衡。
-
-
主要结果:
-
内部验证:准确率71.3%,敏感性70.6%,特异性72.6%,AUC 0.74。
-
外部验证:准确率71.0%,敏感性70.0%,特异性71.2%,AUC 0.71。
-
显著优于传统机器学习(SVM、RF等)及其他集成方法(Bagging、AB-EL等)。
-
本体组合优于单一本体;基于本体的特征划分优于随机特征划分。
-
最具预测性的特征:右侧岛叶厚度、左侧颞中下回前部沟深等。
-
-
结论:OAP-EL可有效利用本体知识提升特征划分多样性和模型性能,实现极早产儿认知缺陷的早期预测。代码已公开。
摘要
结构磁共振成像研究表明,大脑解剖异常与早产儿的认知障碍有关。大脑成熟度和几何特征可以与机器学习模型一起用于预测未来的神经发育缺陷。然而,传统的机器学习模型会受到很大的特征与实例比率的影响(即,大量的特征但少量的实例/样本)。集成学习是一种战略性地生成和集成机器学习分类器库的范例,并已成功地用于各种预测建模问题,以提高模型性能。属性(即特征)装袋方法是最常用的特征划分方法,它从整个特征集中随机、重复地提取特征子集。虽然属性袋化方法可以有效地降低特征维度,以处理较大的特征实例比,但它缺乏对领域知识和特征之间潜在关系的考虑。在这项研究中,我们提出了一种新的本体引导的属性划分(OAP)方法,通过考虑特征之间的特定领域关系来更好地提取特征子集。利用划分较好的特征子集,我们提出了一种集成学习框架,称为OAP-集成学习(OAP-EL)。我们应用OAP-EL来预测2岁时的认知缺陷,使用在极早产儿的足月相同年龄获得的定量脑成熟和几何特征。我们证明了所提出的OAP-EL方法的性能明显优于对等集成学习和传统的机器学习方法。
引言
尽管全球婴儿死亡率已降至约11.1%(Blencowe等人,2013年),但极早产儿(胎龄;GA≤32周)的神经发育障碍发生率仍然很高。大约35%-40%的极早产儿在矫正年龄2岁时出现认知缺陷(Blencowe等人,2012年;Hamilton等人,2014年)。认知缺陷会导致学习成绩和社交能力的困难,影响这些早产儿的一生。不幸的是,一个准确的临床诊断通常在极早产儿直到3-5岁才能诊断出认知障碍,因此,缺乏及时的治疗导致错过了大脑发育的最佳神经可塑性时期,此时干预措施可以发挥最大的预防作用。因此,一个及时和准确的风险分层方法是可取的,以满足早期预测极早产儿认知缺陷的需要。多重结构磁共振成像(SMRI)研究表明,几种大脑解剖异常与早产儿的认知缺陷有关(Fleiss等人,2020年;Inder等人)。在相当于足月年龄的早产儿的脑部sMRI图像上发现了皮质发育的改变。例如,与足月儿相比,早产儿额叶、岛叶和顶前皮质的皮质厚度更大(Bouyssi-Kobar等人,2018;Kline等人,2020;Parikh,2016)。这些研究表明,大脑成熟和几何特征有望成为未来神经发育缺陷的预测生物标志物。最近,我们开发了一个机器学习模型,使用大脑几何特征(例如,体积、皮质厚度等)来预测2岁校正年龄的神经发育结果。来自于110名早产儿(Kline等人,2020年)在相当于足月年龄收集的T2加权MRI扫描,展示了这些特征对异常神经发育的预测能力。然而,我们传统的机器学习模型仍然受到很大的特征与实例比率的影响(即大量的特征但少量的实例/样本)。集成学习是一种机器学习范式,它战略性地生成和集成机器学习分类器库,称为基本分类器。与只学习一个假设的传统机器学习模型不同,集成学习使用模型库中的基分类器定义了一组假设,并将它们总结为最终决策。由于每个基本分类器都有自己的优点和缺点,因此,自然可以预期,利用多个基本分类器的学习方法将产生超过任何单个分类器所获得的水平的优越性能(董等人,2020)。在过去的十年中,集成学习模型已经成功地应用于各种预测建模问题,以提高模型的性能(Zhang和Ma,2012)。在任何集成学习策略中,构建不同的基分类库都是必不可少的。属性(即,特征)打包(也称为随机子空间)方法(Bryll等人,2003;Ho,1998)是最常用的特征划分方案,其从整个特征集中随机且重复地提取特征子集来训练基分类器,而不是使用整个特征集。属性袋方法能够有效地降低每个基本分类器的特征维度并增加模型多样性,提供了一种优雅的特征划分解决方案来处理神经成像研究中的大的特征实例比(Kuncheva等人,2010)。然而,基于随机抽取的属性打包方法缺乏对领域知识和特征间潜在关系的考虑。例如,随机特征绘制简单地将"左杏仁核体积"和"右杏仁核体积"属性视为两个匿名属性(即只考虑它们的数值),而没有注意到两者都是量化的"体积";但一个是"左杏仁核",另一个是"右杏仁核"。本体被定义为对感兴趣的领域中的"概念化"或"知识"的显式规范(Grüninger和Fox,1995;Staab等人,2001;Uschold和Gruninger,1996),它已被用于知识编码、共享和存储(Consortium,2004;Kulmanov等人,2020;Smith等人,2005)。本体驱动的技术正越来越多地被用于各种生物医学研究,如蛋白质-蛋白质相互作用预测(Zhang和Tang,2016)、临床诊断(沈等人,2018)和生物功能推理(Köhler等人,2009)。在这项研究中,我们提出了一种本体论指导的属性划分(OAP)方法,通过考虑标准属性划分方法(如属性袋方法)没有考虑的特征之间的特定领域关系来更好地提取特征子集(Bryll等人,2003;Ho,1998)。通过更好地划分特征子集,我们训练和集成了不同的个体基本分类器的堆叠/集成。我们将这个框架称为OAP-EnSemble学习(OAP-EL)。我们应用OAP-EL来预测2岁时的认知缺陷,使用在极早产儿的足月相同年龄获得的定量大脑成熟和几何特征。我们对提出的OAP-EL方法能够显著优于同级集成学习方法的假设进行了检验。
材料和方法
概述
我们在这项研究中的临床任务是根据在足月相同年龄的结构MRI上获得的定量脑成熟和几何特征,对2岁校正年龄的极早产儿的认知缺陷风险进行分层。如图1所示,我们首先使用正在开发的人类连接组项目(DHCP)处理管道(Makropoulos等人,2018年)从T2加权MRI数据中提取数百个大脑成熟和几何特征(图1A)。接下来,基于两个先前定义的本体,其分别描述大脑部分(例如,额叶、颞叶、顶叶等)。(Gousias等人,2012),以及大脑几何和成熟度(皮质厚度、沟深度、曲率、皮质表面积等)。(Makropoulos等人,2018),我们构造了一个未加权的本体图,其中大脑成熟和几何特征被认为是顶点,本体派生关系是边。然后,我们进行本体图聚类(图1B),将大脑成熟和几何特征划分为k个不重叠的特征子集(图1C)。在这项工作中,我们使用k个特征子集来训练k个基分类器(即极端梯度Boost(XGBoost)分类器(Chen和Guestrin 2016))。最后,使用神经网络作为元分类器来整合k个单独的基本分类器来进行风险分层(图1D)。
磁共振成像数据采集与后续认知评估
CCHMC网站的队列由辛辛那提婴儿神经发育早期预测研究(简称CINEPS队列)的早产儿组成(Parikh等人,2021)。所有在2016年9月至2019年11月出生于胎龄32周或之前、在俄亥俄州辛辛那提五家III/IV级新生儿重症监护病房(NICU)之一接受护理的婴儿,包括CCHMC、辛辛那提大学医学中心、善心撒玛利亚医院、圣伊丽莎白医疗保健和凯特琳纪念医院,都有资格纳入CINEPS。NCH网站的另一组研究(称为哥伦布早期预测研究COEPS)从俄亥俄州哥伦布市四家III/IV NICU之一(包括NCH、俄亥俄州立大学医学中心、河滨医院和卡梅尔圣安医院)招募了出生于31周或以下(2014年12月至2016年4月)的早产儿。经过初步招募讨论和相关同意,所有极早产儿在NICU出院后被医学转移到CCHMC站点(CINEPS队列)或NCH站点(COEPS队列)进行MRI扫描。如果观察到任何已知的先天性脑异常或严重损伤,婴儿被排除在CINEPS和COEPS队列之外(Logan等人,2021年)。CINEPS队列用于模型开发和内部交叉验证,而独立的COEPS队列用作外部验证的看不见的测试数据集。在CCHMC现场,CINEPS受试者在月经后39-44周,在3T飞利浦雌驼龙扫描仪上进行非镇静睡眠的成像,该扫描仪带有32个接收头线圈。轴向T2加权Turbo自旋回波序列的采集参数为重复时间(TR)=8300ms,回波时间(TE)=166ms,FA=90°,分辨率1.0×1.0×1.0mm3,时间3:53min。在NCH站点,COEPS受试者在PMA 38-43周非镇静睡眠期间使用32通道接收头线圈在3T MRI扫描仪(Skyra;Siemens Healthcare)上进行扫描。轴向T2加权快速自旋回波序列的采集参数为:TR=9500ms,TE=147ms,FA=150°,分辨率0.93×0.93×1.0mm3,时间4:09 min。所有受试者在校正年龄2岁时使用贝利婴幼儿发展量表III(Bayley III)测试(Bayley,2006)进行评估。贝利III认知分测验分数(40-160分,平均分100分,标准差显示(SD)作为婴儿认知发展功能水平的主要衡量标准。
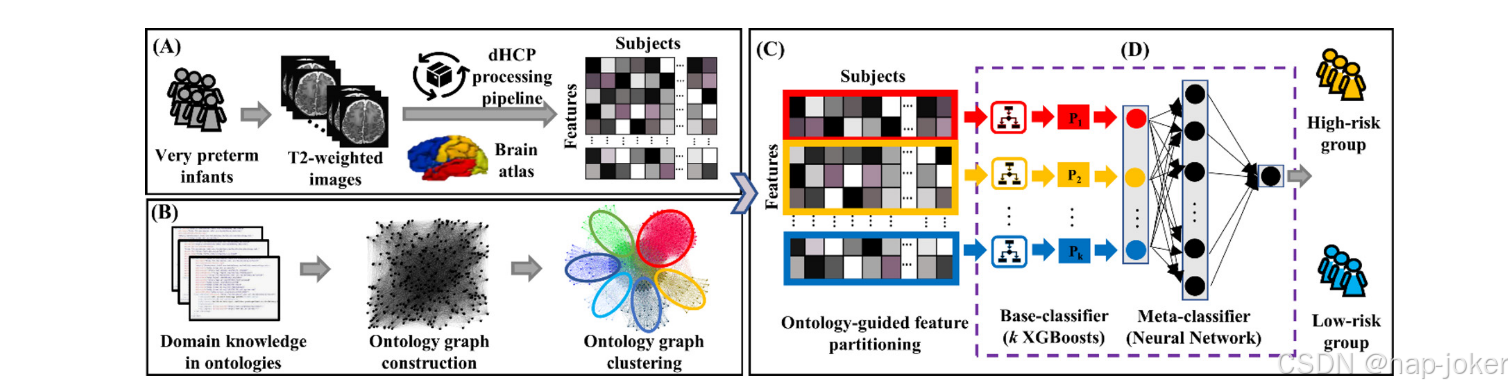
图1。OAP-EL示意图,用于早期预测2岁时的认知缺陷,使用大脑成熟度和来自极早产儿在相当于足月年龄获得的T2加权磁共振成像的几何特征的校正年龄。(A)大脑成熟和几何特征提取;(B)本体图构建和聚类;(C)本体论指导的特征划分;(D)基分类器训练和集成。
MRI数据的预处理、脑成熟及几何特征提取
我们对每个受试者的T2加权MRI数据进行了预处理,并使用DHCP结构管道提取了大脑成熟和几何特征(Makropoulos等人,2018年)。简而言之,该管道进行了偏场校正(Tustison等人,2010年)、脑提取(Smith,2002;Makropoulos等人,2014)和脑表面重建(Scheh等人,2017)。该管道根据年龄匹配的新生儿体积图谱,将整个大脑图像分割成87个感兴趣区(ROI)(Gousias等人,2012;Smith,2002)。对于单个大脑ROI,计算了多达六种不同类型的大脑成熟和几何指标,包括体积、厚度、脑沟深度、曲率、旋转指数和表面积。值得注意的是,对于某些ROI,并不是所有上述指标都可用。例如,DHCP管道仅提取海马体的体积指标。此外,DHCP管道计算体积和表面积指标的绝对和相对指标,这些指标高度依赖于个人大脑的大小。使用绝对测量除以全脑测量来计算相对测量。通过从整个大脑中提取的DHCP管道,计算了510个大脑的成熟度和几何特征。对于体积和表面积度量类型,我们只保留了相对测量来减少个体大脑大小差异的影响。通过这种方式,我们从受试者的T2加权MRI数据中获得了338个大脑成熟和几何特征的列表。我们在补充材料中提供了510项功能的完整列表和338项功能的最终列表。该脑特征向量(1×338)被用作我们提出的OAP-EL模型的输入。同时,可以构建本体图(第2.4节),其中图中的节点数量等于特征的数量(即338个特征)。
本体图构建
我们利用两个预先定义的本体来表示特征之间的潜在关系,这两个本体分别定义了大脑分割以及大脑成熟度和几何形状。大脑分割本体论描述了将整个大脑分割成9个组织(例如,皮质灰质、白质等)。(Makropoulos等人,2018年)和87个地区(Makropoulos等人,2018年;Gousias等人,2012年;Makropoulos等人,2014年)(例如,额叶、海马体、脑岛等)。大脑成熟和几何本体列出了六个大脑成熟指标,包括体积、皮质厚度、脑沟深度、曲率、脑回指数和表面积(Makropoulos等人,2018年)。为了促进知识共享,我们用Web Ontology Language(OWL)格式表达了这两个本体,典型的OWL处理包可以读取或可视化这两个本体,例如Python中的Owlready2(数据和代码可用性)。利用存储在上述两个本体中的领域知识,我们构建了一个未加权的本体图𝐺,在该图中,动态主机配置协议的脑成熟度和几何特征(即来自动态主机配置协议管线的338个特征)被认为是顶点𝑉=𝑣1,...,𝑣𝑛和本体派生的关系是边𝐸=𝑒1,...,𝑒𝑛。如果两个特征量化了相同的大脑成熟度和几何指标(例如,左额叶体积和左枕叶体积)或描述了相同的大脑部分(例如,左枕叶体积和左枕叶表面积),则将两个顶点𝑒和∈𝐸之间的边𝑣𝑖ij𝑣𝑗∀𝑖,𝑗∈𝑛的值设置为1,否则,我们将其设置为0(图2)。
本体引导的属性划分集成学习(OAP-EL)模型
与最常用的属性打包方法(Bryll等人,2003;Ho,1998)不同,我们通过谱聚类算法(Ship和Malik,2000)进行本体图聚类以进行特征划分。给定我们的未加权本体图𝐺=(𝑉,𝐸),图的拉普拉斯矩阵被定义为𝐿=𝐷−𝐴,其中图𝐴的相似度矩阵𝐺,𝐷是图𝐺的度矩阵。由于𝐿∈𝑅𝑛×𝑛是半正定矩阵,因此𝐿的特征分解定义为𝐿=𝑈Λ𝑈−1,其中𝑈∈𝑅𝑛×𝑛的𝑖𝑡ℎ列是𝑢𝑖的特征向量,而𝑈×Λ∈𝑍𝑛0是对角矩阵,其对角元Λ𝑖𝑖=λ𝑖与其特征值对应。谱聚类算法通过对𝑈𝑘的前k个特征向量𝐿执行k-均值,从而输出k组聚类标签,使得,𝑈𝑘∈𝑅𝑛×𝑘⊆𝑈。集群数量𝑘是一个超参数,可以根据下游任务的性能进行优化。最后,我们将大脑成熟度和几何特征划分为k个互不重叠的特征子集。使用k个不重叠的OAP特征子集,我们构建了𝑘XGBoost模型(Chen和Guestrin2016)作为基本分类器。假设𝑐𝑖∈𝐶∀𝑖∈1,...,𝑘是𝑖𝑡ℎOAP功能子集,𝑓𝑏𝑖∈𝐹𝑏∀𝑖∈1,...,𝑘表示𝑖𝑡ℎ基分类符。为了训练每个𝑓𝑏𝑖,我们将损失函数最小化:
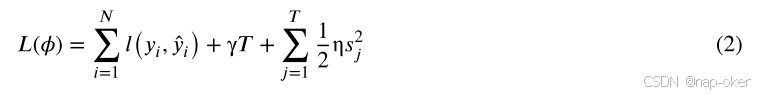
其中,𝑙(𝑦𝑖,̂𝑦𝑖)表示真标签𝑦𝑖和预测̂𝑦𝑖,𝛾之间的凸函数,η表示用于通过调整对应于其分数𝑠𝑗的输出的叶节点j的数目来惩罚模型复杂性的收缩参数。每个𝑓𝑏𝑖获取与𝑐𝑖对应的数据集的输入,并产生概率结果𝑝̂𝑖=𝑓𝑏𝑖(𝑐𝑖)∀𝑖∈1,...,k。因此,𝑃̂=𝐹𝑏(𝐶)其中𝑃̂=̂𝑝1、...,̂𝑝k表示来自𝐹𝑏的一组概率,这些概率将作为元分类器的输入
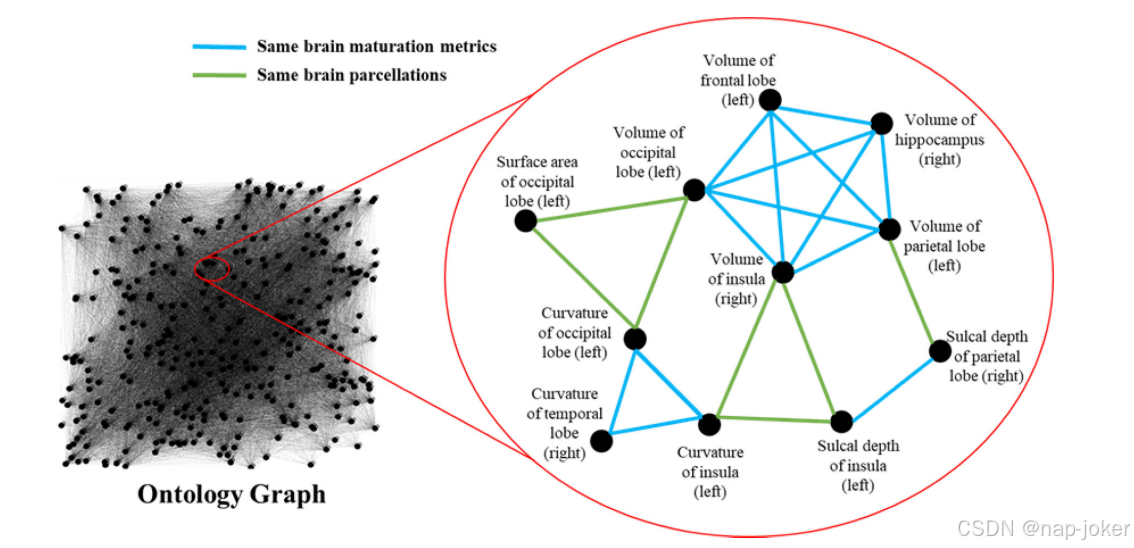
图2.带有放大的子图的本体图。基于两个预定义本体中的领域知识,如果两个顶点量化了相同的大脑成熟度和几何度量或描述了相同的大脑部分,则它们是相连的,否则它们是断开的。
我们使用神经网络模型作为元分类器𝑓𝑚来集成𝑘概率̂𝑝𝑖∈̂𝑃∀𝑖∈1,...,𝑘of𝑓𝑏𝑖∈𝐹𝑏∀𝑖∈1,...,𝑘。该神经网络包括输入层、全连接隐含层和输出层,其中隐含层采用整流线性单元(RELU)作为激励函数,输出层采用Sigmoid函数。最终概率结果̂𝑝∗可以定义为̂𝑝∗=𝑓𝑚(̂𝑃)=1+EXP(−(0,𝑊̂𝑃+𝑏)+)−1,其中𝑊和𝑏是权重矩阵和偏差。为了训练𝑓𝑚,我们用𝐿2范数正则化最小化二元交叉熵损失函数,这是由下式给出的:
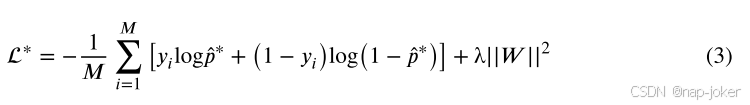
其中𝑀是样本大小,𝑦𝑖表示𝑖𝑡ℎ类别标签∀𝑖∈1,...,𝑀,𝜆是𝐿-2范数正则化的系数,惩罚了权矩阵𝑊,避免了过拟合问题。为了选择𝜆和Maximum Depth𝑚的超参数,我们使用网格搜索(即𝜆=0.001,0。01,0。1;𝑚=2,4,6,8)。我们使用ADAM优化算法训练具有1000个历元的元分类器的神经网络,学习率为0.01%,𝜆=0。𝐿-2正则化选择0.0 1。
内部和外部模型验证
我们使用内部和外部验证实验对所提出的OAP-EL模型进行了评估,性能指标包括准确性、敏感度、特异度和受试者工作特征曲线(ROC)下的面积。为了评估模型在阳性少数样本上的性能,我们绘制了精度-召回(PR)曲线,并计算了PR曲线下的面积(PRAUC)。我们进一步报告了100个实验重复的性能指标的平均值和标准差。对于内部验证,我们使用CINEPS队列和嵌套的留下一次交叉验证(LOOCV)策略来训练和测试模型,该策略包括一个外环和一个内环。在外部LOOCV循环中,我们在N次迭代中将数据集分离为训练验证数据(N-1个样本)和测试数据(1个样本),并反复重复这一过程,直到所有受试者都被视为测试数据。性能指标是根据测试数据计算的。在LOOCV内部循环中,使用训练验证数据(N-1个样本)优化了模型超参数,而没有看到任何测试数据。对于外部验证,我们使用未见的独立COEPS队列测试了内部验证的模型。为了解决数据不平衡的问题,我们在LOOCV数据分割后的训练数据集上应用了一种数据合成方法。对于CINEPS数据集,与1:2的低风险组相比,高风险组中极早产儿的数量较少。在数据集不平衡的情况下,机器学习模型容易成为多数类分类器,即它们无法学习少数类的概念。为了克服这一挑战,我们首先使用合成少数族裔过采样(SMOTE)方法为少数族裔班级生成新的合成样本(仅用于模型训练)(Chawla等人,2002年)。具体地说,我们从少数民族中随机选择一个样本,得到它的五个最近邻域。我们在选定的次要样本和其最近的相邻样本之间插入新的合成样本。我们重复这一过程,直到训练数据集中高风险和低风险受试者的比例为1:1。接下来,我们实施编辑最近邻(ENN)方法(Batista等人,2004)。我们还在多数类中随机选择了一个样本,得到了它的五个最近邻域。如果所选样本的类别与其最近的五个相邻类别不同,则这些样本被移除,而不考虑其在多数类别或少数类别中的类别标签。重复这一过程,直到训练数据集中的高风险和低风险受试者的比例为1:1。该过程被称为SMOTE-ENN方法(Batista等人,2004),更多细节如补充表1所示。我们将我们提出的模型与(1)传统机器学习模型进行比较,包括K-近邻(KNN)(Fix和Hodges,1989)、Logistic回归(LR)(Cox,1958)、支持向量机(SVM)(Cortes and Vapnik,1995)、决策树(DT)(DT)(Wu et.2008)、随机森林(RF)(Ho,1995),神经网络(NN)(McCulloch和Pitts,1943);(2)同伴集成学习模型,包括Vting(Dietterich,2002)、Bging(Breiman,1996)、Stagking(Wolpert,1992)和属性Bging-EnSemble学习(AB-EL);(3)我们在先前研究中发展的多通道神经网络(MNN)(Chen et al.,2019)。所有模型的详细实施可在补充材料中找到。所有机器学习实验都是在一个工作站上进行的,该工作站配备了Intel(R)Core(TM)i5-10600KF CPU(4.10 GHz)、8 GB RAM和NVIDIA GeForce GTX 1660超级图形处理器。使用Python3.7、TensorFlow 2.3.0和Scikit-Learn0.24.1进行实验编码。
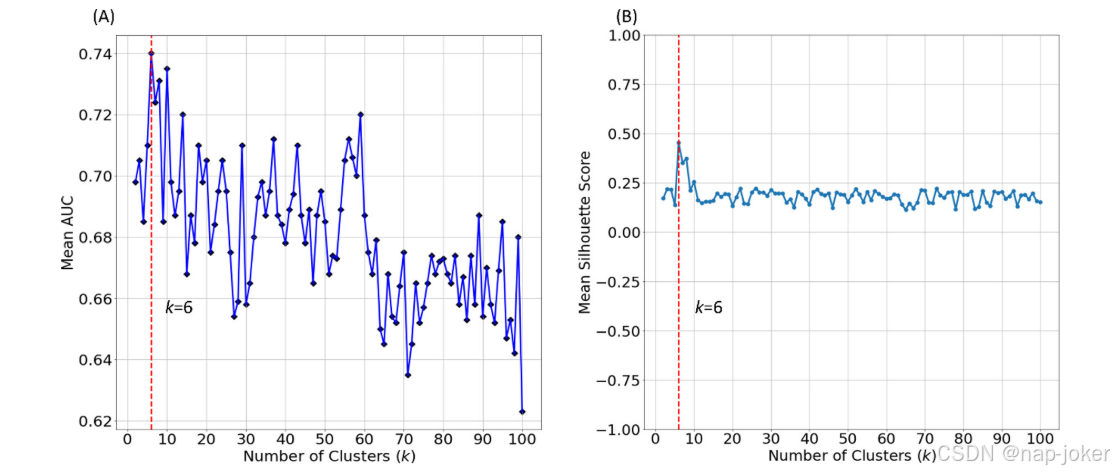
图3.用于早产儿认知缺陷早期预测的特征簇k个数的最优化。(A)具有不同簇数的预测模型的平均AUC。(B)不同数量的集群的平均轮廓得分。
区分性特征识别
我们利用两级特征重要性排序策略,确定并报告了对预测认知缺陷贡献最大的最具辨别性的大脑几何特征。在我们的OAP-EL模型中,假设𝑊表示元分类器的连接权重,权重𝑤𝑖∈𝑊∀𝑖∈1,...,𝑘对应于𝑖𝑡ℎ基分类词。设𝛽𝑖𝑗∈B𝑖∀𝑗∈1,..,\|𝑐𝑖\|,𝑐𝑖∈𝐶]是使用信息增益的𝑗𝑡ℎXG Boost基分类器的𝑖𝑡ℎ特征重要性分数(Azhagusundari和Thanamani,2013),其中|𝑐𝑖|是𝑖𝑡ℎ基分类器内的特征的大小。大脑成熟度和几何特征的全球排名分数定义为𝑤𝑖∑𝑘𝑖=1𝑤𝑖⋅𝛽𝑖𝑗𝑚𝑎𝑥(B𝑖)。
统计分析
为了检验高危和低危婴儿之间的人口学差异,我们使用两样本学生t检验来比较连续变量的平均值,包括出生体重、出生时胎龄(GA)、扫描时的月经后年龄(PMA)和认知得分,并使用皮尔逊卡方检验来比较性别分布。为了比较不同的预后模型,我们使用了非参数的Wilcoxon检验。对于所有推理测试,p值小于0.05被认为具有统计学意义。所有统计分析用R-4.0.3(美国马萨诸塞州波士顿RStudio)进行。
结果
寻找最优特征聚类数k
使用内部验证队列优化了特征簇的数量。具体地说,我们测试了经验值从1到100的簇k的数量,以1为增量。对于每个k,我们重复嵌套LOOCV 100次以评估预测性能。图3(A)显示了不同聚类数k的平均AUC。根据最高的平均AUC,在后续实验中,我们将最佳特征聚类数设置为6。此外,我们还使用Silhouette评分来评估本体引导的聚类的优劣。轮廓分数是衡量对象(即特征)与其自己的簇相比与其他簇的相似程度的量度。它的范围是从−1到+1,其中值越大表示对象聚集得更好。我们为本体图中的每个特征计算了一个轮廓分数,并且计算所有特征的平均轮廓分数。补充材料中包含了平均轮廓分数的详细计算。图3(B)显示,与其他数目的特征聚类相比,最佳数目的特征聚类(k=6)似乎具有最高的轮廓得分,这表明我们提出的OAP能够仅使用先验领域知识将特征划分为更好的聚类。此外,使用谱聚类的本体图(k=6)如图4所示。气泡和链接表示样本节点(即特征)和边,以说明一些聚集的特征示例。我们进一步分析了从我们的OAP方法派生的特征簇。我们举例说明了特征类型和代表性ROI在六个特征簇中的分布。(图5)我们从图5(A)中注意到,从本体图生成的每个特征簇由一种特征类型主导,并且没有一个特征簇包含单一特征类型。这清楚地表明,不同类型的大脑度量具有互补的信息,这可能会提高基分类器的区分能力。另一方面,从图5(B)中,我们观察到所有特征簇都以与颞叶相关的特征为主。这很简单,因为采用的大脑分割本体将颞叶划分为比其他主要脑叶和区域更多的子区域,从而导致更多的颞叶特征。
CINEPS队列的内部验证
我们纳入了207名极早产儿(平均(SD)GA为29.4周;出生体重为1288.3(434.5)g),他们完成了来自CINEPS队列的为期2年的认知评估以进行内部验证。(表1)我们将Bayley III认知评分低于或等于85分(即低于平均分1 SD)的婴儿定义为高风险组(N=69),将认知评分大于85的婴儿定义为低风险组(N=138)。在CINEPS队列中,高风险组和低风险组之间的样本比例为1:2。高危组出生体重1184.1 g(489.3 g),胎龄42.5周(1.3周),男性43例(62.3%)。低风险组出生体重为1340.5(397.3)g,胎龄42.4(1.3)周,男性67例(48.6%)。两组间在出生体重(p=0.02)、出生时胎龄(p<;0.001)和认知评分(p<;0.001)方面有显著差异,而在性别(p=0.08)和经后扫描年龄(p=0.48)方面没有显著差异。
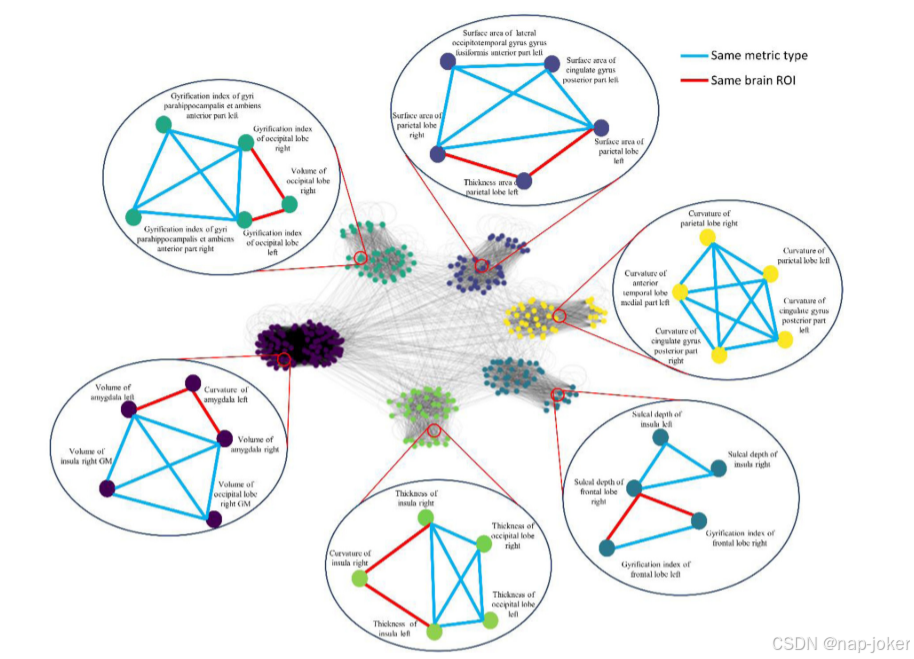
图4.使用谱聚类算法将本体图划分为最优聚类数(k=6)。每个簇中的样例节点和边显示在气泡中。节点根据它们的簇进行着色。边缘颜色被添加到指示相同的度量类型(蓝色)或相同的大脑ROI(红色)(有关此图图例中对颜色的引用的解释,读者请参阅本文的网络版本)。
个体本体对OAP-EL的影响
我们首先调查了个体本体对我们早期预测任务的影响。我们分别使用(1)脑度量本体、(2)脑分割本体和(3)组合本体构建了三个本体图。对所有的本体图进行特征聚类,利用内部队列建立OAP-EL模型。如表2所示,使用组合本体的OAP-EL模型的平均AUC值为0.74,显著高于使用大脑度量本体(AUC=0.69,p<;0.001)或脑分割本体(AUC=0.61,p<;0.001)的OAP-EL模型。这说明个体大脑本体有其自身的辨别能力,而将本体结合在一起能够通过利用个体本体的互补知识来进一步提高整体辨别能力。
OAP-EL模型的性能优于传统机器学习模型
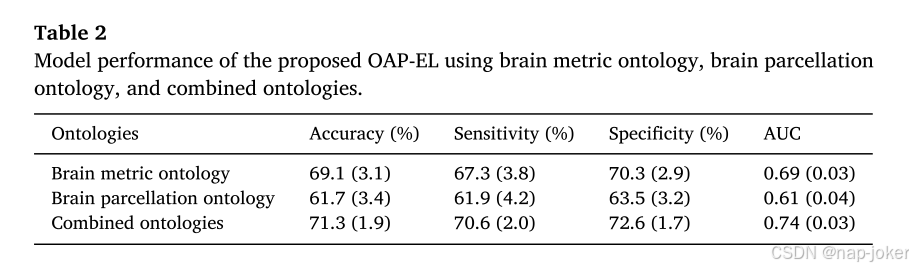
图6显示了我们提出的OAPEL模型和传统机器学习模型在检测具有中/重度认知缺陷高风险的极早产儿方面的性能比较。与性能最好的传统机器学习模型支持向量机相比,该模型的准确率提高了8.2%(p<;0.001),灵敏度提高了9.0%(p<;0.001),特异度提高了7.5%(p<;0.001),AUC值提高了0.1%(p<;0.001)。
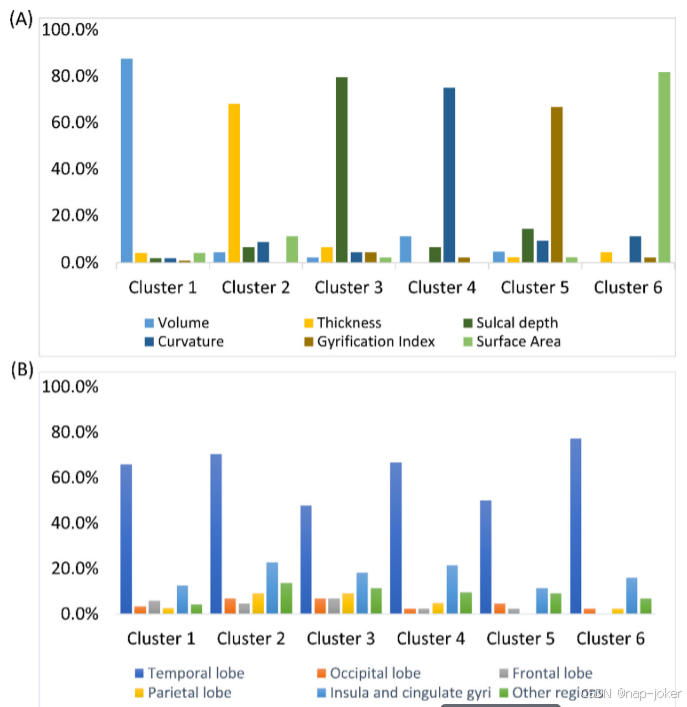
图5。(A)大脑指标和(B)大脑区域在特征簇之间的分布。对于那些包含很少特征的大脑区域(海马体、杏仁核、小脑、脑脊液),我们将它们合并为"其他区域"以便于可视化。
 ROC和PR曲线都表明我们的OAP-EL模型具有更好的预测性能。(图7)与其他传统机器学习模型相比,我们提出的OAP-EL获得了更好的AUC和PRAUC。我们将所提出的OAP-EL模型与几种对等集成学习模型进行了比较,包括投票、装袋和不带/带属性装袋的堆叠方法。预测性能如表3所示。在同级集成学习模型中,我们提出的OAP-EL模型取得了最好的预测性能。与AB-EL模型相比,该模型显著提高了预测精度3.8%(p<;0.001)、灵敏度5.4%(p<;0.001)、特异度4.2%和AUC0.05(p<;0.001)。图8说明了集成学习模型的ROC和PR曲线。ROC曲线表明我们的OAP-EL模型具有更好的预测性能,PR曲线表明我们的OAP-EL模型的性能优于同行集成学习模型,并且有更大的差距。为了评估谱聚类算法对本体图的影响,我们进一步比较了OAP派生特征聚类(k=6)和随机特征聚类(k=6)的模型性能(图9)。使用OAP派生的特征聚类(k=6)的模型获得了71.3%的准确率、70.6%的敏感度、72.6%的特异度和0.74的AUC。其准确率为64.1%(p<;0.001),敏感度为63.6%(p<;0.001),特异度为67.2%(p<;0.001),AUC0.66(p<;0.001)。
ROC和PR曲线都表明我们的OAP-EL模型具有更好的预测性能。(图7)与其他传统机器学习模型相比,我们提出的OAP-EL获得了更好的AUC和PRAUC。我们将所提出的OAP-EL模型与几种对等集成学习模型进行了比较,包括投票、装袋和不带/带属性装袋的堆叠方法。预测性能如表3所示。在同级集成学习模型中,我们提出的OAP-EL模型取得了最好的预测性能。与AB-EL模型相比,该模型显著提高了预测精度3.8%(p<;0.001)、灵敏度5.4%(p<;0.001)、特异度4.2%和AUC0.05(p<;0.001)。图8说明了集成学习模型的ROC和PR曲线。ROC曲线表明我们的OAP-EL模型具有更好的预测性能,PR曲线表明我们的OAP-EL模型的性能优于同行集成学习模型,并且有更大的差距。为了评估谱聚类算法对本体图的影响,我们进一步比较了OAP派生特征聚类(k=6)和随机特征聚类(k=6)的模型性能(图9)。使用OAP派生的特征聚类(k=6)的模型获得了71.3%的准确率、70.6%的敏感度、72.6%的特异度和0.74的AUC。其准确率为64.1%(p<;0.001),敏感度为63.6%(p<;0.001),特异度为67.2%(p<;0.001),AUC0.66(p<;0.001)。
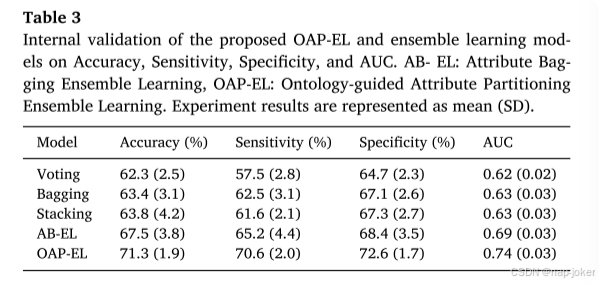
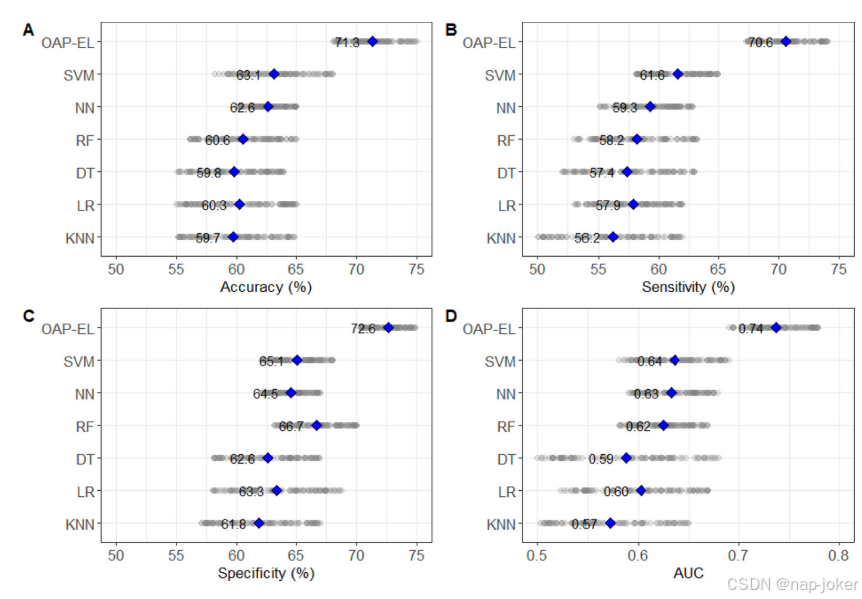
图6.提出的OAP-EL模型和传统机器学习模型在(A)准确性、(B)敏感性、(C)特异性和(D)AUC方面的内部验证。KNN:K-近邻;LR:Logistic回归;支持向量机;DT:决策树;RF:随机森林;NN:神经网络;OAP-EL:本体引导的属性划分集成学习。突出显示的点表示测量的平均值。
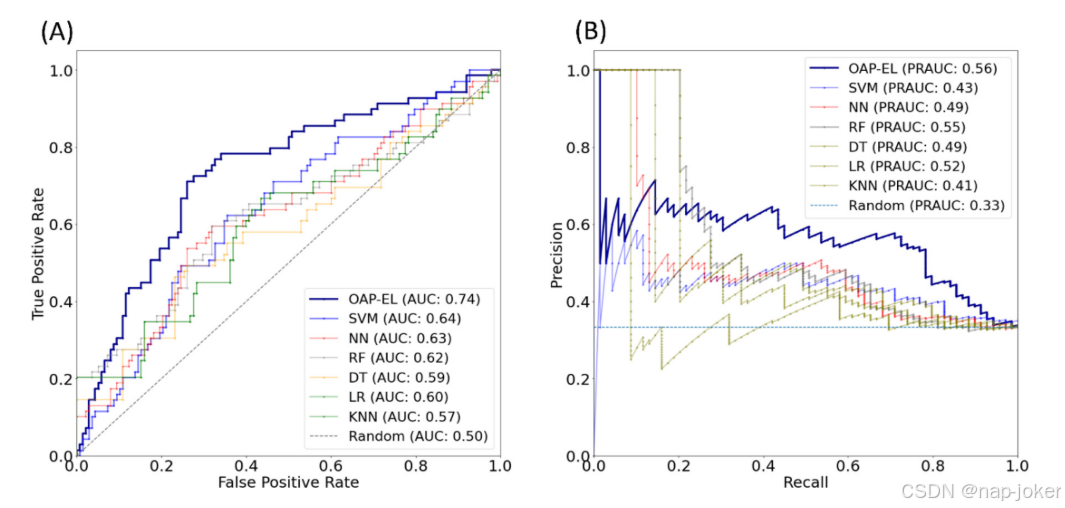
图7.使用(A)接收器操作特性曲线和(B)精度-召回曲线进行内部验证的OAP-EL方法和传统机器学习方法的模型性能比较。AUC-ROC曲线下的面积;PRAUC-精度-召回曲线下的面积。3.2.3 OAP-EL优于同级集成学习模型
OAP-EL优于OAP增强的多通道神经网络(OAP-MNN)
我们将提出的OAP-EL模型与OAP-MNN(补充材料)模型进行了比较。我们观察到,与OAP-MNN相比,提出的OAP-EL具有更好的预测性能,准确率为5.4%(p<;0.001),敏感度为4.8%(p<;0.001),特异度为2.2%(p<;0.001),AUC0.04%(p<;0.001)。图11中的PR曲线表明,尽管OAP-EL和OAP-MNN的ROC曲线看起来相似,但我们的OAP-EL模型的预测性能明显好于OAP-MNN模型。
不同脑度量型对消融影响的研究
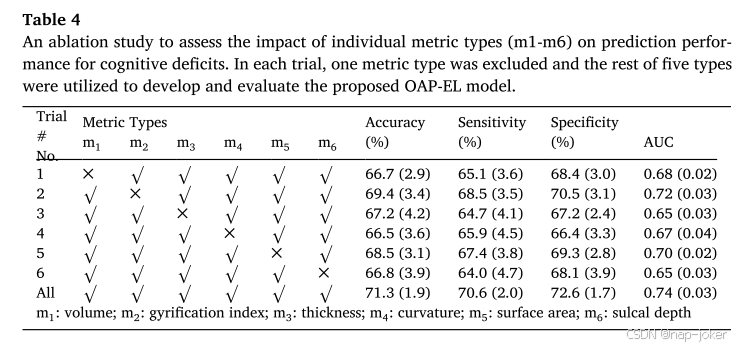
在这一部分,我们进行了一项消融研究,以评估个体大脑成熟和几何测量类型的影响。具体地说,我们删除了一种类型的度量,只利用了五种类型中的其余类型来开发和评估所提出的OAP-EL模型。例如,我们在一次试验中排除了所有与脑体积度量相关的特征,并保留了所有其他特征。我们总共进行了六次试验,其中每一次我们只排除了一种类型的指标。表4显示了OAP-EL模型在所有试验中的预测性能。OAP-EL模型在试验2中达到了最好的精度,在试验2中,我们去掉了与回旋指数相关的所有特征。这表明在所有六种度量类型中,陀螺化指数的影响最小。另一方面,在排除所有曲率特征的试验4中,OAP-EL模型的平均预测准确率最低,为66.5%,而当包括所有特征时,平均准确率为71.3%。这意味着曲率特征可能对模型精度的影响最大。总体而言,我们观察到,所有六种测量类型在早产儿认知缺陷的早期预测上都有自己的区分力。
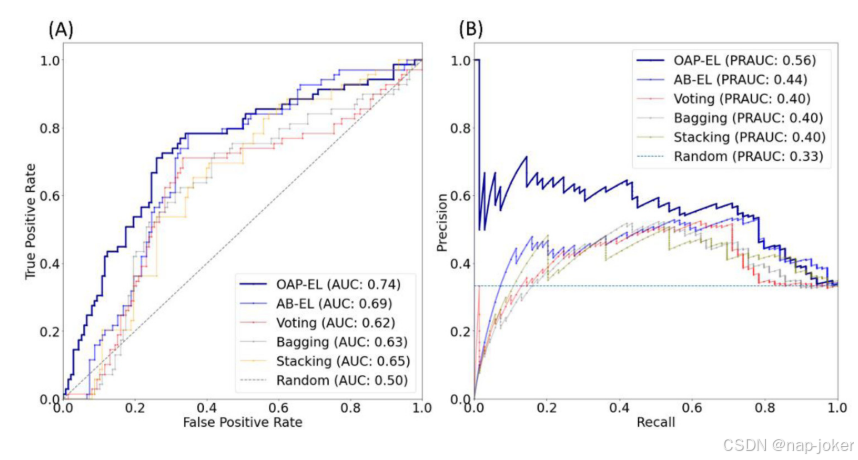
图8.使用(A)接收器操作特性曲线和(B)精度-召回曲线进行内部验证的OAP-EL方法和同级集成学习方法之间的模型性能比较。AUC-ROC曲线下的面积;PRAUC-精度-召回曲线下的面积。
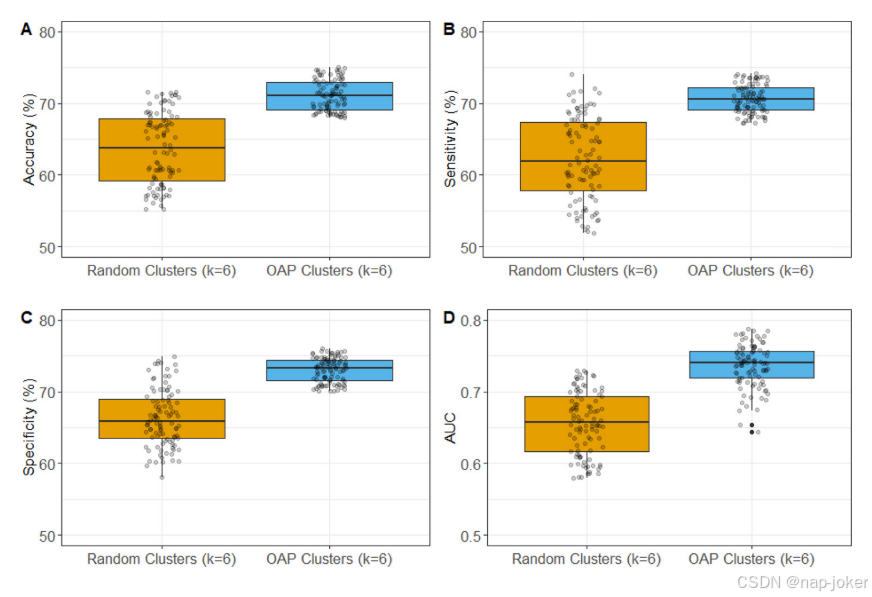
图9使用OAP导出的特征簇(k=6)和随机特征簇(k=6)的模型的预测性能比较。
使用COEPS队列进行外部验证
我们纳入了69名极早产儿,其平均出生体重为1123.6(400.1),平均(SD)GA为28.2.(表5)与CINEPS队列一样,我们使用Bayley III 85作为分界值,以对认知缺陷的风险进行分层。得分小于或等于85的婴儿被定义为高危组(N=10),而得分大于85的婴儿被定义为低危组(N=59)。高危组和低危组的样本比例为∼1:6。高危组出生体重为904.5(358.8)g,平均胎龄2 6.8(2.7)周,平均胎膜早破4 0.4周,男性5例(5 0.0%)。低风险组婴儿平均(SD)GA为28.5(2.2)周,MRI扫描PMA为40.3(0.5)周,
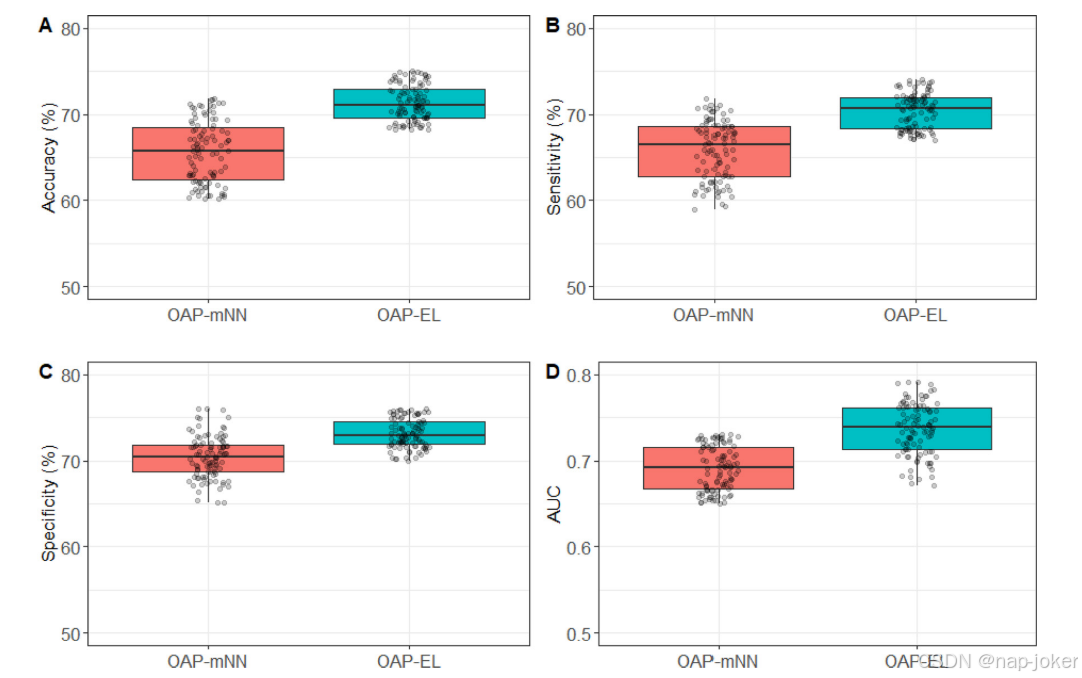
图10认知缺陷的内部风险预测性能与多通道神经网络模型在(A)准确性、(B)敏感性、(C)特异性和(D)AUC方面的比较。OAP-MNN:本体引导的属性划分多通道神经网络OAP-EL:本体引导的属性划分集成学习
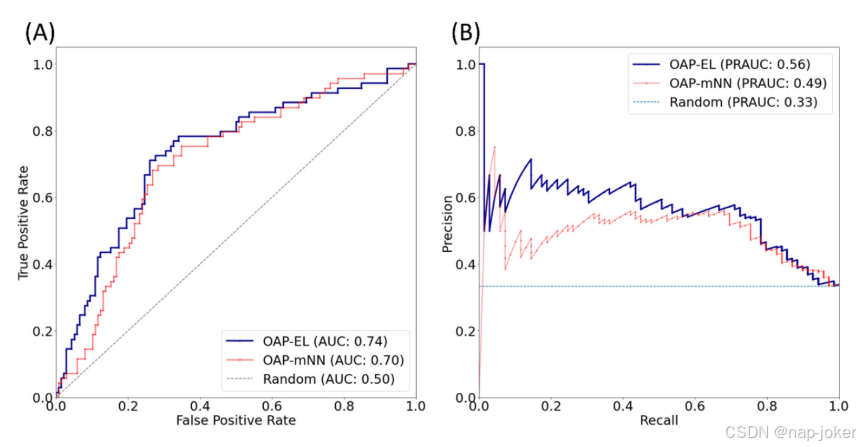
图11.使用(A)接收器工作特性(ROC)曲线和(B)精度-召回曲线进行内部验证的OAP-EL方法和多通道神经网络的模型性能比较。ROC曲线下的面积;PRAUC-精度-召回曲线下的面积。
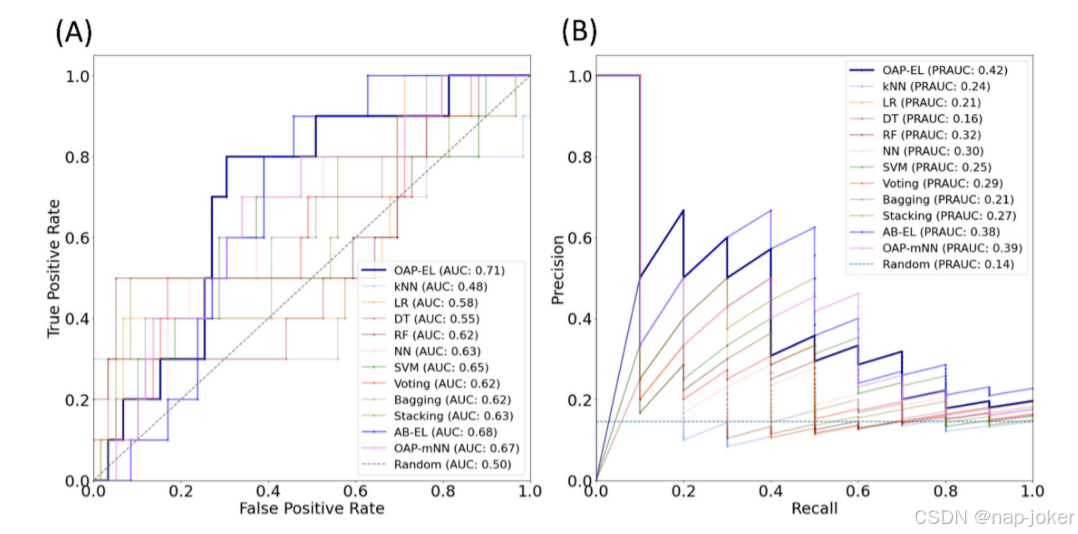
图12使用(A)接收器工作特性(ROC)曲线和(B)精度-召回曲线进行外部验证的OAP-EL方法和所有替代方法之间的模型性能比较。AUC-ROC曲线下的面积;PRAUC-精度-召回曲线下的面积。
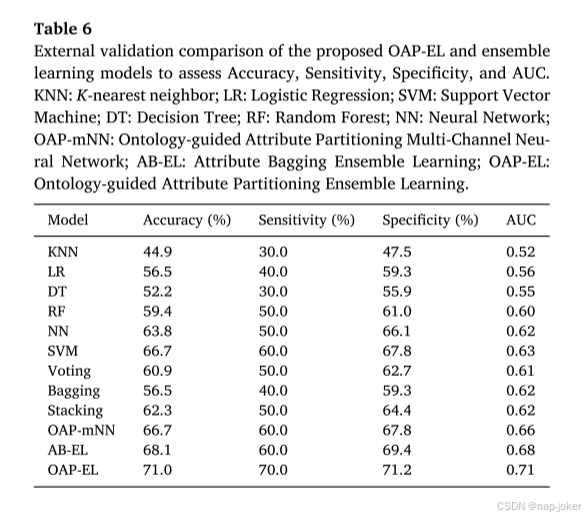
出生体重为1160.8(397.6)克,59名受试者中有25名(42.3%)为男性。与内部队列一样,我们观察到高风险组和低风险组在出生体重(p=0.06)、遗传缺陷(p=0.04)和认知分数(p<;0.001)方面存在显著差异,但在性别(p=0.2)或核磁共振扫描时PMA(p=0.78)方面没有显著差异。使用内部队列的最终训练模型使用该外部队列进行了测试,其性能如表6所示。我们注意到,外部验证的比较结果与内部验证的结果呈现出相似的趋势。(图12)外部验证进一步表明,所提出的OAP-EL模型能够在来自另一个研究站点的未见数据中优于其他传统机器学习和同伴集成学习模型。
最具判别力的大脑成熟和几何特征
为了确定哪些特征对预测认知缺陷的差异贡献最大,我们使用两级特征排名方法(材料和方法)对所有大脑成熟度和几何特征进行了排名。表7显示了我们的OAP-EL模型确定的前15个预测大脑成熟和几何特征以及它们的排名分数。右半球内脑岛区域的厚度被列为最具预测性的特征。然后对左侧大脑半球的内侧回和下回的前部进行脑沟深度测量。在度量类型方面,我们注意到厚度和沟深度是这些顶级特征中的两种常见类型(15种中的9种),尽管其他度量类型也存在。我们进一步可视化了图13中的大脑顶部区域。
讨论
在本文中,我们提出了一种新的OAP特征划分方法,并开发了一个OAP-EL模型,用于使用脑成熟度和等龄时sMRI数据的几何特征来早期预测极早产儿2岁矫正年龄时的认知缺陷。通过对两个独立的早产儿队列进行内部和外部验证,对该模型进行了综合评估。我们提出的OAP-EL内部验证的准确度为71.3%,敏感度为70.6%,特异度为72.6%,AUC为0.74;外部验证的准确度为71.0%,敏感度为70.0%,特异度为71.2%,AUC为0.71。
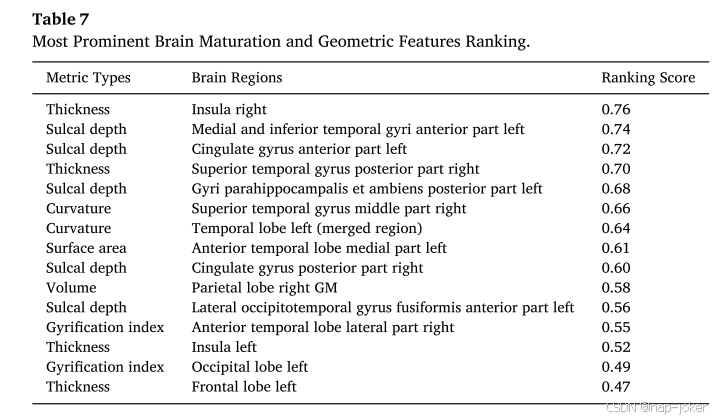
图13.通过本体引导的属性划分集成学习(OAP-EL)模型学习的前15个最具区分性的大脑区域的可视化。
集成模型分类和单个模型分类对比
在临床环境中,对早产儿认知缺陷的早期预测仍然是一项特别具有挑战性的任务。预测分类器可以用不同的特征集来训练,每个预测分类器都有自己的优势和劣势。因此,自然会期望一种利用多个分类器的学习方法会带来更好的性能。为此,集成学习的目标是集成多个分类器以互补彼此的弱点,从而比每个单独的分类器表现出更好的性能(董等人,2020)。对整体学习为什么有效的直观解释是,我们的人性在做出复杂的决定时寻求群体的智慧。这种决定的一个例子是将医疗与特定疾病相匹配(Fitriyani等人,2019年;Raza,2019;Mienye等人,2020;Bhasuran和Natarajan,2018;姚等人,2018)。从理论上讲,有几个原因可以解释集成学习为什么有效,包括避免过度拟合、更高的计算效率和假说强化(Krogh和Sollich,1997;Yang,2017)。我们的内部和外部验证结果实验表明,集成分类器的预测性能明显好于单独的分类器
本体引导的特征分割与随机特征打包的集成学习
特征和分类器的多样性起着关键作用,是建立一个强大的集成模型的充要条件。可以使用不同的特征集来训练基本分类器库中的不同的分类器集。最广泛使用的特征子集划分方案(例如,属性打包)(Bryll等人,2003;Ho,1998)从整个特征集中随机抽取特征子集,这忽略了先验领域知识和特征之间的潜在关系。在这项研究中,我们首次提出将以本体表示的先验领域知识整合到特征划分方案中。实验结果表明,无论是内部验证还是外部验证,基于本体指导的属性划分集成模型的预测性能都明显好于经典的基于属性袋化的分类器。
基于Kappa-Error图的分类器集成经验研究
我们通过描绘Kappa-Error图(一种用于分类器集成的可视化工具)来经验地解释我们提出的OAP集成模型更好的原因(Margineantu和Dietterich,1997)。Kappa-Error图是集成模型的基本分类器库中所有分类器对的散点图(即,每对基本分类器被表示为图上的一个点)。该点的x坐标是两个分类器的输出之间的差异性(表示为K)的量度。两两K定义为K=2(𝑎𝑏−𝑏𝑐)(𝑎+𝑏)(𝑐+𝑑)+(𝑎+𝑐)(𝑏+𝑑),其中a是两个基本分类器正确分类的实例的比例,b是第一个基本分类器正确分类但第二个基本分类器错误分类的比例,c是第一个基本分类器错误分类但第二个基本分类器正确分类的比例,d是两个基本分类器错误分类的比例。K值越低,分类器的差异就越大,填补彼此弱点的机会就越高,从而产生更好的分类器集成。该点的y坐标是该对分类器的平均误分类率。具有𝑘基分类器的集成模型由𝑘(𝑘−1)2点和100𝑘(𝑘−1)2组成的"云"表示重复100次LOOCV的点数。更好的组合将是那些在图表左下角附近有点的"云"的组合(即,高多样性和低个体误差)。图14显示,我们提出的OAP-EL模型产生了更准确和更多样化的个体分类器,因为OAP-EL的"云"更多地位于图形的左下角。这表明了我们看到的OAP-EL更好的整体性能的关键。
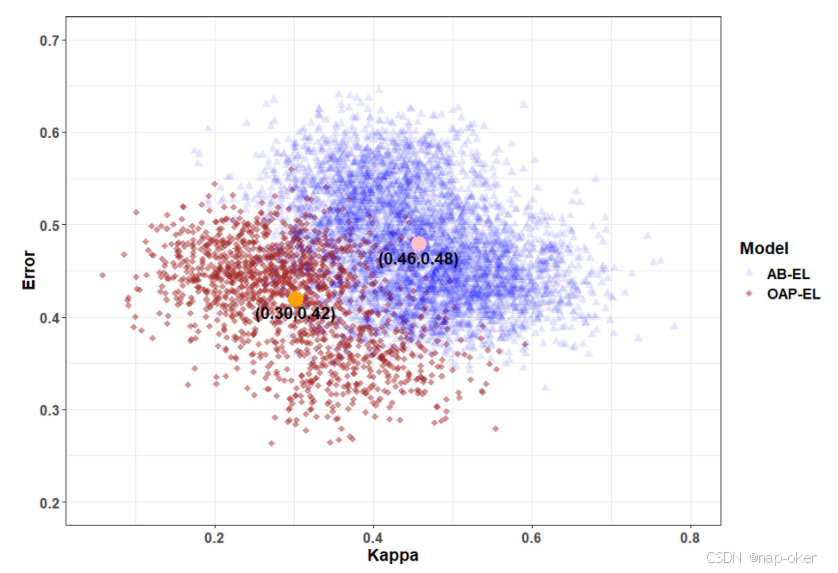
图14 AB-EL和OAP-EL模型的Kappa-Error图。点的x坐标表示成对分类器的分集kappa度量,y坐标表示每对基分类器的平均误分类误差。AB-EL:属性打包集成学习;OAP-EL:本体引导的属性划分集成学习。突出显示的点表示两组的平均值。
分类器集成与特征集成
目前的研究提出集成多个分类器,每个分类器都是使用特征子集训练的单通道分类器。与这种"分类器集成"方法不同,我们还可以训练一个多通道分类器来集成所有特征子集("特征集成"),就像我们在先前的工作中提出的那样(Chen等人,2019年)。我们已经证明OAP-EL模型("分类器集成")比OAP-MNN模型("特征集成")在这一特定应用中的内部和外部验证都要好得多。由于两个模型的特征分割方案是完全相同的,性能差异是可能的,因为多通道模型通常需要相对较大的数据集来达到收敛的稳定训练损失。集成学习模型的参数要少得多,从而减少了潜在的过拟合问题。
数据集不平衡的影响
CINEPS和COEPS队列都有不平衡的数据集,因为患有认知缺陷的早产儿通常比发育正常的早产儿少。这种不平衡的数据集往往会影响我们的研究的两个方面:模型训练和模型评估。在模型训练方面,在数据集不平衡的情况下,机器学习模型偏向于多数类。有一架较小的在CINEPS数据集中,高风险组中极早产儿的数量与低风险组中的极早产儿数量之比为1:2。为了解决这个问题,我们应用了一种数据合成方法SMOTE-ENN,该方法同时为少数类生成新的合成样本,并在多数类中随机删除可能对模型学习产生不利影响的样本。在模型评估方面,我们提供了PR曲线,并计算了内部和外部验证的PRAUC。在今后的临床实践中,更好的做法是正确识别尽可能多的高危极早产儿,以便在治疗对预防产生最大影响的时候进行早期干预。当数据集具有严重不平衡的样本率时,PR曲线将是一种适当的评估方法。PR曲线和PRAUC能够更好地反映少数类中正样本的模型性能,其中ROC曲线和AUC可能不能真实反映模型性能。在PR曲线中,由于随机猜测基线根据正负样本比率变化,因此将我们的模型与随机猜测基线进行比较是至关重要的。在内部验证中,CINEPS数据集的正负样本比率为1:2,导致随机猜测基线的PRAUC为0.33。(图7、8和11)我们的OAP-EL模型在所有竞争模型中的PRAUC最好,为0.56。同样,在外部验证中,随机猜测基线的PRAUC为0.14,而所开发的OAP-EL模型的PRAUC为0.42,是随机猜测基线的3倍。(图12)
最具判别力的大脑成熟和几何特征
使用两级特征排序法,我们确定了15个区分大脑成熟度和几何特征的顶级特征。由OAP-EL模型排序的最具预测性的特征是右侧岛叶皮质的厚度。左岛区厚度(排名第13位)也在包含在我们的功能列表中。岛叶是将额叶和顶叶与颞叶分开的深埋区域。他们参与了一系列不同的大脑功能,包括感知、同情心、自我意识和认知功能(Craig和Craig,2009)。脑岛厚度与非计划性冲动呈正相关,非计划性冲动是一种广泛使用的衡量情绪发展和决策的指标(Churchwell和Yurelun-Todd,2013)。因此,我们的模型将脑岛厚度确定为预测极早产儿认知缺陷的区别性特征也就不足为奇了。研究人员还发现了其他几个与认知相关的大脑区域。例如,我们的OAP-EL模型发现,左侧内侧和下回前部的脑沟深度对认知障碍有显著的预测作用。以往的研究已经证明,中、下回与语言和语义记忆加工、视觉感知和多通道感觉整合有关(Cabeza和Nyberg,2000;Chao等人,1999;Ishai等人,1999;Trael等人,1997)。另一个具有高度区分性的脑区是左侧扣带回前部的沟深度。扣带回被认为高度参与情绪的形成和加工、学习和记忆(Tranel等人,1997;Hadland等人,2003;Stanislav等人,2013)。考虑到额叶和枕叶在学习中的重要作用,有趣的是,我们的模型从每个区域中只选择了一个特征作为预测认知缺陷的前15个区分特征。然而,由于认知功能高度分布在大脑中,对也参与学习和认知的其他大脑区域和特征的选择表明,我们提出的OAP-EL模型能够学习有意义的大脑成熟和几何特征,而不是被随机噪声过度拟合。
研究局限性
目前的研究包含了一定的局限性。首先,本体图的构建可能在不同的研究之间有所不同。关于如何利用领域知识来构建本体图,目前还没有通用的方法。此外,我们只利用领域先验知识构造了一个未加权的本体图。如何有效地利用领域知识来构建一个加权的本体图可能是一个非常有趣的未来方向。其次,应用谱图聚类算法将特征划分为多个互不重叠的子集。在当前的研究中,没有考虑将特征划分为重叠的子集。第三,外部验证数据集(即COEPS队列)是一个小数据集,其中高风险组仅包含10名受试者。这导致了这样一个事实:对少数样本的预测可能会导致模型性能的巨大差异(例如,一个正确预测的早产儿可能会将模型的敏感度从60%提高到70%)。因此,尽管我们的模型在当前研究中的内部和外部验证方面都优于同行模型,但需要更大的外部队列来验证我们建议的模型的普适性。最后,如果将所有功能划分为同一类别,则我们的OAP方法不适用。
总结
我们提出了一种新的OAP增强集成学习模型,该模型集成了大脑成熟和在等同年龄获得的几何特征,用于早期预测极早产儿在2岁校正年龄时的认知障碍。新集成模型的预测性能明显高于传统的机器学习模型和同伴集成学习模型。通过帮助增加基分类器之间的多样性,所提出的技术总体上将促进集成学习。在未来,我们还有兴趣开发本体辅助的机器学习方法,以更好地理解和描述大脑放射和连接特征。