minillava_refactor
文中代码: https://github.com/wz940216/From0to1-MLLM-StudyLog.git
上一篇手搓了minillava模型,并从零开始训练,让qwen1.5具备了多模态能力。
从零到一 | CV转多模态大模型 | week08 | Minillava Training_v1手搓MiniLlava训练推理完整流程
本篇会重新梳理llava的结构细节,从源码出发再次理解llava的核心原理。结合week08的简单实现,重构代码为更合理的结构,并在此过程中加深对llava模型的印象,补充一些细节上的知识点。
S2-Wrapper
llava的源码中,vision tower除了有标准的clip外还有一个s2版本,既多尺度图像特征提取。
python
class CLIPVisionTowerS2(CLIPVisionTower):
def __init__(self, vision_tower, args, delay_load=False):
super().__init__(vision_tower, args, delay_load)
self.s2_scales = getattr(args, 's2_scales', '336,672,1008')
self.s2_scales = list(map(int, self.s2_scales.split(',')))
self.s2_scales.sort()
self.s2_split_size = self.s2_scales[0]
self.s2_image_size = self.s2_scales[-1]
try:
from s2wrapper import forward as multiscale_forward
except ImportError:
raise ImportError('Package s2wrapper not found! Please install by running: \npip install git+https://github.com/bfshi/scaling_on_scales.git')
self.multiscale_forward = multiscale_forward
# change resize/crop size in preprocessing to the largest image size in s2_scale
if not delay_load or getattr(args, 'unfreeze_mm_vision_tower', False):
self.image_processor.size['shortest_edge'] = self.s2_image_size
self.image_processor.crop_size['height'] = self.image_processor.crop_size['width'] = self.s2_image_size
def load_model(self, device_map=None):
if self.is_loaded:
print('{} is already loaded, `load_model` called again, skipping.'.format(self.vision_tower_name))
return
self.image_processor = CLIPImageProcessor.from_pretrained(self.vision_tower_name)
self.vision_tower = CLIPVisionModel.from_pretrained(self.vision_tower_name, device_map=device_map)
self.vision_tower.requires_grad_(False)
self.image_processor.size['shortest_edge'] = self.s2_image_size
self.image_processor.crop_size['height'] = self.image_processor.crop_size['width'] = self.s2_image_size
self.is_loaded = True
@torch.no_grad()
def forward_feature(self, images):
image_forward_outs = self.vision_tower(images.to(device=self.device, dtype=self.dtype), output_hidden_states=True)
image_features = self.feature_select(image_forward_outs).to(images.dtype)
return image_features
@torch.no_grad()
def forward(self, images):
if type(images) is list:
image_features = []
for image in images:
image_feature = self.multiscale_forward(self.forward_feature, image.unsqueeze(0), img_sizes=self.s2_scales, max_split_size=self.s2_split_size)
image_features.append(image_feature)
else:
image_features = self.multiscale_forward(self.forward_feature, images, img_sizes=self.s2_scales, max_split_size=self.s2_split_size)
return image_features
@property
def hidden_size(self):
return self.config.hidden_size * len(self.s2_scales)S2-Wrapper的核心思想是在任何视觉模型上实现多尺度特征提取。传统的视觉模型通常只在单一尺度上处理图像,而S2-Wrapper允许模型在多个尺度上提取特征,从而捕获更丰富的视觉信息。
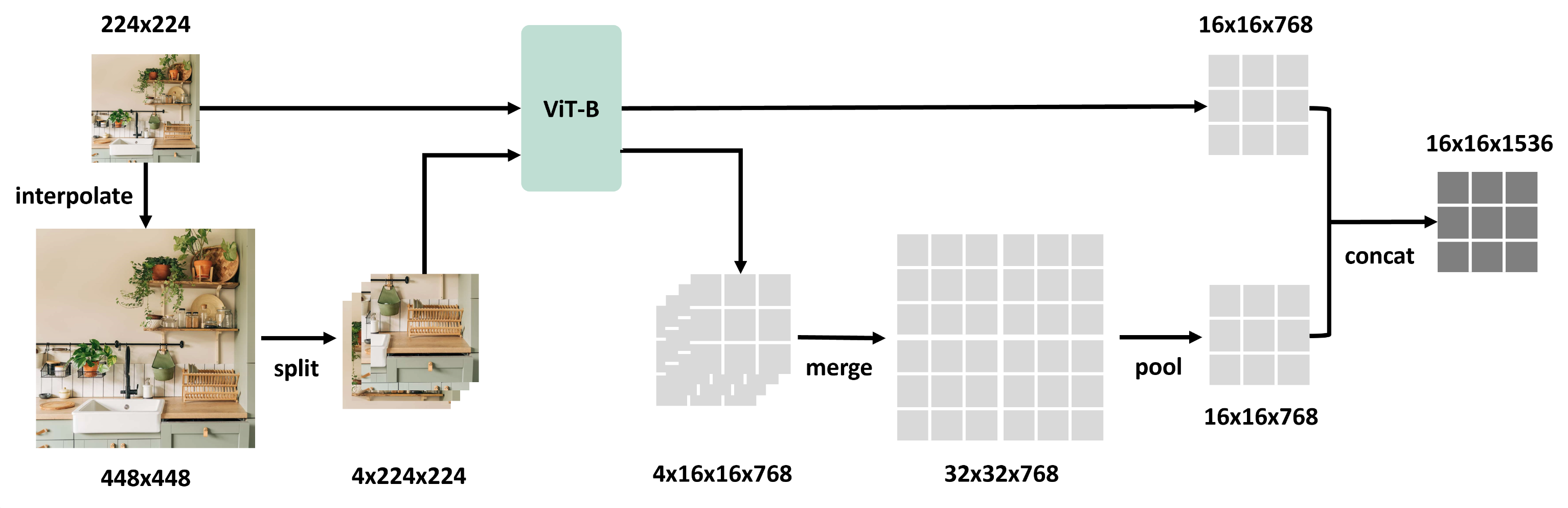
S2-Wrapper的工作流程可以概括为以下几个步骤:
1、调整输入图像到不同尺度
2、每个尺度的图像都通过相同的视觉模型进行处理
3、合并不同尺度的特征,形成更加丰富的特征表示
python
image_feature = self.multiscale_forward(self.forward_feature, image.unsqueeze(0), img_sizes=self.s2_scales, max_split_size=self.s2_split_size)这里的这一句是s2调用的精髓,其中img_sizes是个列表,代表输入图像不同尺度大小,max_split_size表示切块的大小。
为什么要split切块呢?
如果图太大,直接喂ViT后patch太多容易爆显存。所以一种直觉的方式是,将大图切成多块小图后,经过ViT得到小图feature在拼回元空间。
不同尺度的feature长度不同如何拼接?
例如:
python
outputs = [
feat_336,
feat_672,
feat_1008
]一般有三种方法:
1、interpolation
2、pooling
3、patch re-alignment
interpolation
插值实现方法很简单,ViT输出通常是B, N, D,先reshape成B, H, W, D
然后:
python
F.interpolate(feature_map, size=(H_target, W_target))本质是用连续空间假设,让token变密或变稀
优点是简单,快,可微
缺点是语义被拉伸,小目标可能变糊,且这种对齐不是真正对齐patch边界
pooling
高分辨率变低分辨率
同理,这里可以用maxpool或avgpool
python
x = x.reshape(B, H, W, D)
x = avg_pool(x, kernel=2, stride=2)优点是稳定,去噪,保留主要语义
缺点是细节损失严重,小物体容易被吞掉,空间精度下降
patch re-alignment
每个ViT token都对应原图中的一个真实区域:
在多尺度时输入时,不同scale的token数不同,但它们其实都来自同一张原图。所以可以把token映射回原图坐标系再对齐。
方法通常以下三种:
coordinate mapping图像空间对齐
relative position关系空间对齐
grid projection语义空间对齐
mini LLaVA的其他细节
一、Feature Select:该取哪一层的hidden state?
CLIP Vision Tower的forward中会有一步self.feature_select,这个函数的作用是从ViT的多层hidden state中选择实际使用的特征。LLaVA源码中有两种配置:
python
# 方式1:取最后一层(最常用)
image_features = image_forward_outs.last_hidden_state # (B, 1+patch_num, D)
# 方式2:取倒数第二层(base版本默认)
image_features = image_forward_outs.hidden_states[-2] # 可以拿到每一层输出为什么last_hidden_state要去掉cls?
CLS更偏全局摘要,MiniLLaVA需要给LLM更细粒度的图像信息,因此去掉CLS,只保留patch token作为视觉上下文。
关键代码:
python
def forward(self, images):
"""将PIL图片列表编码为patch级视觉特征。
Args:
images: List[PIL.Image],长度为batch size。
Returns:
Tensor,形状为 (B, N, D)。以CLIP ViT-B/16为例,224x224图片会得到
14x14=196个patch,每个patch维度为768。
"""
inputs = self.processor(images=images, return_tensors="pt")
pixel_values = inputs["pixel_values"].to(self.device)
# 冻结VisionTower时关闭梯度,节省显存;不冻结时保留梯度用于端到端微调。
if self.freeze:
with torch.no_grad():
outputs = self.vision_model(pixel_values=pixel_values)
else:
outputs = self.vision_model(pixel_values=pixel_values)
# last_hidden_state形状为 (B, 1 + patch_num, hidden_dim),第0个是CLS。
# CLS更偏全局摘要,MiniLLaVA需要给LLM更细粒度的图像信息,因此去掉CLS,
# 只保留patch token作为视觉上下文。
patch_features = outputs.last_hidden_state[:, 1:, :]
return patch_features这个设计体现了视觉特征粒度与语义之间的权衡,CLS更偏全局摘要,patch更保留空间结构。
二、Projector的设计细节
LLaVA源码中的projector是一个简单的两层MLP,但有几个关键设计决策:
2.1为什么不用单层线性投影?
LLaVA论文实验表明,两层MLP(带GELU激活)比单层线性投影效果好约3% 以上。原因是视觉特征空间和语言特征空间差异很大,单层线性变换表达能力不足,非线性变换可以提供更好的语义对齐能力。
2.2 LayerNorm的位置
python
# LLaVA源码中projector的标准结构
self.linear_1 = nn.Linear(config.mm_hidden_size, config.mm_mlp_dim)
self.linear_2 = nn.Linear(config.mm_mlp_dim, config.hidden_size)
self.gelu = nn.GELU()
self.layer_norm = nn.LayerNorm(config.hidden_size)minillava仓库的Projector把LayerNorm加在输出端,而不是中间隐藏层之后。原因是:
- 视觉特征经过映射后通过LayerNorm可以稳定进入LLM的embedding空间分布
- LLM的词向量通常也有LayerNorm,让视觉特征的分布与文本embedding分布更一致
2.3初始化的讲究
python
# MiniLLaVA中的xavier初始化
def init_weights(self):
for m in self.modules():
if isinstance(m, torch.nn.Linear):
torch.nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
torch.nn.init.zeros_(m.bias)minillava仓库使用显式Xavier初始化。LLaVA官方实现不一定需要这样写,但显式初始化的好处是:
- 避免训练初期projector输出分布偏移过大
- 让视觉特征在进入LLM之前的scale更加稳定
三、Labels构造:-100屏蔽的艺术
这是多模态训练中最重要的细节之一。在LLaVA的collator中,labels的构造需要遵循严格规则:
完整序列: [img_patches] [prompt_tokens] [answer_tokens] [pad_tokens]
labels: [-100]... [-100]... [answer_ids]... [-100]...
python
# 核心逻辑
def __call__(self, features):
images = [x["image"] for x in features]
prompts = [x["prompt"] for x in features]
answers = [x["answer"] for x in features]
# eos可以明确告诉模型回答结束;如果tokenizer没有eos,就退化为空字符串。
eos = self.tokenizer.eos_token or ""
full_texts = [prompt + answer + eos for prompt, answer in zip(prompts, answers)]
tokenized = self.tokenizer(
full_texts,
padding=True,
truncation=True,
max_length=self.max_length,
return_tensors="pt"
)
labels = tokenized.input_ids.clone()
# 逐条计算prompt token长度,并把prompt位置label屏蔽为 -100。
for row, prompt in enumerate(prompts):
prompt_ids = self.tokenizer(
prompt,
truncation=True,
max_length=self.max_length,
add_special_tokens=True
).input_ids
prompt_len = min(len(prompt_ids), labels.size(1))
labels[row, :prompt_len] = -100
# padding不参与训练损失。
labels[tokenized.attention_mask == 0] = -100
return {
"images": images,
"input_ids": tokenized.input_ids,
"attention_mask": tokenized.attention_mask,
"labels": labels
}为什么prompt部分必须屏蔽loss?
- 因果语言模型的CrossEntropyLoss对所有token位置都计算loss
- 如果prompt部分不屏蔽,模型会学习预测用户问题的无意义任务
- LLaVA只需要学习在看到图像和问题后,如何生成正确回答
image token的 -100屏蔽 :
在mini_llava.py的forward中还有一道屏障:
python
# 图片部分全部置 -100
image_labels = torch.full(
(labels.size(0), image_token_num),
-100,
dtype=torch.long,
device=self.device
)
labels = torch.cat([image_labels, labels], dim=1)这是因为视觉token是连续embedding(不是离散token id),无法参与CrossEntropyLoss。
四、LLaVA的两阶段训练策略
LLaVA原版常采用两阶段训练,这是LLaVA和其他多模态模型的重要区别。需要注意:minillava仓库当前没有写两个独立训练入口,而是通过config.yaml的freeze/LoRA配置模拟不同训练策略。
Stage 1的目的 :
只训练projector,让视觉特征能"翻译"到LLM的embedding空间。这一步用的是CC3M等图文对数据,监督信号是语言模型预测caption的loss。
Stage 2的目的 :
解冻LLM(或部分解冻),让模型学习更复杂的指令跟随和视觉推理能力。这一步使用LLaVA-Instruct-150K等指令数据。
关键参数:
python
# 配置文件中的freeze控制
VISION_ENCODER:
FREEZE: true # VisionTower通常全程冻结
LLM_DECODER:
FREEZE: true
LORA_R: 8 # 当前配置启用LoRA;PEFT通常冻结base model,只训练adapter这种"先对齐视觉语义,再联合微调"的思路也被BLIP-2、MiniGPT-4等模型沿用。
当前实现的小坑 :
LLMDecoder中使用if r != 'None':判断是否启用LoRA。当前YAML写LORA_R: 8没问题;但如果写成LORA_R: null,Python读到的是None,仍会满足None != 'None',可能把非法rank传给LoraConfig。更稳妥的判断应同时处理None和字符串"None"。
五、LoRA在多模态模型中的注意事项
LLaVA微调时使用LoRA有几个关键点需要留意:
5.1 LoRA到底作用于LLM的哪些层?
python
# LLaVA中的LoRA配置通常作用于attention模块
self.peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=r,
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
# target_modules: 'q_proj', 'v_proj' 或全部线性层
target_modules=['q_proj', 'v_proj', 'k_proj', 'o_proj']
)为什么不把所有参数都解冻来微调?
- 显存限制:LLM参数量巨大(7B、13B),全参数微调需要多卡
- 灾难性遗忘:完全微调可能导致LLM丢失预训练语言能力
- LoRA用低秩适配矩阵 ΔW来模拟参数更新,训练参数量减少1000倍以上
5.2 LoRA和Projector的协同
通过should_save_param函数可以看到,checkpoint需要同时保存projector和LoRA参数:
python
def should_save_param(name, param):
name = name.lower()
return param.requires_grad or "lora_" in name or ".lora_" in name这里用requires_grad捕获projector和其它可训练参数,用lora_关键字捕获PEFT包的LoRA参数。严格来说,使用PEFT LoRA时base LLM通常仍是冻结的;代码里freeze = False只是避免后续把整个PEFT模型手动冻结。
六、Tokenizer的特殊处理
因果语言模型(Causal LM)的tokenizer经常没有pad_token_id,但训练时batch内序列长度不同必须做padding。LLaVA源码中惯用的解决方案:
python
# 方案1:用eos_token代替pad_token(最常用)
if self.tokenizer.pad_token_id is None:
self.tokenizer.pad_token = self.tokenizer.eos_token
# 方案2:显式设置pad_token
# self.tokenizer.add_special_tokens({'pad_token': '[PAD]'})
# 但增加新token后需要resize词表:model.resize_token_embeddings(len(tokenizer))用eos代替pad为什么不影响训练?
因为padding位置会被attention_mask屏蔽(注意力机制看不到),loss也用 -100屏蔽了,所以padding token的具体值不影响训练效果。但必须注意在generate阶段pad_token_id需要正确设置,否则模型可能把pad当作有效token来生成。
tokenizer的trust_remote_code参数:
python
self.model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True # 兼容部分国产模型仓库的自定义实现
)对于Qwen、ChatGLM等非huggingface原生结构,需要trust_remote_code=True来允许执行模型仓库中的自定义Python代码。
七、多模态Embedding拼接的原理
这是理解LLaVA核心架构最关键的一步。LLM原本只能接收input_ids(离散token),但LLaVA通过inputs_embeds接口绕过了这一限制:
python
# 标准LLM forward:走input_ids路径
# 根据token id查embedding table,得到 [batch, seq_len, hidden_dim]
outputs = self.model(input_ids=input_ids, ...)
# LLaVA的forward:走inputs_embeds路径
# 由外部拼好embedding后直接传入
outputs = self.model(inputs_embeds=inputs_embeds, ...)视觉与文本的拼接流程:
1. 图片 → CLIP ViT → [B, 196, 768] patch_features
2. patch_features → Projector → [B, 196, 2048] projected_visual
3. 文本 → tokenizer → input_ids → embedding_table → [B, L, 2048] text_embed
4. 拼接: concat(projected_visual, text_embed, dim=1) → [B, 196+L, 2048]
5. 扩展attention_mask: concat(ones(196), text_mask, dim=1) → [B, 196+L]关键理解 :
对于LLM来说,视觉token和文本token在输入层没有区别------它们都是[B, N, hidden_dim]的continuous embedding。LLM自动对它们施加同样的causal attention,视觉token在attention计算中会被当作前置上下文。
八、Training阶段的梯度流控制
训练时需要清楚哪些参数参与梯度计算:
image → [CLIP ViT (冻结, no_grad)] → patch_features → [Projector] → proj_features ─┐
├→ concat → [LLM (LoRA)] → logits → loss
text → [tokenizer + embedding (冻结)] → text_embeds ──────────────────────────────────┘ 梯度流经的路径:
- loss.backward() → LLM的LoRA参数(A和B矩阵)获得梯度
- loss.backward() → Projector的两层Linear获得梯度
- CLIP ViT被
torch.no_grad()或requires_grad=False包裹,梯度到此为止 - 文本embedding table通常也被冻结,不参与更新
为什么冻结VisionTower?
- CLIP ViT是在4亿图文对上预训练的,视觉特征已经很通用
- 小数据集上微调VisionTower反而容易过拟合,破坏预训练的视觉语义
- 端到端训练VisionTower对显存消耗极大(ViT-L有300M+ 参数)
九、Generation阶段的KV Cache
训练时设置use_cache=False,生成时使用KV Cache加速:
python
# 训练阶段:不使用KV Cache,每步计算完整的因果attention
outputs = self.language_decoder(
inputs_embeds=inputs_embeds,
attention_mask=combined_attention_mask,
labels=labels,
use_cache=False
)
# 生成阶段:自动使用KV Cache
output_ids = self.language_decoder.model.generate(
inputs_embeds=inputs_embeds,
attention_mask=attention_mask,
max_new_tokens=max_new_tokens,
use_cache=True # generate函数默认启用
)KV Cache在多模态场景的特有问题:
- 视觉token(196个)作为prefix,它们的K/V在生成过程中保持不变
- 每次新token只需要计算新token与全部prefix + history的attention
- 多模态场景下prefix长度(196个视觉token + prompt token)显著长于纯文本场景,KV Cache的加速效果更明显
十、AnyRes:高分辨率图像的处理
LLaVA-1.5引入的一种替代S2-Wrapper的方式,用于支持高分辨率图像。核心思路是将高分辨率图像切分成grid子图,每个子图独立过ViT,再组合特征。
┌───────────────────┐
│cell(1,1)│cell(1,2)│
├───────────────────┤ 每一个cell过ViT,得到特征token
│cell(2,1)│cell(2,2)│
└───────────────────┘
原始图 + 2x2 grid = 5张子图
python
# LLaVA-1.5中AnyRes的关键思路:
# 1. 对原始图做center crop得到base_image (336x336)
# 2. 将原始图resize到合适大小后切分成n个336x336的子图
# 3. 每张子图 + base_image分别送入ViT
# 4. 所有特征拼成一个大序列送入LLMAnyRes vs S2-Wrapper的区别:
- S2-Wrapper是在多尺度上做特征提取,然后合并
- AnyRes是把大图切成小块分别提取特征,然后拼回原图空间网格
- AnyRes产生的token数更多(一张672x672的图产生 (2*2+1) * (336/14)^2 = 5 * 576 = 2880个token)
十一、Delay Load机制
LLaVA源码中有一个delay_load参数,控制vision tower是否在初始化时立刻加载:
python
class CLIPVisionTower(nn.Module):
def __init__(self, vision_tower, args, delay_load=False):
super().__init__()
self.is_loaded = False
if not delay_load:
# 立即加载:训练时使用
self.load_model()
# 延迟加载:推理时先用轻量配置,用到VisionTower时再加载为什么要delay load?
在多卡分布式训练中,如果所有进程在初始化时就加载视觉模型,会造成不必要的显存占用。通过delay_load,VisionTower可以在accelerator.prepare之后才加载,优化显存分配。这也和LLaVA的"先做projector对齐,再端到端训练"的哲学一致。
十二、Config-driven架构设计的启示
从config.yaml可以看到LLaVA风格的训练脚本是如何参数化的:
配置分层原则:
yaml
# 按模块划分配置域,每个域独立可配置
MINILLAVA: # 模型结构参数
VISION_ENCODER: ...
LLM_DECODER: ...
PROJECTOR: ...
DATA: # 数据参数
TRAIN_DATASET: ...
PREPROCESS: ...
TRAINING: # 训练参数
OPTIMIZER: ...
SCHEDULER: ... 这样设计的好处:
- 不同实验只需改YAML,不碰代码
- 每个模块的参数内聚,修改一个域不影响其他域
- 便于后续扩展(比如增加AnyRes配置项、S2配置项)
十三、Accelerate分布式训练的适配细节
python
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, dataloader = accelerator.prepare(model, optimizer, dataloader)Accelerator在多模态训练中的几个关键配合:
- loss聚合:
python
# 多卡训练时,每张卡的loss是局部batch的
# accelerator.gather_for_metrics会收集所有卡的loss并求平均
loss_value = accelerator.gather_for_metrics(loss.detach()).mean().item()- checkpoint保存:
python
if not accelerator.is_main_process:
return # 只有主进程保存checkpoint
unwrapped_model = accelerator.unwrap_model(model) # 解开DDP包装- seed同步:
python
accelerate_set_seed(seed) # 保证多卡场景下数据shuffle一致为什么要用accelerator.unwrap_model ?
accelerator.prepare后的model可能被DistributedDataParallel包装,此时model.named_parameters()获取的参数名会带有module.前缀。unwrap_model可以拿到原始模型,确保checkpoint中的参数名与初始化时一致,方便加载。
十四、数据格式:LLaVA的conversation结构
LLaVA的预训练数据(CC3M)和指令微调数据(LLaVA-Instruct-150K)使用不同的对话格式:
预训练数据格式(CC3M):
json
{
"image": "xxx.jpg",
"conversations": [
{"from": "human", "value": "What is this?"},
{"from": "gpt", "value": "This is a photo of a cat."}
]
}指令微调数据格式(LLaVA-Instruct):
json
{
"image": "xxx.jpg",
"conversations": [
{"from": "human", "value": "<image>\nDescribe this image in detail."},
{"from": "gpt", "value": "The image shows..."},
{"from": "human", "value": "What color is the car?"},
{"from": "gpt", "value": "The car is red."}
]
}多轮对话的处理:
- 第一轮是"看图描述"类型任务
- 后续轮次是"基于视觉上下文的问答"
- 每轮只监督gpt的回答部分,human部分和视觉token全部 -100
<image>占位符的清理:
python
def _clean_text(text):
return text.replace("<image>", "").strip()因为图片已经作为视觉token拼在了序列最前面,文本中不需要再保留<image>标记。
十五、总结:LLaVA的可学习参数与内存分析
假设使用CLIP ViT-B/16 (86M) + Qwen1.5-1.8B (1.8B):
| 模块 | 参数量 | freeze? | 显存占用 |
|---|---|---|---|
| CLIP ViT | 86M | ✅ | ~344MB (推理) |
| Projector | 768×2048 + 2048×2048 ≈ 5.8M | ❌ | ~23MB |
| LLM (Qwen1.5) | 1.8B | 部分(LoRA) | ~7.2GB (bf16) |
| LoRA adapter | r×d × 4 ≈ 0.5M (r=8) | ❌ | ~2MB |
| Optimizer States (AdamW) | ~12M | - | ~48MB |
| 总计 | ~1.9B | 训练 ~6.3M | ~7.6GB + 输入缓存 |
为什么LoRA能省这么多显存?
- 全参数微调需要保存所有1.8B参数的优化器状态(动量和方差)
- LoRA只优化0.5M的A/B矩阵,优化器状态可忽略
- 梯度也只对LoRA参数有效,反向传播的中间激活更少
这也是LLaVA系列能在单卡24GB显存上完成微调的原因。
十六、相比于llava源码,minillava仓库实际实现
前面的内容包含了LLaVA原版机制和minillava仓库代码两部分。
16.1各个脚本功能
text
code/vision_encoder.py # CLIPImageProcessor + CLIPVisionModel,输出patch features
code/llm_decoder.py # AutoModelForCausalLM、AutoTokenizer、LoRA、Projector
code/dataset.py # LLaVA-CC3M chat.json读取、prompt构造、labels mask
code/mini_llava.py # 组装VisionTower、projector、LLM,并拼接inputs_embeds
code/train.py # Accelerate训练、scheduler、checkpoint保存
code/infer.py # 加载部分checkpoint后调用generate
tests/test_mini_llava.py # 用dummy模型测试拼接与labels前缀 -10016.2 minillava仓库的完整forward路径
text
PIL images
-> VisionEncoder
-> outputs.last_hidden_state[:, 1:, :]
-> [B, 196, 768]
-> Projector
-> [B, 196, llm_hidden_size]
input_ids
-> LLM embedding table
-> [B, text_len, llm_hidden_size]
torch.cat([image_embeds, text_embeds], dim=1)
-> LLM(inputs_embeds=..., attention_mask=..., labels=...)这里采用的是视觉token prefix 方案:图片token永远拼在文本token前面。没有根据文本里的<image>位置插入视觉token;dataset.py会先把<image>字符串清掉。
16.3 Prompt模板细节
build_prompt当前实现为:
python
return f"User:{question}\nAssistant"训练时full_texts = prompt + answer + eos,推理时也复用build_prompt(args.question)。这保证了训练/推理模板一致。
代码可以跑通,但更规范的写法一般使用Qwen tokenizer/chat template,在后续多轮对话中将更规范prompt的构造。
16.4 labels构造的两个阶段
LlavaCollator先屏蔽prompt和padding:
text
[prompt_tokens] [answer_tokens] [pad_tokens]
[-100 ...] [answer_ids] [-100 ...]MiniLlavaModel.forward再给图片token补-100:
text
[image_tokens] [prompt_tokens] [answer_tokens] [pad_tokens]
[-100 ...] [-100 ...] [answer_ids] [-100 ...]测试文件tests/test_mini_llava.py重点验证的正是这两个行为:图片embedding拼到文本前面,图片labels前缀为-100。
16.5 checkpoint与推理加载
train.py只保存可训练参数和LoRA参数:
python
return param.requires_grad or "lora_" in name or ".lora_" in name推理时用:
python
model.load_state_dict(state["model"], strict=False)因此checkpoint不是完整模型权重。加载时必须先用同一份配置初始化CLIP、LLM、LoRA结构,再把projector/LoRA等增量参数加载进去。
16.6 Dataset的健壮性问题
LlavaPretrainDataset.__getitem__中捕获异常后只打印:
python
except Exception as e:
print(f"getitem error {e}")如果图片打不开或conversation缺字段,image/question/answer可能未定义,后续return会继续报错。后续可以增加初始化阶段过滤坏样本,或者在__getitem__中重采样一条有效样本的功能。
16.7 S2、AnyRes、Delay Load与minillava仓库关系
前文的S2-Wrapper、AnyRes、Delay Load都是LLaVA原版或后续版本的扩展知识。minillava仓库当前没有实现这些能力:
VisionEncoder初始化时直接加载CLIP,没有delay_load。- 图片只走
CLIPImageProcessor的标准resize/crop,没有S2多尺度。 - 没有AnyRes grid切图,也没有可变数量image token的复杂拼接。
如果后续要扩展高分辨率能力,最自然的改动点在VisionEncoder.forward:让它返回更长或多尺度对齐后的patch features,而MiniLlavaModel._build_multimodal_inputs只要继续接收[B, N_img, D]即可。
以上笔记来源于我的仓库: https://github.com/wz940216/From0to1-MLLM-StudyLog.git
我正在连载一个从零到一的多模态大模型学习笔记。
如果你对多模态大模型感兴趣,或者也在准备往大模型方向转
可以点赞/Fork我的仓库: https://github.com/wz940216/From0to1-MLLM-StudyLog.git
也可评论区留言交流,后面我会继续把每周的学习记录、踩坑经验陆续更新到仓库和这里。