本系列文章将从提示词工程出发,逐步讨论人类如何提升对大模型行为的控制能力:从优化提问方式,到设计输入环境,再到连接外部能力,最终形成可复用的能力单元。
换句话说,我们关注的不只是"如何让模型回答更好",而是"如何让模型稳定地完成工作"。
在掌握提示词技巧后,人们很快会遇到一个问题:即使 prompt 写得很好,模型表现仍然不稳定。这时我们逐渐意识到,影响模型行为的并不只是提问方式,而是模型在生成答案时能够看到的全部信息。
本篇是系列第二篇,将讨论上下文工程:如何组织、筛选与管理模型输入,使模型的行为变得可预期、可重复,而不是依赖偶然的好回答。
很多人在熟悉提示词技巧之后,都会经历一个阶段。一开始,会明显感觉模型变聪明了:
- 加上 few-shot,格式对了
- 加上逐步思考,推理更准了
- 加上 step-back,回答更完整了
但很快就会遇到一种奇怪的现象:同一个问题,有时表现很好,有时却突然变笨。
明明使用了各种 prompt 技巧,模型的能力也没有变,但结果却开始变得不可预测。这时候我们往往会下意识地继续优化 prompt,改措辞、加规则、补示例、调顺序。
然而很多情况下,问题并不在"怎么问",而在模型回答时究竟看到了什么。
当对话变长、信息变多、任务变复杂时,模型的行为开始更多地受到"上下文"影响,而不是单条 prompt 的表达方式。
换句话说:模型并不是只在理解你刚刚写的那句话,它是在理解整个输入环境。
而一旦你开始关注这个输入环境,问题的性质就发生了变化 ------ 我们不再只是写提示词,而是在设计模型的工作空间,这正是 上下文工程(Context Engineering) 所关注的事情。
System、contextual 和 role prompting
在日常使用模型时,我们往往会把输入理解成一句话:我写了一段 prompt → 模型回答
但实际上,模型接收到的从来不只是一句话,而是一整段由不同层次信息组成的输入。
为了更好地理解这一点,可以把输入大致分成三类信息:
- System
- Contextual
- Role
System:模型此刻要做什么事
有些信息并不直接回答问题,而是在规定模型的整体行为。例如:
javascript
你是一个翻译助手
你只输出 JSON
你负责判断情感倾向这些内容不会直接成为答案的一部分,但它们决定了模型工作的"模式"。可以把它理解为:在回答任何问题之前,先设定模型的任务类型与边界。
Contextual:当前问题所处的环境
接下来是与当前任务直接相关的背景信息,例如:
- 对话历史
- 提供的资料
- 用户状态
- 限制条件
这些信息的作用不是改变模型身份,而是告诉模型: **这次回答发生在什么情境下。**同样的问题,在不同上下文中往往会得到不同答案。
Role:模型应该以什么方式表达
还有一类信息更偏向表达方式,例如:
用老师的语气解释
用面试官的角度评价
以心理咨询师的方式回答它并不改变任务本身,而是影响回答的风格与侧重点。
这三类内容在实际 prompt 中常常混在一起,看起来像是一段自然语言。但从模型的角度看,它们承担着不同作用:
- System 决定任务类型
- Contextual 决定理解范围
- Role 决定表达方式
当问题变复杂时,模型表现的差异往往不是来自某一句话写得好不好,而是来自这些信息组合后形成的"输入环境"。
也正是从这里开始,我们逐渐意识到:影响模型行为的,并不只是 prompt 的写法,而是整个上下文结构。
与 RCT 构词法的区别
看到这里,可能会觉得这些内容和前一篇文章提到的 RCT 很相似。它们确实描述的是同一段输入,但视角完全不同:
- RCT 是站在人类编写 prompt 的角度:它告诉我们,一条清晰的提示词通常应包含角色、背景与任务三部分,是一种写作结构。
- 这里的 System、Contextual 与 Role,则是从模型接收信息的角度出发:它关注的是模型在生成时,究竟把哪些信息当作规则、当作环境、又当作表达方式,是一种理解层级。
换句话说:
- RCT 关注的是 如何组织一句话
- System / Contextual / Role 关注的是 模型如何解释整段输入
前者帮助人类写得更清楚,后者帮助我们理解模型为何会这样回答。
当我们开始用后者的视角看待输入时,就不再只是优化措辞,而是在思考如何设计模型的输入环境 ------ 这也正是上下文工程的起点。
上下文工程
所谓 上下文工程(Context Engineering) ,可以先用一句话概括:上下文工程,就是为模型"设计并优化输入环境",让它能够更稳定、更高效地完成任务。
有一个非常形象的比喻,可以帮助理解上下文工程。可以把 LLM 想象成一台全新的"计算机系统"。
- 模型本身,就像 CPU
- context window(上下文窗口),就像 RAM
CPU 负责计算,但真正参与当前运算的,是放在 RAM 里的数据。模型的能力再强,如果某些信息没有被放进 context window,它在这一轮生成时就无法使用这些信息。
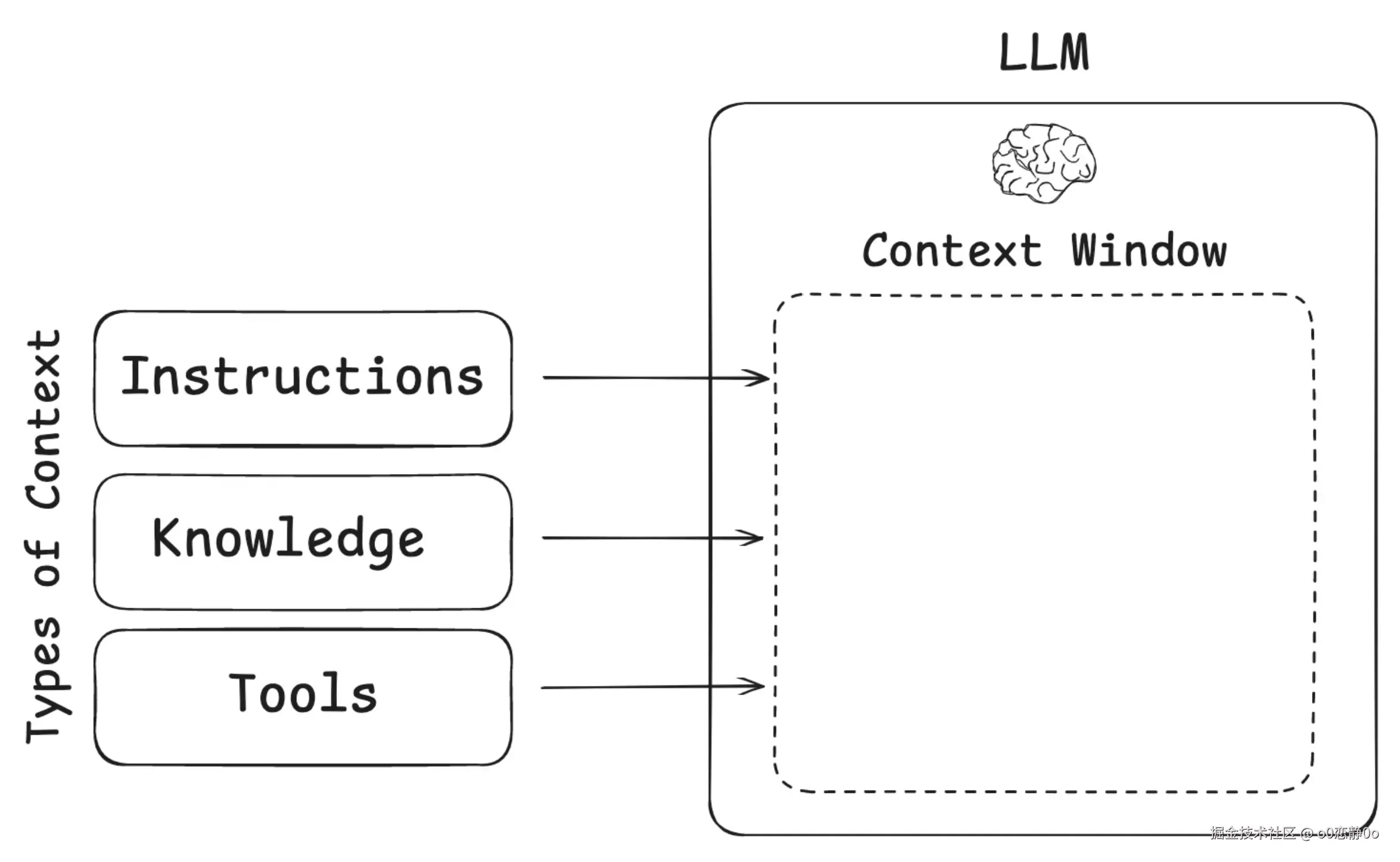
和 RAM 一样,context window 的容量是有限的,你不能把所有资料、所有历史、所有规则都一股脑塞进去。
如果塞得太多:
- 有些重要信息会被淹没
- 上下文可能超过窗口上限
- 模型的注意力会被稀释
因此系统必须考虑,如何把"恰到好处"的信息放进模型的工作记忆里:
- 哪些信息必须给?否则模型会瞎猜
- 哪些信息不能给?给多了会被噪声带偏
- 这些信息以什么结构给?结构不同,效果可能天差地别
这正是上下文工程的本质。
一个真实的案例
我们来看一个具体场景。
假设你要做一个公司内部的 AI 助手,用来回答员工问题。员工问:
报销打车费需要提供什么材料?最直觉的写法是:
你是公司的行政助手,请回答员工问题。
报销打车费需要提供什么材料?有时候,它会给出一个看似合理的回答。但很快你会发现问题:
- 回答听起来像"某家公司"的制度,而不是你公司的
- 有时会编造审批规则
- 有时回答非常笼统
于是你开始优化 prompt。
第一次升级:加强规则
你加了一些约束:
你是公司的行政助手,只能依据公司制度回答。
如果不知道,请说明不清楚。结果稍微好了一点,但依然不稳定。原因很简单:模型根本不知道你公司的制度是什么。
第二次升级:加入制度资料
于是你把公司制度直接放进输入里:
markdown
公司制度:
1. 打车费需提供电子发票
2. 超过100元需主管审批
3. 夜间打车需说明原因
员工问题:
报销打车费需要提供什么材料?这一次,回答明显稳定下来。你几乎没有改"提问方式",只是给了正确的信息。
第三次升级:对话开始变长
员工继续问:
那超过 100 元怎么办?
那我昨晚加班回家打车呢?这时模型有时回答得很好,有时却忘记前面提到的规则。你意识到:模型需要看到对话历史。于是你开始把历史消息一起传入。
第四次升级:制度更新了
公司制度每个月都会更新。如果你把全部制度都放进上下文,模型可能会引用旧版本。
于是你不得不考虑:
- 是否应该动态检索最新制度?
- 是否需要过滤掉无关条款?
- 是否要只给与当前问题相关的段落?
这时你已经不再"写 prompt",而是在做信息筛选。
第五次升级:开始具备行动能力
后来你希望助手不仅能回答问题,还能帮员工发起报销流程。这时模型需要知道:
- 有哪些可调用的工具
- 每个工具的参数是什么
- 什么时候应该调用
你开始提供工具说明。
回头看这个过程,你会发现一件事,我们几乎没有去持续优化"提问方式"。我们在不断做的,是决定:
- 哪些信息必须出现
- 哪些信息必须删除
- 哪些信息需要结构化
- 哪些信息需要动态获取
也就是说,问题早已不再是"prompt 怎么写",而是模型在生成答案时,整个输入环境如何被构建。这个不断构建、调整输入环境的过程,本质上就是上下文工程。
上下文工程通常包含哪些内容?
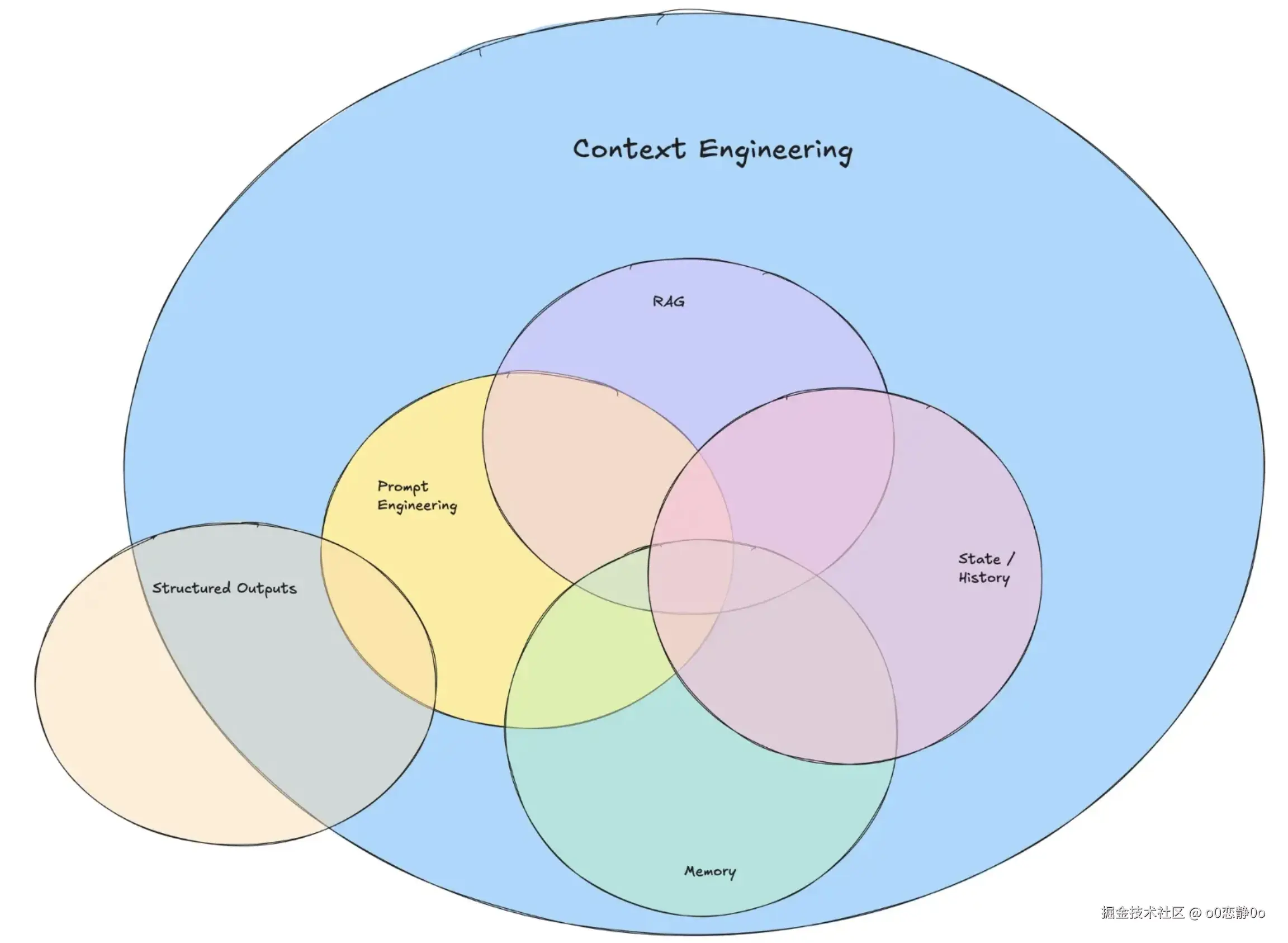
当输入的内容被系统性地整理后,就形成了上下文工程关注的几个核心组成部分。下面这些东西,很多你可能已经"用过",只是不一定意识到它们都属于上下文工程的一部分:
- 指令与规则设计:system prompt 怎么写、边界怎么定
- 示例与模板:few-shot、固定输出结构、JSON schema 等
- 动态上下文:用户输入、时间、地点、状态、历史对话
- 知识补充:RAG 检索、资料拼接、查询改写(query augmentation)
- 工具与能力说明:工具有哪些、怎么用、什么时候用
- 记忆管理:短期记忆(对话历史 / state)与长期记忆(向量库等)
- 评估与迭代:用可衡量的方式验证"上下文调整是否真的更好"
你会发现:当我们把这些拼在一起看时,"prompt 工程"更像只是其中的一项技能。真正决定效果的,是整套上下文被如何构建、如何更新、如何取舍。
限于文章篇幅,这里不会将所有部分一一展开介绍,这里针对部分重要的内容做一个简单的介绍。
RAG
在前面的案例中,我们已经遇到一个非常典型的问题:模型并不是不会表达,而是不知道事实。
当员工问:报销打车费需要什么材料?
模型给出的回答,往往来自它训练时见过的"平均公司制度"。即使我们把 prompt 写得再清晰,它也只能猜一个"合理答案"。
究其原因,是因为语言模型的知识是静态的。它的回答,本质上是在已有参数中寻找最可能的文本模式。当问题涉及具体事实(公司制度、最新政策、私有数据)时,模型并不会"查询",而是在"推测"。
所以会出现一种现象:模型回答听起来很合理,但却是错的。这并不是推理错误,而是信息缺失。
检索增强生成
RAG 英文全称为 Retrieval-Augmented Generation,翻译成中文是检索增强生成。
RAG 做的事情非常直接:在模型生成答案之前,先为它提供与当前问题相关的真实资料,再让模型基于这些资料回答。
也就是说,模型不再依赖记忆,而是依赖当下提供的上下文。
从模型视角看,过程变成:问题 → 获取相关信息 → 在这些信息上生成答案
而不是:问题 → 在参数中猜测答案
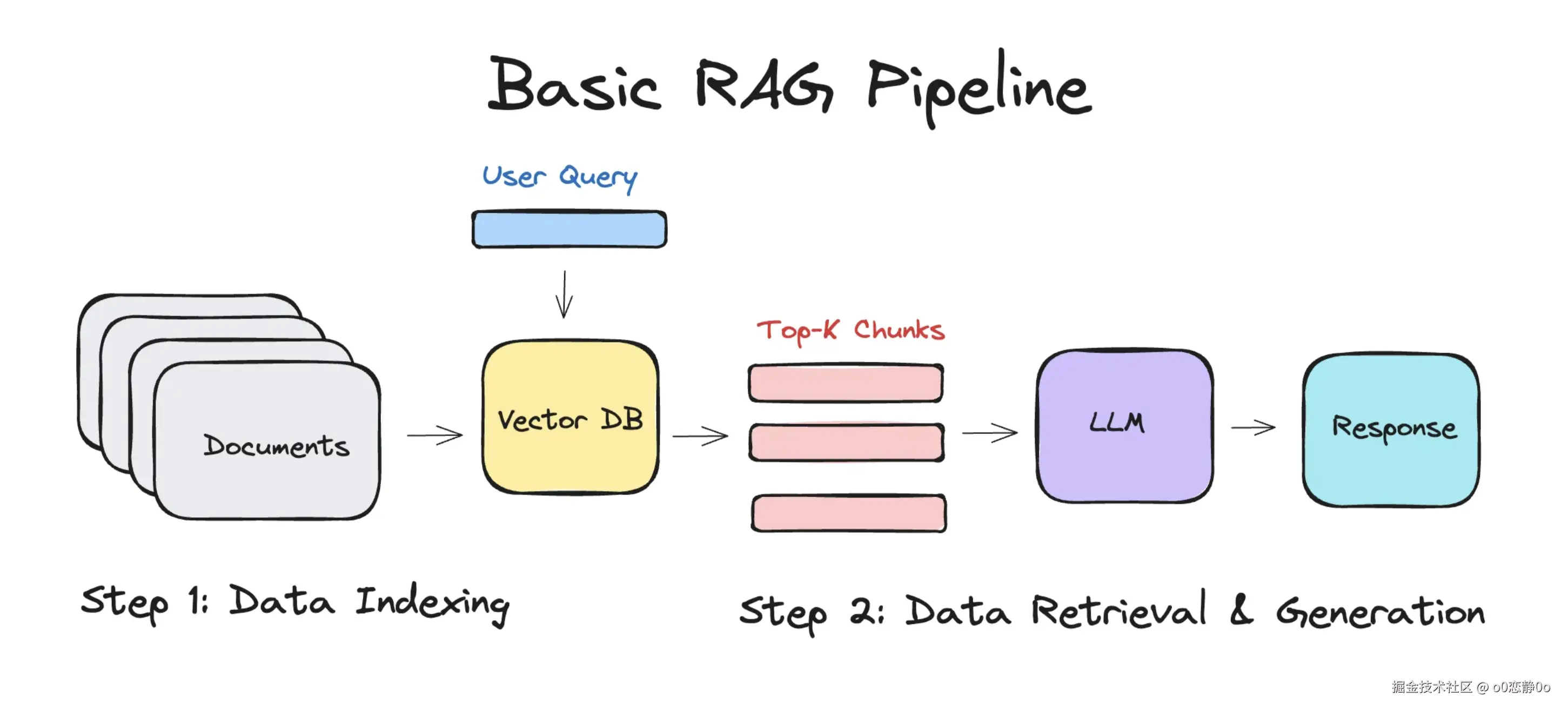
简单的 RAG 应用从整体上分为两个阶段:
- 数据索引(Data Indexing)
- 数据查询(Query)
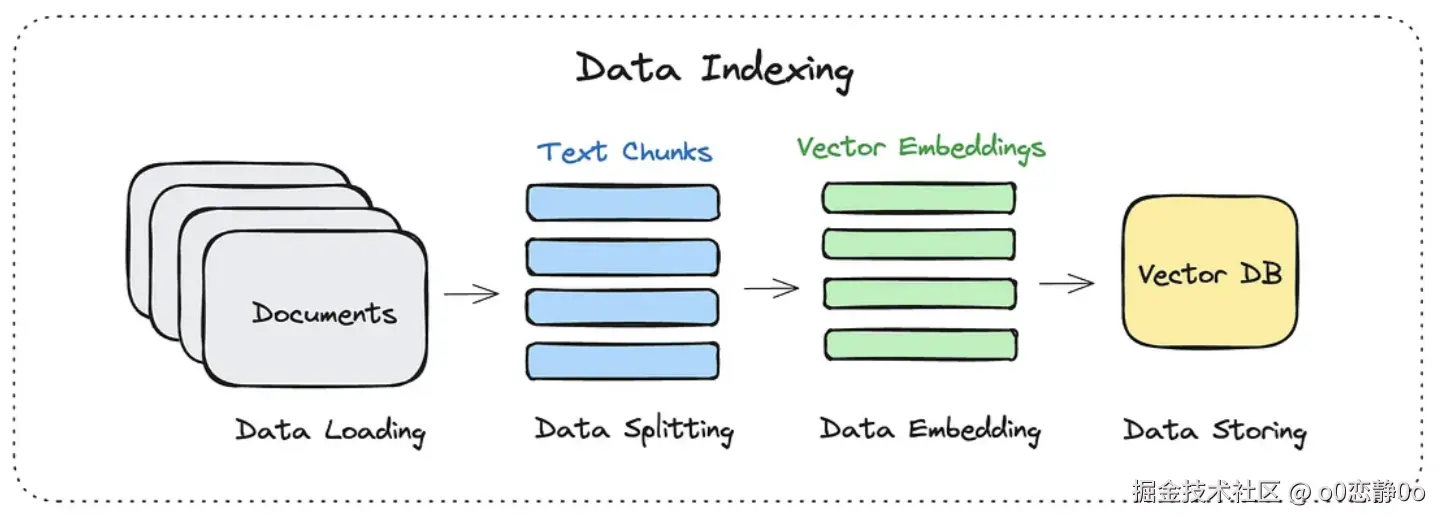
数据索引
在做数据索引时,通常分为这么几个步骤:
- 加载文档
- 切分成 chunks
- 转化为向量嵌入
- 存入向量数据库
数据查询
数据查询阶段的两大核心阶段是 检索 与 生成。
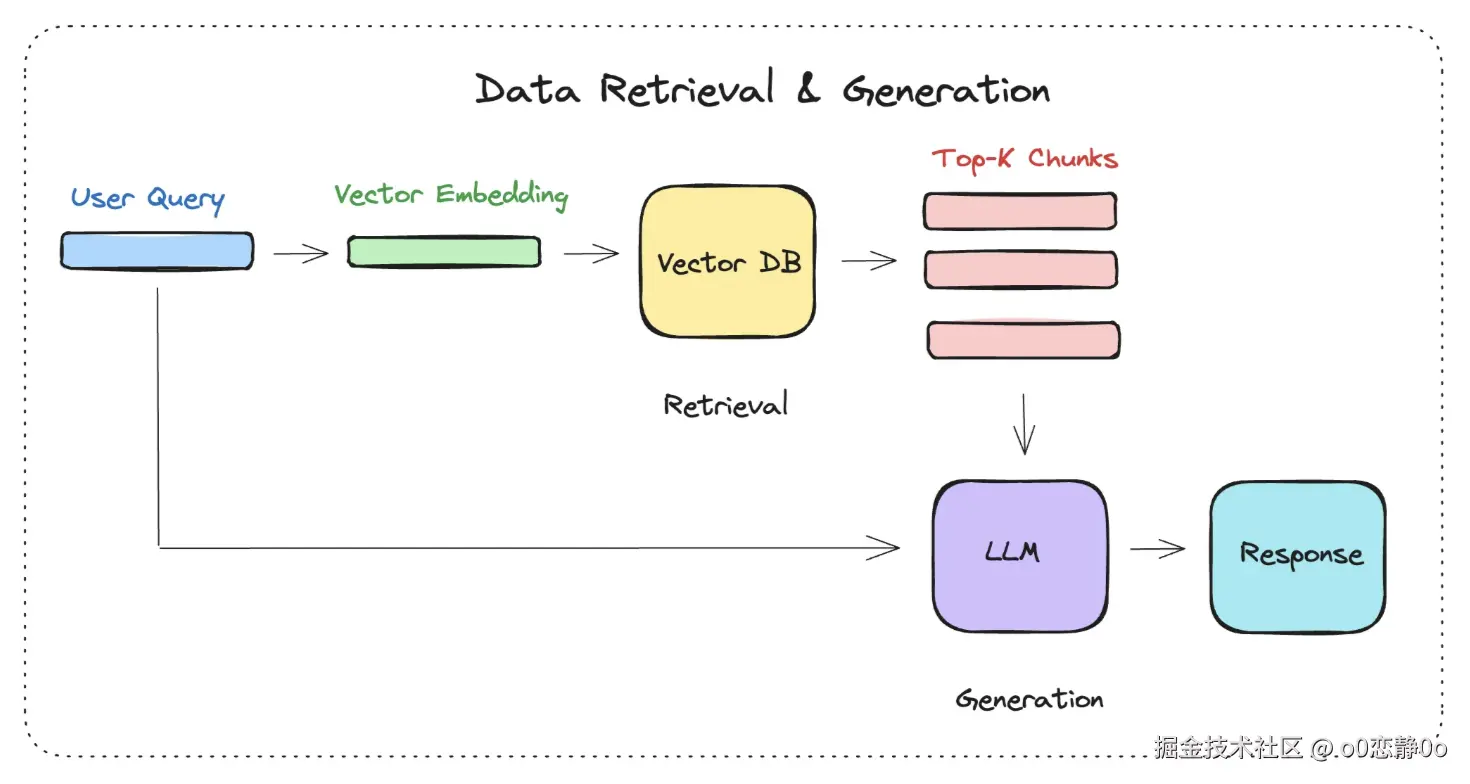
检索阶段
分为下面几个步骤:
-
将 Query(用户的问题) 转化为向量
-
在向量数据库中进行相似度检索(语义检索),相似度的检索,有几种方式
- 余弦相似度
- 欧氏距离
- 点积
-
为生成阶段准备检索结果
生成阶段
构造出来的提示词大致如下:
css
[系统提示]:
你是一个智能客服助手,请基于以下资料回答用户的问题。
[资料内容]:
1. 本产品支持7天无理由退货。
2. 如存在质量问题,可申请退换货。
3. ...
[用户问题]:
我买的这个产品坏了还能退吗?
[你的回答]:完整的流程
为什么它属于"上下文工程"
很多介绍会把 RAG 看作一种"知识库技术",但从模型行为角度看,它更像是在改变输入环境。
我们并没有增强模型能力,只是改变了模型在生成时能看到的内容。也正因此:
- 检索什么内容
- 提供多少内容
- 如何拼接内容
- 是否去除噪声
都会直接影响答案质量。换句话说:RAG 不是让模型更聪明,而是让模型不再盲猜。
它解决的并不是表达问题,而是知识来源问题。因此,RAG 本质上是对"知识上下文"的管理,而不是单纯的数据检索。
记忆管理
如果说 RAG 解决的是"模型不知道"的问题,那么记忆解决的是另一种同样常见的不稳定:模型知道,但它忘了。
在简单问答中,这个问题并不明显。但只要对话变长、任务分步骤、或需要多轮确认,就会出现:
- 模型刚解释过的条件,下一轮就忽略
- 刚确定的需求,突然又重新询问
- 前后回答互相矛盾
这并不是模型推理能力不足,而是状态没有被持续提供。
语言模型本身没有持续状态,它每次生成答案时,只能依赖当前输入里的信息。一旦某些关键信息没有被再次提供,对模型来说就等同于从未发生过。
因此,我们需要把"过程"本身变成上下文的一部分,这就是记忆管理的作用。记忆管理分为两种:
- 短期记忆
- 长期记忆
短期记忆
短期记忆,对应的英文为 Short-term Memory,指的是当前任务过程中产生的临时状态,通常存在于一次会话或一次任务流程内。
例如在刚才的报销助手中:
员工:我要报销打车费
助手:请提供发票
员工:超过100元
助手:需要主管审批这里"超过100元"其实是在补充前文条件,如果模型看不到前面的对话,它就无法理解这句话的含义。
因此系统需要把历史对话一起提供给模型,这就是最常见的短期记忆形式:对话历史。
用户问题 + 历史对话 + 当前任务状态 → 一起发送给模型但短期记忆不只是聊天记录,还包括:
- 当前任务的中间结论
- 已确认的参数
- 任务执行进度
- 工作流中的阶段状态
本质上,短期记忆是在告诉模型:我们现在进行到了哪一步。它让模型从"每次重新开始回答",变成"持续完成同一件事"。
另外,可能有的同学认为,短期记忆不就是简单的堆叠聊天记录么?
这种理解过于简单。
短期记忆确实通常来源于历史对话,但真正的问题不在于"有没有历史",而在于 ------ 如何选择历史。
如果处理不当,会出现两个极端:
- 带得太少,模型会丢失关键条件,回答前后不一致
- 带得太多,模型会被无关信息干扰,甚至超过上下文窗口限制
因此,短期记忆本身也需要设计,常见的优化策略包括:
- 滑动窗口:只保留最近几轮对话,而不是全部历史
- 摘要压缩:将早期对话总结成结构化结论,而不是逐字保留
- 关键状态提取:只提取任务相关的参数、确认结果和阶段状态
- 阶段清理机制:当任务完成或进入新阶段时,主动丢弃旧上下文
换句话说,短期记忆不是"聊天记录堆叠",而是一种有选择地保留任务状态的机制。真正成熟的系统,往往不会简单地拼接全部历史,而是对历史进行筛选、压缩和重组。
长期记忆
有些信息不仅在单次对话中有效,更需要跨越会话周期持续存在。例如:
- 用户偏好(如:习惯简短回答、特定的编程风格)
- 交互历史(如:已执行的操作、已达成的共识)
- 任务进度(如:项目中已完成的阶段、待办事项)
- 私有上下文(如:之前讨论过的家庭成员、公司特定缩写)
如果系统每次都需要重新询问或推理,会显得缺乏"进化能力"和交互深度。将这些信息结构化存储并在后续对话中精准检索,便构成了 AI 的长期记忆(Long-term Memory)。
长期记忆与 RAG 在技术底层虽有相似之处,但核心逻辑存在本质区别:
| 维度 | RAG (检索增强生成) | 长期记忆 (Long-term Memory) |
|---|---|---|
| 类比 | 像是给新同事发了一份《公司规章手册》 | 像是同事记住了"你是谁"以及"你们共事的往事" |
| 内容本质 | 提供公共的、客观的、静态的世界知识 | 提供私有的、主观的、动态的历史背景 |
| 核心作用 | 解决模型"知之不多"的问题(补足知识面) | 解决模型"懂你不够"的问题(实现个性化) |
总结来说:
- RAG 赋予模型的是"外部世界的百科全书"
- 长期记忆赋予模型的是"关于你的专属记忆曲线"
两者结合,才能让 AI 从一个单纯的工具变成一个真正懂你的智能伙伴。
长期记忆是如何实现的
长期记忆与短期记忆的区别在于,它不会在每轮对话中直接保留,而是在需要时被重新取回。
系统会把重要历史,例如:
- 用户偏好
- 过去任务
- 关键结论等
存储在外部,并在需要时重新提供给模型。这些信息通常会被存放在系统可持久化的位置,例如:
- 数据库:保存用户偏好、历史任务、状态记录
- 向量数据库:用于按语义检索相关历史
- 文件或缓存:用于短期或会话级别的存储
当新的问题出现时,再根据相关性把它们重新加入上下文。
从模型角度看,这与 RAG 非常相似:
查询当前问题 → 找到相关历史 → 放入输入 → 生成回答区别在于:
- RAG 检索的是客观知识
- 长期记忆检索的是"与这个用户或任务有关的过去"
因此长期记忆也是一种按需出现的一种动态上下文。
写在最后
如果回顾本篇的内容,会发现一个很有意思的变化。
一开始,我们面对模型的方式是:我怎么问,它就怎么答。于是我们不断优化 prompt:换措辞、补示例、加规则、调顺序。但当任务变复杂后,问题开始变得奇怪:
- 明明写得很清楚,模型却忽然答偏
- 同一问题,有时很好,有时很差
- 多轮对话中,模型不断"失忆"
这时我们才逐渐意识到:模型的问题,往往不是理解能力不足,而是它"看到的世界"不对。
从这一刻起,工作的性质发生了变化。我们不再只是写一句更好的话,而是在思考:
- 哪些信息应该被模型看到
- 哪些信息必须被隐藏
- 哪些知识要实时检索
- 哪些状态要被持续记住
整个上下文工程,由一系列的技术组成:
- RAG
- 记忆管理
- 提示词工程
- 动态上下文
- ....
无论哪种技术,解决的核心问题都只有一个,就是为模型构建整个运行环境,而这正是上下文工程的本质。
好啦,今天的内容就分享到这里啦,我们下一篇文章再见👋
-EOF-