原文: mp.weixin.qq.com/s/ZuA3zSpVH...
关注公zh: AI-Frontiers
论文标题:mHC: Manifold-Constrained Hyper-Connections
延续在节假日搞事情的习惯,2026年元旦期间,Deepseek发表了一篇新论文,提出了名为mHC(Manifold-Constrained Hyper-Connections,流形约束超连接)的新架构。相信各位道友当时心里是五味陈杂:终于又可以抄作业了,等等,为啥你要元旦发啊,还让不让人过节啦。
该研究目标在不损失传统HC(超链接)性能增益的基础上,改善其在大模型训练过程中存在的不稳定性问题。
这次创新并非简单的组件替换,而是对神经网络宏观拓扑的一次重构。mHC将传统Transformer的单一残差流扩展为多流并行架构,通过引入严谨的几何流形约束,成功解决了HC在大规模训练中的数值不稳定和信号爆炸问题。
本文将带大家深扒这篇论文的提出背景、底层原理和实验效果,并附带网友的实战代码资源。
基本概念
残差连接
论文标题:Deep Residual Learning for Image Recognition
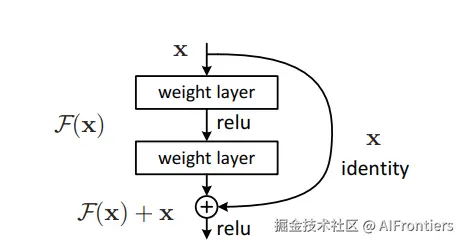
2015年,由微软亚洲研究院的何恺明团队提出ResNet,ResNet引入残差连接的概念,用以解决深层神经网络训练中的梯度消失/爆炸和网络退化问题,使得训练极深的网络成为可能。
xl+1=xl+F(xl,Wl)(1)
在公式(1)中:
-
xl∈R1×d为 l 层网络输入
-
F为对 l层进行的非线性变换,如卷积、Attention或MLP等
-
xl+1∈R1×d为该层的输出
传统的网络试图对每层的输入 x 直接学习目标映射 H(x)。而残差网络的设计思想是:既然直接学习很难,不如让网络去学习每层的残差,
F(x)=H(x)−x(2)
公式(1)和公式(2)本质是一样的:
-
公式(2)中的 F(x)即为公式(1)的 F
-
公式(2)中的 H(x)即为公式(1)的 xl+1
-
公式(2)中的 x 即为公式(1)的 xl
这就像是把原始文件 x复印了一份直接交给下一个人,同时附上一张便利贴,上面写着这一层所做的修改 F(x)。下一个人收到的是「原件 + 修改意见」,该设计的关键特性是恒等映射(Identity Mapping)能力。
在网络初始化的早期阶段,权重通常很小 F(x)≈0。此时:
xl+1≈xl+0=xl(3)
这意味着,信号像是在高速公路上一样,毫无阻碍地从第一层直通最后一层。梯度也可以沿着这条高速公路无损地回传。正是这一特性,使得训练成百上千层的网络(如GPT-4, DeepSeek-V3)成为可能。
超连接(Hyper-Connections, HC)
论文标题:HYPER-CONNECTIONS
残差连接的问题
标准的残差连接强制要求输入信号与经过变换的信号以 1:1 的比例叠加,虽然保证了梯度的高速公路,但也带来了两个问题:
-
信息流瓶颈:原来只有一条残差通道,所有信息不管是简单细节还是高层抽象,都挤在同一条路上传。这就像所有车都走一条车道,没法灵活分配路线,模型没法根据需要把信息送到最合适的地方。
-
表示坍塌:网络特别深的时候,为了不崩、训练稳定,很多层其实学不到有用的新东西,只能改一点点、几乎等于没改。结果就是白白浪费算力,提取出来的特征都长得差不多,没有多样性,表达能力变弱。
在上面的背景下, 字节提出了Hyper-Connections的模型结构来改进传统的残差连接结构。通过扩展残差流宽度和多样化连接模式,拓展了过去十年中广泛应用的残差连接范式。
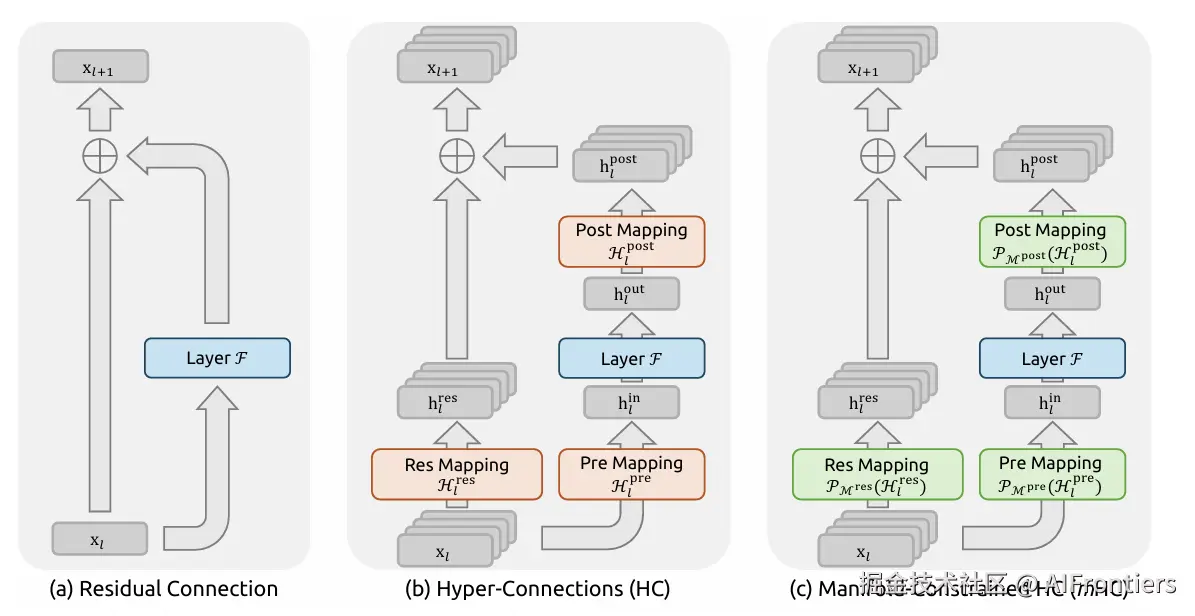
HC的核心思想是将原本单一维度的残差流扩展为$$$$个并行的流,然后乘以一个权重矩阵 Hlres。这增加了信息的带宽,可以更多地捕获输入不同维度之间的融合信息。
在HC架构中,信息不再是简单的标量加法,而是通过矩阵运算进行复杂的混合,数学表达为:
xl+1=Hlresxl+Hlpost TFl(Hlprexl,Wl)(4)
对于公式(4)
-
Hpre (预融合/汇聚) :将 n个并行流的信息汇聚起来,压缩成适合Transformer层(Attention或MLP)处理的输入维度。
-
Hpost (后融合/分发) :将Transformer层的计算结果重新分发回 n个并行流中。
-
Hres (流内混合) :这是最激进也是最关键的组件。它允许 n个并行流在不经过Transformer层计算的情况下,直接进行内部的信息交换和混合。
理论上,HC允许模型学习出任意的连接模式:① 模型认为某一层应该保持恒等映射,可以学习将 Hres变为单位矩阵 I;② 如果模型认为需要剧烈改变信息流向,可以学习复杂的非对角矩阵。这种灵活性极大地增强了模型的拓扑结构复杂度。
mHC
HC 的问题
根据公式(1),传统的残差连接结构模型第 L层和第 l层的关系表示如下:
xL=xl+Σi=lL−1Fi(xi,Wi)(5)
上式表明 xl的梯度信息可以1比1传递给 xL,不会梯度爆炸或者梯度消失,保证训练过程的稳定性。
根据公式(4),可推导出HC结构下第 L层和第 l层的关系:
xL=(i=1∏L−1HL−ires) xl+Σi=lL−1(j=1∏L−1−iHL−jres) Hipost TF(Hiprexi,Wi)(6)
这会导致 ∂xL∂loss(∏i=1L−1HL−ires)∂xl∂loss+...。由于 ∏i=1L−1HL−ires一个典型的连乘过程,矩阵连乘的性质取决于矩阵的谱范数 , 即矩阵最大特征值的模。我们来比较Resnet中残差连接和HC连乘的情况:
-
Resnet中的残差连接 :残差路径是恒等映射,相当于乘以单位矩阵 I。单位矩阵的谱范数严格为 1。无论乘多少次, 1100=1,信号始终稳定。
-
HC :在HC中, Hres是自由学习的参数矩阵,不可控。
- 如果 Hres的平均谱范数略大于 1(例如 1.05),在 60 层的网络中,信号会被放大 1.0560≈18.6倍 。
- 如果谱范数更大,或者网络更深,放大倍数会呈指数级爆炸,破坏残差结构中梯度回传的稳定性,从而导致训练不稳定,具体可见下图。
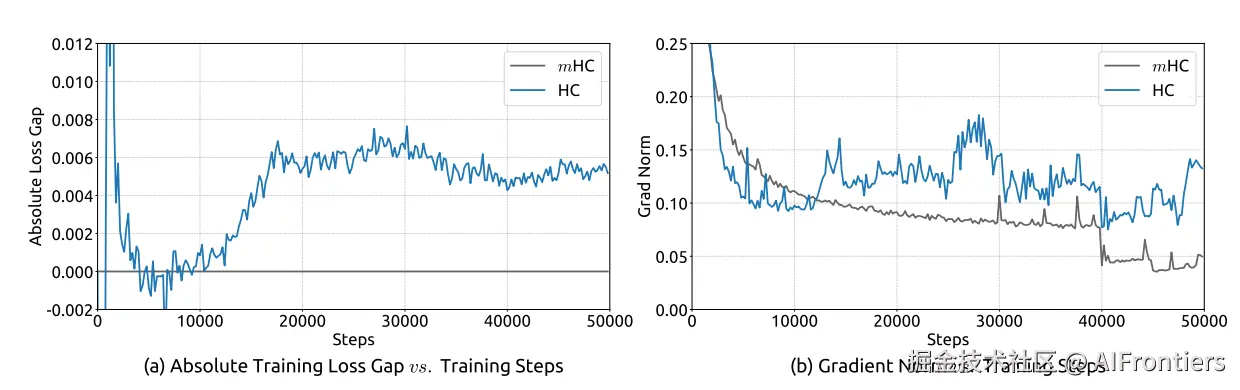
上图显示,27B模型训练到12k step左右,HC的loss突然飙升。与此同时,梯度范数也开始疯狂震荡。
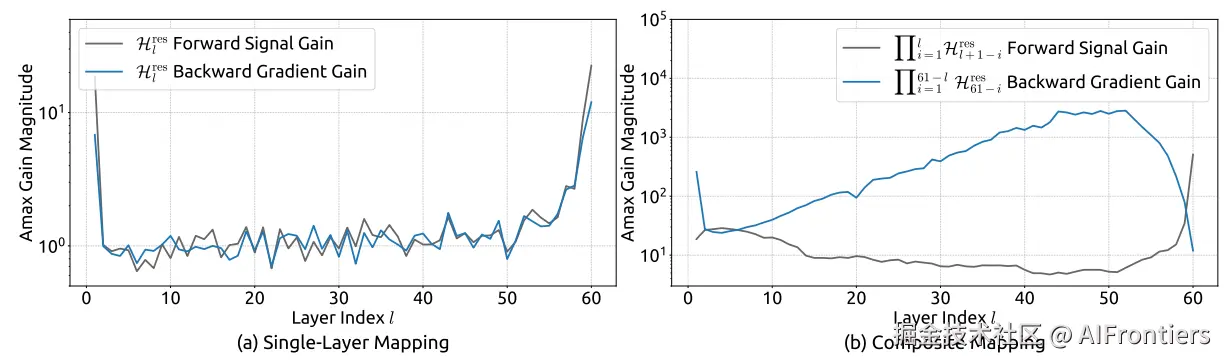
另外,由于 HL−ires矩阵是无约束的,可以往任意方向发散。论文测量了一个叫「Amax Gain Magnitude」的指标,在残差流里被放大了3000倍。在大规模训练中,这就是爆炸的前奏。
mHC的诞生
面对HC的问题,DeepSeek提出了mHC,即Manifold-Constrained Hyper-Connections(流形约束超连接),其核心思路为:将不可控的 Hres矩阵通过数学的手段,转换为可控的双随机矩阵(Doubly Stochastic Matrices)。下面为大家解释mHC几个重要概念。
双随机矩阵(Doubly Stochastic Matrices)
双随机矩阵定义如下:
PMres(Hlres):={Hlres∈Rn×n∣Hlres1n=1n, 1n⊤Hlres=1n⊤, Hlres≥0}(7)
其中, 1n表示所有元素均为 1 的 n维向量。从公式(7)中可看出,双随机矩阵的元素都大于等于0,每一行、每一列的值相加都等于1。
双随机矩阵具备2个重要特性:① 范数值为1;②多个双随机矩阵的乘积还是双随机矩阵。从而可以推出 ∣∏i=1L−1HL−ires∣=1 ,解决了上面提到的范数不可控的问题。
那么怎么把 Hlres矩阵变换成双随机矩阵呢?DeepSeek团队采用的是Sinkhorn-Knopp算法。
Sinkhorn-Knopp算法
① 通过公式(8)计算变换前的 Hlres:
⎩ ⎨ ⎧x~l′=RMSNorm(x~l)H~lpre=αlpre⋅(x~l′φlpre)+blpreH~lpost=αlpost⋅(x~l′φlpost)+blpostH~lres=αlres⋅mat(x~l′φlres)+blres,(8)
其中,输入 xl∈Rn×C,φlpre,φlpost∈RnC×n,φlres∈RnC,n2,先将 xl转换为 R1×nC的向量 x~l,并通过mat(·)操作从 R1×n2空间转换到 Rn×n。
② 通过 M(0)=exp(H~lres)得到元素值都大于0的矩阵,作为迭代起始矩阵。
③ 通过下面的公式迭代做normalization,使其满足每行之和和每列之和接近1:
M(t)=Tr(Tc(M(t−1)))(9)
其中 Tr 和 Tc分别代表按行和按列做归一化,根据Sinkhorn-Knopp算法原理, M(t)会收敛成双随机矩阵,DeepSeek论文中一般迭代20步。
Birkhoff多胞体 流形
论文标题中的Manifold(流形)指的就是由所有双随机矩阵构成的几何空间,被称为Birkhoff多胞体(Birkhoff Polytope), 记为 Bn。
-
多胞体(Polytope) :想象一个多维空间中的多面体(类似于3D空间中的钻石或立方体)。这个多面体的每一个点,都代表一个合法的双随机矩阵。
-
顶点(Vertices) :这个多面体的顶点是所有的置换矩阵(Permutation Matrices)。置换矩阵是只包含0和1的矩阵,且每行每列只有一个1。它们的作用仅仅是交换信息的顺序(比如把通道1的信息换到通道 2),而不改变信息的大小。
-
内部(Interior) :Birkhoff-von Neumann定理告诉我们,这个多面体内部的任何一个点(即任何一个双随机矩阵),都可以表示为这些顶点的加权平均。
DeepSeek的做法,实际上是将神经网络原本在整个欧几里得空间中乱跑的参数,强行拉回到了这个 Birkhoff多胞体的表面或内部。在这个几何体内游走,无论怎么走,都是安全的。
关于mHC的更多知识,可参考www.k-a.in/mHC-math.ht...
系统级实现与工程优化
虽然Sinkhorn-Knopp迭代在理论上很美,但在计算上却很昂贵。如果在每一层、每一步训练中都进行 20次矩阵迭代,训练速度会大打折扣。DeepSeek为mHC量身定制了基础设施设计,将额外开销仅增加6.7%。
算子融合 (Kernel Fusion)
DeepSeek利用了自研的TileLang编程语言开发了定制化的CUDA内核。
- 融合操作:将指数化、20次Sinkhorn迭代、以及后续的矩阵乘法,全部融合进了一个单一的GPU Kernel中。
- SRAM 驻留:在这个Kernel执行期间,中间数据(如迭代过程中的矩阵)一直保留在GPU的高速缓存(SRAM/Register)中,而不需要反复写回慢速的全局显存。
这大大减少了内存 I/O 次数,使得 20 次迭代的计算时间几乎可以忽略不计。
DualPipe通信重叠

在大模型训练中,由于模型太大,往往需要跨多个GPU进行流水线并行(Pipeline Parallelism)。 DeepSeek设计了一种名为DualPipe的调度策略。
-
打时间差:当GPU的计算单元(Tensor Cores)正在全力计算mHC的Sinkhorn投影时,GPU的通信单元(NVLink)并未闲着。
-
重叠执行:DualPipe巧妙地安排了任务,利用mHC计算的时间窗口,同时进行不同GPU之间的数据传输。
-
结果:Sinkhorn带来的额外计算延迟被通信时间完美掩盖了。对于整体训练流程来说,mHC的计算几乎是免费的。
选择性重计算(Selective Recomputation)
由于mHC引入了 n= 的扩展流,中间激活值的显存占用会增加。如果全部存储,会导致显存不足。
DeepSeek 采用了选择性重计算策略:
-
在前向传播时,不存储所有Sinkhorn迭代的中间结果。
-
在反向传播时,利用这一层极快的计算速度,重新计算出所需的中间变量。
-
这种以计算换显存的策略,结合TileLang的高效率,使得 mHC 在显存占用上也保持了高效。
实验结果
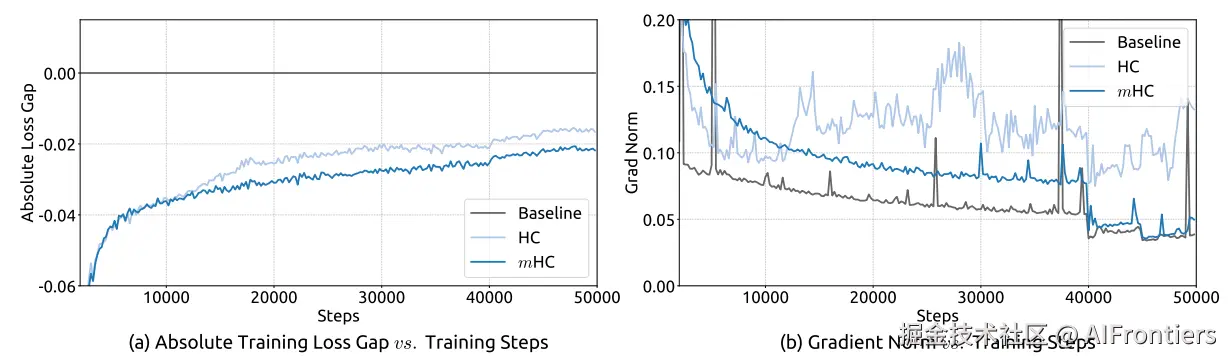
研究首先考察27B模型的训练稳定性与收敛性。如图5 (a) 所示,mHC有效缓解了在HC中观察到的训练不稳定性,与基线相比,最终损失降低了0.021。图5 (b) 中的梯度范数分析进一步证实了这种稳定性的提升,其中mHC表现出明显优于HC的行为,其稳定的表现与基线相当。
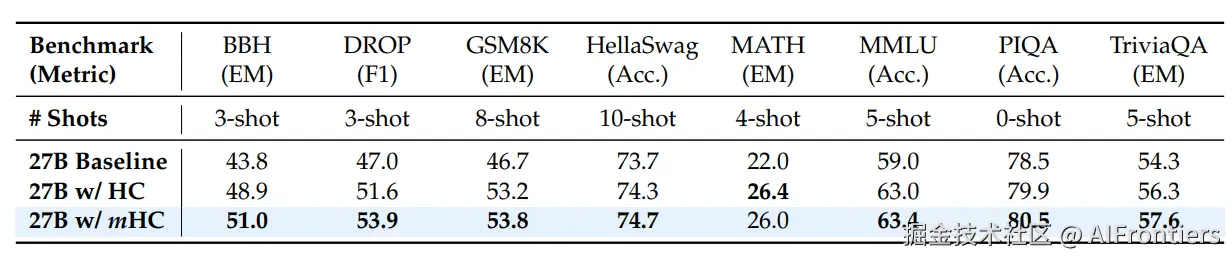
表 4展示了模型在多种下游基准测试中的性能表现。相比于基线模型,mHC实现了全面的性能提升,并在大多数任务上超过了HC。值得注意的是,与HC相比,mHC 进一步增强了模型的推理能力,在 BBH上实现了2.1%的性能提升,在 DROP上实现了2.3%的性能提升。
代码实现
github网友实现的代码,仅供参考