目录
- 1.博客系统的基本信息和测试背景
- 2.手动进行测试
- 3.用selenium来进行Web自动化测试
-
- 3-1新建项目
- [3.2 参照测试用例,编写自动化脚本](#3.2 参照测试用例,编写自动化脚本)
- 4.自动化测试和手动测试的对比
- 5.性能测试
1.博客系统的基本信息和测试背景
该博客系统有博客登陆页面,博客页表页,博客编辑页,博客详情页 。本次的测试主要也是这几个页面来进行测试。主要测试能否正常的登录,删除博客和退出博客等功能能否正常实现。测试该系统能否发布个人博客并记录博客发布日期、时间、标题、博客发布者等信息
2.手动进行测试
2-1编写web测试用例
设计测试用例一般可以从6个方面来考虑:功能测试+界面测试+性能测试+兼容性测试+易用性测试+安全测试
设计测试用例的思想:常规思维+逆向思维+发散性思维
由于我们是对web来就行测试,我们对主要的功能来进行测试
2-2设计测试用例的思维导图
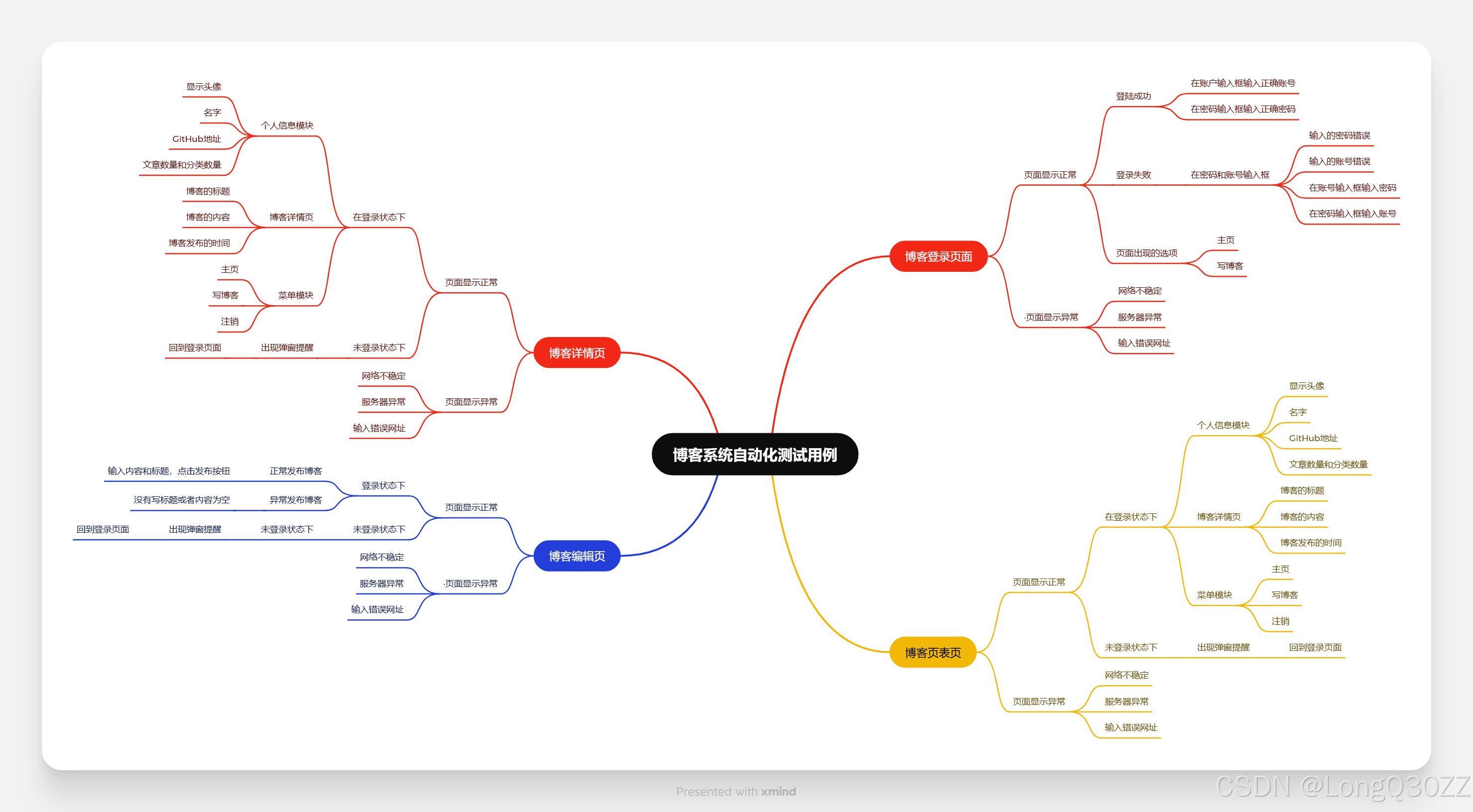
2-3博客登录页测试
1)登录页面展示:
2)输入正确的账号和密码
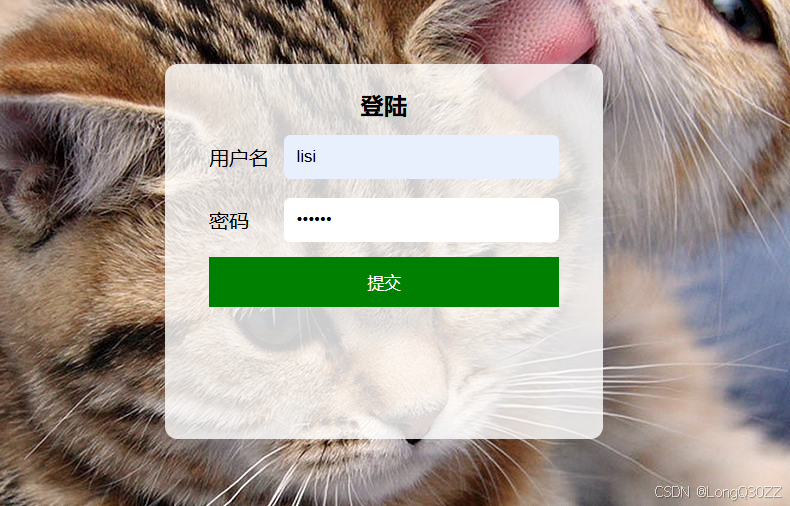
跳转到博客列表页
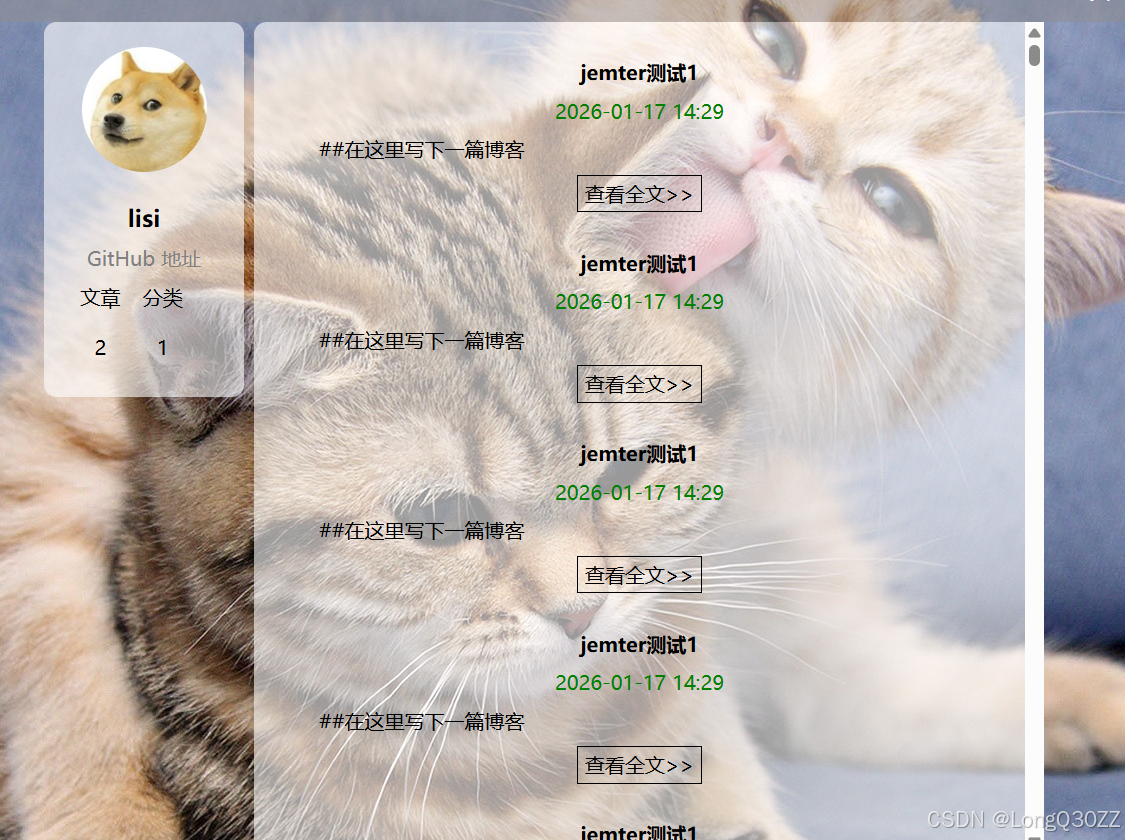
当我们输入错的账号时:
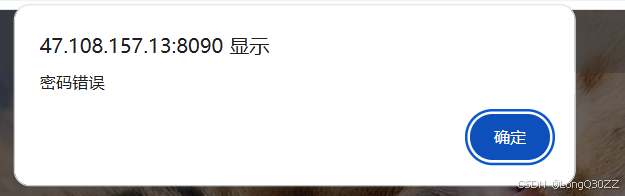
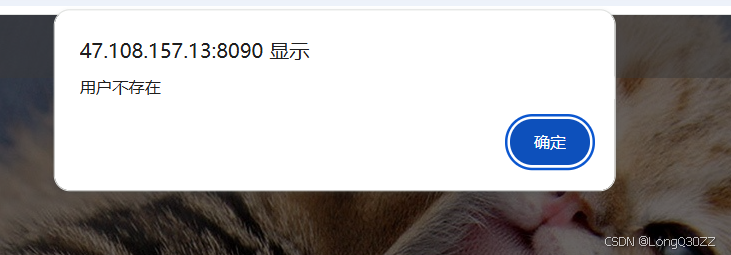 当我们输入错密码时:
当我们输入错密码时:
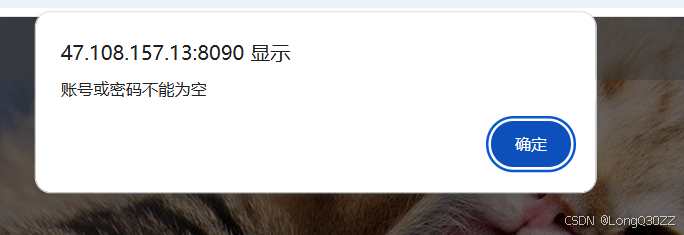
当我们什么都不输入时:
2-4博客列表页测试
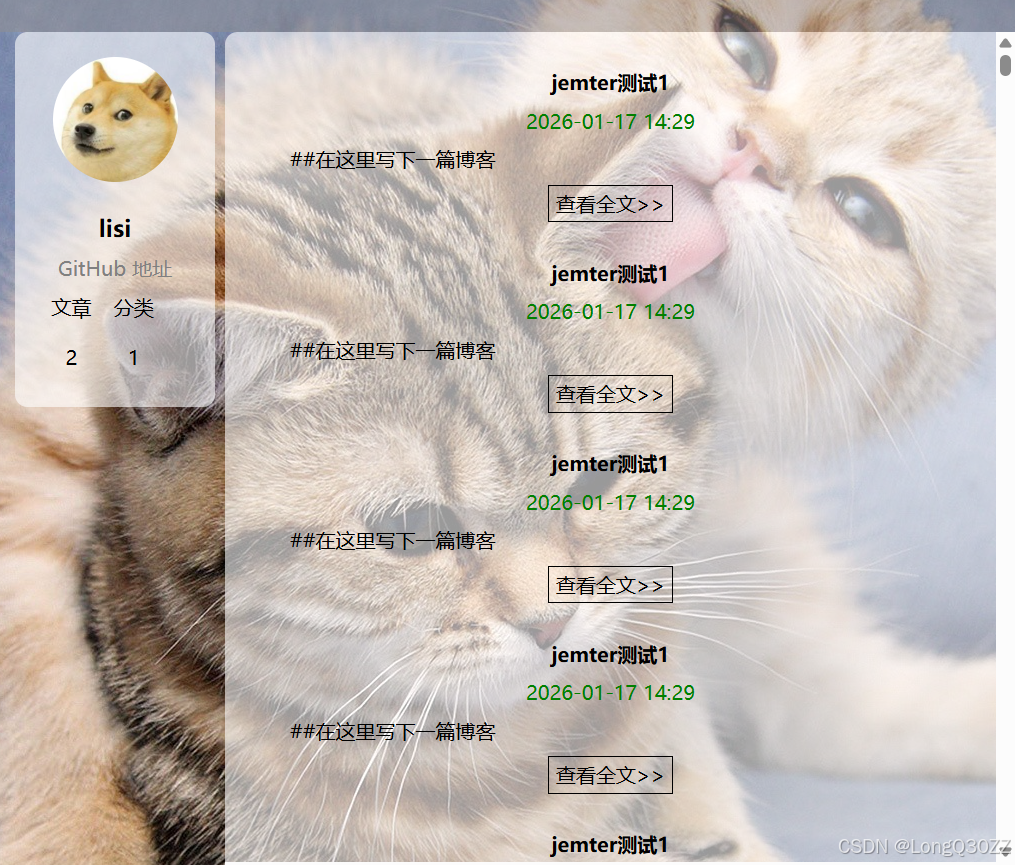
1)当我们正确的输入账号和密码,会跳转到博客列表页,在这个页面会显示你的名字和你发布博客的数量,时间,内容等
效果如图:
2-5博客详情页测试
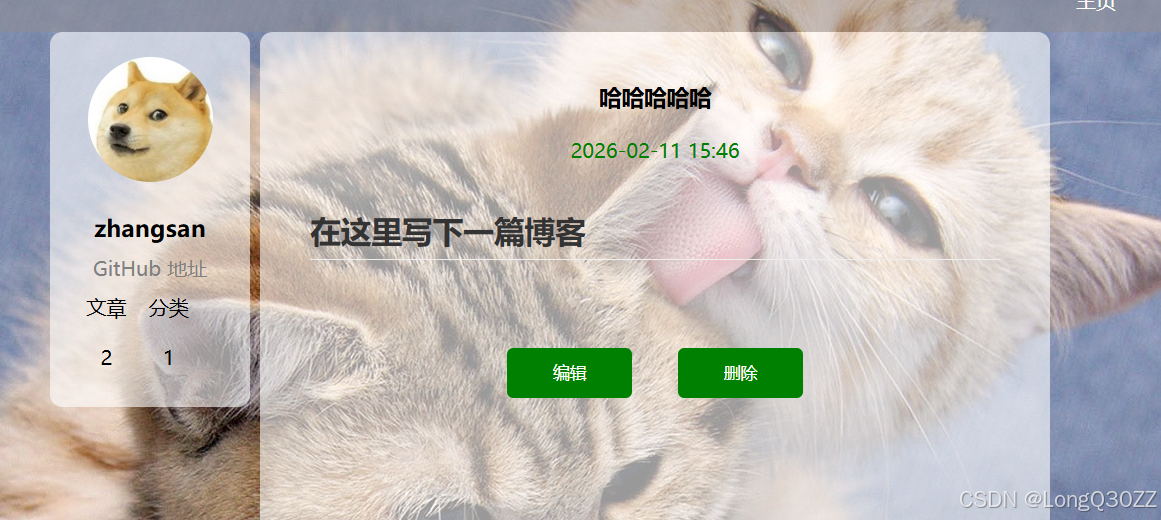
在列表页成功显示的条件下,我们点击"查看原文"就可以进入到博客列表详情页
博客详情页里面会显示用户的名称,文章的数量,博客的内容
如果查看的文章是用户自己发布的,那么就可以对文章进行删除和修改,如果是其他用户发布的就只能查看

2-6博客编辑页测试
在博客列表页点击"写博客",就可以进入到博客编辑页面
博客编辑页有,博客标题编辑区,内容编辑区,内容显示区,文本工具区
2-6-1发布博客
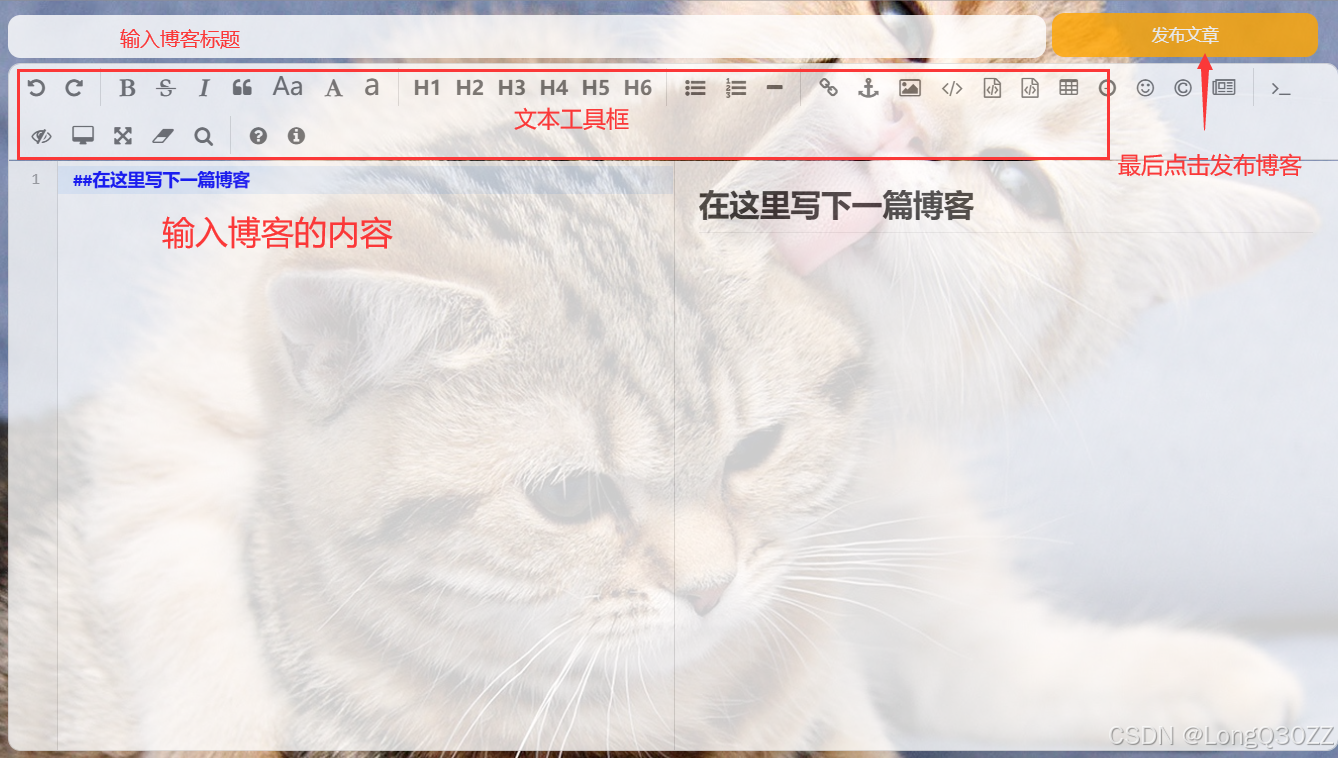
博客的标题和内容不能为空,不然就发布不了
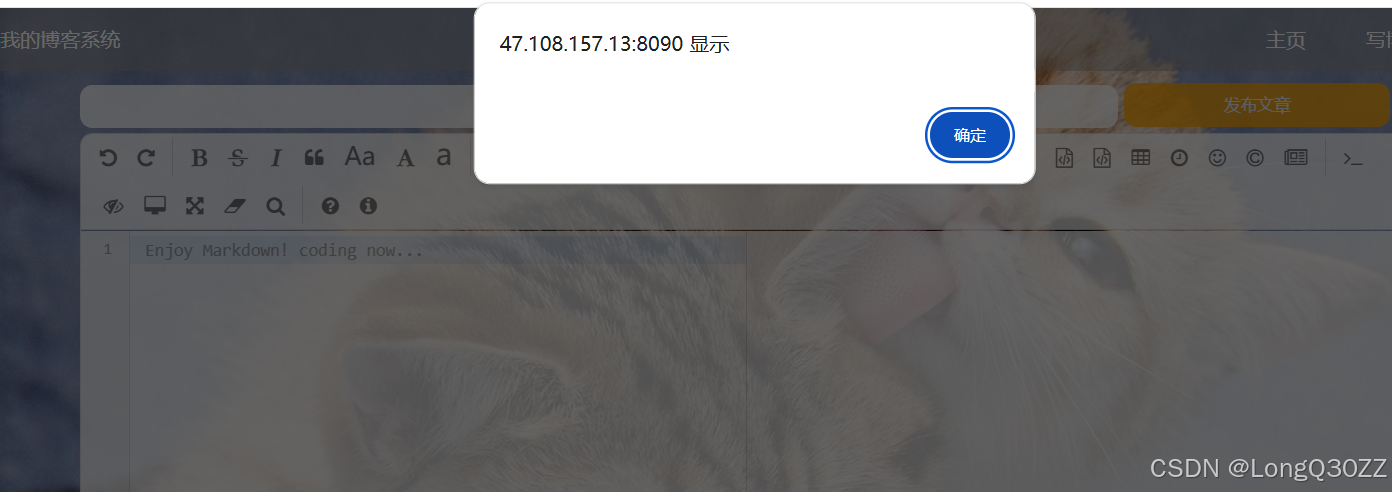
最终效果:

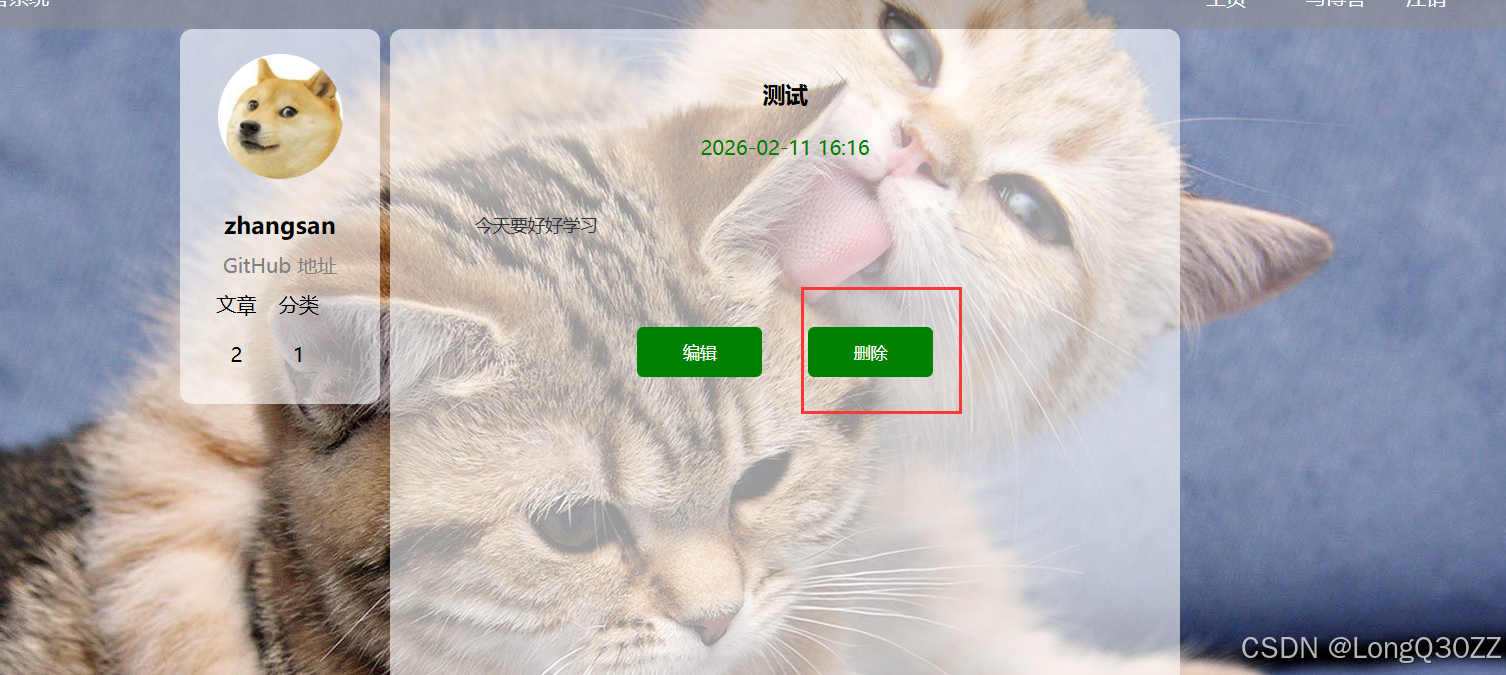
2-6-1删除博客
在博客详情页中点击自己发布的博客,就可以进入到详情页里面删除自己写的博客
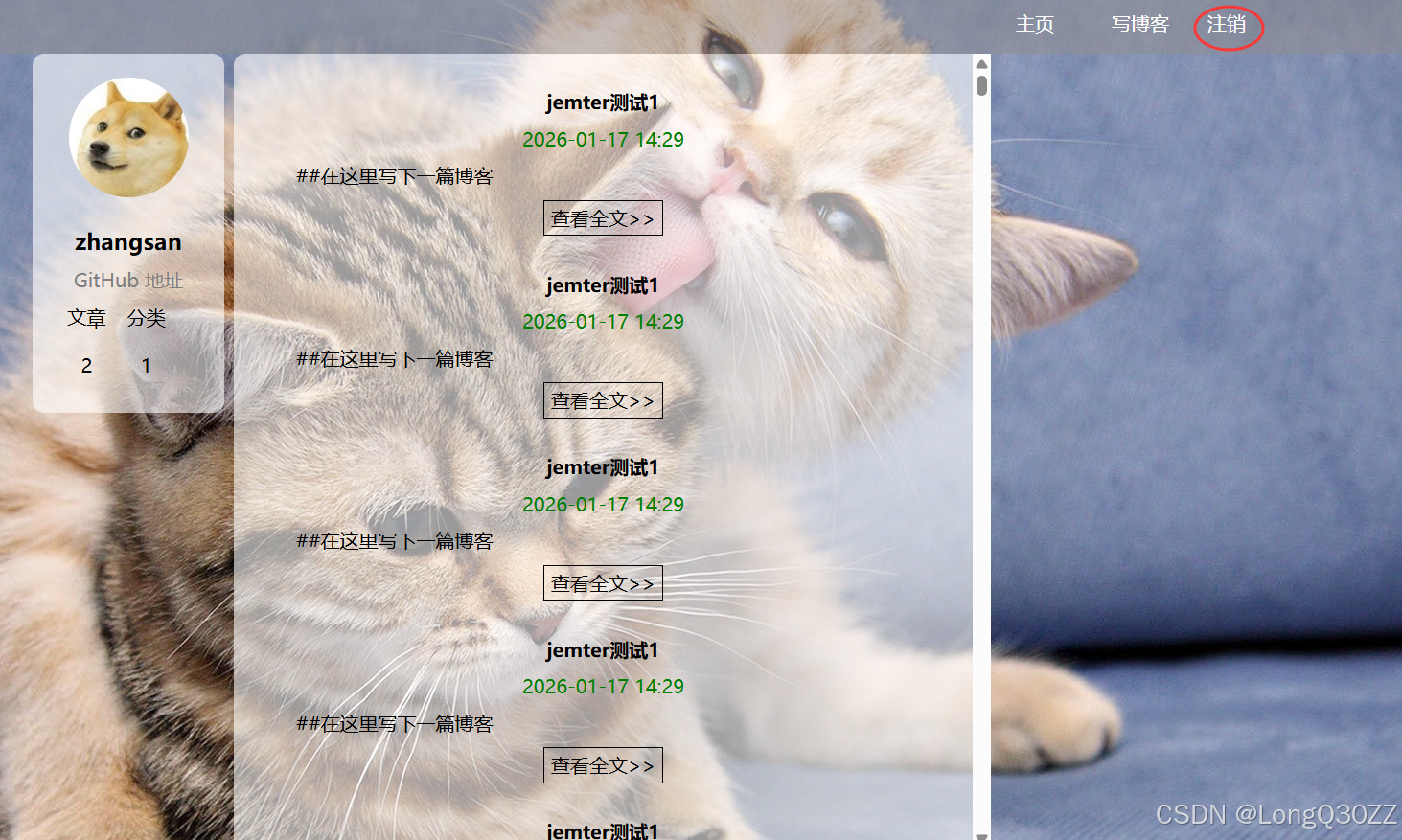
2-7博客退出测试
在博客详情页中,点击注销就可以退出登录
3.用selenium来进行Web自动化测试
selenium 是⼀个web自动化测试⼯具,selenium 中提供了丰富的方法供给使用者进⾏web自动化测试。是一个用于模拟浏览器操作的 Python 库(也支持 Java、C# 等语言) ,可以代替你手动操作浏览器:比如打开网页、点击按钮、输入文字、滚动页面、提交表单,甚至获取网页上的内容。
webdriver-manager: 是一个 Python 第三方库,核心作用是自动管理 Selenium 所需的浏览器驱动(比如 ChromeDriver、GeckoDriver、EdgeDriver 等)。 webdriver-manager 能自动检测浏览器版本、自动下载匹配的驱动、自动配置驱动路径。通过使用WebDriver Manager,我们可以确保浏览器驱动版本始终与浏览器版本保持⼀
致,从而避免因版本不匹配而导致的各种问题。
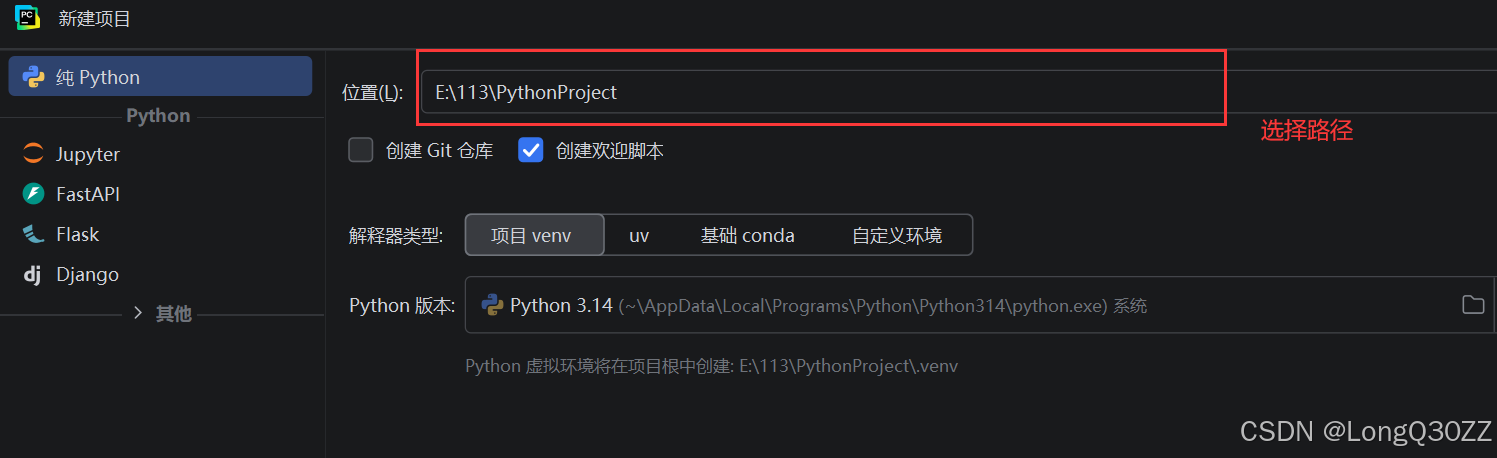
3-1新建项目
安装selenium库,本次用的是4.0.0版本。webdriver-manager用的是4.0.2版本
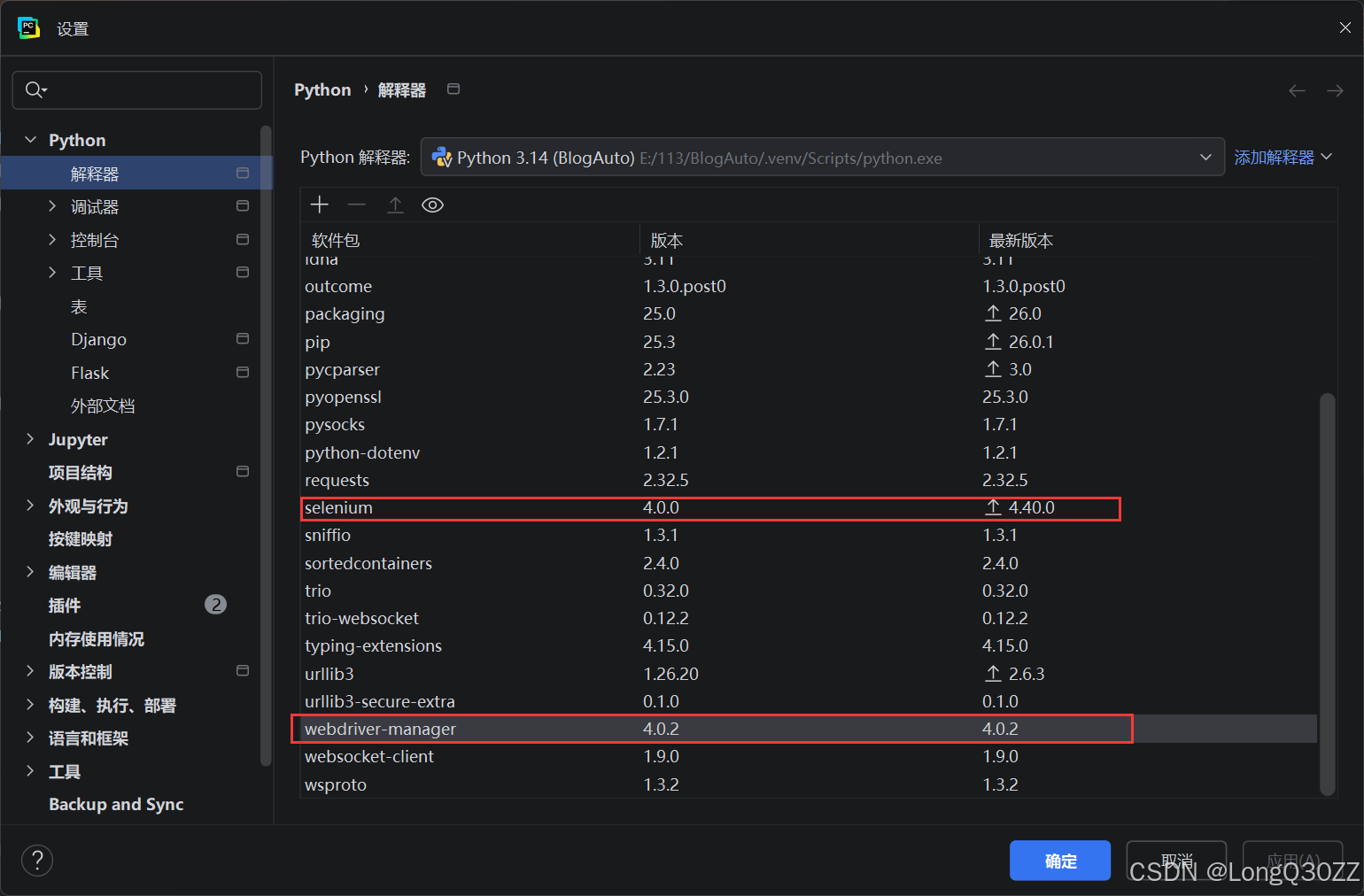
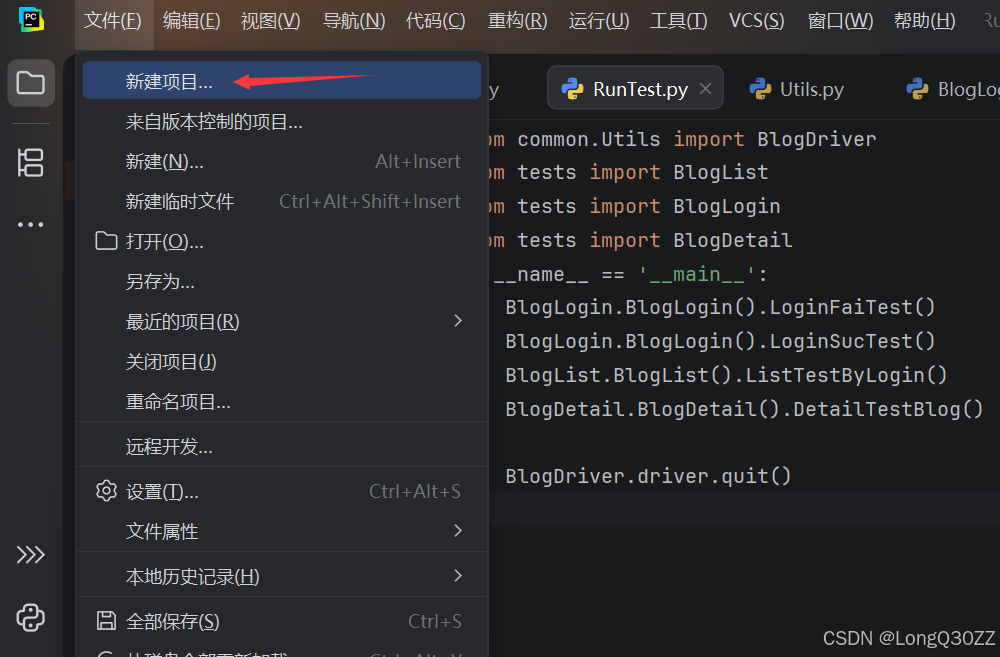
在PyCharm 中新建一个项目
3.2 参照测试用例,编写自动化脚本
我们主要测试的页面有博客首页,博客登录页,博客列表页,博客详情页,博客编辑页

最后新建的文件如下:
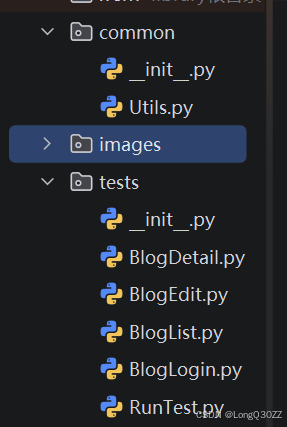
其中的images 文件夹用来截取自动化测试中生成的图片,有助于我们更好的测试
3-2-1创建一个浏览器对象
python
import datetime
import os.path
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from webdriver_manager.drivers.chrome import ChromeDriver
import sys
class Driver:
driver = ""
def __init__(self):
options = webdriver.ChromeOptions()
self.driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()),options=options)
self.driver.implicitly_wait(3)
def getScreenShot(self):
#创建屏幕截图
#放在images文件夹中
#同一天的截图放在一起
dirname=datetime.datetime.now().strftime("%Y-%m-%d")
if not os.path.exists("../images/"+dirname):
os.mkdir("../images/"+dirname)
filename=sys._getframe().f_back.f_code.co_name+"-"+datetime.datetime.now().strftime("%Y-%m-%d%H%M%S")+".png"
self.driver.save_screenshot("../images/"+filename)
BlogDriver = Driver()3-2-2博客登录页的测试用例
python
#测试博客登录系统
from selenium.webdriver.common.by import By
import time
from common.Utils import BlogDriver
class BlogLogin:
url=None
driver=None
def __init__(self):
self.url="http://47.108.157.13:8090/blog_login.html"
self.driver= BlogDriver.driver
self.driver.get(self.url)
#登录成功的方法
def LoginSucTest(self):
self.driver.implicitly_wait(3)
self.driver.find_element(By.CSS_SELECTOR,"#username").send_keys("lisi")
self.driver.find_element(By.CSS_SELECTOR,"#password").send_keys("123456")
self.driver.find_element(By.CSS_SELECTOR,"#submit").click()
self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.left > div > h3")
time.sleep(3)
BlogDriver.getScreenShot()
self.driver.back()
#登录失败的方法
def LoginFaiTest(self):
self.driver.find_element(By.CSS_SELECTOR,"#username").clear()
self.driver.find_element(By.CSS_SELECTOR,"#password").clear()
self.driver.find_element(By.CSS_SELECTOR,"#username").send_keys("lisi")
self.driver.find_element(By.CSS_SELECTOR,"#password").send_keys("123")
self.driver.find_element(By.CSS_SELECTOR,"#submit").click()
time.sleep(2)
alert=self.driver.switch_to.alert
alert.accept()
BlogDriver.getScreenShot()3-2-3博客详情页的测试用例
python
from selenium.webdriver.common.by import By
import time
from common.Utils import BlogDriver
#登录情况下,博客详情页
class BlogDetail:
url=""
driver=""
def __init__(self):
self.url="http://47.108.157.13:8090/blog_detail.html?blogId=58320"
self.driver=BlogDriver.driver
self.driver.get(self.url)
def DetailTestBlog(self):
time.sleep(2)
#博客标题
self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.right > div:nth-child(1) > div.title")
#时间
self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.right > div:nth-child(1) > div.date")
self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.right > div:nth-child(1) > a")
BlogDriver.getScreenShot()3-2-4博客列表页的测试用例
python
import time
from selenium.webdriver.common.by import By
from common.Utils import BlogDriver
#博客首页测试用例
class BlogList:
url=""
driver=""
def __init__(self):
self.url = "http://47.108.157.13:8090/blog_list.html"
self.driver=BlogDriver.driver
self.driver.get(self.url)
#博客首页(登录成功的情况下)
def ListTestByLogin(self):
self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.left > div > h3")
self.driver.find_element(By.CSS_SELECTOR,"body > div.nav > a:nth-child(5)")
self.driver.find_element(By.CSS_SELECTOR,"body > div.nav > a:nth-child(6)")
time.sleep(2)
BlogDriver.getScreenShot()
#3-2-5博客编辑页的测试用例
python
import time
from selenium.webdriver.common.by import By
from common.Utils import BlogDriver
#测试博客编辑页面
class BlogEdit:
url = ""
driver = ""
def __init__(self):
self.url = "http://192.168.47.135:8653/blog_system/blog_edit.html"
self.driver = BlogDriver.driver
self.driver.get(self.url)
#正确发布博客(登陆状态下)
def EditSucTestByLogin(self):
self.driver.find_element(By.CSS_SELECTOR,"#title").send_keys("自动化测试创建")
#找到编辑区域,输入关键词(编辑区域不可操作)
#菜单栏无法元素无法定位
#博客系统编辑区域默认情况下就不为空,可以暂不处理
#直接点击发布按钮来发布博客
self.driver.find_element(By.CSS_SELECTOR,"#submit").click()
#点击完成之后出现页面的跳转,页面跳转需要加载时间,可能会出现代码执行的速度比页面渲染的速度要快,导致元素查找不到,因此可以添加等待
#添加隐式等待和显示等待都可以,任选择一个
#隐式等待:创建浏览器对象之后就可以加上,因为隐式等待的作用域在driver整个生命周期
#显示等待:可以作用在当前代码中
actual=self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.right > div:nth-child(1) > div.title").text
assert actual == "自动化测试创建"
#屏幕截图
BlogDriver.getScreeShot()RunTest.py为统一的测试入口:
按业务流程顺序调用各个模块的测试方法,形成一条完整的测试链路(登录 → 列表 → 详情 → 编辑)
python
from common.Utils import BlogDriver
from tests import BlogList
from tests import BlogLogin
from tests import BlogEdit
from tests import BlogDetail
if __name__ == '__main__':
BlogLogin.BlogLogin().LoginFaiTest()
BlogLogin.BlogLogin().LoginSucTest()
BlogList.BlogList().ListTestByLogin()
BlogDetail.BlogDetail().DetailTestBlog()
BlogEdit.BlogEdit().EditSucTestByLogin()
BlogDriver.driver.quit()我们可以在images 文件夹中看到自动化测试中生成的截图文件
4.自动化测试和手动测试的对比
| 对比维度 | 自动化测试 | 手动测试 |
|---|---|---|
| 执行主体 | 脚本 / 工具自动执行 | 测试人员手工操作 |
| 重复执行 | 适合大量、反复回归 | 适合少量、临时验证 |
| 执行效率 | 速度快,可批量 / 并行 / 7×24小时 | 速度慢,受人力、时间限制 |
| 结果稳定性 | 步骤一致,无人工误差 | 易疲劳、漏测、误操作 |
| 适用场景 | 回归、冒烟、接口、性能、压力 | 探索性、易用性、视觉、临时需求 |
| 前期成本 | 高(写脚本、维护) | 低(上手快、无需编码) |
| 长期成本 | 项目越大、迭代越频繁,成本越低 | 项目越大,人力成本越高 |
自动化测试能够取代人工测试吗?
答:不能,自动化测试无法完全取代人工测试。自动化适合重复性、回归性、大批量的测试任务,能提高效率和稳定性;而探索性测试、用户体验、需求快速变更等场景,必须依靠人工测试的思考和灵活性。二者是互补关系,不是替代关系。
自动化测试不能完全取代人工测试,二者是互补关系,不是替代关系。
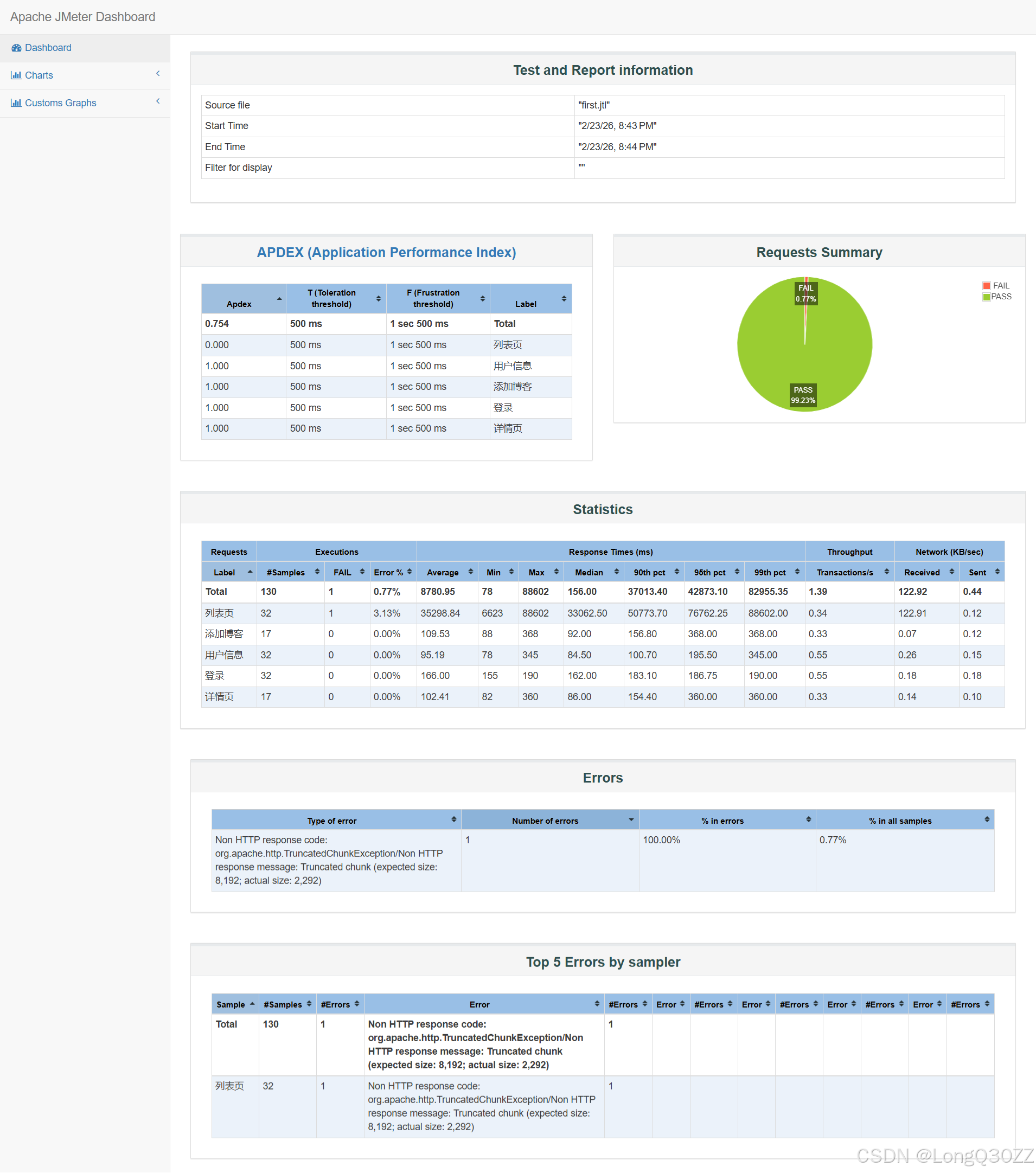
5.性能测试
使用jmeter对博客系统进行性能测试
介绍:JMeter 是 Apache 开源的 性能测试 & 接口测试工具 ,主要用来给软件做 "压力体检" 。可以理解为一个能模拟大量用户、自动发请求、自动出报告的测试机器人。
可以在开发者工具中查看接口的请求,在postman中查看响应
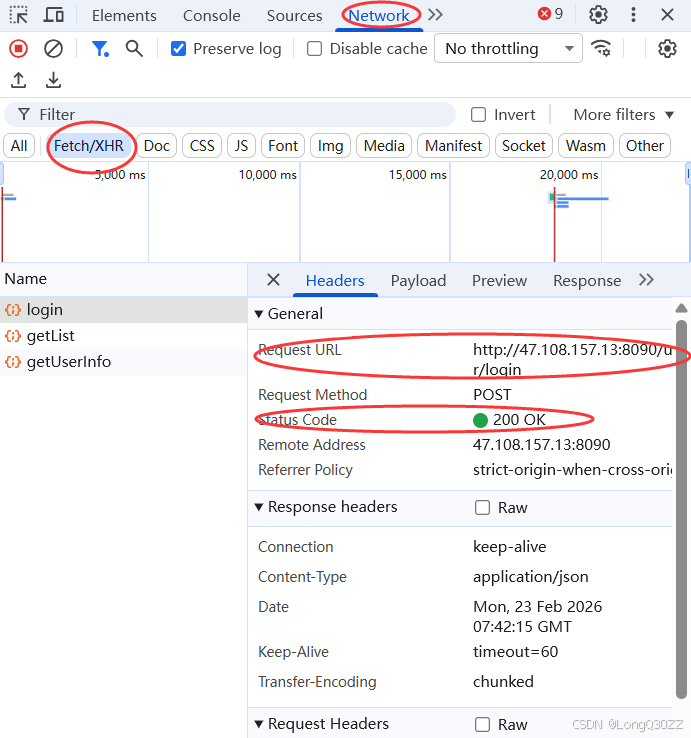
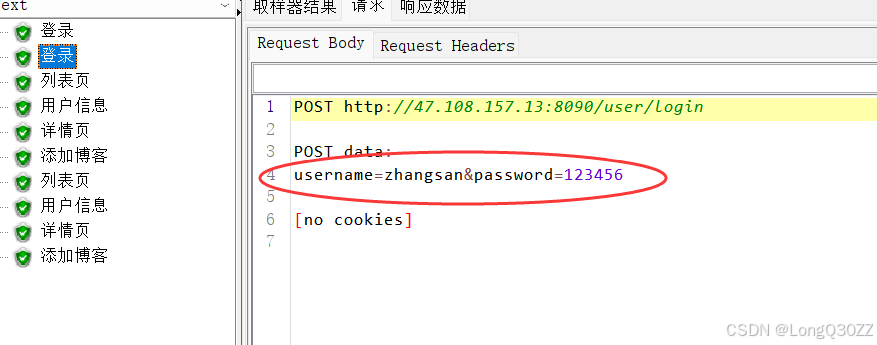
登录成功的响应值
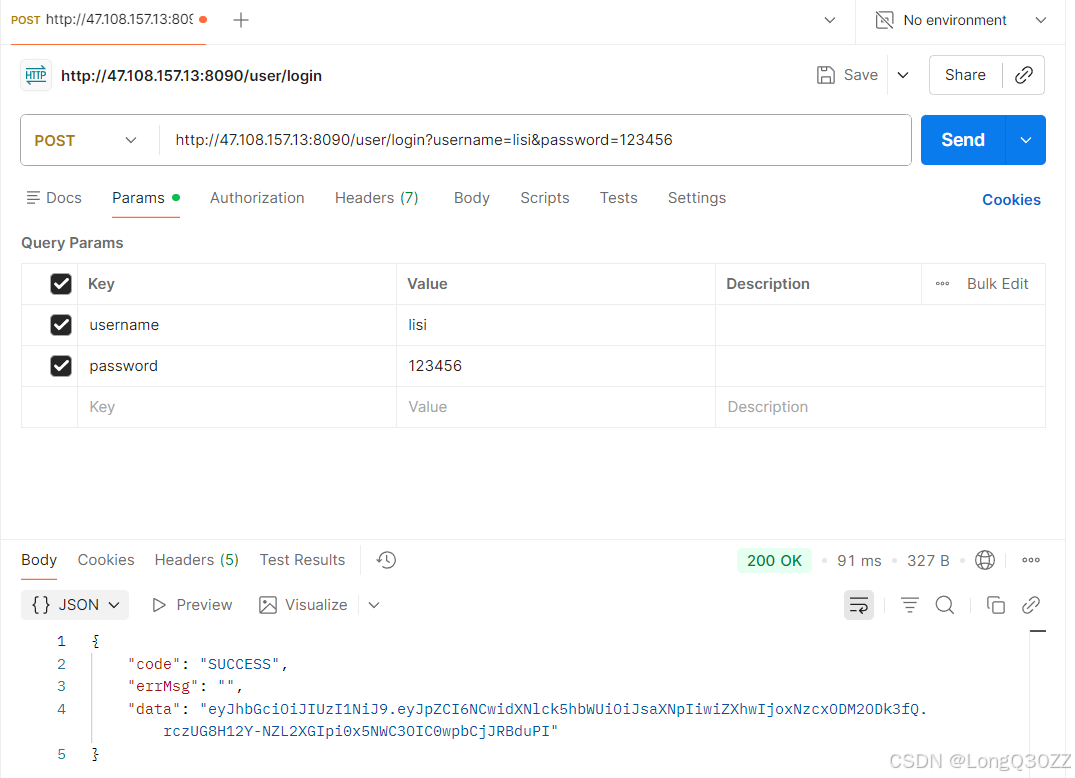
5.1在JMeter里测试博客登录接口
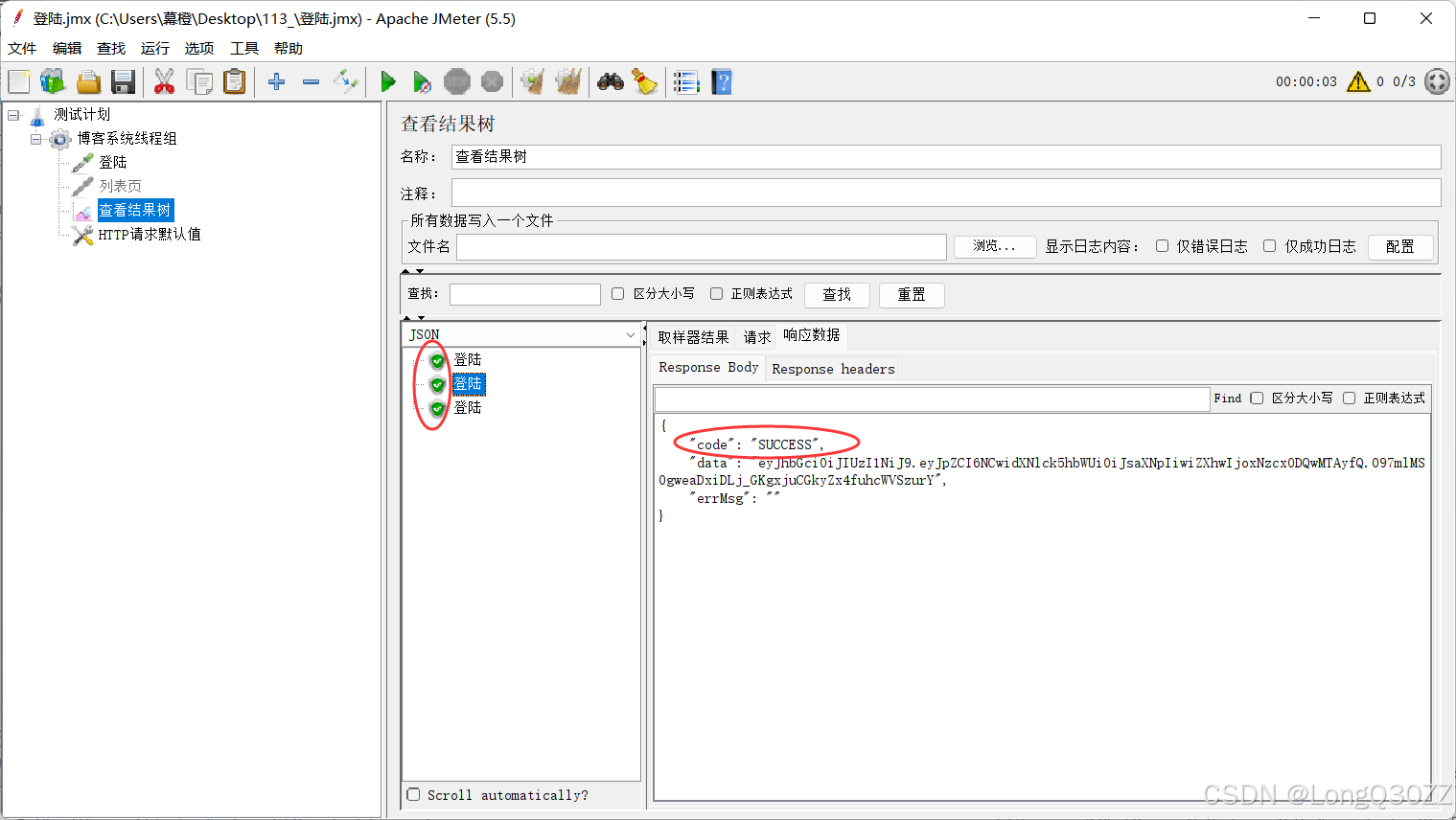
图中绿色的图标即表示测试通过,状态码也正常正确
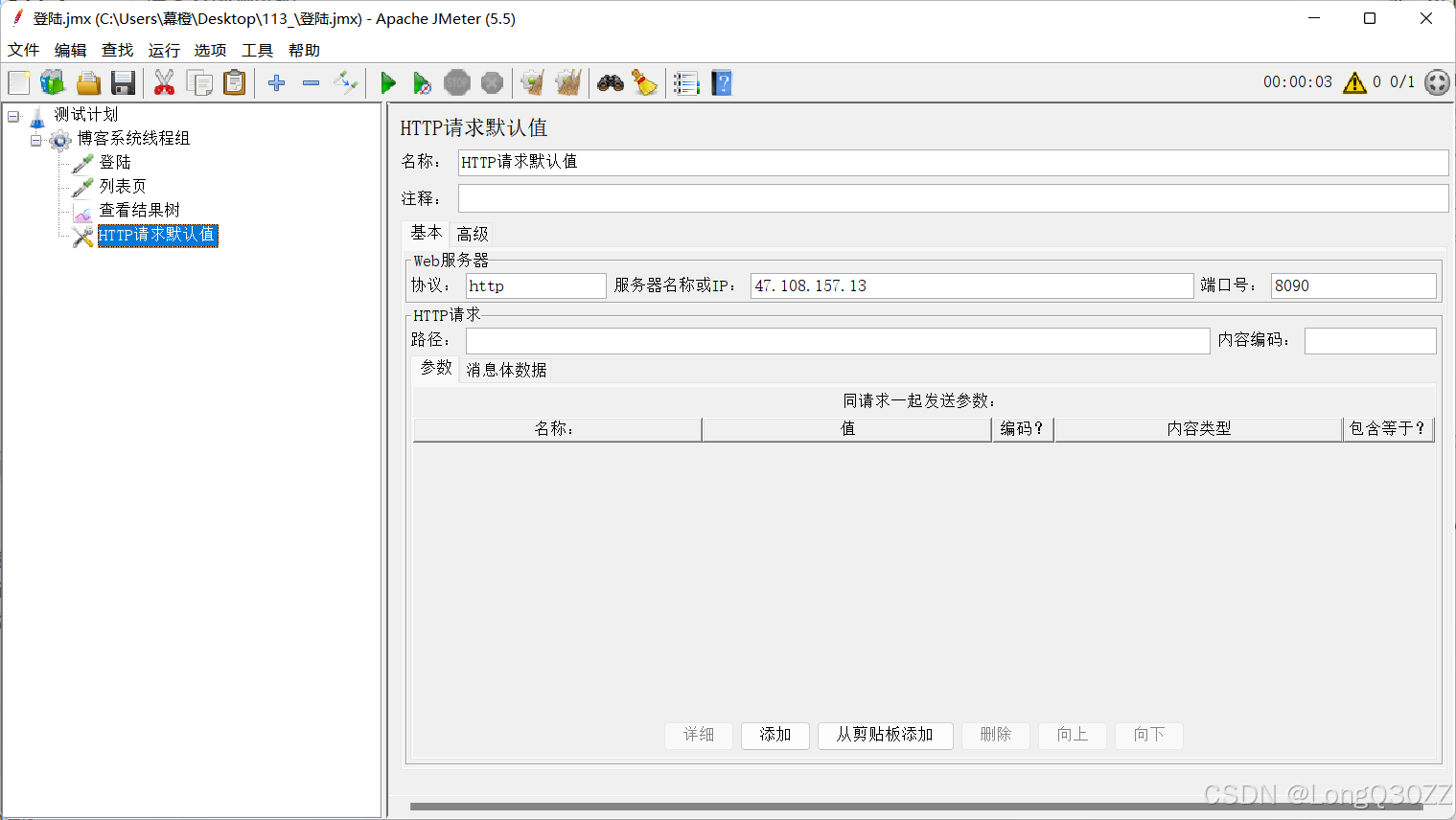
在同一个系统中,协议+IP+端口号是不会发生改变的,我们可以添加HTTP请求默认值 ,给所有接口统一填 "公共参数 ",不用每个接口重复写。
5.2在JMeter里测试博客列表页接口
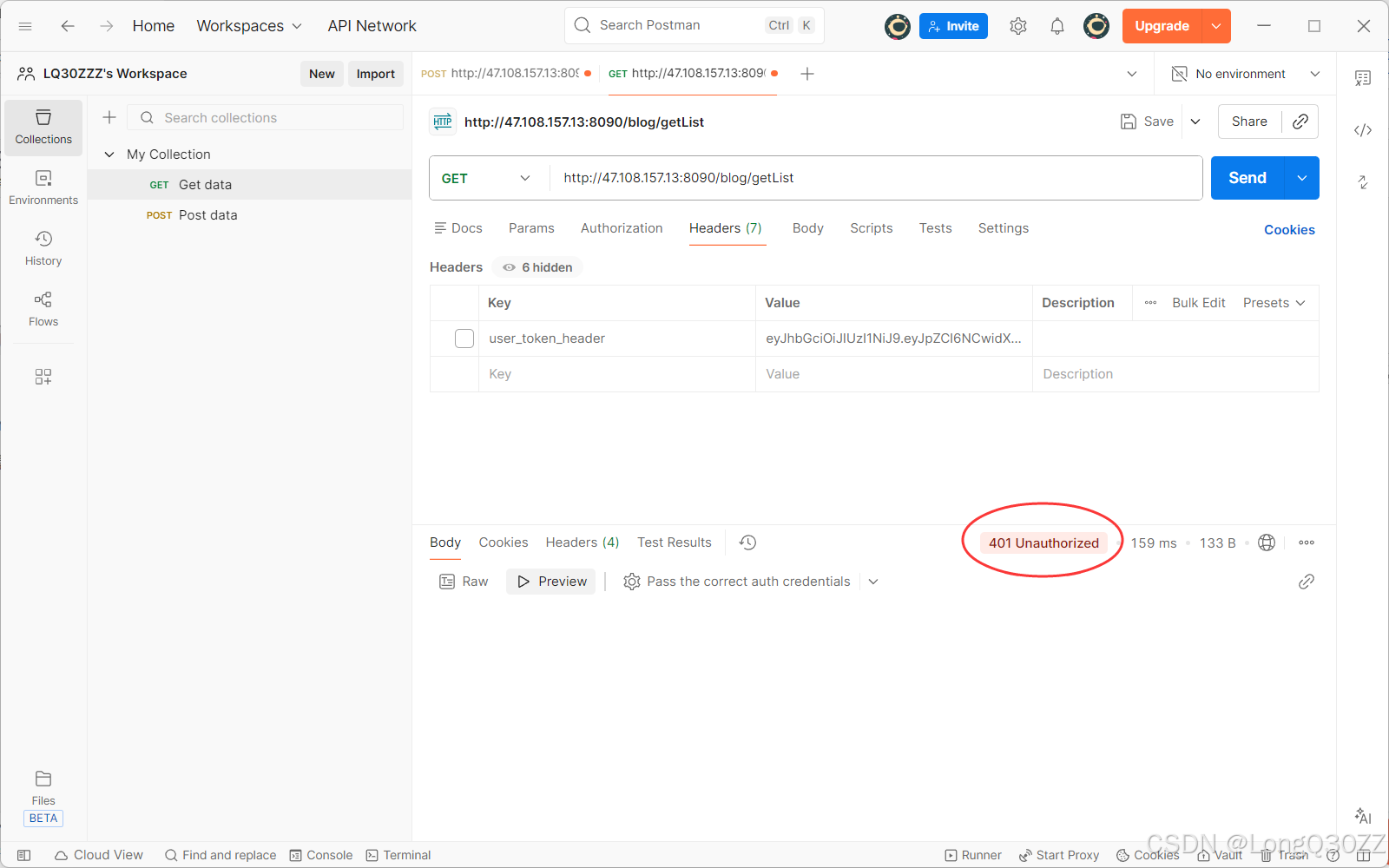
当我们要测试博客列表页时,我们要添加请求头数据,不然就会请求失败
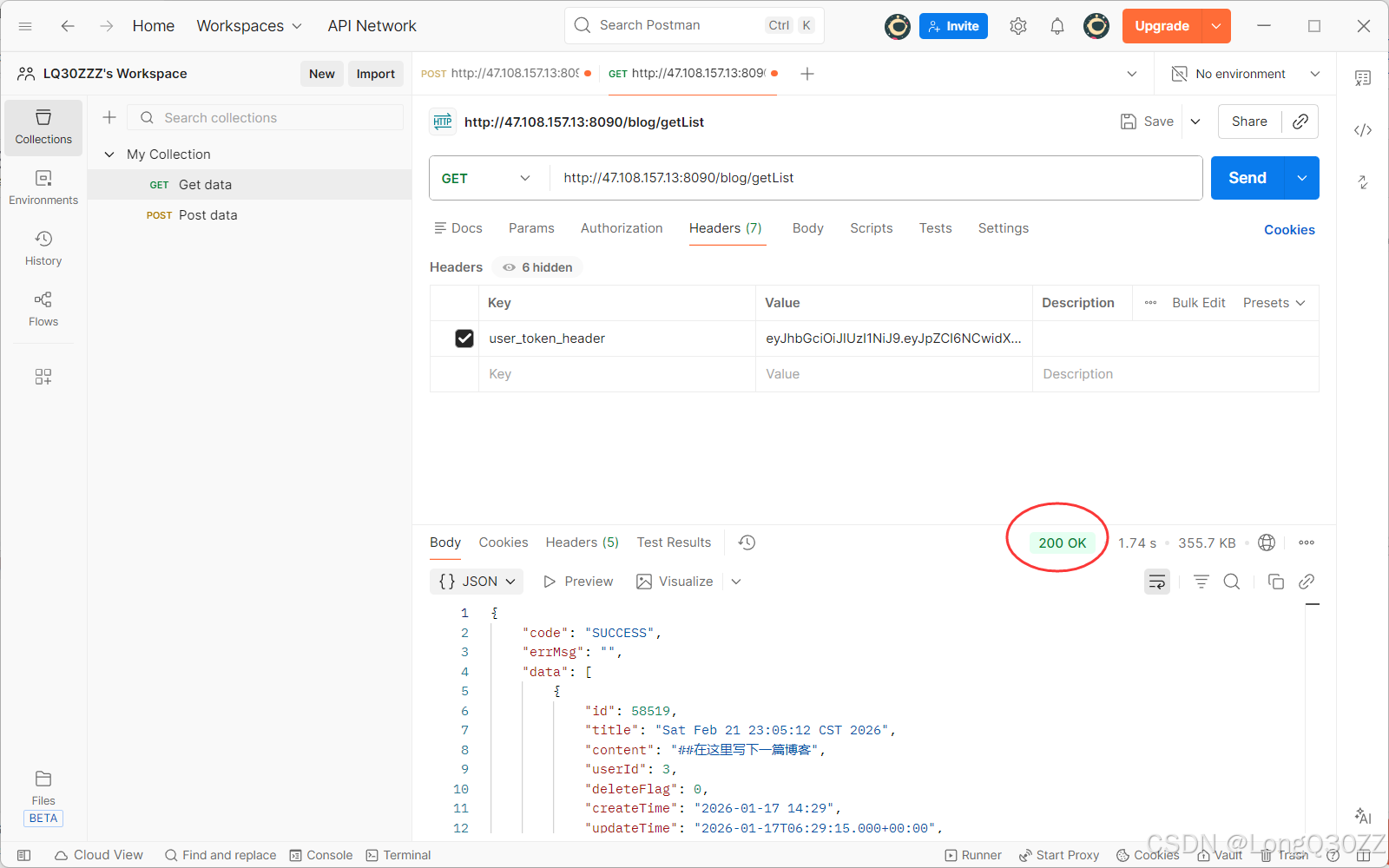
添加之后
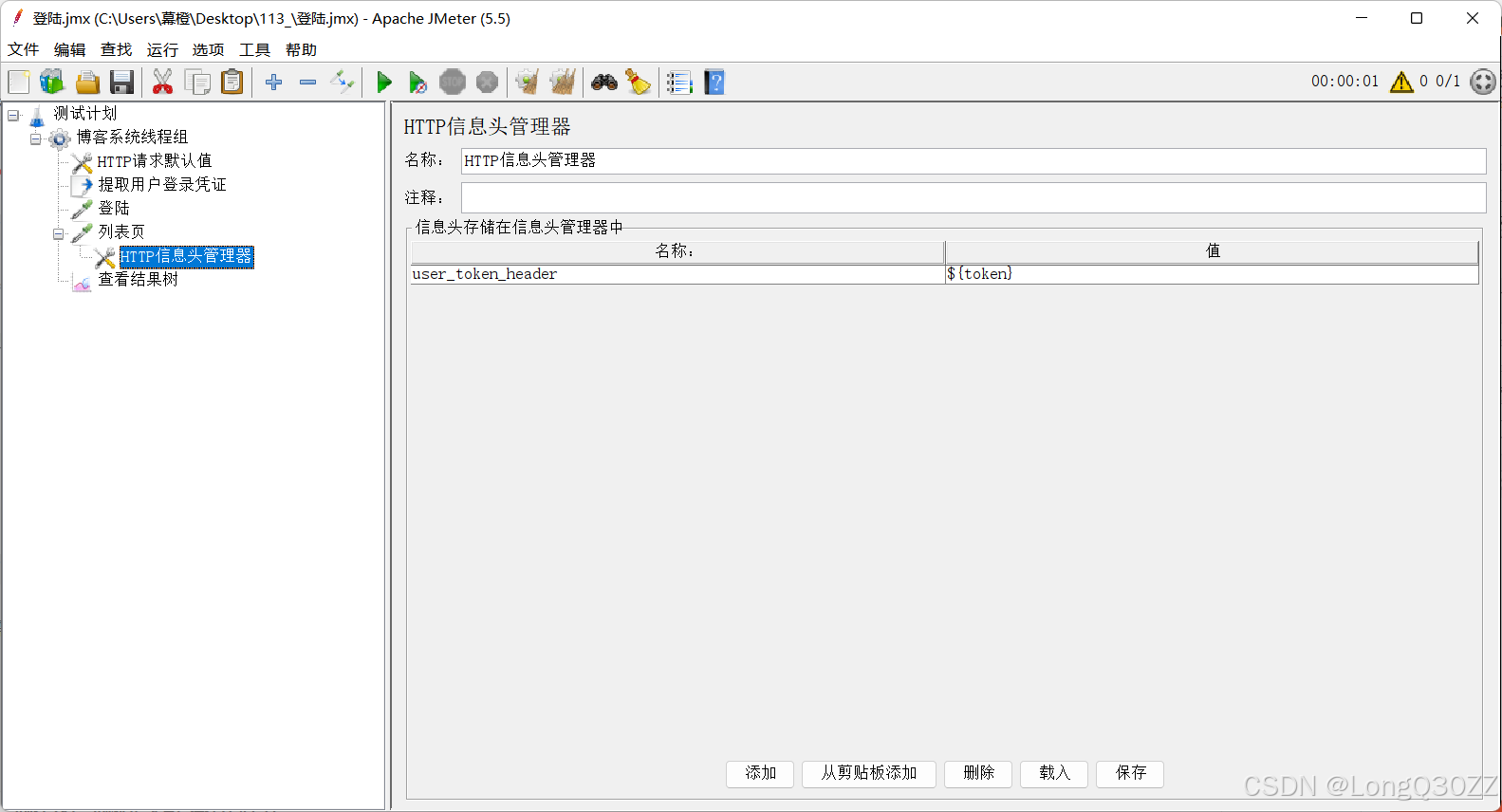
在JMeter中添加HTTP请求头管理器
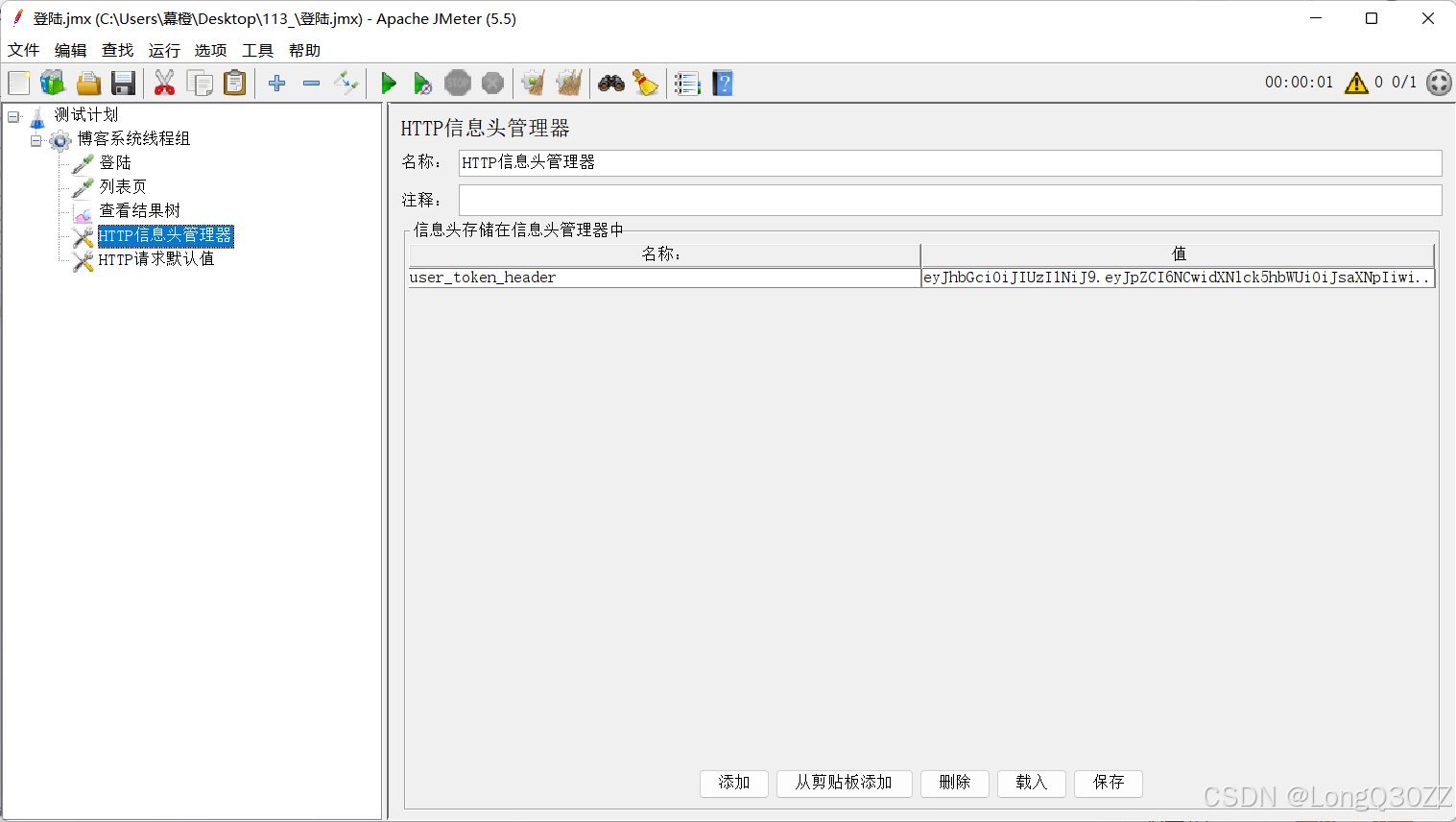
把HTTP信息头管理器移动到列表页中,那么HTTP信息头管理器只作用在列表页接口中

我们还可以用JSON提取器 来获得我们的登录凭证
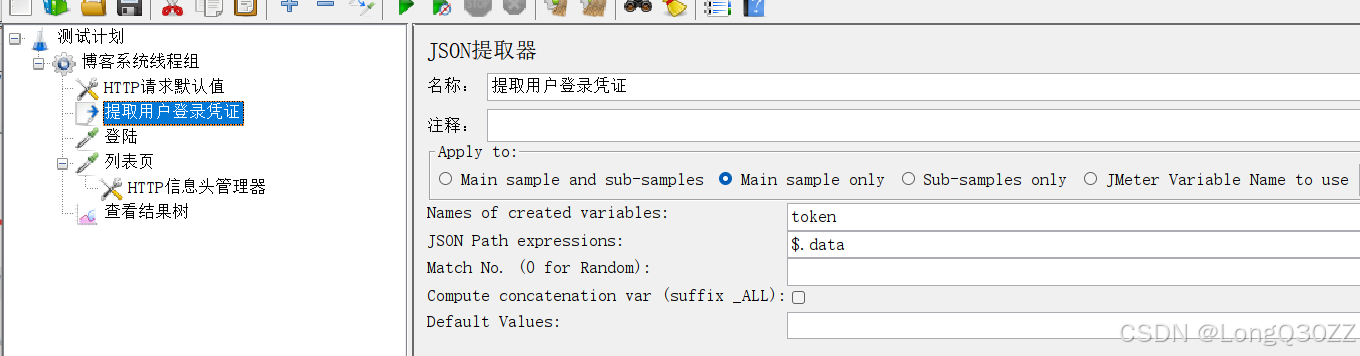
HTTP信息头管理器的参数也需要改变
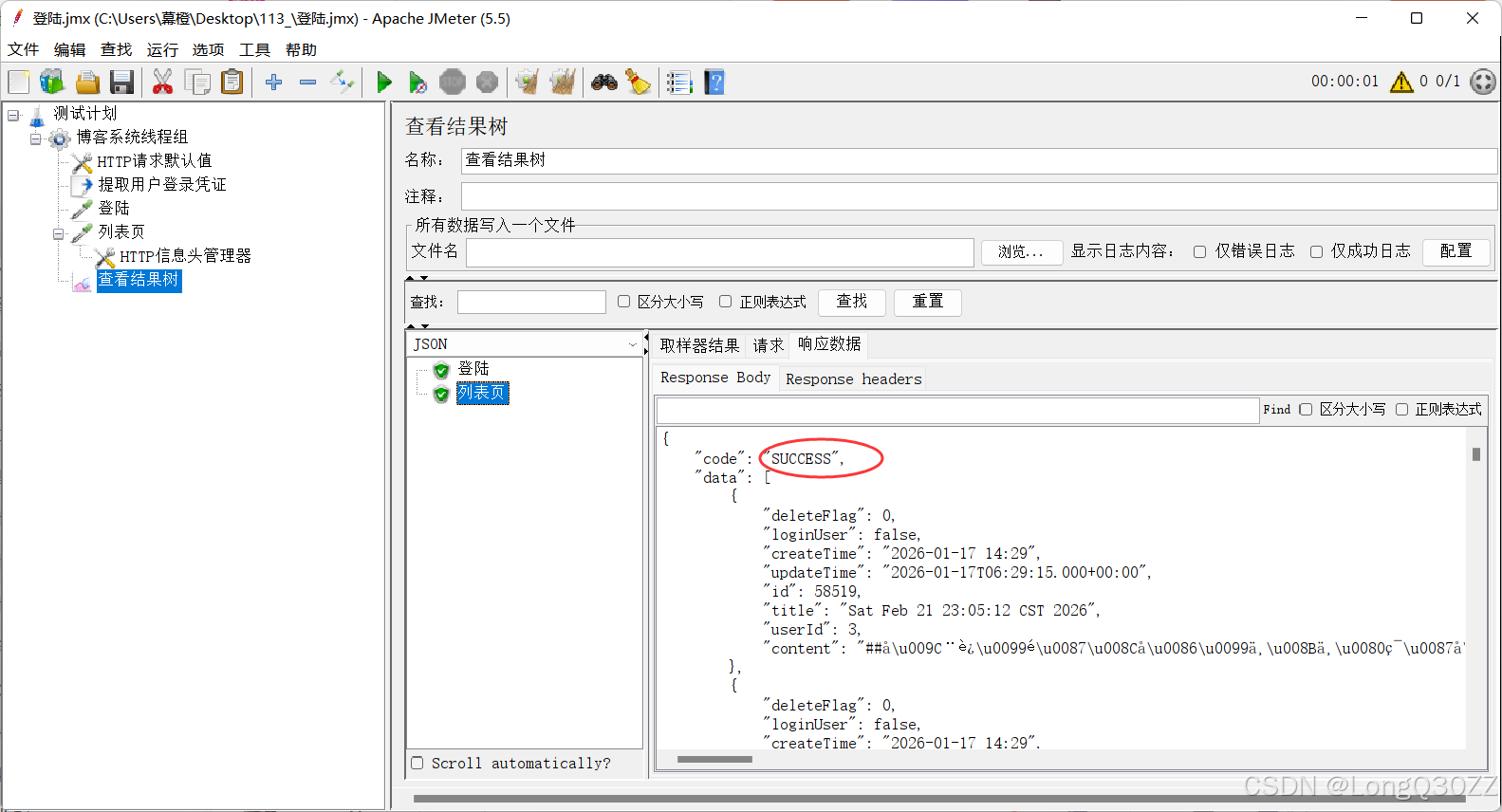
最后我们查看测试结果
5.3在JMeter里测试博客用户信息接口
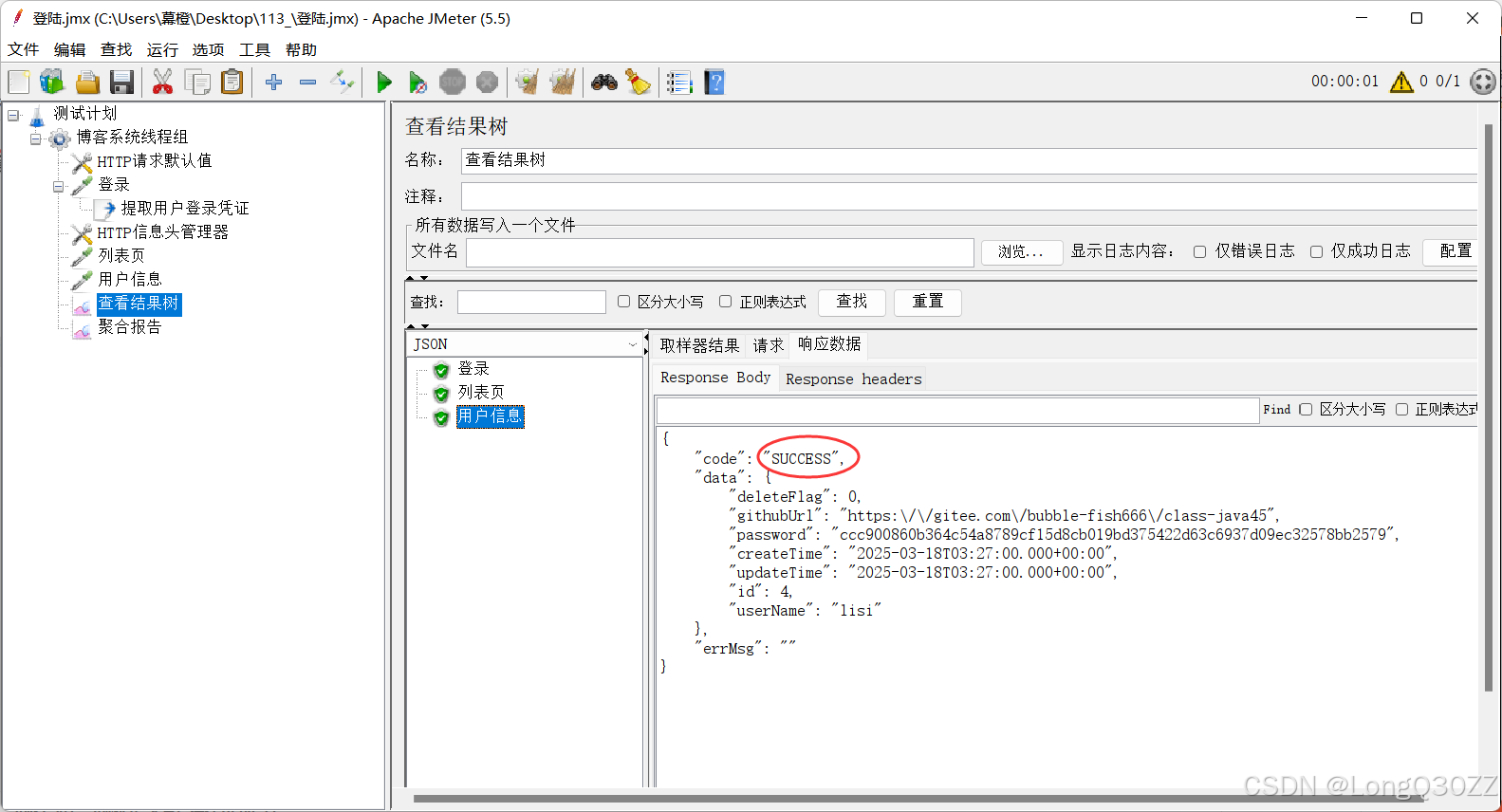
当多个接口中都有符合条件的JSON提取字段,则会发生覆盖,所以我们要把提取用户登陆凭证 这个JSON提取器放到登录 子目录下,这样提取的就是登录接口的token

查看测试结果
5.3在JMeter里测试博客详情页接口
先在postman上测试一下
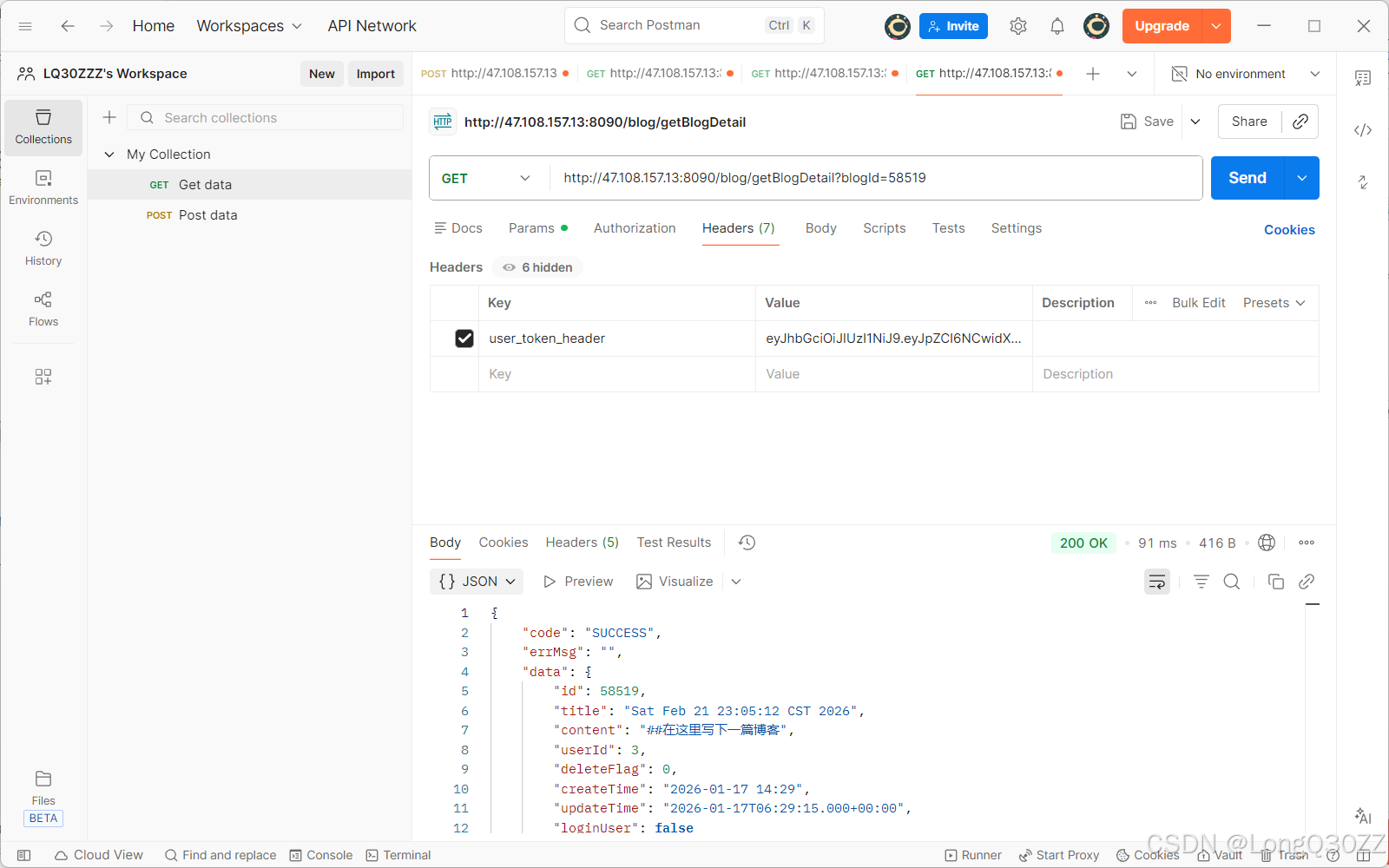
博客详情页接口
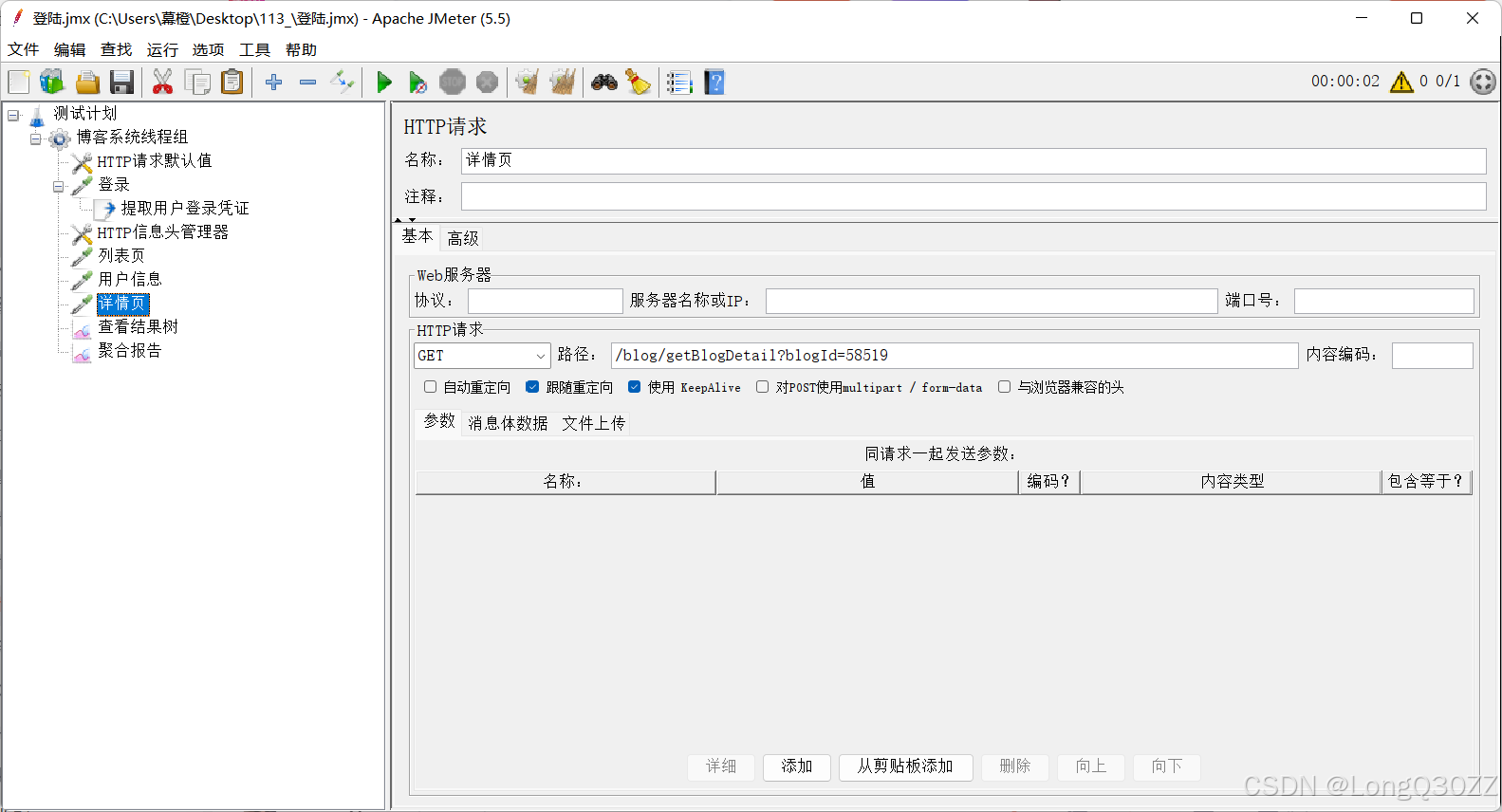
查看测试结果
如果这样测试的话不够灵活,因为我们的blogid是会变的,所以我们要用JSON提取器,把列表页中的blogid给提取出来
把JSON提取器放到列表页下面
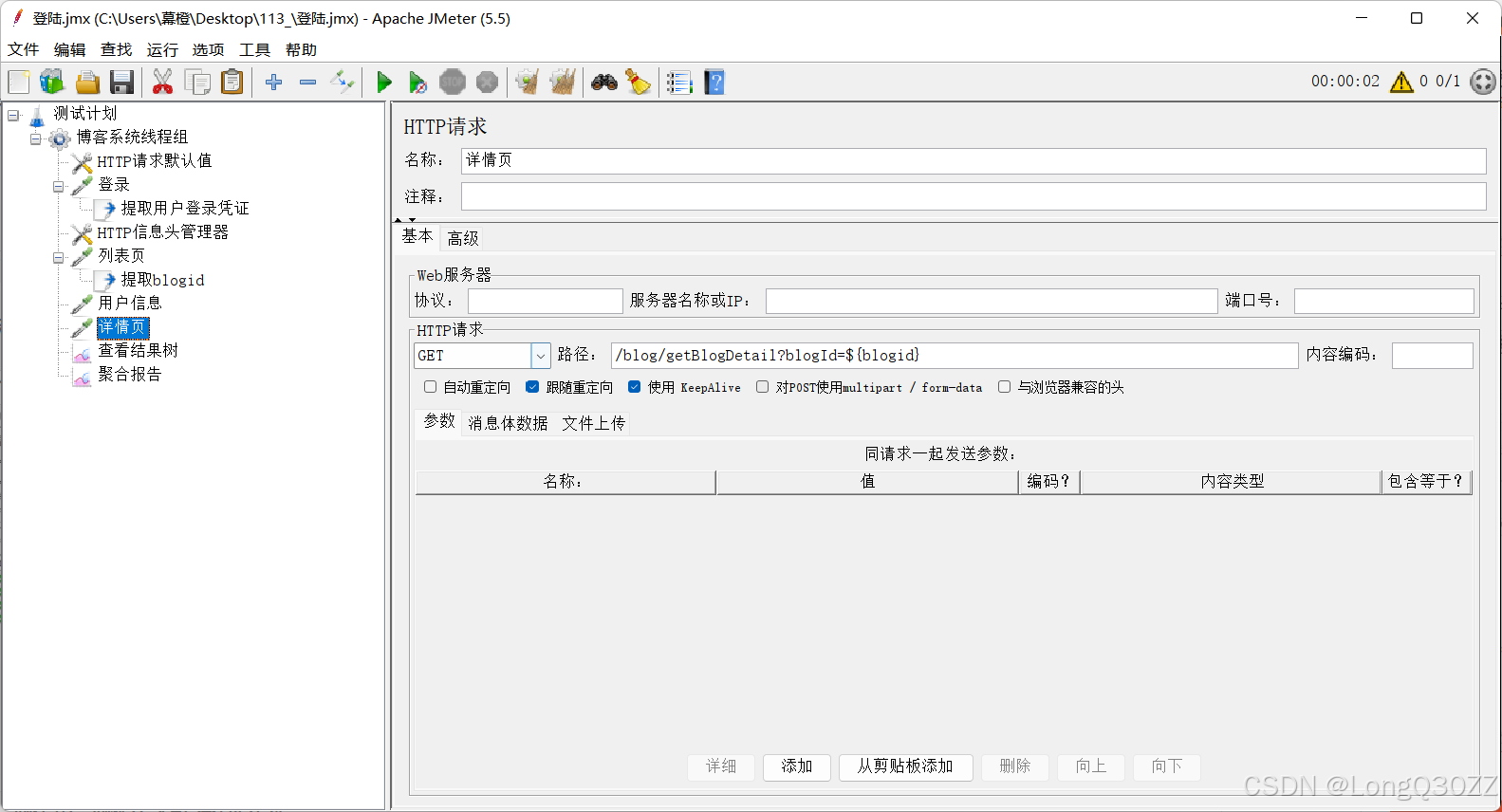
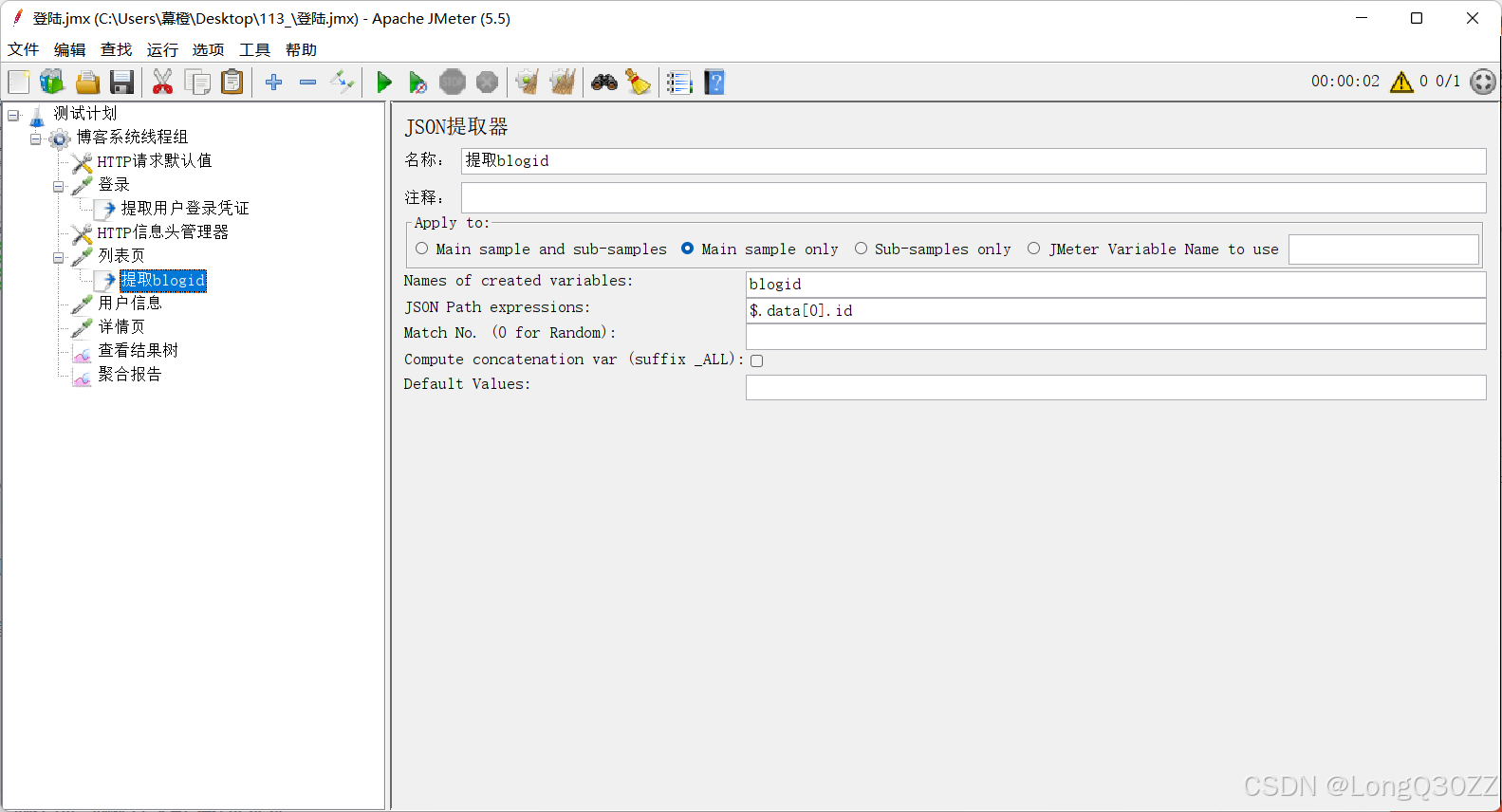
查看结果树,结果和上面的方法一样但是更加灵活
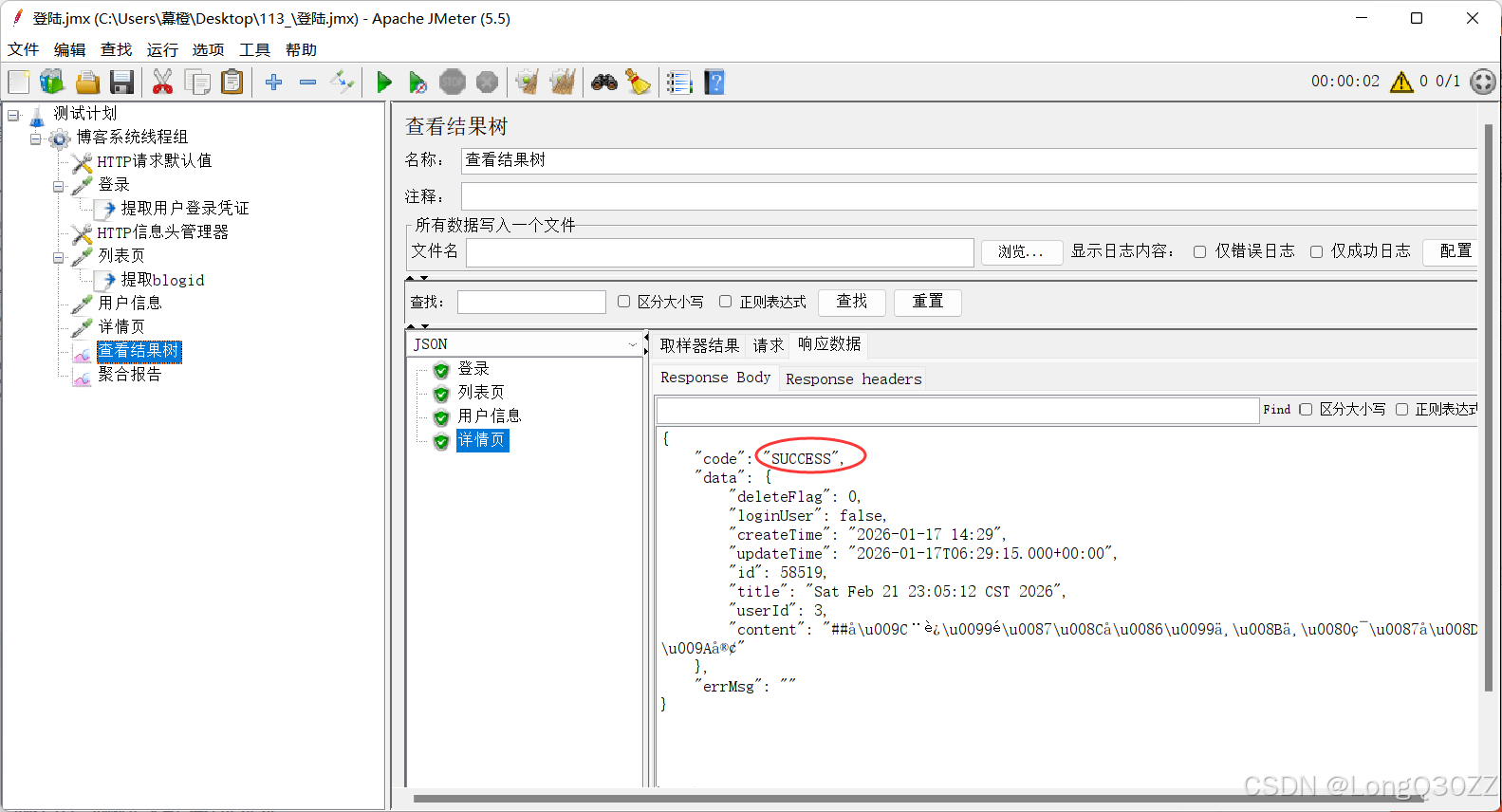
5.4在JMeter里测试添加博客接口
这个接口和上面不同的地方在于我们要多配置一个信息
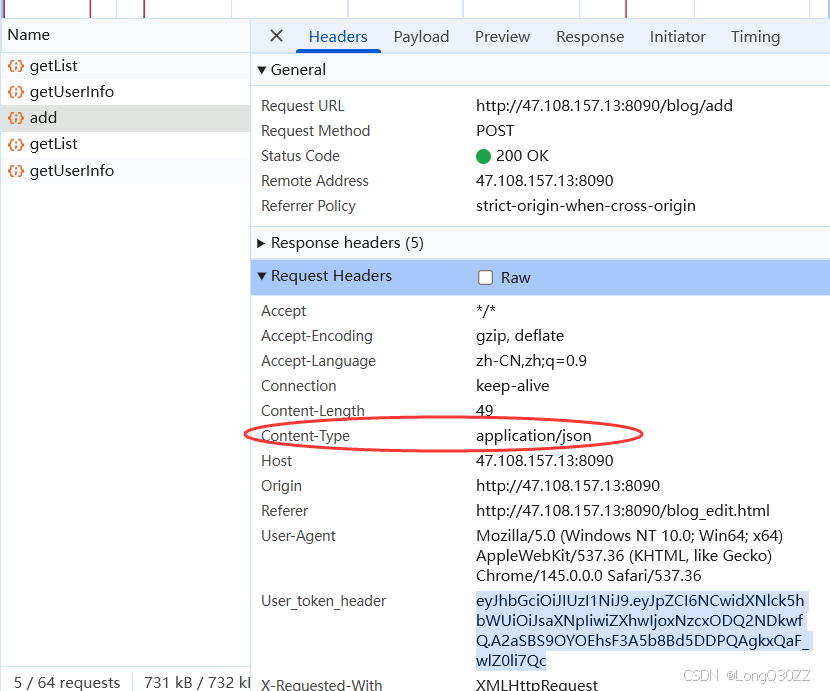
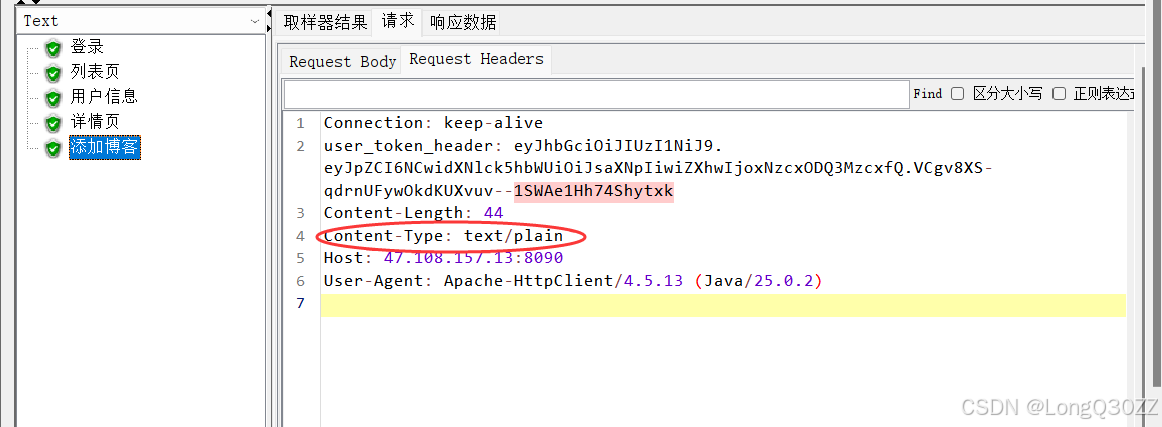
通过对比JMeter中的请求头和网页中的请求头我们可以发现我们要把JMeter中的Cintent-Type改成与网页中的一致才可以
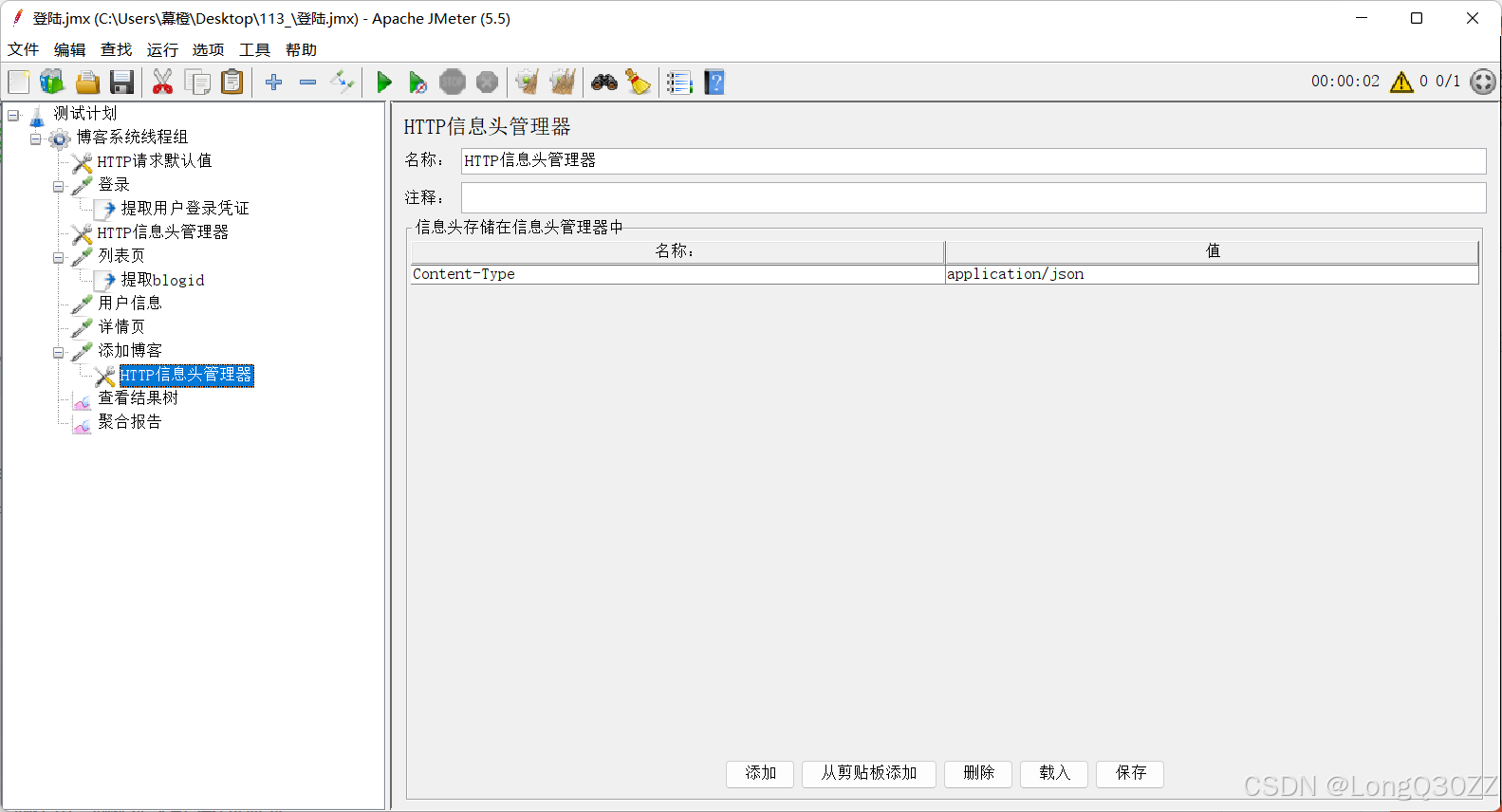
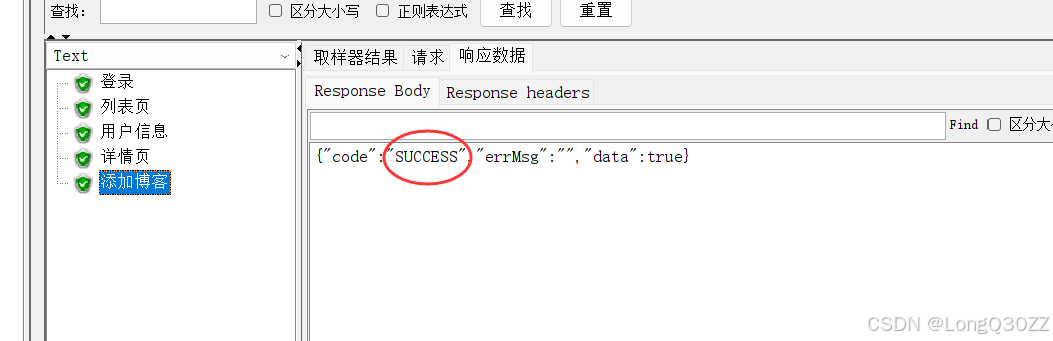
查看测试结果
5.5JMeter里的耦合报告

| 指标 | 说明 |
|---|---|
| Samples | 发起的 HTTP 请求调用数 |
| Average | 平均响应时间,单位为毫秒 |
| Median | 请求调用响应时间的中间值,也就是 50%请求调用的响应时间,单位为毫秒 |
| 90%Line | 90%请求调用的响应时间,单位为毫秒 |
| 95%Line | 95%请求调用的响应时间,单位为毫秒 |
| 99%Line | 99%请求调用的响应时间,单位为毫秒 |
| Min | 请求调用的最小响应时间,单位为毫秒 |
| Max | 请求调用的最大响应时间,单位为毫秒 |
| Error% | 调用失败的请求占比。调用失败一般指响应断言失败或者请求调用出错 |
| Throughput | TPS/QPS,每秒处理的事务数 |
| KB/sec | 每秒网络传输的流量大小,单位为 KB。这个指标是以网络传输的大小来衡量网络的吞吐量 |
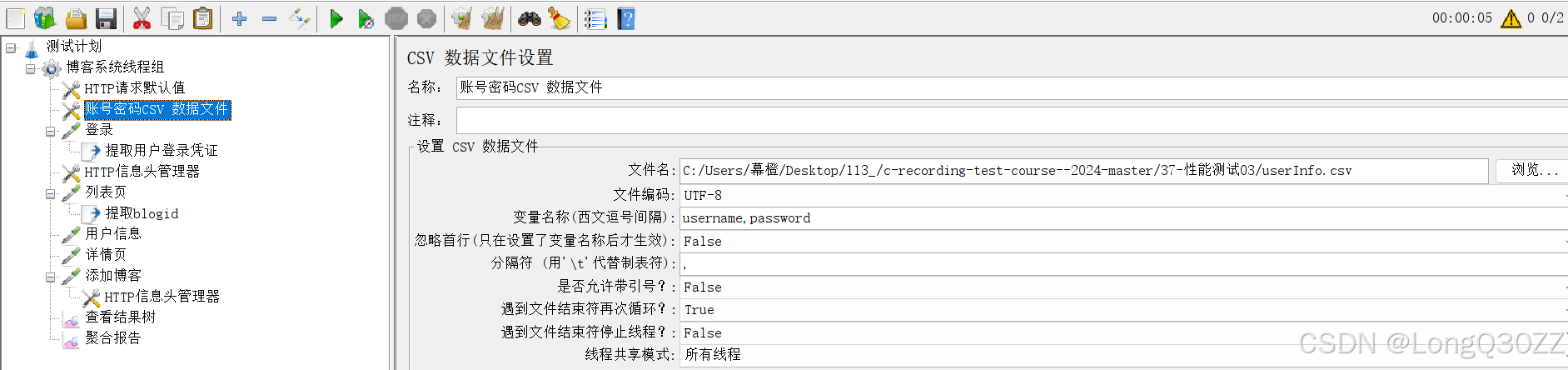
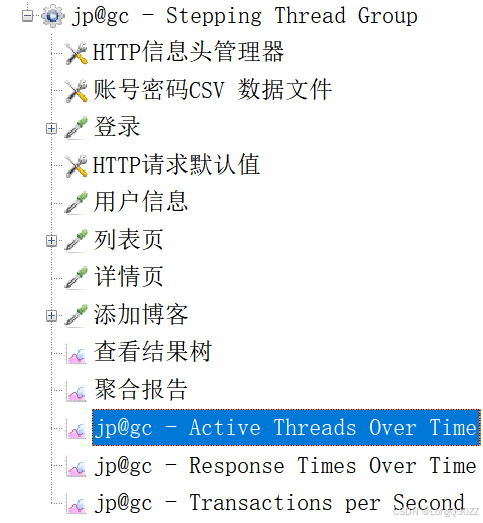
添加CSV数据文件设置
添加CSV数据文件设置可以可以把大量不同的用户名、密码、手机号等数据存放在 CSV 文件中。JMeter 会逐行读取,让每个线程(虚拟用户)或每次循环都使用不同的数据,避免因重复数据导致的测试失败或结果失真。
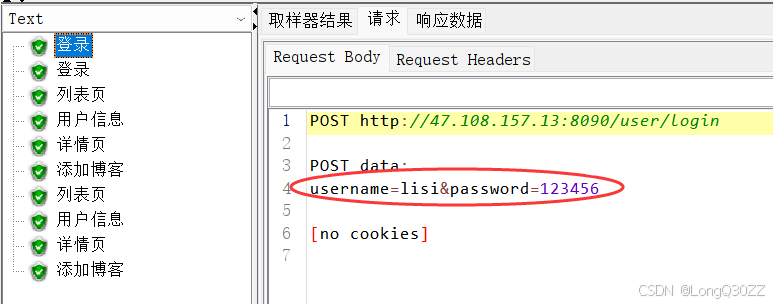
这样就有两个不同的用户登录
梯度压测线程组
梯度压测线程组旨在通过逐步调整线程(模拟用户)的数量,来观察系统在不同负载水平下的性能表现。与一次性施加固定数量线程的测试方式不同,它能更细致地描绘出系统性能随负载变化的曲线,帮助发现系统在不同压力阶段的潜在问题。
简单来说:梯度压测线程组 = 一步步慢慢加压的线程组 不是一下子把并发拉满,而是分段、阶梯式增加用户数。
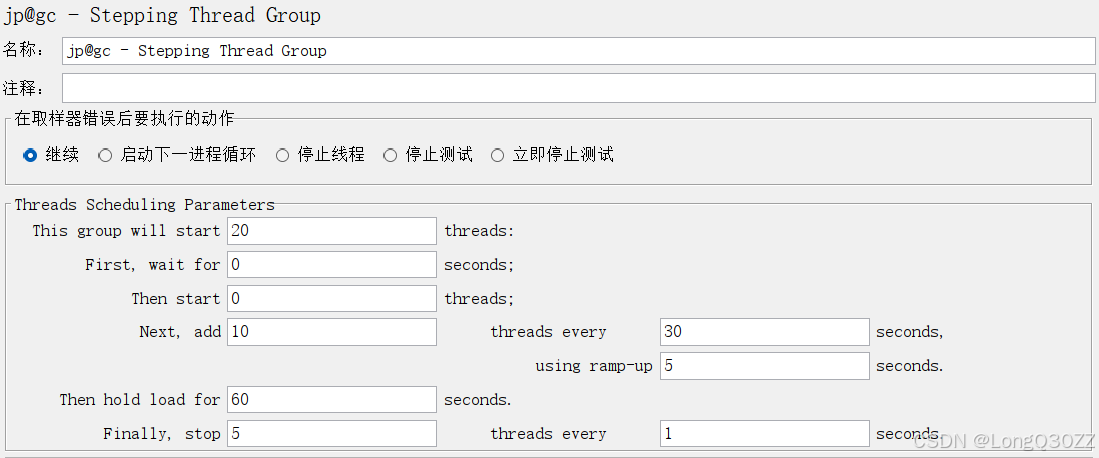
各参数的含义:
This group will start: 启动多少个线程,同线程组中的线程数
First, wait for: 等待多少秒才开始压测,一般默认为0
Then start: 一开始有多少个线程数,一般默认为0
Next, add: 下一次增加多少个线程数
threads every: 当前运行多长时间后再次启动线程,即每一次线程启动完成之后的的持续时间;
using ramp-up: 启动线程的时间;若设置为5秒,表示每次启动线程都持续5秒
thenhold loadfor: 线程全部启动完之后持续运行多长时间
finally, stop/threadsevery: 多长时间释放多少个线程;若设置为5个和1秒,表示持续负载结束之后每1秒钟释放5个线程
测试结果分析
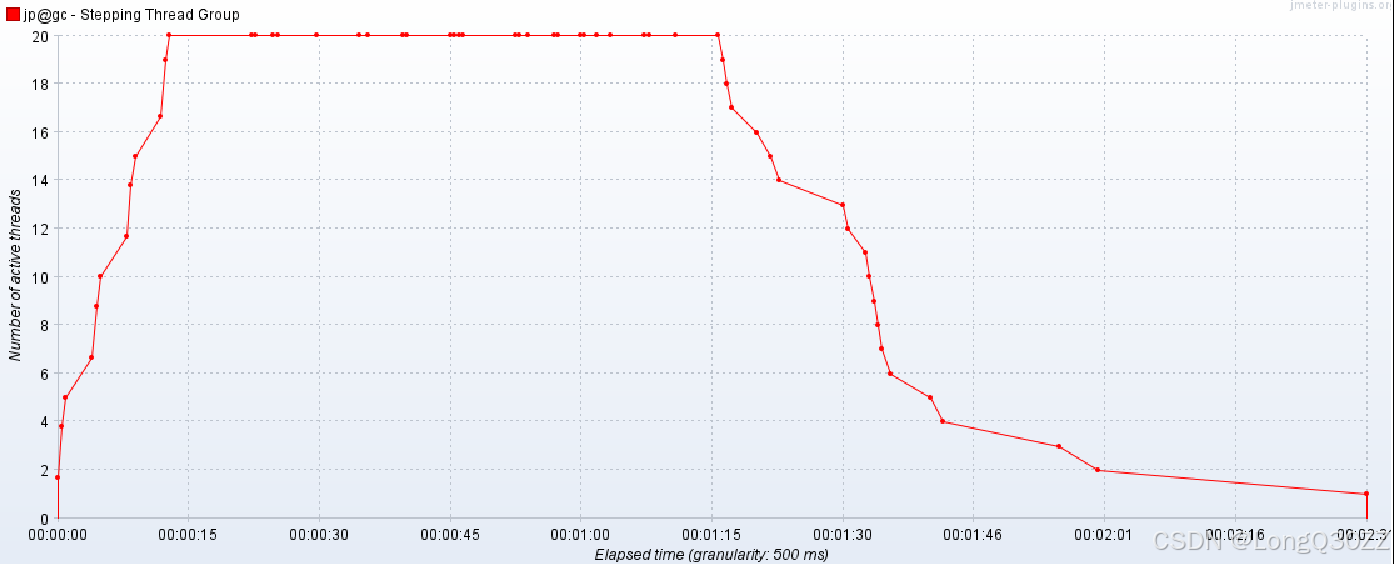
一. 实际线程曲线(Active Threads Over Time)
| 阶段 | 时间范围 | 线程数变化情况 |
|---|---|---|
| 加压阶段 | 0~15秒 | 线程数从0阶梯式增长到20,与配置一致 |
| 平稳阶段 | 15~75秒 | 线程数稳定在20,持续约60秒 |
| 减压阶段 | 75秒后 | 线程数逐步下降,曲线平滑,说明线程停止过程中仍有请求在执行,导致线程数下降比预期缓慢 |
二.响应时间分析(Response Times Over Time)
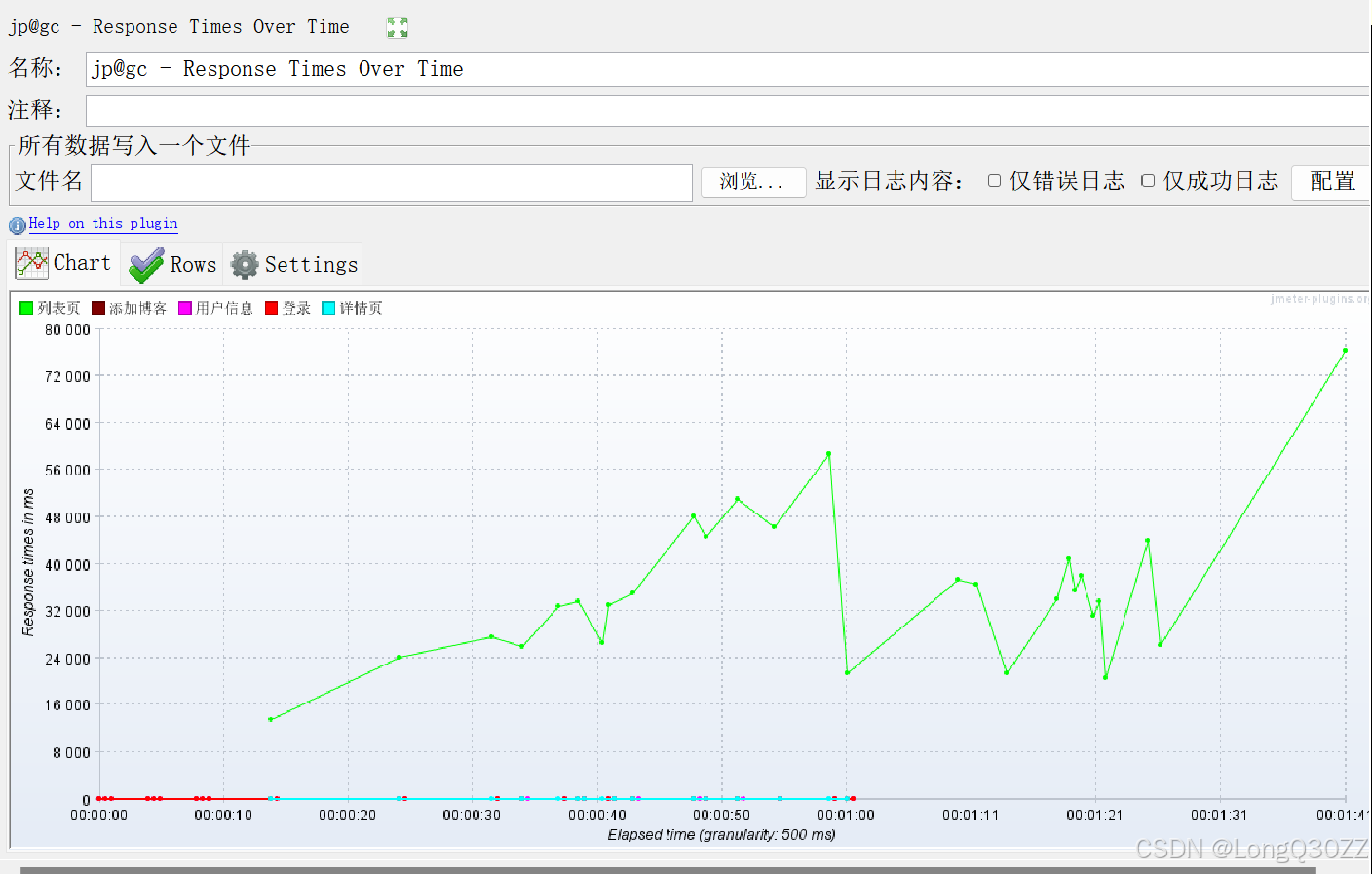
列表页(绿色曲线)::响应时间随并发升高持续恶化,从约 12ms 飙升至 80ms 以上,是本次压测中性能最差的接口。
其他接口(登录、详情页等): 响应时间始终保持在极低水平(接近 0ms),未受并发压力影响。
结论:系统瓶颈依然集中在列表页接口,其性能随并发增加而线性恶化。在 15 并发下,响应时间已达到 80ms,相比 20 并发时的 150ms 有明显改善,说明并发数降低后,列表页的压力得到了缓解
三.吞吐量分析(Transactions per Second)
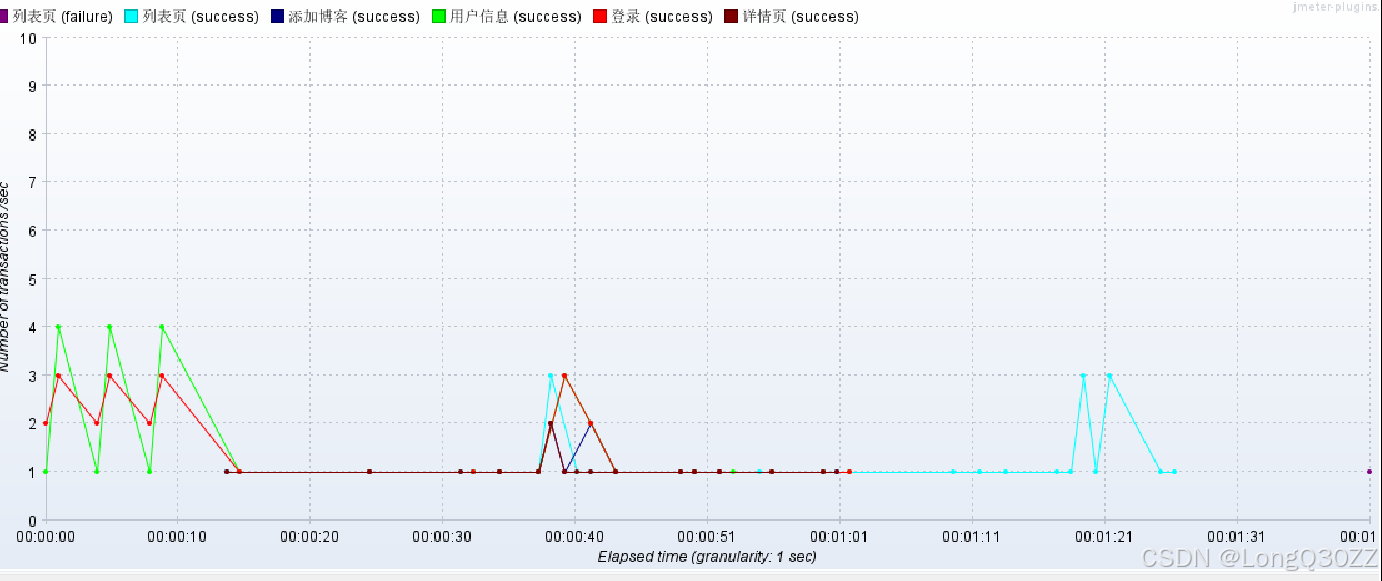
列表页(紫色 / 青色曲线) :在整个压测过程中,仅在极短时间内出现零星的失败请求(紫色),大部分时间都能稳定处理请求(青色),说明在 15 并发下,列表页接口可以稳定支撑负载。
其他接口(登录、详情页等) :TPS 较低且稳定,无明显失败,表现正常。
结论:当并发降低到 15 时,列表页接口的吞吐量和稳定性得到显著提升,不再出现持续失败,说明 15 并发是当前系统下列表页接口的一个相对安全的负载水平。
5.6JMeter性能测试报告
JMeter测试报告是⼀个全面而详细的⽂档,它提供了关于测试执⾏结果的详细信息,帮助用户全面评
估系统的性能并进行性能优化
⽣成性能测试报告的命令:
C
Jmeter -n -t 脚本文件 -l 日志文件 -e -o 目录
-n:无图形化运行
-t:被运行的脚本
-l:将运行信息写入日志文件,后缀为.jtl的日志文件
-e:生成测试报告
-o:指定报告输出目录生成的测试报告