本系列文章将从提示词工程出发,逐步讨论人类如何提升对大模型行为的控制能力:从优化提问方式,到设计输入环境,再到连接外部能力,最终形成可复用的能力单元。
换句话说,我们关注的不只是"如何让模型回答更好",而是"如何让模型稳定地完成工作"。
在上一篇中,我们讨论了上下文工程,理解了模型表现往往取决于它在生成时能够看到的信息。但当我们真正开始构建应用时,很快会遇到新的问题:即使知道上下文重要,如果不会控制它,模型依然会表现不稳定。
- 有的信息应该写入,有的信息应该丢弃
- 有的需要保留细节,有的只需保留结论
- 有的上下文应该共享,有的则必须隔离
本篇是系列第三篇,将从工程角度讨论"如何操作上下文",使上下文从一段文本,变成可管理的资源。
在上一章中,我们逐渐意识到:模型表现的不稳定,不是因为它不会推理,而是因为它在生成时看到的信息不完整、不准确,或者彼此冲突。
于是我们开始构建上下文,无论是:
- RAG
- 长期记忆、短期记忆
- System prompt
- Role
本质上都是在提供上下文信息。但是,即便是提供了上下文,我们经常还是会遇到如下的问题:
- 明明检索到了正确资料,模型却忽略
- 对话越长,回答越偏
- 新信息加入后,旧规则突然失效
- 多个任务同时进行时,模型开始"串台"
此时的问题,从原来的"有没有上下文",升级到了"模型应该看到哪些上下文"。换句话说,上下文不再是一次性准备好的输入,而是在运行过程中被不断调整的。
本篇将讨论的,正是如何控制模型看到的信息 ------ 也就是 Context Operations。
关于上下文的操作,常见的策略有:
- 写入上下文
- 选择上下文
- 压缩上下文
- 隔离上下文
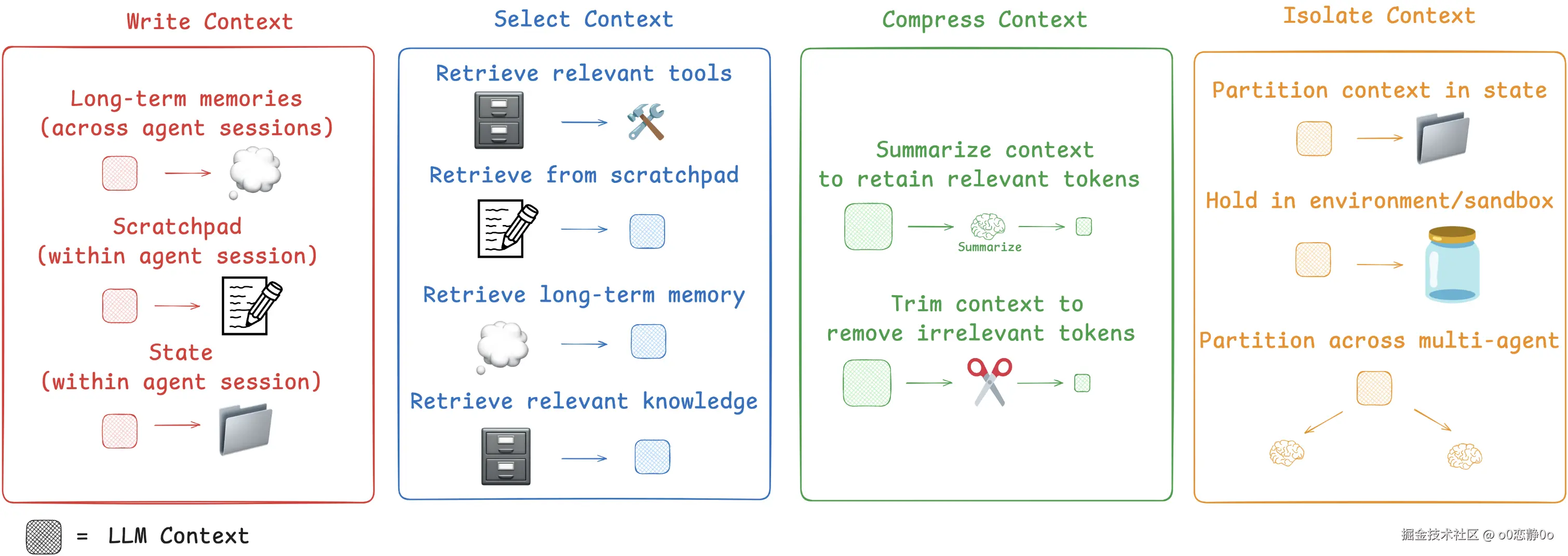
接下来我们依次来看一下关于上下文的这几种操作。
写入上下文
直觉上,我们总希望把尽可能多的信息交给模型。毕竟信息越充分,回答应该越准确。
但在真实系统中,恰恰相反:有些信息必须被记录,却不应该一直放在模型的上下文里。
原因很简单,上下文窗口是模型的"工作记忆",而不是"仓库"。如果我们把所有中间推理、历史结论、尝试过程都持续塞给模型,就会出现:
- 早期错误结论反复干扰后续推理
- 无关历史稀释关键信息
- 上下文迅速膨胀导致注意力下降
因此第一步操作不是给模型更多信息,而是先把信息从当前上下文中"拿出来",保存到外部。这就是 写入上下文 的含义。
写入,并不等于给模型看
写入上下文,本质上是在做一件事:把过程信息从"当前思考空间"转移到"系统存储空间"。模型在执行任务时会不断产生临时信息,例如:
- 中间推理结果
- 已确认的条件
- 尝试失败的方案
- 阶段性结论
这些信息如果直接留在对话中,会持续影响后续生成;但如果完全丢弃,又会失去任务连续性。所以我们可以选择第三种方式:记录,但暂时不提供给模型。
换句话说:写入是为了将来可能使用,而不是现在使用。
常见的写入对象
在实际系统中,被写入的通常不是"聊天记录",而是结构化的过程信息,例如:
- Scratchpad:任务过程中的临时笔记
- State:当前任务的阶段状态与已确认参数
- Reflection:对错误或结果的总结
- Long-term memory:跨会话保留的重要结论
它们有一个共同特点:对系统重要,但对下一步生成不一定重要。因此这些内容会被保存到外部,而不是一直停留在上下文窗口中。常见的存放位置包括:
- 会话级状态(state / session store)
- 数据库记录(任务过程、执行结果)
- 向量数据库(可检索的历史结论)
- 文件或缓存(临时工作数据)
为什么这是第一步
很多上下文问题,其实从这里开始。
如果不写入,所有历史都会堆积在上下文里,后续就无法进行上下文的"选择"和"压缩",因为根本没有干净的来源。
写入的作用,就是把"正在思考的信息"和"已经产生的信息"分开:
- 当前上下文:用于下一步推理
- 外部存储:用于未来可能检索
从这一刻开始,上下文不再是对话记录,而变成一块可以被管理的工作区。
选择上下文
当信息被写入外部之后,一个新的问题出现了:模型到底应该重新看到哪些信息?
如果全部重新放回上下文,写入就失去了意义;但如果什么都不取回,模型又会像刚开始一样"失忆"。
因此系统需要做一件更精细的事情:在多个信息来源中,挑出当前步骤真正需要的那一部分。
这一步,就是 选择上下文。
很多系统的早期实现是:历史对话 + 当前问题 → 一起发送给模型
这在简单聊天中还能工作,但一旦进入任务型场景,常常会遇到如下的问题:
- 旧条件覆盖新条件
- 模型引用过时结论
- 长对话干扰推理
- 上下文窗口被占满
原因在于:模型不会区分"背景"和"重点",它只会基于全部输入做概率预测。
所以问题从"我们保存了哪些信息"变成了"当前步骤需要哪些信息"。因此,选择上下文的本质不是拼接历史,而是相关性检索。
在真实 Agent 中,可被选择的信息通常来自四类来源:
- 过场记录
- 记忆
- 工具
- 知识库
1. 过程记录(scratchpad / state)
系统在运行过程中会不断产生中间信息,例如任务笔记、阶段状态等。这些内容会被写入外部,比如 scratchpad 里面保存的就是完整的过程记录。
不过真正进入上下文的,只是其中的一部分,系统只取出与当前步骤相关的片段,而不是整个过程:
- scratchpad 负责完整记录
- 上下文只读取当前所需
因此这里涉及到选择合适的内容作为上下文。
2. 记忆(memory)
记忆也会涉及到选择。一般来讲,如果系统具有记忆能力,它也必须具备选择记忆的能力。执行任务时,并非所有记忆都应该被唤醒,不同任务需要不同类型的历史:
| 记忆类型 | 存储内容 | 人类示例 | Agent 示例 |
|---|---|---|---|
| 语义记忆(Semantic) | 事实(Facts) | 在学校学到的知识 | 关于用户的事实信息 |
| 情景记忆(Episodic) | 经历(Experiences) | 我做过的事情 | 过去的 Agent 行为 |
| 程序记忆(Procedural) | 指令(Instructions) | 本能或运动技能 | Agent 的 system prompt |
如果无差别加载记忆,模型会表现得"像知道太多",甚至出现用户并未期望的信息泄露。因此记忆不是读取,而是召回。
在记忆索引阶段,通常会使用 embeddings 和/或知识图谱来辅助选择过程。不过,即便如此,记忆选择依然是一项具有挑战性的任务。
3. 工具(tools)
Agent 往往可以使用多个工具,而工具也涉及到选择。因为如果将全部的工具提供给模型,反而会降低准确率。原因在于工具描述之间可能存在重叠,模型会在选择时产生混淆。
一种解决方案是对工具描述应用 RAG(retrieval augmented generation),基于语义相似度为当前任务检索最相关的工具。一些 最新研究表明,这种方法可以将工具选择的准确率提升约 3 倍。
4. 知识(knowledge / RAG)
知识库也是一样。
真正难的从来不是"把资料存起来",而是在这一轮里,到底该把哪几段资料给模型看。尤其当知识规模变大以后,单靠一次向量检索往往不够。通常还需要做三件事:
- 多路召回:向量检索找语义相近,关键词检索兜底精确命中
- 过滤与去噪:剔除看似相关、但其实无用的片段
- 重排序:把"最能支撑当前结论的证据"排到最前面
原因很简单:模型需要的不是"最相似的文本",而是最有助于当前推理的证据上下文。
换句话说,RAG 的关键不是"检索",而是"筛选证据",只把最小但足够的材料放进 context window,让模型在正确的信息上做判断。
总结一下,在成熟的 Agent 架构中,上下文的选择是一场精密的"海选":
| 来源 | 存储职责 | 召回策略 |
|---|---|---|
| 1. 过程记录 (Scratchpad) | 记录任务执行的完整链路。 | 状态快照:仅提取当前步骤相关的状态,而非整本笔记。 |
| 2. 记忆 (Memory) | 沉淀用户画像、历史偏好、经验总结。 | 语义驱动:基于 Embedding 召回关联记忆,防止模型过度唤醒。 |
| 3. 工具 (Tools) | 存放 API 文档、函数定义。 | RAG 筛选:当工具超过 20 个时,先检索最匹配的工具描述,再交给模型决定。 |
| 4. 知识 (Knowledge) | 存放海量的外部非结构化文档。 | 多路召回:通过向量 + 关键词检索,并经由重排序筛选最强证据。 |
压缩上下文
当系统开始稳定运行后,很快会遇到一个现实问题:上下文会越积越多。
对话会变长、工具会产生中间结果、RAG 会不断补充资料、记忆也在持续加入。如果全部原样带给模型,结果通常只有两个:
- 要么超过 context window
- 要么虽然没超,但模型开始"抓不到重点"
因此就出现了第三种操作 ------ 压缩上下文。
它的目标很明确,只保留完成当前任务所必需的信息,而不是完整历史。
常见的方式有两种:
- 总结
- 过滤
总结
总结,英文称之为 Summarization,这是最常见的压缩方式,是让模型自己"提炼历史"。当交互轮次很多时,系统不再把全部对话带入,而是改为带入一段总结。例如:
原始对话(20轮) → 总结 → 1段状态描述这件事你可能已经见过,很多 AI IDE 或 Agent 在上下文接近上限时,会自动进行一次总结压缩。本质上就是用"状态描述"替代"完整过程"。
例如一个代码修复流程:
scss
❌ 原始历史
用户贴代码 → 模型分析 → 调用工具 → 返回日志 → 再修改 → 再运行 → 再报错 ...
✅ 总结后
当前状态:函数 parseUser() 在空值情况下抛出异常,尚未修复模型真正需要的是当前状态,而不是推理过程。
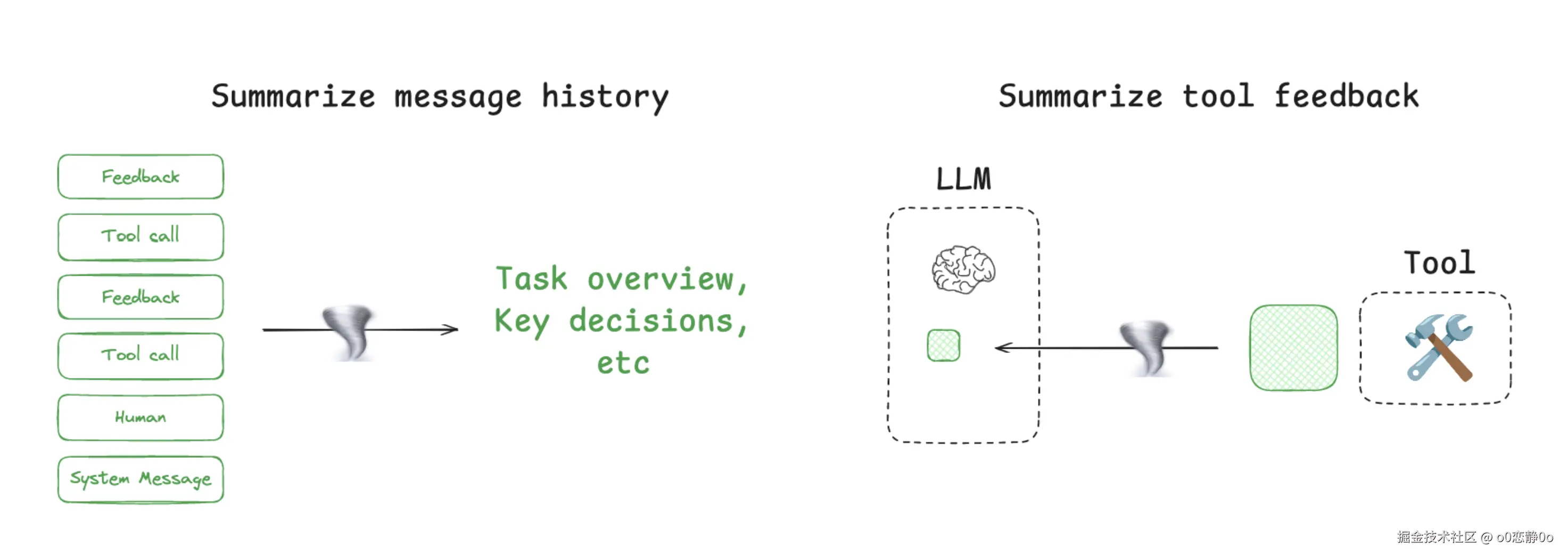
另外,很多系统并不会等到 context 爆炸才开始压缩,而是会在一些天然的"阶段边界"主动进行总结。因为在这些位置,上下文往往刚好从"过程"变成"结果"。典型的触发时机包括:
- 工具调用之后(工具输出通常很长)
比如一次网页搜索、代码分析、数据库查询,返回内容往往是成百上千 token。这些原始数据对模型来说只是"证据",真正需要进入后续推理的,是"结论"。因此系统通常会先把工具输出整理成一句可用的信息,再交给下一步,而不是把整份原始结果继续带着跑。
- 阶段切换时(规划 → 执行 → 汇总)
在规划阶段,模型会产生很多思考与候选方案;但进入执行阶段时,真正需要的只有"最终决定要做什么"。所以这里通常会把整段思考压缩成一个明确的行动计划,相当于从"讨论记录"变成"任务单"。
- Agent 之间交接时
多 Agent 系统中,一个 Agent 的完整推理过程对下一个 Agent 并不重要。下一个 Agent 需要的是结构化的交接信息:结论、约束条件、当前状态。因此这里通常会生成一段交接摘要,而不是直接传递全部历史。
- 对话轮次达到阈值时
长对话中,早期内容的价值会逐渐降低。这时系统会把前面的几十轮对话压缩成一段"会话背景",只保留仍然影响当前任务的部分,让模型继续工作而不被历史噪声拖累。
你可以把它理解为,每完成一个阶段,就写一条"会议纪要",以后只看纪要。
过滤
过滤,对应的英文为 Trimming,如果说总结是"提炼",那么过来的核心思想就是直接剪掉。
有些信息其实不需要模型帮你判断是否重要,而是可以工程上直接决定:
- 很早之前的寒暄对话
- 已完成任务的历史步骤
- 调试过程中失败的中间输出
- 与当前目标无关的工具结果
这时就不需要总结,直接移除即可。
例如:
sql
用户:你好
模型:你好
用户:帮我写 SQL
模型:...
(50轮后)
→ 前两轮可以直接删这类操作通常基于一些确定性规则,而不是依赖 LLM 判断。
常见的规则有:
- 删除最早的 N 轮对话
- 删除工具的原始返回(只保留解析结果)
- 删除已完成任务的中间推理
- 仅保留当前 task 的 state
- 限制 scratchpad 最大长度
这些规则的特点是:可预测、稳定、不会随机波动
而如果交给 LLM,每次判断都会略有不同,系统行为就会变得不可复现,这对 Agent 来说是灾难级问题。
下面的表格是对两种方式的一句话概括:
| 方法 | 做的事情 |
|---|---|
| 总结 | 把很多信息变少 |
| 过滤 | 把无关信息删掉 |
工程里通常是组合使用,先过滤,再总结。先去掉明显无关的噪声,再对剩余上下文进行提炼,成本最低,效果最好。
隔离上下文
前面几个操作,本质上都在回答同一个问题:模型要看到什么?
而"隔离上下文"解决的是另一个更高级的问题:模型不应该看到什么?
很多时候,问题不是信息太少,而是信息混在一起。当不同任务、不同阶段、不同角色共享同一份上下文时,模型就会开始"串线"。
典型现象:
- 规划阶段的思考影响执行阶段的回答
- 工具返回的原始数据污染最终输出
- 上一轮任务的规则干扰当前任务
- 多任务时模型开始自相矛盾
所以,上下文不仅要筛选、压缩,还要拆开,这就涉及到上下文的隔离。
多 Agent:把任务拆开,让每个模型只关心自己的事
最直接的隔离方式,就是不要让一个模型做所有事。把系统拆成多个子 Agent:
| Agent | 负责 |
|---|---|
| Planner | 规划步骤 |
| Retriever | 检索资料 |
| Tool Agent | 调用工具 |
| Writer | 生成最终回答 |
每个 Agent:
- 有自己的 system prompt
- 有自己的工具
- 有自己的 context window
每个模型都活在一个更小、更干净的世界里。
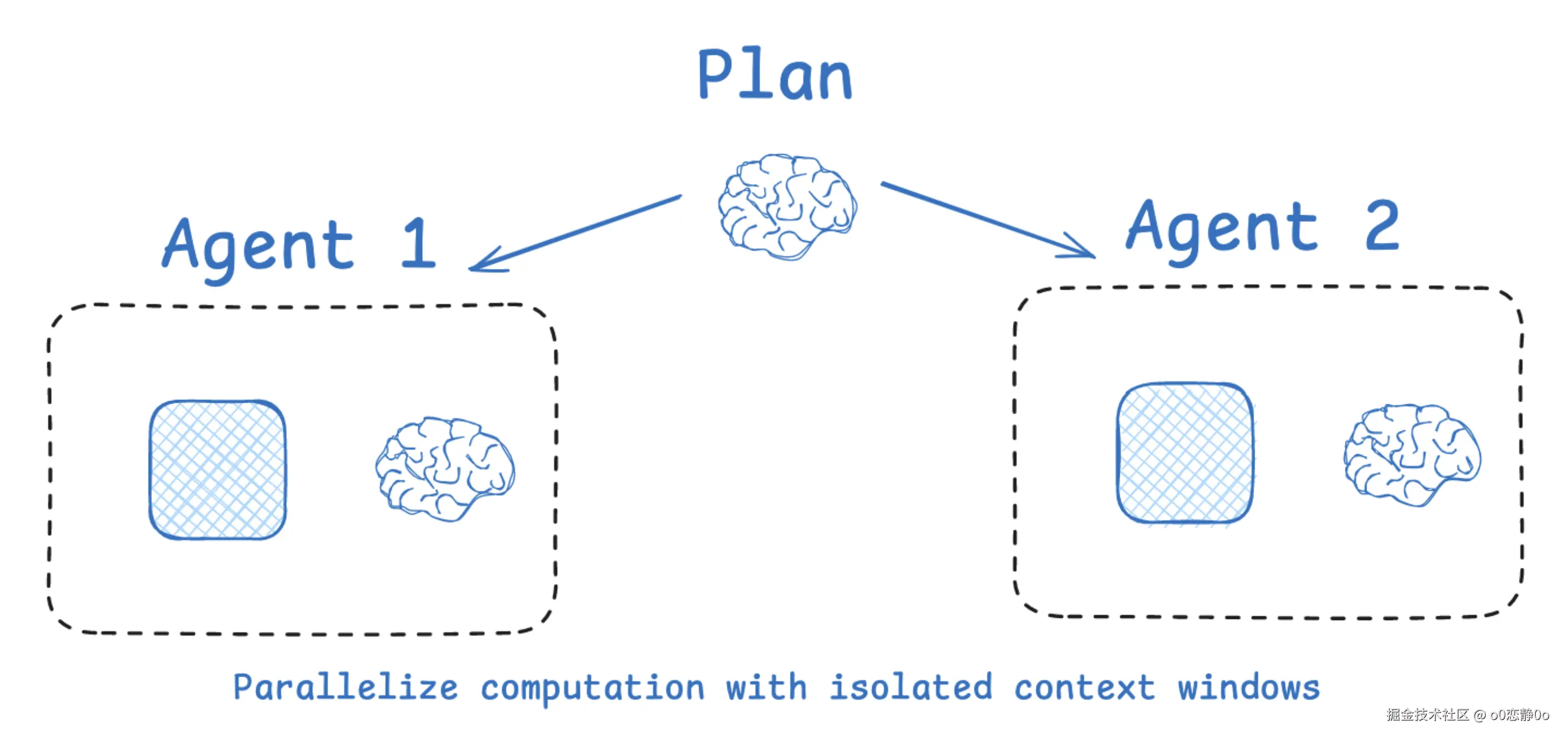
这样带来的效果非常明显,不再需要一个模型同时记住"为什么做"和"怎么做"。因为规划的思考不会污染生成回答,工具的中间结果不会影响语言风格,写作模型只专注表达。
不过,在稳定性显著提升的另一面,也存在一些代价,那就是 token 会增加、调度会更加复杂。
环境隔离:让模型只看到"结果",看不到"过程"
另一种精细的隔离策略,不是切换模型,而是重塑信息的"可见性"。
在复杂的任务中,大量底层数据并不适合直接塞进上下文窗口(Context Window)。如果将搜索原文、多媒体文件或冗长的代码执行日志一股脑丢给模型,会导致严重的副作用:
- Token 膨胀:不仅大幅推高成本,更会挤占模型宝贵的推理空间。
- 注意力稀释:模型在处理长文本中间位置时,容易忽略关键约束(即 Lost in the Middle 现象)。
- 逻辑干扰:中间计算的噪音可能被模型误认为是最终指令,导致输出混乱。
更好的做法是将模型置于一个隔离的环境(Sandbox/Environment)中运行。流程从"全量读取"转变为"按需调用":
- 决策层(LLM):模型仅负责发出高层指令(如:"搜索某事件并总结要点")。
- 执行层(Environment):在外部环境(如 Python 代码沙盒、搜索 API、多模态解析器)中完成繁杂的计算与筛选。
- 反馈层(Filter):仅将清洗后的高价值证据或最终计算结果返回给模型。
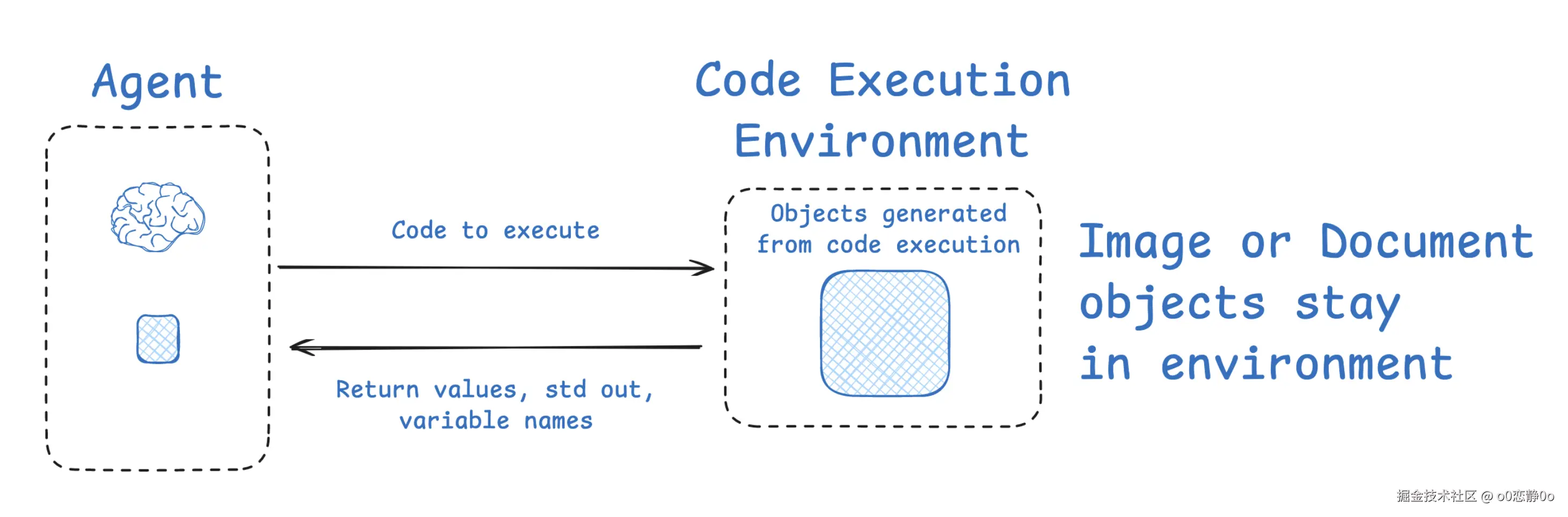
这种机制就像现代数据库的演进:
- 传统方式:像是在内存里读取整张原始表(Full Table Scan),效率低下且容易溢出。
- 环境隔离:模型发送的是一个 SQL 查询语句,它不需要关心数据库底层如何翻阅磁盘,只需要拿到返回的那几行结果。
通过环境隔离,我们将模型的注意力从"海量噪音"中解放出来,使其专注于最高阶的逻辑推理。
State 隔离:Agent 内部的"分层内存"架构
即使是单一 Agent,也需要建立严密的"信息防火墙"。
最高效的隔离手段不是物理拆分,是将 运行时状态(Runtime State) 与 模型上下文(Model Context) 解耦。不再机械地将所有信息塞进 messages 列表,而是构建一个结构化的 State 对象:
js
// 典型的结构化 State 示例
state = {
"messages": [], // 核心对话流(给用户看的)
"plan": [], // 任务编排与进度(给模型对齐的)
"scratchpad": "", // 思考草稿纸(推理过程,可隐藏)
"memory": {}, // 用户长期画像(召回后的片段)
"tool_cache": {} // 工具原始输出(待过滤的中间结果)
}这里的 State 相当于系统的全量数据库,而 Context 只是该数据库在某一瞬间的"视图"。在每一轮执行中,系统会根据当前的任务阶段,通过预设的选择逻辑,只向模型暴露必要的"切片":
- 对话流 (Messages):始终保持连贯,作为交互基石。
- 规划区 (Plan):仅在执行决策或进度对齐时可见,防止模型在执行细节时被宏观规划干扰。
- 工具缓存 (Tool Cache):仅在调用后及结果总结阶段暴露,任务完成后即从上下文移除。
- 记忆区 (Memory):通过语义检索(RAG)按需注入,而不是全量加载。
- 草稿纸 (Scratchpad):模型内部的思考过程,在输出给用户前会被自动过滤。
这样做的工程优势:
- 实现"受控上下文":模型只看到当前阶段"必须知道"的信息,极大地降低了推理噪音。
- 打破 Token 枷锁:State 可以无限大,但 Context 始终保持精简。
- 支持长程任务:通过在 State 中持久化
plan和memory,Agent 可以在长达数百轮的交互中不丢失目标,且不产生严重的注意力偏移。
总结一下,隔离上下文本质上不是在减少信息,而是对信息做分区。
- 多 Agent:按职责隔离
- 环境 / 工具:按执行位置隔离
- State:按数据类型隔离
如果说 RAG 的作用是为模型补充知识,那么"隔离"做的事情,就是避免这些知识彼此干扰。一个稳定的 Agent,并不取决于信息有多少,而取决于信息的边界是否清晰。
写在最后
在 AI 应用开发的早期,我们往往沉迷于"模型的能力",试图通过更换更强大的底座来解决所有问题。但随着工程实践的深入,你会发现:模型的上限固然由算法决定,但一个 Agent 系统的下限,却是由它对上下文的处理水平决定的。
正如我们在本篇中探讨的,Context Operations 的本质是将模型从"信息的海洋"中解救出来。
- 写入:是为了让工作记忆保持整洁,实现"离线存储"与"在线思考"的解耦。
- 选择:是为了在海量数据中实现"精准唤醒",确保模型只在正确的证据上进行推理。
- 压缩:是为了对抗熵增,通过总结与过滤让系统在长程任务中依然能抓住重点。
- 隔离:则是为了建立秩序,通过多 Agent、环境沙盒或结构化 State,为模型画出清晰的思维边界。
从"喂给模型所有信息"转变为"只让模型看到最关键的信息",这是从实验原型走向工业级应用的必经之路。 当我们不再把上下文看作一段简单的文本,而是一块可以被精细操控的工作区时,我们才真正拥有了构建稳定、可预测、且能胜任复杂任务的 Agent 系统的能力。
下一篇,我们将介绍另外一种扩展上下文的边界的方式 ------ MCP。
好啦,今天的内容就分享到这里啦,我们下一篇文章再见👋
-EOF-