VLA模型
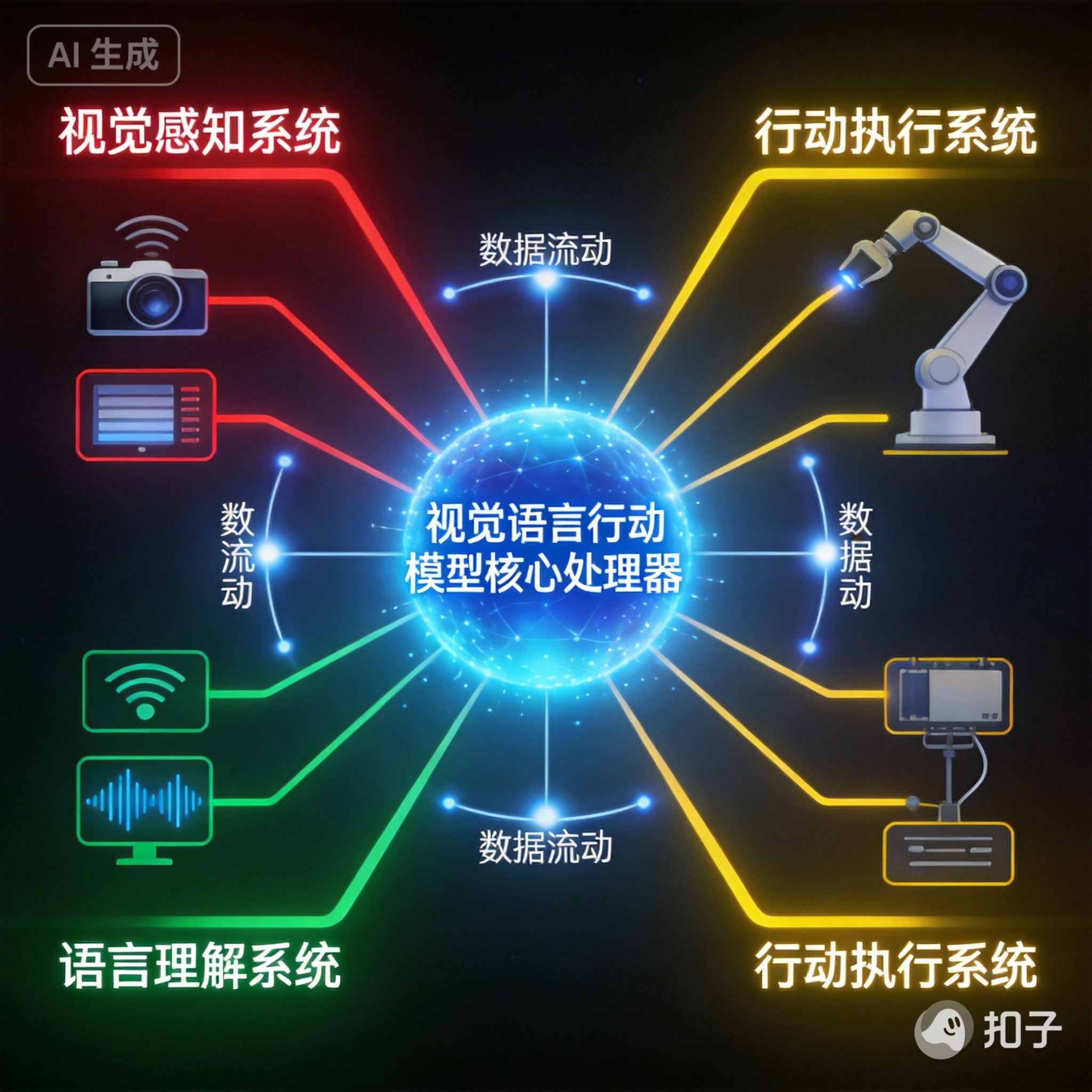
VLA模型,全称视觉-语言-动作模型 (Vision-Language-Action Model),是一种将视觉感知、语言理解和动作执行融合在单一端到端架构 中的AI模型。

你可以把它想象成一个"大脑"、"眼睛"和"手脚"完全打通的智能体。它不再需要工程师为每一个动作编写复杂的代码,而是像人一样,通过"看"到环境、"听"懂指令,直接"做"出相应的动作。

🤖 核心原理:从"感知"到"执行"的闭环
传统的机器人或自动驾驶系统通常是"模块化"的:一个模块负责看(感知),一个模块负责想(规划),一个模块负责动(控制)。这种结构容易产生误差累积,且难以应对未知环境。
VLA模型则打破了这种壁垒,其核心工作流程如下:
- 输入 :接收视觉信息 (如摄像头画面)和语言指令(如"把那个红色的杯子拿给我")。
- 融合与理解:在模型内部,视觉和语言信息被统一到同一个语义空间中进行处理。模型不仅识别出"红色杯子",还能理解"拿给我"这个动作的意图。
- 推理与决策:利用大模型的推理能力(如思维链,Chain of Thought),将高层指令分解为可执行的低级动作序列(例如:移动到杯子位置 -> 伸手 -> 抓取 -> 回退)。
- 输出 :直接生成控制机器(如机械臂、汽车)的动作指令(如电机的转动角度、方向盘的转向角)。
🚀 主要应用领域
VLA模型目前主要在两个前沿领域展现出巨大潜力:
1. 机器人控制
这是VLA模型的发源地。它让机器人能够理解开放域的自然语言指令,并在未见过的环境中执行复杂任务。
- 典型任务:如"把茶几上的遥控器拿给我"、"把脏衣服放进洗衣机"。
- 代表项目 :
- 谷歌DeepMind的RT-2:2023年发布的首个VLA模型,让机器人能执行如"把可乐递给穿红衣服的人"这类需要视觉推理的指令。
- OpenVLA:一个开源的VLA框架,降低了研究门槛,让开发者能在消费级硬件上运行和微调模型。
- 家务机器人:如前面提到的能叠衣服、端茶倒水的机器人,其背后核心就是VLA技术。
2. 自动驾驶
在自动驾驶领域,VLA模型被视为"端到端"方案的2.0版本,它让汽车不仅会开,还能"听"和"想"。
- 典型场景:驾驶员说"我渴了",车辆不仅能理解这是寻找饮水的需求,还能结合视觉感知,将车开到附近的便利店门口。
- 代表项目 :
- 理想汽车的VLA司机大模型:将VLA应用于智能驾驶,旨在让车辆能理解人类的自然语言意图,并做出符合人类驾驶习惯的决策。
- 小鹏汽车的VLA模型:用于提升车辆在复杂场景下的推理和决策能力。
- 英伟达的Alpamayo:一个具备可解释性推理能力的VLA模型,能通过"思维链"解释其驾驶决策,提升安全性。
⚖️ 两种主流技术架构
目前,VLA模型主要存在两种技术路径,它们各有侧重:
| 架构类型 | 工作模式 | 优势与特点 |
|---|---|---|
| 端到端直连 | 视觉+语言输入 → 直接映射 → 动作输出 | 反应迅速:省去了中间的语言解释环节,适合对实时性要求极高的动态控制(如躲避突然出现的障碍物)。 |
| 推理链增强 | 视觉+语言输入 → 生成文本推理过程 → 动作输出 | 可解释性强:模型会先输出"我要先绕过障碍物,再向左转"这样的文本,再执行动作。这使得决策过程透明,便于调试和提升安全性。 |
📈 优势与挑战
-
优势:
- 强大的泛化能力:得益于在大规模互联网数据上的预训练,VLA模型能理解从未见过的物体和场景,执行零样本(zero-shot)任务。
- 自然的人机交互:用户无需学习复杂的指令集,用日常语言就能指挥机器。
- 系统简化:端到端的架构减少了模块间接口的复杂性,提升了整体效率。
-
挑战:
- 数据瓶颈:训练高性能的VLA模型需要海量、高质量的"视觉-语言-动作"三元组数据,这类数据的收集和标注成本极高。
- 安全性与可靠性:在真实物理世界中,模型的任何微小错误都可能导致严重后果,如何保证其在长尾场景下的绝对安全仍是巨大挑战。
- 算力需求 :强大的VLA模型通常参数量巨大,对部署端的算力提出了很高要求,轻量化是一个重要的研究方向。
VLA模型如何理解"我渴了"这类指令?
VLA(视觉-语言-动作)模型理解"我渴了"这类模糊的人类指令,其实是一个从**"听懂意图"到 "推理规划",再到"精准执行"**的复杂过程。
简单来说,它不是简单地匹配关键词,而是像一个聪明的管家一样,结合了常识推理 、环境观察 和动作拆解。基于目前的技术架构(如2026年的VLA 2.0或模块化架构),其理解流程主要分为以下几个步骤:
1. 意图理解与常识推理(大脑思考)
当听到"我渴了"时,VLA模型首先利用其内置的**大语言模型(LLM)**能力进行语义和常识推理。
- 语义转换:模型将这句模糊的生理需求("渴"),转化为明确的机器人任务目标("获取饮用水")。
- 常识调用:模型会调用预训练中学习到的常识知识。它知道解渴通常需要"水"或"饮料",而这些液体通常存放在"厨房"、"冰箱"或"茶几"上。
- 生成高层计划:模型会生成一个高层的行动计划(Action Token),比如:"寻找水源 -> 获取容器 -> 倒水 -> 递送"。
2. 视觉定位与环境交互(眼睛观察)
有了"找水"的计划后,单纯的LLM是无法行动的,VLA模型会结合**视觉编码器(Vision Encoder)**来观察现实世界。
- 视觉-语言对齐:模型会指挥机器人的摄像头,去寻找与"水"相关的物体。它能识别出什么是"水杯"、什么是"茶壶"或"冰箱把手",即使这些物体的摆放位置每天都在变化。
- 场景理解:如果指令是"倒一杯茶",它会通过视觉确认茶壶里是否有水,茶杯是否干净,以及 coaster(杯垫)的位置。
3. 动作生成与执行(手脚干活)
这是将"想法"落地为"动作"的关键一步。根据高层计划和视觉反馈,模型会生成具体的控制指令。
- 动作标记(Action Token):系统会将"倒茶"这个大任务,拆解成一系列微小的机器人关节动作。例如,先生成语言描述的子任务:"抓取茶壶把手",再转化为具体的机械臂轨迹坐标。
- 低级控制 :最终,这些指令会变成控制机械臂电机的电信号,比如"关节1旋转30度,关节2伸展20厘米,末端执行器施加5牛顿的抓握力",确保稳稳地拿起茶杯而不捏碎它。

📊 技术架构对比:它是如何"涌现"智能的?
目前主流的VLA模型主要有两种思路来处理这类指令,一种是"深思熟虑型",一种是"直觉反应型":
| 架构类型 | 工作原理 | 优势与特点 |
|---|---|---|
| 模块化/推理链 | 语言转译:指令 -> 文本计划(如"抓壶"、"倒水") -> 动作代码 -> 执行。 | 可解释性强:像写作文一样一步步来,适合处理复杂的多步骤任务(如准备晚餐)。 |
| 端到端直连 | 感官直连 :视觉/指令输入 -> 直接映射 -> 机器人动作(跳过中间语言描述)。 | 反应更精准:避免了语言转译的信息损耗(如小鹏VLA2.0),动作更流畅,适合毫秒级的动态响应。 |
💡 举个例子:从"渴了"到"端茶"的全过程
假设你对机器人说:"我渴了,请倒杯茶。"
- 理解:LLM理解"渴"=需要液体,"茶"=特定饮品。
- 规划:视觉系统扫描环境,锁定茶壶和茶杯的位置。系统规划路径:移动到茶几 -> 抓取茶壶 -> 倾倒 -> 放回茶壶 -> 端起茶杯。
- 执行:机械臂根据VLA模型计算出的坐标和力度,精准完成倒茶动作,并考虑到茶水的重量调整握力,最后把茶端给你。
总结来说 ,VLA模型之所以能听懂"人话",是因为它把互联网上学到的海量知识(LLM) 、**摄像头看到的实时画面(视觉)和机器人的物理动作(控制)**完美地融合在了一起,构建了一个"感知-决策-行动"的闭环。