文章目录
- 一、Transformer的核心思想
-
- [1 Transformer与其他模型对比](#1 Transformer与其他模型对比)
- 二、Transformer原理(核心模块拆解)
-
- [1 输入处理:词嵌入和位置编码](#1 输入处理:词嵌入和位置编码)
- [2 编码器(Encoder):特征提取与上下文建模](#2 编码器(Encoder):特征提取与上下文建模)
- [3 解码器(Decoder):生成输出序列](#3 解码器(Decoder):生成输出序列)
- [4 输出处理:线性变换与 Softmax](#4 输出处理:线性变换与 Softmax)
- 三、总结
-
- [1 关键创新点](#1 关键创新点)
- [2 应用场景](#2 应用场景)
一、Transformer的核心思想
Transformer最早来自论文:Attention Is All You Need
核心结论一句话:
不用RNN/CNN,仅用Self-Attention(自注意力机制)+前馈网络 就能建模序列。
1 Transformer与其他模型对比
| 模型 | 问题 |
|---|---|
| RNN | 串行计算,无法并行 |
| LSTM | 长距离依赖仍然困难 |
| CNN | 感受野有限 |
Transformer解决几个问题:
- 全并行计算
- 长距离依赖
- 计算效率高(适合GPU)
二、Transformer原理(核心模块拆解)
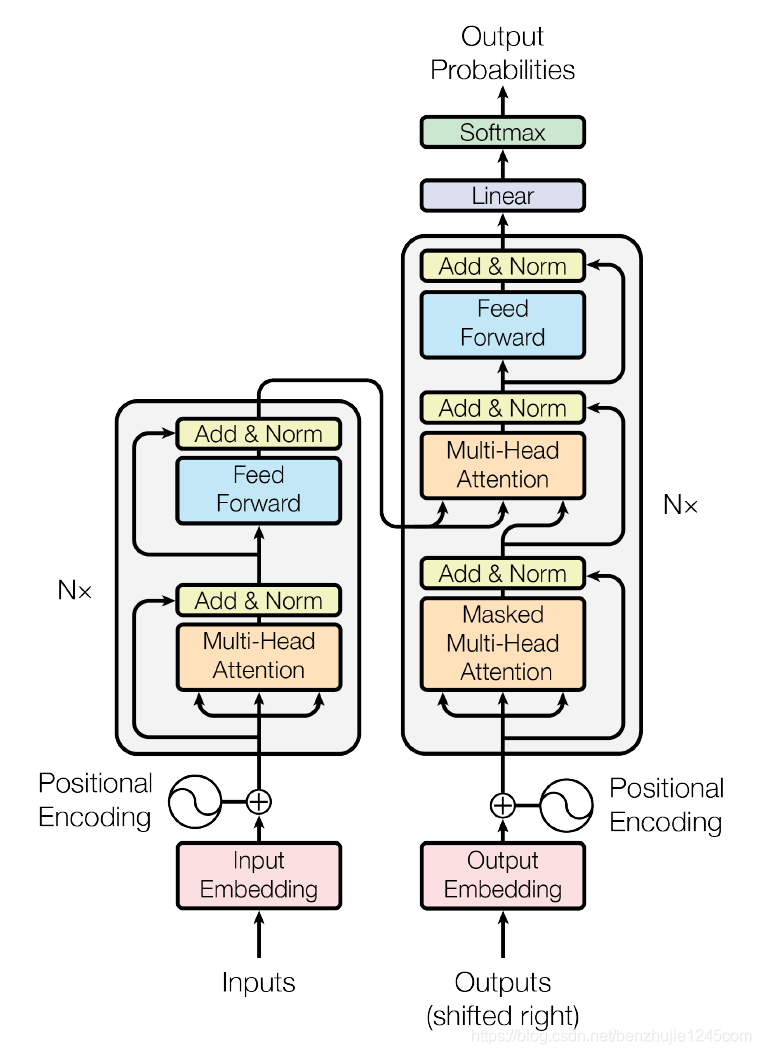
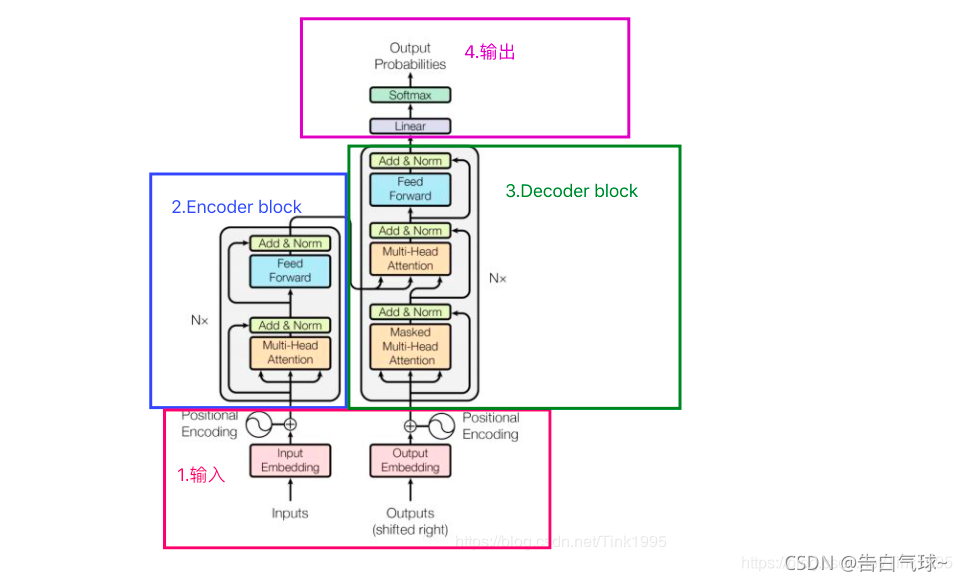
1 输入处理:词嵌入和位置编码
词嵌入:
- 将输入序列的每个词转换为固定维度的向量(如512维),捕捉词汇的语义信息。
- 例如:输入序列
["Hello", "world"]会被映射为[[0.3, 0.6, ...], [0.5, -0.2, ...]].
位置编码:
-
由于自注意力机制本身不包括位置信息,需通过正弦/余弦函数生成位置编码,与词嵌入相加。
-
公式:
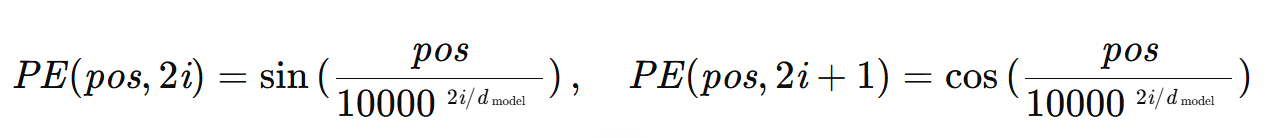
其中,pos是词的位置,i是维度索引,d_model是嵌入维度(如512)
-
作用:使模型能够区分词在序列中的顺序(如猫吃鱼与鱼吃猫)。
2 编码器(Encoder):特征提取与上下文建模
编码器由N个相同层堆叠(通常N=6),每次包含两个核心子层:
多头注意力机制:
- 原理:将输入序列的每个词与其他词建立关联,捕捉上下文依赖。
- 步骤:
(1)线性变换:将输入向量X映射为查询(Q)、键(K)、值(V)三个矩阵。
(2)缩放点积注意力:计算Q与K的点积,除以缩放因子,再通过softmax得到注意力权重,最后加权求和V。
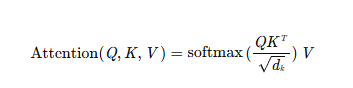
作用:模型可同时关注不同位置的词(如猫和鱼的关联)。
前馈神经网络(Feed-Forward Network,FFN):
- 结构:两个全连接层+ReLu激活函数
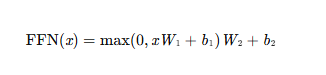
作用:对注意力输出的特征进行非线性变换,增强表达能力。
残差连接与层归一化:
- 残差连接:将子层输入与输出相加,缓解梯度消失问题。
- 层归一化:对每个样本的维度进行归一化,稳定训练过程。
3 解码器(Decoder):生成输出序列
解码器同样由N个相同层堆叠,每层包括三个核心子层:
掩码多头自注意力机制(Masked Multi-Head Self-Attention)
- 掩码机制:在计算注意力时,将未来位置(如生成第 t个词时,屏蔽 t+1及之后的词)的权重设为负无穷,确保自回归生成(逐词预测)。
- 作用:防止模型"偷看"未来信息,保证生成逻辑性。
编码器-解码器注意力(Encoder-Decoder Attention)
- 原理:解码器的 Q来自自身,而 K,V来自编码器的输出,使解码器能够关注输入序列的相关部分。
- 作用:建立输入与输出的对齐关系(如翻译中"Hello"对应"你好")。
前馈神经网络:
- 与编码器中的 FFN 结构相同,进一步处理特征。
残差连接与层归一化:
- 同编码器,确保训练稳定性。
4 输出处理:线性变换与 Softmax
线性层:
- 将解码器输出的向量映射到词汇表大小(如10,000维),得到每个词的概率分布。
Softmax
- 将线性层输出转换为概率值,选择概率最高的词作为预测结果。
三、总结
1 关键创新点
并行计算: 自注意力机制可同时处理所有位置,突破 RNN 的顺序计算限制。
长距离依赖建模: 通过多头注意力捕捉序列中任意位置的关联(如"虽然...但是"的语法结构)。
分成特征提取: 多层编码器逐步抽象语义(如第1层学词性,第6层学句子意图)。
自回归生成: 解码器通过掩码机制实现逐词预测,适用于生成任务(如翻译、文本摘要)。
2 应用场景
机器翻译: 编码器处理源语言,解码器生成目标语言。
文本生成: 如 GPT 模型,仅用解码器实现自回归生成。
预训练模型: 如 BERT(双向编码器)和 GPT(单向解码器),通过大规模无监督学习捕捉通用语言特征。