大家好,我是专注中国大模型生态与开发者工具的技术博主。今天我们来聊聊智谱AI(Zhipu AI)刚刚发布的GLM Coding Plan 致歉信 。这封公开信直面用户痛点,承认了 GLM-5 灰度开放以来在规则透明度、节奏把控和老用户升级机制上的三大主要失误,并公布了详细的处理与补偿方案。
这不仅是智谱的一次危机公关,更是国内大模型公司在流量爆炸、资源紧张下的真实写照。让我们一条条拆解信中内容,看看智谱是怎么"认错+补救"的。

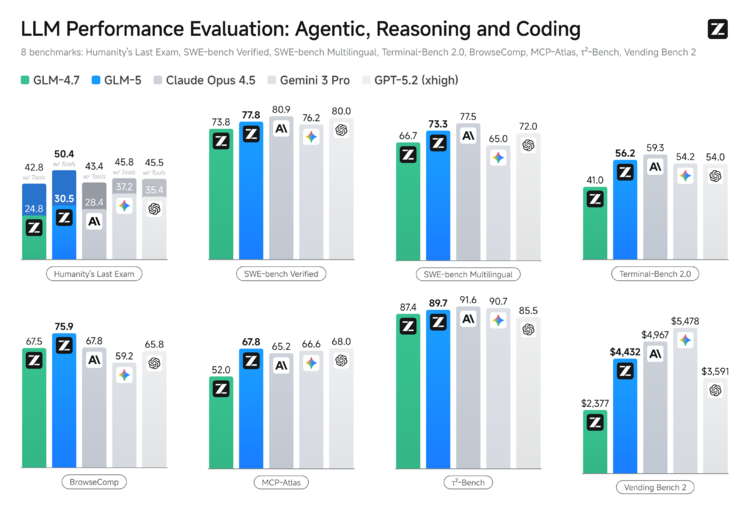
(上图:智谱 GLM-5 官方发布海报与性能对比图,GLM-5 在开源智能体编程榜单登顶,逼近 Claude Opus 4.5 水平)
三大核心失误:智谱自己总结的"锅"
-
规则透明度不够 GLM-5 定位为参数规模是 GLM-4.7 两倍以上 的"大杯"模型,目标是效果逼近 Claude Opus 4.5,适合复杂任务、Agentic Engineering、长上下文推理等重度场景。但为了让更多用户把 GLM-5 用在"真正需要"的地方,智谱设计了分层消耗策略:
- 日常简单任务优先调度 GLM-4.7(消耗正常)
- GLM-5 按高峰期 3 倍、非高峰期 2 倍计算 token 消耗
-
GLM-5 灰度节奏太慢 + 看板延迟 发布后流量远超预期,同时叠加灰产号池、黄牛党恶意占用资源,扩容节奏跟不上,不得不分阶段开放:Max → Pro → Lite。 早期看板刷新周期长达 1 小时,用户根本看不到实时消耗变化,加剧了不满。
-
老用户升级机制设计粗糙 部分老用户在 2 月 12-16 日期间误升新套餐,系统没有提供便捷回滚通道,引发集中投诉。
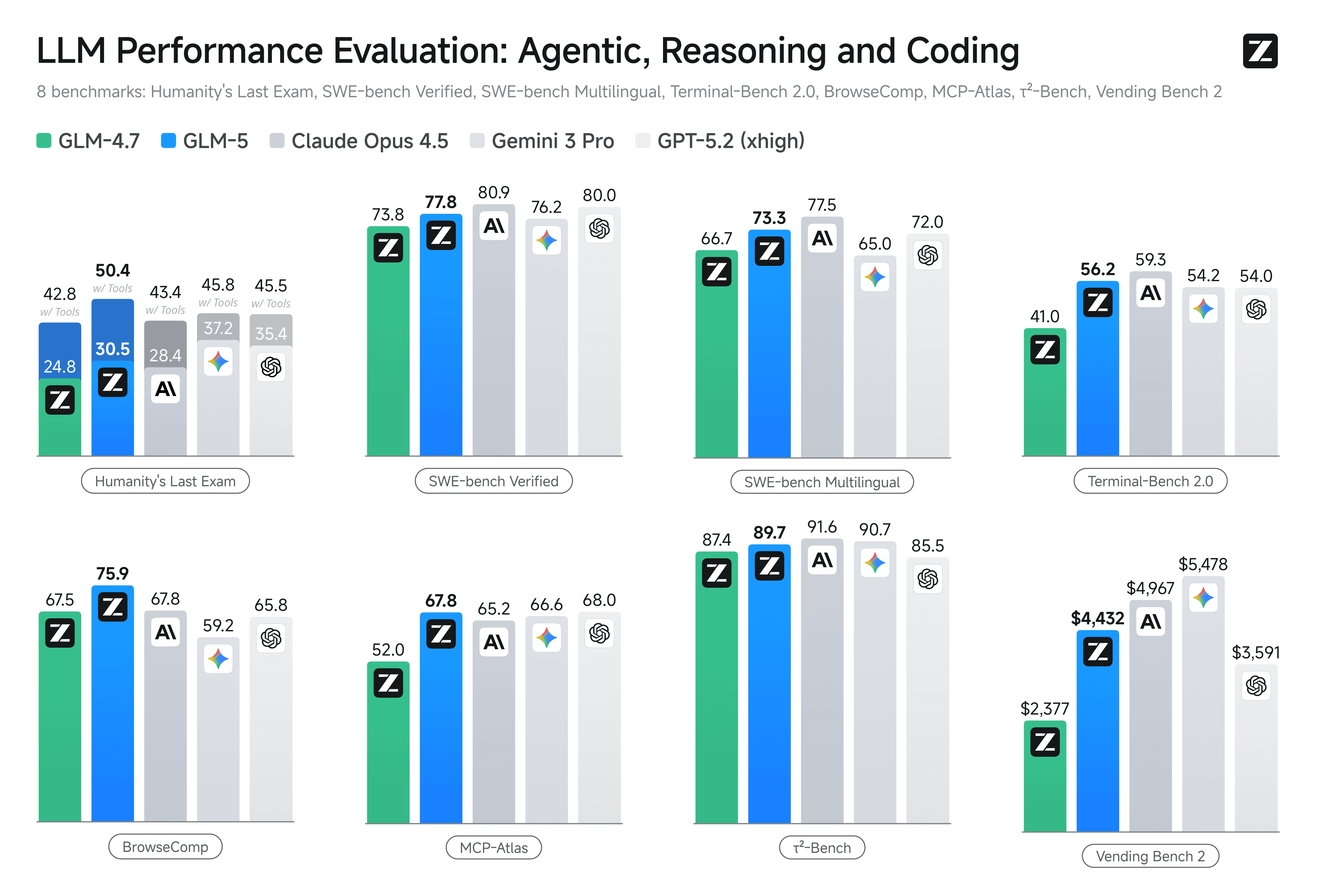
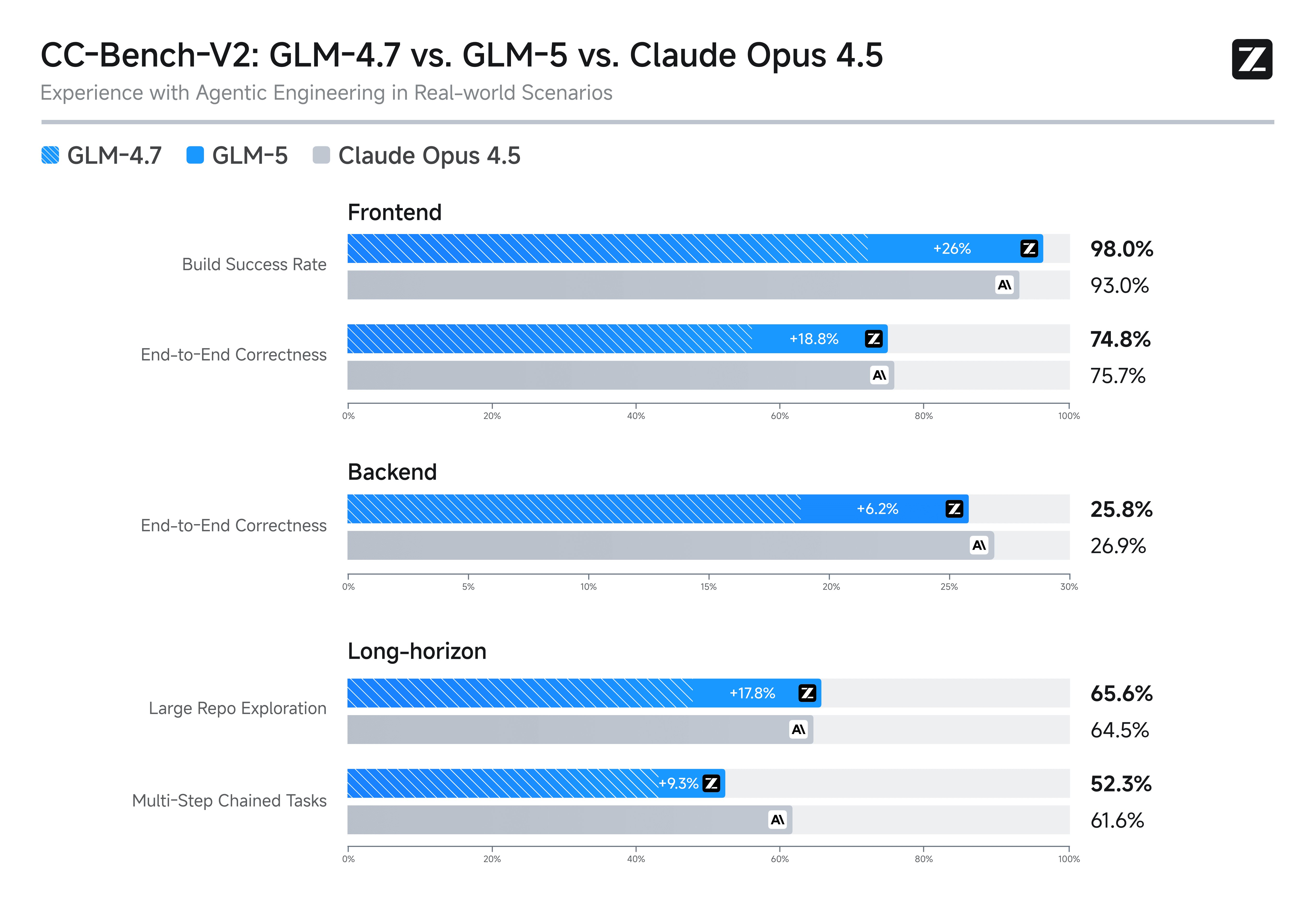
(上图:GLM-5 vs GLM-4.7 vs Claude Opus 4.5 在 SWE-bench、Terminal-Bench 等编程核心榜单的详细对比,GLM-5 在 Agentic 场景大幅领先)
智谱的补救措施:补偿 + 优化双管齐下
-
消耗与规则透明化
- 购买页面已全面展示 GLM-5 的详细消耗倍率和分层调度逻辑。
- 看板刷新频率从 1 小时优化到 10 分钟一次 ,用户能实时监控用量。
-
分阶段开放进度更新
- Max 用户已全面开放。
- Pro 用户已开放,但高峰期可能因集群负载限流。
- Lite 用户将在节后非高峰期逐步灰度开放。 智谱还提到,这种"流量爆表+限流"策略在同行也常见(如去年 Claude 3.5 发布时对 Pro 用户加限额)。
-
用户补偿方案(最硬核部分)
- 受影响的 Lite 和 Pro 用户(不分新老) :支持自主申请退款 。 退款范围:2026 年 1 月 1 日至今日,全部请客(即全额退还对应期间费用)。
- 2 月 12-16 日误升新套餐的老用户 :支持一键回滚到原套餐。
这两条补偿力度很大,基本覆盖了所有核心痛点用户,体现了智谱"把用户体验放第一"的态度。
(上图:智谱 GLM Coding Plan 官方定价页面截图,Lite/Pro/Max 三档清晰对比,首购享 5 折特惠)
技术视角:为什么 GLM-5 要"贵"这么多?
GLM-5 是智谱当前旗舰 MoE 混合专家模型(参数规模显著大于 GLM-4.7),在 SWE-bench Verified、Terminal-Bench 2.0 等编程/Agent 榜单上达到开源 SOTA,综合性能逼近 Claude Opus 4.5。
但"大模型 = 高算力 = 高成本"是行业铁律:
- 推理时 KV Cache、上下文长度、复杂 Agent 链路都会成倍放大显存与计算需求。
- 分层调度(简单任务走小模型、重任务走大模型)是目前最成熟的性价比方案,类似 OpenAI 的 GPT-4o mini + GPT-4o、Claude 的 Haiku + Sonnet + Opus。
智谱的 2-3 倍消耗倍率,其实已经是相对克制的定价策略。但关键在于提前沟通不足,让用户感觉"被偷袭"。
结语:大模型时代,用户与厂商都在共同成长
这封致歉信反映出国内大模型公司在 2026 年面临的真实困境:技术迭代快、用户期待高、资源永远不够用。智谱选择公开认错 + 真金白银补偿,是对用户负责任的表现,也给行业树立了一个正面案例。
如果你是 GLM Coding Plan 的 Pro/Lite 用户,建议尽快检查看板、申请退款或回滚;如果你是开发者,不妨继续关注 GLM-5 的后续优化------毕竟,在开源编程领域,它已经是性价比极高的选择之一。
你怎么看这次事件?是觉得智谱处理得当,还是补偿力度还不够?欢迎评论区讨论!我们会持续跟踪智谱后续更新,带来更多 GLM-5 实测与开发者工具解读。